


✅ 第 8 题:哈夫曼树如何"合并两个最小节点"
📘 本题考什么?
这道题不是考你会不会写哈夫曼编码,
而是考你是否真正理解👇
哈夫曼树在"合并两个最小节点"时,
新节点到底是什么?
要放进哪一个队列?
📌 正确答案:A
1、先认识 3 个"重要角色"(非常关键)
🧱 1️⃣ Node 结构体(树节点)
cpp
struct Node {
long long w; // 权值(频率)
int l, r; // 左右孩子(下标)
int sym; // 叶子:符号下标;内部节点:-1
};👉 记住一句话:
| 节点类型 | sym |
|---|---|
| 叶子节点 | ≥ 0 |
| 内部节点 | -1 |
🎵 2️⃣ leafIdx(A 队列)
cpp
vector<int> leafIdx;👉 这里放的是:
原始字符对应的"叶子节点"下标
-
一开始就排好序
-
只用于"最初的叶子"
🧩 3️⃣ internalIdx(B 队列)
cpp
vector<int> internalIdx;👉 这里放的是:
合并出来的新节点(内部节点)
2、哈夫曼算法的核心流程
🌳 哈夫曼树是这样长出来的:
1️⃣ 找到 当前权值最小的两个节点
2️⃣ 把它们合并成一个 新爸爸节点
3️⃣ 新节点:
-
权值 = 两个孩子的权值之和
-
左右孩子 = 这两个节点
-
不是叶子!
4️⃣ 把新节点放入 内部节点队列
5️⃣ 重复,直到只剩一个根
3、回到关键代码(第 3 步)
cpp
int x = PopMinNode(...);
int y = PopMinNode(...);
int z = (int)nodes.size();
________________________现在问题是👇
👉 合并 x 和 y 之后,这一行应该写什么?
4、一步一步分析"新节点 z 是什么"
🧠 新节点 z 的身份
| 属性 | 应该是什么 |
|---|---|
| 权值 w | nodes[x].w + nodes[y].w |
| 左孩子 l | x |
| 右孩子 r | y |
| sym | -1(不是叶子) |
👉 所以,新节点的正确创建方式是:
cpp
Node(nodes[x].w + nodes[y].w, x, y, -1)5、新节点 z 应该放进哪个队列?
❓ 能放进 leafIdx 吗?
❌ 绝对不行!
因为:
-
leafIdx只放 原始字符 -
新节点不是字符,是"合并节点"
✅ 正确答案
新节点必须放进 internalIdx(B 队列)
6、所以正确代码只能是👇
cpp
nodes.push_back(Node(nodes[x].w + nodes[y].w, x, y, -1));
internalIdx.push_back(z);👉 这正是 A 选项
7、逐个"打死"错误选项(非常重要)
❌ B 选项
cpp
nodes.push_back(...);
leafIdx.push_back(z);❌ 错在:
-
把"内部节点"
-
当成"叶子节点"
👉 逻辑错误
❌ C 选项
cpp
internalIdx.push_back(z);
nodes.push_back(Node(..., x+y));❌ 两个大错:
1️⃣ sym = x + y
- 内部节点的
sym必须是-1
2️⃣ 先 push index,再 push node
z指向了不存在的节点!
👉 逻辑 + 顺序双错
❌ D 选项
cpp
nodes.push_back(Node(..., x+y));
leafIdx.push_back(z);❌ 错上加错:
-
sym 错
-
队列错
8、给小学生的"记忆口诀"⭐
🧠 哈夫曼合并三原则:
1️⃣ 新节点不是字符 →
sym = -12️⃣ 新节点是内部节点 → 放 internalIdx
3️⃣ 叶子队列只放最初的字符
9、用一个"小画面"帮助记忆 🎨
cpp
叶子 A(2) 叶子 B(3)
\ /
\ /
新节点 C(5) ← 不是字符!👉 C:
-
权值 5
-
有左右孩子
-
必须进 internalIdx
✅ 最终总结
-
哈夫曼编码的合并节点:
-
sym = -1 -
放入
internalIdx
-
-
只有 A 同时满足这两个条件
-
所以本题答案 一定是 A

✅ 第 9 题:关于哈夫曼编码,哪个说法对?
