MegaBeam-Mistral-7B:扩展上下文而非参数的高效长文本处理
一句话总结 :MegaBeam通过RoPE theta调优、bf16精度修复和Ring Attention等系统级优化,将7B模型的上下文扩展至512K tokens,成为首个无需RAG即可在超长上下文下实现竞争性推理的开源模型。
📖 论文信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Scaling Context, Not Parameters: Training a Compact 7B Language Model for Efficient Long-Context Processing |
| 作者 | Chen Wu, Yin Song |
| 机构 | Amazon Web Services (AWS) |
| 发表会议 | ACL 2025 Industry Track |
| 论文链接 | arXiv / ACL Anthology |
| 模型地址 | HuggingFace |
| 开源协议 | Apache 2.0 |
| 下载量 | 10万+次 |
🎯 1. 研究背景与问题定义
1.1 长文本处理的两难困境
处理长文本是LLM应用的核心挑战之一。想象一下,你需要让AI审查一份500页的合同------当前主流方案存在明显的权衡:
| 方案 | 优势 | 劣势 |
|---|---|---|
| RAG方案 | 节省计算资源,支持动态知识更新 | 可能丢失关键信息,检索质量影响大 |
| 大参数模型 | 直接处理长文本,信息完整 | 成本高昂,部署困难 |
核心问题:能否用小参数模型(7B级别)处理超长文本(512K tokens)?
💡 生活化比喻:这就像问"一个记忆力超强的普通人,能否完成需要团队协作才能完成的文档审查工作?"MegaBeam的答案是:可以,只要训练方法得当。
1.2 MegaBeam的设计理念
MegaBeam提出**"扩展上下文,而非参数"**的技术路线:
| 维度 | 传统大模型方案 | MegaBeam方案 |
|---|---|---|
| 参数规模 | 70B+ | 7B |
| 上下文长度 | 8K-32K | 512K |
| 部署成本 | 高(多卡/集群) | 低(单卡A100) |
| 推理速度 | 慢 | 快 |
1.3 实际应用驱动
MegaBeam的开发源于AWS与客户的真实需求,涵盖数字设计、银行、生命科学等领域。论文详细描述了一个企业合规监控的典型场景:
| 组件 | 内容 | 规模 |
|---|---|---|
| 输入1 | 客户交互日志 | 数十万tokens |
| 输入2 | 标准操作程序(SOP) | 数万tokens |
| 任务 | 检测违规行为 | 全局理解 |
MegaBeam优势:无需切分对话,直接处理完整上下文,识别分散在不同位置的关联违规。
🏗️ 2. 方法论:四阶段训练流程
2.1 整体训练流程
MegaBeam基于Mistral-7B-Instruct-v0.2,采用四阶段渐进式训练:
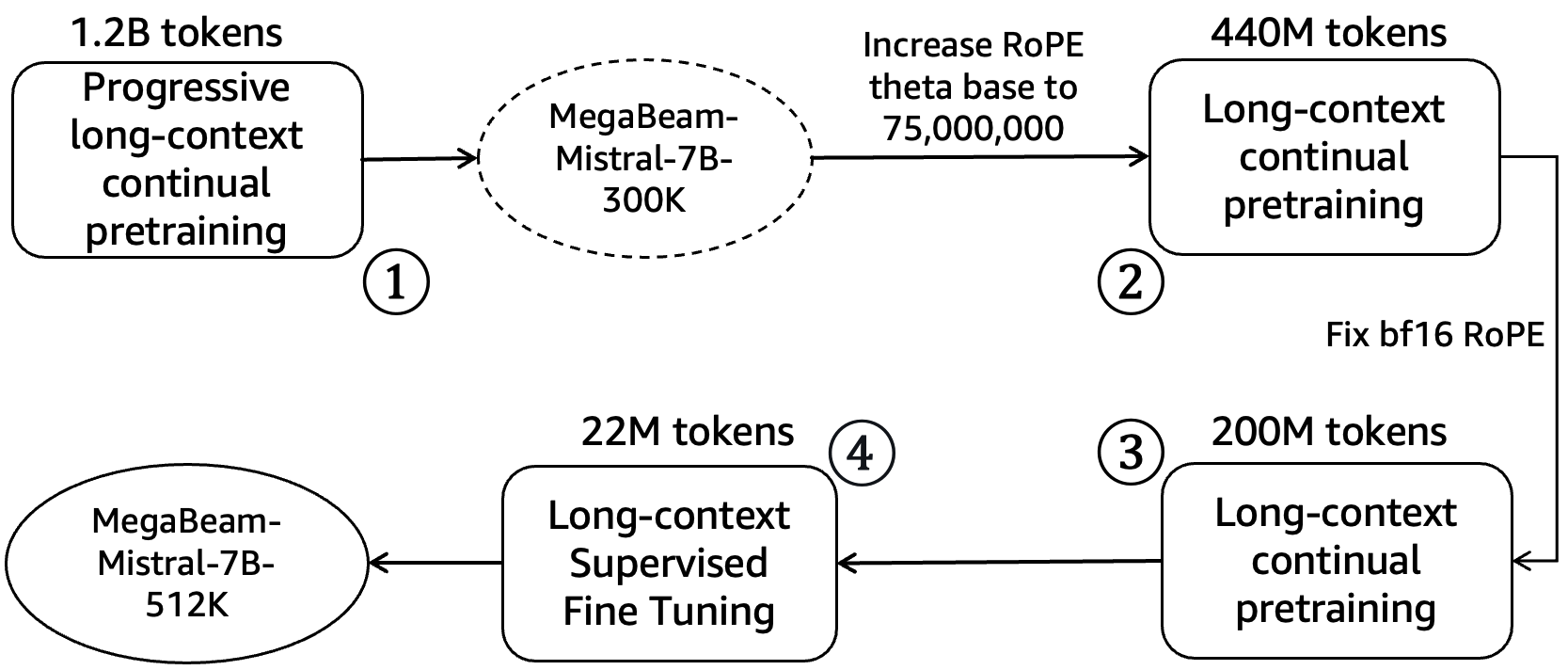
图1:MegaBeam的四阶段训练流程------从长上下文预训练到最终的监督微调
阶段1: 长上下文预训练 (1.2B tokens)
↓
阶段2: RoPE theta调优 + 端点修复 (0.44B tokens)
↓
阶段3: bf16精度修复 + 持续预训练 (0.2B tokens)
↓
阶段4: 长上下文SFT (22M tokens)
↓
最终模型: MegaBeam-Mistral-7B-512K2.2 阶段一:长上下文预训练
数据配比:
| 数据类型 | 占比 | 说明 |
|---|---|---|
| 源代码 | 70% | 天然具有长程依赖结构(函数调用、变量引用跨越数百行) |
| 开放网络内容 | 15% | 多样化文本,增强泛化能力 |
| 研究论文 | 10% | 结构化长文档,逻辑性强 |
| 公共领域书籍 | 5% | 超长连贯叙事,测试极限长度 |
训练规模:
- 总计1.2B tokens
- 0.64B tokens作为300K序列
- 0.56B tokens作为600K序列
💡 为什么源代码占70%? 代码天然具有长程依赖------一个函数可能在文件开头定义,在结尾调用;一个变量可能跨越数百行被多次引用。这种结构迫使模型学习"记住远处的信息"。
