OCR(光学字符识别)是文字数字化的核心技术,而 PaddleOCR 凭借百度飞桨框架的底层优势,兼具高精度、轻量化与易部署特性,成为工业级 OCR 落地的首选方案。在 Linux 环境下搭建稳定的 PaddleOCR 识别服务器,既能满足批量文字识别、实时接口调用等业务需求,也能适配服务器端的高性能、高并发场景。本文聚焦实操层面,从环境依赖配置、PaddleOCR 源码部署,到服务器接口封装、性能调优,全程拆解 Linux 系统下 OCR 识别服务器的搭建流程,旨在帮助开发者快速完成从环境准备到服务上线的全流程落地,解决实际业务中文字识别的部署痛点。

1 服务环境安装
环境准备是服务稳定运行的基础,本节将完成 Conda 虚拟环境搭建、核心依赖安装及模型下载,适配 CPU 与 GPU 两种部署场景。
1.1 下载依赖
首先通过 Conda 创建独立的虚拟环境(避免依赖冲突),再根据硬件环境(CPU/GPU)安装对应的 PaddleOCR 相关依赖包。
shell
conda create -n paddleocr python=3.8
conda activate paddleocr
# CPU用户下载命令
python -m pip install -U paddle_serving_server paddle_serving_client paddle_serving_app paddlepaddle
# GPU用户下载命令
python -m pip install -U paddle_serving_server_gpu paddle_serving_client paddle_serving_app paddlepaddle-gpu
git clone https://github.com/paddlepaddle/Serving
# 下载其依赖
cd Serving
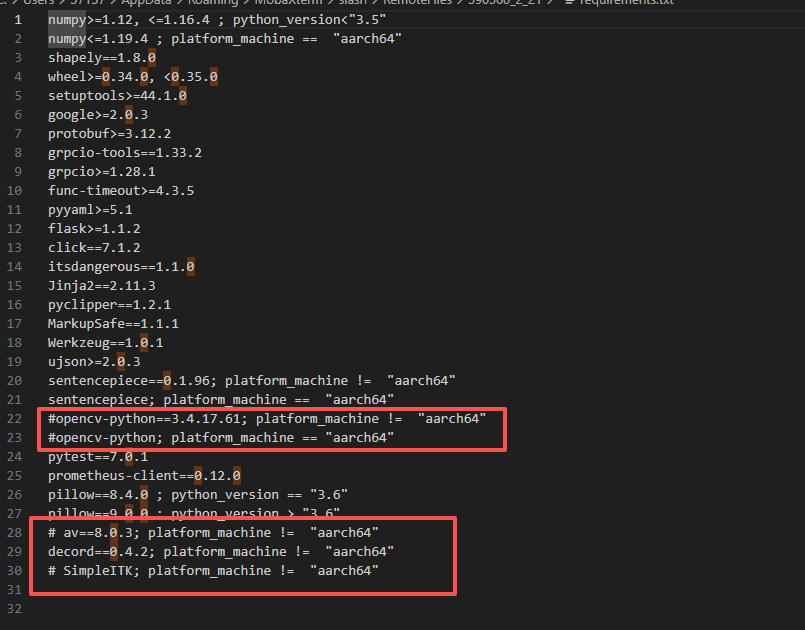
pip install -r python/requirements.txt如果安装 paddle_serving*失败不要着急,试着单个安装,甚至忽略依赖安装,使用以下命令:
shell
# 单个安装
pip install paddle_serving_server_gpu
pip install paddle_serving_client
pip install paddle_serving_app
# 忽略依赖安装
pip install paddle_serving_server_gpu --no-deps
pip install paddle_serving_client --no-deps
pip install paddle_serving_app --no-deps说明:忽略依赖安装后,启动服务时若提示缺失某依赖(如 numpy、flask 等),直接用 pip install 缺失包名 补装即可。若安装 requirements.txt 时失败,可打开文件注释掉报错的包名,先完成其他依赖安装,再单独处理问题包。
1.2 下载模型并解压
PaddleOCR 识别服务依赖检测模型(ocr_det,用于定位文字区域)和识别模型(ocr_rec,用于识别文字内容),需下载预训练模型并解压到指定目录。
shell
cd Serving/examples/C++/PaddleOCR/ocr/