📘 本题考什么?
👉 哈夫曼编码的核心性质
👉 前缀编码
1、先用一句话认识"哈夫曼编码"
🎯 哈夫曼编码是一种:
用得多的字符 → 编码短
用得少的字符 → 编码长
专门用来 压缩数据 的编码方法
2、正确选项:B(为什么一定对)
✅ B:
"哈夫曼编码中,没有任何一个字符的编码是另一个字符编码的前缀"
🧠 这句话什么意思?
👉 前缀 :
一个编码,是另一个编码的"开头"。
❌ 错误的例子(不是哈夫曼编码)
cpp
A : 0
B : 01-
0是01的前缀 -
看到
0,你不知道是 A 还是 B 的一部分
👉 解码会乱掉
✅ 哈夫曼编码一定满足
任何一个编码,
都不会是别人的开头
比如:
cpp
A : 0
B : 10
C : 11✔ 没有前缀冲突
✔ 一看就能解码
📌 这叫:前缀码(Prefix Code)
🧒 小学生理解
每个密码
都不能"踩到别人门口" 🚪
否则会走错房间
3、错误选项 A:为什么错?
❌ A:
"哈夫曼编码是定长编码"
🧠 什么叫"定长编码"?
每个字符,用的位数都一样
比如 ASCII 编码:
- 每个字符:8 位(1 个字节)
❌ 哈夫曼编码恰恰相反!
👉 哈夫曼编码是:变长编码
-
常见字符 → 编码短
-
罕见字符 → 编码长
🌰 举例
假设:
| 字符 | 频率 | 哈夫曼编码 |
|---|---|---|
| A | 很多 | 0 |
| B | 少 | 110 |
| C | 很少 | 111 |
👉 长短不一样!
🧒 记忆
定长 = 人人一样
哈夫曼 = 用得多就短
4、错误选项 C:为什么错?
❌ C:
"哈夫曼编码一定唯一"
🧠 真相是什么?
👉 哈夫曼编码的"长度分配"是最优的
👉 但 具体的 0 / 1 分配方式,不唯一
🌰 举例
假设:
| 字符 | 频率 |
|---|---|
| A | 5 |
| B | 5 |
| C | 10 |
可能的哈夫曼编码 1️⃣:
cpp
C : 0
A : 10
B : 11也可能是 2️⃣:
cpp
C : 1
A : 00
B : 01👉 都是合法的哈夫曼编码
👉 压缩效果一样
👉 但编码不同
🧒 小学生理解
树左右一换
0 和 1 调个位置
👉 还是对的 🌳
5、错误选项 D:为什么错?
❌ D:
"哈夫曼编码不能用于数据压缩"
🧠 这是完全反着说了!
👉 哈夫曼编码的最大作用就是压缩数据
🌍 真实应用
-
ZIP 压缩
-
图片压缩
-
音频压缩
-
文件压缩
👉 哈夫曼编码是"压缩界的大明星"
🧒 小学生理解
行李箱 🧳
常用的东西放前面
不常用的放后面
👉 更省空间
6、四个选项"对错总表"
| 选项 | 对 / 错 | 原因 |
|---|---|---|
| A | ❌ | 哈夫曼是变长编码 |
| B | ✅ | 前缀码,无歧义 |
| C | ❌ | 编码方式不唯一 |
| D | ❌ | 本来就是用来压缩的 |
7、给小学生的本题总结 ⭐
🧠 记住这 4 句话:
1️⃣ 哈夫曼编码是 变长编码
2️⃣ 哈夫曼编码 没有前缀冲突
3️⃣ 哈夫曼编码 不唯一
4️⃣ 哈夫曼编码 专门用来压缩
只要这 4 句话记住,
所有哈夫曼选择题基本都能秒杀 ✅

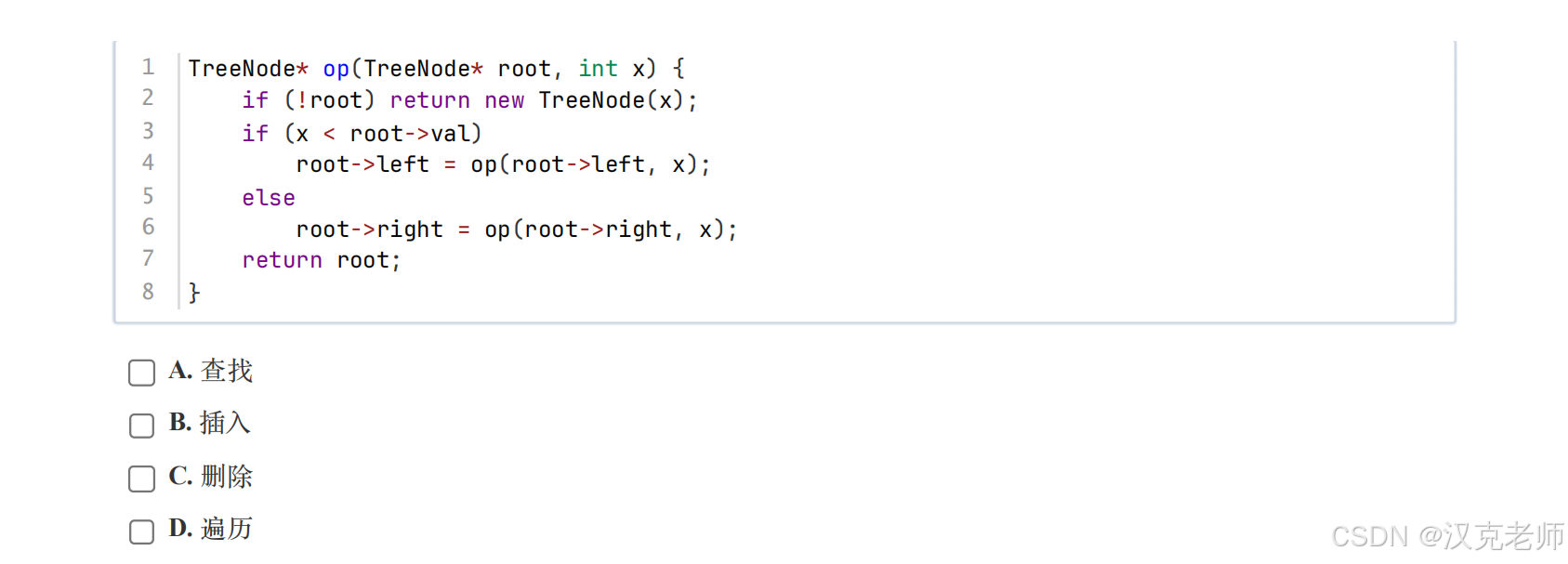
✅ 第 10 题:这段代码在做 BST 的什么操作?
📘 本题考什么?
👉 二叉搜索树(BST)
👉 递归操作
📌 正确答案:B(插入)
👀 关键代码
cpp
if (!root) return new TreeNode(x);
if (x < root->val)
root->left = op(root->left, x);
else
root->right = op(root->right, x);🧠 为什么是插入?
