目录
题目链接:牛客网在线编程_算法笔面试篇_面试TOP101 (nowcoder.com)
前置条件
java
public class ListNode {
int val;
ListNode next = null;
public ListNode(int val) {
this.val = val;
}
}1.反转链表(简单)
题目:

思路:
next用来暂存剩余的链表,pre用来记录反转的链表,head则持续指向next剩余的链表,每次开始循环时,先用next将head剩余的链表暂存,然后将head的下一个节点换成pre,然后将此时的head直接赋值给pre,通过pre间接实现反转
第一次循环后:
next=head.next;(next=2->3)
head.next=pre;(head=1)
pre=head;(pre=1)
head=next;(head=2->3)
第二次循环后:
next=head.next;(next=3)
head.next=pre;(head=2->1)
pre=head;(pre=2->1)
head=next;(head=3)
第三次循环后:
next=head.next;(next=null)
head.next=pre;(head=3->2->1)
pre=head;(pre=3->2->1)
head=next;(head=null)
即:
pre=3->2->1
head=null
next=null
代码:
java
/*
* public class ListNode {
* int val;
* ListNode next = null;
* public ListNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
public ListNode ReverseList (ListNode head) {
ListNode pre=null;
ListNode next=null;
while(head!=null){
next=head.next;
head.next=pre;
pre=head;
head=next;
}
return pre;
}
}2.链表内指定区间反转(中等)

思路:
创建虚拟头节点dummyNode,指向真正的头节点,目的:统一处理边界情况(当m=1时,也能正确反转),pre用于定位到第m个节点的前一个节点,cur永远指向第m个节点(反转部分的第一个节点) ,next用于临时存储cur的下一个节点
| 变量 | 作用 | 类比 |
|---|---|---|
dummyNode |
永远指向虚拟头节点,保证能返回完整链表 | 保险绳 |
pre |
指向反转区间的前一个节点,用于连接 | 锚点 |
cur |
指向当前要处理的节点(反转区间的第一个节点) | 工作指针 |
next |
临时保存cur.next,准备移到前面 | 搬运工 |
开始前先有一点要注意
所有变量共享同一个链表, 在Java中,链表节点是对象引用。这意味着:变量存储的是引用(地址),操作会互相影响
例如:
java
ListNode pre = dummyNode; // pre存储dummyNode的地址
ListNode cur = pre.next; // cur存储dummyNode.next的地址当执行:
java
cur.next = cur.next.next;这实际上修改了节点2的next指针,从指向3改为指向4。
结果所有引用这个链表的变量都会看到变化:
cur:2 → 4 → 5
pre:1 → 2 → 4 → 5 (因为pre.next就是cur指向的节点2)
dummyNode:-1 → 1 → 2 → 4 → 5
流程演示:
初始:
pre=1->2->3->4->5
cur=2->3->4->5
next=null
第一轮循环后:
next=cur.next;(next=3->4->5)
cur.next=cur.next.next;(cur=2->4->5,pre=1->2->4->5)
next.next=pre.next;(next=3->2->4->5)
pre.next=next;(pre=1->3->2->4->5)
bash
1.执行:next=cur.next
dummyNode → 1 → 2 → 3 → 4 → 5
↑ ↑ ↑
pre cur next
2.执行:cur.next = next.next
dummyNode → 1 → 2 → 4 → 5
↑ ↑ ↑
pre cur next(3) ← 3现在"游离"了
next → 3 → 4 → 5
整个链表:dummyNode → 1 → 2 → 4 → 5(此时4被2和3同时指向)
3 ↗
3.执行:next.next = pre.next
dummyNode → 1 → 2 → 4 → 5
↑ ↑
pre cur
next → 3 → 2 → 4 → 5
整个链表:dummyNode → 1 → 2 → 4 → 5(此时2被1和3同时指向)
3 ↗
4.执行:pre.next = next
dummyNode → 1 → 3 → 2 → 4 → 5(1重新指向3,而3不用动,这样又组成了完整的链表)
↑ ↑ ↑
next pre cur第二轮循环后:
next=cur.next;(next=4->5)
cur.next=cur.next.next;(cur=2->5,pre=1->3->2->5)
next.next=pre.next;(next=4->3->2->5)
pre.next=next;(pre=1->4->3->2->5)
...
