elasticSearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
Logstash
Logstash 是开源的服务器端数据处理管道,支持从不同来源采集数据,装换数据,并将数据发送到不同的存储库中,我们这里利用logstash将oracle数据转化为json格式存储到elasticsearch检索引擎的集群中。
elasticSearch安装
-
1.elasticSearch安装需要电脑配置Java环境,下载jdk1.8之后,再配置环境变量
-
2.下载elasticSearch
从 elastic 的官网 elastic.co/downloads/elasticsearch 获取最新版本的Elasticsearch,我本机下载的是elasticSearch6.2.3,下载后直接解压即可
- 3.elasticSearch配置
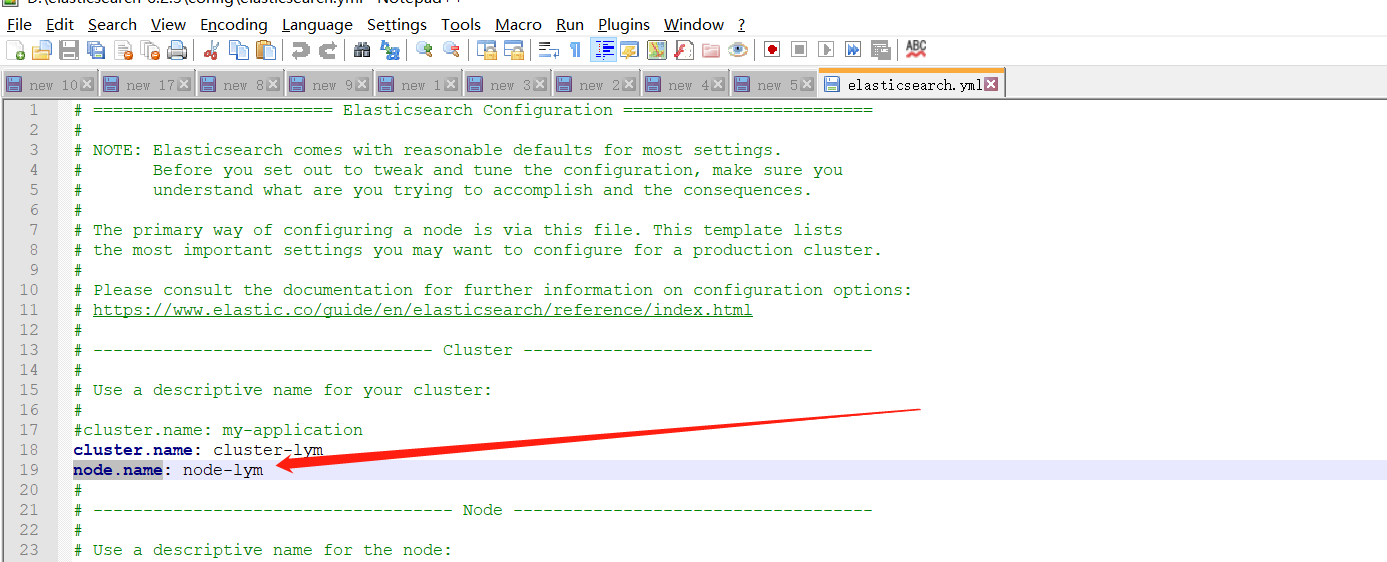
