在计算机视觉领域,目标检测始终是一个充满活力且至关重要的研究方向。从最初的R-CNN系列到如今百花齐放的算法家族,其演进史就是一部追求"更快、更准、更智能"的奋斗史。而其中,YOLO系列凭借其独特的一阶段检测思路、卓越的实时性能和高精度的巧妙平衡,长期以来都是工业界和学术界关注的焦点,YOLO的进化也从未停止。在保证速度的前提下,深度集成多种注意力机制是提升模型在复杂场景下判别力的关键路径。 这也引出了我们今天要探讨的核心问题:当面对极端环境,比如浓烟滚滚、火光冲天、背景杂乱、目标微小的消防救援现场时,现有的YOLO"利器"是否依然锋利?又该如何锻造一把更适应此等"地狱难度"场景的新武器?
《FireRescue: A UAV-Based Dataset and Enhanced YOLO Model for Object Detection in Fire Rescue Scenes》的研究给出了精彩的答案。它不仅揭示了现有模型在垂直应用领域的局限,更通过构建大规模消防救援专用数据集和提出增强型FRS-YOLO模型,为我们展示了如何针对特定场景的痛点进行精准创新。

痛点剖析:为什么通用YOLO在火场会"失灵"?
想象一下无人机从高空俯瞰火场的画面:消防车小如蚁虫,淹没在建筑和车辆的背景中;浓密的黑烟与喷溅的水雾让画面模糊不清,对比度骤降;一辆红色普通卡车和一辆消防车并肩停放,轮廓相似,极易混淆......这些场景对目标检测器提出了严峻挑战:
- 数据鸿沟: 主流数据集(如COCO、VisDrone)缺乏消防车、消防员、火焰、烟雾等关键类别,模型"没见过"自然"认不出"。
