当我们开始思考3D数据或视频时,一个很自然的想法就是把它们视为一系列2D帧,然后通过简单地把时间作为额外维度来应用同样的模型。
从直觉上看,这种方法似乎可行,但实际上它很快会遇到瓶颈。随着输入变得更高维,模型通常需要变得更大才能表现良好。这导致内存使用增加、计算成本上升,训练也更难稳定,尤其是在GPU资源有限的情况下。
对于像视频生成这样的任务,这个问题变得更加严重。视频中的帧并不是独立的,它们在时间上紧密相连。由于这种强烈的时间依赖性,单一的生成模型很难同时学会物体的外观和运动方式。
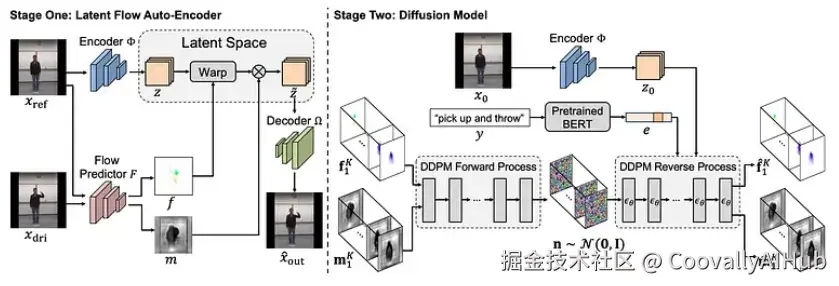
在这篇文章中,将介绍隐式流扩散模型,这是一个为应对上述挑战而设计的两阶段框架。第一阶段专注于学习像素级的空间关系,而第二阶段则建模视频帧之间的时间依赖性。
到文章结尾,你将看到LFDM如何用于在MHAD数据集上进行条件式的图像到视频生成,并配有PyTorch的实战代码实现。
隐式流扩散模型的核心思想
正如前文提到的,视频之所以难以建模,是因为空间外观和时间运动高度纠缠。当扩散模型直接在像素空间逐帧生成视频时,结果往往不稳定,导致闪烁、物体形状扭曲或帧间突然不一致。
与其直接生成视频,LFDM采用了一种不同的策略:通过光流来建模运动。在第一阶段,模型被训练来预测源帧和目标帧之间的光流。然后,这个流被用来扭曲源帧,从而生成对应的目标帧。
给定一个源帧 x0,我们可以进一步训练一个扩散模型来生成一系列光流,例如 flow(x0, x1), flow(x0, x2)......通过用这些预测的流来扭曲同一个源帧 x0,就可以合成并组装出连贯的未来帧。
因为所有帧都是由同一张源图像变形生成的,空间结构保持一致,并且运动随时间演化更平滑。这使得扩散模型可以专注于学习运动动态,而非细节外观,让学习问题变得更简单,生成的视频也更稳定。
LFDM背后的另一个关键思想是:光流是在隐式空间而不是直接在像素级应用的。这显著降低了内存使用和计算成本。在我的实验中,源帧被缩放到128×128,并编码成32×32的隐式特征。模型预测一个流场来扭曲这个隐式表示,然后解码器将扭曲后的隐式表示重建为目标帧。
- 阶段一:隐式流自编码器
- 训练一个自编码器,将源帧编码到隐式空间,并将经过流扭曲的隐式表示解码回图像。
- 训练一个流预测器,用于估计源帧和目标帧之间在隐式空间(32×32)的光流。
- 阶段二:扩散模型

- 使用第一阶段训练好的流预测器,从一个固定的源帧 x0 生成一系列隐式光流(如上图所示)。
- 使用扩散模型(或其他生成模型)来建模这个流序列的分布,并生成新的隐式流序列。
- 光流与反向采样

在计算机视觉中,光流通过为每个像素估计一个2D位移向量,来描述两个连续图像帧 x0 和 x1 之间像素的表观运动。
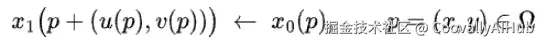
流扭曲可以用上面的方程表示,其中 p = (x, y) 表示像素坐标,(u, v) 表示光流的水平和垂直分量。这个方程定义了一个像素级的映射,描述了源帧 x0 中的像素如何被移动到目标帧 x1 中,将每个在 (x, y) 的像素映射到 (x + u, y + v)。
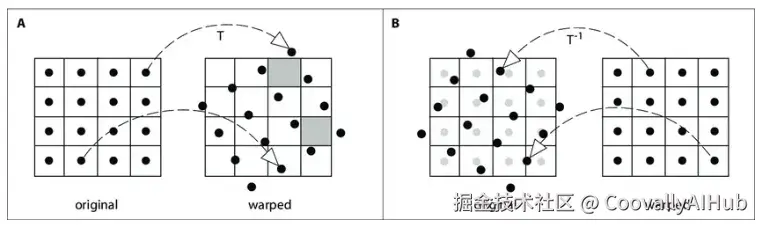
根据流动方向,扭曲可以分为前向扭曲和后向扭曲。前向扭曲使用流场将源帧的每个像素映射到目标帧,但有些像素可能会落在有效图像区域之外,导致缺失或未定义的区域(见A图)。而后向扭曲则指定每个目标像素如何从源帧采样,从而避免了这些缺失区域。
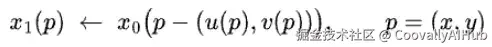
在LFDM中,我们选择后向扭曲,因为所有未来帧(x₁, x₂, ...)都是从同一个源帧(x₀)采样得到的,确保了跨时间的空间和外观一致性。此外,后向扭曲避免了目标帧中的缺失或未定义区域。
关节动画的运动表示
对于简单的运动,传统的光流方法(例如经典的或基于学习的方法)通常效果不错。然而,当运动变得更加复杂时------例如,当多个物体独立运动或发生关节式、非刚性的变形时------准确估计光流就变得困难得多。
因此,LFDM采用了基于MRAA的运动表示,它使用结构化的关键点位移来建模运动,并将它们聚合成一个密集的变形场。这种设计使得LFDM即使在复杂的运动场景下,也能以更稳定、更连贯的方式预测光流和遮挡图。
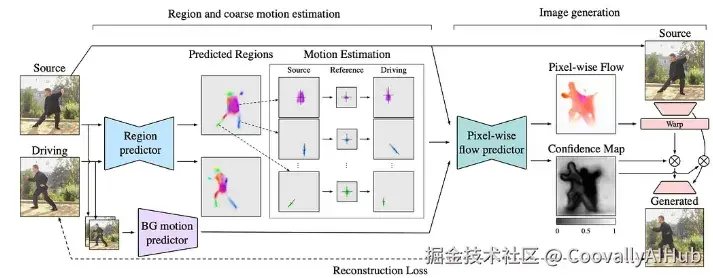
MRAA背后的核心思想相当简单:它不试图一次性建模复杂的整体运动,而是将运动分解成几个较小的局部运动。每个部分被单独建模,然后所有这些局部运动被组合起来形成整体运动。
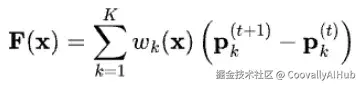
例如,当一个人将手从低位举过头顶时,多个身体部位------如肩膀、上臂和前臂------会一起运动。MRAA不是直接估计一个单一的、全局的像素级运动场,而是对连续帧之间每个局部组件的相对运动进行建模,然后通过加权聚合将它们组合起来,产生最终的整体运动场(光流)。
- MRAA的组成部分
- 区域预测器: 从输入图像中提取一组关键区域,每个区域代表一个局部运动组件。这些区域提供了参与运动的物体部件的结构化和紧凑表示。
- 流预测器: 通过组合区域级运动,建模源帧和驱动帧之间的相对运动。它将运动聚合成一个密集的变形场以及一个遮挡图。
- 生成器: 使用预测的流和遮挡图来扭曲源图像,以重建目标帧。通过重建损失,它实现了对有意义的、稳定的运动表示的端到端学习。
- 背景运动预测器: 估计静态背景的全局运动,例如相机移动。
注:遮挡图指示了由于帧间遮挡而变得不可见的区域,在这些区域,直接从源图像进行扭曲并不可靠。它允许模型在重建过程中降低这些区域的权重或忽略它们,从而防止伪影并提高时间一致性。
区域预测器

区域预测器的目标是学习图像中多个区域的可微分局部表示。它使用一个U-Net来预测每个区域的软热图,以概率方式将像素分配到不同的区域。
从这些热图中,我们计算每个区域的中心和协方差:
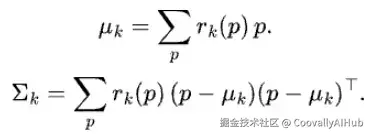
基于这些一阶和二阶矩,我们进一步利用PCA推导出每个区域相对于规范坐标系的仿射表示。这些稀疏的、区域级的线索随后被流预测器用来建模密集的光流。
另一个细节是,流预测器在隐式空间运行,并预测一个空间分辨率低得多的光流,而不是直接在像素级。为了保持区域表示与这个隐式流对齐,我们在训练区域预测器时,将输入图像缩放到与隐式特征相同的分辨率。在我的实现中,128×128的图像被缩放到32×32作为模型输入。
ini
class RegionPredictor(nn.Module):
def __init__(self, block_expansion=32, num_regions=10, num_channels=3, \
