相关项目下载链接
本节内容详细解析基于二进制球面量化(BSQ, Binary Spherical Quantization) 的 Patch 级自编码器代码bsq.py,该代码是在基础 Patch 自编码器ae.py之上扩展,核心目标是将连续的图像特征量化为离散整数 Token,同时保留图像重构能力,为后续自回归模型训练打下基础。具体流程如下:
导入依赖库
python
import abc
import torch
from .ae import PatchAutoEncoder定义模型加载函数
python
def load() -> torch.nn.Module:
from pathlib import Path
model_name = "BSQPatchAutoEncoder"
model_path = Path(__file__).parent / f"{model_name}.pth"
print(f"Loading {model_name} from {model_path}")
return torch.load(model_path, weights_only=False)定义可微分符号函数 diff_sign()
核心问题 :普通sign函数(x≥0→1,否则 - 1)是离散操作,梯度为 0,无法反向传播;
解决方案 :直通估计器(STE, Straight-Through Estimator):
作用:让 BSQ 的离散量化操作可训练,是端到端训练的核心。
python
def diff_sign(x: torch.Tensor) -> torch.Tensor:
sign = 2 * (x >= 0).float() - 1 # 离散输出±1
return x + (sign - x).detach() # STE直通估计器定义Tokenize抽象基类
python
class Tokenizer(abc.ABC):
@abc.abstractmethod
def encode_index(self, x: torch.Tensor) -> torch.Tensor:
"""图像→整数Token,形状(B,H,W,3)→(B,h,w)"""
@abc.abstractmethod
def decode_index(self, x: torch.Tensor) -> torch.Tensor:
"""整数Token→图像,形状(B,h,w)→(B,H,W,3)"""BSQ 核心量化模块(BSQ 类)
python
class BSQ(torch.nn.Module):
def __init__(self, codebook_bits: int, embedding_dim: int):
super().__init__()
self.codebook_bits = codebook_bits
self.embedding_dim = embedding_dim
self.down_proj = torch.nn.Linear(embedding_dim, codebook_bits)
self.up_proj = torch.nn.Linear(codebook_bits, embedding_dim)
def encode(self, x: torch.Tensor) -> torch.Tensor:
"""
Implement the BSQ encoder:
- A linear down-projection into codebook_bits dimensions
- L2 normalization
- differentiable sign
"""
x = self.down_proj(x) # 降维:将高维特征压缩到codebook_bits维
x = torch.nn.functional.normalize(x, p=2, dim=-1) # L2 归一化:将特征投影到单位球面,保证量化后分布均匀
x = diff_sign(x) # 可微分符号化:输出 ±1 的二进制量化码(离散值,可微分)
return x
def decode(self, x: torch.Tensor) -> torch.Tensor:
"""
Implement the BSQ decoder:
- A linear up-projection into embedding_dim should suffice
"""
x = self.up_proj(x) # 通过线性层将二进制量化码升维回原特征维度
return x
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.decode(self.encode(x))
# 对外接口
def encode_index(self, x: torch.Tensor) -> torch.Tensor:
"""
Run BQS and encode the input tensor x into a set of integer tokens
"""
return self._code_to_index(self.encode(x))
# 对外接口
def decode_index(self, x: torch.Tensor) -> torch.Tensor:
"""
Decode a set of integer tokens into an image.
