论文:KnowVal: A Knowledge-Augmented and Value-Guided Autonomous Driving System(arXiv:2512.20299v1, 2025-12-23)
本文面向自动驾驶/机器学习工程与研究读者,目标是将 KnowVal 的关键贡献以"可复现(reproducible)"的方式落地描述:给出模块化系统结构、知识图谱(Knowledge Graph, KG)的构建与检索机制、价值模型(Value Model)的训练信号与推理流程、关键超参数与消融结论,并提供复现清单(replication checklist)。
说明 :本文依据论文 PDF 文本抽取(
pdftotext)整理。附录中 KG 统计(1,324 nodes / 2,785 edges) 、Value Model 数据集 GT 构造 Prompt(Listing 1) 、以及 检索阶段关键词抽取 Prompt(B.2) 可以稳定抽取;但 Listing 2(retrieval prompt)正文在当前抽取结果中缺失 ,仅保留模板壳(Entity_types/Text/Output),因此本文对 Listing 2 的"精确 prompt 字符串级复刻"暂以占位符标注。
1. 问题定义与动机(Motivation)
1.1 现有范式的结构性不足
论文将自动驾驶系统主流范式概括为:
- 端到端(end-to-end)规划模型:基于 BEV/3D feature 直接解码轨迹。优势是闭环端到端优化;局限在于缺少语言层可解释推理与显式规范约束,复杂决策逻辑往往隐式地"被蒸馏"进网络权重。
- VLA(Vision--Language--Action)模型:以多模态大模型为核心进行 chain-of-thought 式推理并生成动作。优势是具备语言表达能力;局限是推理通常停留在语言空间,难以形成对感知与规划的硬约束(即"语言推理结果无法实质性改变量化感知/规划状态")。
1.2 KnowVal 的主张
KnowVal 旨在引入两个关键能力:
- 知识增强(knowledge augmentation):将交通法规、道德规范、防御性驾驶经验等组织为可检索的驾驶知识图谱,并以检索结果介入决策。
- 价值引导(value guidance / value alignment):通过训练一个 Value Model,对候选轨迹及其预测未来状态进行价值评估,使得系统能在多个可能未来中选择更符合人类偏好与社会规范的方案。
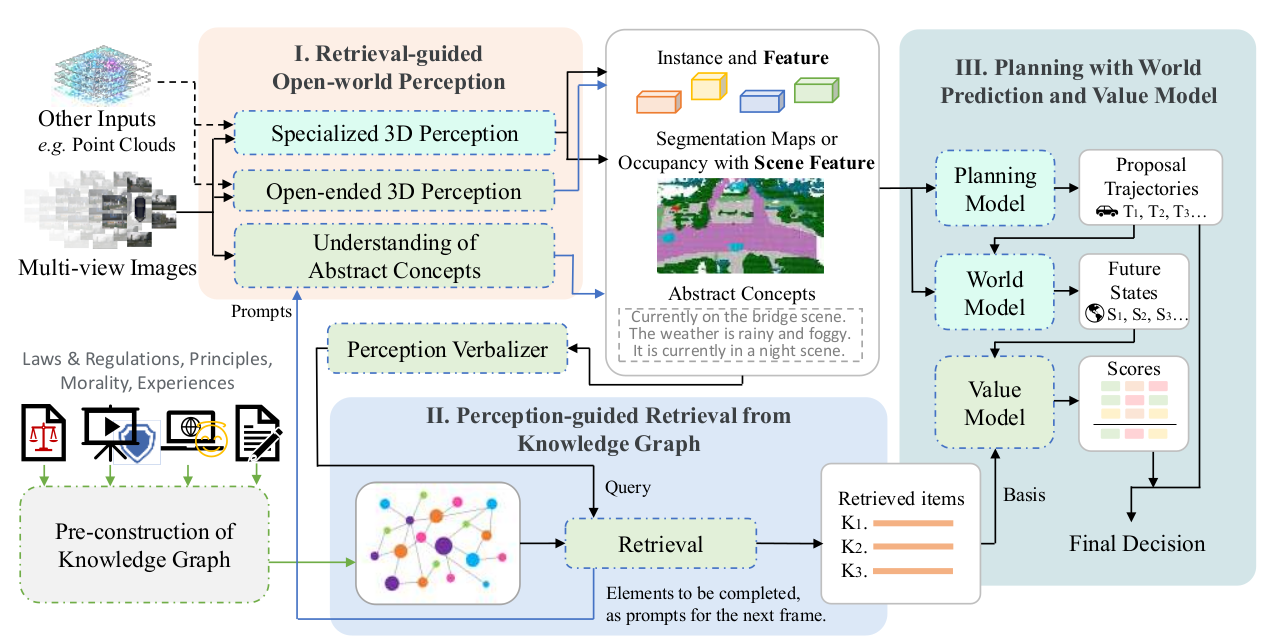
2. 系统总览(System Overview)
论文 Figure 2/4 给出统一架构,可抽象为三阶段流水线,并以特征/文本在模块间传播(feature propagation)实现信息闭环:
- Retrieval-guided Open-world Perception(检索引导开放世界感知)
- Perception-guided Retrieval from Knowledge Graph(感知引导知识图谱检索)