用文本编辑器打开根目录的config文件夹中的elasticsearch.yml文件,将集群名:cluster.name和节点名node.name配置成你自己定义的名字
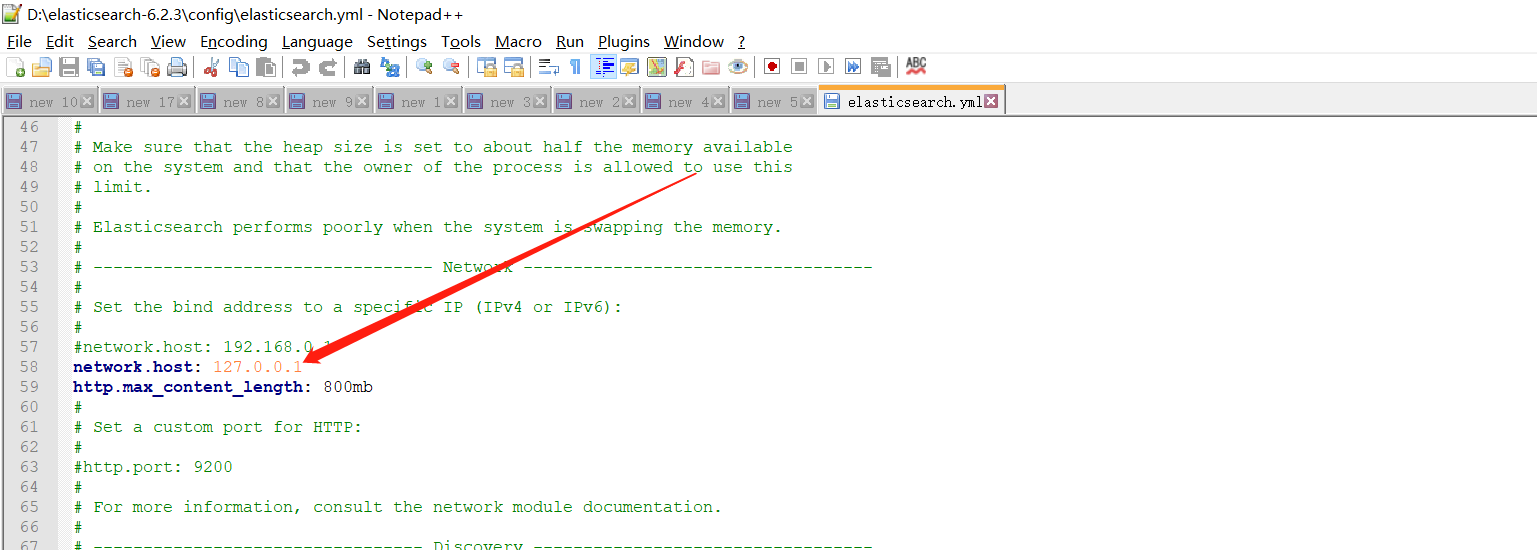
elasticsearch本地主机名也需要配置,如下
- 4配置好之后,点击bin目录下的elasticsearch.bat即可启动
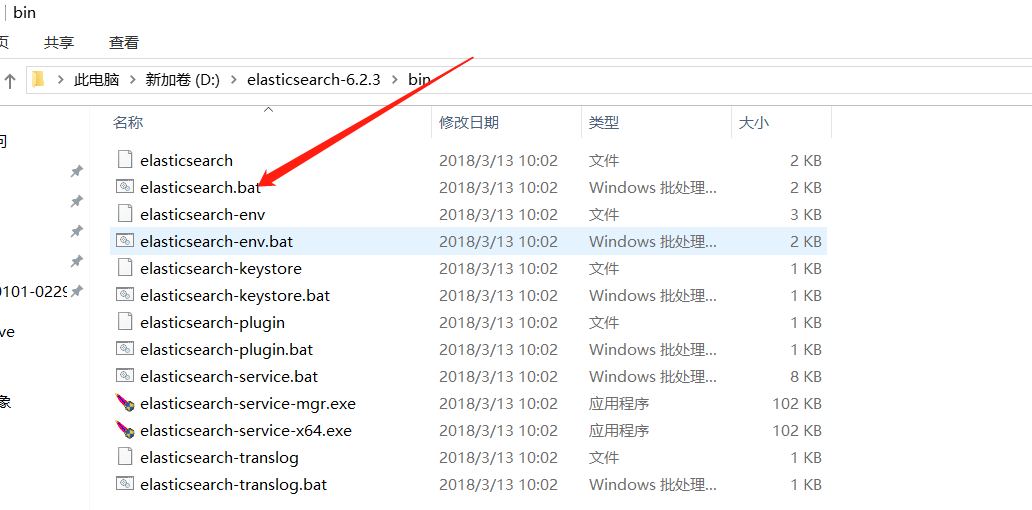
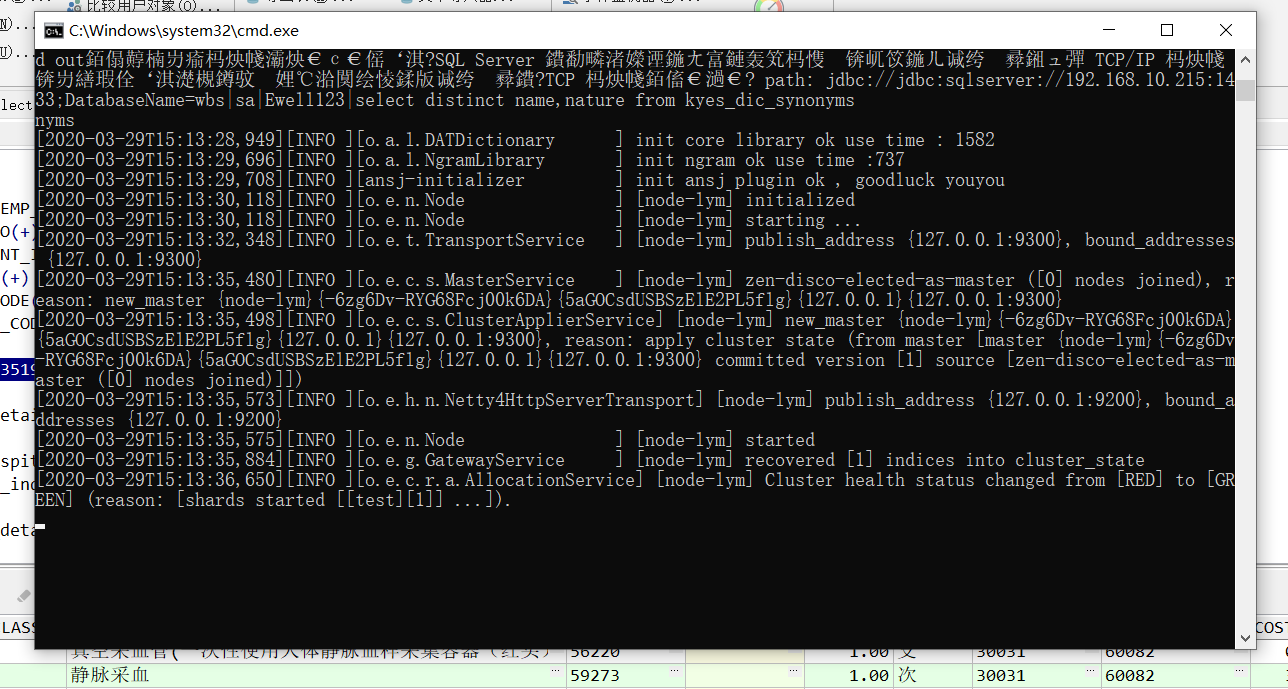
可以看到elasticsearch已正常启动,并且地址是127.0.0.1:9200,这时候我们可以在浏览器中输入改地址来测试elasticsearch是否正常启动
2.logstash安装
可以直接到 https://www.elastic.co/downloads/logstash 下载想要的版本,这里使用的是7.6.1 版本,直接下载解压即可
