一、背景
coredump是程序员人人都知道的东西,在进行core的dump时,系统正在疯狂地写磁盘,如果core比较大,排队写磁盘的任务拥挤,加上系统上近期已经累计了不少脏页要写,就可能会出发coredump时的hungtask,在下面第二章,我们分析一次相关的hungtask的栈,继而提出几个疑问,在第三章里,我们做一些coredump的实验及针对实验结果结合代码进行原理分析。
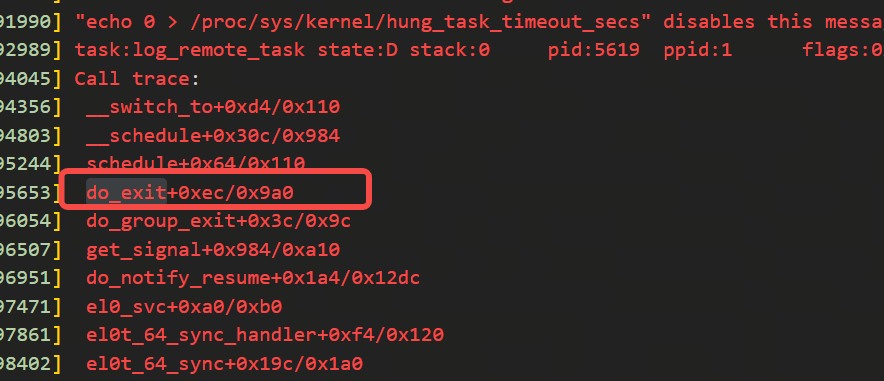
二、do_exit的hungtask问题的堆栈分析
抓到的这次hungtask的堆栈显示的是:
用 常用的底层调试用的不容易记住的命令整理(持续更新) 里第二章里的命令:
bash
aarch64-linux-gnu-objdump -S vmlinux --start-address=0xffff80000809af80 --stop-address=0xffff80000809b920 > vmlinux_do_exit.txt可以如下图看到,得到的elf文件看do_exit函数的大小与堆栈里的函数的大小是匹配的:
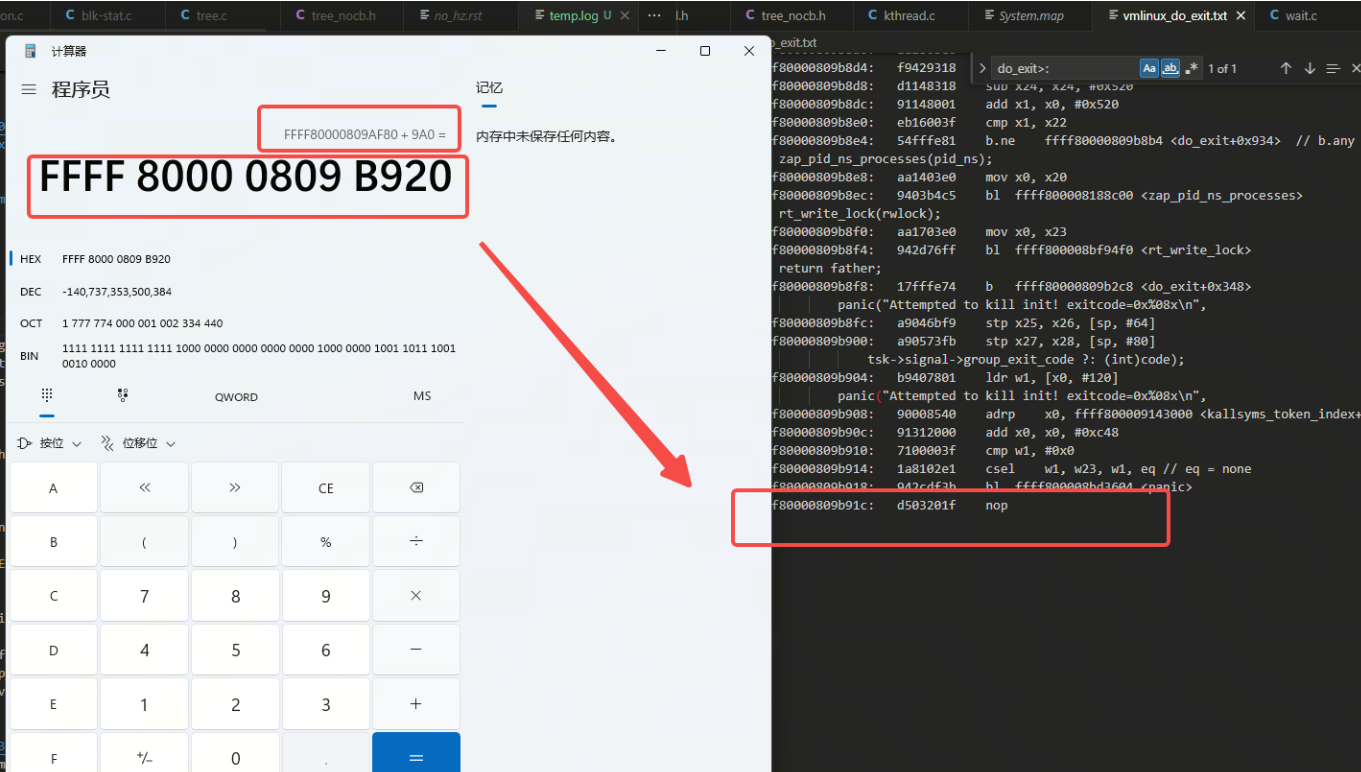

看一下offset到0xec是在哪里:

搜索b06c附近的代码:
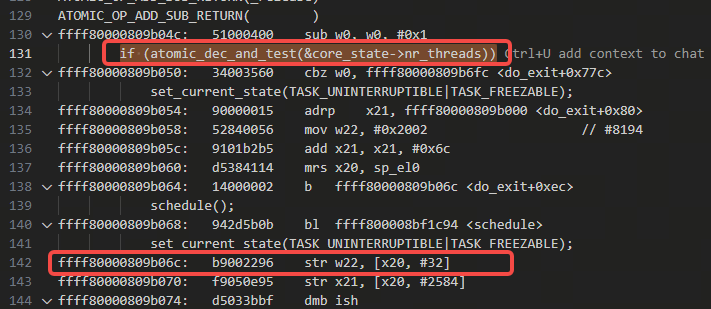
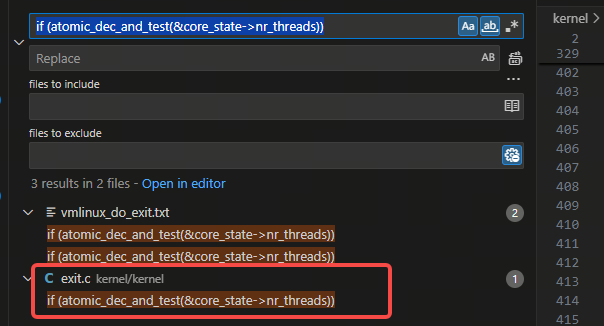
代码里就唯一一处,在exit.c里:
可以看到是coredump_task_exit函数这里的下图里的逻辑,进行schedule等待被唤醒:
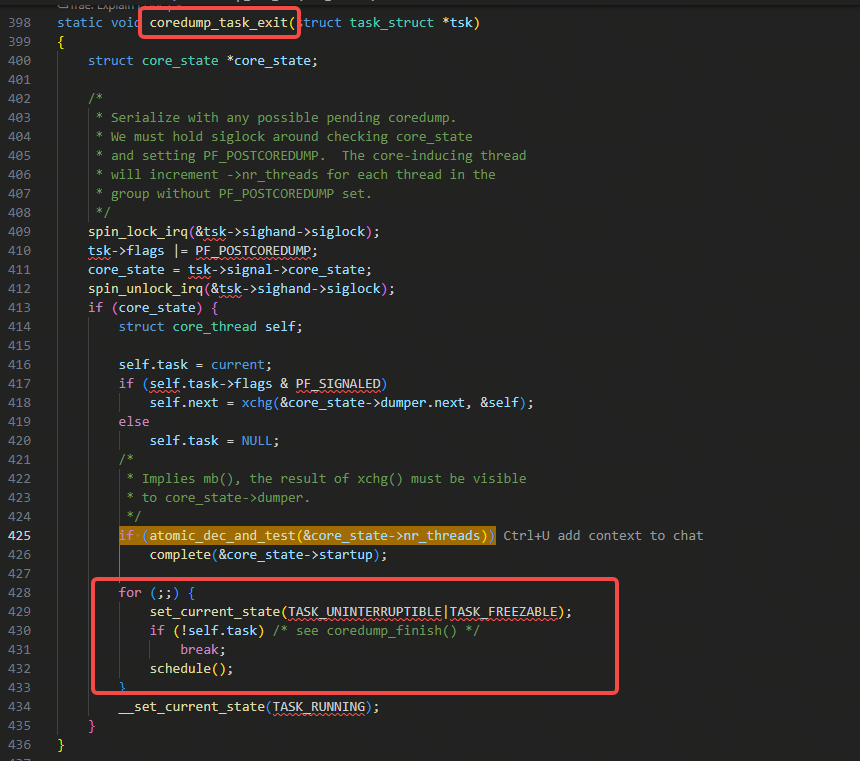
而coredump_task_exit是coredump流程里的重要函数,是除了负责coredump文件生成core的线程之外的其他线程都要经历这个函数,去等最终负责生成core的线程完成core的生成后,再通知回来,再走完do_exit的流程。
在下面第三章里,我们通过实验来说明这个流程。
三、coredump的相关实验及原理分析
3.1 设置coredump格式及配置生成coredump
在通过下面的命令设置coredump的生成路径及格式前,需要配置打开coredump:
bash
ulimit -c unlimited来设置core的文件大小不受限制。
通过下面的命令我想让生成的文件输出到当前目录,并带上一些必要的信息:
bash
echo "./core.%e.%p.%h.%m.%d.%s" > /proc/sys/kernel/core_pattern如下图,可以成功生成coredump:
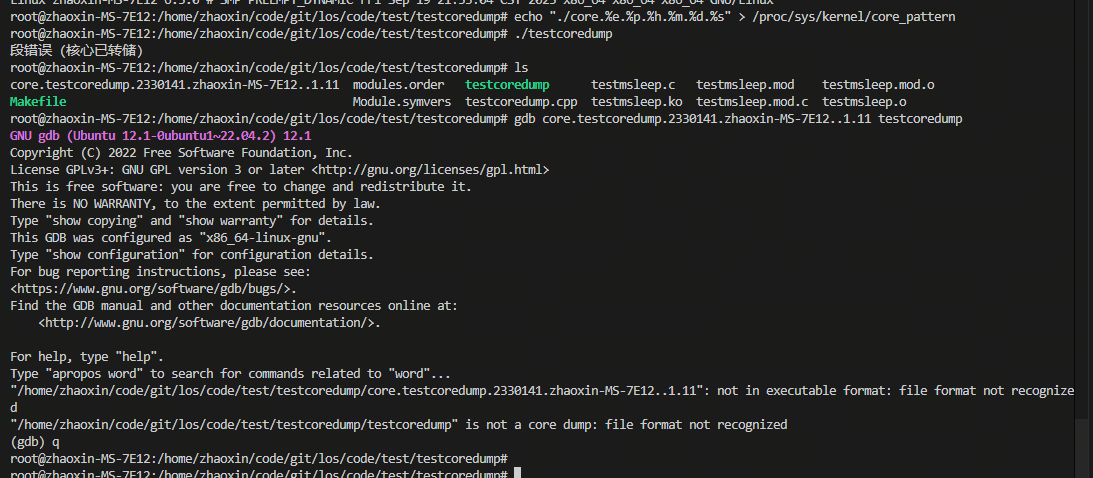
上图执行时用的testcoredump.cpp的源文件如下:
cpp
int main() {
int *p = (int *)0;
*p = 1;
return 1;
}3.2 分析生成coredump的整个流程的调度栈的程序