python -m paddle_serving_app.package --get_model ocr_rec
tar -xzvf ocr_rec.tar.gz
python -m paddle_serving_app.package --get_model ocr_det
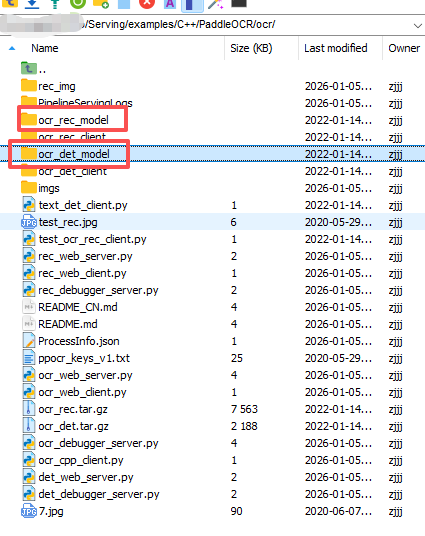
tar -xzvf ocr_det.tar.gz模型下载解压完成后,当前目录下会生成 ocr_rec_model 和 ocr_det_model 两个文件夹,分别存储识别模型和检测模型的配置文件与权重,目录结构如下:
2 启动并测试 OCR 服务
完成环境与模型准备后,即可启动服务端,并通过客户端测试服务可用性
2.1 启动服务端
根据硬件环境选择 CPU 或 GPU 方式启动服务,启动成功后会监听 9292 端口(默认端口,可在代码中修改)。
shell
# gpu启动服务
python ocr_debugger_server.py gpu
# cpu启动服务
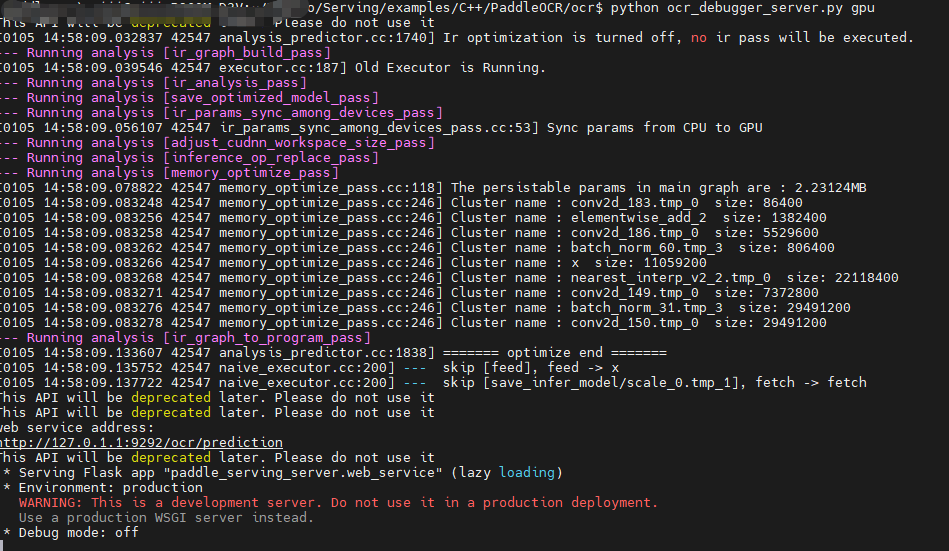
python ocr_debugger_server.py cpu服务启动成功后,终端会输出类似如下信息,提示服务已在 9292 端口运行:
2.2 客户端调用
保持服务端运行,打开新的终端窗口,执行客户端脚本调用 OCR 服务,验证识别功能是否正常。
shell
python ocr_web_client.py客户端调用成功后,会输出识别结果(文字内容及置信度),示意图如下:

3 注册系统服务(实现开机自启)
为避免每次服务器重启后手动启动 OCR 服务,可将其注册为 Linux 系统服务,实现开机自启、异常自动重启等功能。
3.1 编写服务配置文件
创建 ocr.service 配置文件,指定服务描述、运行目录、启动命令等关键信息。注意将配置中的路径替换为实际环境路径
txt
[Unit]
Description=paddle_ocr_srv (Remote access)
After=network-online.target
[Service]
Type=simple
WorkingDirectory=/xxx/Serving/examples/C++/PaddleOCR/ocr/
ExecStart=/xxx/anaconda3/envs/paddleocr/bin/python /xxx/Serving/examples/C++/PaddleOCR/ocr/ocr_debugger_server.py gpu
ExecStop=/bin/kill -TERM $MAINPID
ExecReload=/bin/kill -HUP $MAINPID
KillMode=control-group
Restart=on-failure
[Install]
WantedBy=graphical.target配置说明:
- WorkingDirectory: 需填写 OCR 服务示例的实际目录(即 ocr_debugger_server.py 所在目录);
- ExecStart: 需填写 Conda 虚拟环境中 Python 解释器的实际路径(可通过 which python 命令在激活环境后查看);
- 若服务器为纯命令行模式(无图形化桌面),需将 WantedBy=graphical.target 改为 WantedBy=multi-user.target。