-
如果树是空的 → 新建节点
-
小的去左边
-
大的去右边
👉 完全符合 BST 插入规则
🧒 小学生理解
找位置 → 坐下
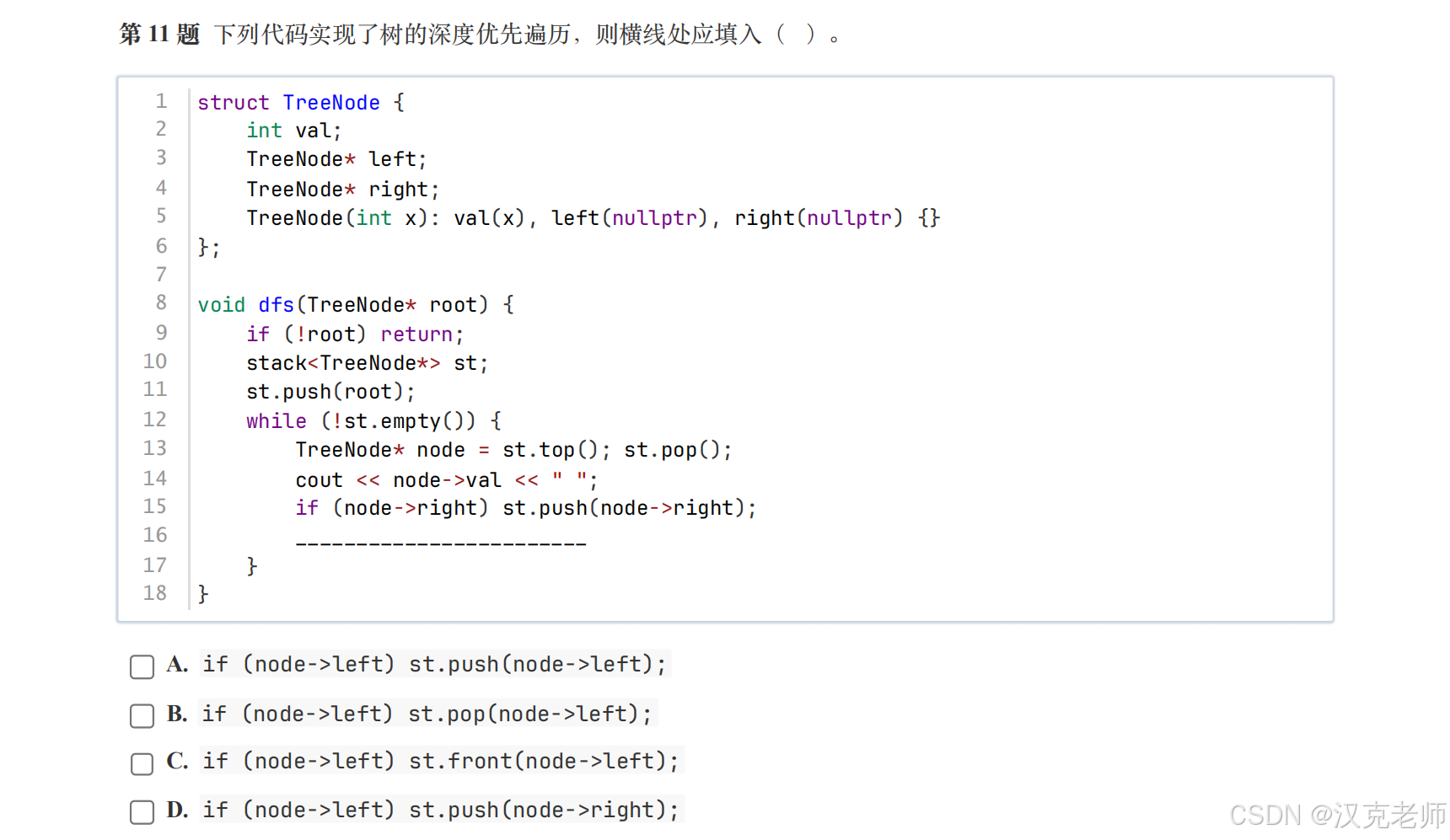
✅ 第 11 题:栈实现 DFS,横线填什么?
📘 本题考什么?
👉 深度优先遍历
👉 栈(stack)
👉 访问顺序
📌 正确答案:A
cpp
if (node->left)
st.push(node->left);🧠 为什么?
