文章目录
- [CS336 作业 4(数据):语言模型数据过滤](#CS336 作业 4(数据):语言模型数据过滤)
-
- [1 作业概述](#1 作业概述)
- [2 过滤 Common Crawl 数据集](#2 过滤 Common Crawl 数据集)
-
- [2.1 数据初探](#2.1 数据初探)
-
- [问题(数据初探):4 分](#问题(数据初探):4 分)
- [2.2 HTML 转文本转换](#2.2 HTML 转文本转换)
-
- [问题(文本提取):3 分](#问题(文本提取):3 分)
- [2.3 语言识别](#2.3 语言识别)
-
- [问题(语言识别):6 分](#问题(语言识别):6 分)
- [2.4 2.4 Personal identifiable information](#2.4 2.4 Personal identifiable information)
-
- [问题(个人身份信息掩码):3 分](#问题(个人身份信息掩码):3 分)
- [2.5 有害内容](#2.5 有害内容)
- [2.6 Quality Rules](#2.6 Quality Rules)
- [2.7 质量分类器 Quality Classifier](#2.7 质量分类器 Quality Classifier)
- [3 去重](#3 去重)
-
- [3.1 精确行去重](#3.1 精确行去重)
- [3.2 MinHash + LSH 文档去重](#3.2 MinHash + LSH 文档去重)
- 问题(minhash_deduplication):8分
- [4 排行榜:为语言建模筛选数据](#4 排行榜:为语言建模筛选数据)
- 问题(filter_data):6分
- 问题(inspect_filtered_data):4分
- 问题(tokenize_data):2分
- 模型训练
- 问题(train_model):2分
CS336 作业 4(数据):语言模型数据过滤
版本 1.0.4
CS336 课程组
2025 年春季
1 作业概述
本次作业中,你将获得过滤网络爬虫数据以构建语言模型训练数据的实践经验。
需实现的内容
- 将通用爬虫(Common Crawl)的 HTML 数据转换为文本。
- 使用多种方法过滤提取的文本(例如,有害内容、个人身份信息等)。
- 对训练数据进行去重处理。
需运行的内容
- 在不同数据集上训练语言模型,以更好地理解特定处理决策对模型性能的影响。
代码结构
所有作业代码及本说明文档均可在 GitHub 上获取:
github.com/stanford-cs336/assignment4-data
请克隆该代码仓库。若有更新,我们会通知你,你可通过 git pull 获取最新版本。
cs336-basics/*:该文件夹包含作业 1 中构建的模型训练代码。该模型已进行轻微优化,将作业 1 中部分手工编写的组件替换为 PyTorch 原生对应组件(例如,使用 PyTorch 内置的交叉熵核)。我们还提供了支持多 GPU 分布式数据并行训练的训练脚本。你将使用该脚本在过滤后的数据集上训练模型,并参与排行榜提交------后续会详细说明。cs336_data/*:这是你将编写作业 4 代码的目录。我们创建了一个名为cs336_data的空模块。注意该目录初始无任何代码,你可从零开始实现所需功能。tests/*.py:包含所有必须通过的测试用例。这些测试会调用tests/adapters.py中定义的接口。你需要实现这些接口,将你的代码与测试用例关联。编写更多测试或修改测试代码有助于调试你的实现,但你的代码需能通过原始提供的测试套件。README.md:该文件包含预期的目录结构详情,以及环境配置的基本说明。
提交方式
需向 Gradescope 提交以下文件:
writeup.pdf:回答所有书面问题,要求排版规范。code.zip:包含你编写的所有代码。
若要提交至排行榜,请向以下仓库提交拉取请求(PR):github.com/stanford-cs336/assignment4-data-leaderboard
详见排行榜仓库中的 README.md 以获取详细提交说明。
2 过滤 Common Crawl 数据集
大型语言模型主要基于互联网数据训练,但大多数研究人员不会为模型训练数据构建专属网络爬虫,而是使用公开可用的爬虫数据集。最受欢迎的公开网络爬虫数据集来自 Common Crawl------一家非营利组织,提供免费的网页语料库,涵盖"17 年间的超 2500 亿个网页"¹。¹https://commoncrawl.org/