- 配置文件修改
进入到logstash的bin目录下新建两个文件,一个为logstash_default.conf,一个为emr_oracle.sql。
其中logstash_default.conf的内容为:
input {
stdin {
}
jdbc {
jdbc_driver_library => "D:\elasticsearch-6.2.3\lib\ojdbc6-11.2.0.3.jar"
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
jdbc_connection_string => "jdbc:oracle:thin:@192.168.3.213:1521/orcl"
jdbc_user => "ihd"
jdbc_password => "ihd"
schedule => "* * * * *"
statement_filepath => "D:\logstash-7.6.1\bin\emr_oracle.sql"
use_column_value => true
tracking_column_type => numeric
tracking_column => rn
codec => plain { charset => "UTF-8"}
jdbc_paging_enabled => true
jdbc_page_size => 50000
last_run_metadata_path => "D:\logstash-7.6.1\bin\emr\last_id.txt"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "cpoe_exam"
document_type => "_doc"
document_id => "%{rn}"
template_overwrite => true
}
stdout{
codec => json_lines
}
}其中上半部分是配置和oracle数据库的连接相关的信息,下半部分是配置数据输入输出参数,
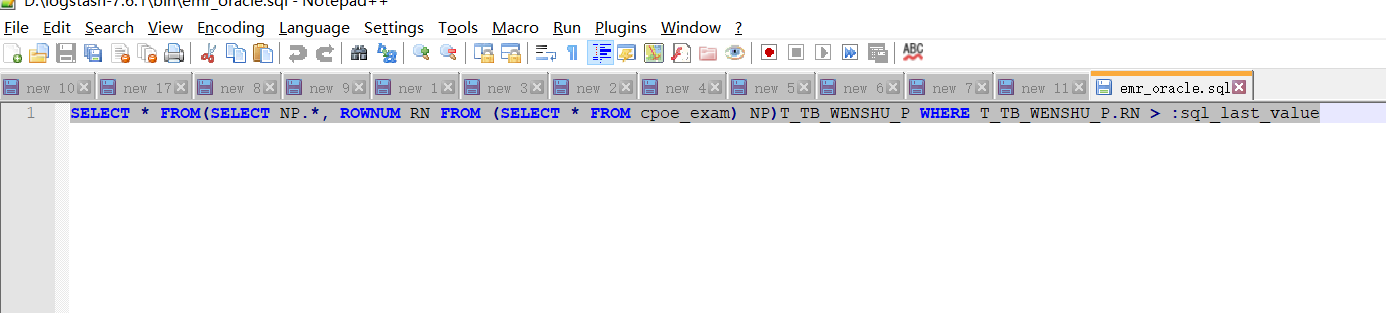
emr_oracle.sql文件中写需要导入的数据的查询语句,我这里导出的是检查申请表的数据,例如:
- 再在bin目录下面新建一个emr文件夹,里面新建一个last_id.txt文本用于记录上次同步数据的最新一条的id。
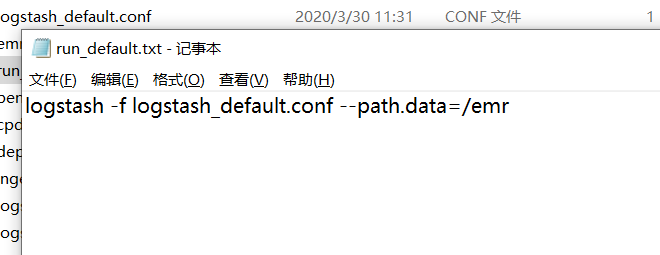
- 再在bin目录下新建一个批处理bat文件run_default.bat,内容为运行之前我们改好的配置文件
- 最后,运行改批处理文件,即可进行数据转换
3.elasticsearch查询
首先我们需要在谷歌浏览器中安装head插件,并且配置连接地址为之前我们配置的ElasticSearch的地址localhost:9200,回车之后就可以看到我们转化的数据所存储的集群和节点,可以看到,在ES中已经有我们在logstash配置文件中配置的集群,以及对应的节点
