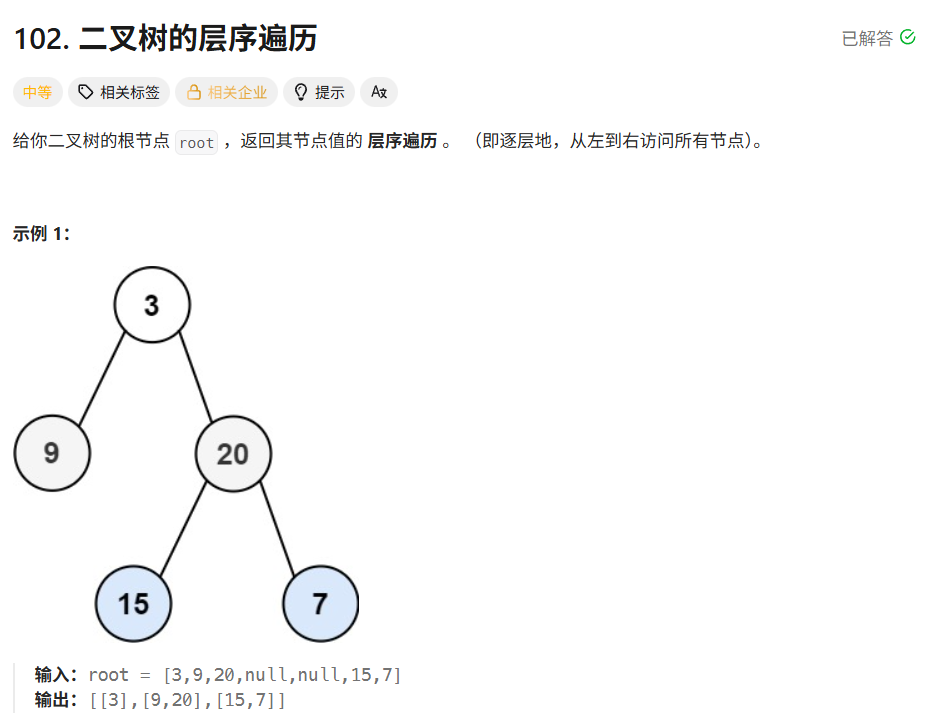

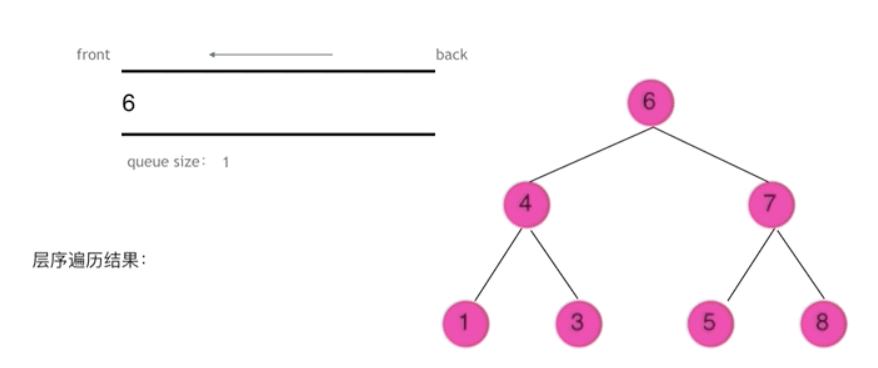
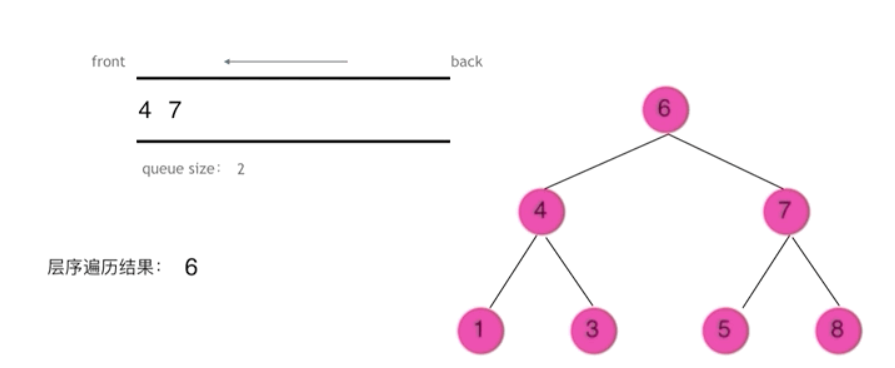
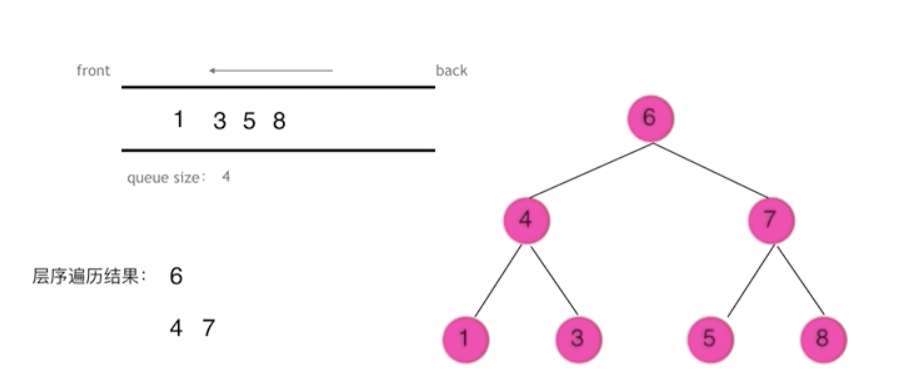
cpp
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
// 创建一个队列用于BFS(广度优先搜索),存储待处理的树节点
queue<TreeNode*> que;
// 如果根节点不为空,将其加入队列
if (root != NULL) que.push(root);
// 结果二维数组,每层一个子数组
vector<vector<int>> result;
// 当队列不为空时,继续处理
while (!que.empty()) {
// 记录当前层的节点数量(重要:需要在循环前固定大小)
int size = que.size();
// 存储当前层所有节点值的数组
vector<int> vec;
// 遍历当前层的所有节点
// 注意:必须使用固定size,不能直接用que.size(),因为循环中que.size()会变化
for (int i = 0; i < size; i++) {
// 从队列头部取出节点
TreeNode* node = que.front();
que.pop(); // 弹出已处理的节点
// 将当前节点的值加入当前层的数组
vec.push_back(node->val);
// 如果左子节点存在,加入队列(下一层)
if (node->left) que.push(node->left);
// 如果右子节点存在,加入队列(下一层)
if (node->right) que.push(node->right);
}
// 将当前层的节点值数组加入结果集
