文章目录
VectorStore存储组件
VectorStore组件介绍
对非结构化数据的存储与检索,最常用的方法是先将文本进行嵌入,转换为向量后存储到向量数据库中;在查询时,同样将查询文本嵌入生成向量,再将该向量传递给向量数据库,由数据库完成后续的相似度计算与检索过程。
在 LangChain 中,这一过程由顶层接口 VectorStore 统一管理,不同类型的向量数据库只需实现该接口中的抽象方法即可完成集成。VectorStore 接口提供了多个常用方法,例如:
- add_texts:将文本列表转换为向量,并存储到向量数据库。
- add_documents:将文档列表转换为向量,并存储到向量数据库。
- as_retriever:返回向量数据库初始化的检索器。
- similarity_search_with_relevance_scores:进行相似性检索,返回文档及其相关性得分(范围在0,1之间)。
- delete:根据向量id删除向量数据
- from_texts:传入文本列表、元数据信息、文本嵌入模型,返回创建好的VectorStore。
VectorStore接口,常用的实现类如下:
| 类名 | 描述 |
|---|---|
| InMemoryVectorStore | 基于内存实现的向量数据库 |
| ElasticsearchStore | Elasticsearch为基础实现的向量数据库 |
| TencentVectorDB | 腾讯向量数据库,当前类还在community包下,没有独立出来 |
| PineconeVectorStore | Pinecone向量数据库 |
| WeaviateVectorStore | Weaviate向量数据库 |
RedisVectorStore数据存储
RedisVectorStore是 VectorStore 接口的一个实现类,下面将以它为例介绍 VectorStore 的用法。在使用 WeaviateVectorStore 之前,需要先安装 langchain-redis 依赖:
python
pip install langchain-redisRedis 向量存储可参考文档:https://www.langchain.com.cn/docs/integrations/vectorstores/redis/
Ollama Embedding 可参考文档:https://python.langchain.com/api_reference/community/embeddings/langchain_community.embeddings.ollama.OllamaEmbeddings.html
接下来,先展示如何Ollama Embedding 转为词向量后使用 RedisVectorStore 进行数据存储,示例程序如下
python
from langchain_ollama import OllamaEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
import dotenv
# 读取env配置
dotenv.load_dotenv()
# 初始化 Embedding 模型
embedding = OllamaEmbeddings(model="deepseek-r1:14b")
# ========== 存储数据 ==========
# 定义待处理的文本数据列表
texts = [
"我喜欢吃苹果",
"苹果是我最喜欢吃的水果",
"我喜欢用苹果手机",
]
# 获取文本向量
# 使用embedding模型将文本转换为向量表示
embeddings = embedding.embed_documents(texts)
# 打印结果
# 遍历并打印每个文本及其对应的向量信息
for i, vec in enumerate(embeddings, 1):
print(f"文本 {i}: {texts[i-1]}")
print(f"向量长度: {len(vec)}")
print(f"前5个向量值: {vec[:10]}\n")
# 定义每条文本对应的元数据信息
metadata = [{"segment_id": "1"}, {"segment_id": "2"}, {"segment_id": "3"}]
# 配置Redis连接参数和索引名称
config = RedisConfig(
index_name="newsgroups",
redis_url="redis://localhost:6379",
)
# 创建Redis向量存储实例
vector_store = RedisVectorStore(embedding, config=config)
# 将文本和元数据添加到向量存储中
ids = vector_store.add_texts(texts, metadata)
# 打印前5个存储记录的ID
print(ids[0:5])执行结果如下
python
10:12:26 httpx INFO HTTP Request: POST http://127.0.0.1:11434/api/embed "HTTP/1.1 200 OK"
文本 1: 我喜欢吃苹果
向量长度: 5120
前5个向量值: [-0.0048059775, 0.0110130375, 0.0008511835, 0.00023040122, 0.0031677634, 0.00023193852, -0.0036830187, 0.00031026654, 0.003424279, 0.002071732]
文本 2: 苹果是我最喜欢吃的水果
向量长度: 5120
前5个向量值: [-0.016867071, 0.006843345, 0.0056118295, -0.012666135, -0.00062124344, 0.0024224545, -0.0016708882, -0.0017295848, 0.01790834, 0.0042891167]
文本 3: 我喜欢用苹果手机
向量长度: 5120
前5个向量值: [0.0014743459, 0.0019745259, 0.003218666, 0.0019062049, -0.008469705, -0.003524136, -0.0010743507, -0.0026532735, -0.0065791565, 0.0043244734]
10:12:26 httpx INFO HTTP Request: POST http://127.0.0.1:11434/api/embed "HTTP/1.1 200 OK"
10:12:26 redisvl.index.index INFO Index already exists, not overwriting.