"""
return self.decode(self._index_to_code(x))
# 量化码→Token
def _code_to_index(self, x: torch.Tensor) -> torch.Tensor:
x_bin = (x >= 0).int() # ±1→0/1二进制(1对应≥0,0对应<0)
# 生成位权(如10比特→[1,2,4,...,512]),reshape适配广播
bit_weights = 2 ** torch.arange(self.codebook_bits).to(x.device).reshape(1, 1, 1, -1)
x_idx = (x_bin * bit_weights).sum(dim=-1) # 二进制→整数,形状(B,h,w,codebook_bits)→(B,h,w)
return x_idx
# Token→量化码
def _index_to_code(self, x: torch.Tensor) -> torch.Tensor:
x_exp = x[..., None] # (B,h,w)→(B,h,w,1),适配广播
bit_weights = 2 ** torch.arange(self.codebook_bits).to(x.device).reshape(1, 1, 1, -1)
x_bin = (x_exp & bit_weights) > 0 # 按位与判断每一位是否为1,得到0/1二进制
x_code = 2 * x_bin.float() - 1 # 0/1→±1,还原量化码
return x_codeBSQPatchAutoEncoder:AE+BSQ 的组合实现
python
class BSQPatchAutoEncoder(PatchAutoEncoder, Tokenizer):
"""
Combine your PatchAutoEncoder with BSQ to form a Tokenizer.
Hint: The hyper-parameters below should work fine, no need to change them
Changing the patch-size of codebook-size will complicate later parts of the assignment.
"""
def __init__(self, patch_size: int = 5, latent_dim: int = 128, codebook_bits: int = 10):
super().__init__(patch_size=patch_size, latent_dim=latent_dim)
self.bsq = BSQ(codebook_bits=codebook_bits, embedding_dim=latent_dim)
self.codebook_bits = codebook_bits
self.patch_size = patch_size
self.latent_dim = latent_dim
# 实现 Tokenizer 接口
def encode_index(self, x: torch.Tensor) -> torch.Tensor:
latent = super().encode(x)
tokens = self.bsq.encode_index(latent)
return tokens
# 实现 Tokenizer 接口
def decode_index(self, x: torch.Tensor) -> torch.Tensor:
latent = self.bsq.decode_index(x)
recon_img = super().decode(latent)
return recon_img
# 重写 encode:整合 BSQ
def encode(self, x: torch.Tensor) -> torch.Tensor:
patch_latent = super().encode(x)
bsq_code = self.bsq.encode(patch_latent)
return bsq_code
# 重写 decode:整合 BSQ
def decode(self, x: torch.Tensor) -> torch.Tensor:
bsq_latent = self.bsq.decode(x)
recon_img = super().decode(bsq_latent)
return recon_img
# 前向传播 返回重构图像 + 监控指标
def forward(self, x: torch.Tensor) -> tuple[torch.Tensor, dict[str, torch.Tensor]]:
"""
Return the reconstructed image and a dictionary of additional loss terms you would like to
minimize (or even just visualize).
Hint: It can be helpful to monitor the codebook usage with
cnt = torch.bincount(self.encode_index(x).flatten(), minlength=2**self.codebook_bits)
and returning
{
"cb0": (cnt == 0).float().mean().detach(),
"cb2": (cnt <= 2).float().mean().detach(),
...
}
"""
recon_img = self.decode(self.encode(x))
recon_loss = torch.nn.functional.mse_loss(recon_img, x)
tokens = self.encode_index(x)
cnt = torch.bincount(tokens.flatten(), minlength=2 ** self.codebook_bits)
extra_metrics = {
"recon_loss": recon_loss,
"cb0": (cnt == 0).float().mean().detach(), # 未使用的码本比例
"cb2": (cnt <= 2).float().mean().detach(), # 使用次数<=2的码本比例
"avg_code_usage": cnt.float().mean().detach() # 平均码本使用次数
}
return recon_img, extra_metrics模块测评
下面进行模型训练:
python
python -m homework.train BSQPatchAutoEncoder模型训练过程如图所示

将代码打包为压缩文件
python
python bundle.py homework 20260104进行评分自测:
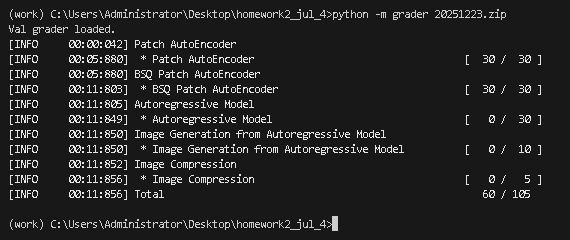
python
python -m grader 20260104.zip最终测试得分如下: