1. R2R (room to room )benchmark
A navigation benchmark = scene dataset + simulator + task dataset
简单说就是集成了 算法 仿真器 和仿真任务评估的方式
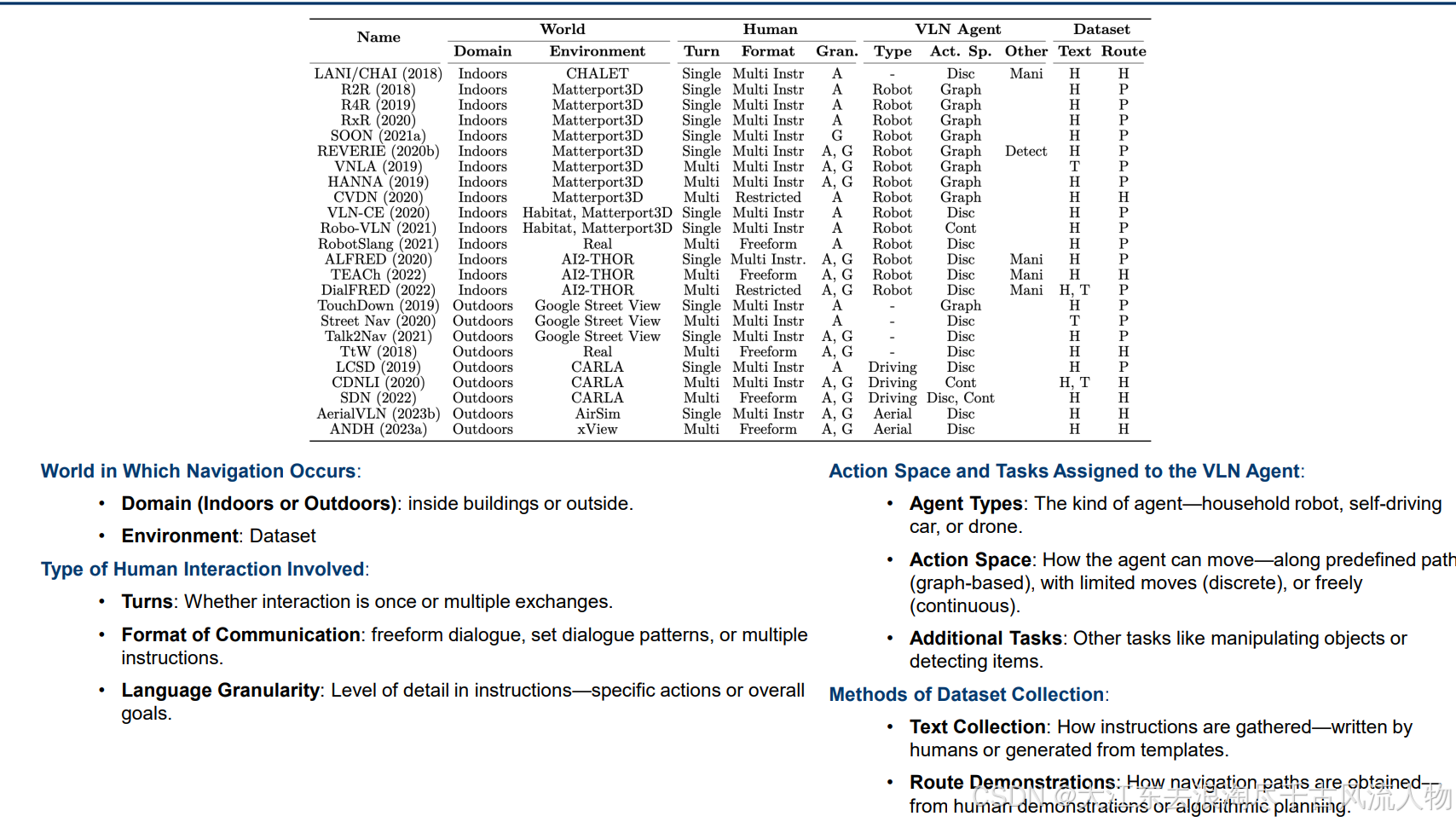
R2R(Room-to-Room)是视觉语言导航(VLN)领域首个、也是最经典的基准测试集,由场景数据集、仿真器、任务与评估体系构成,核心是让智能体在真实室内 3D 环境中,依据自然语言指令完成跨房间导航。
• R2R is based on the MP3D scene dataset,
• It uses the MP3D simulator,
• The navigation space is a pre-defined graph.