10:12:26 httpx INFO HTTP Request: POST http://127.0.0.1:11434/api/embed "HTTP/1.1 200 OK"
['newsgroups::01K4HQ5H2JJ5Z5C3KW6RZVMFWZ', 'newsgroups::01K4HQ5H2JJ5Z5C3KW6RZVMFX0', 'newsgroups::01K4HQ5H2JJ5Z5C查看 Redis 数据
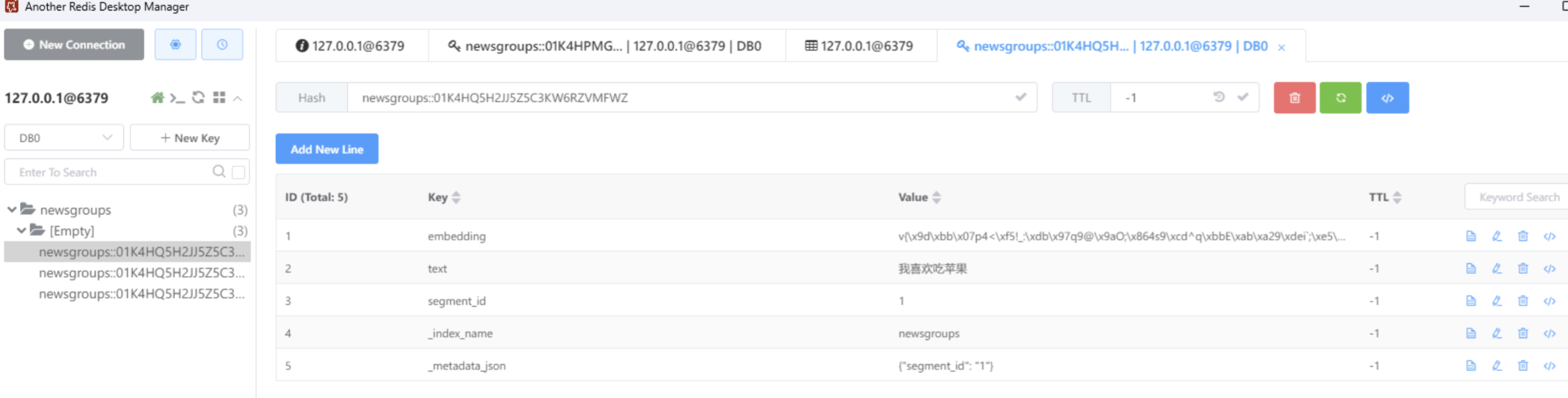
RedisVectorStore数据检索
在上面的示例程序中,我们将文本信息和元数据信息都保存到了数据库中。接下来,使用 VectorStore的similarity_search_with_relevance_scores() 方法进行相似性检索。在调用该方法时,传入查询文本 query,并指定 k=3,即返回匹配分数最高的三条数据(k 的默认值为 4)。
python
from langchain_ollama import OllamaEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
import dotenv
# 读取env配置
dotenv.load_dotenv()
# 初始化 Embedding 模型
embedding = OllamaEmbeddings(model="deepseek-r1:14b")
# 配置Redis连接参数和索引名称
config = RedisConfig(
index_name="newsgroups",
redis_url="redis://localhost:6379",
)
# 创建Redis向量存储实例
vector_store = RedisVectorStore(embedding, config=config)
# ========== 查询数据 ==========
# 定义查询文本
query = "我喜欢用什么手机"
# 将查询语句向量化,并在Redis中做相似度检索
results = vector_store.similarity_search_with_score(query, k=3)
print("=== 查询结果 ===")
for i, (doc, score) in enumerate(results, 1):
similarity = 1 - score # score 是距离,可以转成相似度
print(f"结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
print(f"相似度: {similarity:.4f}")执行结果如下,返回了3个与查询文本最相关的文本信息。
python
=== 查询结果 ===
结果 1:
内容: 我喜欢用苹果手机
元数据: {'segment_id': '3'}
相似度: 0.9202
结果 2:
内容: 我喜欢吃苹果
元数据: {'segment_id': '1'}
相似度: 0.8157
结果 3:
内容: 苹果是我最喜欢吃的水果
元数据: {'segment_id': '2'}