- 小目标与遮挡: 高空视角下,关键目标像素占比极小,加之车辆、建筑遮挡,传统检测器特征提取困难,漏检率高。
- 极端视觉干扰: 烟雾、火焰、水花、灰尘造成严重的图像退化,模型鲁棒性面临巨大考验。
- 类间相似性混淆: 消防车与普通卡车、工程车等在颜色、形状上高度相似,在密集场景下易引发连锁误检。
基石:FireRescue------专为"逆火而行"打造的数据集
为了解决"无米之炊"的问题,研究团队首先构建了FireRescue数据集。这个数据集堪称消防救援视觉AI的"里程碑":
- 规模与质量: 包含15,980张无人机航拍图像,32,000+个高质量标注框。
- 场景与类别: 覆盖城市、山地、森林、水域等多场景,聚焦8类关键目标,包括5种专业消防车、消防员、火焰、烟雾。
- 专业保障: 所有标注均由资深消防专家团队逐帧审核校正,确保在复杂火场环境下的语义正确性。
- 挑战性: 包含了大量夜间、雨雾天气、小目标、严重遮挡和极端干扰的样本,更能检验模型的真实能力。
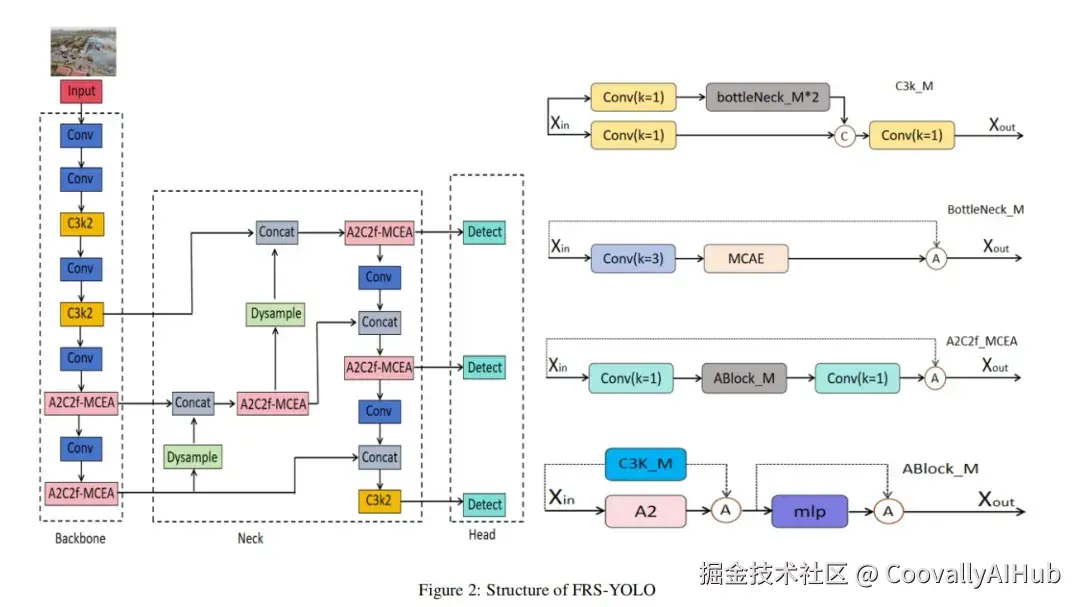
FRS-YOLO的两大核心创新
有了高质量数据,还需强大的模型。研究团队在YOLOv12的基础上,进行了两项关键创新,打造出FRS-YOLO。
- 创新一:多维协同增强注意力模块
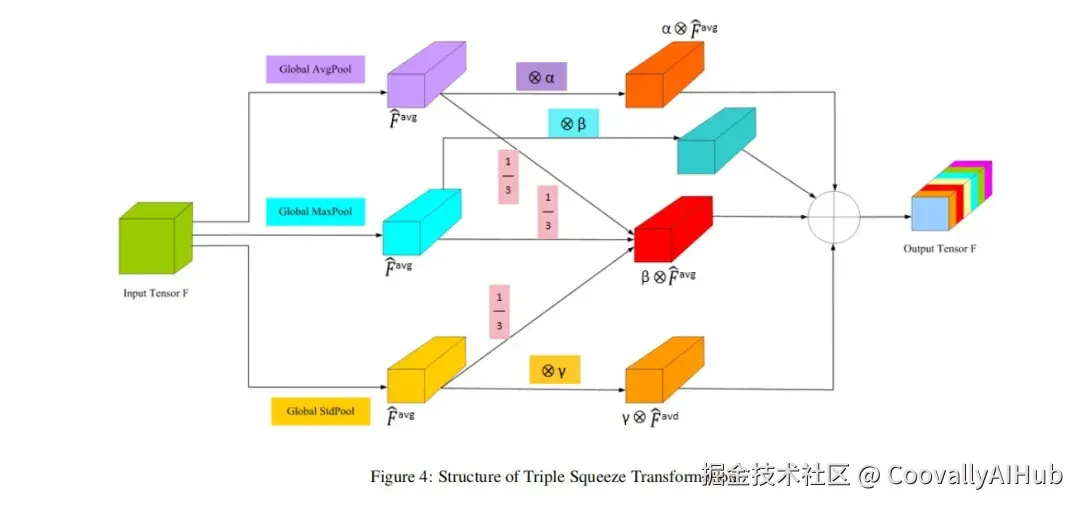
注意力机制能让模型"聚焦"关键信息。但传统注意力(如SE、CBAM)在火场这种复杂背景下,容易被无关信息分散,或因为降维操作丢失重要特征。
MCEA模块的聪明之处在于:
三重信息聚合:它没有简单地使用单一池化,而是并行整合了全局平均池化、标准差池化和全局最大池化。

为何是三者?