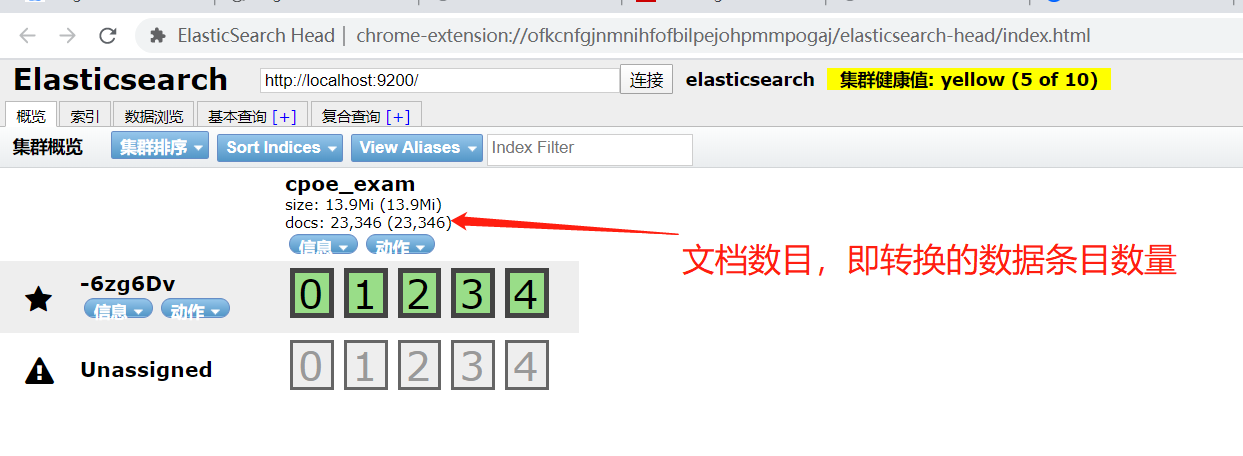
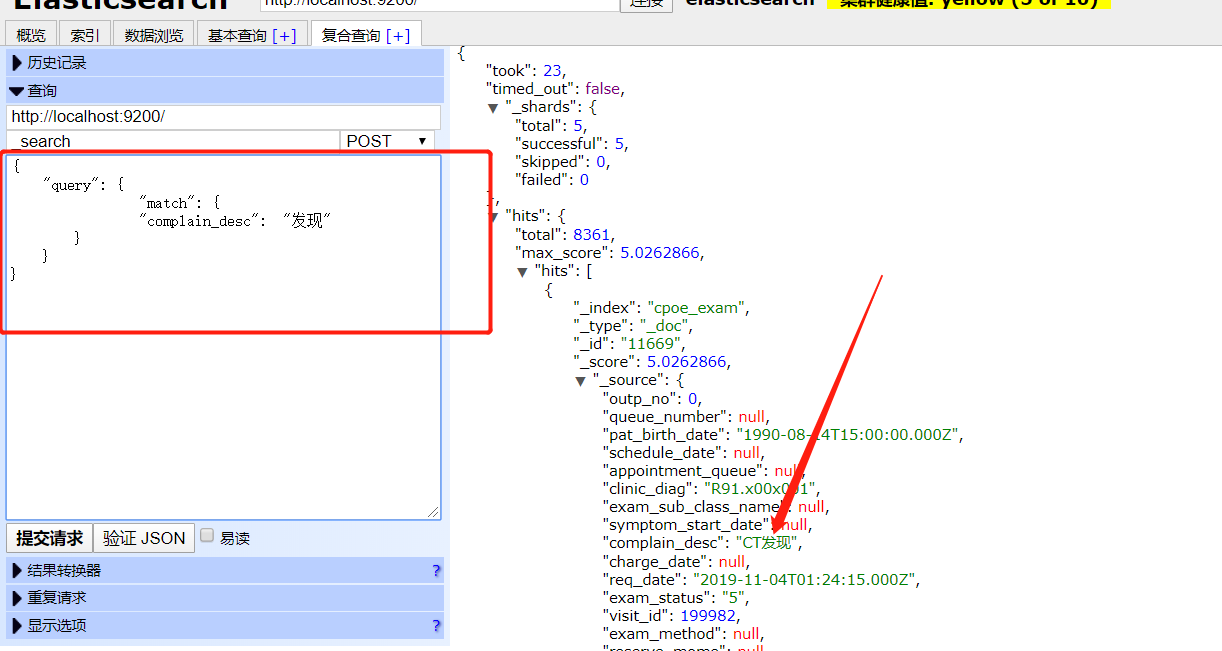
- 切换到基本查询页面和复合查询页面即可对集群中的数据进行检索
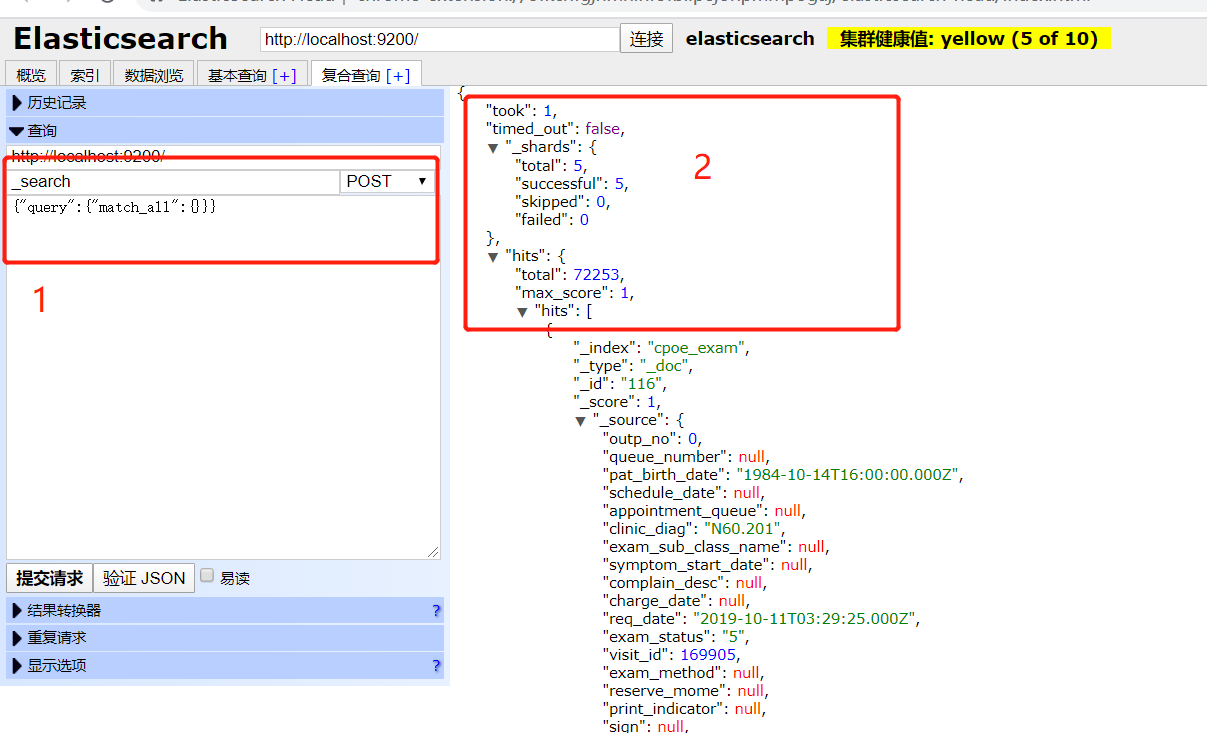
- 其中1部分框中的是ElasticSearch查询语法,第2部分是检索结果,took表示检索时间(图片中是1毫秒)、_shards节点是分片信息、hits节点中为数据集信息,total表示检索到了72253条数据,hits集合中为所有json文档的集合,之前oracle表中每一条数据在这里都为一份JSON文档。
- 我们还可以用match接口进行模糊查询,如下图,查询检查申请单中,主诉包括"发现"两字的文档,可以看出总共有8361份文档被检索出来,