• It provides annotated instructions and path
R2R(Room-to-Room)是视觉语言导航(VLN)领域首个、也是最经典的基准测试集,由场景数据集、仿真器、任务与评估体系构成,核心是让智能体在真实室内3D环境中,依据自然语言指令完成跨房间导航。
1.1 核心构成(场景+仿真器+任务)
1. 场景数据集:Matterport3D
- 来源 :90栋真实建筑(住宅/办公/商业)的毫米级3D扫描数据。
- 数据形式:全景RGB-D图像、深度图、相机位姿、场景拓扑图(视点节点+连通边)。
- 特点:高真实感、室内布局复杂、包含家具/门窗/地标等视觉线索。
2. 仿真器:Matterport3D Simulator
- 功能:提供可交互的3D环境,支持智能体在视点间移动、获取全景视觉、执行动作。
- 动作空间 :
forward(前进)、left/right(转向)、up/down(俯仰)、stop(停止)。 - 交互逻辑:基于场景拓扑图,智能体只能在连通视点间移动,每次动作返回当前视点全景图。
3. 任务数据集(核心)
-
任务定义 :智能体从起点出发,理解自然语言指令,在未知建筑中导航到目标房间/位置。
-
数据规模与统计 :
项目 详情 路径总数 7,189 条(最短路径,≥5米,4--6个节点) 指令总数 21,567 条(每条路径配3条人工指令) 平均指令长度 29 词,词汇量约 3.1k 平均路径长度 10米,6个导航节点 数据集划分 train(61场景,14025指令)、val_seen(61场景,1020)、val_unseen(11场景,2349)、test(18场景,4173) -
指令特点 :人工标注,含地标参照 (如"穿过客厅")、方位描述 (如"左转")、动作序列,经第三方验证(路径偏差<3米)。
1.2 评估体系(核心指标)
- 成功到达率(SR):终点与目标距离<3米的比例(核心指标)。
- 路径长度(PL):实际路径长度与最优路径的比值(越小越好)。
- 导航误差(NE):终点与目标的平均距离(米)。
- 官方平台:EvalAI 提供测试集评估与排行榜。
1.3核心作用与价值
- 统一研究基准 :解决VLN早期"数据孤岛"问题,提供标准化场景、任务、评估,成为领域"ImageNet"。
- 推动跨模态融合 :强制模型同时处理视觉(全景图)、语言(指令)、动作(导航),促进CV+NLP+RL交叉研究。
- 验证泛化能力 :
val_unseen/test为全新场景,检验模型在未知环境的迁移能力。 - 催生算法创新:作为基线,推动VLN模型从早期seq2seq(ResNet+LSTM)发展到Transformer、强化学习、预训练等方案。
- 落地应用基础 :为家用服务机器人、AR导航、室内智能体等提供仿真训练与评估环境。
1.4 与后续扩展集的关系
- R4R/R8R:更长路径、更复杂指令的R2R扩展。
- RxR:多语言、多模态指令的大规模VLN基准。
- FGR2R:将指令拆分为子指令,提供细粒度视觉-语言对齐标注。
需要我帮你整理一份R2R数据集的快速上手清单 (含仿真器安装、数据加载、基线模型运行与评估指标计算的关键命令与代码片段)吗?
