Timer : Transformers for Time Series Analysis at Scale
名词 :大型时间序列模型 (large time series models, LTSM ), 单序列序列 (single-series sequence, S3 ), 分位数 (Quantile)
论文解决的问题:
这篇论文试图解决的问题是在时间序列分析领域中,深度学习模型在小样本场景下性能瓶颈的问题:
- 构建统一时间序列数据集(Unified Time Series Dataset,UTSD):为了支持大型时间序列模型(LTSM)的研究,论文首先从公开可用的时间序列数据集中筛选和构建了一个具有层次化能力的统一时间序列数据集(UTSD)。这个数据集包含了来自不同领域的大量时间序列数据,为模型提供了丰富的预训练信息。
- 提出单序列序列(S3)格式:为了将异构时间序列数据统一处理,论文提出了S3格式,将不同时间序列转换为统一的token序列。这种格式保留了序列的模式,同时允许模型在预训练过程中观察到来自不同数据集和时间段的序列,增加了预训练的难度,迫使模型更加关注时间变化。
- 采用GPT风格的预训练目标:论文采用了类似于大型语言模型(如GPT)的预训练目标,即通过自回归下一个时间点预测来训练模型。这种目标允许模型学习时间序列的生成过程,从而在下游任务中展现出更好的泛化能力。
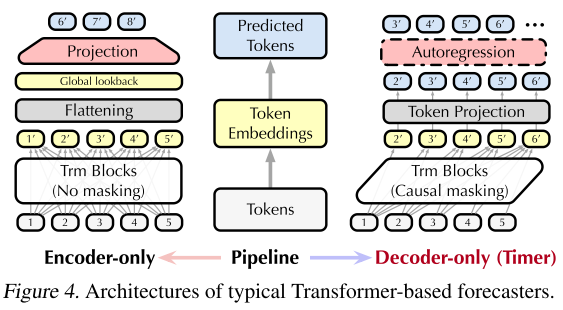
- 开发时间序列Transformer(Timer) :基于上述数据集、训练策略和模型架构,论文提出了Timer,这是一个大规模预训练的时间序列Transformer。Timer采用了与大型语言模型相似的解码器结构,通过自回归生成进行预训练,这使得它在各种时间序列分析任务中展现出显著的泛化能力、可扩展性和适用性。
- 统一生成式方法处理下游任务 :为了利用Timer处理不同的时间序列分析任务,论文将预测、插补和异常检测等任务统一为一个生成式任务。这样,Timer可以通过微调来适应不同的下游任务,而不需要为每个任务单独训练模型。
- 评估和分析 :论文通过在多个真实世界数据集上进行实验 ,验证了Timer在时间序列预测、插补和异常检测等任务中的有效性。同时,论文还分析了模型的可扩展性,包括模型大小和数据规模对性能的影响,以及不同架构对LTSMs的适用性。
模型微调(全量微调)
(1)环境配置:
bash
conda activate Sundial
pip install -r requirements.txt(2)准备数据集:
将下游数据集放在./dataset/文件夹下,可以使用提供的数据集微调, 也可以使用自定义的数据集进行微调,不过默认是按照7:1:2划分数据集。
(3)下载预训练模型:
将下载的预训练checkpoint放在./checkpoints文件夹下
(4)配置微调脚本:
参考scripts/forecast/Traffic.sh创建微调脚本, 利用关键参数配置:指定预测任务和特征模式(单变量还是多变量等)
(5)执行微调脚本:
bash
bash ./scripts/forecast/ECL.sh(6)微调的过程:
- 加载数据:加载训练、验证和测试数据集
- 初始化优化器:使用Adam优化器
- 训练循环:迭代训练指定的epoch数
- 验证和早停:每个epoch后验证并检查是否早停
- 加载最佳模型:训练结束后加载验证集上表现最好的模型
(7)自定义数据集微调:
对于自定义数据集,使用CIDatasetBenchmark或CIAutoRegressionDatasetBenchmark数据加载器,其中CIDatasetBenchmark:用于直接多步预测,CIAutoRegressionDatasetBenchmark:用于迭代多步预测(需要label_len参数)
微调技巧
- 数据稀缺实验 :可以通过
subset_rand_ratio参数控制使用的训练数据比例 - 学习率调整:建议使用较小的学习率(如3e-5)进行微调
- 批量大小:根据GPU内存调整batch_size
- IMS模式 :使用
--use_ims启用迭代多步预测模式, 其中--use_ims参数表示可以按迭代多步方式评估Decoder-Only模型,未启用则按照直接多步方法评估Encoder-Only模型,Direct Multi-step (DMS) and Iterative Multi-step (IMS)