为什么不直接返回pre?
因为pre的位置变了 :pre在循环中一直在移动,最终指向的是第m-1个节点(这里是节点1,只能说是特殊情况,如果是2,那么就返回的数据不完整了,只有dummyNode始终指向头节点,是完整的)
代码:
java
public class Solution {
public ListNode reverseBetween (ListNode head, int m, int n) {
ListNode dummy=new ListNode(0);
dummy.next=head;
ListNode pre=dummy; // 用于定位到第m个节点的前一个节点
for(int i=1;i<m;i++){
pre=pre.next;
}
//反转n-m次(也可用while)
ListNode cur=pre.next; // cur指向第m个节点(反转部分的第一个节点)
ListNode next; // 用于临时存储
for(int i=0;i<n-m;i++){
next = cur.next; // 1. 保存cur的下一个节点
cur.next = cur.next.next; // 2. cur跳过下一个节点,指向下下个
next.next = pre.next; // 3. 将next插入到pre后面
pre.next = next; // 4. 更新pre的next
}
return dummy.next;
}
}3.链表中的节点每k个一组翻转(中等)
题目:

思路:
跟上一题差不多,差别就在于是多个区间反转,一些代码细节看看就行,前三题都是有关联的,都是区间反转的特殊例子,要仔细归纳,注意dummy、pre、cur、next代表的意义
代码:
java
public class Solution {
public ListNode reverseKGroup (ListNode head, int k) {
//预处理
if(head==null||head.next==null||k<2){
return head;
}