举例如下
2. Scene Dataset 真实数据集和仿真数据集
Type of scene datasets
• Scan and then reconstruction: MP3D, HM3D
• Synthetic scene datasets: HSSD, ProcTHOR
Links:
MP3D: https://niessner.github.io/Matterport/
HM3D: https://aihabitat.org/datasets/hm3d/
HSSD: https://3dlg-hcvc.github.io/hssd/
ProcTHOR: https://procthor.allenai.org/
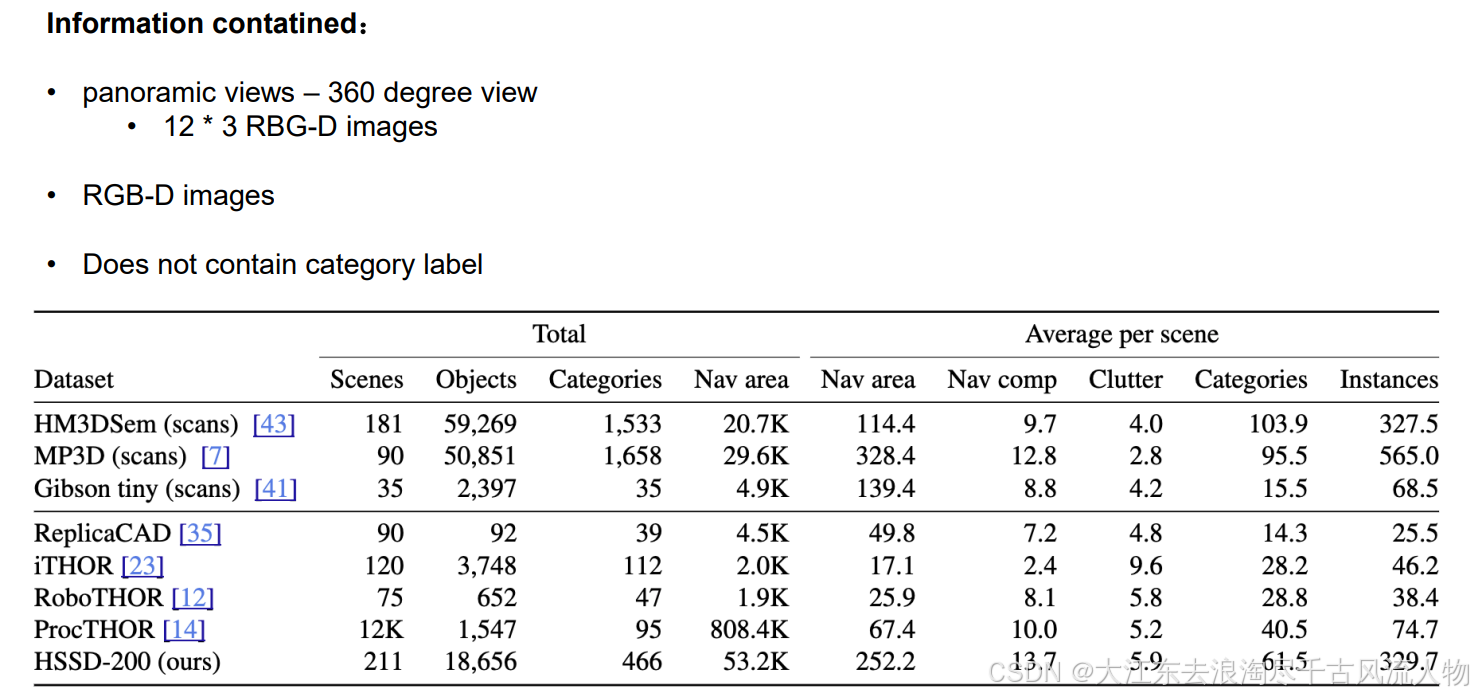
2.1 MP3D-- The one R2R uses 真实数据集特点解析
2.2 MP3D 模拟器(Matterport3D Simulator)总结
| 模块 | 核心内容 |
|---|---|
| 核心特点(Core Features) | 1. 将场景离散化为拓扑图(Discretize scenes into a topological graph) 2. 智能体仅能通过图中的节点进行导航(Agent navigates only through graph nodes) |
| 仿真观测空间(Simulation Observation Space) | 1. 12张RGB-D图像(每张视场角30°) 2. 当前空间位置 3. 附近可导航点(按与当前朝向的角度排序,第一个点为当前位置) |
| 仿真动作空间(Simulation Action Space) | 1. 选择一个附近的可导航点(可以停留在当前点) 2. 选择目标旋转角度 ⚠️ 视觉语言导航(VLN)任务要求智能体在目标位置执行STOP动作 |
| 模型动作空间(Model Action Space) | 1. 底层动作:前进(Move forward)、左转(turn left)、右转(turn right)、抬头(look up)、低头(look down)、停止(stop) 2. 可导航点/方向选择 |
2.3 任务执行流程(Task Execution Process)

任务执行流程(Task Execution Process)
| 阶段 | 英文描述 | 中文翻译 |
|---|---|---|
| 初始化(Initialization) | - Receive a language instruction (L) of length (T) (x = \langle x_1, x_2, ..., x_L \rangle) - Start at initial position (s_0 = \langle v_0, \psi_0, \theta_0 \rangle) (3D position: xyz, rotation, elevation) | - 接收一条长度为 (T) 的语言指令 (L) (x = \langle x_1, x_2, ..., x_L \rangle) - 从初始位置出发 (s_0 = \langle v_0, \psi_0, \theta_0 \rangle)(3D位置:xyz坐标、旋转角、俯仰角) |