3.2 注册并管理系统服务
将编写好的配置文件移动到系统服务目录,执行相关命令完成注册、启动与自启设置。
shell
sudo vim /etc/systemd/system/ocr.service
# 重新配置服务
sudo systemctl daemon-reload
# 开机自启动
sudo systemctl enable ocr
# 开启服务
sudo systemctl start ocr
# 查看服务状态
sudo systemctl status ocr若服务状态显示 active (running),说明系统服务注册并启动成功;若失败,可通过 journalctl -u ocr.service 命令查看详细日志排查问题。
4 遇到报错
-
CMake Error: CMake was unable to find a build program corresponding to "Ninja".shellsudo apt update && sudo apt install -y build-essential ninja-build -
PaddleCheckError: Expected id < GetCUDADeviceCount(), but received id:0 >= GetCUDADeviceCount():0一般原因是找不到驱动文件。请检查环境设置,需要在 LD_LIBRARY_PATH 中加入 /usr/lib64(驱动程序libcuda.so所在的实际路径)。
-
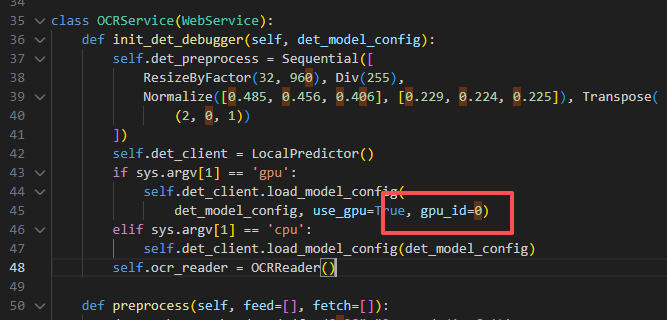
failed to create predictor: Log_id: 0 Raise_msg: (InvalidArgument) Device id must be less than GPU count, but received id is: 1. GPU count is: 1. [Hint: Expected id < GetGPUDeviceCount(), but received id:1 >= GetGPUDeviceCount():1.] (at /paddle/paddle/phi/backends/gpu/cuda/cuda_info.cc:255) ClassName: LocalPredictor.load_model_config.<locals>.create_predictor_check FunctionName: create_predictor_check将
gpu_id修改成你的GPU_ID,如果只有一张卡,设置成0.
总结
本文完整梳理了 Linux 环境下 PaddleOCR 识别服务器的部署流程,核心分为环境搭建、模型准备、服务启动、系统注册四大环节。通过 Conda 创建独立虚拟环境可有效规避依赖冲突,根据硬件选择 CPU/GPU 依赖包并补充缺失依赖,下载解压预训练模型后即可快速启动服务;将服务注册为系统服务能实现开机自启与异常重启,提升服务稳定性。针对部署中常见的 CMake 工具缺失、GPU 配置错误、CUDNN 库缺失等问题,提供了精准的解决方案。遵循本教程可快速完成从环境准备到服务上线的全流程落地,满足实时接口调用、批量文字识别等业务需求,为工业级 OCR 应用提供稳定的服务器部署方案。