max_features=1024, num_blocks=5, temperature=0.1, scale_factor=0.25, pad=0):
super().__init__()
self.temperature = temperature
self.scale_factor = scale_factor
self.predictor = Hourglass(
block_expansion,
in_features=num_channels,
max_features=max_features,
num_blocks=num_blocks
)
self.regions = nn.Conv2d(
in_channels=self.predictor.out_filters,
out_channels=num_regions,
kernel_size=(7, 7),
padding=pad
)
# Rescale 128 * 128 frame into 32 * 32
if self.scale_factor != 1:
self.down = AntiAliasInterpolation2d(num_channels, self.scale_factor)
else:
self.down = None
def _region_to_pca_params(self, region: torch.Tensor):
# region: (B, K, H, W) softmax heatmap
B, K, H, W = region.shape
grid = make_coordinate_grid((H, W), region.dtype).to(region.device)
grid = grid.unsqueeze(0).unsqueeze(0)
# mean/shift: (B, K, 2)
region_w = region.unsqueeze(-1)
mean = (region_w * grid).sum(dim=(2, 3))
# covariance: (B, K, 2, 2)
mean_sub = grid - mean.unsqueeze(-2).unsqueeze(-2)
covar = mean_sub.unsqueeze(-1) * mean_sub.unsqueeze(-2)
covar = covar * region.unsqueeze(-1).unsqueeze(-1)
covar = covar.sum(dim=(2, 3))
I = torch.eye(2, device=covar.device, dtype=covar.dtype).view(1, 1, 2, 2)
covar = covar + 1e-6 * I
covar = 0.5 * (covar + covar.transpose(-1, -2))
# SVD to get sqrt(covar) as "affine"
covar_flat = covar.view(-1, 2, 2)
U, S, Vh = torch.linalg.svd(covar_flat, full_matrices=False)
# sqrt matrix: U * diag(sqrt(S))
D = torch.diag_embed(torch.sqrt(torch.clamp(S, min=1e-6)))
sqrt = U @ D
sqrt = sqrt.view(B, K, 2, 2)
U = U.view(B, K, 2, 2)
D = D.view(B, K, 2, 2)
return {"shift": mean, "covar": covar, "affine": sqrt, "u": U, "d": D}
def forward(self, x: torch.Tensor):
# x: (B, 3, H, W)
if self.down is not None:
x = self.down(x)
feature_map = self.predictor(x)
logits = self.regions(feature_map) # (B, K, H, W)
B, K, H, W = logits.shape
region = logits.view(B, K, -1)
region = F.softmax(region / self.temperature, dim=2)
region = region.view(B, K, H, W)
region_params = self._region_to_pca_params(region)
region_params["heatmap"] = region
return region_params像素级流预测器
在区域预测器中,我们获得了每个区域的粗略的、区域级的运动信息。流预测器然后通过以下方程聚合这些区域级线索,合成一个密集的光流场:(其中A: 仿射矩阵,s: 区域中心,x: 像素坐标)
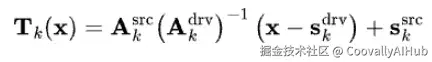
思路很简单。我们首先通过 x - s_drv 移动像素坐标,使得一切都以驱动区域为中心。然后,我们使用驱动帧的逆仿射变换 A_drv^-1 将坐标带入一个规范空间。之后,我们应用源帧的仿射变换 A_src 将其映射回源姿态。最后,我们加上 s_src 得到用于后向扭曲的流网格。
class
def __init__(self, block_expansion=64, num_blocks=5, max_features=1024, \
num_regions=10, num_channels=3, scale_factor=0.25):
super().__init__()
self.num_regions = num_regions
self.scale_factor = scale_factor
in_ch = (num_regions + 1) * (num_channels + 1)
self.hourglass = Hourglass(
block_expansion=block_expansion,
in_features=in_ch,
max_features=max_features,
num_blocks=num_blocks,
)
self.mask = nn.Conv2d(self.hourglass.out_filters, num_regions + 1, kernel_size=7, padding=3)
self.occlusion = nn.Conv2d(self.hourglass.out_filters, 1, kernel_size=7, padding=3)
if self.scale_factor != 1:
self.down = AntiAliasInterpolation2d(num_channels, self.scale_factor)
def create_heatmap_representations(self, source_image, driving_region_params, source_region_params):
spatial_size = source_image.shape[2:] # (h, w)
covar_d = driving_region_params["covar"]
covar_s = source_region_params["covar"]
gaussian_driving = region2gaussian(driving_region_params["shift"], covar=covar_d, spatial_size=spatial_size)
gaussian_source = region2gaussian(source_region_params["shift"], covar=covar_s, spatial_size=spatial_size)
heatmap = gaussian_driving - gaussian_source # (B, K, H, W)
# add background channel (zeros), can consider adding background feature
zeros = torch.zeros(heatmap.size(0), 1, spatial_size[0], spatial_size[1],
device=heatmap.device, dtype=heatmap.dtype)
heatmap = torch.cat([zeros, heatmap], dim=1) # (B, K+1, H, W)
return heatmap.unsqueeze(2) # (B, K+1, 1, H, W)
def create_sparse_motions(self, source_image, driving_region_params, source_region_params):
bs, _, h, w = source_image.shape
identity_grid = make_coordinate_grid((h, w), type=source_region_params["shift"].type())
identity_grid = identity_grid.view(1, 1, h, w, 2) # (1,1,H,W,2)
# region-wise coords centered at driving shift
coordinate_grid = identity_grid - driving_region_params["shift"].view(bs, self.num_regions, 1, 1, 2)
affine = torch.matmul(source_region_params["affine"], torch.inverse(driving_region_params["affine"]))
affine = affine * torch.sign(affine[:, :, 0:1, 0:1])
affine = affine.unsqueeze(-3).unsqueeze(-3) # (B,K,1,1,2,2)
affine = affine.repeat(1, 1, h, w, 1, 1) # (B,K,H,W,2,2)
coordinate_grid = torch.matmul(affine, coordinate_grid.unsqueeze(-1)).squeeze(-1) # (B,K,H,W,2)
driving_to_source = coordinate_grid + source_region_params["shift"].view(bs, self.num_regions, 1, 1, 2)
# background motion is always identity (no bg predictor)
bg_grid = identity_grid.repeat(bs, 1, 1, 1, 1) # (B,1,H,W,2)
return torch.cat([bg_grid, driving_to_source], dim=1)
def create_deformed_source_image(self, source_image, sparse_motions):
bs, _, h, w = source_image.shape
source_repeat = source_image.unsqueeze(1).unsqueeze(1).repeat(bs, self.num_regions + 1, 1, 1, 1, 1)
source_repeat = source_repeat.view(bs * (self.num_regions + 1), -1, h, w)
sparse_motions = sparse_motions.view(bs * (self.num_regions + 1), h, w, 2)
sparse_deformed = F.grid_sample(source_repeat, sparse_motions)
sparse_deformed = sparse_deformed.view(bs, self.num_regions + 1, -1, h, w)
return sparse_deformed
def forward(self, source_image, driving_region_params, source_region_params):
if self.scale_factor != 1:
source_image = self.down(source_image)
bs, _, h, w = source_image.shape
heatmap_representation = self.create_heatmap_representations(source_image, driving_region_params, source_region_params)
sparse_motion = self.create_sparse_motions(source_image, driving_region_params, source_region_params)
deformed_source = self.create_deformed_source_image(source_image, sparse_motion) # (B, K+1, C, H, W)