下一步我们抓一下生成coredump期间的进程内的各个线程是如何依次处理coredump相关的信号的。
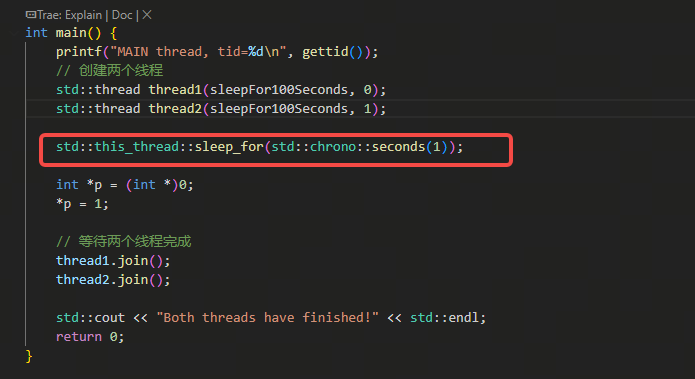
为了能分析多线程的情况,我们改写一下testcoredump.cpp文件,增加两个线程,两个线程分别执行一个很长时间的sleep:
cpp
#include <iostream>
#include <thread>
#include <chrono>
#include <unistd.h>
void sleepFor100Seconds(int n) {
printf("thread %d, tid=%d\n", n, gettid());
while (1) {
std::this_thread::sleep_for(std::chrono::milliseconds(1));
}
}
int main() {
printf("MAIN thread, tid=%d\n", gettid());
// 创建两个线程
std::thread thread1(sleepFor100Seconds, 0);
std::thread thread2(sleepFor100Seconds, 1);
std::this_thread::sleep_for(std::chrono::seconds(1));
int *p = (int *)0;
*p = 1;
// 等待两个线程完成
thread1.join();
thread2.join();