问题发现:使用NIAH(大海捞针)基准测试发现,超过300K tokens后性能显著下降。
2.3 阶段二:RoPE Theta调优
关键发现:Theta Base与上下文长度的关系
| 目标上下文长度 | 理论下界 | MegaBeam实验值 | 说明 |
|---|---|---|---|
| 256K tokens | 28,000,000 | 25,000,000 | 与理论紧密匹配 |
| 512K tokens | 86,000,000 | 75,000,000 | 过高会导致端点性能下降 |
理论公式 (来自Xu et al., 2024):
β = 0.0424 × L 1.628 \beta = 0.0424 \times L^{1.628} β=0.0424×L1.628
其中 L L L是目标序列长度, β \beta β是theta base的理论下界。
问题诊断:当theta base设为100M时,序列端点(depth 0和100)出现性能下降。
💡 直觉解释:theta base过大就像把"位置刻度"拉得太宽------相邻位置的编码差异变小,模型难以区分"第1个词"和"第100个词"的区别。
解决方案:
- 将theta base从25M调整至75M
- 使用较短序列(32K-80K)进行额外训练(0.26B tokens),修复端点问题
2.4 阶段三:bf16精度问题修复
问题发现
在处理长上下文时,研究者发现了一个诡异的bug:
症状:数字回忆任务中丢失最后一位数字
例如:要求回忆 7418118,模型输出 741811根本原因:bfloat16在大位置索引的RoPE计算中存在精度丢失。
| 数据类型 | 符号位 | 指数位 | 尾数位 | 有效十进制位 |
|---|---|---|---|---|
| float32 | 1 | 8 | 23 | ~7位 |
| float16 | 1 | 5 | 10 | ~3位 |
| bfloat16 | 1 | 8 | 7 | ~2位 |
💡 为什么bf16会出问题? 想象你用只有2位小数的计算器做复杂运算------当位置索引达到512,000时,sin/cos计算的微小误差会被放大,导致位置编码"模糊"。
解决方案
python
# 修复前:全bf16计算
rope_embedding = compute_rope(position, theta) # bf16精度丢失
# 修复后:RoPE计算强制float32
with torch.autocast(enabled=False): # 禁用自动混合精度
rope_embedding = compute_rope(position.float(), theta)
rope_embedding = rope_embedding.to(torch.bfloat16) # 其他操作保持bf16后续验证:MegaBeam发布后,Wang et al., 2024的论文《When Precision Meets Position: BFloat16 Breaks Down RoPE in Long-Context Training》对这一问题进行了全面分析,验证了MegaBeam团队的发现。
训练配置:使用0.2B tokens,数据分布在80K、256K、512K三种序列长度:
- 1,200个80K序列(96M tokens)
- 300个256K序列(77M tokens)
- 30个512K序列(15M tokens)
2.5 阶段四:长上下文SFT
使用22M tokens的小型数据集进行有监督微调。关键技巧是创建合成长文档(64K-512K tokens),通过重组真实问答对来挑战模型的长程信息检索能力。
⚙️ 3. 系统级优化
3.1 Ring Attention:序列并行
MegaBeam采用JAX实现的Ring Attention进行序列并行(SP):
| 特性 | 说明 |
|---|---|
| 线性扩展 | 序列并行度(DoSP)随设备数量线性增长 |
| 显存优化 | 超过64K token时禁用张量并行(TP),优先为SP分配显存 |
| 设备支持 | 单节点8x A100 80GB可训练512K序列 |
💡 Ring Attention的直觉:想象8个人围成一圈传递卡片------每人手里拿着自己的Query(问题),而Key/Value(答案线索)像卡片一样在圈里传递。每个人都能看到所有线索,但不需要一个人记住全部。
为什么选择Ring Attention而非DeepSpeed-Ulysses?