result.push_back(vec);
}
// 返回层序遍历的结果
return result;
}
};
cpp
if (root != NULL) que.push(root);
vector<vector<int>> result;
while (!que.empty()) {
// 循环体
}
return result;优点:
-
逻辑连贯:代码流程更顺畅,先判断根节点是否为空,不为空则入队
-
减少return语句:避免提前返回,代码结构更统一
-
可读性好:一目了然,符合大多数人的阅读习惯
-
适合简单逻辑:对于简单的初始化操作很自然
缺点:
- 边界情况处理不够明确:当根节点为空时,直接进入while循环,但实际上while循环不会执行(因为队列为空)
cpp
if (root == NULL) return result;
que.push(root);
vector<vector<int>> result;
while (!que.empty()) {
// 循环体
}
return result;优点:
-
提前处理边界情况:更显式地处理空树情况
-
性能稍好:直接返回空结果,避免创建队列和后续判断
-
防御性编程:明确展示了"如果输入为空,直接返回空结果"的逻辑
-
符合一些编码规范:优先处理异常/边界情况
缺点:
-
代码结构稍显分散:有两个return语句
-
对于简单情况略显冗余:这种写法的优势在复杂函数中更明显
综上所述,
对于这道题,第一种写法更好,原因如下:
-
逻辑简单直观:代码表达了"如果根不为空,就放入队列"的自然逻辑
-
代码紧凑:不需要提前return,整个函数只有一个return语句
-
可读性更强:对于算法题,这种写法更常见,易于理解
-
性能差异极小:两种写法的性能差异可以忽略不计
但如果是生产环境 或者更复杂的函数,第二种写法可能更好,因为它:
-
明确处理了边界条件
-
遵循了"快速失败"原则
-
减少了嵌套层次