概述
- 数据加载 - 加载并探索数据集
- 数据预处理 - 调整大小、进行增强以及划分数据
- 模型训练 - 训练迁移学习模型
- 模型评估 - 在测试集上进行全面评估
主要特点
- ✅ 专为 T4x2 GPU 进行优化
- ✅ 一个笔记本即可完成整个流程
- ✅ 使用 ResNet50/EfficientNetB0/MobileNetV2 进行迁移学习
- ✅ 自动对二分类数据进行目录重组
- ✅ 全面的评估指标
- ✅ 可用于发表的可视化图表
预期成果
- 目标准确率:>85%
- 训练时间:在 T4x2 GPU 上约需 15 至 20 分钟
- 最佳模型:ResNet50(预期)
python
# Check GPU availability
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
print("GPU Available:", tf.config.list_physical_devices('GPU'))
print("GPU Name:", tf.test.gpu_device_name() if tf.test.is_gpu_available() else "No GPU")
# Enable mixed precision for faster training on GPU (optional)
# Note: This may cause issues when loading H5 files, but .keras format handles it well
USE_MIXED_PRECISION = True # Set to False if you encounter loading issues
if USE_MIXED_PRECISION and tf.config.list_physical_devices('GPU'):
try:
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)
print("✓ Mixed precision enabled for GPU acceleration")
print(" Note: Models will be saved in .keras format to avoid loading issues")
except Exception as e:
print(f"⚠ Could not enable mixed precision: {e}")
USE_MIXED_PRECISION = False
else:
print("ℹ Mixed precision disabled (CPU mode or disabled)")
USE_MIXED_PRECISION = False2026-01-05 17:40:27.555633: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:467] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1767634827.742566 24 cuda_dnn.cc:8579] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1767634827.796543 24 cuda_blas.cc:1407] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
W0000 00:00:1767634828.267074 24 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1767634828.267126 24 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1767634828.267129 24 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1767634828.267131 24 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
TensorFlow version: 2.19.0
GPU Available: [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'), PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU')]
WARNING:tensorflow:From /tmp/ipykernel_24/2532149210.py:5: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.config.list_physical_devices('GPU')` instead.
GPU Name: /device:GPU:0
✓ Mixed precision enabled for GPU acceleration
Note: Models will be saved in .keras format to avoid loading issues
I0000 00:00:1767634841.719775 24 gpu_device.cc:2019] Created device /device:GPU:0 with 13942 MB memory: -> device: 0, name: Tesla T4, pci bus id: 0000:00:04.0, compute capability: 7.5
I0000 00:00:1767634841.723664 24 gpu_device.cc:2019] Created device /device:GPU:1 with 13942 MB memory: -> device: 1, name: Tesla T4, pci bus id: 0000:00:05.0, compute capability: 7.5
I0000 00:00:1767634841.726050 24 gpu_device.cc:2019] Created device /device:GPU:0 with 13942 MB memory: -> device: 0, name: Tesla T4, pci bus id: 0000:00:04.0, compute capability: 7.5
I0000 00:00:1767634841.726269 24 gpu_device.cc:2019] Created device /device:GPU:1 with 13942 MB memory: -> device: 1, name: Tesla T4, pci bus id: 0000:00:05.0, compute capability: 7.5
python
# Import required libraries
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from PIL import Image
from pathlib import Path
import shutil
from sklearn.model_selection import train_test_split
from sklearn.metrics import (
classification_report, confusion_matrix, accuracy_score,
precision_score, recall_score, f1_score, roc_auc_score,
roc_curve, precision_recall_curve, average_precision_score
)
from sklearn.utils.class_weight import compute_class_weight
import warnings
from collections import Counter
from tqdm import tqdm
# TensorFlow/Keras
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models, optimizers
from tensorflow.keras.applications import ResNet50, EfficientNetB0, MobileNetV2
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau, CSVLogger
# Configure display settings
warnings.filterwarnings('ignore')
plt.style.use('seaborn-v0_8-darkgrid')
sns.set_palette("husl")
# Set random seeds for reproducibility
np.random.seed(42)
tf.random.set_seed(42)
print("✓ All libraries imported successfully!")
print(f"✓ NumPy: {np.__version__}")
print(f"✓ Pandas: {pd.__version__}")
print(f"✓ TensorFlow: {tf.__version__}")✓ All libraries imported successfully!
✓ NumPy: 2.0.2
✓ Pandas: 2.2.2
✓ TensorFlow: 2.19.0第 1 部分:数据加载与探索
加载数据集,并对其结构进行探索。
python
# Kaggle paths
KAGGLE_INPUT = Path("/fresh-vs-rotten-fruit-images")
KAGGLE_WORKING = Path("/working")
# Dataset path (adjust based on actual Kaggle structure)
DATASET_DIR = KAGGLE_INPUT / "Fruit Freshness Dataset" / "Fruit Freshness Dataset"
# Check if dataset exists
if not DATASET_DIR.exists():
# Try alternative paths
possible_paths = [
KAGGLE_INPUT / "Fruit Freshness Dataset",
KAGGLE_INPUT,
]
for path in possible_paths:
if path.exists():
# Find the actual dataset directory
for subdir in path.rglob("Apple"):
if subdir.is_dir() and (subdir.parent / "Banana").exists():
DATASET_DIR = subdir.parent
break
if DATASET_DIR.exists():
break
print(f"Dataset directory: {DATASET_DIR}")
print(f"Dataset exists: {DATASET_DIR.exists()}")
if DATASET_DIR.exists():
print(f"\nDataset structure:")
for item in sorted(DATASET_DIR.iterdir()):
if item.is_dir():
print(f" 📁 {item.name}/")
for subitem in sorted(item.iterdir()):
if subitem.is_dir():
count = len(list(subitem.glob("*.jpg"))) + len(list(subitem.glob("*.png"))) + len(list(subitem.glob("*.webp")))
print(f" 📁 {subitem.name}/ ({count} images)")
else:
print("⚠ Dataset directory not found. Please check the path.")