| 方案 | 通信方式 | 并行度限制 | 优势 |
|---|---|---|---|
| Ring Attention | 点对点环形 | 无限制 | DoSP随设备数线性扩展 |
| DeepSpeed-Ulysses | all-to-all | 受KV头数量限制 | 实现简单 |
3.2 XLA编译器优化:反直觉的发现
问题:在8x A100 GPU上训练512K序列时,遇到编译时OOM(内存溢出)。
根因分析 :XLA编译器的dynamic_update_slice操作预分配了32GB内存用于查找表。
HLO操作:
mhlo.dynamic_update_slice(
tensor<8x1x64x32x524288xi32>, // 输出张量:32GB
tensor<1x1x64x32x524288xi32>,
...)反直觉发现:增大Query和Key/Value的块大小(chunk sizes)反而减少内存占用!
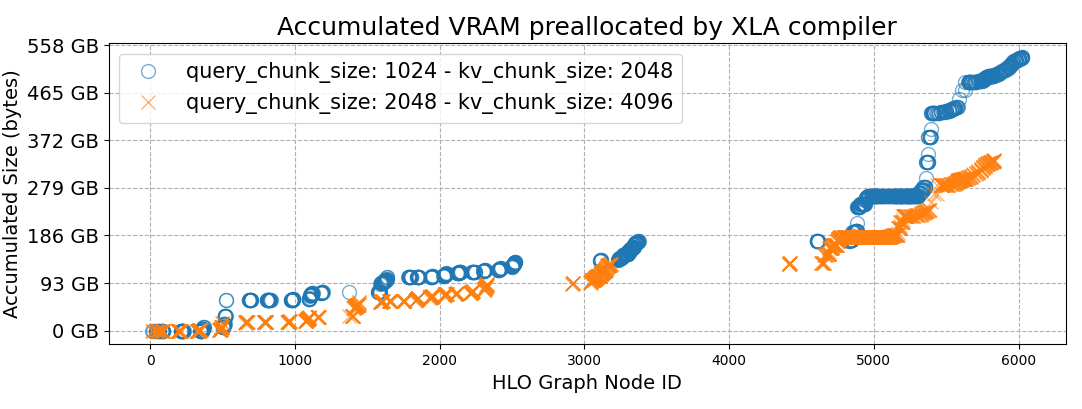
图2:两种chunk配置下的内存预分配对比------橙色线(大chunk)比蓝色线(小chunk)内存占用更低,峰值减少186GB
| 配置 | Q chunk | KV chunk | 最大训练长度 |
|---|---|---|---|
| 原始 | 1024 | 2048 | 256K |
| 优化 | 2048 | 4096 | 512K |
💡 为什么大chunk反而省内存? 传统认为大chunk消耗更多显存(因为每块计算量更大)。但这里的瓶颈是查找表大小------chunk数量减少,查找表维度就变小,内存占用反而下降。
3.3 技术栈总结