predictor_input = torch.cat([heatmap_representation, deformed_source], dim=2) # (B, K+1, 1+C, H, W)
predictor_input = predictor_input.view(bs, -1, h, w)
prediction = self.hourglass(predictor_input)
mask = F.softmax(self.mask(prediction), dim=1).unsqueeze(2) # (B,K+1,1,H,W)
sparse_motion = sparse_motion.permute(0, 1, 4, 2, 3) # (B,K+1,2,H,W)
deformation = (sparse_motion * mask).sum(dim=1).permute(0, 2, 3, 1) # (B,H,W,2)
out_dict = {"optical_flow": deformation}
out_dict["occlusion_map"] = torch.sigmoid(self.occlusion(prediction))
return out_dict还使用一个U-Net来预测一个遮挡图。它告诉我们,对于每个像素,哪个区域的运动是可靠的。更重要的是,它让生成器知道哪些部分被遮挡了,无法通过扭曲获得,因此这些区域需要生成器自己来填充。
生成器与训练循环
最后,第一阶段训练的最后一个部分是生成器,它是一个基于自编码器的模型。它首先将源帧 x_s 编码成一个隐式表示 z_s。然后,这个隐式表示被光流扭曲,产生一个变形后的特征。
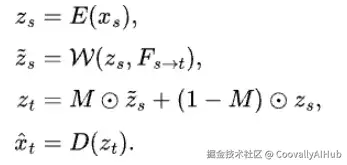
一个遮挡图 M 被用来混合变形后的隐式表示和原始隐式表示,指示哪些区域应该被信任,哪些需要被填充。解码器然后使用这个混合后的隐式表示来重建目标帧 x_t。
ini
class Generator(nn.Module):
def __init__(self, num_channels=3, num_regions=10, block_expansion=64, max_features=512,
num_down_blocks=2, num_bottleneck_blocks=6):
super().__init__()
self.first = SameBlock2d(num_channels, block_expansion, kernel_size=(7, 7), padding=(3, 3))
down_blocks = []
up_blocks = []
for i in range(num_down_blocks):
in_features = min(max_features, block_expansion * (2 ** i))
out_features = min(max_features, block_expansion * (2 ** (i + 1)))
down_blocks.append(DownBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))
for i in range(num_down_blocks):
in_features = min(max_features, block_expansion * (2 ** (num_down_blocks - i)))
out_features = min(max_features, block_expansion * (2 ** (num_down_blocks - i - 1)))
up_blocks.append(UpBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1)))
self.down_blocks = nn.ModuleList(down_blocks)
self.up_blocks = nn.ModuleList(up_blocks)
in_features = min(max_features, block_expansion * (2 ** num_down_blocks))
self.bottleneck = nn.Sequential(*[
ResBlock2d(in_features, kernel_size=(3, 3), padding=(1, 1))
for _ in range(num_bottleneck_blocks)
])
self.final = nn.Conv2d(block_expansion, num_channels, kernel_size=(7, 7), padding=(3, 3))
self.num_channels = num_channels
@staticmethod
def deform_input(inp, grid):
# grid: (B, H, W, 2) in normalized coords for grid_sample
b, c, h, w = inp.shape
gh, gw = grid.shape[1], grid.shape[2]
if (gh, gw) != (h, w):
grid = grid.permute(0, 3, 1, 2) # (B,2,H,W)
grid = F.interpolate(grid, size=(h, w), mode='bilinear', align_corners=True)
grid = grid.permute(0, 2, 3, 1) # (B,H,W,2)
return F.grid_sample(inp, grid, align_corners=True)
def apply_optical(self, x_skip, x_prev, motion_params):
if motion_params is None:
return x_prev if x_prev is not None else x_skip
x = self.deform_input(x_skip, motion_params['optical_flow'])
occ = motion_params['occlusion_map']
if occ.shape[-2:] != x.shape[-2:]:
occ = F.interpolate(occ, size=x.shape[-2:], mode='bilinear', align_corners=True)
if x_prev is None:
return x * occ
return x * occ + x_prev * (1 - occ)