代码中已经有:
cpp
if (node->right)
st.push(node->right);👉 为了保证:
cpp
根 → 左 → 右👉 栈是后进先出
👉 右孩子先压,左孩子后压
🧒 口诀
"右先入,左先出"

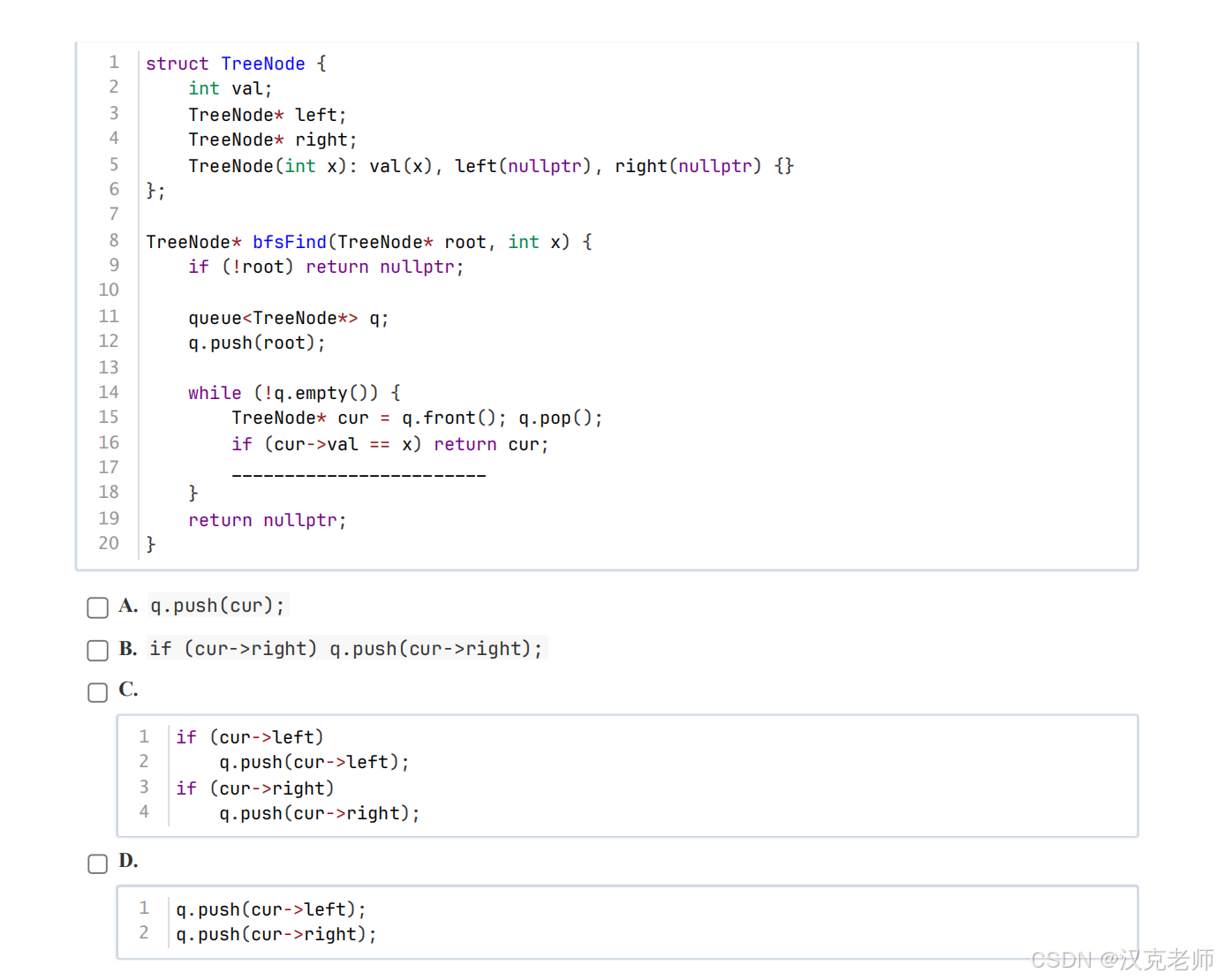
✅ 第 12 题:判断普通二叉树中是否存在值 x
📘 本题考什么?