| 组件 | 选择 | 理由 |
|---|---|---|
| 基座模型 | Mistral-7B-Instruct-v0.2 | 强大的指令遵循能力 |
| 位置编码 | RoPE (theta=75M) | 支持超长序列 |
| 注意力实现 | Ring Attention (JAX) | 序列并行,线性扩展 |
| 精度 | bf16 + RoPE fp32 | 平衡效率与精度 |
| 训练框架 | JAX/XLA | 编译优化,显存高效 |
🧪 4. 实验设置
4.1 评估基准
| 基准测试 | 评估能力 | 任务类型 |
|---|---|---|
| RULER | 检索追踪 | 大海捞针、多跳追踪、聚合、长文档QA |
| BABILong | 长程推理 | 超长文本中分布式事实的多步推理 |
| HELMET | 上下文学习 | 现实世界下游任务的Few-shot学习 |
4.2 对比模型
| 模型 | 参数量 | 最大上下文 |
|---|---|---|
| Llama-2-7B | 7B | 4K |
| Llama-3.1-8B | 8B | 128K |
| Llama-3.1-70B | 70B | 128K |
| Mistral-Nemo | 12B | 128K |
| Command-R | 104B | 128K |
| Qwen-2-72B | 72B | 128K |
| GPT-4-0125-preview | ~1T | 128K |
📊 5. 实验结果
5.1 RULER基准:检索追踪能力
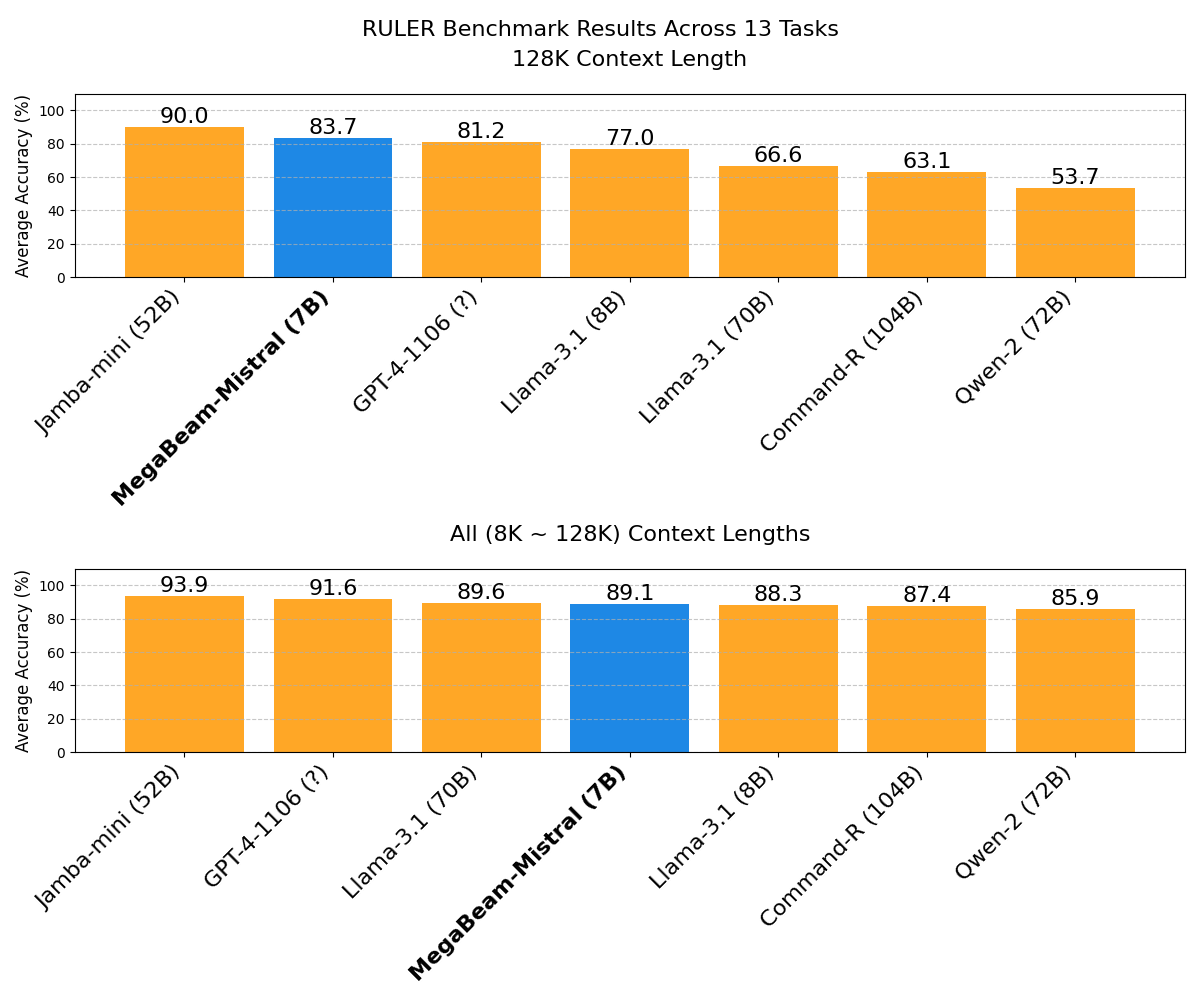