std::cout << "Both threads have finished!" << std::endl;
return 0;
}然后用ftracestart和ftracestop抓取testcoredump程序启动到最后触发coredump的完整的调度情况。(有关ftracestart和ftracestop见之前博客 常用的底层调试用的不容易记住的命令整理(持续更新) 里 第六章)。
写一个测试脚本,来无缝的开始和结束ftrace:
bash
#!/bin/bash
ftrace_start
sleep 0.1
./testcoredump
sleep 0.1
ftrace_stop运行这个测试脚本:

过滤出 perfetto可识别的 trace文件,如何过滤见之前博客 常用的底层调试用的不容易记住的命令整理(持续更新) 里 第六章)。
3.3 分析trace,拆解一步步coredump流程
抓到的触发coredump到进程进行coredump落盘,再到最后进程退出的ftrace在perfetto里解析出来的调度图:

我们依次分析一个个步骤:
3.3.1 主线程完成睡眠,执行会触发coredump的逻辑
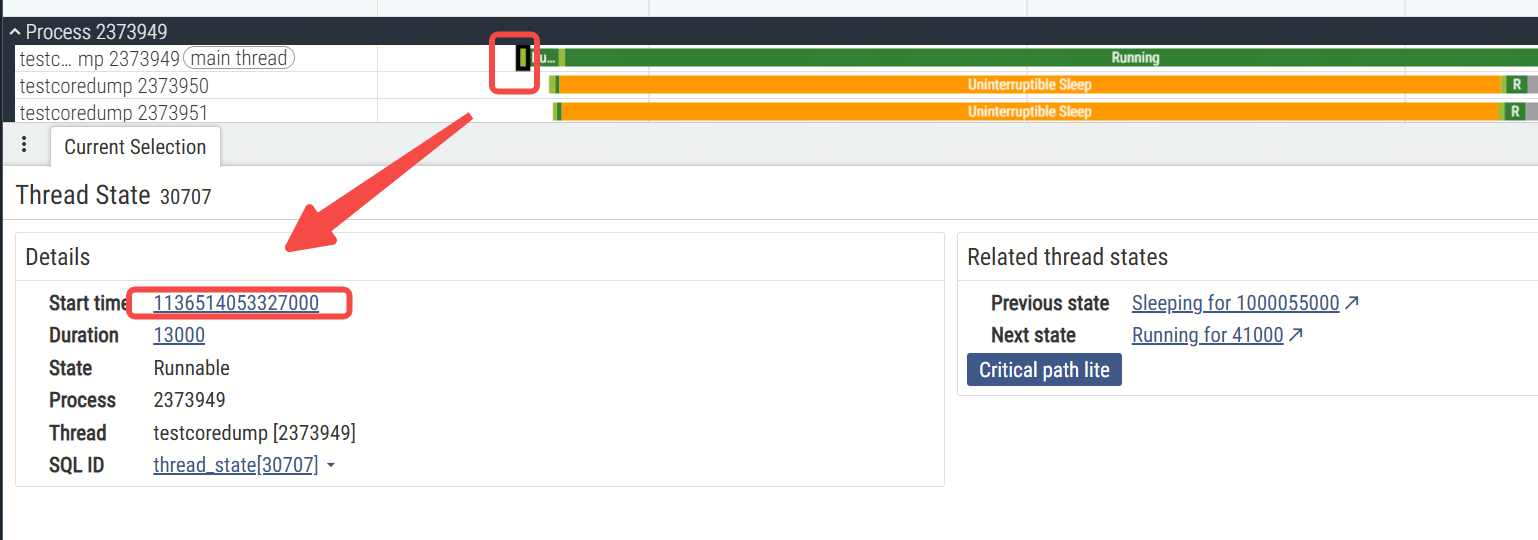
从主线程完成睡眠,开始执行会触发coredump的逻辑开始,ftrace里下面这次:
对应的ftrace里的抓取:
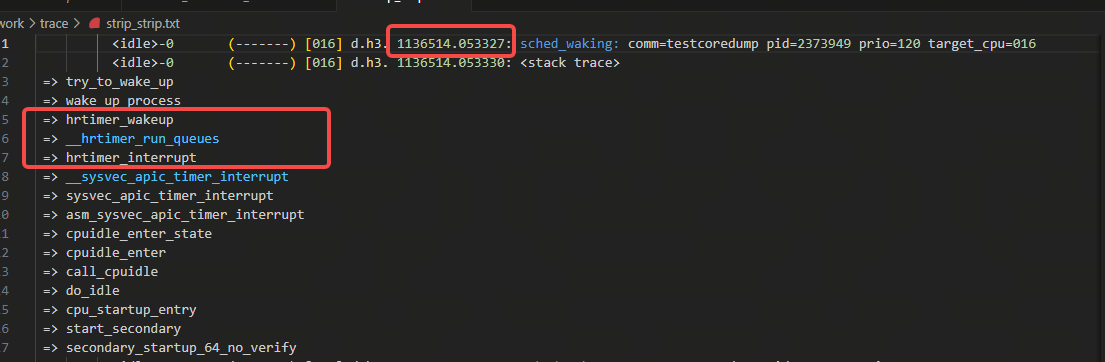
可以看到时间是匹配的,是timer的唤醒,对应源码里下图部分:
然后就执行会触发coredump的逻辑了:

3.3.2 触发coredump的线程唤醒其他线程
接下来就是触发coredump的线程在do_coredump的流程里唤醒进程内的其他线程,如下图是主线程唤醒2373950线程(大概率是thread1):
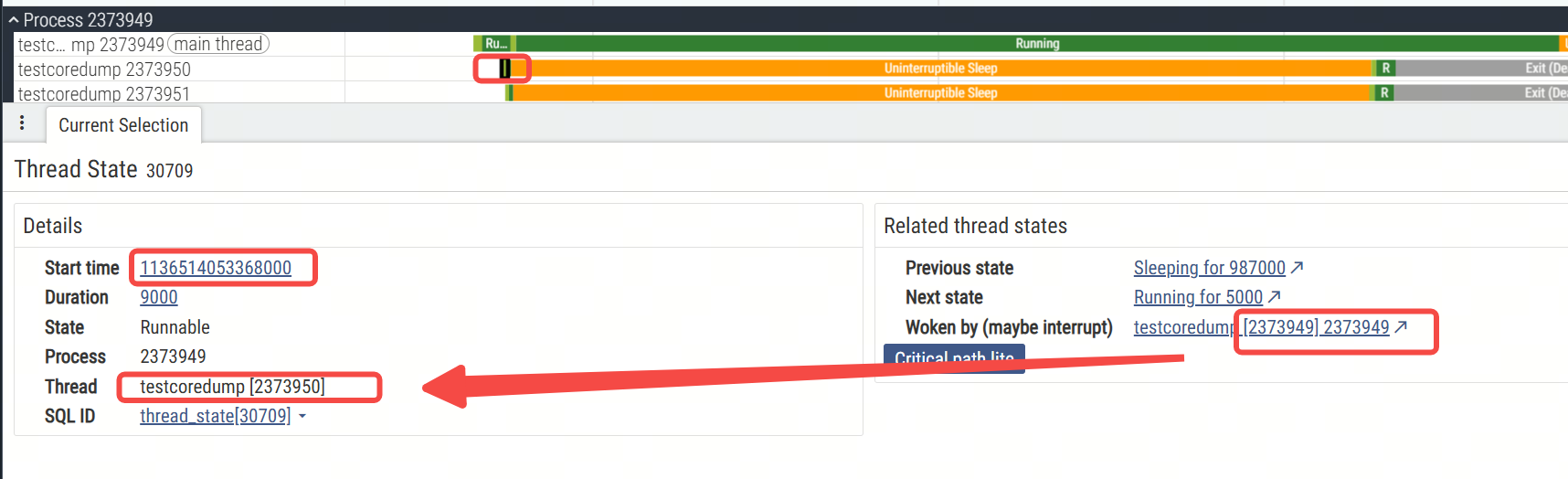


时间和线程id都能对上,看一下do_coredump里唤醒进程内其他线程的逻辑,还是根据elf里去找上图里的do_coredump下一级的调用signal_wake_up_state,找到如下的部分:
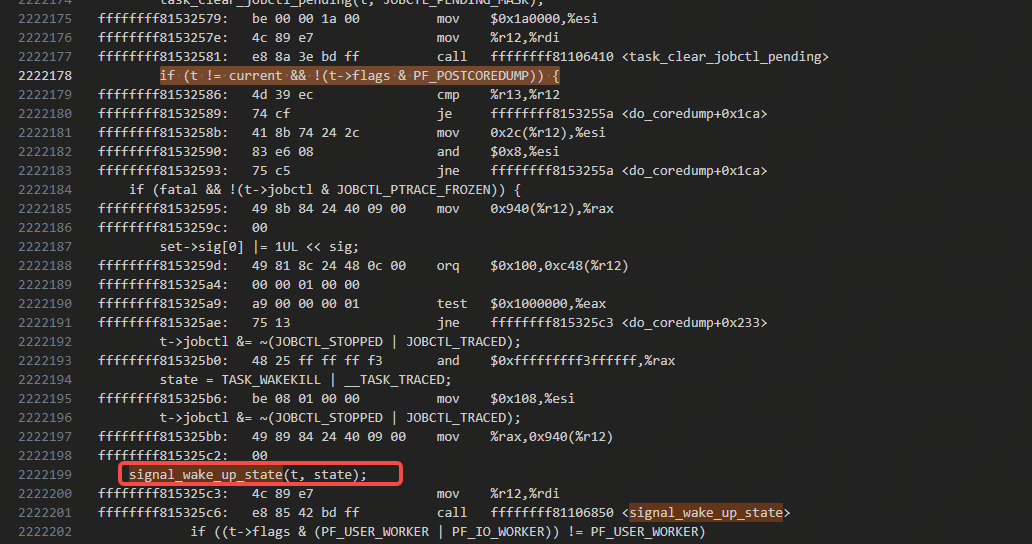
搜索上图里的if (t != current && !(t->flags & PF_POSTCOREDUMP)) {的这段代码,找到唯一一处,在zap_process里:
 signal_wake_up就是在zap_process(所谓的清理进程)这个函数里调用的,看一下zap_process在do_coredump里如何被使用,是下面的调用链:
signal_wake_up就是在zap_process(所谓的清理进程)这个函数里调用的,看一下zap_process在do_coredump里如何被使用,是下面的调用链:
do_coredump
coredump_wait
zap_threads
zap_process
