一、问题背景
在深度学习训练过程中,特别是使用 GPU 进行联邦学习训练时,经常会遇到 torch.OutOfMemoryError: CUDA out of memory 错误。
1.1 现象发生的可能原因
- 模型较大(如 VGG16、ResNet 等)
- 批次大小(batch_size)过大
- 多个客户端共享模型对象
- 长时间训练导致内存碎片化
- 未及时释放中间变量和缓存
1.2 典型错误信息
bash
torch.OutOfMemoryError: CUDA out of memory.
Tried to allocate 6.12 GiB.
GPU 2 has a total capacity of 44.42 GiB of which 1.67 GiB is free.
Including non-PyTorch memory, this process has 42.74 GiB memory in use.
Of the allocated memory 21.18 GiB is allocated by PyTorch,
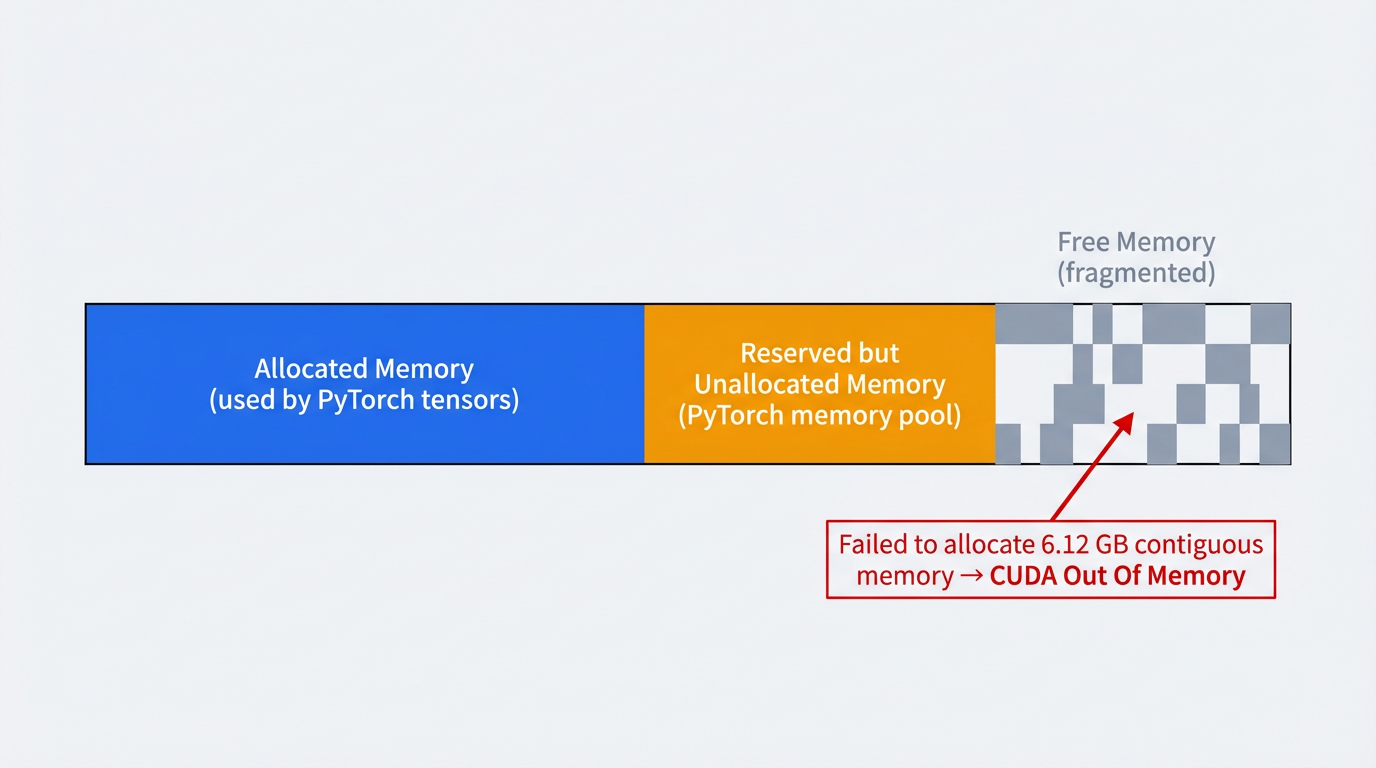
and 21.23 GiB is reserved by PyTorch but unallocated. GPU 显存不足:当前进程已经几乎占满 GPU 显存,PyTorch 尝试再分配一块 6.12 GiB 的显存时失败。
| 项目 | 显存 |
|---|---|
| GPU 总显存 | 44.42 GiB |
| 当前可用 | 1.67 GiB |
| 进程占用总量 | 42.74 GiB |
| PyTorch 实际使用 | 21.18 GiB |
| PyTorch 缓存预留 | 21.23 GiB |
| 本次尝试申请 | 6.12 GiB ❌ |
- 该 OOM 错误表明,尽管 GPU 总显存仍有少量空闲,但由于 PyTorch 显存缓存机制与当前显存碎片化,无法再为新的计算分配一块连续的 6.12 GiB 显存,从而触发 CUDA out of memory 错误。
二、CUDA 内存不足的原因分析
2.1 内存分配问题
-
问题描述:
- PyTorch 使用内存池(memory pool)管理 GPU 内存
- 当内存碎片化严重时,即使有足够的空闲内存,也可能无法分配连续的大块内存
-
原因:
- 频繁的小块内存分配和释放
- 未及时清理缓存
- 多个模型实例同时占用内存
2.2 批次大小过大
-
问题描述:
batch_size过大导致单次前向传播需要大量显存- VGG16 模型在 224 × 224 224 \times 224 224×224 输入下,每个样本约需 12 − 15 M B 12-15 MB 12−15MB 显存
batch_size=512需要约 6 − 7.5 G B 6-7.5 GB 6−7.5GB 显存(仅前向传播)
-
计算公式:
KaTeX parse error: Expected 'EOF', got '_' at position 30: ...} = \text{batch_̲size} \times \t...
2.3 模型对象共享
问题描述:
- 多个客户端共享同一个模型对象引用
- 在联邦学习中,所有客户端同时训练会导致内存累积
- 模型参数的梯度信息会占用额外内存
2.4 计算图保留
问题描述:
- 默认情况下,PyTorch 会保留计算图用于反向传播
- 在计算参数差异时,如果不需要梯度,应该使用
torch.no_grad()
三、解决方案概述
我们的解决方案采用多层次的内存优化策略:
-
环境变量优化 - 减少内存碎片
-
批次大小调整 - 降低单次内存需求
-
模型副本管理 - 避免共享对象导致的内存累积
-
主动内存清理 - 及时释放不需要的内存
-
计算图优化 - 避免不必要的梯度计算
3.1 环境变量优化
-
方法:
在脚本开头设置环境变量,优化 CUDA 内存分配策略:
pythonimport os # 优化 CUDA 内存分配,避免内存碎片 os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'expandable_segments:True' -
作用:
expandable_segments:True允许内存段动态扩展,减少内存碎片- 提高内存利用率,避免"有内存但无法分配"的情况
3.2 批次大小调整
根据模型大小和 GPU 显存容量选择合适的 batch_size:
python
conf = {
"batch_size": 32,
# VGG16 + 224x224: 推荐 16-64
# ResNet50 + 224x224: 推荐 32-128
# 小型模型: 可以更大
}(1) 选择原则
- 大型模型(VGG16, ResNet50): 16-64
- 中型模型(ResNet18): 32-128
- 小型模型(MobileNet): 64-256
- 输入尺寸: 224x224 使用较小值,32x32 可以使用较大值
(2)内存估算
python
# 粗略估算公式
estimated_memory = batch_size * input_size * channels * 4 bytes * 3
# 3 倍包括:输入、梯度、优化器状态3.3 模型副本管理
为每个客户端创建独立的模型实例,避免共享对象:
python
from torchvision import models
import torch.nn as nn
# 为每个客户端创建独立的模型副本
client_model = models.vgg16(weights=None)
# 修改分类层
in_features = client_model.classifier[6].in_features
client_model.classifier[6] = nn.Linear(in_features, num_classes)
# 复制参数(不共享对象)
client_model.load_state_dict(server.global_model.state_dict())
client_model = client_model.to(device)(1)关键点
- ✅ 正确做法: 创建新模型实例,只复制参数
- ❌ 错误做法 : 使用
copy.deepcopy()或直接共享模型对象
(2)内存对比
- 共享模型对象:所有客户端共享同一份模型内存 + 梯度内存累积
- 独立模型副本:每个客户端独立内存,训练完成后可释放
3.4 主动内存清理
在关键位置主动清理 GPU 缓存,但是需要注意频繁调用 empty_cache() 会引入同步开销,不建议在每个 batch 调用。
(1) 训练循环中的清理
python
for batch_id, (imgs, labels) in enumerate(self.train_loader):
data, target = imgs.to(self.device), labels.to(self.device)
optimizer.zero_grad()
output = self.local_model(data)
loss = loss_func(output, target)
loss.backward()
optimizer.step()
# 清理中间变量释放内存
del data, target, output, loss
# 定期清理缓存
if (batch_id + 1) % 10 == 0:
if torch.cuda.is_available():
torch.cuda.empty_cache()- 清理时机:
- 每个批次后删除中间变量
- 每 N 个批次清理一次缓存(N=10 或根据内存情况调整)
- 客户端训练完成后清理
(2) 参数差异计算优化
python
# 使用 no_grad 避免保存计算图
with torch.no_grad():
diff = dict()
for name, data in self.local_model.state_dict().items():
global_data = global_model.state_dict()[name]
# 移到 CPU 避免 GPU 内存累积
diff[name] = (data - global_data).cpu()
# 清理 GPU 缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()- 优化点:
torch.no_grad(): 不保存计算图,节省内存.cpu(): 将结果移到 CPU,释放 GPU 内存- 计算完成后立即清理缓存