然而,将 Common Crawl(CC)数据转储转换为可用的语言模型训练数据需要大量工作。例如,网页原始数据为 HTML 格式,我们需要从中提取文本;此外,许多网页可能质量低下、存在完全或近乎重复的内容、包含有害信息或敏感数据,因此我们需要过滤掉这些网页,或从数据集中移除内容中不符合要求的部分。本次作业中,你将搭建一个包含多个处理步骤的流水线,将原始互联网数据转换为可用的语言模型训练集。
2.1 数据初探
在开始实现任何功能前,查看原始数据并建立初步认知总是有益的。CC 数据提供三种格式:
- WARC("Web 归档格式 - Web ARChive format")文件:包含原始 CC 数据,具体包括页面 ID、URL、元数据和 HTTP 请求详情(例如,请求日期和时间、服务器 IP 地址),以及网页原始内容(例如,HTML)。
- WAT("Web 归档转换 - Web Archive Transformation"")文件:包含从 WARC 文件中提取的高层级元数据,以 JSON 对象形式存储。例如,对于 HTML 页面,包含该页面的链接列表和页面标题。
- WET("Web 提取文本 - Web Extracted Text")文件:包含从原始 HTML 页面中提取的纯文本。
针对以下问题,我们将查看一个 WARC 文件及其对应的 WET 文件。这些文件来自 2018 年 4 月的爬虫数据集,可通过以下命令下载:
bash
# 下载示例 WARC 文件
$ wget https://data.commoncrawl.org/crawl-data/CC-MAIN-2025-18/segments/1744889135610.12/warc/CC-MAIN-20250417135010-20250417165010-00065.warc.gz
# 下载对应的 WET 文件
$ wget https://data.commoncrawl.org/crawl-data/CC-MAIN-2025-18/segments/1744889135610.12/wet/CC-MAIN-20250417135010-20250417165010-00065.warc.wet.gz在 Together 集群中,这些文件位于以下路径:
/data/CC/example.warc.gz/data/CC/example.warc.wet.gz
警告:这些文件包含完全未过滤的互联网页面,可能包含大量潜在有害内容。若遇到不想阅读的文档,可直接滚动跳过。
问题(数据初探):4 分
(a) 下载上述 WARC 文件,或使用集群中提供的副本。查看该文件中的第一个页面。该文件为 gzip 压缩格式,可通过以下命令浏览内容:
bash
$ zcat /data/CC/example.warc.gz | lessless 命令支持使用键盘方向键、Page Up、Page Down 浏览文件,按"q"退出。查看第一个网页,其 URL 是什么?该 URL 仍可访问吗?通过查看原始 HTML,你能判断该页面大致主题是什么?
- 提交要求:2-3 句话的回答。
答:从WARC-Target-URI: http://0371rykj.com/ipfhsb/34.html中可以看到这个链接;打开是空白网页。看文本内容可知,它原来是"上海林頻儀器股份有限公司"的网址。
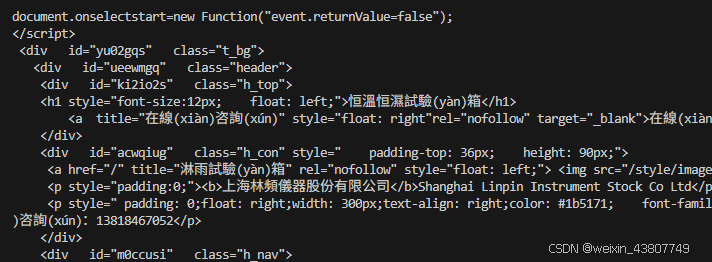
(b) 查看对应的 WET 文件:
bash
$ zcat /data/CC/example.warc.wet.gz | less注意,WET 文件包含 HTTP 头(例如,Content-Length),这些不属于提取的文本内容。查看第一个示例,你会发现其中包含从刚才看到的原始 HTML 中提取的文本。
注意到,提取的文本中很大一部分带有 HTML 结构的痕迹,并非页面的核心内容。你认为提取器应过滤掉文本中的哪些部分?从训练数据质量的角度思考:使用此类文本训练模型可能会出现什么问题?相反,模型可能从该页面中提取到哪些有用信息?
- 提取器应过滤掉HTML标签、脚本代码、样式表、导航菜单、页眉页脚等非正文内容。直接使用含HTML结构的文本训练,会导致模型学习到无关的标记模式,降低对自然语言的理解能力,并可能产生包含HTML片段的不良输出。但从这类页面中,模型仍可能提取到技术术语、产品描述等特定领域的词汇和概念。
© 优质训练样本的定义具有极强的场景相关性。请描述一个该示例可能对其训练数据有用的应用领域,以及一个可能无用的应用领域。
- 提交要求:1-2 句话的回答。
(d) 查看更多示例以更好地了解 Common Crawl 的数据内容。浏览另外 25 个 WET 记录,对每个记录简要说明文档的语言(若能识别)、域名、页面类型等信息。需要查看多少个示例才能找到一个你认为的"高质量"网页?