def forward(self, source_image, motion_params):
out = self.first(source_image)
skips = [out]
for block in self.down_blocks: # Encoder
out = block(out)
skips.append(out)
output_dict = {
"bottle_neck_feat": out,
"deformed": self.deform_input(source_image, motion_params["optical_flow"]),
"optical_flow": motion_params["optical_flow"],
}
output_dict["occlusion_map"] = motion_params["occlusion_map"]
out = self.apply_optical(x_skip=out, x_prev=None, motion_params=motion_params)
out = self.bottleneck(out)
for i, up in enumerate(self.up_blocks): # Decoder
out = self.apply_optical(
x_skip=skips[-(i + 1)],
x_prev=out,
motion_params=motion_params
)
out = up(out)
out = torch.sigmoid(self.final(out))
output_dict["prediction"] = out
return output_dict
def compute_fea(self, source_image):
out = self.first(source_image)
for block in self.down_blocks:
out = block(out)
return out- UTD-MHAD数据集
在这个实现中,我使用UTD-MHAD数据集来训练模型的两个阶段。对于第一阶段,从同一个视频中随机采样两帧,一帧作为源帧,另一帧作为目标帧。对于第二阶段,随机选择一个视频,并提取一个连续的40帧序列作为模型输入。
ini
from PIL import Image
from decord import VideoReader, cpu
class UTDDataset(Dataset):
def __init__(self,
root="/content/drive/MyDrive/LFDM_data",
image_size=128,
mode="stage1",
clip_len=40):
super().__init__()
assert mode in ["stage1", "stage2"]
self.mode = mode
self.clip_len = clip_len
self.video_files = sorted(glob(os.path.join(root, "**", "*.avi"), recursive=True))
self.transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
])
def __len__(self):
return len(self.video_files)
def __getitem__(self, idx):
# Stage 1: random (x0, xt)
if self.mode == "stage1":
while True:
vid_path = random.choice(self.video_files)
vr = VideoReader(vid_path, ctx=cpu(0))
n = len(vr)
if n < 2:
continue
i0, i1 = sorted(random.sample(range(n), 2))
f0 = Image.fromarray(vr[i0].asnumpy())
f1 = Image.fromarray(vr[i1].asnumpy())
x0 = self.transform(f0)
xt = self.transform(f1)
return x0, xt
# Stage 2: clip + action
vid_path = self.video_files[idx]
vr = VideoReader(vid_path, ctx=cpu(0))
n = len(vr)
if n == 0:
return self.__getitem__((idx + 1) % len(self.video_files))
K = self.clip_len
if n >= K:
start = random.randint(0, n - K)
indices = range(start, start + K)
else:
indices = sorted(random.choices(range(n), k=K))
frames = []
for i in indices:
img = Image.fromarray(vr[i].asnumpy())
frames.append(self.transform(img))
clip = torch.stack(frames, dim=1) # (C, K, H, W)
video_name = os.path.basename(vid_path)
action_idx = int(video_name.split("_")[0][1:]) - 1 # a01 -> 0
return clip, action_idx- 第一阶段训练循环
- 从源帧 x0 和目标帧 xt 中提取区域信息。
- 使用流预测器预测光流和遮挡图。
- 用预测的运动扭曲源帧,并使用生成器重建目标帧 pred_xt。
- 测量重建帧与目标帧之间的感知损失。
注:你也可以尝试应用一个等变性损失,这可以加强几何一致性,并提高学习到的运动表示的稳定性。
def
x_vgg = vgg(pred)
y_vgg = vgg(real)
loss = 0.0
for i, w in enumerate(per_weights):
loss = loss + w * torch.abs(x_vgg[i] - y_vgg[i].detach()).mean()
return loss
region_predictor = RegionPredictor().to(device)
flow_predictor = PixelwiseFlowPredictor().to(device)
generator = Generator().to(device)