ListNode dummy=new ListNode(0);
dummy.next=head; //dummy 存储完整链表
ListNode pre=dummy; //pre 指向反转区间的前一个节点(这里比较特殊,一开始的区间是[1,k])
ListNode cur=head; // cur 指向当前反转区间的第一个节点
ListNode next; //next 临时保存cur.next,准备移到前面
int len=0;
while(head!=null){
len++;
head=head.next;
}
for(int i=0;i<len/k;i++){
for(int j=1;j<k;j++){
next=cur.next;
cur.next=cur.next.next;
next.next=pre.next;
pre.next=next;
}
pre=cur;
cur=cur.next;
}
return dummy.next;
}
}4.合并两个排序的链表(简单)(递归)
题目:
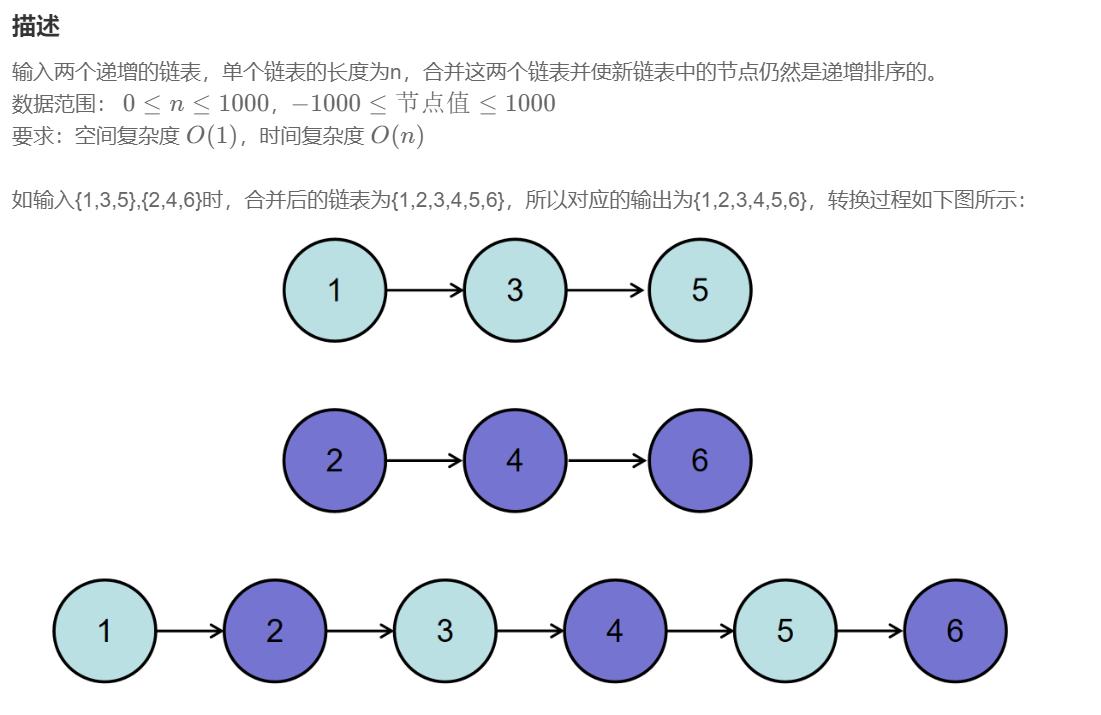
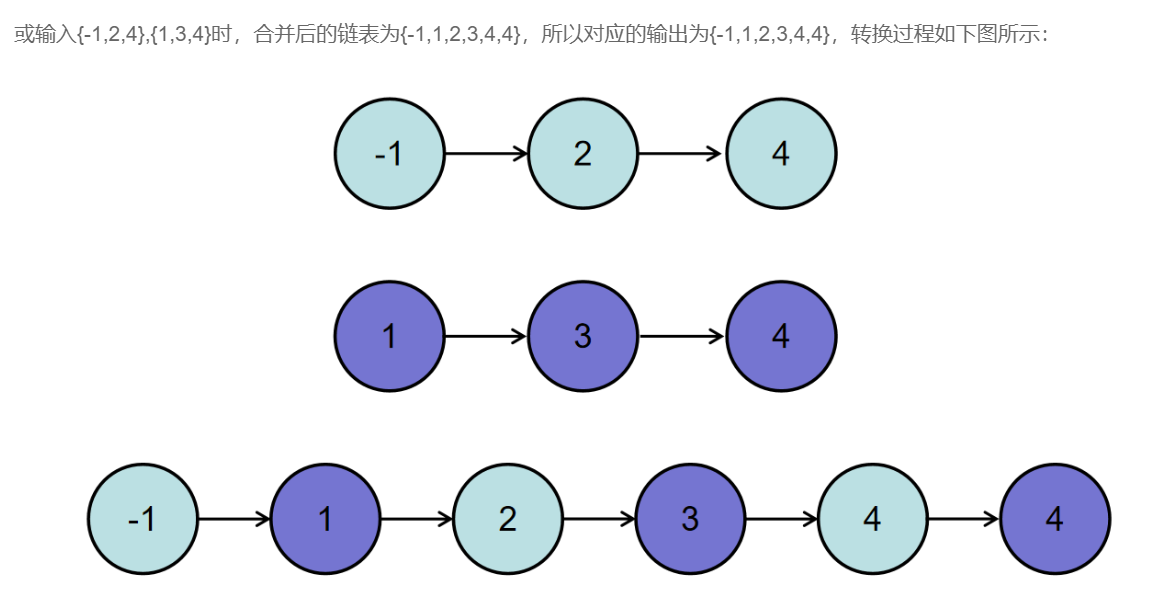

思路:
因为节点的值的大小是排好序的,这道题最简单的方法就是使用递归,当然也可以使用while循环(大部分递归都能转换成循环)
终止条件是某个链表变成null
递归条件是一条链表节点的值比另一条链表节点的值大或者小或者等于,
比如第一条链表的节点的值比另一条链表节点的值小(或者等于),即pHead1.val<=pHead2.val,则第一条链表的next指针则指向递归结果,递归的参数是Merge(pHead1.next,pHead2),表示将第一条链表的节点的下一个节点跟当前第二条链表的节点继续比较,直到递归终止,逐个返回。
可视化流程:
bash
初始状态:
List1: 1 → 3 → 5 → null
List2: 2 → 4 → 6 → null
递归过程:
1.next = Merge(3, 2) // 因为2>1,所以是1.next
2.next = Merge(3, 4) // 因为3>2,所以是2.next
3.next = Merge(5, 4) // 因为4>3,所以是3.next
4.next = Merge(5, 6) // 因为5>4,所以是4.next
5.next = Merge(null, 6) // 因为6>5,所以是5.next
返回6
5.next = 6,返回5 → 6
4.next = 5,返回4 → 5 → 6
3.next = 4,返回3 → 4 → 5 → 6
2.next = 3,返回2 → 3 → 4 → 5 → 6
1.next = 2,返回1 → 2 → 3 → 4 → 5 → 6
最终结果:1 → 2 → 3 → 4 → 5 → 6代码:
java
public class Solution {
public ListNode Merge (ListNode pHead1, ListNode pHead2) {
if(pHead1==null){
return pHead2;
}
if(pHead2==null){
return pHead1;
}
if(pHead1.val<=pHead2.val){
pHead1.next=Merge(pHead1.next,pHead2);
return pHead1;
}else{
pHead2.next=Merge(pHead1,pHead2.next);
return pHead2;
}
}
}5.合并k个已排序的链表(较难)(分治+递归)
题目:
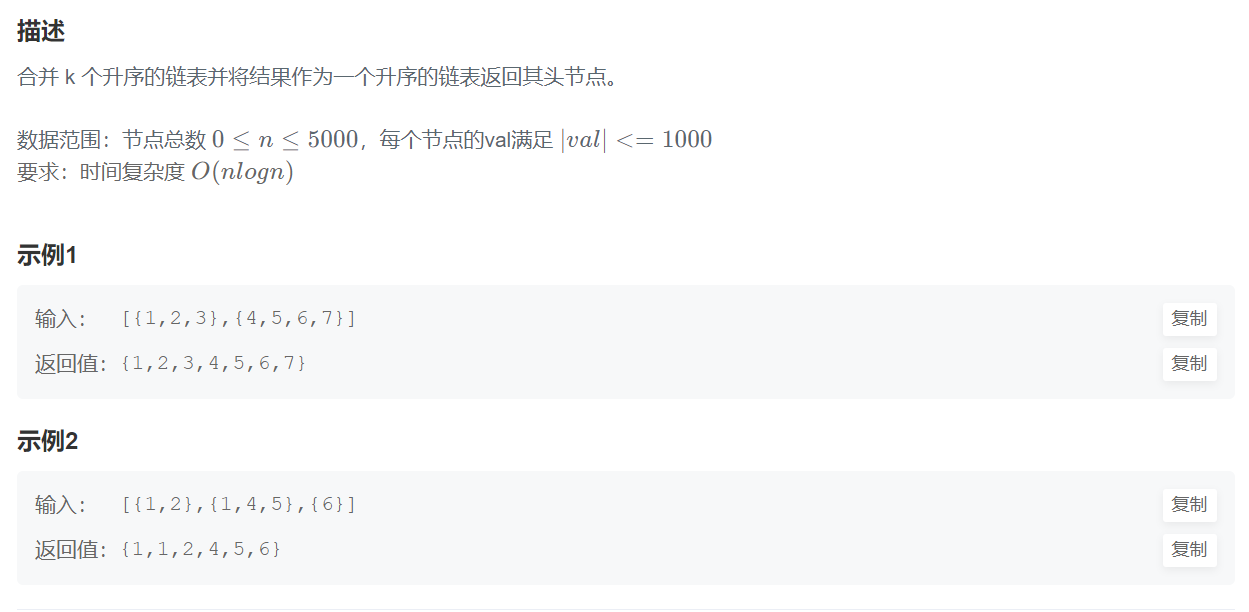
思路一(分治+递归):
这题跟上一题的区别就是从两个链表变成k个不确定的链表,核心思路依然是两两链表递归进行合并,关键就在于如何高效进行两两合并,所以就使用了分治思想
假如有四条链表,流程如下:
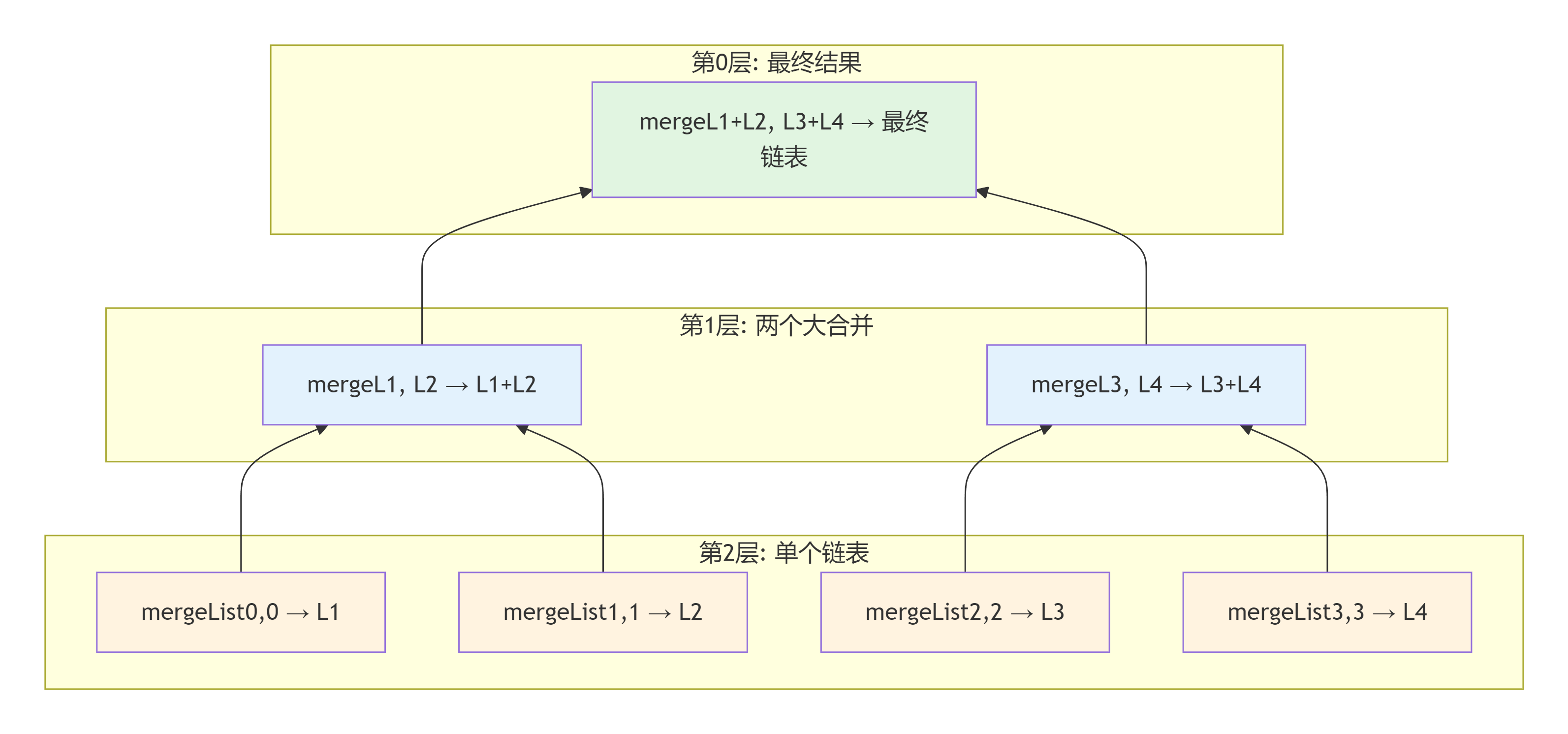
代码一:
java
public class Solution {