相似度: 0.6804Retrievers检索器组件
BaseRetriever接口
BaseRetriever 是检索器相关类的顶层接口。当给定一个查询文本需要进行非结构化查询时,它比 VectorStore 更为通用。检索器本身不需要存储文档,只要能够对文档进行检索并返回检索到的文档即可。检索器可以通过 VectorStore 创建,也可以对诸如维基百科等数据源进行检索。
在 langchain 项目中, VectorStore 是 底层存储接口,负责和具体的向量数据库交互(比如 Redis、Weaviate、Milvus、Pinecone 等) ,而 VectorStoreRetriever 是 LangChain 的 Retriever 抽象(Retriever 是统一的"检索器"接口,用于在链/Agent 中做检索)。
最重要的是,BaseRetriever 是一个可运行组件,它可以方便地使用 LECL 表达式对检索器组件进行集成。检索器接受一个查询文本作为输入,返回一个 Document 对象列表作为输出。BaseRetriever 的 invoke 方法定义如下:
python
def invoke(
self, input: str, config: Optional[RunnableConfig] = None, **kwargs: Any
) -> List[Document]:VectorStoreRetriever使用
在 RAG 应用中,当需要基于向量数据库进行文档检索时,就可以使用VectorStoreRetriever。它封装了向量数据库检索的底层逻辑,能够直接调用 VectorStore 的方法,从向量数据库中检索最相关的文档。
在前面介绍 VectorStore 常用方法时,包括了 as_retriever() 方法,该方法可以构建一个检索器对象,这个检索器就是 VectorStoreRetriever。
使用示例如下,使用as_retriever()方法创建了一个VectorStoreRetriever 对象,之后调用invoke()方法传入query进行文档检索。
python
from langchain_ollama import OllamaEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
import dotenv
# 读取env配置
dotenv.load_dotenv()
# 初始化 Embedding 模型
embedding = OllamaEmbeddings(model="deepseek-r1:14b")
# 配置Redis连接参数和索引名称
config = RedisConfig(
index_name="newsgroups",
redis_url="redis://localhost:6379",
)
# 创建Redis向量存储实例
vector_store = RedisVectorStore(embedding, config=config)
# 创建检索器,进行数据检索
retriever = vector_store.as_retriever()