python
Dataset directory: /Fruit Freshness Dataset/Fruit Freshness Dataset
Dataset exists: True
Dataset structure:
📁 Apple/
📁 Fresh/ (123 images)
📁 Rotten/ (55 images)
📁 Banana/
📁 Fresh/ (19 images)
📁 Rotten/ (90 images)
📁 Strawberry/
📁 Fresh/ (215 images)
📁 Rotten/ (44 images)
python
# Collect dataset statistics
FRUIT_TYPES = ['Apple', 'Banana', 'Strawberry']
CLASSES = ['Fresh', 'Rotten']
dataset_stats = []
total_images = 0
for fruit in FRUIT_TYPES:
fruit_dir = DATASET_DIR / fruit
if fruit_dir.exists():
for class_name in CLASSES:
class_dir = fruit_dir / class_name
if class_dir.exists():
# Count all image formats
image_files = []
for ext in ['*.jpg', '*.jpeg', '*.png', '*.webp', '*.jfif']:
image_files.extend(list(class_dir.glob(ext)))
image_files.extend(list(class_dir.glob(ext.upper())))
count = len(image_files)
total_images += count
dataset_stats.append({
'fruit_type': fruit,
'class': class_name,
'count': count
})
df_stats = pd.DataFrame(dataset_stats)
print("Dataset Statistics:")
print("=" * 60)
print(df_stats.pivot(index='fruit_type', columns='class', values='count').fillna(0).astype(int))
print(f"\nTotal Images: {total_images}")
# Visualize distribution
fig, ax = plt.subplots(figsize=(10, 6))
pivot = df_stats.pivot(index='fruit_type', columns='class', values='count').fillna(0)
pivot.plot(kind='bar', ax=ax, color=['#2ecc71', '#e74c3c'], width=0.8)
ax.set_title('Dataset Distribution by Fruit Type and Class', fontsize=14, fontweight='bold')
ax.set_xlabel('Fruit Type', fontsize=12)
ax.set_ylabel('Number of Images', fontsize=12)
ax.legend(title='Class', title_fontsize=11)
ax.grid(axis='y', alpha=0.3)
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()Dataset Statistics:
============================================================
class Fresh Rotten
fruit_type
Apple 124 55
Banana 33 90
Strawberry 220 44
Total Images: 566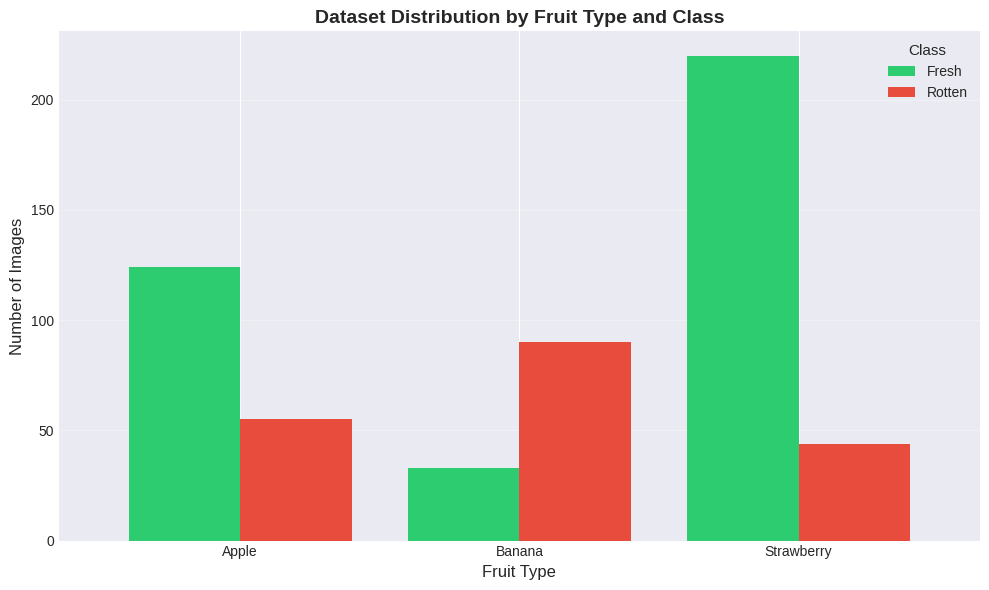
第二部分:数据预处理
预处理图像:调整大小、转换格式,并进行分类准备。
python
# Configuration
TARGET_SIZE = (224, 224)
TARGET_FORMAT = 'JPEG'
QUALITY = 95
TRAIN_RATIO = 0.7
VAL_RATIO = 0.15
TEST_RATIO = 0.15
# Create working directories
PROCESSED_DIR = KAGGLE_WORKING / "processed_data"
PROCESSED_DIR.mkdir(exist_ok=True, parents=True)
def preprocess_image(input_path, output_path, target_size=TARGET_SIZE):
"""Preprocess a single image: resize and convert format"""
try:
with Image.open(input_path) as img:
if img.mode != 'RGB':
img = img.convert('RGB')
img_resized = img.resize(target_size, Image.Resampling.LANCZOS)
output_path.parent.mkdir(parents=True, exist_ok=True)
img_resized.save(output_path, format=TARGET_FORMAT, quality=QUALITY, optimize=True)
return True
except Exception as e:
print(f"Error processing {input_path}: {e}")
return False
print("✓ Preprocessing function defined")✓ Preprocessing function defined
python
# Preprocess all images and organize by class (not fruit type) for binary classification
PROCESSED_RAW_DIR = PROCESSED_DIR / "raw_processed"
print("Preprocessing images... This may take a few minutes...")
processed_count = 0
failed_count = 0
for fruit in FRUIT_TYPES:
fruit_dir = DATASET_DIR / fruit
if fruit_dir.exists():
for class_name in CLASSES:
class_dir = fruit_dir / class_name
if class_dir.exists():
# Get all image files
image_files = []
for ext in ['*.jpg', '*.jpeg', '*.png', '*.webp', '*.jfif']:
image_files.extend(list(class_dir.glob(ext)))
image_files.extend(list(class_dir.glob(ext.upper())))
# Process each image
for img_path in tqdm(image_files, desc=f"{fruit}-{class_name}", leave=False):
output_dir = PROCESSED_RAW_DIR / class_name # Organize by class, not fruit
output_path = output_dir / f"{fruit}_{img_path.stem}.jpg"
if preprocess_image(img_path, output_path):
processed_count += 1
else:
failed_count += 1
print(f"\n✓ Preprocessing complete!")
print(f" Successfully processed: {processed_count} images")
print(f" Failed: {failed_count} images")Preprocessing images... This may take a few minutes...
✓ Preprocessing complete!