public ListNode mergeKLists (ArrayList<ListNode> lists) {
return mergeList(lists, 0, lists.size() - 1);
}
// 分治进行链表两两合并
public ListNode mergeList(ArrayList<ListNode> lists, int l, int r) {
if (l == r) {
return lists.get(l);
}
if (l > r) {
return null;
}
int mid = l + ((r-l) >> 1);
return merge(mergeList(lists, l, mid), mergeList(lists,mid+1,r));
}
// 合并两个链表
public ListNode merge (ListNode pHead1, ListNode pHead2) {
if (pHead1 == null) {
return pHead2;
}
if (pHead2 == null) {
return pHead1;
}
if (pHead1.val <= pHead2.val) {
pHead1.next = merge(pHead1.next, pHead2);
return pHead1;
} else {
pHead2.next = merge(pHead1, pHead2.next);
return pHead2;
}
}
}思路二(优先队列):
先把集合里面所有的链表按头结点的值从小到大的顺序放到优先队列PriorityQueue里,这样每次取出的链表的头结点的值都一定是最小的
定义一个答案链表dummy,其后面用来存储要返回的合并后的链表,定义一个current,用来指向答案链表的下一个节点,准备链接下一个节点
while循环的整个过程,可以理解为从队列头取出一条链表node,取出这个链表的头结点,这个头结点先接到答案链表的后面,然后这个被截断了头的node链表又重新放会优先队列里,直到优先队列里面的链表全部取完,然后直接返回dummy.next即可
