本文介绍了Neurocomputing期刊上的一篇论文《TrajVAE: A Variational AutoEncoder model for trajectory generation》,该论文提出了两种轨迹生成的解决方案,即TrajGAN和TrajVAE。这两种方案首先利用长短期记忆网络(LSTM)对轨迹特征进行建模,然后分别借助生成对抗网络(GAN)和变分自编码器(VAE)框架来生成轨迹。论文将TrajGAN作为基准模型,通过实验发现TrajVAE相对于基准模型具有更高的准确性和稳定性。
本文作者邓镝,审校韩煦。
论文链接 :https://www.sciencedirect.com/science/article/pii/S0925231220312017
一、研究背景
大规模轨迹数据集对于交通相关的数据挖掘和仿真任务至关重要,例如自动驾驶、热门路线挖掘以及交通信号灯控制等。然而,在部分城市或地区,由于多种原因往往难以获取充足的轨迹数据。一方面,出于隐私保护考虑,部分城市的政府禁止对车辆和行人的轨迹信息进行永久存储和共享;另一方面,获取大规模轨迹数据需要大量用户授权允许收集其位置信息,而这对于特定地区的许多企业而言往往难以实现。因此,在这类场景下,生成高质量的大规模轨迹数据对于支撑相关应用具有重要意义。
一些研究能够通过部分观测结果来预测未来轨迹,也有一些方法针对给定的起讫点对进行轨迹生成。然而,这些方法均需要特定的输入条件,要么是生成轨迹的前半部分,要么是特定的起讫点(origin-destination,OD)对。然而,实际应用中迫切需要一种更灵活的模型,该模型生成轨迹时不仅不受输入条件限制,还能遵循数据集中真实轨迹的特征,即生成的轨迹与真实轨迹难以区分。
该论文提出了一种基于变分自编码器(VAE)的轨迹生成模型。该模型能够有效提取现有轨迹的特征,进而生成相似的轨迹,使得生成轨迹与真实轨迹难以区分。论文的主要贡献如下:
1、设计了一种基于生成对抗网络(GAN)的轨迹生成模型TrajGAN作为基准模型,该模型能够生成相似的轨迹;
2、利用VAE在生成性问题中的优势,提出了一种稳定且准确的轨迹生成模型TrajVAE,该模型在生成相似轨迹方面表现优异;
3、为了分析所提方法的精度,采用了不同的轨迹距离度量指标来计算现有轨迹与生成轨迹之间的相似性。通过多项实验验证,所提方法相比基准模型在轨迹生成方面更准确、更稳定。
二、研究方法
2.1 轨迹生成对抗网络(TrajGAN)
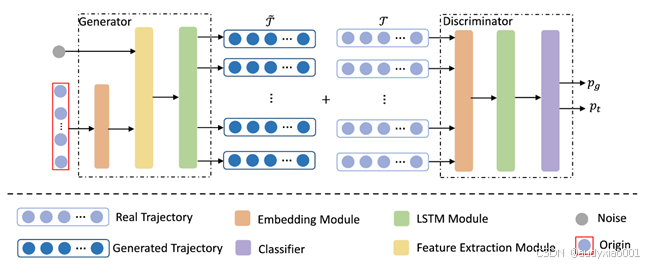
图 1 TrajGAN 的架构
文中采用GAN的传统结构来生成与现有轨迹特征最相似的轨迹,该模型称为TrajGAN。为了捕捉轨迹数据的序列特征,在判别器D和生成器G网络中均采用了LSTM。