Successfully processed: 566 images
Failed: 0 images
python
# Create train/validation/test splits
FINAL_DATASET_DIR = PROCESSED_DIR / "final_dataset"
# Collect all processed images
all_images = []
for class_name in CLASSES:
class_dir = PROCESSED_RAW_DIR / class_name
if class_dir.exists():
for img_path in class_dir.glob("*.jpg"):
all_images.append({
'class': class_name,
'path': str(img_path),
'filename': img_path.name
})
df_all = pd.DataFrame(all_images)
# Create stratified splits
train_images = []
val_images = []
test_images = []
for class_name in CLASSES:
subset = df_all[df_all['class'] == class_name]
if len(subset) == 0:
continue
# First split: train vs temp (val + test)
train, temp = train_test_split(
subset,
test_size=(VAL_RATIO + TEST_RATIO),
random_state=42,
shuffle=True
)
# Second split: val vs test
val, test = train_test_split(
temp,
test_size=(TEST_RATIO / (VAL_RATIO + TEST_RATIO)),
random_state=42,
shuffle=True
)
train_images.append(train)
val_images.append(val)
test_images.append(test)
df_train = pd.concat(train_images, ignore_index=True)
df_val = pd.concat(val_images, ignore_index=True)
df_test = pd.concat(test_images, ignore_index=True)
print("Split Statistics:")
print("=" * 60)
print(f"Train: {len(df_train)} images ({len(df_train)/len(df_all)*100:.1f}%)")
print(f"Validation: {len(df_val)} images ({len(df_val)/len(df_all)*100:.1f}%)")
print(f"Test: {len(df_test)} images ({len(df_test)/len(df_all)*100:.1f}%)")
print("\nTrain distribution:")
print(df_train['class'].value_counts())
print("\nValidation distribution:")
print(df_val['class'].value_counts())
print("\nTest distribution:")
print(df_test['class'].value_counts())Split Statistics:
============================================================
Train: 363 images (69.8%)
Validation: 78 images (15.0%)
Test: 79 images (15.2%)
Train distribution:
class
Fresh 233
Rotten 130
Name: count, dtype: int64
Validation distribution:
class
Fresh 50
Rotten 28
Name: count, dtype: int64
Test distribution:
class
Fresh 51
Rotten 28
Name: count, dtype: int64
python
# Organize final dataset structure
def organize_split(df_split, split_name):
"""Organize images into train/val/test directories"""
split_dir = FINAL_DATASET_DIR / split_name
for idx, row in tqdm(df_split.iterrows(), total=len(df_split), desc=f"Organizing {split_name}"):
class_name = row['class']
source_path = Path(row['path'])
dest_dir = split_dir / class_name
dest_dir.mkdir(parents=True, exist_ok=True)
dest_path = dest_dir / source_path.name
shutil.copy2(source_path, dest_path)
return split_dir
train_dir = organize_split(df_train, 'train')
val_dir = organize_split(df_val, 'validation')
test_dir = organize_split(df_test, 'test')
print(f"\n✓ Final dataset organized!")
print(f" Train: {train_dir}")
print(f" Validation: {val_dir}")
print(f" Test: {test_dir}")
python
Organizing train: 100%|██████████| 363/363 [00:00<00:00, 3481.80it/s]
Organizing validation: 100%|██████████| 78/78 [00:00<00:00, 3424.14it/s]
Organizing test: 100%|██████████| 79/79 [00:00<00:00, 3347.04it/s]
✓ Final dataset organized!
Train: /final_dataset/train
Validation: /final_dataset/validation
Test: /final_dataset/test第三部分:模型训练
构建并训练针对 GPU 进行优化的迁移学习模型。
python
# Training configuration
IMG_SIZE = (224, 224)
BATCH_SIZE = 32 # Can increase to 64 or 128 for T4x2 GPU
EPOCHS = 30
NUM_CLASSES = 2
CLASS_NAMES = ['Fresh', 'Rotten']
# Calculate class weights
train_labels = []
for class_name in CLASSES:
count = len(df_train[df_train['class'] == class_name])
train_labels.extend([0 if class_name == 'Fresh' else 1] * count)
train_labels = np.array(train_labels)
class_weights = compute_class_weight('balanced', classes=np.unique(train_labels), y=train_labels)
class_weight_dict = {i: weight for i, weight in enumerate(class_weights)}
print(f"Class weights: {class_weight_dict}")
print(f"Batch size: {BATCH_SIZE}")
print(f"Epochs: {EPOCHS}")Class weights: {0: np.float64(0.778969957081545), 1: np.float64(1.396153846153846)}
Batch size: 32
Epochs: 30
python
# Create data generators
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest',
brightness_range=[0.9, 1.1]
)
val_test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
str(train_dir),
target_size=IMG_SIZE,
batch_size=BATCH_SIZE,
class_mode='binary',
shuffle=True,
seed=42
)
val_generator = val_test_datagen.flow_from_directory(
str(val_dir),
target_size=IMG_SIZE,
batch_size=BATCH_SIZE,
class_mode='binary',
shuffle=False,
seed=42
)
test_generator = val_test_datagen.flow_from_directory(
str(test_dir),
target_size=IMG_SIZE,
batch_size=BATCH_SIZE,
class_mode='binary',
shuffle=False,
seed=42
)
print("✓ Data generators created")
print(f"Train samples: {train_generator.samples}")
print(f"Validation samples: {val_generator.samples}")
print(f"Test samples: {test_generator.samples}")
print(f"Class indices: {train_generator.class_indices}")Found 363 images belonging to 2 classes.
Found 78 images belonging to 2 classes.
Found 79 images belonging to 2 classes.
✓ Data generators created
Train samples: 363
Validation samples: 78
Test samples: 79
Class indices: {'Fresh': 0, 'Rotten': 1}
python
def build_improved_model(base_model_name='resnet50', input_shape=(224, 224, 3)):
"""Build improved model with BatchNormalization"""
# Select base model
if base_model_name.lower() == 'resnet50':
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=input_shape)
elif base_model_name.lower() == 'efficientnetb0':
base_model = EfficientNetB0(weights='imagenet', include_top=False, input_shape=input_shape)
elif base_model_name.lower() == 'mobilenetv2':
base_model = MobileNetV2(weights='imagenet', include_top=False, input_shape=input_shape)
else:
raise ValueError(f"Unknown base model: {base_model_name}")
base_model.trainable = False
# Build model
inputs = keras.Input(shape=input_shape)
x = base_model(inputs, training=False)
x = layers.GlobalAveragePooling2D()(x)
x = layers.BatchNormalization()(x)
x = layers.Dense(512, activation='relu')(x)
x = layers.Dropout(0.5)(x)
x = layers.BatchNormalization()(x)
x = layers.Dense(256, activation='relu')(x)
x = layers.Dropout(0.3)(x)
outputs = layers.Dense(1, activation='sigmoid', dtype='float32')(x) # Explicit dtype for mixed precision
model = keras.Model(inputs, outputs)
return model
# Test model creation
test_model = build_improved_model('resnet50')
print("✓ Model building function defined")
print(f"Total parameters: {test_model.count_params():,}")
python
I0000 00:00:1767634855.294219 24 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 13942 MB memory: -> device: 0, name: Tesla T4, pci bus id: 0000:00:04.0, compute capability: 7.5
I0000 00:00:1767634855.294435 24 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:1 with 13942 MB memory: -> device: 1, name: Tesla T4, pci bus id: 0000:00:05.0, compute capability: 7.5
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/resnet/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5
[1m94765736/94765736[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 0us/step
✓ Model building function defined
Total parameters: 24,778,625
python
# Build and compile model
MODELS_DIR = KAGGLE_WORKING / "models"
MODELS_DIR.mkdir(exist_ok=True)
model = build_improved_model('resnet50', input_shape=(224, 224, 3))
# Compile with mixed precision support
model.compile(
optimizer=optimizers.Adam(learning_rate=0.0001),
loss='binary_crossentropy',
metrics=['accuracy', 'precision', 'recall', 'AUC']
)
print("✓ Model compiled")
model.summary()✓ Model compiled
Model: "functional_1"
python
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ input_layer_3 (InputLayer) │ (None, 224, 224, 3) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ resnet50 (Functional) │ (None, 7, 7, 2048) │ 23,587,712 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ global_average_pooling2d_1 │ (None, 2048) │ 0 │
│ (GlobalAveragePooling2D) │ │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ batch_normalization_2 │ (None, 2048) │ 8,192 │
│ (BatchNormalization) │ │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_3 (Dense) │ (None, 512) │ 1,049,088 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout_2 (Dropout) │ (None, 512) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ batch_normalization_3 │ (None, 512) │ 2,048 │
│ (BatchNormalization) │ │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_4 (Dense) │ (None, 256) │ 131,328 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout_3 (Dropout) │ (None, 256) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_5 (Dense) │ (None, 1) │ 257 │
└─────────────────────────────────┴────────────────────────┴───────────────┘Total params: 24,778,625 (94.52 MB)
Trainable params: 1,185,793 (4.52 MB)
Non-trainable params: 23,592,832 (90.00 MB)
python
# Create callbacks
RESULTS_DIR = KAGGLE_WORKING / "results"
RESULTS_DIR.mkdir(exist_ok=True)
callbacks = [
ModelCheckpoint(
filepath=str(MODELS_DIR / "resnet50_best.keras"), # Use .keras format
monitor='val_accuracy',
save_best_only=True,
mode='max',
verbose=1,
save_weights_only=False
),
# Also save weights separately for easier loading
ModelCheckpoint(
filepath=str(MODELS_DIR / "resnet50_best.weights.h5"), # Must end with .weights.h5
monitor='val_accuracy',
save_best_only=True,
mode='max',
verbose=0,
save_weights_only=True
),
EarlyStopping(
monitor='val_loss',
patience=8,
restore_best_weights=True,
verbose=1
),
ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=4,
min_lr=1e-7,
verbose=1
),
CSVLogger(
filename=str(RESULTS_DIR / "training_log.csv"),
append=False
)
]
print("✓ Callbacks created")✓ Callbacks created
python
# Train the model
print("Starting training on GPU...")