| 首次动作(First Action) | Capture an RGB image (s_0) and generate the first action (a_0). | 采集一张RGB图像 (s_0) 并生成第一个动作 (a_0)。 |
| 动作执行(Action Execution) | - Each action (a_t) moves the agent to a new position: (s_{t+1} = \langle v_{t+1}, \psi_{t+1}, \theta_{t+1} \rangle) - Obtain new observation (s_{(t+1)}). | - 每个动作 (a_t) 会将智能体移动到新位置: (s_{t+1} = \langle v_{t+1}, \psi_{t+1}, \theta_{t+1} \rangle) - 获取新的观测信息 (s_{(t+1)})。 |
| 动作序列(Action Sequence) | Execute a series of actions: (\langle s_0, a_0, s_1, a_1, ..., s_T, a_T \rangle) | 执行一系列动作: (\langle s_0, a_0, s_1, a_1, ..., s_T, a_T \rangle) |
| 成功条件(Success Condition) | Perform "Stop" action within 3m of the target point. | 在目标点3米范围内执行"停止"动作。 |

2.4 语言指令的来源与数据集详情
1. 指令收集(Instruction Collection)
- 预先定义一条导航路径,由人类对这条路径进行详细描述。
- 在 R2R 数据集中,路径相对较短,但描述十分详尽。
2. 数据集统计(Dataset Statistics)
- 共收集 21,567 条语言指令。
- 指令平均长度:29 个单词。
- 同一条路径可能对应多条不同的语言指令。
R2R 数据集格式(R2R Dataset Format)
- 每个任务单元(episode)是一个三元组:
(\langle \text{Instruction}, \text{Image}, \text{Action Sequence} \rangle)
(指令、图像、动作序列) - 支持离线训练,可直接利用已有数据进行模型训练。
3. Simulators
3.0 表格对比
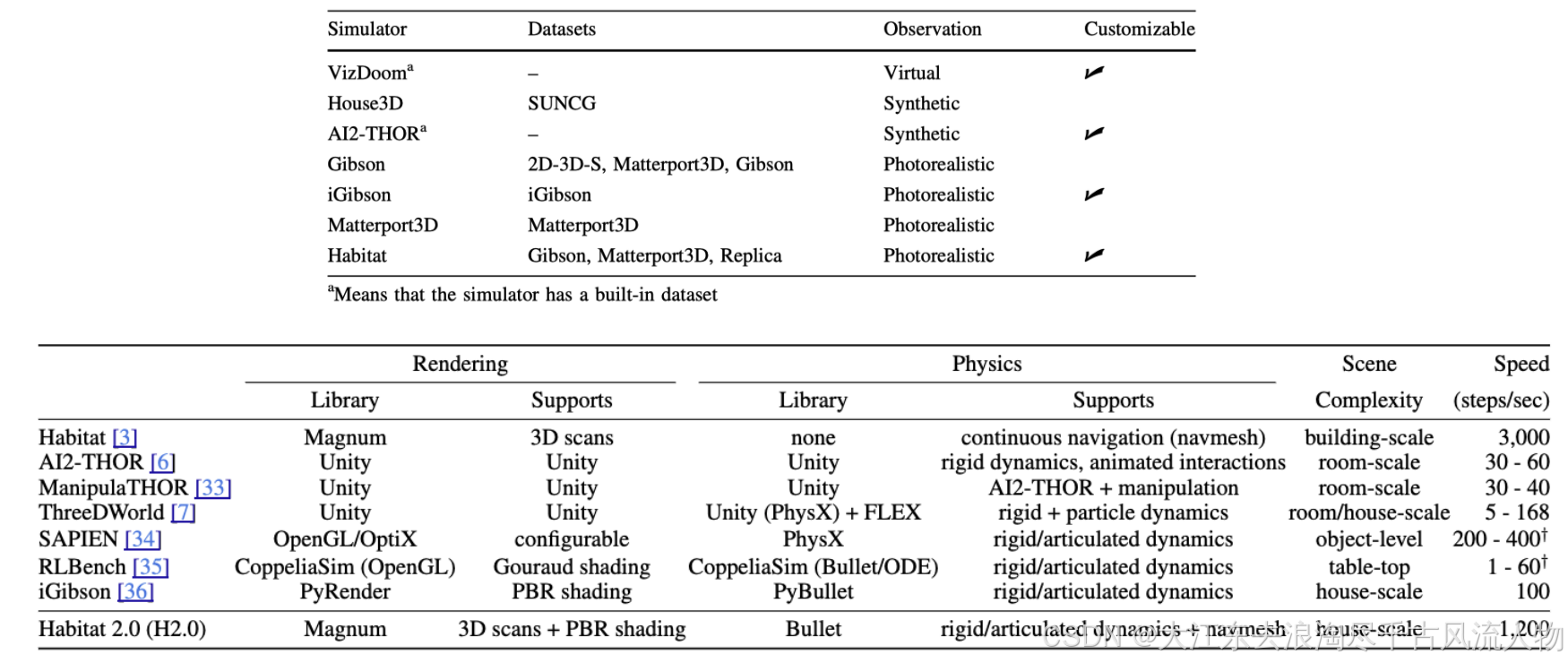
3.1 Habitat、MP3D、R2R、AI-THOR、ProcTHOR 关系对照表
| 项目 | 定位 | 在视觉语言导航(VLN)中的作用 | 与其他项目的关系 |
|---|---|---|---|
| Habitat | 具身智能仿真平台 | 提供高性能3D环境渲染、传感器模拟和智能体交互能力,是运行VLN任务的"引擎" | 支持 MP3D、HM3D、ProcTHOR 等场景数据集,可运行 R2R 等 VLN 任务 |