- 提交要求:对 25 个文档的简要标注(包括语言、域名、页面类型及其他相关说明),以及找到高质量示例所需的浏览数量。
2.2 HTML 转文本转换
从之前对 WARC 和 WET 文件的查看中,你可能已经意识到从 HTML 中提取文本具有一定挑战性。通常,任何提取流程都会查找 HTML 中的可见内容(例如,本应包含文本块的 <p> 标签),但这仍可能提取出远超我们在网页浏览器中打开页面时所感知的核心内容的信息。例如,打开 Stack Overflow 时,核心内容是问题和回答,但从技术上讲,菜单选项、指向其他 Stack Exchange 无关页面的链接、页脚、注册或登录链接------这些均为可见文本,而要可靠地将其与页面核心内容区分开具有一定难度。
许多工具都实现了文本提取流水线。本次作业中,我们将使用 Resiliparse² 库执行文本提取。Resiliparse 还能帮助解决一个更基础的问题:检测包含原始内容的字节数据的文本编码。尽管互联网上大多数页面采用 UTF-8 编码(根据维基百科,占比 98.2%),但我们的文本提取流水线仍需对其他编码具有鲁棒性。²https://resiliparse.chatnoir.eu/en/stable/index.html
注意:建议使用 FastWARC 库迭代处理每个 WARC 文件中的记录。以下类可能会有所帮助:
python
from fastwarc.warc import ArchiveIterator, WarcRecordType问题(文本提取):3 分
(a) 编写一个函数,从包含原始 HTML 的字节字符串中提取文本。使用 resiliparse.extract.html2text.extract_plain_text 执行提取。该函数需要输入字符串,因此你需要先将字节字符串解码为 Unicode 字符串。注意,输入字节字符串可能并非 UTF-8 编码,因此当 UTF-8 解码失败时,你的函数应能检测编码。Resiliparse 提供的 resiliparse.parse.encoding.detect_encoding() 可能会有所帮助。
- 提交要求:一个接收包含 HTML 的字节字符串并返回提取文本字符串的函数。实现接口
[run_extract_text_from_html_bytes],并确保通过测试uv run pytest -k test_extract_text_from_html_bytes。
python
from fastwarc.warc import ArchiveIterator, WarcRecordType
from resiliparse.extract.html2text import extract_plain_text
from resiliparse.parse.encoding import detect_encoding
def extract_text_from_html_bytes(html_bytes: bytes) -> str | None:
encoding = detect_encoding(html_bytes)
html_str = html_bytes.decode(encoding, errors='ignore')
# 从包含原始HTML字节字符串中提取文字
text = extract_plain_text(html_str)
return text(b) 在单个 WARC 文件上运行你的文本提取函数,将其输出与对应的 WET 文件中的提取文本进行比较。你发现了哪些差异和/或相似之处?哪种提取结果更好?
- 提交要求:2-3 句话的回答,对比你的函数提取的文本与 WET 文件中的提取文本。
2.3 语言识别
网络包含数以千计语言编写的页面。然而,在计算资源有限的条件下,训练一个能有效利用如此多样化大规模数据的多语言模型仍然面临挑战。因此,许多基于Common Crawl构建的语言模型训练数据集往往仅涵盖有限语种的数据。
fastText(https://fasttext.cc)是一个实用的库,提供高效的文本分类器。该库既提供了在自定义数据上训练分类器的框架,也包含一系列预训练模型,包括语言识别模型。你可从 https://fasttext.cc/docs/en/language-identification.html 下载 fastText 语言识别模型 lid.176.bin;该模型在 Together 集群中也可通过路径 /data/classifiers/lid.176.bin 获取。
通常,语言过滤器会使用分类器给出的分数来决定是否保留某个页面。使用 fastText 语言识别分类器实现一个语言识别过滤器,该过滤器应返回一个非负分数,表示其对预测结果的置信度。
问题(语言识别):6 分
(a) 编写一个函数,接收一个 Unicode 字符串并识别其中的主要语言。该函数应返回一个元组,包含语言标识符和一个 0 到 1 之间表示预测置信度的分数。
- 提交要求:一个执行语言识别并返回顶级语言预测结果及分数的函数。实现接口
[run_identify_language],并确保通过uv run pytest -k test_identify_language中的两个测试。注意,这些测试假设英语("en")和中文("zh")有特定的字符串标识符,因此你的测试接口需根据需要执行相应的映射。
python
from typing import Any
import fasttext
import numpy as np
def identify_language(text: str) -> tuple[Any, float]:
model = fasttext.load_model("/home/zzz1/codes/cs336/assignment4-data-main/cs336_data/data/classifiers/lid.176.bin")
text = text.replace("\n", " ")
labels, prob = model.predict(text)
language_code = labels[0].replace("__label__", "")
if isinstance(prob, np.ndarray):
prob = float(prob[0])
else:
prob = float(prob)
return language_code, prob
if __name__ == "__main__":
text = "Hello, how are you?"