total_iters = 200000
save_interval = 20000
# You may use any pretrained VGG model.
# Here, we use the outputs of the last five layers to compute the perceptual loss.
vgg = Vgg19().to(device)
vgg.eval()
for p in vgg.parameters():
p.requires_grad_(False)
dataset = UTDDataset(mode="stage1", image_size=128)
dataloader = DataLoader(
dataset,
batch_size=16,
shuffle=True,
pin_memory=True,
drop_last=True,
num_workers=4
)
optimizer = torch.optim.Adam(
list(region_predictor.parameters()) +
list(flow_predictor.parameters()) +
list(generator.parameters()),
lr=5e-5,
betas=(0.5, 0.999)
)
data_iter = iter(dataloader)
pbar = trange(1, total_iters + 1, desc="Training", dynamic_ncols=True)
for it in pbar:
try:
x0, xt = next(data_iter)
except StopIteration:
data_iter = iter(dataloader)
x0, xt = next(data_iter)
x0, xt = x0.to(device, non_blocking=True), xt.to(device, non_blocking=True)
source_region = region_predictor(x0)
driving_region = region_predictor(xt)
motion = flow_predictor(x0, source_region_params=source_region, driving_region_params=driving_region)
generated = generator(x0, motion)
pred = generated["prediction"]
real = xt
perc = perceptual_loss(vgg, pred, real)
optimizer.zero_grad(set_to_none=True)
perc.backward()
optimizer.step()
# ---- save ----
if it % save_interval == 0:
ckpt = {
"it": it,
"region_predictor": region_predictor.state_dict(),
"flow_predictor": flow_predictor.state_dict(),
"generator": generator.state_dict(),
"optimizer": optimizer.state_dict(),
}
torch.save(ckpt, f"stage1_ckpt_{it:06d}.pt")LFDM第二阶段训练
终于到了最后一步。我们现在要做的事情很简单:训练一个生成模型,能够生成合理的隐式流序列,其形状为:
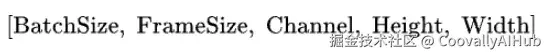
到了这一步,大部分困难的工作已经完成了。使用MRAA风格的方法,我们已经分离了空间结构,并将原始图像压缩到了一个低维隐式空间。因此,模型不再需要关心外观------它只需要学习运动如何随时间演化。
我们现在可以将隐式流序列视为一个3D体积,并使用扩散模型来生成它。当然,扩散模型不是唯一的选择------整流流、Transformer或GANs在这里也能很好地工作。
注:在我的实现中,我使用了"修正流"而不是扩散模型,因为它更容易实现且收敛更快。
python
import ...
from einops import rearrange
class TemporalSelfAttention(nn.Module):
def __init__(self, dim, heads=8, max_frames=64, dropout=0.0):
super().__init__()
self.max_frames = max_frames
self.pos_emb = nn.Embedding(max_frames, dim)
self.attn = nn.MultiheadAttention(dim, heads, dropout=dropout, batch_first=True)
def forward(self, x):
b, c, f, h, w = x.shape
if f > self.max_frames:
raise ValueError(f"num_frames={f} exceeds max_frames={self.max_frames}")
x_seq = rearrange(x, 'b c f h w -> (b h w) f c') # (BHW, F, C)
pos = torch.arange(f, device=x.device)
x_seq = x_seq + self.pos_emb(pos).unsqueeze(0) # (BHW, F, C)
out, _ = self.attn(x_seq, x_seq, x_seq, need_weights=False)
out = rearrange(out, '(b h w) f c -> b c f h w', b=b, h=h, w=w)
return out
class SinusoidalPosEmb(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, x):
device = x.device
half_dim = self.dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
emb = x[:, None] * emb[None, :]
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
return emb
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, *args, **kwargs):
return self.fn(x, *args, **kwargs) + x
def Upsample(dim, padding_mode="reflect"):
return nn.Sequential(
nn.Upsample(scale_factor=(1, 2, 2), mode='nearest'),
nn.Conv3d(dim, dim, (1, 3, 3), (1, 1, 1), (0, 1, 1), padding_mode=padding_mode)
)
def Downsample(dim):
return nn.Conv3d(dim, dim, (1, 4, 4), (1, 2, 2), (0, 1, 1))
class NormAttn(nn.Module):
def __init__(self, norm, attn):
super().__init__()
self.norm = norm
self.attn = attn
def forward(self, x):
return self.attn(self.norm(x))
class ResnetBlock(nn.Module):
def __init__(self, dim, dim_out, *, time_emb_dim=None, groups=8):
super().__init__()
if time_emb_dim is None:
self.mlp = None
else:
self.mlp = nn.Sequential(
nn.SiLU(),
nn.Linear(time_emb_dim, dim_out * 2)
)
self.conv1 = nn.Conv3d(dim, dim_out, (1, 3, 3), padding=(0, 1, 1))
self.norm1 = nn.GroupNorm(groups, dim_out)
self.act1 = nn.SiLU()
self.conv2 = nn.Conv3d(dim_out, dim_out, (1, 3, 3), padding=(0, 1, 1))
self.norm2 = nn.GroupNorm(groups, dim_out)
self.act2 = nn.SiLU()
self.res_conv = nn.Conv3d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
def forward(self, x, time_emb=None):
scale = shift = None