| MP3D(Matterport3D) | 真实场景数据集 | 提供真实建筑扫描的3D场景数据(拓扑图、全景图等),是VLN任务的"真实虚拟世界" | 是 Habitat 的核心场景数据源,也是 R2R 任务的场景支撑 |
| R2R(Room-to-Room) | 视觉语言导航基准任务 | 提供标注好的语言指令、路径和评估标准,是VLN任务的"考题" | 基于 MP3D 场景构建,可在 Habitat 或 AI-THOR 平台上运行 |
| AI-THOR | 交互式3D具身智能仿真平台 | 基于Unity引擎,提供高质量视觉与物理模拟,支持导航、交互等任务,是另一个"仿真引擎" | 与 Habitat 定位相似,支持 ProcTHOR 等合成场景数据集,可运行 VLN 任务 |
| ProcTHOR | 大规模程序化合成场景数据集 | 通过算法生成大量室内场景,是VLN任务的"合成虚拟世界" | 可被 Habitat 和 AI-THOR 加载,用于训练和评估智能体的泛化能力 |
3.2 具身智能仿真平台对比表
| 项目 | 定位 | 核心特点 | 适用场景 |
|---|---|---|---|
| AI-THOR | 交互式3D具身智能仿真平台 | 基于Unity引擎,提供高质量视觉与物理模拟;专注固定环境中的交互任务;可扩展性较弱 | 室内场景交互、物体操作、视觉语言导航 |
| Habitat | 具身智能仿真平台 | 专为导航与探索优化;渲染性能高,但缺乏高保真物理模拟 | 视觉语言导航(VLN)、目标导航、大规模场景探索 |
| Isaac Suite (Lab/Gym/Sim) | NVIDIA 推出的机器人仿真与强化学习工具集 | 基于Omniverse平台,支持GPU加速;结合高保真物理模拟、可扩展性与多环境并行能力;Isaac Gym已停止维护,由Isaac Lab替代 | 机器人运动控制、强化学习训练、复杂物理交互任务 |
3.3 关键能力对比表
| 能力维度 | AI-THOR | Habitat | Isaac Suite |
|---|---|---|---|
| 物理模拟 | 中高保真 | 基础 | 高保真 |
| 渲染性能 | 高 | 高 | 高(GPU加速) |
| 可扩展性 | 较弱 | 高 | 极高(支持数千环境并行) |
| 导航任务优化 | 支持 | 深度优化 | 支持 |
| 交互任务支持 | 深度优化 | 基础 | 深度优化 |
| 强化学习支持 | 支持 | 支持 | 深度优化 |
| 与ROS集成 | 不支持 | 不支持 | 支持 |
3.4 具身智能仿真平台选型决策表
| 决策维度 | Habitat | AI-THOR | Isaac Suite |
|---|---|---|---|
| 核心任务匹配 | ✅ 视觉语言导航(VLN)/场景探索(深度优化,配套R2R等基准任务) 🆗 支持基础交互/物体操作 | ✅ 室内交互/物体操作(交互能力强,物理模拟成熟) 🆗 支持VLN(场景规模较小) | ✅ 机器人运动控制/强化学习训练(高保真物理、GPU加速、ROS集成) 🆗 支持复杂物理交互任务 |