documents = retriever.invoke("介绍一下我喜欢用什么手机")
for document in documents:
print(document.page_content)
print(document.metadata)
print("=================================")执行结果如下:
python
我喜欢用苹果手机
{'segment_id': '3'}
=================================
我喜欢吃苹果
{'segment_id': '1'}
=================================
苹果是我最喜欢吃的水果
{'segment_id': '2'}
=================================在默认情况下,检索器使用相似性检索方式进行检索。另一种检索方式是最大边际相关性检索(简称 MMR),可以在调用 as_retriever() 方法时通过 search_type="mmr" 指定,但前提是检索器所使用的底层数据库必须支持该检索方式。
python
retriever = vector_store.as_retriever(search_type="mmr")除了 search_type 之外,还可以使用 search_kwargs 将参数传递给 VectorStore 的底层搜索方法,例如传递 k 值,将默认匹配度最高的前三个文档返回(默认 k=4)。
python
retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": 3})MultiQueryRetriever使用
在向量检索过程中,查询文本会被转换为向量,并通过计算向量间距离来检索相似文档。然而,检索结果的准确性可能会受到查询文本表达方式的影响。
因此,为了提升查询结果的准确性,可以将查询文本传递给大语言模型,由其生成多个不同表达方式的查询文本变体。随后,使用这些不同的查询文本分别进行文档检索,并将所有检索结果汇总、排序,返回最相关的文档。
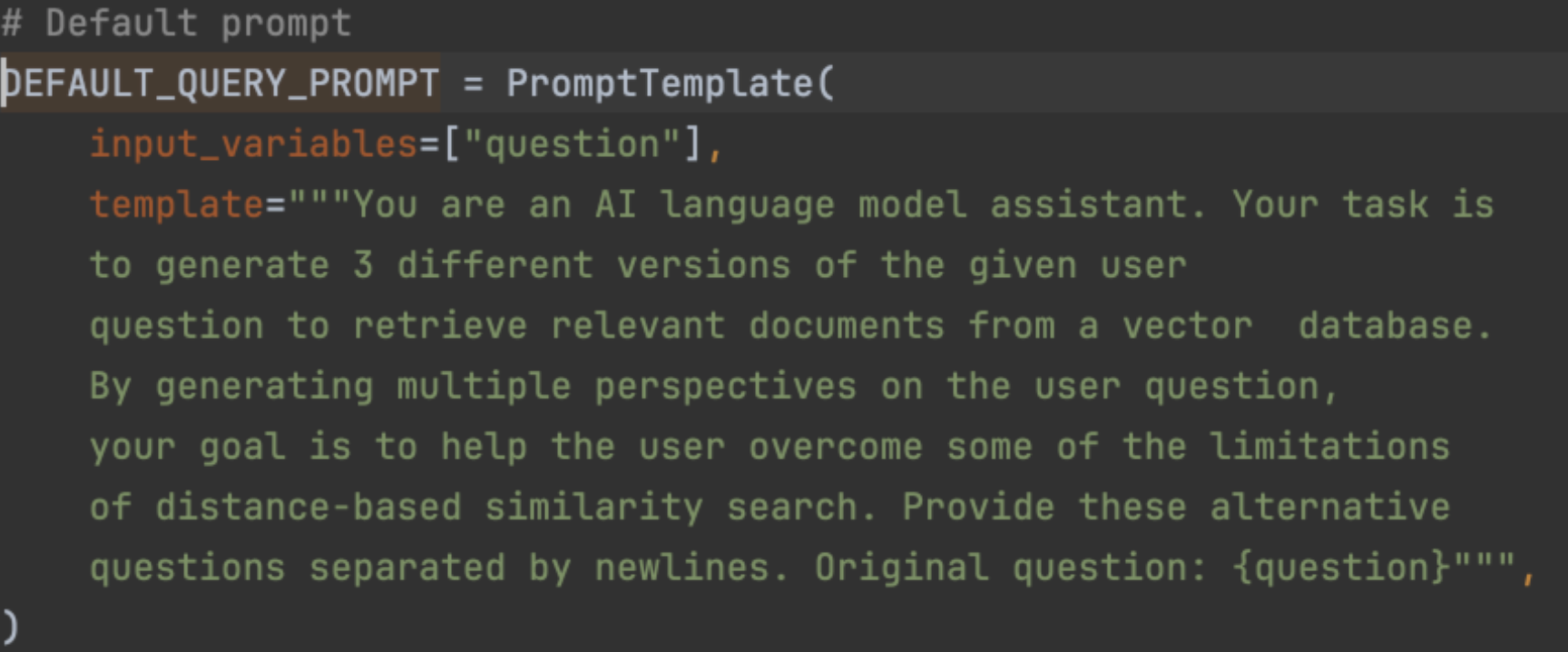
MultiQueryRetriever(多查询检索器)正是实现上述 RAG 检索优化逻辑的工具。可以使用 MultiQueryRetriever.from_llm() 方法创建一个多查询检索器。进入 from_llm() 源码可以看到,除了需要传递检索器对象和模型对象之外,还可以传入 prompt 参数,该参数用于调用大模型生成多个查询文本的提示词,并提供了默认值。
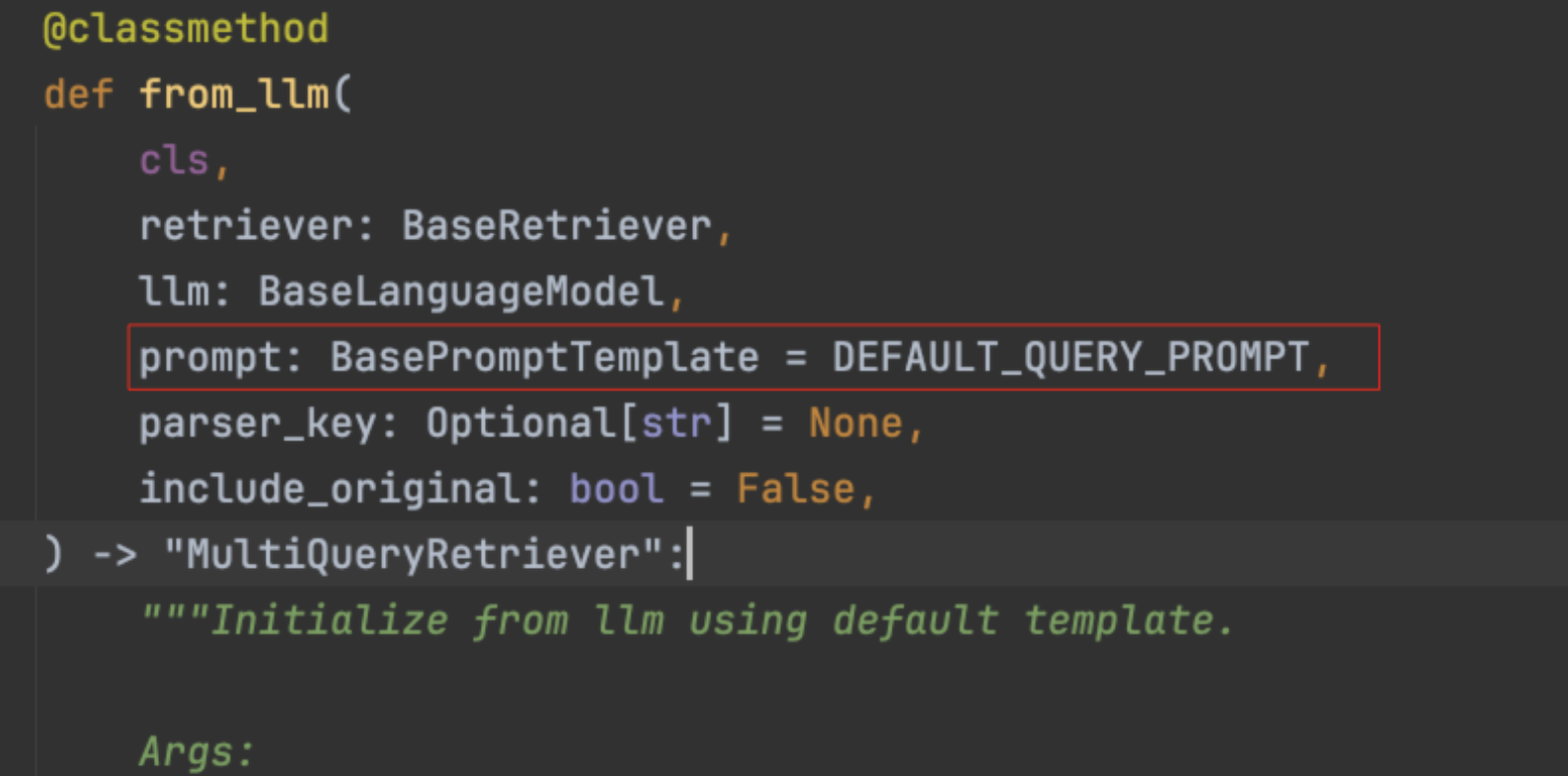
该默认提示词为英文版,在使用时需要进行汉化,否则返回的查询文本将全部为英文,导致检索效果下降。
MultiQueryRetriever 使用示例如下,首先进行了日志设置,在调用大语言模型生成多个查询文本时,MultiQueryRetriever 会进行 INFO 级别的日志打印,将生成的文本输出,
在创建 MultiQueryRetriever 时,需要传入 BaseRetriever 对象、模型对象以及汉化后的 prompt,之后同样通过调用invoke()方法传入查询文本进行检索。