流程演示:
假设有三个链表需要合并:
-
List1: 1 → 4 → 7
-
List2: 2 → 5 → 8
-
List3: 3 → 6 → 9

代码二:
java
public class Solution {
public ListNode mergeKLists(ArrayList<ListNode> lists) {
//预处理
if (lists == null || lists.isEmpty()) {
return null;
}
PriorityQueue<ListNode> heap = new PriorityQueue<>(
Comparator.comparingInt(node -> node.val)
);
// 初始化堆
for (ListNode list : lists) {
if (list != null) heap.offer(list);
}
ListNode dummy = new ListNode(0);// 哑节点
ListNode current = dummy;//指向下一个要连接的节点
while (!heap.isEmpty()) {
ListNode node = heap.poll();
current.next = node;
current = current.next;
if (node.next != null) {
heap.offer(node.next);
}
}
return dummy.next;
}
}6.判断链表中是否有环(简单)(快慢指针)
题目:
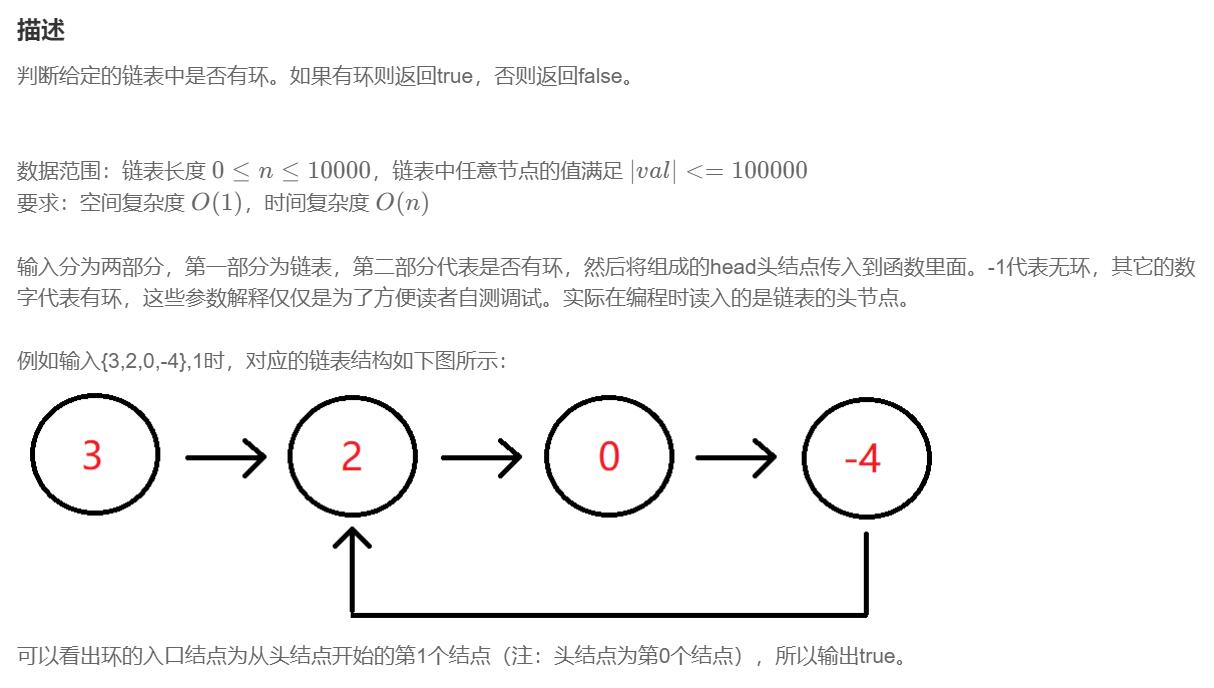

思路:
这题可以直接使用快慢指针,快指针一次走两步,慢指针一次走一步,如果成环,那么快指针一定能追上慢指针,且一定会重合
(因为low一旦进环,可看作fast在后面追赶low的过程,每次两者都接近一步,最后一定能追上)