图3:RULER基准测试模型性能对比------上半部分为128K上下文结果,下半部分为8K-128K平均性能
| 模型 | 8K-128K平均 | 128K | 特点 |
|---|---|---|---|
| GPT-4-1106 | - | 低于MegaBeam | 商业闭源 |
| Llama-3.1-70B | ~MegaBeam | - | 10倍参数量 |
| Llama-3.1-8B | 低于MegaBeam | - | 同级别参数 |
| Command-R-104B | 低于MegaBeam | - | 15倍参数量 |
| Qwen-2-72B | 低于MegaBeam | - | 10倍参数量 |
| MegaBeam-7B | 顶级 | 97%(7/8任务) | 最小参数量 |
关键发现:
- 在128K长度的检索任务上,MegaBeam达到近乎完美的表现(8个任务中7个达到97%)
- 多跳追踪任务达到89%
- QA任务达到77.4%
- 短上下文能力保持:4K-16K仍保持92-94%准确率
💡 有趣发现 :Llama-3.1-8B在RULER上超越了其70B版本,说明模型大小并不能保证长上下文性能------专门的训练方法更重要。
5.2 BABILong基准:长程推理能力
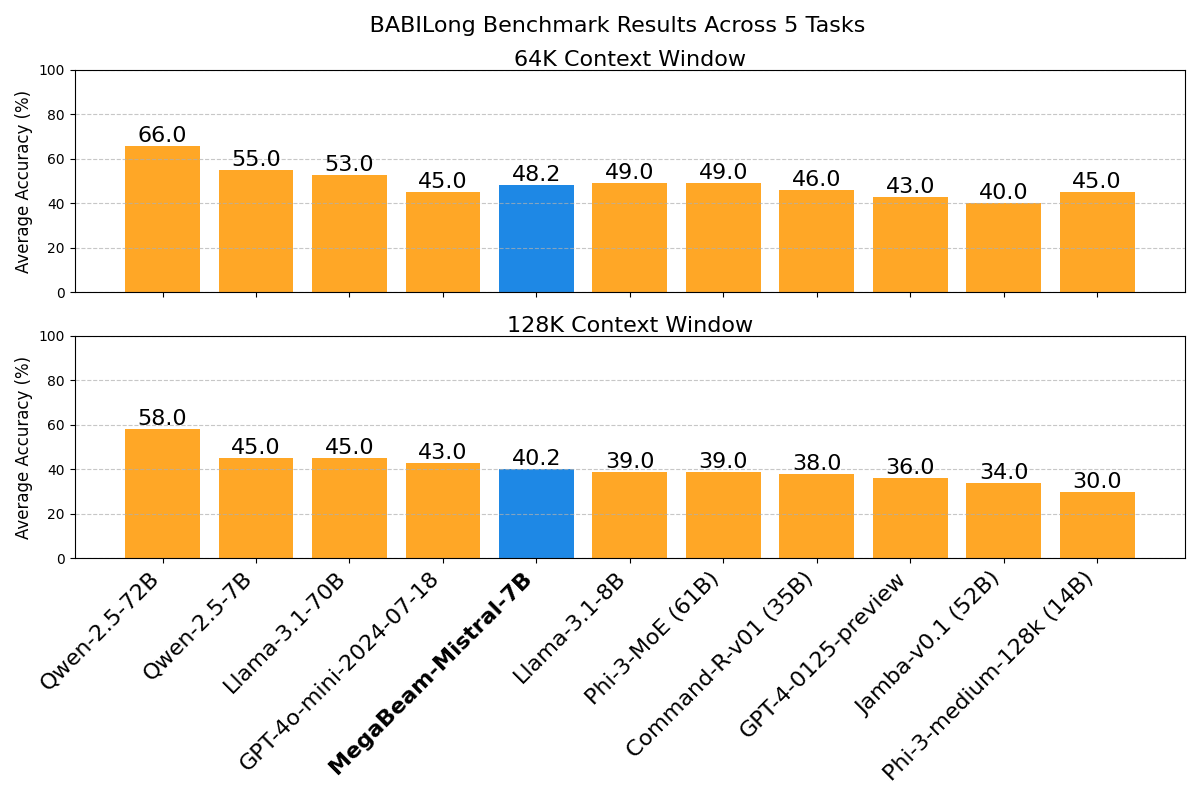
图4:BABILong基准测试在64K和128K上下文长度下的性能对比
| 模型 | 64K | 128K | 512K | 方法 |
|---|---|---|---|---|
| GPT-4-0125-preview | 43% | 36% | - | 原生 |
| Llama-3.1-8B | 49% | 39% | - | 原生 |