- 平均池化:获取整体上下文。
- 标准差池化:捕捉特征内部的波动与差异。
- 最大池化(关键!) :直接"锁定"最显著的特征点(如消防车的亮红色、警示灯的闪烁),防止小目标的微弱信号被复杂背景"淹没"。
- 自适应融合:通过可学习的权重参数,让模型自己决定在不同阶段、对不同特征,这三种信息该如何组合,形成更具判别力的特征描述符。
简单说,MCEA让模型学会了在浓烟中"火眼金睛",既能纵观全局,又能抓住最刺眼的关键细节。
- 创新二:动态上采样器
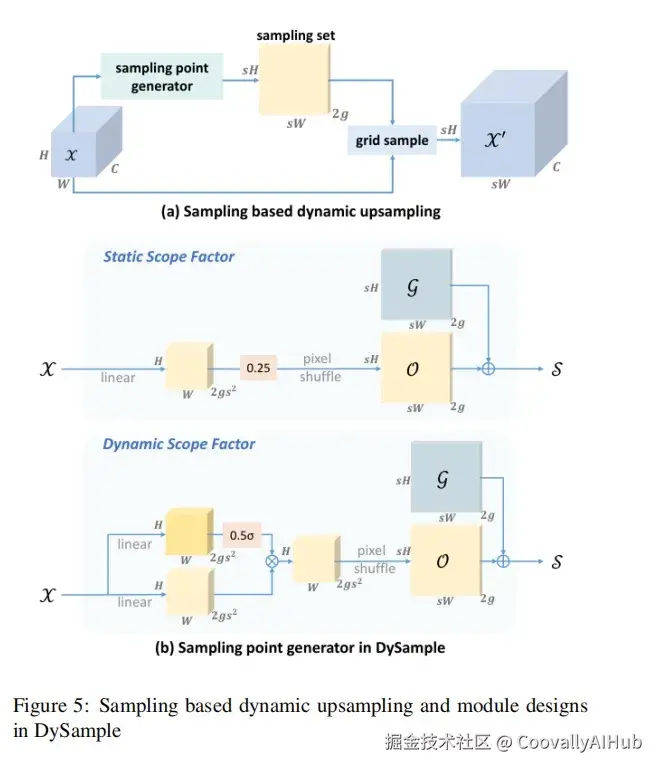
在特征金字塔中,上采样负责将低分辨率特征图放大,以便与高层特征融合。传统的插值方法(如最近邻)是"死板的",对所有区域一视同仁。
研究引入了Dysample,一种动态上采样器:
动态采样点:它根据特征图内容本身,动态生成采样点的位置偏移,而不是固定模式。
效果:这使得特征重建过程更具内容自适应性,能更好地恢复小目标的细节和轮廓,在存在烟雾模糊、像素损失的情况下,显著提升对小目标和模糊目标的定位精度。
实战效果:数据说话,眼见为实
实验在FireRescue数据集上进行,结果令人印象深刻:
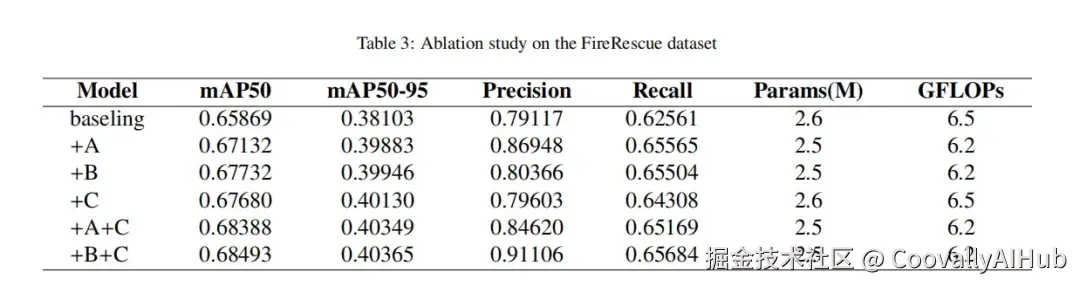
消融实验:逐项添加MCEA和Dysample,各项指标(mAP50, 召回率)均稳步提升,验证了每个模块的有效性。
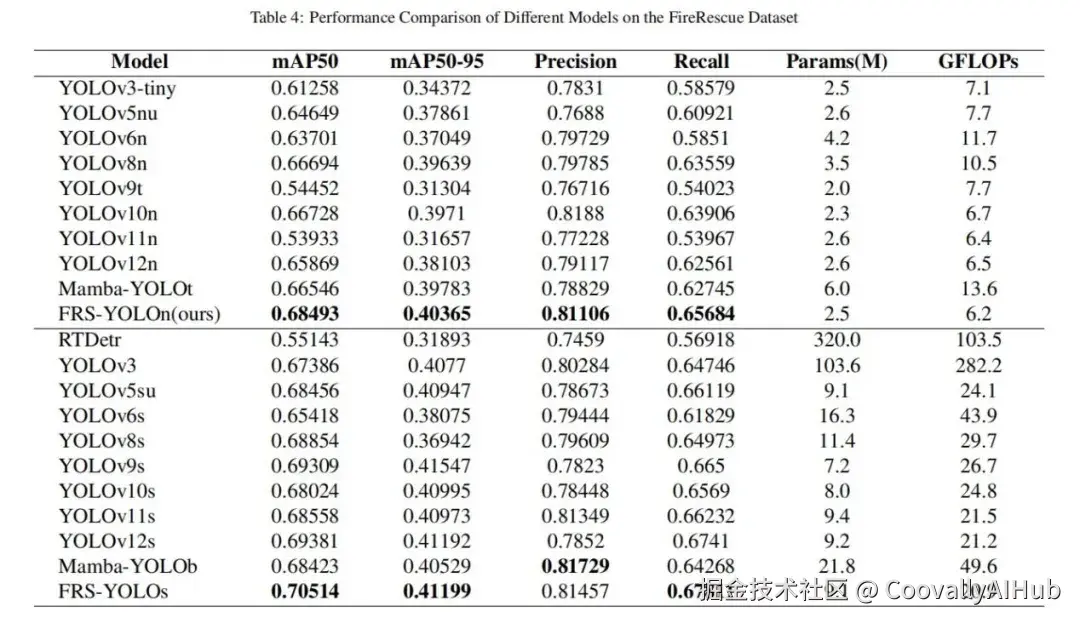