label, prob = identify_language(text)
print(f"Label: {label}, Probability: {prob:.4f}")(b) 语言模型在推理时的行为很大程度上取决于其训练数据。因此,数据过滤流水线中的问题可能会导致后续出现问题。你认为语言识别流程中可能会出现哪些问题?在高风险场景(例如,部署面向用户的产品时),你会如何缓解这些问题?
- 提交要求:2-5 句话的回答。
对低资源语言识别准确率低、混合语言文本误判、含噪声文本(如代码、特殊符号)导致错误分类,以及训练数据偏差造成的系统性偏见。在高风险场景中,可采取以下缓解措施:对识别结果设置置信度阈值并在低置信时触发人工审核或回退机制。
© 在通过你之前实现的文本提取函数从 WARC 文件中提取的文本上运行你的语言识别系统。手动识别 20 个随机示例的语言,并将你的标签与分类器预测结果进行比较。报告分类器的任何错误。有多少比例的文档是英语?基于你的观察,在过滤时应使用什么合适的分类器置信度阈值?
- 提交要求:2-5 句话的回答。
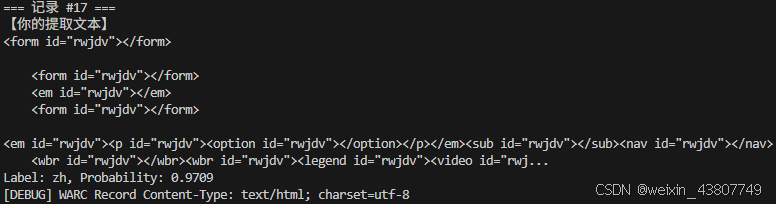
这种数据居然被识别成中文。。。
2.4 2.4 Personal identifiable information
互联网包含大量可用于联系或识别个人的信息,例如电子邮件地址、电话号码或 IP 地址。我们不希望面向用户的语言模型输出有关真实个人的此类信息,因此常见的处理步骤是在训练数据集中对这些信息进行掩码处理。
你需要实现三种掩码处理流程,分别用于掩码(a)电子邮件地址、(b)电话号码和(c)IP 地址。
问题(个人身份信息掩码):3 分
- 编写一个掩码电子邮件地址的函数。该函数接收一个字符串作为输入,将所有电子邮件地址替换为字符串 "|||EMAIL_ADDRESS|||"。可通过查找可靠的正则表达式来检测电子邮件地址。
- 提交要求:一个将输入字符串中所有电子邮件地址替换为 "|||EMAIL_ADDRESS|||" 的函数,返回包含新字符串和掩码实例数量的元组。实现接口
[run_mask_emails],并确保通过uv run pytest -k test_mask_emails中的所有测试。
-
编写一个用于屏蔽电话号码的函数。该函数接收一个字符串作为输入,并将其中所有电话号码替换为字符串"|||PHONE_NUMBER|||"。要可靠地完成这一任务可能极具挑战性,因为电话号码的书写格式极其多样。但你至少应能识别并处理美国最常用的电话号码格式,并对轻微的语法变体(如不同的分隔符或空格)具有鲁棒性。
交付成果 :编写一个函数,将给定字符串中的电话号码替换为"|||PHONE_NUMBER|||",返回包含新字符串和被屏蔽实例数量的二元组。实现适配器 run_mask_phone_numbers,并确保通过uv run pytest -k test_mask_phones测试。 -
编写一个屏蔽 IP 地址的函数。本题仅需关注 IPv4 地址(4 个不超过 255 的数字,以点分隔)。函数接收字符串作为输入,将所有 IPv4 地址替换为"|||IP_ADDRESS|||"。
交付成果 :编写一个函数,将给定字符串中的 IPv4 地址替换为"|||IP_ADDRESS|||",返回包含新字符串和被屏蔽实例数量的二元组。实现适配器 run_mask_ips,并确保通过uv run pytest -k test_mask_ips测试。
python
import regex as re
def mask_emails(text: str) -> tuple[str, int]:
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
matches = re.findall(email_pattern, text)
masked_text = re.sub(email_pattern, "|||EMAIL_ADDRESS|||", text)
return masked_text, len(matches)
def mask_phones(text: str) -> tuple[str, int]:
# 匹配美国手机号码的各种格式 (宽松规则以通过测试)
# 包括: 2831823829, (283)-182-3829, (283) 182 3829, 283-182-3829
pattern = r'''
\b[2-9]\d{9}\b |
\([2-9]\d{2}\)-\d{3}-\d{4} |
\([2-9]\d{2}\)\s\d{3}\s\d{4} |
[2-9]\d{2}-\d{3}-\d{4}
'''
compiled_pattern = re.compile(pattern, re.VERBOSE)
masked_text, count = compiled_pattern.subn("|||PHONE_NUMBER|||", text)
return masked_text, count
def mask_ips(text: str) -> tuple[str, int]:
# 精确匹配 IPv4 的正则(每段 0-255)
ip_pattern = r'\b(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b'
# 使用 subn() 同时完成替换和计数
masked_text, count = re.subn(ip_pattern, "|||IP_ADDRESS|||", text)
return masked_text, count- 若在训练集中简单应用这些过滤器,你认为可能会给语言模型后续带来哪些问题?如何缓解这些问题?