(2) 模型聚合优化
python
def model_aggregate(self, weight_accumulator):
with torch.no_grad():
for name, data in self.global_model.state_dict().items():
# 确保张量在正确的设备上
if isinstance(weight_accumulator[name], torch.Tensor):
update_per_layer = weight_accumulator[name].to(data.device) * self.conf["lambda"]
else:
update_per_layer = weight_accumulator[name] * self.conf["lambda"]
data.add_(update_per_layer)
# 清理 GPU 缓存
if torch.cuda.is_available():
torch.cuda.empty_cache()3.5 内存监控
添加内存监控代码,便于调试和优化:
python
if torch.cuda.is_available():
device_id = 2
torch.cuda.set_device(device_id)
device = torch.device(f'cuda:{device_id}')
# 清理 GPU 缓存
torch.cuda.empty_cache()
# 显示内存使用情况
allocated = torch.cuda.memory_allocated(device_id) / 1024**3
total = torch.cuda.get_device_properties(device_id).total_memory / 1024**3
print(f"GPU 内存使用情况: {allocated:.2f} GB / {total:.2f} GB")四、最佳实践
4.1 批次大小选择
python
# 根据 GPU 显存选择 batch_size
gpu_memory_gb = torch.cuda.get_device_properties(0).total_memory / 1024**3
if gpu_memory_gb >= 24: # RTX 3090, A100 等
batch_size = 64
elif gpu_memory_gb >= 12: # RTX 3060, V100 等
batch_size = 32
else: # GTX 1080 等
batch_size = 164.2 梯度累积(Gradient Accumulation)
当显存不足但需要大批次训练时,使用梯度累积:
python
accumulation_steps = 4 # 累积 4 个批次
effective_batch_size = batch_size * accumulation_steps
for batch_id, (data, target) in enumerate(train_loader):
output = model(data)
loss = criterion(output, target) / accumulation_steps
loss.backward()
if (batch_id + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
torch.cuda.empty_cache()4.3 混合精度训练(Mixed Precision)
使用 FP16 可以显著减少显存占用:
python
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for data, target in train_loader:
optimizer.zero_grad()
with autocast():
output = model(data)
loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()4.4 检查点机制(Checkpointing)
对于非常大的模型,可以使用梯度检查点:
python
from torch.utils.checkpoint import checkpoint