| 性能与规模 | 🆗 高可扩展性 🆗 极致渲染速度(专为导航优化) 🔶 物理模拟基础 | 🔶 可扩展性较弱 🆗 高保真物理模拟(适合日常交互) 🆗 高质量渲染 | ✅ 大规模并行训练(支持数千环境并行) ✅ 高保真物理模拟(专业级引擎) ✅ GPU加速渲染 |
| 配套资源 | ✅ 成熟VLN基准任务(R2R、RxR等) 🆗 兼容ProcTHOR合成场景 | ✅ 支持ProcTHOR合成场景 🔶 无原生VLN基准任务 | ✅ ROS与机器人工具链集成 🔶 无原生VLN基准任务 |
4. Benchmarks
4.1 VLN Benchmark 构成结构
VLN Benchmark
Scene
Task
Agent
Indoor
Outdoor
Instruction
Task Goal
Short instruction
Detailed instruction
Dialogue
Path following
Find object
Discrete navigation space
Continuous navigation space
4.1.1 Overview of Benchmarks
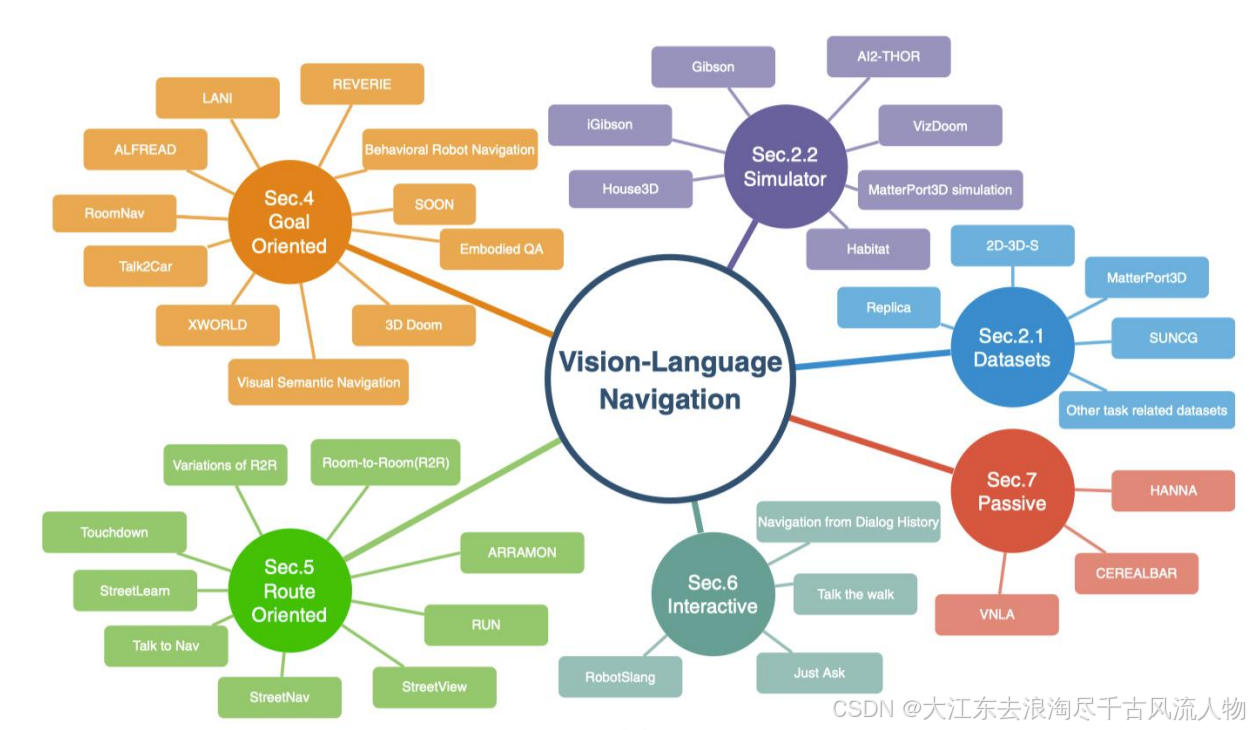
4.1.2 Timeline of Benchmarks
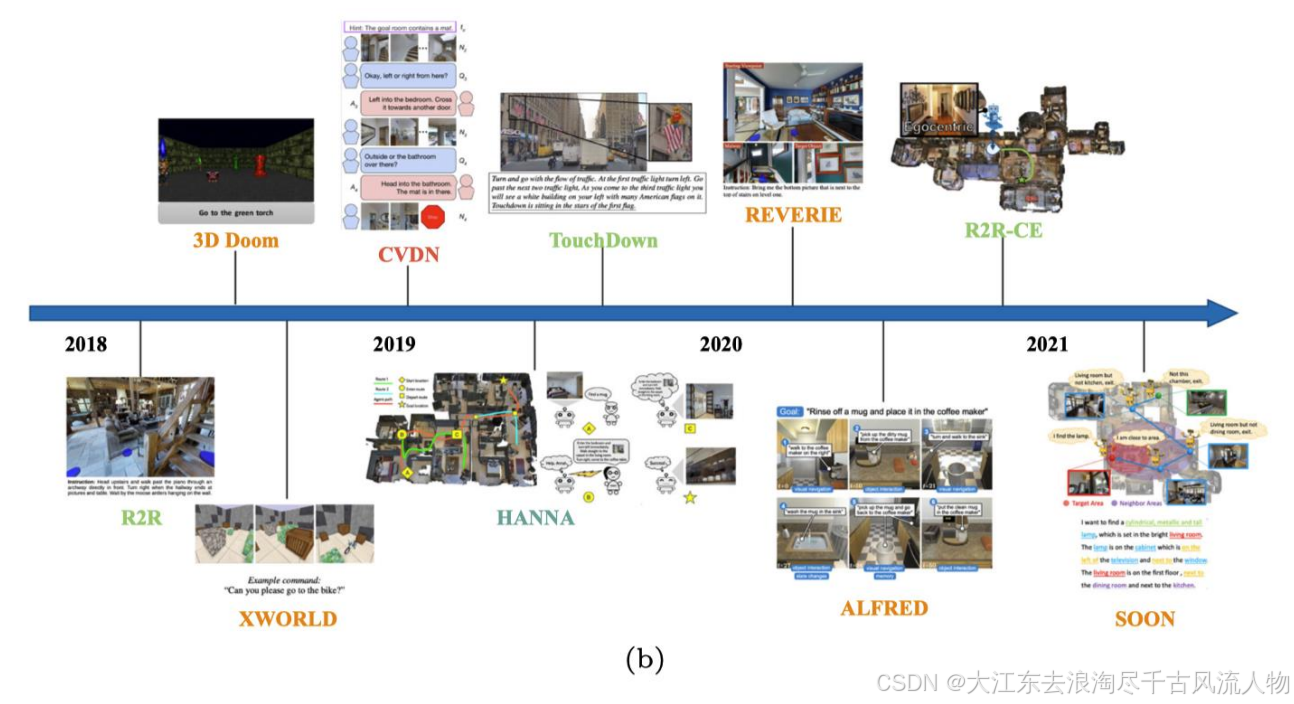
4.2 Summary of Benchmarks
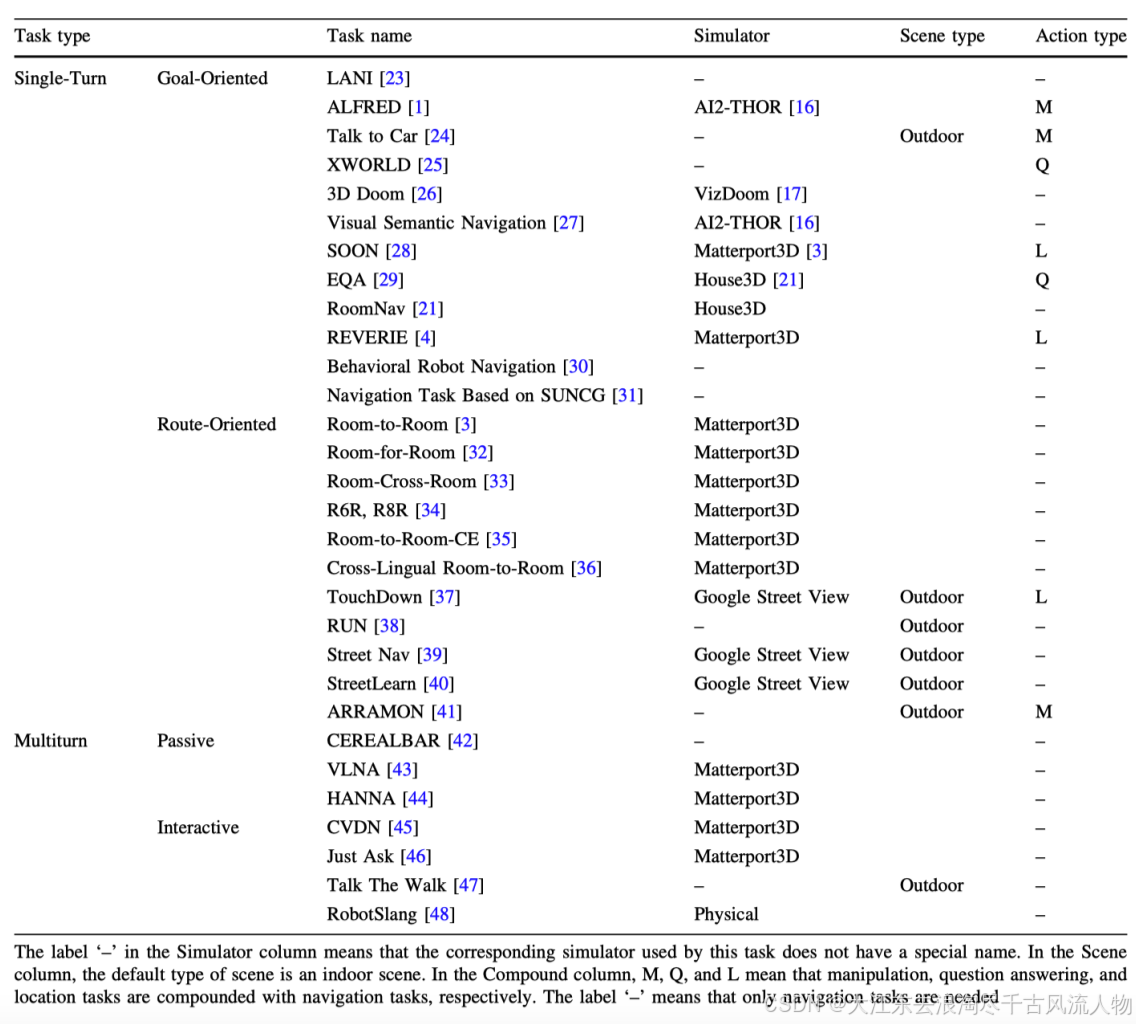
4.2.1 R*R Serious
| 任务名称 | 目标 | 实现方式 | 意义 |
|---|---|---|---|
| R4R (Room-for-Room) | 让 R2R 的路径更长、难度更高 | 将多条 R2R 路径组合成 3 倍长度的复杂路线 | 测试智能体在长且曲折的路径上导航而不犯错的能力 |
| RxR (Room-across-Room) | 为 R2R 增加多语言支持(英语、印地语、泰卢固语) | 收集 12.6 万条带人类分步示例的指令 | 帮助智能体理解不同语言的指令及细节,提升多语言泛化能力 |
| Landmark-RxR | 在 RxR 中加入地标(如沙发、桌子等) | 指令中包含地标信息来引导智能体 | 帮助智能体利用物体地标更快定位,提升导航效率和鲁棒性 |
4.2.2 VLN-CE 中文核心信息表
| 模块 | 中文内容 |
|---|---|
| 什么是 VLN-CE? | 目标:训练 AI 智能体在真实的 3D 环境(如住宅)中,通过自由移动而非固定路径来遵循语言指令。 核心思路:移除预先生成的地图或传送等"捷径",模拟真实世界中机器人面临的挑战。 |
| VLN-CE 核心特性 | 1. 无固定路径 - 智能体需逐步移动(例如"左转 15°"、"前进 0.25 米") - 不允许在预定义节点间传送 2. 路径更长、难度更高 - 平均路径包含 55 个动作(而在 R2R 等早期基准中仅为 4--6 步) - 路径长度是早期基准的 3 倍,且更复杂 3. 数据集 - 基于 R2R 数据构建,但针对连续移动进行了调整 - 包含 4,475 条带有人工编写指令的路径 |