交付成果:2-5 句话的回答。
问题: 在训练数据中简单地把电话、IP 等直接替换成固定占位符(如
|||PHONE_NUMBER|||),会导致:
- 模型学不会真实格式和上下文用法;
- 推理时可能乱生成占位符或无法生成合法号码/IP;
- 技术语义(如
127.0.0.1)丢失,影响专业任务。缓解方法(简单有效): ✅ 用保留格式的假数据替换,例如:
- 电话 →
(555) 123-4567(北美保留号段)- IP →
192.0.2.1(IANA 文档专用地址)这样既保护隐私,又保持语言结构和语义,模型训练更自然、推理更准确。
- 在从 WARC 文件提取的文本上(通过你之前实现的文本提取函数)运行个人身份信息(PII)屏蔽函数。随机查看 20 个已进行替换的示例;给出一些误报和漏报的案例。
交付成果:2-5 句话的回答。
2.5 有害内容
未经筛选的网络数据包含大量文本,我们不希望语言模型在推理时重复这些内容。其中一些训练示例甚至可能来自通常无害的网站(如维基百科)------例如,用户在多个页面留下的评论可能具有较强的毒性。尽管很难为"有害内容"划定明确界限,但许多数据筛选流程仍会对主要包含有害内容的页面进行筛选。
识别此类内容的方法有很多,包括统计禁用词列表中的词汇数量,或基于人工标注的标签构建简单分类器。在本作业的这一部分,我们将重点识别两大类有害内容:"不适合工作场景(NSFW)"(包括色情内容、亵渎性语言或其他可能令人不适的内容)和有毒言论("粗鲁、无礼或不合理的语言,可能导致他人退出讨论"³)。我们将使用 Dolma 项目 Soldaini 等人,2024 提供的预训练 fasttext 模型,判断输入文本是否属于上述任一类别。这些分类器在 Jigsaw 有毒评论数据集上训练而成,该数据集包含多种标签分类的维基百科评论⁴。
NSFW 分类器可通过以下链接下载:
仇恨言论分类器可通过以下链接下载:
我们也已将这两个分类器放置在 Together 集群中:
- /data/classifiers/dolma_fasttext_hatespeech_jigsaw_model.bin:用于仇恨言论和有毒言论的预训练分类器
- /data/classifiers/dolma_fasttext_nsfw_jigsaw_model.bin:用于 NSFW 内容的预训练分类器
³https://current.withgoogle.com/the-current/toxicity/
⁴https://paperswithcode.com/dataset/toxic-comment-classification-challenge
请使用这些模型实现一个函数,该函数接收包含页面内容的 Unicode 字符串,返回标签(如"有毒""无毒")及置信度分数。
题目(有害内容):6 分
-
编写一个检测 NSFW 内容的函数。
交付成果 :编写一个函数,判断给定字符串是否包含 NSFW 内容,返回包含标签和置信度分数的二元组。实现适配器 run_classify_nsfw,并确保通过uv run pytest -k test_classify_nsfw测试。注意,该测试仅为合理性检查(取自 Jigsaw 数据集),绝不代表你的分类器准确无误,你应对其准确性进行验证。 -
编写一个检测有毒言论的函数。
交付成果 :编写一个函数,判断给定字符串是否为有毒言论,返回包含标签和置信度分数的二元组。实现适配器 run_classify_toxic_speech,并确保通过uv run pytest -k test_classify_toxic_speech测试。同样,该测试仅为合理性检查(亦取自 Jigsaw 数据集)。 -
若将这些过滤器应用于训练集构建,你认为可能会给语言模型后续带来哪些问题?如何缓解这些问题?