如下图,进行coredump的线程在执行do_coredump时,判断coredump_wait的返回值,如果返回值小于0,则直接返回,因为已经有一个线程在执行coredump了(因为可能有并发的进程内多个线程的地址非法访问):

3.3.3 coredump_wait的实现
看一下coredump_wait的实现:
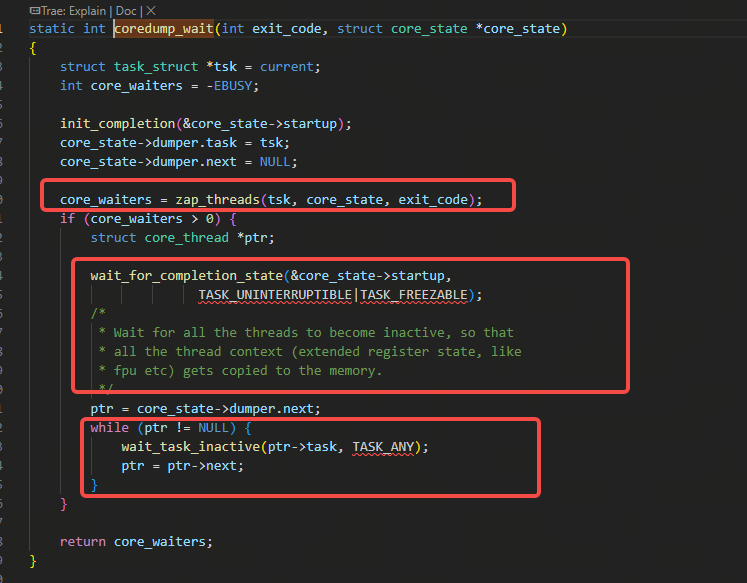
如上图,coredump_wait的实现分为三步:
1)zap_threads去通知其他线程要醒来进入inactive状态
2)等待core_state->nr_threads减为0(这是在非处理core的其他各个线程里做和判断),减为0则被唤醒往下走
3)等待其他线程进入inactive状态
可以从上图里看到,能让coredump_wait返回小于0从而不去走do_coredump的接下来的core进行dumpd的逻辑是建立在zap_threads小于0的情况下,这一点会在下面 3.3.4 一节里介绍。
另外,zap_threads里有上面 3.3.2 分析的触发唤醒其他线程的逻辑,这一点会在下面 3.3.6 一节里介绍。
在介绍zap_threads的逻辑前,先快速看一下wait_task_inactive的注释:
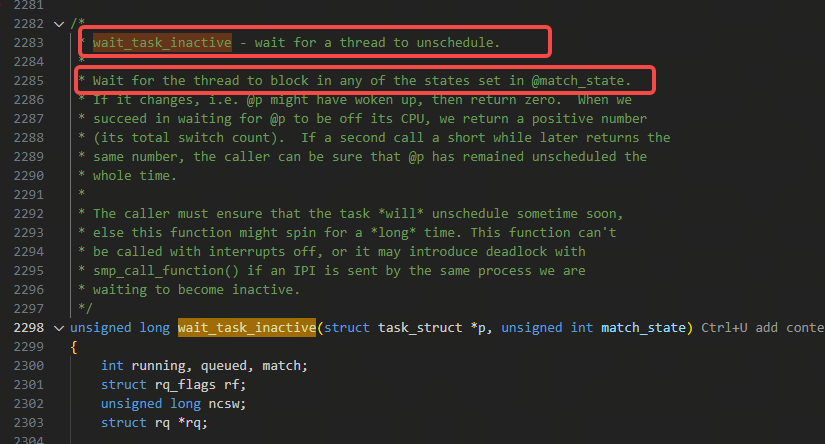
另外,上面说的2)里的非处理core的其他各个线程里做和判断,是在下图里的exit.c里的coredump_task_exit的逻辑里:
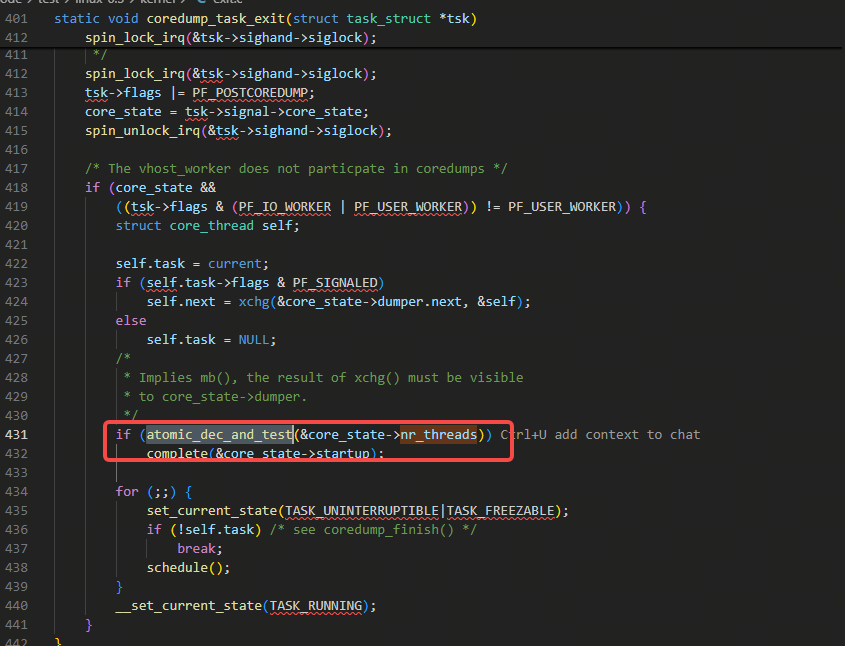