if self.mlp is not None:
t = self.mlp(time_emb)
t = rearrange(t, 'b c -> b c 1 1 1')
scale, shift = t.chunk(2, dim=1)
h = self.conv1(x)
h = self.norm1(h)
if scale is not None:
h = h * (scale + 1) + shift
h = self.act1(h)
h = self.conv2(h)
h = self.norm2(h)
h = self.act2(h)
return h + self.res_conv(x)以上是U-Net模型的一些关键模块。这里,我们添加了一个时间注意力模块,通过关注时间(帧)维度来更好地保持时间一致性。
ini
class Unet3D(nn.Module):
def __init__(self, dim=64, num_classes=28, cond_embed_dim=128, dim_mults=(1, 2, 4, 8),
channels=3 + 256, attn_heads=8, max_frames=64, init_kernel_size=7, resnet_groups=8):
super().__init__()
self.channels = channels
init_dim = dim
init_padding = init_kernel_size // 2
self.init_conv = nn.Conv3d(
channels, init_dim,
kernel_size=(1, init_kernel_size, init_kernel_size),
padding=(0, init_padding, init_padding),
padding_mode="zeros"
)
self.init_norm = nn.GroupNorm(1, init_dim, eps=1e-5)
self.init_attn = TemporalSelfAttention(init_dim, heads=attn_heads, max_frames=max_frames)
self.init_attn_res = Residual(lambda x: self.init_attn(self.init_norm(x)))
dims = [init_dim] + [dim * m for m in dim_mults]
in_out = list(zip(dims[:-1], dims[1:]))
num_resolutions = len(in_out)
# time embedding
time_dim = dim * 4
self.time_mlp = nn.Sequential(
SinusoidalPosEmb(dim),
nn.Linear(dim, time_dim),
nn.GELU(),
nn.Linear(time_dim, time_dim)
)
# class embedding
self.cond_emb = nn.Embedding(num_classes, cond_embed_dim)
cond_dim = time_dim + cond_embed_dim
block_klass = partial(ResnetBlock, groups=resnet_groups)
block_klass_cond = partial(block_klass, time_emb_dim=cond_dim)
self.downs = nn.ModuleList([])
self.ups = nn.ModuleList([])
for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1)
norm = nn.GroupNorm(1, dim_out, eps=1e-5)
attn = TemporalSelfAttention(dim_out, heads=attn_heads, max_frames=max_frames)
attn_res = Residual(NormAttn(norm, attn))
self.downs.append(nn.ModuleList([
block_klass_cond(dim_in, dim_out),
block_klass_cond(dim_out, dim_out),
attn_res,
Downsample(dim_out) if not is_last else nn.Identity()
]))
mid_dim = dims[-1]
self.mid_block1 = block_klass_cond(mid_dim, mid_dim)
norm = nn.GroupNorm(1, mid_dim, eps=1e-5)
attn = TemporalSelfAttention(mid_dim, heads=attn_heads, max_frames=max_frames)
self.mid_attn_res = Residual(NormAttn(norm, attn))
self.mid_block2 = block_klass_cond(mid_dim, mid_dim)
for ind, (dim_in, dim_out) in enumerate(reversed(in_out)):
is_last = ind >= (num_resolutions - 1)
norm = nn.GroupNorm(1, dim_in, eps=1e-5)
attn = TemporalSelfAttention(dim_in, heads=attn_heads, max_frames=max_frames)
attn_res = Residual(NormAttn(norm, attn))
self.ups.append(nn.ModuleList([
block_klass_cond(dim_out * 2, dim_in),
block_klass_cond(dim_in, dim_in),
attn_res,
Upsample(dim_in, padding_mode="zeros") if not is_last else nn.Identity()
]))
self.out = nn.Sequential(
block_klass(dim * 2, dim),
nn.Conv3d(dim, 3, 1)
)
def forward(self, x, time, cond):
device = x.device
x = self.init_conv(x)
r = x.clone()
x = self.init_attn_res(x)
t = self.time_mlp(time)
if cond.dim() == 2 and cond.size(-1) == 1:
cond = cond.squeeze(-1)
cond = cond.long().to(device)
t = torch.cat([t, self.cond_emb(cond)], dim=-1)
h = [] # unet
for block1, block2, attn_res, downsample in self.downs:
x = block1(x, t)
x = block2(x, t)
x = attn_res(x)
h.append(x)
x = downsample(x)
x = self.mid_block1(x, t)
x = self.mid_attn_res(x)
x = self.mid_block2(x, t)
for block1, block2, attn_res, upsample in self.ups:
x = torch.cat([x, h.pop()], dim=1)
x = block1(x, t)
x = block2(x, t)
x = attn_res(x)
x = upsample(x)
x = torch.cat([x, r], dim=1)
return self.out(x)get_latent_flow_residual 函数收集源帧与所有其他帧之间的流。它还输出源帧的特征图,用作U-Net的条件输入。
@torch.no_grad()
def get_latent_flow_residual(x, region_predictor, flow_predictor, generator):
b, _, T, H, W = x.shape
source_img = x[:, :, 0] # (B,3,H,W)
flow_list = []
conf_list = []
source_region = region_predictor(source_img)
for t in range(T):
driving_img = x[:, :, t]
driving_region = region_predictor(driving_img)
flow_motion = flow_predictor(
source_img,
source_region_params=source_region,
driving_region_params=driving_region
)
grid = flow_motion["optical_flow"]