交付成果:2-5 句话的回答。 -
在从 WARC 文件提取的文本上(通过你之前实现的文本提取函数)运行有害内容过滤器。随机查看 20 个示例,将分类器预测结果与你自己的判断进行比较。报告分类器的任何错误。有害文档占比多少?基于你的观察,筛选时应使用何种合适的分类器置信度阈值?
交付成果:2-5 句话的回答。
2.6 Quality Rules
即使经过语言筛选和有害内容移除,剩余页面中仍有相当一部分对语言模型训练而言质量较低。同样,"质量"的定义并不明确,但查看 Common Crawl 示例有助于识别低质量内容,例如:
- 付费墙内容页面
- 失效链接的占位符页面
- 登录、注册或联系表单
- 主要包含非文本内容的页面(如图片、视频),这些内容在文本提取过程中会丢失
Gopher 论文 Rae 等人,2021 描述了一组简单的质量过滤器,用于从网络爬取数据中移除类似的简单低质量文本案例。这些过滤器由易于理解的启发式规则组成,通常能覆盖许多明显不适合作为训练数据的示例。Gopher 质量过滤器包含多个基于文档长度、单词长度、符号与单词比率以及特定英语停用词存在情况的标准。在本作业中,你将实现 Gopher 论文 Rae 等人,2021 中描述的部分过滤器。具体而言,你应移除以下文档:
- 单词数少于 50 或多于 100,000 的文档。
- 平均单词长度超出 3 至 10 个字符范围的文档。
- 超过 30% 的行以省略号("...")结尾的文档。
- 包含至少一个字母的单词占比低于 80% 的文档。
有关 Gopher 论文使用的所有质量过滤器的完整描述,请参阅其附录 A。
题目(Gopher 质量过滤器) :3 分
(a) 实现(至少)上述描述的 Gopher 质量过滤器子集。将文本分词为单词时,你可能会发现 NLTK 包(特别是 from nltk.tokenize import word_tokenize)很有用,但不强制要求使用该包。
交付成果 :编写一个函数,仅接收一个字符串作为参数,返回一个布尔值,指示该文本是否通过 Gopher 质量过滤器。实现适配器 run_gopher_quality_filter。然后,确保你的过滤器通过 uv run pytest -k test_gopher 中的测试。
注意,如果使用nltk的话,需要先下载一个模型 nltk.download('punkt_tab')
(b) 在从 WARC 文件提取的文本上(通过你之前实现的文本提取函数)运行基于规则的质量过滤器。随机查看 20 个示例,将过滤器预测结果与你自己的判断进行比较。评论过滤器判断与你个人判断不一致的情况。
交付成果:2-5 句话的回答。
2.7 质量分类器 Quality Classifier
现在,我们超越 Gopher 规则所捕捉的简单语法质量标准。语言模型训练并非首个需要对内容进行质量排序的场景。特别是在信息检索中,文本质量也是一项核心挑战。搜索引擎利用的经典信号之一是网络链接结构:高质量页面往往倾向于链接到其他高质量页面Page等人,1998。OpenAI在构建GPT-2Radford等人,2019训练数据集WebText时也采用了类似思路:他们收集了Reddit评论中超过最低"karma"阈值所链接的页面。除了Reddit,维基百科可作为高质量链接的替代来源,因为维基百科页面引用的外部资源通常是可信页面Touvron等人,2023。
虽然使用受控来源通常能获得高质量内容,但按现今标准,由此构建的数据集规模仍偏小(OpenWebText仅40GB文本,而The Pile数据集规模是其20倍以上)。一种解决方案是:将这些参考页面作为正样本,将Common Crawl中的随机页面作为负样本,训练一个fastText分类器。该分类器可给出质量评分,用于在整个Common Crawl中筛选页面。通过设置质量阈值,可以在精确率和召回率之间进行权衡。
在本作业的这一部分,你将构建一个质量分类器。为方便起见,我们已从最近的维基百科数据转储中提取了参考页面的 URL,并将其放置在 Together 集群的 /data/wiki/enwiki-20240420-extracted_urls.txt.gz 路径下⁵。该文件包含截至 2024 年 4 月在英文维基百科页面上发现的 4350 万个外部链接,但我们希望你对这些 URL 进行子采样,以获取用于训练分类器的"高质量"文本正例。请注意,这些正例可能仍包含不良内容,因此可能需要应用你已构建的其他基本工具(如语言识别、筛选规则等)进一步提高其质量。给定一个 URL 文件,你可以使用 wget 以 WARC 格式爬取其内容:
wget ---timeout=5 \
-i subsampled_positive_urls.txt \
--warc-file=subsampled_positive_urls.warc \
-O /dev/null⁵维基百科参考 URL 也可通过以下链接下载:https://nlp.stanford.edu/data/nfliu/cs336-spring-2024/assignment4/enwiki-20240420-extracted_urls.txt.gz。
题目(质量分类器) :15 分
(a) 训练一个质量分类器,给定文本后返回数值型质量分数。
交付成果:一个用于下一子题的质量分类器。
(b) 编写一个函数,将页面标记为高质量或低质量,并提供该标签的置信度分数。
交付成果 :编写一个函数,仅接收一个字符串作为参数,返回包含标签(高质量或非高质量)和置信度分数的二元组。实现适配器 run_classify_quality。作为合理性检查,请运行 uv run pytest -k test_classify_quality,确保其能正确分类我们提供的两个示例。
3 去重
网络中存在大量重复内容。有些页面是完全重复的------例如存档页面,或由标准工具生成的默认页面(如热门 Web 服务器的 404 页面)。但大多数重复发生在更细粒度的层面。例如,考虑 Stack Overflow 上的所有问题页面。虽然每个页面都有独特内容(如问题、评论、答案本身),但所有页面都包含大量冗余内容(如页眉、菜单选项和页脚),当所有此类页面被渲染时,这些冗余内容会以完全相同的形式重复出现。在本节的第一部分,我们将处理此类完全重复,之后将探讨如何处理近似重复。
3.1 精确行去重
消除精确重复的一种简单方法是仅保留文档中在语料库中唯一的行。这被证明足以消除大部分冗余(如我们之前提到的页眉和菜单选项)。在较简单的情况下,移除在其他地方完全重复的行后,我们通常会得到每个页面的唯一主要内容(如 Stack Overflow 上的问题和答案)。要实现这一点,我们可以先遍历语料库一次,统计每行的出现次数。然后在第二次遍历时,通过仅保留每个文档的唯一行来重写文档。 naive 做法下,用于存储计数器的数据结构所需的空间可能与存储语料库中所有唯一行所需的空间相当。一个简单的内存优化技巧是使用行的哈希值作为键,使键具有固定大小(而非依赖行的长度)。现在请你实现这种简单的去重方法。
题目(精确去重) :3 分
编写一个函数,接收输入文件的路径列表,并对其执行精确行去重。该函数应首先使用哈希值减少内存占用,统计语料库中每行的频率,然后重写每个文件,仅保留其唯一行。
交付成果 :一个执行精确行去重的函数。你的函数应接收两个参数:(a) 输入文件的路径列表;(b) 输出目录。函数应将每个输入文件重写到输出目录中,文件名保持不变,但通过移除在输入文件集中出现次数超过一次的行来对内容进行去重。例如,若输入路径为 a/1.txt 和 a/2.txt,输出目录为 b/,则函数应生成文件 b/1.txt 和 b/2.txt。实现适配器 run_exact_line_deduplication,并确保通过 uv run pytest -k test_exact_line_deduplication 测试。
3.2 MinHash + LSH 文档去重
精确去重有助于移除多个网页中逐字重复的内容,但无法处理文档内容略有差异的情况。例如,考虑软件许可文档------许可文档通常基于模板生成,仅需填写年份和软件作者姓名。因此,一个 MIT 许可项目的许可文件与另一个 MIT 许可项目的许可文件内容大致相同,但并非完全重复。要移除此类重复的、主要为模板化的内容,我们需要模糊去重。为高效执行文档级模糊去重,我们将使用 MinHash 结合局部敏感哈希(LSH)⁶。⁶有关 LSH 和 MinHash 的更深入探讨,请参阅 Leskovec 等人 2014 的第 3 章。该章节可在线查阅:infolab.stanford.edu/ullman/mmds/ch3n.pdf。
要执行模糊去重,我们需要采用特定的文档相似度定义:每个文档的 n 元语法集合之间的杰卡德相似度(Jaccard similarity)。集合 S 和 T 之间的杰卡德相似度定义为 ∣ S ∩ T ∣ / ∣ S ∪ T ∣ |S \cap T| / |S \cup T| ∣S∩T∣/∣S∪T∣。 naive 的模糊去重方法是将每个文档表示为 n 元语法集合,计算所有文档对之间的杰卡德相似度,若相似度超过特定阈值,则将该文档对标记为重复。然而,这种方法对于大型文档集合(如 Common Crawl)并不实用。此外,naive 存储 n 元语法集合所需的内存远大于存储文档本身。