👉 广度优先搜索(BFS)
👉 队列
📌 正确答案:C
cpp
if (cur->left)
q.push(cur->left);
if (cur->right)
q.push(cur->right);🧠 原理讲清楚
-
普通二叉树 ❌ 没有大小规则
-
只能 一个一个找
-
用 队列,从上到下找
🧒 小故事
教室找人:
第一排 → 第二排 → 第三排
👉 这就是 BFS
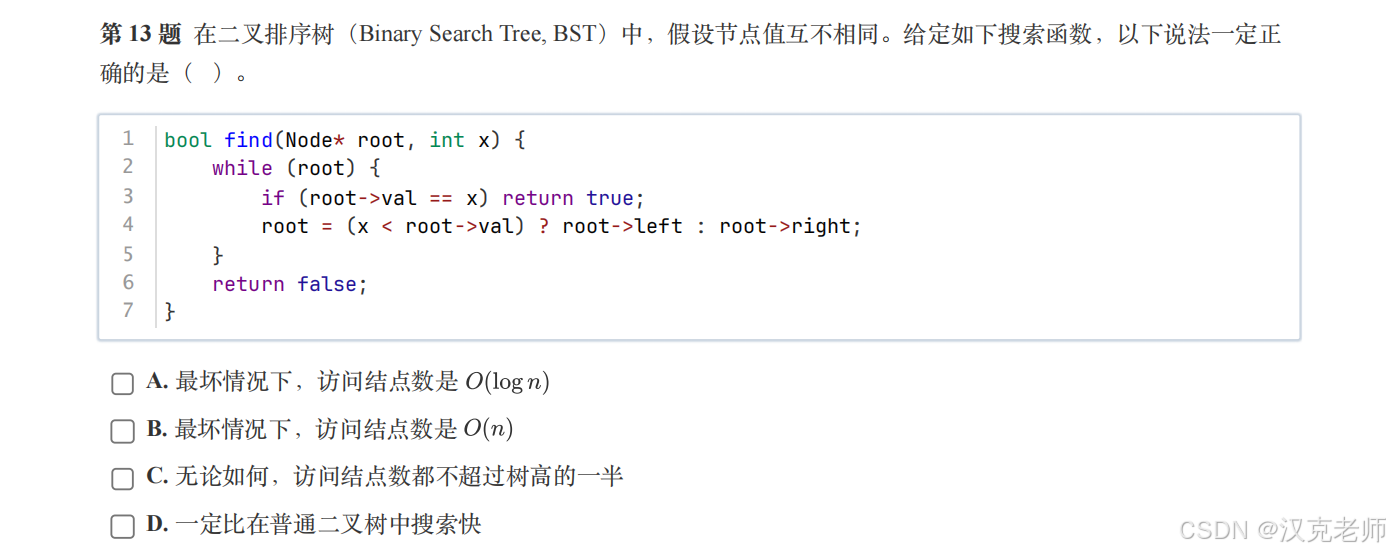
✅ 第 13 题:BST 搜索,哪个说法一定对?
📘 本题考什么?
👉 BST 搜索复杂度
📌 正确答案:B
👉 最坏情况:访问所有节点
🧠 为什么?
如果 BST 长这样:
cpp
1
\
2
\
3
\
4👉 就退化成 链表
👉 搜索要从头走到尾
❌ 其他选项为什么错?
-
A:正常情况是O(logn)
-
C:不一定小于一半
-
D:不一定比普通树快
🧒 记住一句话
BST 搜索,最差可能要全找一遍


✅ 第 14 题:0/1 背包,为什么 j 要倒着走?
📘 本题考什么?
👉 动态规划
👉 0/1 背包
📌 正确答案:B
👀 核心代码
cpp
for (int j = W; j >= w; --j)
dp[j] = max(dp[j], dp[j-w] + v);🧠 为什么要从大到小?
如果从小到大:
👉 同一件物品会被 重复使用
👉 就变成 完全背包
🧒 小故事
一件宝物只能拿一次
所以要 倒着算

✅ 第 15 题:关于动态规划,哪个说法是错的?
📘 本题考什么?
👉 动态规划基本理解
📌 正确答案:B
🧠 为什么 B 错?
动态规划时间复杂度
❌ 不是只和状态个数有关
还和:
-
状态转移次数
-
循环层数
有关
✅ 其他选项
-
A:有递推公式 ✔
-
C:有递归 & 递推 ✔
-
D:复杂度通常相当 ✔