print("=" * 60)
history = model.fit(
train_generator,
epochs=EPOCHS,
validation_data=val_generator,
callbacks=callbacks,
class_weight=class_weight_dict,
verbose=1
)
# Save final model - use .keras format to avoid mixed precision issues
model.save(str(MODELS_DIR / "resnet50_final.keras"))
model.save_weights(str(MODELS_DIR / "resnet50_final.weights.h5")) # Use .weights.h5 format
# Also try to save H5 format (may have issues with mixed precision)
try:
model.save(str(MODELS_DIR / "resnet50_final.h5"))
except Exception as e:
print(f"Note: Could not save H5 format (mixed precision): {e}")
print(f"\n✓ Training complete!")
print(f"✓ Model saved: resnet50_final.keras")
print(f"✓ Weights saved: resnet50_final.weights.h5")Starting training on GPU...
============================================================
Epoch 1/30
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1767634869.647135 91 service.cc:152] XLA service 0x7d2f70003510 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
I0000 00:00:1767634869.647168 91 service.cc:160] StreamExecutor device (0): Tesla T4, Compute Capability 7.5
I0000 00:00:1767634869.647173 91 service.cc:160] StreamExecutor device (1): Tesla T4, Compute Capability 7.5
I0000 00:00:1767634871.846854 91 cuda_dnn.cc:529] Loaded cuDNN version 91002
[1m 1/12[0m [32m━[0m[37m━━━━━━━━━━━━━━━━━━━[0m [1m3:30[0m 19s/step - AUC: 0.3831 - accuracy: 0.4062 - loss: 1.0232 - precision: 0.0000e+00 - recall: 0.0000e+00
I0000 00:00:1767634879.469078 91 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 1s/step - AUC: 0.5670 - accuracy: 0.5961 - loss: 0.8054 - precision: 0.3335 - recall: 0.2570
Epoch 1: val_accuracy improved from -inf to 0.35897, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m42s[0m 2s/step - AUC: 0.5700 - accuracy: 0.5998 - loss: 0.8060 - precision: 0.3467 - recall: 0.2657 - val_AUC: 0.5661 - val_accuracy: 0.3590 - val_loss: 0.7711 - val_precision: 0.3590 - val_recall: 1.0000 - learning_rate: 1.0000e-04
Epoch 2/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 357ms/step - AUC: 0.6234 - accuracy: 0.6512 - loss: 0.7207 - precision: 0.4686 - recall: 0.4281
Epoch 2: val_accuracy did not improve from 0.35897
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 376ms/step - AUC: 0.6273 - accuracy: 0.6511 - loss: 0.7189 - precision: 0.4720 - recall: 0.4337 - val_AUC: 0.6479 - val_accuracy: 0.3590 - val_loss: 0.7904 - val_precision: 0.3590 - val_recall: 1.0000 - learning_rate: 1.0000e-04
Epoch 3/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 362ms/step - AUC: 0.7408 - accuracy: 0.7109 - loss: 0.6306 - precision: 0.6307 - recall: 0.5852
Epoch 3: val_accuracy did not improve from 0.35897
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 381ms/step - AUC: 0.7413 - accuracy: 0.7111 - loss: 0.6293 - precision: 0.6283 - recall: 0.5870 - val_AUC: 0.7075 - val_accuracy: 0.3590 - val_loss: 0.8160 - val_precision: 0.3590 - val_recall: 1.0000 - learning_rate: 1.0000e-04
Epoch 4/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 364ms/step - AUC: 0.8337 - accuracy: 0.7178 - loss: 0.4927 - precision: 0.5442 - recall: 0.8111
Epoch 4: val_accuracy did not improve from 0.35897
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 385ms/step - AUC: 0.8320 - accuracy: 0.7188 - loss: 0.4960 - precision: 0.5479 - recall: 0.8091 - val_AUC: 0.7368 - val_accuracy: 0.3590 - val_loss: 0.8142 - val_precision: 0.3590 - val_recall: 1.0000 - learning_rate: 1.0000e-04
Epoch 5/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 355ms/step - AUC: 0.8394 - accuracy: 0.7406 - loss: 0.5004 - precision: 0.6502 - recall: 0.7476
Epoch 5: val_accuracy did not improve from 0.35897
Epoch 5: ReduceLROnPlateau reducing learning rate to 4.999999873689376e-05.