(可以自己模拟一下,无论奇数还是偶数个节点都是一样的,且不会出现快指针从后面直接越过慢指针的情况,假设发生越过的情况,那么其实就证明越过之前就是重合的状态了~)
代码:
java
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while(fast!=null&&fast.next!=null){
fast=fast.next.next;
slow=slow.next;
if(fast==slow){
return true;
}
}
return false;
}
}7.链表中环的入口结点(中等)(快慢指针+结论)
题目:


思路:
这道题有两个考点,一个是判断是否成环,一个是找出成环入口
第一点看上一题即可,对于第二点,有一个结论:两个指针分别从链表头和相遇点继续出发,每次走一步,最后一定相遇于环入口。
证明过程:(参考评论区大佬链表中环的入口结点_牛客题霸_牛客网 (nowcoder.com))

无论 k 取何值(即无论快指针绕环多少圈),两个指针最终一定在环入口相遇,即使a>c,那么fast可以多走k-1圈,最后也会在入口相遇
代码:
java
public class Solution {
public ListNode EntryNodeOfLoop(ListNode pHead) {
ListNode fast = pHead;
ListNode slow = pHead;
while(fast!=null&&fast.next!=null){
fast=fast.next.next;
slow=slow.next;
if(fast==slow){
break;
}
}
if(fast==null||fast.next==null){
return null;
}
slow=pHead;
while(fast!=slow){
fast=fast.next;
slow=slow.next;
}
return slow;
}
}本篇文章到此结束,如果对你有帮助可以点个赞吗~
个人主页有很多个人总结的 Java、MySQL 等相关的知识,欢迎关注~