# 在前向传播中使用检查点
output = checkpoint(model, input)4.5 内存清理检查清单
在以下位置添加内存清理:
✅ 每个训练批次后删除中间变量
✅ 每个客户端训练完成后清理缓存
✅ 模型聚合后清理缓存
✅ 评估前清理缓存
✅ 使用 torch.no_grad() 进行不需要梯度的计算
五、故障排查
问题 1: 仍然出现内存不足
可能原因:
batch_size仍然太大- 模型太大
- 多个进程共享 GPU
解决方案:
python
# 1. 进一步减小 batch_size
conf["batch_size"] = 16 # 或更小
# 2. 使用梯度累积
# 3. 使用混合精度训练
# 4. 检查是否有其他进程占用 GPU
nvidia-smi # 查看 GPU 使用情况问题 2: 内存清理后仍然占用大量内存
可能原因:
- PyTorch 的内存池机制会保留已分配的内存
- 这是正常现象,不影响使用
解决方案:
python
# 如果需要强制释放,可以重启 Python 进程
# 或者在代码中定期重置
torch.cuda.empty_cache()
torch.cuda.ipc_collect() # 收集 IPC 资源问题 3: 训练速度变慢
可能原因:
- 频繁的内存清理会影响性能
batch_size太小
解决方案:
python
# 1. 减少清理频率
if (batch_id + 1) % 50 == 0: # 改为每 50 个批次清理一次
torch.cuda.empty_cache()
# 2. 在非关键路径清理
# 3. 使用更大的 batch_size(如果内存允许)问题 4: 多 GPU 训练时的内存问题
解决方案:
python
# 使用 DataParallel 或 DistributedDataParallel
if torch.cuda.device_count() > 1:
model = torch.nn.DataParallel(model)
# 注意:batch_size 会按 GPU 数量自动分配六、代码示例总结
6.1 完整的客户端训练代码示例
python
def local_train(self, global_model):
# 1. 复制模型参数(使用 no_grad)
with torch.no_grad():
self.local_model.load_state_dict(global_model.state_dict())
# 2. 初始化优化器
optimizer = torch.optim.SGD(self.local_model.parameters(), lr=0.001)
loss_func = torch.nn.CrossEntropyLoss()
# 3. 训练循环
self.local_model.train()
for epoch in range(self.conf["local_epochs"]):
for batch_id, (imgs, labels) in enumerate(self.train_loader):
# 数据移动到设备
data, target = imgs.to(self.device), labels.to(self.device)
# 前向传播和反向传播
optimizer.zero_grad()
output = self.local_model(data)
loss = loss_func(output, target)
loss.backward()
optimizer.step()
# 清理中间变量
del data, target, output, loss
# 定期清理缓存
if (batch_id + 1) % 10 == 0:
torch.cuda.empty_cache()
# 4. 计算参数差异(移到 CPU)
with torch.no_grad():
diff = dict()
for name, data in self.local_model.state_dict().items():
diff[name] = (data - global_model.state_dict()[name]).cpu()
# 5. 最终清理
torch.cuda.empty_cache()
return diff