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 372ms/step - AUC: 0.8386 - accuracy: 0.7406 - loss: 0.5009 - precision: 0.6470 - recall: 0.7492 - val_AUC: 0.7693 - val_accuracy: 0.3590 - val_loss: 0.8307 - val_precision: 0.3590 - val_recall: 1.0000 - learning_rate: 1.0000e-04
Epoch 6/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 347ms/step - AUC: 0.7845 - accuracy: 0.7126 - loss: 0.5654 - precision: 0.5793 - recall: 0.6821
Epoch 6: val_accuracy did not improve from 0.35897
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m4s[0m 365ms/step - AUC: 0.7864 - accuracy: 0.7139 - loss: 0.5625 - precision: 0.5811 - recall: 0.6852 - val_AUC: 0.7782 - val_accuracy: 0.3590 - val_loss: 0.8119 - val_precision: 0.3590 - val_recall: 1.0000 - learning_rate: 5.0000e-05
Epoch 7/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 355ms/step - AUC: 0.7979 - accuracy: 0.7157 - loss: 0.5475 - precision: 0.5666 - recall: 0.7471
Epoch 7: val_accuracy did not improve from 0.35897
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 372ms/step - AUC: 0.7997 - accuracy: 0.7179 - loss: 0.5457 - precision: 0.5705 - recall: 0.7470 - val_AUC: 0.8007 - val_accuracy: 0.3590 - val_loss: 0.7924 - val_precision: 0.3590 - val_recall: 1.0000 - learning_rate: 5.0000e-05
Epoch 8/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 374ms/step - AUC: 0.8162 - accuracy: 0.7509 - loss: 0.5299 - precision: 0.6031 - recall: 0.7809
Epoch 8: val_accuracy did not improve from 0.35897
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m4s[0m 391ms/step - AUC: 0.8187 - accuracy: 0.7527 - loss: 0.5264 - precision: 0.6070 - recall: 0.7812 - val_AUC: 0.8100 - val_accuracy: 0.3590 - val_loss: 0.7838 - val_precision: 0.3590 - val_recall: 1.0000 - learning_rate: 5.0000e-05
Epoch 9/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 352ms/step - AUC: 0.8355 - accuracy: 0.7360 - loss: 0.5013 - precision: 0.5926 - recall: 0.7770
Epoch 9: val_accuracy did not improve from 0.35897
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 383ms/step - AUC: 0.8352 - accuracy: 0.7374 - loss: 0.5015 - precision: 0.5954 - recall: 0.7764 - val_AUC: 0.8257 - val_accuracy: 0.3590 - val_loss: 0.7669 - val_precision: 0.3590 - val_recall: 1.0000 - learning_rate: 5.0000e-05
Epoch 10/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 351ms/step - AUC: 0.8351 - accuracy: 0.7424 - loss: 0.4925 - precision: 0.5983 - recall: 0.7334
Epoch 10: val_accuracy improved from 0.35897 to 0.41026, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 519ms/step - AUC: 0.8357 - accuracy: 0.7432 - loss: 0.4924 - precision: 0.6004 - recall: 0.7356 - val_AUC: 0.8311 - val_accuracy: 0.4103 - val_loss: 0.7439 - val_precision: 0.3784 - val_recall: 1.0000 - learning_rate: 5.0000e-05
Epoch 11/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 359ms/step - AUC: 0.9065 - accuracy: 0.8370 - loss: 0.3933 - precision: 0.7244 - recall: 0.8605
Epoch 11: val_accuracy improved from 0.41026 to 0.42308, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 528ms/step - AUC: 0.9041 - accuracy: 0.8336 - loss: 0.3969 - precision: 0.7208 - recall: 0.8564 - val_AUC: 0.8396 - val_accuracy: 0.4231 - val_loss: 0.7277 - val_precision: 0.3836 - val_recall: 1.0000 - learning_rate: 5.0000e-05
Epoch 12/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 349ms/step - AUC: 0.8052 - accuracy: 0.7494 - loss: 0.5510 - precision: 0.5942 - recall: 0.7580
Epoch 12: val_accuracy improved from 0.42308 to 0.43590, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 526ms/step - AUC: 0.8058 - accuracy: 0.7494 - loss: 0.5507 - precision: 0.5966 - recall: 0.7571 - val_AUC: 0.8479 - val_accuracy: 0.4359 - val_loss: 0.7158 - val_precision: 0.3889 - val_recall: 1.0000 - learning_rate: 5.0000e-05
Epoch 13/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 362ms/step - AUC: 0.8020 - accuracy: 0.7088 - loss: 0.5568 - precision: 0.5609 - recall: 0.6952
Epoch 13: val_accuracy improved from 0.43590 to 0.46154, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 533ms/step - AUC: 0.8041 - accuracy: 0.7104 - loss: 0.5540 - precision: 0.5641 - recall: 0.6974 - val_AUC: 0.8546 - val_accuracy: 0.4615 - val_loss: 0.7025 - val_precision: 0.4000 - val_recall: 1.0000 - learning_rate: 5.0000e-05
Epoch 14/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 375ms/step - AUC: 0.8419 - accuracy: 0.7476 - loss: 0.4961 - precision: 0.6087 - recall: 0.7650
Epoch 14: val_accuracy improved from 0.46154 to 0.50000, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 545ms/step - AUC: 0.8429 - accuracy: 0.7492 - loss: 0.4944 - precision: 0.6113 - recall: 0.7677 - val_AUC: 0.8586 - val_accuracy: 0.5000 - val_loss: 0.6850 - val_precision: 0.4179 - val_recall: 1.0000 - learning_rate: 5.0000e-05
Epoch 15/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 375ms/step - AUC: 0.8701 - accuracy: 0.7447 - loss: 0.4672 - precision: 0.6390 - recall: 0.7294
Epoch 15: val_accuracy improved from 0.50000 to 0.51282, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 547ms/step - AUC: 0.8702 - accuracy: 0.7467 - loss: 0.4657 - precision: 0.6395 - recall: 0.7348 - val_AUC: 0.8625 - val_accuracy: 0.5128 - val_loss: 0.6627 - val_precision: 0.4219 - val_recall: 0.9643 - learning_rate: 5.0000e-05
Epoch 16/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 354ms/step - AUC: 0.8272 - accuracy: 0.7433 - loss: 0.5232 - precision: 0.6310 - recall: 0.7490
Epoch 16: val_accuracy improved from 0.51282 to 0.55128, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 530ms/step - AUC: 0.8256 - accuracy: 0.7401 - loss: 0.5253 - precision: 0.6263 - recall: 0.7446 - val_AUC: 0.8718 - val_accuracy: 0.5513 - val_loss: 0.6417 - val_precision: 0.4426 - val_recall: 0.9643 - learning_rate: 5.0000e-05
Epoch 17/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 356ms/step - AUC: 0.9024 - accuracy: 0.8197 - loss: 0.4048 - precision: 0.6874 - recall: 0.8708
Epoch 17: val_accuracy improved from 0.55128 to 0.57692, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 528ms/step - AUC: 0.9018 - accuracy: 0.8192 - loss: 0.4053 - precision: 0.6882 - recall: 0.8683 - val_AUC: 0.8821 - val_accuracy: 0.5769 - val_loss: 0.6216 - val_precision: 0.4576 - val_recall: 0.9643 - learning_rate: 5.0000e-05
Epoch 18/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 357ms/step - AUC: 0.8758 - accuracy: 0.7936 - loss: 0.4483 - precision: 0.7066 - recall: 0.7993