代码分析
S3格式的处理
(1)数据的处理:使用border1s和border2s来定义训练集、验证机、测试集的起止位置;ETTH、ETTm用固定的分割方式分割数据集。
python
if self.data_type == 'custom':
data_len = len(df_raw) # 训练, 验证, 测试集划分为70%, 20%, 10%
num_train = int(data_len * 0.7)
num_test = int(data_len * 0.2)
num_vali = data_len - num_train - num_test
border1s = [0, num_train - self.input_len, data_len - num_test - self.input_len]
border2s = [num_train, num_train + num_vali, data_len] # border1s和border2s用于定义训练集、验证集和测试集的起止位置Pytorch中的DataLoader需要通过一维索引 来访问样本, 需要一个映射机制将一维索引 转换为二维坐标
(2)S3的思想:将每个变量视为独立的单变量时序,每次使用__getitem__调用只返回一个变量的时序片段, 而不是所有变量, 利用c_begin: c_begin+1来选择一列(一个变量)
① 计算每个变量能产生多少个窗口
② 数据集的组织
索引范围 对应内容
0, 880 变量0的881个窗口
881, 1761 变量1的881个窗口
1762, 2642 变量2的881个窗口
2643, 3523 变量3的881个窗口
3524, 4404 变量4的881个窗口
4405, 5285 变量5的881个窗口
5286, 6166 变量6的881个窗口
③ 索引到变量和时间的映射
整除运算 :c_begin = index // n_timepoint 确定变量编号
index = 0 到 880:0 // 881 = 0→ 变量0index = 881 到 1761:881 // 881 = 1→ 变量1index = 1762 到 2642:1762 // 881 = 2→ 变量2
取模运算 : s_begin = index % n_timepoint 确定该变量内的时间起点:
index = 0:0 % 881 = 0→ 变量0的第0个窗口index = 100:100 % 881 = 100→ 变量0的第100个窗口index = 881:881 % 881 = 0→ 变量1的第0个窗口index = 1000:1000 % 881 = 119→ 变量1的第119个窗口
④ 训练集的稀疏采样:通过将索引乘以采样间隔实现跳跃式的选择样本
当 index = index * self.internal 执行时,实际访问的样本索引会被放大。
具体示例 (假设 subset_rand_ratio = 0.2,internal = 5):
| DataLoader 给的 index | 乘以 internal 后 | 实际访问的样本 |
|---|---|---|
| 0 | 0 × 5 = 0 | 第0个样本 |
| 1 | 1 × 5 = 5 | 第5个样本 |
| 2 | 2 × 5 = 10 | 第10个样本 |
| 3 | 3 × 5 = 15 | 第15个样本 |
| ... | ... | ... |
能够实现每隔5个样本取1个的效果,同时__len__方法返回的长度也适配了训练过程的采样,能够覆盖原始数据集中均匀分布的样本。
假设:
- 原始数据集有 6167 个样本 (7个变量 × 881个时间窗口)
subset_rand_ratio = 0.2设置--subset_rand_ratio参数来决定小样本场景下训练样本的占比。internal = 5
训练集的处理:
__len__()返回int(6167 × 0.2) = 1233- DataLoader 会请求索引 0, 1, 2, ..., 1232
- 在__getitem__中:
- 请求 index=0 → 实际访问 0×5=0
- 请求 index=1 → 实际访问 1×5=5
- 请求 index=2 → 实际访问 2×5=10
- ...