- Planning with World Prediction and Value Assessment(世界预测 + 价值评估的规划决策)
其中关键设计是:perception 与 retrieval 互导(mutual guidance)。
- 感知输出经 verbalizer 构成检索 query,从 KG 检索条款。
- 检索模块在返回条款的同时输出"待补全要素"(elements to be completed),作为下一时刻感知的针对性提示,从而形成跨时刻的闭环更新。
3. 知识图谱(Knowledge Graph)构建:Forest → Graph
本节对应论文 3.2.1。
3.1 设计目标
论文强调 KG 构建应满足两点:
- 原文保真(fidelity to original text):每条知识条款以原始文本存储,避免经典 RAG 对证据的"改写/压缩"导致事实漂移与幻觉(hallucination)。
- 显式语义连接(explicit semantic linkage):在保持原始层级结构的同时,通过实体节点将跨章节/跨来源的条款连接为图结构,提升检索召回与上下文覆盖。
3.2 Step 1:知识收集与 knowledge forest 构造
数据源包括(论文明确列举):
- 交通法规与监管条款(laws & regulations)
- 防御性驾驶教育视频提炼(principles extracted from educational videos on defensive driving)
- 司机访谈文本(driver interview transcripts)
- 道德/伦理指南(ethical guidelines)
组织形式:
- 法规天然具备 chapter/section/article 的树状层级,直接作为初始 forest backbone。
- 叶子节点(clause node)保存原文条款;非叶节点保存标题/描述信息。
- forest 中节点标注为 native(论文用语)。
3.3 Step 2:实体抽取与实体链接(Entity Linking)
目标是将"互不相交的多棵树"转为"高连通语义图"。论文流程为:
- 对每条 clause leaf,使用强 LLM(例如 GPT-4 或 Qwen)执行受控实体抽取。
- 实体类别为预定义概念集合(论文举例):
- Traffic-Sign-Device(信号控制装置:traffic signal, stop sign 等)
- Road-User(道路参与者:pedestrian, bicycle 等)
- Driving-Maneuver(驾驶动作:turning, merging 等)
- RoadCondition(道路条件:wet pavement, construction zone 等)
- 对每个唯一实体创建 entity node,并将其连接到包含该实体的所有 native clause node。