Epoch 18: val_accuracy improved from 0.57692 to 0.62821, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 528ms/step - AUC: 0.8758 - accuracy: 0.7938 - loss: 0.4476 - precision: 0.7047 - recall: 0.7999 - val_AUC: 0.8879 - val_accuracy: 0.6282 - val_loss: 0.6035 - val_precision: 0.4909 - val_recall: 0.9643 - learning_rate: 5.0000e-05
Epoch 19/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 369ms/step - AUC: 0.8273 - accuracy: 0.7047 - loss: 0.5107 - precision: 0.5356 - recall: 0.7350
Epoch 19: val_accuracy improved from 0.62821 to 0.76923, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 538ms/step - AUC: 0.8283 - accuracy: 0.7084 - loss: 0.5100 - precision: 0.5424 - recall: 0.7377 - val_AUC: 0.8918 - val_accuracy: 0.7692 - val_loss: 0.5812 - val_precision: 0.6136 - val_recall: 0.9643 - learning_rate: 5.0000e-05
Epoch 20/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 345ms/step - AUC: 0.9242 - accuracy: 0.8249 - loss: 0.3701 - precision: 0.6465 - recall: 0.9029
Epoch 20: val_accuracy did not improve from 0.76923
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 373ms/step - AUC: 0.9214 - accuracy: 0.8231 - loss: 0.3739 - precision: 0.6497 - recall: 0.8962 - val_AUC: 0.8911 - val_accuracy: 0.7564 - val_loss: 0.5600 - val_precision: 0.6047 - val_recall: 0.9286 - learning_rate: 5.0000e-05
Epoch 21/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 350ms/step - AUC: 0.8926 - accuracy: 0.7715 - loss: 0.4119 - precision: 0.6335 - recall: 0.8026
Epoch 21: val_accuracy improved from 0.76923 to 0.83333, saving model to /kaggle/working/models/resnet50_best.keras
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m6s[0m 516ms/step - AUC: 0.8927 - accuracy: 0.7734 - loss: 0.4115 - precision: 0.6371 - recall: 0.8036 - val_AUC: 0.8975 - val_accuracy: 0.8333 - val_loss: 0.5419 - val_precision: 0.7027 - val_recall: 0.9286 - learning_rate: 5.0000e-05
Epoch 22/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 375ms/step - AUC: 0.8553 - accuracy: 0.7842 - loss: 0.5055 - precision: 0.6808 - recall: 0.8171
Epoch 22: val_accuracy did not improve from 0.83333
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 405ms/step - AUC: 0.8558 - accuracy: 0.7838 - loss: 0.5031 - precision: 0.6789 - recall: 0.8164 - val_AUC: 0.9032 - val_accuracy: 0.8205 - val_loss: 0.5240 - val_precision: 0.7059 - val_recall: 0.8571 - learning_rate: 5.0000e-05
Epoch 23/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 349ms/step - AUC: 0.8804 - accuracy: 0.8067 - loss: 0.4463 - precision: 0.6439 - recall: 0.8774
Epoch 23: val_accuracy did not improve from 0.83333
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 379ms/step - AUC: 0.8800 - accuracy: 0.8061 - loss: 0.4464 - precision: 0.6463 - recall: 0.8750 - val_AUC: 0.9064 - val_accuracy: 0.7949 - val_loss: 0.5069 - val_precision: 0.7000 - val_recall: 0.7500 - learning_rate: 5.0000e-05
Epoch 24/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 342ms/step - AUC: 0.8968 - accuracy: 0.8039 - loss: 0.4007 - precision: 0.6754 - recall: 0.8732
Epoch 24: val_accuracy did not improve from 0.83333
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m4s[0m 371ms/step - AUC: 0.8959 - accuracy: 0.8029 - loss: 0.4025 - precision: 0.6744 - recall: 0.8711 - val_AUC: 0.9096 - val_accuracy: 0.7821 - val_loss: 0.4917 - val_precision: 0.6897 - val_recall: 0.7143 - learning_rate: 5.0000e-05
Epoch 25/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 375ms/step - AUC: 0.8966 - accuracy: 0.7970 - loss: 0.4212 - precision: 0.6732 - recall: 0.8142
Epoch 25: val_accuracy did not improve from 0.83333
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 406ms/step - AUC: 0.8948 - accuracy: 0.7959 - loss: 0.4238 - precision: 0.6722 - recall: 0.8137 - val_AUC: 0.9136 - val_accuracy: 0.7821 - val_loss: 0.4770 - val_precision: 0.6897 - val_recall: 0.7143 - learning_rate: 5.0000e-05
Epoch 26/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 359ms/step - AUC: 0.8663 - accuracy: 0.7794 - loss: 0.4678 - precision: 0.6582 - recall: 0.7972
Epoch 26: val_accuracy did not improve from 0.83333
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 387ms/step - AUC: 0.8671 - accuracy: 0.7809 - loss: 0.4660 - precision: 0.6602 - recall: 0.7986 - val_AUC: 0.9157 - val_accuracy: 0.8205 - val_loss: 0.4608 - val_precision: 0.7500 - val_recall: 0.7500 - learning_rate: 5.0000e-05
Epoch 27/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 353ms/step - AUC: 0.8964 - accuracy: 0.8033 - loss: 0.4128 - precision: 0.6773 - recall: 0.8468
Epoch 27: val_accuracy did not improve from 0.83333
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 381ms/step - AUC: 0.8956 - accuracy: 0.8032 - loss: 0.4135 - precision: 0.6778 - recall: 0.8456 - val_AUC: 0.9275 - val_accuracy: 0.8333 - val_loss: 0.4451 - val_precision: 0.7586 - val_recall: 0.7857 - learning_rate: 5.0000e-05
Epoch 28/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 348ms/step - AUC: 0.9333 - accuracy: 0.8641 - loss: 0.3311 - precision: 0.7415 - recall: 0.9235
Epoch 28: val_accuracy did not improve from 0.83333
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 378ms/step - AUC: 0.9324 - accuracy: 0.8614 - loss: 0.3332 - precision: 0.7397 - recall: 0.9187 - val_AUC: 0.9300 - val_accuracy: 0.8205 - val_loss: 0.4305 - val_precision: 0.7500 - val_recall: 0.7500 - learning_rate: 5.0000e-05
Epoch 29/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 355ms/step - AUC: 0.8428 - accuracy: 0.7736 - loss: 0.5236 - precision: 0.6776 - recall: 0.7449
Epoch 29: val_accuracy did not improve from 0.83333
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 385ms/step - AUC: 0.8454 - accuracy: 0.7752 - loss: 0.5178 - precision: 0.6778 - recall: 0.7491 - val_AUC: 0.9329 - val_accuracy: 0.8205 - val_loss: 0.4176 - val_precision: 0.7500 - val_recall: 0.7500 - learning_rate: 5.0000e-05
Epoch 30/30
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 345ms/step - AUC: 0.8927 - accuracy: 0.8127 - loss: 0.4123 - precision: 0.7008 - recall: 0.8644
Epoch 30: val_accuracy did not improve from 0.83333
[1m12/12[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m5s[0m 374ms/step - AUC: 0.8923 - accuracy: 0.8119 - loss: 0.4127 - precision: 0.6991 - recall: 0.8630 - val_AUC: 0.9343 - val_accuracy: 0.8077 - val_loss: 0.4040 - val_precision: 0.7407 - val_recall: 0.7143 - learning_rate: 5.0000e-05
Restoring model weights from the end of the best epoch: 30.
WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`.
✓ Training complete!