| Phi-3-MoE-61B | 49% | 39% | - | 原生 |
| MegaBeam-7B | 48.2% | 40.2% | 35% | 原生(无RAG) |
里程碑意义 :MegaBeam是唯一一个在512K上下文长度下,无需RAG或特定任务微调,即可实现竞争性推理的开源模型。
推理能力细分分析
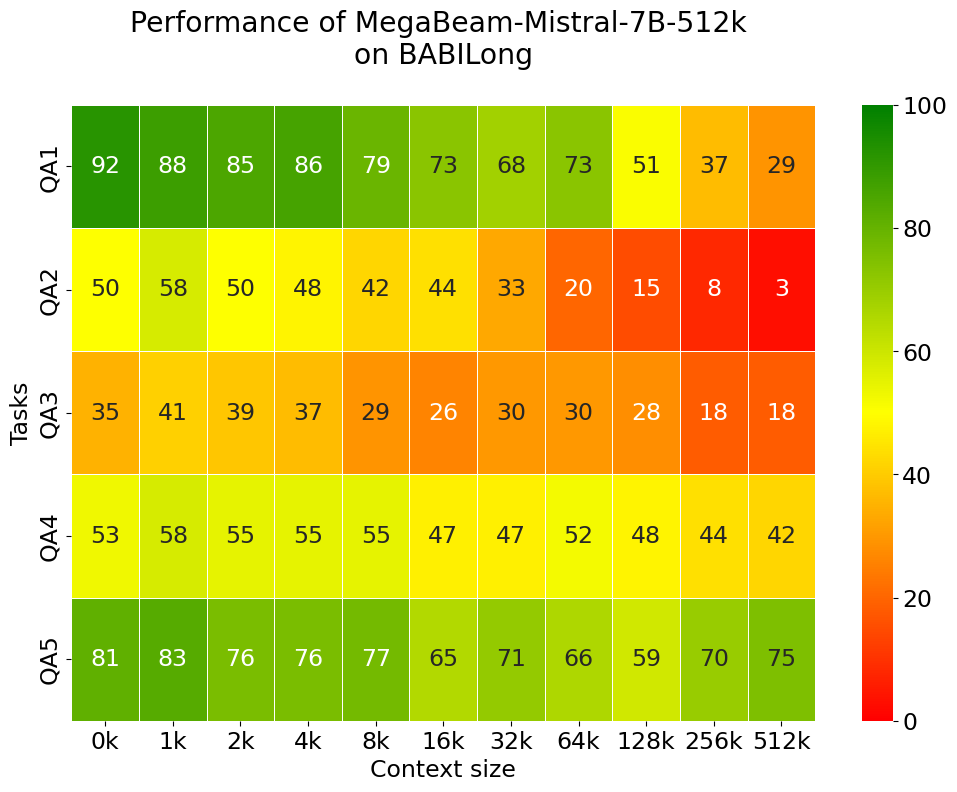
图5:MegaBeam在BABILong各任务上从0K到512K的性能热力图------显示模型在不同任务类型上的上下文扩展能力差异
| 任务类型 | 能力描述 | 32K→512K保留率 | 详细分析 |
|---|---|---|---|
| QA1 | 单事实检索 | 57% | 64K达73%,512K仍有29% |
| QA4 | 双参数关系推理 | 89% | 64K时52%,512K时44%,极其稳定 |
| QA5 | 三参数关系推理 | 92% | 512K时75%,甚至优于32K |
| QA2 | 双事实推理 | 9% | 从32K的33%降至512K的3% |
| QA3 | 三事实推理 | 51% | 从35%降至18% |
洞察:
- ✅ 强项:单跳检索(QA1)和关系推理(QA4/QA5)
- ⚠️ 弱项:多跳推理(QA2/QA3)------需要追踪物体位置、理解时序、整合分布式信息
5.3 HELMET基准:上下文学习能力
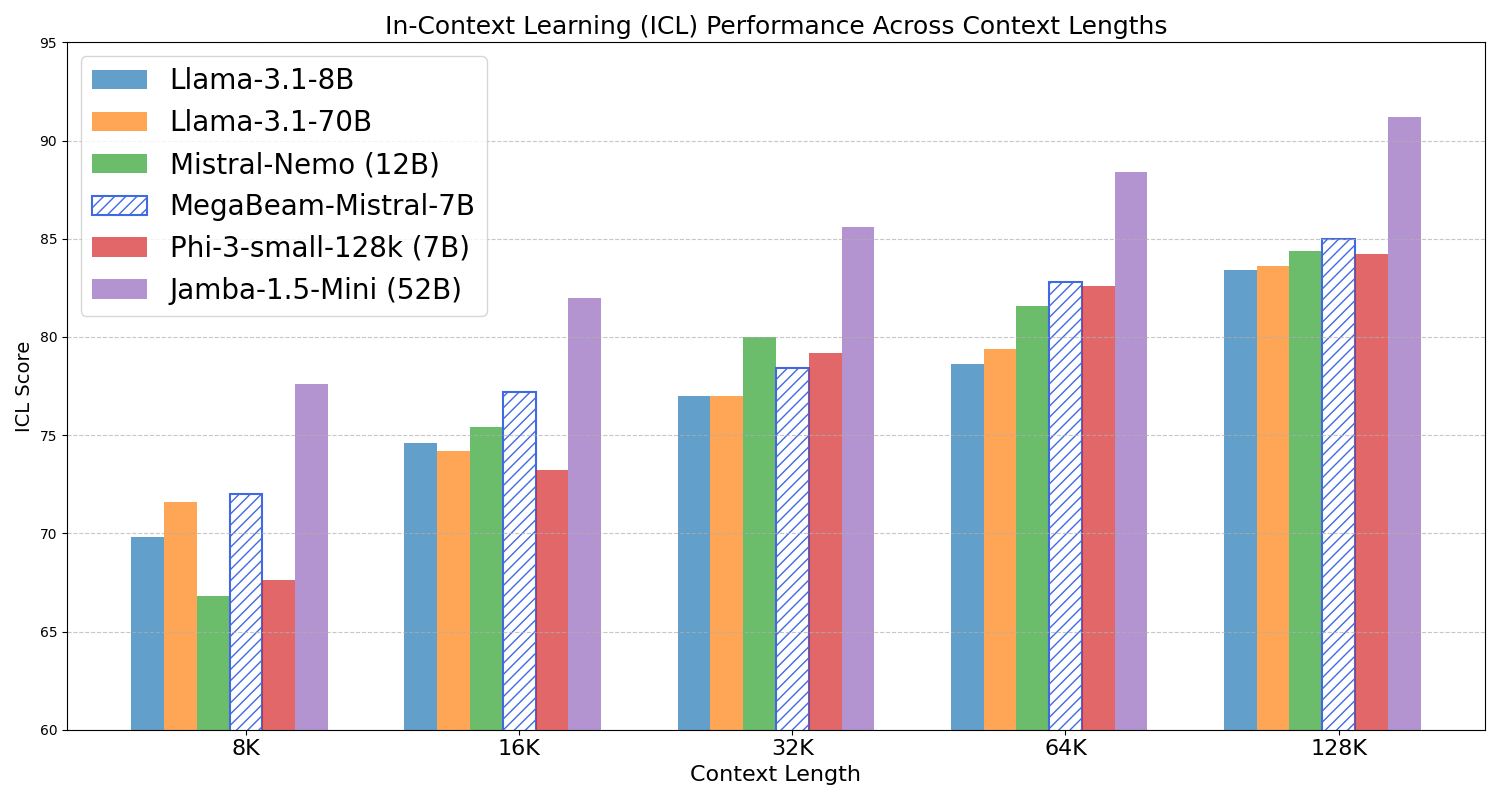
图6:HELMET基准测试的上下文学习(ICL)性能对比------MegaBeam在多个上下文长度下保持领先