- LLM 为边分配语义权重与关系描述(semantic weights and relationship descriptions)。
- 受 LightRAG 启发,对 node/edge 生成多组 text keys(简短短语)用于高效索引检索。
3.4 KG 规模(论文附录硬指标)
附录 C "About the Knowledge Graph"给出当前图谱规模:
- 1,324 nodes
- 2,785 edges
该统计可作为复现 sanity check:若规模偏离显著,通常意味着知识源覆盖、实体抽取策略、实体去重/归一化策略存在差异。
4. 在线检索(Online Retrieval):从感知到 KG,再回流感知
本节对应论文 3.2.2。
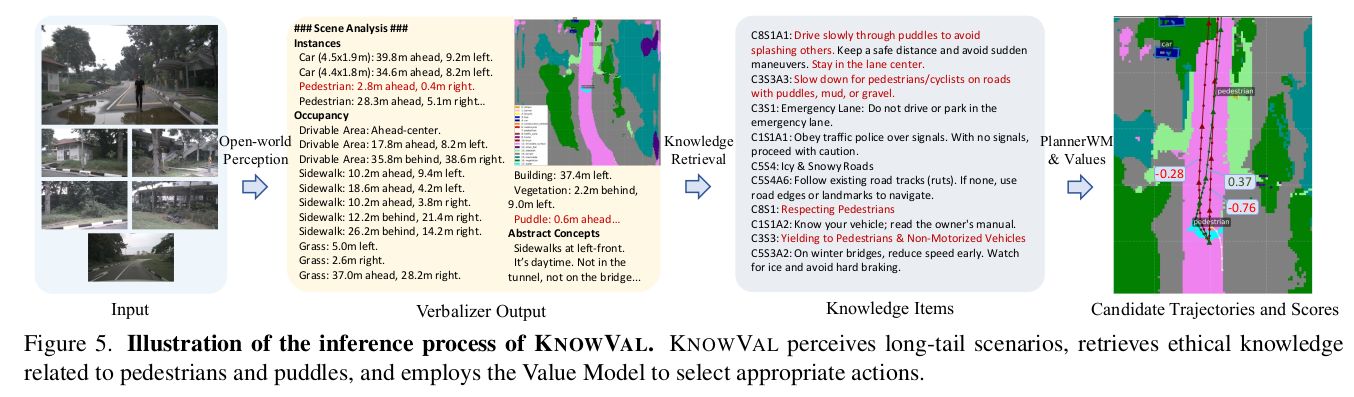
4.1 Perception Verbalizer:将多结构感知输出统一为检索 query
论文指出自动驾驶检索与对话式 RAG 的本体差异在于:检索驱动信号不是用户 prompt,而是感知结果。因此 KnowVal 在检索前引入 templated verbalizer:
- 对 3D instances:将 3D box 的空间位姿与语义类别转为文本描述。
- 对语义图/occupancy:先用 BFS(Breadth-First Search) 识别语义连通区域(connected blocks),并以动态 connectivity threshold 处理不连续边界,然后将区域位置与语义属性转为文本。
- 追加抽象概念(scene-level concepts)、导航信息(navigational data)、用户指令(user instructions)形成最终 retrieval query。
复现要点:verbalizer 决定 query 的结构稳定性与可解析性,进而决定检索一致性。建议以 schema-first 方式固定字段、单位、坐标系与离散化策略。
4.2 两层关键词抽取(Two-layer keyword extraction)
论文使用轻量 LLM 对 query 执行两层关键词抽取:
- 第一层:宏观上下文关键词(macro-level context),例如 Driving Security、Scene Analysis。
- 第二层:实体/事件关键词(entity and event keywords),例如 Pedestrians、Rainy Weather。
附录 B.2 给出关键词抽取 prompt 的关键要求:
- 输出语言参数化(
{language})。 - 输出格式含
record_delimiter/tuple_delimiter/completion_delimiter,便于工程解析。 - 同时抽取实体与实体关系(可用于构图与检索扩展)。
复现建议:实现稳定解析器,将 LLM 输出落为结构化 JSON;并提供 LLM 失败时的回退(规则/NER)。
4.3 图谱检索与 TopK 邻居扩展(Graph expansion)
论文检索流程要点:
- 使用抽取到的关键词匹配 KG 节点/边的 index keys,得到初始关联集合。
- 为捕获更丰富上下文,在图上执行 TopK nearest-neighbor expansion,纳入与初始节点强连接的邻近节点。
- 对候选条款按 importance 与 relevance 排序。
- 强约束:检索结果保持原文条款,避免对证据的改写导致幻觉。
4.4 检索输出与"互导"闭环
检索模块除了返回条款集合,还会输出:
- elements requiring additional perception:需要补全的感知要素
这些要素作为下一时刻感知模块(尤其是 VLM/开放世界感知)的提示输入,使感知与检索形成跨时刻闭环。
4.5 Listing 2(retrieval prompt)复刻状态
在当前 PDF 文本抽取结果中:
- 定位到 "Listing 2. The prompt used for retrieval"
- 仅保留模板壳:
Entity_types: [{entity_types}]Text: {input_text}Output:
但 Listing 2 的完整 prompt 正文缺失(疑似由于 PDF 排版/字体导致文本抽取丢失)。
若需 prompt 字符串级复刻,请提供 Listing 2 页的原文复制或截图,或在环境中安装更强 PDF 文本抽取工具后再补全。
5. 规划、世界预测与价值模型(Planner/World Model/Value Model)
本节对应 Figure 4 及论文 3.3(以及实现细节 4.2)。
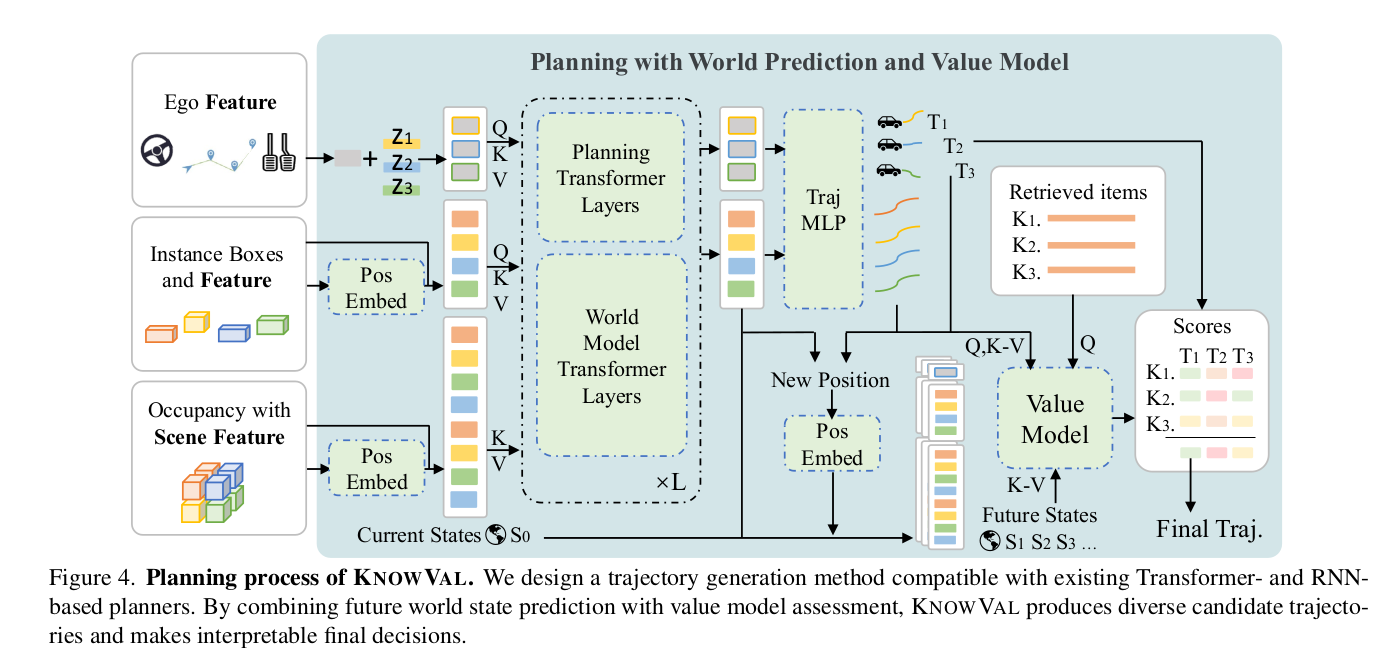
5.1 Planner 与 World Model 的功能耦合
论文指出:现有规划模块多为 Transformer 或 RNN,具备不同程度的未来预测能力。KnowVal 在此基础上扩展:
- Planner 生成多样化候选轨迹集合 {Ti}i=1NT\{T_i\}_{i=1}^{N_T}{Ti}i=1NT
- 同时预测每条轨迹对应的未来世界状态 {Si}\{S_i\}{Si}(world prediction)
这些未来状态随后进入 Value Model 进行价值评估。
5.2 Value Model:基于检索条款的 item-wise 价值评估
核心理念:仅有 world model 不能决定"哪个未来更 desirable",需要价值评估器。
论文给出 Value Model 形态:
- Transformer Encoder + MLP Decoder
- 对每条候选轨迹 TiT_iTi 与每条检索条款 KjK_jKj 进行 item-wise 评估,再聚合得到轨迹总分。
论文实现细节(4.2)给出关键推理超参:
- 检索条款数:NK=16N_K = 16NK=16
- 候选轨迹数:NT=20N_T = 20NT=20
- Value Model iterative reasoning steps:L=3L = 3L=3
- 价值聚合衰减因子:γ=0.7\gamma = 0.7γ=0.7