要注意,atomic_dec_and_test减到0是返回true。
3.3.4 zap_threads何时返回小于0
我们来看一下zap_threads的实现,刚才说到zap_threads返回小于0,do_coredump里就不会再去生成core文件了(因为已经有人正在生成了),看看zap_threads什么时候回返回小于0,如下图看到nr初始时是设置成了-EAGAIN,也就是下面的if判断不满足就会返回负值:
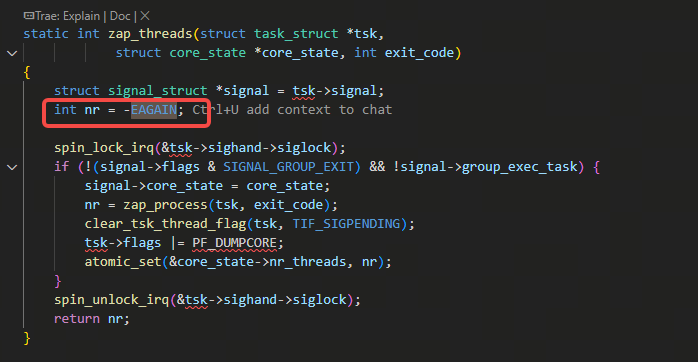
因为上图里的nr = zap_process的逻辑只会赋值成正数:
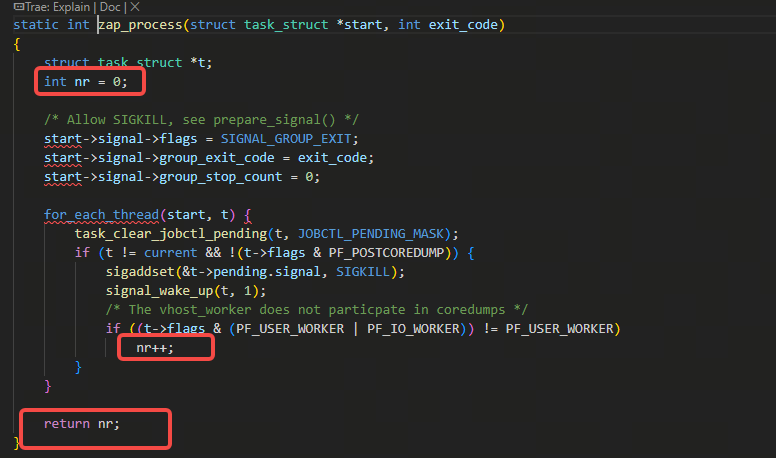
回到zap_threads里,何时会走不进下图里的红色框出的逻辑:
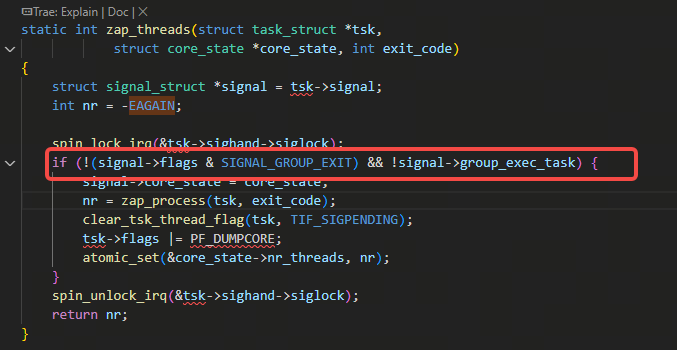
也就是上图里的signal->flags & SIGNAL_GROUP_EXIT是true,要不就是signal->group_exec_task是非空,意思就是任务已经退出状态了,因为后入do_coredump的函数,要进入的时候,前面进入do_coredump函数的线程已经完成了zap_threads的工作,zap_threads里会设置上SIGNAL_GROUP_EXIT状态表示已经开始退出流程了:
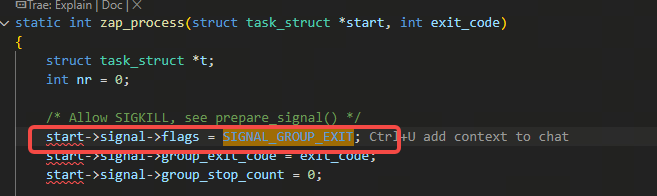
3.3.5 group_exec_task什么时候是非空呢