| VLN-CE 的重要性 | - 面向真实机器人 :让 AI 为真实世界任务做好准备(没有固定地图等捷径) - 更严格的测试:迫使智能体真正去导航(而不是仅仅跟随地图) |
4.2.3 REVERIE
| 模块 | 中文内容 |
|---|---|
| 什么是 REVERIE? | 目标:训练 AI 智能体在 3D 住宅环境中,通过高层语言指令(例如"把沙发旁边的靠垫拿给我")找到并指向目标物体。 |
| 核心特性 | 1. 一站式双任务 - 导航至目标房间 - 用边界框识别出正确的物体 2. 真实世界复杂度 - 初始状态下目标物体不可见 - 指令简短实用(无分步导航指引) 3. 数据集 - 包含 86 个真实 3D 住宅中的 21,702 条指令 - 共 4,140 个物体(涵盖椅子、灯具等 489 个类别) - 划分为训练集、验证集(已见/未见场景)和隐藏测试集 |
| 成功规则 | - 正确识别物体:选择正确的边界框 - 3米范围内:智能体必须位于目标物体3米以内 - 仅一次机会:智能体不能进行多次尝试 |
| 评估指标 | 1. 远程定位成功率(RGS) - 核心指标:智能体找到并正确识别目标物体的任务占比 2. 导航指标 - 成功率(SR):成功到达目标的任务占比 - SPL:结合路径效率加权的成功率 - 路径长度(PL):平均移动距离 |
| REVERIE 为何具有挑战性 | - 无分步指引:指令较为模糊(例如"找到床附近的台灯") - 贴近真实场景:模拟人类向机器人求助的实际方式 - 未知住宅环境:在全新场景中测试,验证智能体的泛化能力 |
| 与其他基准的区别 | - R2R/VLN:侧重详细的导航指令 - REVERIE:将导航与物体识别结合,使用高层指令 |
4.3 不同的 beanchmarks 特点说明
| 任务名称 | 中文说明 |
|---|---|
| TOUCHDOWN | - 基于纽约市真实街景图像的城市街道导航任务 - 场景为室外,因视觉多样性导致任务更复杂 |
| SOON | - 智能体仅通过物体描述,在住宅中寻找目标物体,无给定路线 - 要求智能体自主规划路线并探索环境 |
| VNLA | - 智能体在室内环境中导航以寻找物体,导航过程中会持续获得指令 - 任务提供导航中的实时引导 |
| CVDN | - 智能体通过与人类向导的历史对话来导航至目标 - 依赖多轮对话辅助完成导航 |
| RoomNav | - 指令为前往特定类型的房间(如"去厨房"),智能体需自主找到目标房间 - 要求理解房间类型,无引导路径 |
4.4 其他类型的beanchmarks
| 任务名称 | 中文说明 |
|---|---|
| Just Ask | - 当智能体不确定时,可以向人类向导提问以获取信息 |
| Talk the Walk | - 游客与向导通过对话在虚拟城市中导航并抵达目的地的任务 - 基于双智能体对话,场景为室外城市环境 |
| EQA | - 智能体探索环境以回答问题 - 强调通过探索和推理来解答问题 |
| LANI | - 智能体在简单的合成环境中遵循指令抵达目标 - 聚焦于在简单场景下将指令映射为动作 |