复现要点:Value Model 必须与条款级证据对齐,否则很容易退化为"额外一层黑箱打分器"。
5.3 Value Model 训练数据:偏好数据集与条款级 GT
论文构建人类偏好数据集用于训练 Value Model,并在附录 D 提到未来将公开数据集与模型。
附录 Listing 1 给出了用于构造 Value Model 数据集 GT 的 prompt(文本抽取可见其输出结构包含):
rule(条款)reasoning字段(positive/negative evidence, risk_level, conclusion)score(条款/轨迹对应评分)
该设计使 Value Model 训练信号具备"条款级可解释依据"。
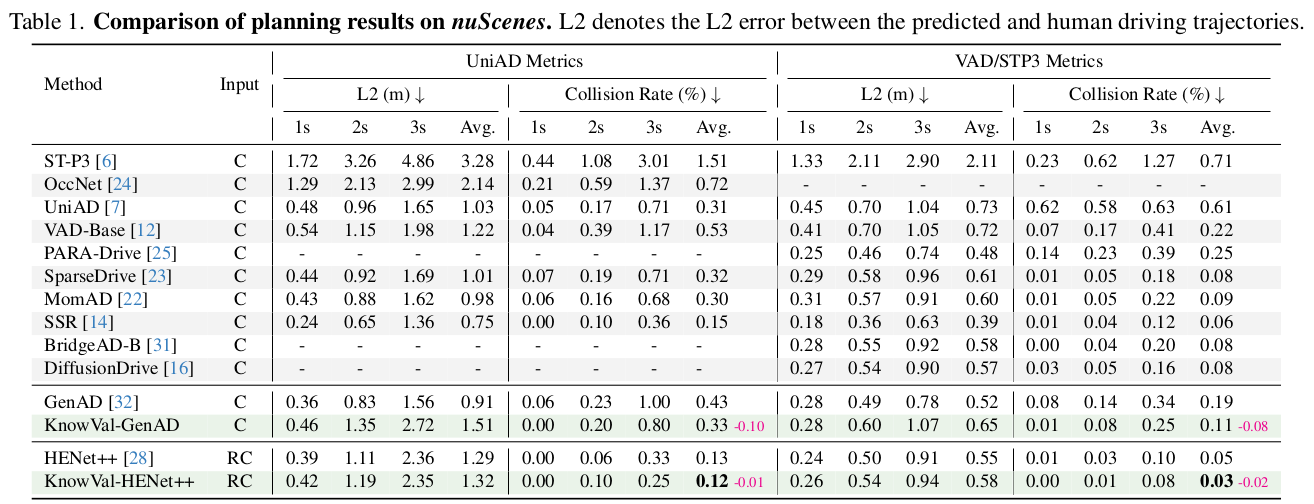
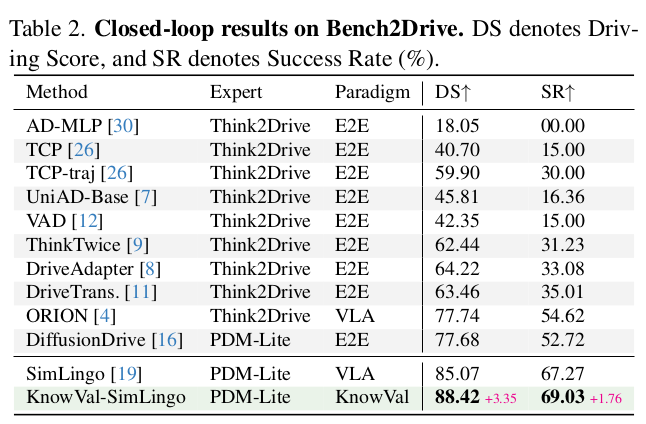
6. 实验设置与关键结果(nuScenes / Bench2Drive)
6.1 数据集与指标(论文 4.1)
- nuScenes :open-loop 评估
- 指标包含:规划轨迹与人类轨迹的 L2 误差(L2 error)、碰撞率(collision rate)
- Bench2Drive(B2D) :closed-loop 仿真评估
- Driving Score(Route Completion + Infraction Penalty)
- Success Rate(完成率)
6.2 实现与训练设置(论文 4.2)
- 检索与知识 embedding:Qwen2.5-3B
- 资源与训练轮次(用于复现预算):
- nuScenes:8×A100,finetune 3 epochs
- B2D:8×A100,finetune 1 epoch
- Value Model:8×V100,训练 50 epochs,AdamW + cosine schedule
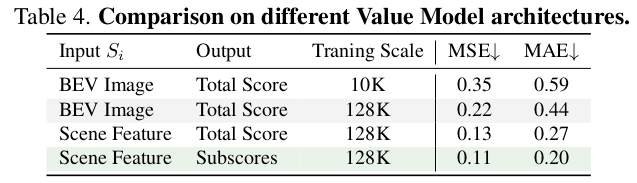
7. 消融研究(Ablation):KG 与 Value Model 的可量化贡献
论文 4.5 给出系统级消融(Table 3)与 Value Model 消融(Table 4)。
7.1 系统级消融结论(Table 3,论文原文总结)
论文明确结论:
- 引入 knowledge retrieval + value model (K&V),并同时加入 open-world perception、retrieval-guided supplementary perception(RgP),能够稳定降低碰撞率。
- 规划轨迹对人类轨迹的偏差(L2)可能略有增加,但论文强调这并不直接意味着规划质量下降,可能反映了"模仿人类"与"遵守法规/伦理/防御性策略"之间的策略偏移。
- 增大检索条款数量 NKN_KNK 与候选轨迹数量 NTN_TNT 在超过阈值后出现收益递减。
7.2 Value Model 架构消融(Table 4)
论文结论包括:
- 用 BEV 图像 + CNN 的 Value Model 具备与 baseline 解耦的优势,但预测性能较弱。
- 引入分解子分数(subscores)并做加权平均有助于降低误差。
- 数据规模从 10K 增至 128K 显著降低 MSE/MAE。
8. 复现清单(Replication Checklist)
本节给出"论文级复刻"的工程分解与验收标准。
8.1 必备模块与接口契约
- KG 构建
- 输入:法规/原则/访谈/伦理文本(可溯源)
- 输出:forest(原始层级)+ graph(实体节点与跨树连接)+ index keys
- 验收:节点/边规模接近 1324/2785;随机抽查条款原文保真。
- Perception Verbalizer
- 输入:instances + occupancy/semantic + abstract concepts + navigation
- 输出:结构化 query 文本
- 验收:同一场景多帧 query 稳定且可解析;对 occupancy 的 BFS 连通块抽取可复现。
- Keyword extraction / Entity extraction
- 方法:两层关键词抽取(macro + entity/event),并输出结构化结果
- 验收:抽取字段完整、解析稳定、LLM 失败可回退。
- Graph retrieval
- 方法:keys 命中 + TopK 邻居扩展 + relevance/importance 排序
- 输出:条款集合(原文)+ 待补全要素
- 验收:条款可追溯(节点 ID/来源);检索不改写证据。
- Planner/World Model
- 输出:候选轨迹 TiT_iTi + 对应未来状态 SiS_iSi
- 验收:候选多样性可控(与 NTN_TNT 对齐)。
- Value Model
- 输入:(Ti,Si)(T_i, S_i)(Ti,Si) 与条款 KjK_jKj 的条款级特征
- 输出:条款级评分 + 轨迹聚合总分
- 验收:与条款级 GT 一致(Listing 1 形式);能给出可解释依据。
8.2 关键超参复刻(论文 4.2)
- NK=16N_K = 16NK=16
- NT=20N_T = 20NT=20
- L=3L = 3L=3
- γ=0.7\gamma = 0.7γ=0.7
8.3 评测协议
- nuScenes:open-loop,报告 L2 与 collision rate
- Bench2Drive:closed-loop,报告 Driving Score 与 Success Rate
9. 讨论与局限(Limitations)
- 检索延迟与稳定性:在线检索引入 LLM 调用与图扩展,对车规级延迟与确定性提出挑战。
- KG 维护成本:跨域法规差异与长期更新需要持续的数据治理与版本控制。
- 评测指标缺口:论文指出现有 benchmark 对"违规但未碰撞"的行为不敏感,价值对齐改进可能被低估。
- Prompt 复刻完整性:当前文本抽取缺失 Listing 2 正文,导致检索 prompt 的字符串级复刻不完整。