对比实验:FRS-YOLO(包括nano和small版本)在参数量几乎不变甚至略有减少的情况下,全面超越了同规模的YOLOv12、YOLOv10、YOLOv8等主流模型,在mAP50和召回率上取得显著优势。这证明了性能提升源于"架构创新",而非粗暴的"堆参数"。
- 可视化对比:
小目标与遮挡:在基线模型漏检严重的情况下,FRS-YOLO能通过车臂等局部特征成功检出被遮挡的消防车。
极端干扰:在浓烟火焰中,FRS-YOLO对关键救援车辆保持了更高的召回率。
相似目标辨别:在车辆密集处,FRS-YOLO有效降低了将普通卡车误判为消防车的概率。

热力图洞察:Grad-CAM热力图显示,基线模型的注意力常分散于背景,而FRS-YOLO的注意力则强有力地聚焦在目标本体及关键部件上,决策依据更清晰。

结论
本文通过引入基于YOLOv12构建的增强模型FRS-YOLO,应对了复杂消防救援场景下目标检测的挑战。本工作的一个关键贡献是创建了首个专为消防救援场景设计的综合性数据集,为该领域未来研究提供了宝贵的基准。其他贡献包括设计了一个多维协同增强注意力模块,该模块整合了全局平均池化、标准差池化和最大池化以丰富特征表示,同时重构了主干网络中的A2C2f模块以加强对判别性区域的关注。此外,我们引入了一个动态采样器,自适应地增强了模型对困难样本的关注,显著提高了在消防救援环境中尤其具有挑战性的小而模糊目标的检测精度。实验评估表明,所提方法在精度、mAP50、mAP50-95和召回率方面相比基线模型取得了显著提升,同时保持了理想的轻量特性。