引言:不确定性的数学语言
在我们生活的世界中,不确定性无处不在。明日的天气、股票的涨跌、用户的点击行为------这些现象都包含着固有的随机性。概率论为我们提供了一套严谨的数学工具来描述和分析这种不确定性,而随机变量正是这套工具的核心概念。
随机变量本质上是一个函数,它将随机试验的结果映射到实数。通过这种方式,我们可以用数值来描述随机现象,进而应用数学分析工具进行研究。理解随机变量及其分布,不仅是掌握概率论与统计学的基础,更是深入学习机器学习、金融工程、信号处理等现代学科的关键。
一、离散型随机变量:可数的可能性
离散型随机变量的取值是可数的------要么有限,要么可数无限。这类随机变量常用于描述计数型问题,如抛硬币的结果、网站访问量等。
对于离散型随机变量X,我们使用概率质量函数 来描述其分布:
P ( X = x ) = p ( x ) P(X = x) = p(x) P(X=x)=p(x)
其中 p ( x ) p(x) p(x)表示X取特定值x的概率。概率质量函数满足两个基本性质:
- 非负性: 0 ≤ p ( x ) ≤ 1 0 \leq p(x) \leq 1 0≤p(x)≤1 对所有x成立
- 归一性: ∑ x p ( x ) = 1 \sum_{x} p(x) = 1 ∑xp(x)=1
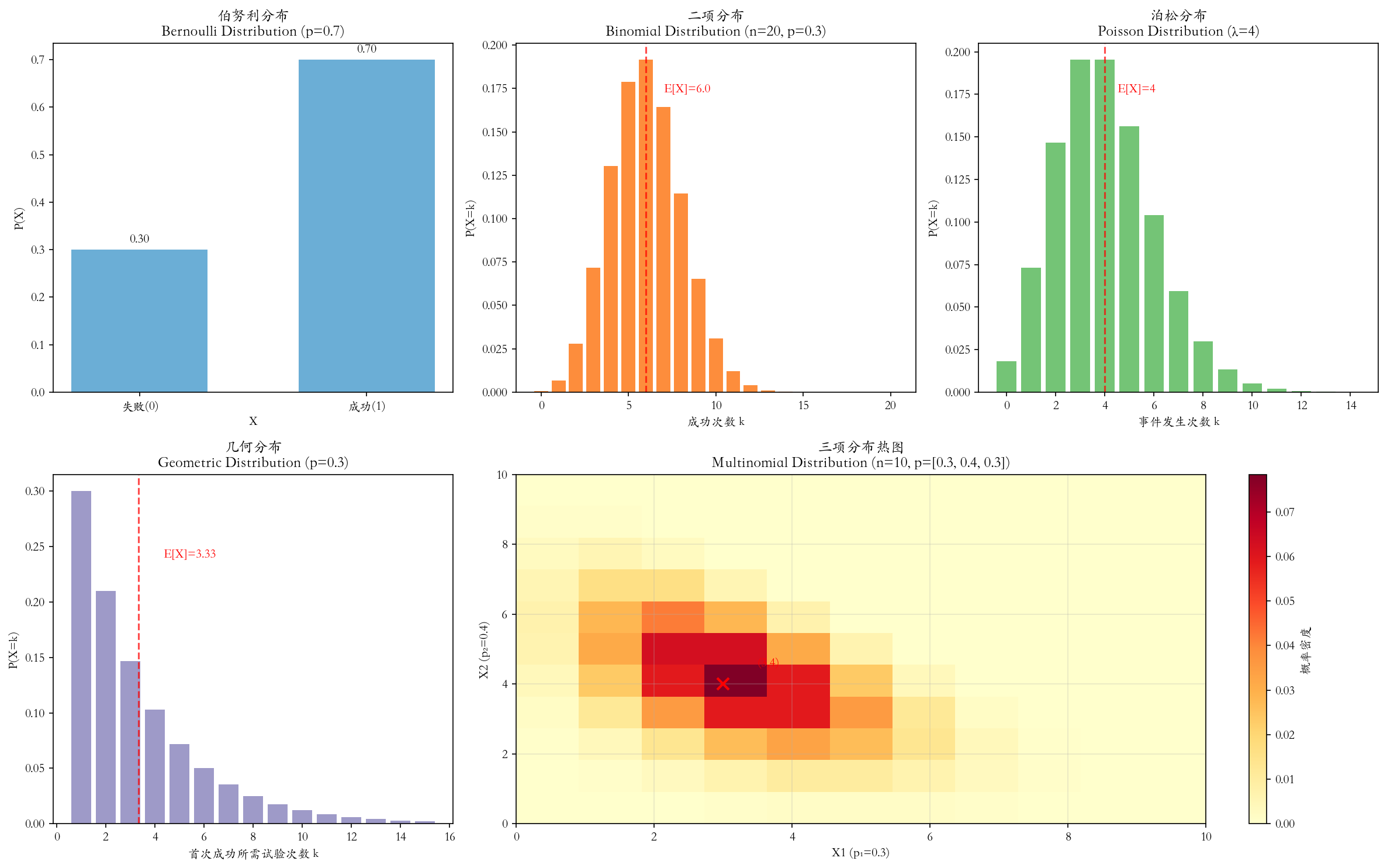
| 分布名称 | 描述与定义 | 概率质量函数 | 关键参数 | 期望 E X EX EX | 方差 V a r ( X ) Var(X) Var(X) |
|---|---|---|---|---|---|
| 伯努利分布 | 描述单次 随机试验,结果只有两种(成功/失败)。 是0-1分布。 | P ( X = 1 ) = p P(X=1) = p P(X=1)=p P ( X = 0 ) = 1 − p P(X=0) = 1-p P(X=0)=1−p | p p p:单次试验中成功的概率 | p p p | p ( 1 − p ) p(1-p) p(1−p) |
| 二项分布 | 描述n次独立 的伯努利试验中,成功次数 的分布。 (伯努利分布的推广) | P ( X = k ) = ( n k ) p k ( 1 − p ) n − k P(X=k) = \binom{n}{k} p^k (1-p)^{n-k} P(X=k)=(kn)pk(1−p)n−k 其中 k = 0 , 1 , ... , n k = 0, 1, \ldots, n k=0,1,...,n | n n n:试验总次数 p p p:单次成功概率 | n p np np | n p ( 1 − p ) np(1-p) np(1−p) |
| 多项分布 | 描述n次独立 试验中,多种可能结果 出现次数的联合分布 。 (二项分布向多元的推广) | P ( X 1 = x 1 , ... , X k = x k ) = n ! x 1 ! ⋯ x k ! p 1 x 1 ⋯ p k x k P(X_1=x_1, \ldots, X_k=x_k) = \frac{n!}{x_1! \cdots x_k!} p_1^{x_1} \cdots p_k^{x_k} P(X1=x1,...,Xk=xk)=x1!⋯xk!n!p1x1⋯pkxk 约束: ∑ i = 1 k x i = n \sum_{i=1}^k x_i = n ∑i=1kxi=n, ∑ i = 1 k p i = 1 \sum_{i=1}^k p_i = 1 ∑i=1kpi=1 | n n n:试验总次数 p 1 , ... , p k p_1, \ldots, p_k p1,...,pk:各类别发生的概率 | E X i = n p i EX_i = np_i EXi=npi | V a r ( X i ) = n p i ( 1 − p i ) Var(X_i) = np_i(1-p_i) Var(Xi)=npi(1−pi) C o v ( X i , X j ) = − n p i p j Cov(X_i, X_j) = -np_i p_j Cov(Xi,Xj)=−npipj |
| 泊松分布 | 描述在固定时间或空间 内,稀有事件 发生次数 的分布。 (二项分布当n很大p很小时的极限) | P ( X = k ) = λ k e − λ k ! P(X=k) = \frac{\lambda^k e^{-\lambda}}{k!} P(X=k)=k!λke−λ 其中 k = 0 , 1 , 2 , ... k = 0, 1, 2, \ldots k=0,1,2,... | λ \lambda λ:单位时间/空间内事件发生的平均次数(速率) | λ \lambda λ | λ \lambda λ |
| 几何分布 | 描述在一系列独立伯努利试验 中,首次获得成功 所需的试验次数。 | P ( X = k ) = ( 1 − p ) k − 1 p P(X=k) = (1-p)^{k-1} p P(X=k)=(1−p)k−1p 其中 k = 1 , 2 , 3 , ... k = 1, 2, 3, \ldots k=1,2,3,... | p p p:单次试验成功的概率 | 1 p \frac{1}{p} p1 | 1 − p p 2 \frac{1-p}{p^2} p21−p |
二、连续型随机变量:连续的可能性
连续型随机变量的取值充满一个或多个区间,不可数。这类随机变量常用于描述测量型问题,如人的身高、温度变化等。对于连续型随机变量X,我们使用概率密度函数 f ( x ) f(x) f(x)来描述其分布。与离散情形不同,连续型随机变量取某个特定值的概率为0,我们关注的是它落在某个区间的概率:
P ( a ≤ X ≤ b ) = ∫ a b f ( x ) d x P(a \leq X \leq b) = \int_a^b f(x) dx P(a≤X≤b)=∫abf(x)dx
概率密度函数满足:
- 非负性: f ( x ) ≥ 0 f(x) \geq 0 f(x)≥0 对所有x成立
- 归一性: ∫ − ∞ ∞ f ( x ) d x = 1 \int_{-\infty}^{\infty} f(x) dx = 1 ∫−∞∞f(x)dx=1
常见连续分布
均匀分布 描述在区间a,b上取值可能性相同的情况:
f ( x ) = { 1 b − a , a ≤ x ≤ b 0 , 其他 f(x) = \begin{cases} \frac{1}{b-a}, & a \leq x \leq b \\ 0, & \text{其他} \end{cases} f(x)={b−a1,0,a≤x≤b其他
正态分布 (高斯分布)是最重要的连续分布,呈钟形曲线:
f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(x-\mu)^2}{2\sigma^2}} f(x)=2π σ1e−2σ2(x−μ)2
其中μ是均值,σ是标准差。
指数分布 描述事件发生的时间间隔,具有无记忆性:
f ( x ) = { λ e − λ x , x ≥ 0 0 , x < 0 f(x) = \begin{cases} \lambda e^{-\lambda x}, & x \geq 0 \\ 0, & x < 0 \end{cases} f(x)={λe−λx,0,x≥0x<0
三、分布函数:统一的描述框架
累积分布函数 为离散型和连续型随机变量提供了一个统一的描述框架。随机变量X的分布函数定义为:
F ( x ) = P ( X ≤ x ) F(x) = P(X \leq x) F(x)=P(X≤x)
分布函数具有以下关键性质:
- 单调不减 :如果 x 1 < x 2 x_1 < x_2 x1<x2,则 F ( x 1 ) ≤ F ( x 2 ) F(x_1) \leq F(x_2) F(x1)≤F(x2)
- 有界性 : lim x → − ∞ F ( x ) = 0 \lim_{x \to -\infty} F(x) = 0 limx→−∞F(x)=0, lim x → ∞ F ( x ) = 1 \lim_{x \to \infty} F(x) = 1 limx→∞F(x)=1
- 右连续性 : F ( x ) = lim h → 0 + F ( x + h ) F(x) = \lim_{h \to 0^+} F(x+h) F(x)=limh→0+F(x+h)
对于连续型随机变量,分布函数与密度函数的关系为:
F ( x ) = ∫ − ∞ x f ( t ) d t , f ( x ) = d d x F ( x ) ( 在 f 连续的点 ) F(x) = \int_{-\infty}^x f(t) dt, \quad f(x) = \frac{d}{dx} F(x) \ (\text{在}f\text{连续的点}) F(x)=∫−∞xf(t)dt,f(x)=dxdF(x) (在f连续的点)
四、多维随机变量与联合分布
现实世界中的问题往往涉及多个随机变量。两个随机变量X和Y的联合分布函数 定义为:
F ( x , y ) = P ( X ≤ x , Y ≤ y ) F(x,y) = P(X \leq x, Y \leq y) F(x,y)=P(X≤x,Y≤y)
对于离散型随机变量,我们使用联合概率质量函数 :
p ( x , y ) = P ( X = x , Y = y ) p(x,y) = P(X=x, Y=y) p(x,y)=P(X=x,Y=y)
对于连续型随机变量,我们使用联合概率密度函数 f ( x , y ) f(x,y) f(x,y),满足:
P ( ( X , Y ) ∈ A ) = ∬ A f ( x , y ) d x d y P((X,Y) \in A) = \iint_A f(x,y) dx dy P((X,Y)∈A)=∬Af(x,y)dxdy
五、边缘分布与条件分布
边缘分布:从联合到部分
从联合分布中可以提取单个变量的分布,称为边缘分布:
- 离散情形: p X ( x ) = ∑ y p ( x , y ) p_X(x) = \sum_y p(x,y) pX(x)=∑yp(x,y)
- 连续情形: f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y f_X(x) = \int_{-\infty}^{\infty} f(x,y) dy fX(x)=∫−∞∞f(x,y)dy
条件分布:已知部分信息下的分布
给定一个随机变量的值时,另一个随机变量的分布称为条件分布 。对于离散情形,给定Y=y时X的条件分布为:
P ( X = x ∣ Y = y ) = p ( x , y ) p Y ( y ) , 如果 p Y ( y ) > 0 P(X=x | Y=y) = \frac{p(x,y)}{p_Y(y)}, \quad \text{如果}p_Y(y)>0 P(X=x∣Y=y)=pY(y)p(x,y),如果pY(y)>0
对于连续情形,给定Y=y时X的条件密度为:
f X ∣ Y ( x ∣ y ) = f ( x , y ) f Y ( y ) , 如果 f Y ( y ) > 0 f_{X|Y}(x|y) = \frac{f(x,y)}{f_Y(y)}, \quad \text{如果}f_Y(y)>0 fX∣Y(x∣y)=fY(y)f(x,y),如果fY(y)>0
条件分布是贝叶斯统计和机器学习中许多算法的核心概念。
六、随机变量的独立性
两个随机变量X和Y独立 ,当且仅当它们的联合分布可以分解为各自边缘分布的乘积:
P ( X ≤ x , Y ≤ y ) = P ( X ≤ x ) ⋅ P ( Y ≤ y ) P(X \leq x, Y \leq y) = P(X \leq x) \cdot P(Y \leq y) P(X≤x,Y≤y)=P(X≤x)⋅P(Y≤y)
等价地:
- 离散情形: p ( x , y ) = p X ( x ) ⋅ p Y ( y ) p(x,y) = p_X(x) \cdot p_Y(y) p(x,y)=pX(x)⋅pY(y)
- 连续情形: f ( x , y ) = f X ( x ) ⋅ f Y ( y ) f(x,y) = f_X(x) \cdot f_Y(y) f(x,y)=fX(x)⋅fY(y)
独立性的一个重要推论是:如果X和Y独立,则任何基于X的函数与任何基于Y的函数也独立。
七、链式法则与全概率公式
链式法则:分解联合分布
对于多个随机变量,联合分布可以通过条件分布逐步分解:
P ( X 1 , X 2 , ... , X n ) = P ( X 1 ) ⋅ P ( X 2 ∣ X 1 ) ⋅ P ( X 3 ∣ X 1 , X 2 ) ⋯ P ( X n ∣ X 1 , ... , X n − 1 ) P(X_1, X_2, \ldots, X_n) = P(X_1) \cdot P(X_2|X_1) \cdot P(X_3|X_1,X_2) \cdots P(X_n|X_1,\ldots,X_{n-1}) P(X1,X2,...,Xn)=P(X1)⋅P(X2∣X1)⋅P(X3∣X1,X2)⋯P(Xn∣X1,...,Xn−1)
这一公式在概率图模型和序列建模中有重要应用。
全概率公式:从条件到边缘
全概率公式是处理复杂概率问题的强大工具,它将一个事件的概率分解为在不同条件下该事件发生的概率之和:
P ( A ) = ∑ i P ( A ∣ B i ) P ( B i ) P(A) = \sum_i P(A | B_i) P(B_i) P(A)=i∑P(A∣Bi)P(Bi)
其中 { B i } \{B_i\} {Bi}构成一个完备事件组(互斥且并集为整个样本空间)。
在随机变量的语境下,全概率公式表现为:
- 离散情形: P ( X = x ) = ∑ y P ( X = x ∣ Y = y ) P ( Y = y ) P(X=x) = \sum_y P(X=x|Y=y) P(Y=y) P(X=x)=∑yP(X=x∣Y=y)P(Y=y)
- 连续情形: f X ( x ) = ∫ − ∞ ∞ f X ∣ Y ( x ∣ y ) f Y ( y ) d y f_X(x) = \int_{-\infty}^{\infty} f_{X|Y}(x|y) f_Y(y) dy fX(x)=∫−∞∞fX∣Y(x∣y)fY(y)dy
全概率公式与条件概率公式 P ( X = x ∣ Y = y ) = p ( x , y ) / p Y ( y ) P(X=x|Y=y) = p(x,y)/p_Y(y) P(X=x∣Y=y)=p(x,y)/pY(y)构成完美的对偶关系:一个用于"分解",一个用于"合成"。
八、数字特征:分布的量化描述
虽然分布函数完整地描述了随机变量的统计规律,但数字特征提供了更简洁的量化描述。
期望:分布的中心
期望是随机变量的"平均值",反映了分布的中心位置:
- 离散: E X = ∑ x x ⋅ p ( x ) EX = \sum_x x \cdot p(x) EX=∑xx⋅p(x)
- 连续: E X = ∫ − ∞ ∞ x f ( x ) d x EX = \int_{-\infty}^{\infty} x f(x) dx EX=∫−∞∞xf(x)dx
方差:分布的离散程度
方差衡量随机变量取值与其期望的偏离程度:
V a r ( X ) = E ( X − E \[ X ) 2 ] = E X 2 − ( E X ) 2 Var(X) = E(X - E\[X)^2] = EX\^2 - (EX)^2 Var(X)=E(X−E\[X)2]=EX2−(EX)2
协方差与相关系数:变量间的关系
协方差衡量两个随机变量之间的线性关系:
C o v ( X , Y ) = E ( X − E \[ X ) ( Y − E Y ) ] Cov(X,Y) = E(X - E\[X)(Y - EY)] Cov(X,Y)=E(X−E\[X)(Y−EY)]
相关系数是标准化的协方差,取值在-1到1之间:
ρ X Y = C o v ( X , Y ) V a r ( X ) V a r ( Y ) \rho_{XY} = \frac{Cov(X,Y)}{\sqrt{Var(X)Var(Y)}} ρXY=Var(X)Var(Y) Cov(X,Y)
九、极限定理:大数定律与中心极限定理
大数定律:频率的稳定性
大数定律表明,当试验次数足够多时,样本均值以概率收敛于期望值:
1 n ∑ i = 1 n X i → P E X \frac{1}{n} \sum_{i=1}^n X_i \xrightarrow{P} EX n1i=1∑nXiP EX
这为用频率估计概率提供了理论依据。
中心极限定理:正态分布的普遍性
中心极限定理是统计学中最重要的定理之一,它表明独立同分布随机变量和的标准化形式依分布收敛于标准正态分布:
∑ i = 1 n X i − n μ σ n → d N ( 0 , 1 ) \frac{\sum_{i=1}^n X_i - n\mu}{\sigma\sqrt{n}} \xrightarrow{d} N(0,1) σn ∑i=1nXi−nμd N(0,1)
这解释了正态分布在自然界和社会现象中的普遍性。
十、在机器学习中的应用
随机变量及其分布在机器学习中有着广泛而深入的应用:
概率图模型
贝叶斯网络和马尔可夫随机场等概率图模型建立在随机变量及其条件独立性假设之上,用于表示复杂的概率关系。
生成模型
变分自编码器、生成对抗网络、扩散模型等生成模型都需要对随机变量的分布进行建模,以生成新的数据样本。
贝叶斯推断
贝叶斯方法通过先验分布和似然函数得到后验分布,实现了从数据中学习参数分布的过程:
P ( θ ∣ D ) = P ( D ∣ θ ) P ( θ ) P ( D ) P(\theta|D) = \frac{P(D|\theta)P(\theta)}{P(D)} P(θ∣D)=P(D)P(D∣θ)P(θ)
强化学习
在强化学习中,状态、动作和奖励都可以建模为随机变量,策略学习本质上是对这些随机变量分布的学习和优化。
总结与展望
随机变量及其分布构成了概率论与统计学的核心框架,为我们描述和分析不确定性提供了统一的数学语言。从简单的伯努利试验到复杂的联合分布,从离散计数到连续测量,这一理论体系不断发展完善,成为现代数据科学和机器学习的基石。
关键要点回顾:
- 离散与连续是随机变量的两种基本类型,分别用概率质量函数和概率密度函数描述
- 分布函数提供了统一的概率计算框架
- 联合分布、边缘分布与条件分布共同描述了多个随机变量之间的关系
- 独立性简化了复杂系统的分析
- 链式法则与全概率公式是处理条件概率问题的基本工具
- 数字特征提供了分布的简洁量化描述
- 极限定理揭示了大量随机现象背后的统计规律
现代扩展与发展:
- 混合分布如高斯混合模型,能够描述复杂多模态数据
- 非参数方法如核密度估计,不假设特定分布形式
- 随机过程研究随时间演化的随机变量序列
- 高维统计处理现代数据科学中的高维随机变量
随机变量理论仍在不断发展,特别是在高维统计、非参数贝叶斯方法和深度学习等领域。深入理解这些基础概念,不仅有助于掌握经典统计方法,也为学习现代机器学习算法奠定了坚实基础。
在数据驱动的时代,随机变量及其分布的理论框架将继续为我们提供分析不确定性、提取数据洞见、构建预测模型的有力工具。无论是理论研究还是实际应用,这一领域都充满着挑战与机遇。