✓ Model saved: resnet50_final.keras
✓ Weights saved: resnet50_final.weights.h5第四部分:模型评估
在测试集上使用全面的指标对训练好的模型进行评估。
python
# Load best model and evaluate
# Try multiple loading methods to handle mixed precision
best_model = None
# Method 1: Try loading .keras format (preferred)
if (MODELS_DIR / "resnet50_best.keras").exists():
try:
best_model = keras.models.load_model(MODELS_DIR / "resnet50_best.keras")
print("✓ Loaded model from .keras format")
except Exception as e:
print(f"Could not load .keras format: {e}")
# Method 2: Load weights and rebuild model
weights_file = MODELS_DIR / "resnet50_best.weights.h5"
if best_model is None and weights_file.exists():
try:
print("Rebuilding model from weights...")
best_model = build_improved_model('resnet50', input_shape=(224, 224, 3))
best_model.compile(
optimizer=optimizers.Adam(learning_rate=0.0001),
loss='binary_crossentropy',
metrics=['accuracy', 'precision', 'recall', 'AUC']
)
best_model.load_weights(weights_file)
print("✓ Loaded model from weights")
except Exception as e:
print(f"Could not load from weights: {e}")
# Method 3: Try H5 format with custom objects for mixed precision
if best_model is None and (MODELS_DIR / "resnet50_best.h5").exists():
try:
# Import Cast layer for mixed precision models
try:
from keras.src.layers.core.casting import Cast
except ImportError:
# Alternative import path
Cast = type('Cast', (), {})
best_model = keras.models.load_model(
MODELS_DIR / "resnet50_best.h5",
custom_objects={'Cast': Cast} if 'Cast' in dir() else {}
)
print("✓ Loaded model from H5 format")
except Exception as e:
print(f"Could not load H5 format (mixed precision issue): {e}")
print(" This is expected with mixed precision. Use .keras format or weights instead.")
# Method 4: Use final model
if best_model is None:
try:
if (MODELS_DIR / "resnet50_final.keras").exists():
best_model = keras.models.load_model(MODELS_DIR / "resnet50_final.keras")
elif (MODELS_DIR / "resnet50_final.h5").exists():
best_model = keras.models.load_model(MODELS_DIR / "resnet50_final.h5")
print("✓ Loaded final model")
except Exception as e:
print(f"Error loading model: {e}")
raise
if best_model is None:
raise ValueError("Could not load any model file. Please check training completed successfully.")
# Evaluate on test set
print("Evaluating on test set...")
test_results = best_model.evaluate(test_generator, verbose=1)
print(f"\nTest Set Results:")
print(f" Loss: {test_results[0]:.4f}")
print(f" Accuracy: {test_results[1]:.4f} ({test_results[1]*100:.2f}%)")
print(f" Precision: {test_results[2]:.4f} ({test_results[2]*100:.2f}%)")
print(f" Recall: {test_results[3]:.4f} ({test_results[3]*100:.2f}%)")
print(f" AUC: {test_results[4]:.4f}")✓ Loaded model from .keras format
Evaluating on test set...
[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 2s/step - AUC: 0.7247 - accuracy: 0.8625 - loss: 0.5267 - precision: 0.5227 - recall: 0.7321
Test Set Results:
Loss: 0.5137
Accuracy: 0.8734 (87.34%)
Precision: 0.7500 (75.00%)
Recall: 0.9643 (96.43%)
AUC: 0.9660
python
# Get predictions
test_generator.reset()
predictions = best_model.predict(test_generator, verbose=1)
y_pred_proba = predictions.flatten()
y_pred = (y_pred_proba > 0.5).astype(int)
y_true = test_generator.classes
# Calculate additional metrics
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred, zero_division=0)
recall = recall_score(y_true, y_pred, zero_division=0)
f1 = f1_score(y_true, y_pred, zero_division=0)
auc = roc_auc_score(y_true, y_pred_proba)
ap = average_precision_score(y_true, y_pred_proba)
print("\nComprehensive Metrics:")
print("=" * 60)
print(f"Accuracy: {accuracy:.4f} ({accuracy*100:.2f}%)")