python
from langchain.retrievers import MultiQueryRetriever
from langchain_core.prompts import PromptTemplate
from langchain_ollama import OllamaEmbeddings, ChatOllama
from langchain_redis import RedisConfig, RedisVectorStore
import dotenv
# 读取env配置
dotenv.load_dotenv()
# 初始化 Embedding 模型
embedding = OllamaEmbeddings(model="deepseek-r1:14b")
# 初始化大语言模型
llm = ChatOllama(model="deepseek-r1:14b", reasoning=False)
# 配置Redis连接参数和索引名称
config = RedisConfig(
index_name="newsgroups",
redis_url="redis://localhost:6379",
)
# 创建Redis向量存储实例
vector_store = RedisVectorStore(embedding, config=config)
# 创建多查询检索器
retriever = vector_store.as_retriever()
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=retriever, llm=llm,
prompt=PromptTemplate(
input_variables=["question"],
template="""你是一个 AI 语言模型助手。你的任务是:
为给定的用户问题生成 3 个不同的版本,以便从向量数据库中检索相关文档。
通过生成用户问题的多种视角(改写版本),
你的目标是帮助用户克服基于距离的相似性搜索的某些局限性。
请将这些改写后的问题用换行符分隔开。原始问题:{question}""")
)
# 5.进行数据检索
documents = retriever_from_llm.invoke("介绍一下我喜欢使用的手机")
for document in documents:
print(document.page_content)
print(document.metadata)
print("=================================")执行结果如下。通过日志可以观察到,LLM 生成了三个查询文本,并且最终检索结果中排在前面的前两条文档与查询文本的信息最为相关。
python
10:12:26 httpx INFO HTTP Request: POST http://127.0.0.1:11434/api/embed "HTTP/1.1 200 OK"
10:12:26 redisvl.index.index INFO Index already exists, not overwriting.