如图1所示,生成器G包含三个模块:嵌入模块(embedding)、特征提取模块(feature extraction)和LSTM模块。首先,利用嵌入模块将离散的起点转换为连续向量;然后,通过包含两个多层感知机的特征提取模块提取LSTM的初始隐藏状态;最后,借助LSTM模块捕捉轨迹数据的序列特征,生成与原始轨迹数据集高度相似、难以区分的轨迹数据集。
判别器D可视为一个分类器,以真实轨迹数据集和生成轨迹数据集中的轨迹作为输入。判别器D由三个模块组成:嵌入模块用于将轨迹转换为低维空间中的连续向量;LSTM模块用于捕捉轨迹的特征;最后,采用一个多层感知机作为分类器,计算样本来自真实数据集而非生成数据集的概率。判别器D的输出包含两个部分:训练数据的得分pt 和生成数据的得分pg 。其中,pg 反向传播至生成器G,pt 和pg反向传播至判别器D。
2.2 轨迹变分自编码器(TrajVAE)
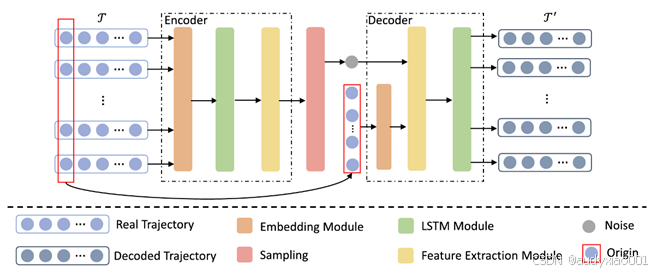
图 2 TrajVAE 的架构
论文设计了一种基于VAE的轨迹生成模型TrajVAE,该模型能够有效提取现有轨迹的特征,并将噪声转换为相似的轨迹。
TrajVAE的模型结构如图2所示,包含两个部分:编码器和解码器。论文中利用预训练的嵌入模型将相邻交叉点之间的关系嵌入到连续的潜在空间中,以提取轨迹的空间信息。文中提到,为了通用性考虑,在编码器和解码器中均采用了基础的LSTM模型,同时该模型也易于扩展到其他LSTM变体。
为了提取道路网络中的空间信息,首先通过DeepWalk预训练一个嵌入模型,该模型可用于将相邻时空点之间的关系编码到连续向量空间中。具体而言,两个时空点之间的距离可以通过它们在低维空间中的嵌入向量之间的邻近性来建模。首先在道路网络中反复进行随机游走,将该过程的输出作为"语料库";然后,利用词嵌入方法(如word2vec)学习道路网络中每个时空点的潜在表征;最后,得到轨迹的连续表征,这些嵌入向量随后将用于编码器和解码器中。
编码器网络用于尽可能地将训练轨迹数据集的分布近似为正态分布,其输出是训练数据的均值向量与标准差向量。编码器网络同样包括三个模块:嵌入模块、LSTM模块和特征提取模块。随后,噪声分布与特定起点一起作为解码器网络的输入。
解码器包括特征提取模块和LSTM模块,其损失函数包括两个部分:重构误差和分布误差。重构误差指训练轨迹与重构轨迹之间的均方误差,分布误差为潜在变量空间的分布与正态分布之间的KL散度。
三、实验结果
3.1 实验设置
论文中的实验参数如表1所示。
表 1 实验参数设置
|---------------------------------------------------------|---------|
| 参数 | 默认值 |
| 批次大小( Batch size ) | 64 |
| 嵌入维度( Embedding size ) | 100 |
| 潜在维度( Latent dimension ) | 128 |