- 请求 index=1232 → 实际访问 1232×5=6160
这样就从 6167 个样本中均匀采样了约 20% 的样本。
CIAutoRegressionDatasetBenchmark与CIDatasetBenchmark两个数据集类的区别
(1) CIDatasetBenchmark是直接预测模式, 关键在于__getitem__:
python
def __getitem__(self, index):
if self.set_type == 0:
index = index * self.internal
c_begin = index // self.n_timepoint # select variable 选择变量
s_begin = index % self.n_timepoint # select start time 选择时间起点
s_end = s_begin + self.input_len
r_begin = s_end
r_end = r_begin + self.pred_len
seq_x = self.data_x[s_begin:s_end, c_begin:c_begin + 1] # 提取单个变量的时序片段
seq_y = self.data_y[r_begin:r_end, c_begin:c_begin + 1] # 提取单个变量的预测目标
seq_x_mark = self.data_stamp[s_begin:s_end] # 输入序列的时间特征
seq_y_mark = self.data_stamp[r_begin:r_end] # 预测目标的时间特征
return seq_x, seq_y, seq_x_mark, seq_y_mark预测窗口紧接在输入窗口之后,没有重叠
目标序列长度为:
pred_len
seq_y形状:[pred_len, 1], 只包含需要预测的未来值
时间轴: [0 -------- 672] [672 -------- 768]
↑ seq_x (输入) ↑ ↑ seq_y (目标) ↑
s_begin s_end r_begin r_end seq_x: 时间步 0-672 (输入序列)seq_y: 时间步 672-768 (预测目标,长度96)- 无重叠,直接预测未来96步
(2) CIAutoRegressionDatasetBenchmark是自回归预测模式
python
def __getitem__(self, index):
if self.set_type == 0:
index = index * self.internal
c_begin = index // self.n_timepoint # select variable
s_begin = index % self.n_timepoint # select start time
s_end = s_begin + self.input_len
r_begin = s_end - self.label_len
r_end = r_begin + self.label_len + self.pred_len
seq_x = self.data_x[s_begin:s_end, c_begin:c_begin + 1]
seq_y = self.data_y[r_begin:r_end, c_begin:c_begin + 1]
seq_x_mark = self.data_stamp[s_begin:s_end]
seq_y_mark = self.data_stamp[r_begin:r_end]
return seq_x, seq_y, seq_x_mark, seq_y_mark预测窗口向前延伸
label_len,与输入窗口有重叠目标序列长度为
label_len + pred_len
seq_y形状:[label_len + pred_len, 1]- 包含历史标签和未来预测值
时间轴: [0 -------- 672]
[96 ------------ 768]
↑ seq_x ↑ ↑ seq_y ↑
s_begin s_end r_begin r_end
(s_end-576) seq_x: 时间步 0-672 (输入序列)seq_y: 时间步 96-768 (标签+预测,长度672)- 前576步 (96-672): 历史标签,与
seq_x末尾重叠 - 后96步 (672-768): 需要预测的未来值
- 前576步 (96-672): 历史标签,与
- 有重叠, 自回归预测
PatchEmbedding分析
PatchEmbedding 将连续的时间序列分割成固定长度的 patches,然后将每个 patch 投影到高维嵌入空间
python
class PatchEmbedding(nn.Module):
def __init__(self, d_model, patch_len, stride, padding, dropout, position_embedding=True):
super(PatchEmbedding, self).__init__()
# Patching
self.patch_len = patch_len
self.stride = stride
self.padding_patch_layer = nn.ReplicationPad1d((0, padding)) # 在末尾使用复制填充
# Backbone, Input encoding: projection of feature vectors onto a d-dim vector space
self.value_embedding = nn.Linear(patch_len, d_model, bias=False)
self.positioned = position_embedding
# Positional embedding
if position_embedding:
self.position_embedding = PositionalEmbedding(d_model)
# Residual dropout
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# do patching
n_vars = x.shape[1] # [B, M, T]
x = self.padding_patch_layer(x)
x = x.unfold(dimension=-1, size=self.patch_len, step=self.stride) # [B, M, N, L]
x = torch.reshape(x, (x.shape[0] * x.shape[1], x.shape[2], x.shape[3]))
# Input encoding
if self.positioned:
x = self.value_embedding(x) + self.position_embedding(x)
else:
x = self.value_embedding(x)
return self.dropout(x), n_varspatch_len: 每个 patch 的长度(时间步数)stride: patch 之间的步长,在 Timer 中等于patch_len(非重叠)padding: 填充长度,确保序列可以被完整分割d_model: 嵌入维度-1024position_embedding: 是否使用位置编码
x.unfold(dimension=-1, size=self.patch_len, step=self.stride)
沿着最后一维创建滑动窗口,Timer在输入之前,对x=551, 672, 1做了交换维度的操作, permute之后变成了551, 1, 672;每个窗口patch的大小是96, 步长也是 96。patchembedding之后维度是551, 1, 7, 96,之后将batch和变量维度合并,这样做是因为Timer能够对每个变量独立处理, 将他们视为独立的样本。
PatchEmbedding 通过以下步骤将时间序列转换为 patch 嵌入:
- 填充 : 确保序列长度可被
patch_len整除 - 分割 : 使用
unfold将序列分割成非重叠的 patches - 重塑: 将 batch 和变量维度合并,独立处理每个变量
- 投影: 通过线性层将每个 patch 投影到高维空间
- 位置编码: 添加位置信息(可选)
- Dropout: 正则化
Timer执行的完整流程
- 输入归一化:
[B, L, M]→[B, M, L] - Patch embedding:
[B, M, L]→[B*M, N, D] - Transformer 处理:
[B*M, N, D]→[B*M, N, D] - 投影回时间域:
[B*M, N, D]→[B*M, N, patch_len] - 重塑和反归一化:
[B*M, N, patch_len]→[B, L, M]