10:12:26 httpx INFO HTTP Request: POST http://127.0.0.1:11434/api/chat "HTTP/1.1 200 OK"
10:12:26 langchain.retrievers.multi_query INFO Generated queries: ['你常用的手机有哪些特点? ', '你能描述一下你平时使用的一款手机吗? ', '你最喜欢使用的手机是什么样子的?']
10:12:26 httpx INFO HTTP Request: POST http://127.0.0.1:11434/api/embed "HTTP/1.1 200 OK"
10:12:26 httpx INFO HTTP Request: POST http://127.0.0.1:11434/api/embed "HTTP/1.1 200 OK"
10:12:26 httpx INFO HTTP Request: POST http://127.0.0.1:11434/api/embed "HTTP/1.1 200 OK"
苹果是我最喜欢吃的水果
{'segment_id': '2'}
=================================
我喜欢吃苹果
{'segment_id': '1'}
=================================
我喜欢用苹果手机
{'segment_id': '3'}
=================================自定义检索器实现
在前面已经介绍过 BaseRetriever 接口,我们可以通过继承 BaseRetriever 来实现自定义检索器。查看 BaseRetriever 的 invoke 方法(省略部分代码)可以发现,最终真正执行检索的核心方法是 _get_relevant_documents。
python
def invoke(
self, input: str, config: Optional[RunnableConfig] = None, **kwargs: Any
) -> List[Document]:
......
try:
_kwargs = kwargs if self._expects_other_args else {}
if self._new_arg_supported:
result = self._get_relevant_documents(
input, run_manager=run_manager, **_kwargs
)
else:
result = self._get_relevant_documents(input, **_kwargs)
except Exception as e:
run_manager.on_retriever_error(e)
raise e
else:
run_manager.on_retriever_end(
result,
)
return result并且 _get_relevant_documents 是一个抽象方法,需要由子类去实现。
python
@abstractmethod
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:因此,实现一个自定义检索器需要继承 BaseRetriever 并实现 _get_relevant_documents 方法。
假设有如下需求:需要一个自定义检索器,将传入的查询文本按空格拆分成关键词数组,并在文档中进行匹配。只要有任意一个关键词匹配成功,即返回该文档信息,同时支持通过传递参数控制检索器返回的文档数量。
具体实现该需求的代码示例如下:
python
from typing import List
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetriever
class KeywordsRetriever(BaseRetriever):
"""自定义检索器
该检索器根据查询中的关键词来检索相关文档,支持返回前k个匹配的文档
Attributes:
documents: 文档列表,用于检索的文档集合
k: 返回文档数量,指定最多返回多少个相关文档
"""
documents: List[Document]
k: int
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:
"""根据查询关键词检索相关文档
Args:
query: 查询字符串,将被拆分为多个关键词进行匹配
run_manager: 回调管理器,用于处理检索过程中的回调
Returns:
List[Document]: 包含匹配文档的列表,最多返回k个文档
"""
# 获取返回文档数量参数
k = self.k if self.k is not None else 3
documents_result = []
# 将查询字符串按空格拆分为关键词列表
query_keywords = query.split(" ")
# 遍历所有文档,筛选包含任一关键词的文档
for document in self.documents:
if any(query_keyword in document.page_content for query_keyword in query_keywords):
documents_result.append(document)
# 返回前k个匹配的文档
return documents_result[:k]
# 定义文档列表,包含用于检索的文本内容
documents = [
Document("苹果是我最喜欢吃的水果"),
Document("我喜欢吃苹果"),
Document("我喜欢用苹果手机"),
]
# 创建关键词检索器实例,设置文档集合和返回文档数量
retriever = KeywordsRetriever(documents=documents, k=1)
# 执行检索操作,根据查询"手机"查找相关文档
result = retriever.invoke("手机")
# 输出检索结果,打印匹配文档的内容
for document in result:
print(document.page_content)
print("===========================")执行结果
python
我喜欢用苹果手机
===========================