| HANNA | - 智能体接收"寻找物体"等简单指令并导航定位 - 强调智能体在极少指令下自主决策路径 |
4.5未来发展方向
- 统一且真实的任务与平台
- 增加操作能力(如物体抓取、交互)
- 动态环境(环境中的物体或场景会变化)
- 从室内拓展到室外
5. VLN基准任务-仿真平台整合速查表
| 任务名称 | 场景 | 任务类型 | 核心特点 | 适配仿真平台 | 适配说明 |
|---|---|---|---|---|---|
| R2R | 室内 | 导航 | 短路径、详细分步指令、固定节点传送 | Habitat、AI-THOR | Habitat原生支持,AI-THOR需通过适配工具对接 |
| R4R | 室内 | 导航 | 路径为 R2R 的 3 倍长度、路线曲折、无分步指引 | Habitat | 基于R2R扩展,Habitat原生支持,无需额外适配 |
| VLN-CE | 室内 | 导航 | 无固定路径、连续移动、无传送、长路径(55 个动作) | Habitat | Habitat官方优化任务,内置配置文件,可直接运行 |
| REVERIE | 室内 | 导航 + 交互 | 导航至目标房间并识别物体、高层指令、初始物体不可见 | Habitat | 需加载物体识别相关配置,适配边界框标注功能 |
| SOON | 室内 | 导航 + 交互 | 仅通过描述寻找物体、自主规划路线 | Habitat、AI-THOR | 适配场景数据集(MP3D/ProcTHOR)即可运行 |
| VNLA | 室内 | 导航 | 导航中持续获得指令、实时引导 | Habitat | 需配置实时指令输入接口,适配多轮指令接收逻辑 |
| CVDN | 室内 | 导航 + 交互 | 基于多轮对话导航、历史对话辅助 | Habitat | 需集成对话处理模块,加载历史对话数据集 |
| RoomNav | 室内 | 导航 | 前往特定类型房间、理解房间类型 | Habitat、AI-THOR | 需适配房间类型标注数据,支持房间类别识别 |
| Just Ask | 室内 | 导航 + 交互 | 不确定时可向人类提问 | Habitat | 需集成提问接口与人类反馈接收逻辑,支持动态交互 |
| LANI | 室内(合成) | 导航 | 简单合成环境、指令映射为动作 | Habitat、AI-THOR | 适配简单合成场景数据集,指令-动作映射逻辑简单 |
| HANNA | 室内 | 导航 + 交互 | 极少指令下自主决策路径、寻找物体 | Habitat | 需优化少样本指令理解模块,增强自主路径规划能力 |
| TOUCHDOWN | 室外 | 导航 | 纽约市真实街景、视觉多样性高 | 专用室外仿真平台 | 需加载真实街景数据集,适配室外场景渲染与导航逻辑 |
| Talk the Walk | 室外 | 导航 + 交互 | 双智能体对话导航、虚拟城市环境 | 专用室外仿真平台 | 需集成双智能体对话模块,适配室外城市场景数据集 |
| EQA | 室内 / 室外 | 问答 + 探索 | 探索环境以回答问题、强调推理能力 | Habitat、专用室外平台 | 需集成问答推理模块,适配室内外不同场景的探索逻辑 |