那么什么情况下group_exec_task是非空呢,那是在执行exec时,(由于已经执行exec了,那么执行exec时的进程里的所有线程都不再需要),会设置这个group_exec_task变量:
调用链是:
begin_new_exec
de_thread
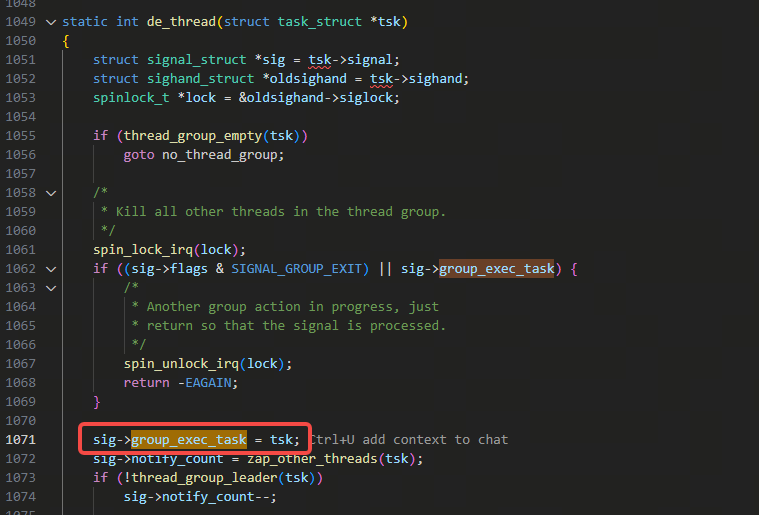
而exec执行期间所引起的segment fault是不处理的,在exec执行完之后会把group_exec_task重新置成NULL:

3.3.6 zap_threads里唤醒非生成core的以外的别的线程
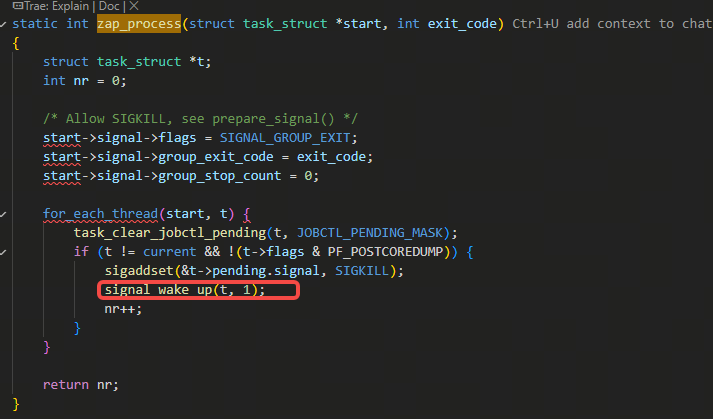
zap_threads里在判断出满足需要进行进程退出逻辑的条件(也就是zap_threads返回值不小于0情况时)会调用下图的zap_process函数,从而调用signal_wake_up函数去唤醒非生成core的以外的别的线程:
3.3.7 总结一下:触发coredump后第一次唤醒其他线程的调用栈
do_coredump
coredump_wait
zap_threads
zap_process
signal_wake_up
signal_wake_up_state
wake_up_state
try_to_wake_up
trace里的接下来的步骤放到之后的"coredump的实验及原理分析二"博文里去展开,虽然这篇博客里在分析上面列出来的coredump_wait时也已经分析了不少细节了。