conf = flow_motion["occlusion_map"]
flow_list.append(grid) # keep (B,H,W,2)
conf_list.append(conf)
fea = generator.compute_fea(source_img)
grid = torch.stack(flow_list, dim=1) # (B,T,H,W,2)
conf = torch.stack(conf_list, dim=2) # (B,1,T,H,W)
id_grid = make_coordinate_grid((32, 32), grid.dtype).to(grid.device)
id_grid = id_grid.unsqueeze(0).repeat(b, 1, 1, 1)
id_grid = id_grid.unsqueeze(1).repeat(1, T, 1, 1, 1)
delta = grid - id_grid
delta = delta.permute(0, 4, 1, 2, 3).contiguous()
conf = conf * 2 - 1 # conf to [-1,1]
out = torch.cat([delta, conf], dim=1)
# fea repeat on T (B,C,Hf,Wf)->(B,C,T,Hf,Wf)
fea = fea.unsqueeze(2).repeat(1, 1, T, 1, 1)
return out, fea
from torchdiffeq import odeint
class RectifiedFlow(nn.Module):
def __init__(self, unet, p_uncond=0.25, null_label_id=27):
super().__init__()
self.unet = unet
self.p_uncond = p_uncond
self.null_label_id = null_label_id
def forward(self, x0, fea, label):
B = x0.size(0)
device = x0.device
# Classified Free Guidence
if (self.null_label_id is not None) and (self.p_uncond > 0):
drop = torch.rand(B, device=device) < self.p_uncond
label = label.clone()
label[drop] = self.null_label_id
t = torch.rand(B, device=device) # (B,)
t_view = t.view(B, 1, 1, 1, 1)
x1 = torch.randn_like(x0)
x_t = (1.0 - t_view) * x1 + t_view * x0
v_gt = x0 - x1
x_in = torch.cat([x_t, fea], dim=1) # (B, C+C_fea, F, H, W)
v_pred = self.unet(x_in, t, label)
loss = F.mse_loss(v_pred, v_gt)
return loss
@torch.no_grad()
def rf_sample_target(model, fea, label, device, steps=40):
# You can use this function to get the latent flow
# and use the 'decoder' in Generator to recover the video back
B = label.size(0)
x0 = torch.randn(B, 3, 40, 32, 32, device=device)
def func(t, x):
t_vec = torch.full((B,), float(t), device=device)
x_in = torch.cat([x, fea], dim=1)
v = model(x_in, t_vec, label)
return v
t_span = torch.linspace(0.0, 1.0, steps + 1, device=device)
x_traj = odeint(func, x0, t_span, method="rk4", rtol=1e-5, atol=1e-5)
x1 = x_traj[-1]
x1 = x1.clamp(-1, 1)
return x1, x0- 无分类器引导
对于视频生成,仅仅使用一个标签来控制输出通常是不够的。标签只告诉模型要生成什么动作,但它没有解释这个动作应该如何随时间演化。
因此,模型在训练过程中很容易走捷径,生成一个仅仅"看起来在动"的序列,而没有真正遵循给定标签的语义含义。换句话说,条件信号太弱了,所以模型可以轻易忽略它。
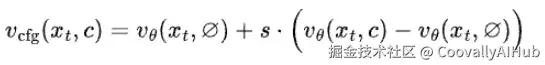
为了解决这个问题,引入无分类器引导来让标签更重要。CFG通过在生成过程中放大条件的影响,明确地加强了条件的约束力,迫使模型遵循标签,而不是退回到通用的、无条件的运动。这对于视频生成尤其重要,因为可能的运动空间比图像大得多。
注:在实践中,CFG非常容易实现。只需添加一个额外的类别来表示空(无条件)条件,并在训练过程中随机丢弃原始标签。
device
best_path = "Your pretrain model"
ckpt = torch.load(best_path, map_location=device)
generator.load_state_dict(ckpt["generator"])
region_predictor.load_state_dict(ckpt["region_predictor"])
flow_predictor.load_state_dict(ckpt["flow_predictor"])
unet = Unet3D()
rf_model = RectifiedFlow(unet).to(device)
dataset = UTDDataset(mode='stage2)
optimizer = torch.optim.Adam(list(unet.parameters()), lr=1e-4, betas=(0.9, 0.999))
dataloader = torch.utils.data.DataLoader(dataset, batch_size=4, shuffle=True, num_workers=4)
total_iters = 200000
log_interval = 20000
running_loss = 0.0
loss_history = []
iter_history = []
generator.eval()
region_predictor.eval()
flow_predictor.eval()
unet.train()
data_iter = iter(dataloader)
pbar = trange(1, total_iters + 1, desc="Training", dynamic_ncols=True)
for it in pbar:
try:
clip, label = next(data_iter)
except StopIteration:
data_iter = iter(dataloader)
clip, label = next(data_iter)
clip, label = clip.to(device), label.to(device)
B = clip.size(0)
flow, fea = get_latent_flow_residual(clip, region_predictor, flow_predictor, generator)
loss = rf_model(flow, fea, label)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(unet.parameters(), 1.0)
optimizer.step()
ema_update(ema_unet, unet, beta=0.995)
running_loss += loss.item()
pbar.set_postfix({"loss": f"{loss.item():.4f}"})
if it % log_interval == 0:
avg_loss = running_loss / log_interval
pbar.write(f"[Iter {it}] loss = {avg_loss:.4f}")
iter_history.append(it)
loss_history.append(avg_loss)
running_loss = 0.0
torch.save(
{
"unet": unet.state_dict(),
"ema_unet": ema_unet.state_dict(),
"optimizer": optimizer.state_dict(),
"it": it,
},
f"{ckpt_dir}/unet_{it}.pt"
)
pbar.write(f"Saved checkpoint at iter {it}")