| 中间维度( Intermediate dimension ) | 256 |
| 生成轨迹的数量( Number of generated trajectories ) | 10 |
论文在GAOTONG轨迹数据集上训练模型。数据集进行以下预处理:首先将每条轨迹中的每个时空点编码为唯一的ID,然后将每条训练轨迹映射为ID序列。最后,使用一个n ×k 矩阵表示真实轨迹数据集,其中n 是训练轨迹的数量,k 表示训练轨迹的最大长度,第i 行表示数据集中的第i 条轨迹,第j 列表示时间步j 时的路段ID。对于长度小于k的轨迹,采用-1进行填充。
评估指标采用了豪斯多夫距离(Hausdorff Distance)与动态时间规整(Dynamic Time Warping, DTW)。豪斯多夫距离是一种传统的轨迹相似性度量方法,无需参数,适用于大多数轨迹数据。动态时间规整则能够自适应地度量时间序列的距离。
3.2 实验结果
表 2 TrajVAE 与 TrajGAN 的性能对比
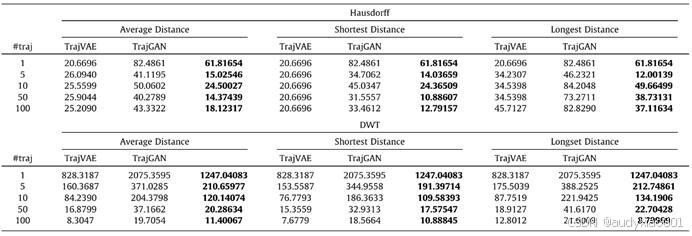
表2列出了所提方法TrajVAE与基准模型TrajGAN在豪斯多夫距离和DTW距离这两个指标上的对比结果,其中每个指标均采用平均距离、最短距离和最长距离来衡量轨迹之间的相似性。实验发现,无论生成轨迹的数量多少,TrajVAE的性能均优于TrajGAN。并且TrajVAE与TrajGAN之间的性能差距约为40%。
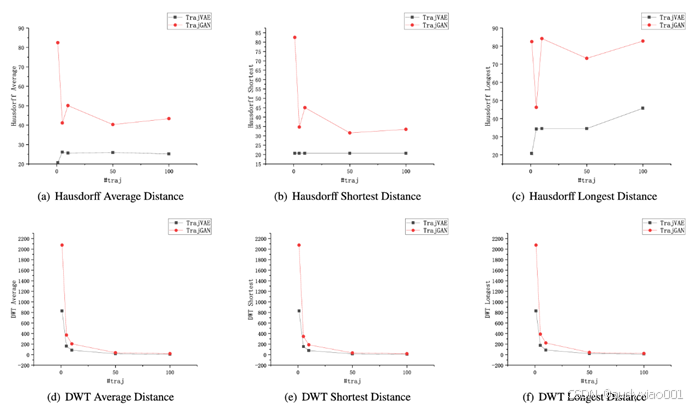
图 3 生成轨迹数量对性能的影响: (a) 豪斯多夫平均距离; (b) 豪斯多夫最短距离; (c) 豪斯多夫最长距离; (d)DWT 平均距离; (e)DWT 最短距离; (f)DWT 最长距离
从图3可以看出,随着生成轨迹数量的增加,TrajVAE表现出更稳定的趋势。针对该现象,文中提出了以下几点原因:
(1)TrajGAN的对抗性学习机制可能导致训练不稳定、梯度消失和模式崩溃等问题。而TrajVAE虽然也包含编码器和解码器两个模块,但这两个网络仅通过一个损失函数更新参数,可视为一个整体进行训练。
(2)从博弈论的角度来看,TrajGAN难以达到纳什均衡,即生成器G和判别器D很少能同时达到最优解。而TrajVAE通过合适的损失函数和优化器,易于收敛到最优解。
(3)TrajGAN需要较长时间才能收敛,且在收敛过程中可能会丢失一些特征。而TrajVAE的训练过程相对简单,尤其是在轨迹重要特征的丢失方面更少。
四、总结
该论文聚焦于轨迹生成问题,研究如何生成与真实轨迹高度相似、难以区分的高质量数据集。文中提出了两种解决方案,即TrajGAN和TrajVAE。这两种方案首先利用LSTM对轨迹特征进行建模,然后分别借助GAN和VAE框架来生成轨迹。实验结果表明,所提出的TrajVAE模型能够有效解决轨迹生成问题,且生成的轨迹与现有轨迹具有更高的相似性。