print(f"Precision: {precision:.4f} ({precision*100:.2f}%)")
print(f"Recall: {recall:.4f} ({recall*100:.2f}%)")
print(f"F1-Score: {f1:.4f} ({f1*100:.2f}%)")
print(f"AUC-ROC: {auc:.4f}")
print(f"Avg Precision: {ap:.4f}")
print("=" * 60)[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m8s[0m 2s/step
Comprehensive Metrics:
============================================================
Accuracy: 0.8734 (87.34%)
Precision: 0.7500 (75.00%)
Recall: 0.9643 (96.43%)
F1-Score: 0.8438 (84.38%)
AUC-ROC: 0.9650
Avg Precision: 0.9318
============================================================
python
# Classification report
print("\nClassification Report:")
print("=" * 60)
print(classification_report(y_true, y_pred, target_names=CLASS_NAMES))
print("=" * 60)
# Confusion matrix
cm = confusion_matrix(y_true, y_pred)
print("\nConfusion Matrix:")
print(cm)Classification Report:
============================================================
precision recall f1-score support
Fresh 0.98 0.82 0.89 51
Rotten 0.75 0.96 0.84 28
accuracy 0.87 79
macro avg 0.86 0.89 0.87 79
weighted avg 0.90 0.87 0.88 79
============================================================
Confusion Matrix:
[[42 9]
[ 1 27]]
python
# Visualize results
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
# 1. Confusion Matrix
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', ax=axes[0],
xticklabels=CLASS_NAMES, yticklabels=CLASS_NAMES)
axes[0].set_title(f'Confusion Matrix\nAccuracy: {accuracy:.3f}', fontsize=12, fontweight='bold')
axes[0].set_ylabel('True Label', fontsize=10)
axes[0].set_xlabel('Predicted Label', fontsize=10)
# 2. ROC Curve
fpr, tpr, _ = roc_curve(y_true, y_pred_proba)
axes[1].plot(fpr, tpr, label=f'ROC (AUC = {auc:.3f})', linewidth=2)
axes[1].plot([0, 1], [0, 1], 'k--', label='Random', linewidth=1)
axes[1].set_xlabel('False Positive Rate', fontsize=10, fontweight='bold')
axes[1].set_ylabel('True Positive Rate', fontsize=10, fontweight='bold')
axes[1].set_title('ROC Curve', fontsize=12, fontweight='bold')
axes[1].legend()
axes[1].grid(alpha=0.3)
# 3. Precision-Recall Curve
precision_curve, recall_curve, _ = precision_recall_curve(y_true, y_pred_proba)
axes[2].plot(recall_curve, precision_curve, label=f'PR (AP = {ap:.3f})', linewidth=2)
axes[2].set_xlabel('Recall', fontsize=10, fontweight='bold')
axes[2].set_ylabel('Precision', fontsize=10, fontweight='bold')
axes[2].set_title('Precision-Recall Curve', fontsize=12, fontweight='bold')
axes[2].legend()
axes[2].grid(alpha=0.3)
plt.tight_layout()
plt.savefig(RESULTS_DIR / 'evaluation_results.png', dpi=300, bbox_inches='tight')
plt.show()
print(f"✓ Evaluation visualizations saved")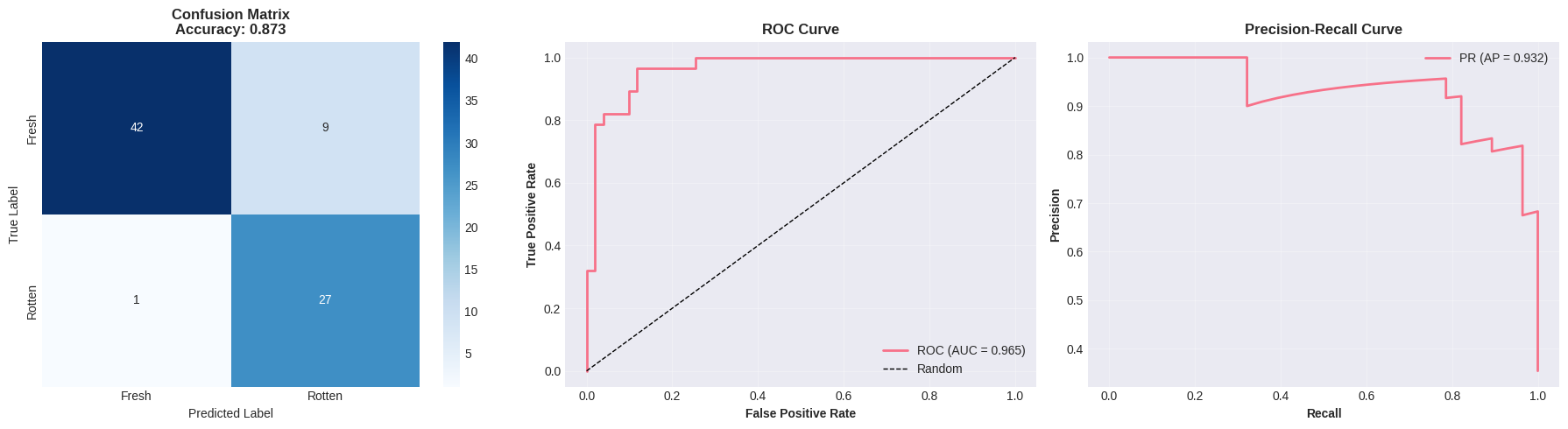
✓ Evaluation visualizations saved
python
# Plot training history
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
metrics = ['accuracy', 'loss', 'precision', 'recall']
for idx, metric in enumerate(metrics):
ax = axes[idx // 2, idx % 2]
ax.plot(history.history[metric], label=f'Train {metric}', linestyle='-', linewidth=2)
if f'val_{metric}' in history.history:
ax.plot(history.history[f'val_{metric}'], label=f'Val {metric}', linestyle='--', linewidth=2)
ax.set_title(f'{metric.capitalize()}', fontsize=12, fontweight='bold')
ax.set_xlabel('Epoch', fontsize=10)
ax.set_ylabel(metric.capitalize(), fontsize=10)
ax.legend()
ax.grid(alpha=0.3)
plt.suptitle('Training History', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.savefig(RESULTS_DIR / 'training_curves.png', dpi=300, bbox_inches='tight')
plt.show()
print(f"✓ Training curves saved")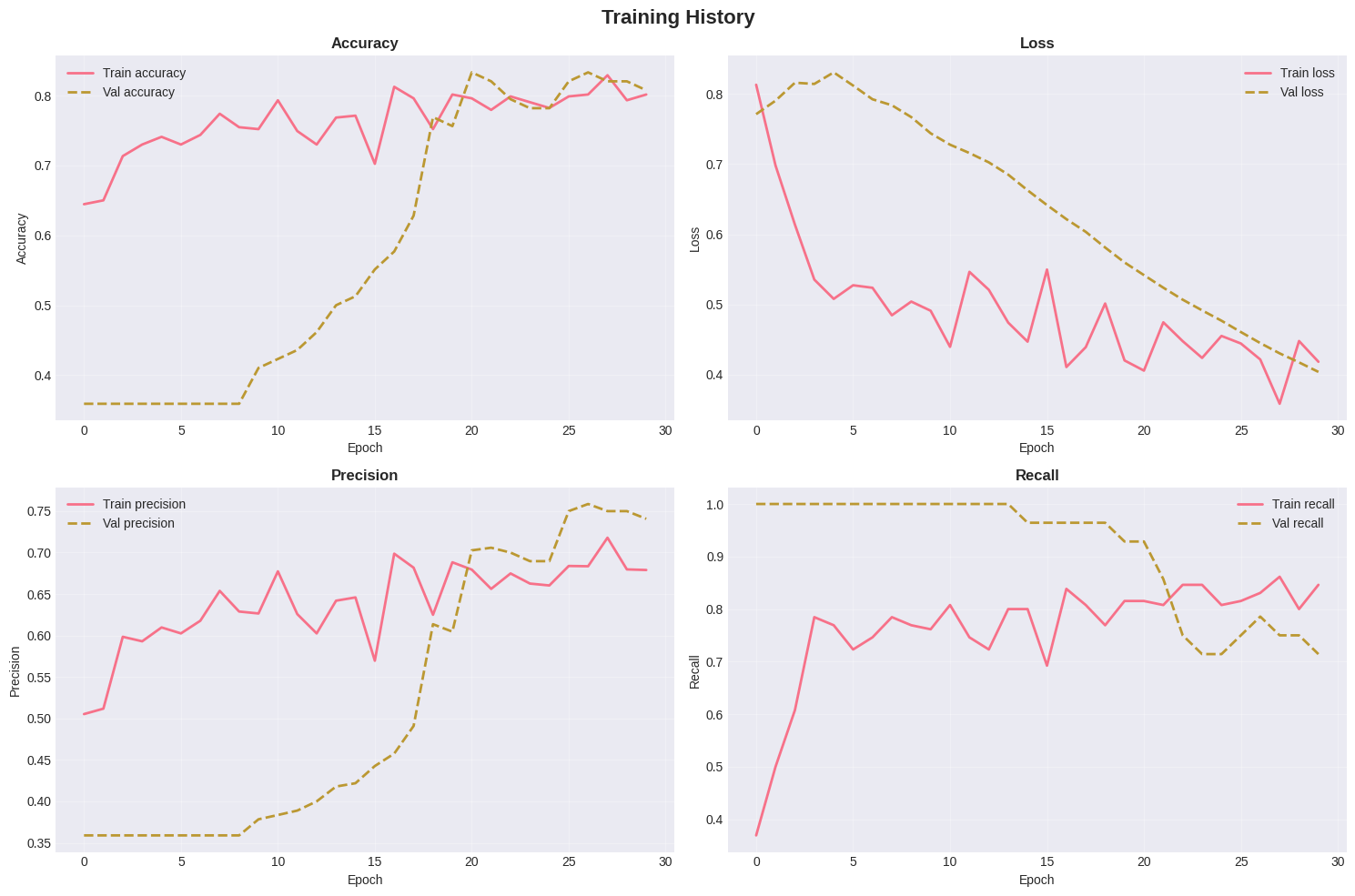
✓ Training curves saved