| 模型 | 参数量 | 128K ICL得分 |
|---|---|---|
| Mistral-Nemo | 12B | 低于MegaBeam |
| Llama-3.1-8B | 8B | 低于MegaBeam |
| Llama-3.1-70B | 70B | 低于MegaBeam |
| MegaBeam-7B | 7B | 85% |
5.4 效率对比
| 指标 | GPT-4-128K | MegaBeam-7B | 优势 |
|---|---|---|---|
| 参数量 | ~1T | 7B | 143倍更小 |
| 最大上下文 | 128K | 512K | 4倍更长 |
| API成本(100K tokens) | ~$3 | 自部署免费 | 零成本 |
| 部署要求 | API调用 | 单卡A100 | 可私有化 |
🏭 6. 应用场景
6.1 典型应用场景
| 场景 | 输入规模 | 任务 | MegaBeam优势 |
|---|---|---|---|
| 合规监控 | 500页合同 | 检查违规条款 | 识别跨章节关联违规 |
| 代码审查 | 10万行代码 | 安全漏洞检测 | 追踪跨文件数据流 |
| 文档验证 | 技术文档+源代码 | 一致性校验 | 交叉引用验证 |
| 法律分析 | 案卷材料 | 证据关联 | 全局事实整合 |
6.2 开源生态
| 指标 | 数据 |
|---|---|
| HuggingFace下载 | 10万+次 |
| 推理框架支持 | vLLM、TGI、Transformers |
| 开源协议 | Apache 2.0(商用友好) |
🔬 7. 技术深度解析
7.1 为什么RoPE Theta Base很关键?
RoPE(旋转位置编码)通过在复数平面上旋转向量来编码位置信息。theta base决定了旋转的"基础频率":
RoPE ( x , m ) = x ⋅ e i m θ \text{RoPE}(x, m) = x \cdot e^{im\theta} RoPE(x,m)=x⋅eimθ
其中 m m m是位置索引, θ = base − 2 k / d \theta = \text{base}^{-2k/d} θ=base−2k/d。
| Theta Base | 效果 | 问题 |
|---|---|---|
| 过小(如10M) | 短序列精度高 | 长序列位置混淆(旋转"太快") |
| 适中(75M) | 平衡精度与长度 | 最优选择 |
| 过大(如100M) | 理论支持更长序列 | 端点性能下降(旋转"太慢") |
💡 直觉:theta base就像时钟的刻度------刻度太密(小theta),长序列的位置会"挤在一起";刻度太疏(大theta),相邻位置的差异太小,模型分不清。
7.2 bf16精度问题的数学原理
bfloat16只有7位尾数,能精确表示的最大整数约为128。当位置索引超过这个范围时:
python
import torch
# 模拟bf16精度丢失
pos = torch.tensor(500000, dtype=torch.float32)
pos_bf16 = pos.to(torch.bfloat16)
print(f"float32: {pos}") # 500000.0
print(f"bfloat16: {pos_bf16}") # 499712.0 ← 精度丢失!对于512K序列,位置索引可达512,000,远超bf16精度范围。这导致RoPE的sin/cos计算出现误差,进而影响位置编码的准确性。
7.3 Ring Attention vs 其他长序列方案
| 方案 | 原理 | 优势 | 劣势 |
|---|---|---|---|
| Ring Attention | 序列切分,环形通信 | 线性扩展,通信高效 | 需要多设备 |
| Flash Attention | IO优化,分块计算 | 单卡高效 | 不解决序列长度限制 |
| 稀疏注意力 | 只计算部分位置 | 计算量减少 | 可能丢失信息 |
| DeepSpeed-Ulysses | all-to-all通信 | 实现简单 | 受KV头数量限制 |
MegaBeam选择Ring Attention是因为它能在保持完整注意力的同时,支持超长序列训练。
⚠️ 8. 局限性与未来方向
8.1 当前局限
| 局限性 | 说明 | 影响 |
|---|---|---|
| 多跳推理 | QA2/QA3任务512K保留率仅9% | 复杂推理场景受限 |
| 推理资源 | 512K上下文需A100 80G | 部署门槛仍较高 |
| 训练数据 | 超长文本训练数据稀缺 | 进一步扩展困难 |
8.2 多跳推理为何困难?
QA2/QA3任务需要模型同时完成:
- 物体追踪:记住物体在不同时间点的位置
- 时序理解:理解事件发生的先后顺序
- 信息整合:将分散在文档各处的事实组合起来
- 因果推理:理解动作与状态变化的关系
这些能力的组合在超长上下文中面临指数级的复杂度增长。
8.3 未来研究方向
- 多跳推理增强:改进长序列中的多步推理能力
- 更长上下文:探索1M+上下文的可能性
- 效率优化:进一步降低显存占用,支持消费级GPU
- 多模态扩展:支持长视频、长音频等输入
- 混合架构:MegaBeam + RAG的最优组合
💡 9. 实践启示
9.1 长文本处理技术选型
| 考量因素 | RAG优先 | 原生长上下文优先 |
|---|---|---|
| 知识更新频率 | 高频更新 | 低频/固定 |
| 全局理解需求 | 低 | 高 |
| 部署资源 | 有限 | 充足(A100级别) |
| 延迟要求 | 极低(<1s) | 可接受(~10s) |
| 推理类型 | 简单事实查询 | 关系推理、综合分析 |
9.2 MegaBeam部署建议
| 配置项 | 推荐设置 | 说明 |
|---|---|---|
| GPU | A100 80G或更高 | 512K上下文必需 |
| 推理框架 | vLLM | 支持长序列优化 |
| 批处理 | 单请求 | 长序列场景 |
| 精度 | FP16 | 平衡精度与效率 |
| RoPE计算 | FP32 | 避免精度丢失 |
9.3 何时选择MegaBeam而非RAG?
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 动态知识库问答 | RAG | 知识需要实时更新 |
| 单文档深度理解 | MegaBeam | 需要全局上下文 |
| 多文档综合分析 | MegaBeam | 需要跨文档关联 |
| 简单事实查询 | RAG | 检索效率更高 |
| 合规审查、代码审计 | MegaBeam | 需要追踪长程依赖 |
9.4 复现与借鉴思路
如果你想训练自己的长上下文模型,MegaBeam提供了以下可借鉴的经验:
- 数据配比:70%代码 + 30%其他长文档是一个好的起点
- 渐进式训练:从短到长逐步扩展,而非一步到位
- 精度管理:RoPE计算务必使用fp32
- theta调优 :使用公式 β = 0.0424 × L 1.628 \beta = 0.0424 \times L^{1.628} β=0.0424×L1.628作为起点
- 端点修复:扩展theta后,用短序列训练修复端点问题
- 系统优化:增大chunk size可能反而节省内存(需要具体分析)
📚 参考文献
- Chen, S., et al. (2023). Extending Context Window of Large Language Models via Positional Interpolation. arXiv:2306.15595.
- Dao, T., et al. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS 2022.
- Peng, B., et al. (2023). YaRN: Efficient Context Window Extension of Large Language Models. arXiv:2309.00071.
- Liu, H., et al. (2023). Ring Attention with Blockwise Transformers for Near-Infinite Context. arXiv:2310.01889.
- Wang, H., et al. (2024). When Precision Meets Position: BFloat16 Breaks Down RoPE in Long-Context Training. arXiv:2411.13476.
- Xu, G., et al. (2024). Base of RoPE Bounds Context Length. arXiv:2405.14591.
🔗 相关资源
- 论文链接 :arXiv / ACL Anthology
- 模型下载 :HuggingFace
- 开源协议:Apache 2.0(商用友好)
- 相关论文 :BFloat16 Breaks RoPE