MinHash(最小哈希) :为解决内存问题,我们将文档的 n 元语法集合表示替换为签名。具体而言,我们希望构建这样的签名:比较两个文档的签名即可近似得到它们的 n 元语法集合之间的杰卡德相似度。MinHash 签名满足这一特性。要计算文档 n 元语法集合 S = { s 1 , . . . , s n } S = \{s_1, ..., s_n\} S={s1,...,sn} 的 MinHash 签名,我们需要 k 个不同的哈希函数 h 1 , . . . , h k h_1, ..., h_k h1,...,hk⁷。每个哈希函数将一个 n 元语法映射到一个整数。给定哈希函数 h i h_i hi,文档 n 元语法集合 S 的 MinHash 定义为 m i n h a s h ( h i , S ) = m i n ( h i ( s 1 ) , h i ( s 2 ) , . . . , h i ( s n ) ) minhash(h_i, S) = min(h_i(s_1), h_i(s_2), ..., h_i(s_n)) minhash(hi,S)=min(hi(s1),hi(s2),...,hi(sn))。文档 n 元语法集合 S 的签名是一个 R k \mathbb{R}^k Rk 中的向量,其中第 i 个元素为 S 在随机哈希函数 h i h_i hi 下的 MinHash,即 m i n h a s h ( h 1 , S ) \[minhash(h_1, S) \[minhash(h1,S), minhash ( h 2 , S ) , . . . , (h_2, S), ..., (h2,S),...,minhash ( h k , S ) (h_k, S)] (hk,S)]。
⁷这 k 个不同的哈希函数可以来自同一函数族,但使用不同的种子。例如,MurmurHash3 是一个哈希函数族,使用特定种子即可实例化该族中的一个特定哈希函数。
实践证明,对于两个文档的 n 元语法集合 S 1 S_1 S1 和 S 2 S_2 S2,集合之间的杰卡德相似度可通过具有相同 MinHash 值的列的比例来近似(证明见 Leskovec 等人,2014 年著作第 3 章 3.3.3 节)。例如,给定文档签名 1, 2, 3, 2 和 5, 2, 3, 4,n 元语法集合之间的杰卡德相似度近似为 2 / 4 2/4 2/4,因为这两个签名的第 2 列和第 3 列具有相同的 MinHash 值。
局部敏感哈希(LSH) :尽管 MinHash 为我们提供了内存高效且保留文档对期望相似度的文档表示,但我们仍需比较所有文档对以找到相似度最高的文档。LSH 提供了一种高效的方法,将可能具有高相似度的文档分入同一个桶中。要将 LSH 应用于我们的文档签名(现为 R k \mathbb{R}^k Rk 中的向量),我们将签名划分为 b 个带(band),每个带包含 r 个 MinHash 值,满足 (k = b \times r)。例如,若我们有 100 维的文档签名(由 100 个随机哈希函数生成),我们可以将其(MinHash签名)划分为多个桶组(band),例如每组50个最小哈希值的2个桶组、每组25个最小哈希值的4个桶组,或每组2个最小哈希值的50个桶组等。若两个文档在某个特定桶组中的哈希值完全一致,则它们会被聚类到同一个存储桶(bucket)中,并被视为候选重复文档。因此,在签名数量固定的情况下,增加桶组数量会提高召回率(recall),但会降低精确率(precision)。
为具体说明上述原理,假设文档 D 1 D_1 D1的MinHash签名为1, 2, 3, 4, 5, 6,文档 D 2 D_2 D2的MinHash签名为1, 2, 3, 5, 1, 2。若采用3个桶组(每组包含2个最小哈希值),则 D 1 D_1 D1的第一个桶组为1, 2、第二个桶组为3, 4、第三个桶组为5, 6;同理, D 2 D_2 D2的第一个桶组为1, 2、第二个桶组为3, 5、第三个桶组为1, 2。由于第一个桶组的哈希值完全匹配(两个文档均为1, 2), D 1 D_1 D1和 D 2 D_2 D2会在该桶组下被聚类在一起,而在其他桶组中因哈希值不匹配不会聚类。但需注意,只要文档在至少一个桶组中聚类,无论其他桶组是否匹配,都会被视为候选重复文档。
识别出候选重复文档后,可通过多种方式进行处理。例如,可计算所有候选重复文档对的杰卡德相似度(Jaccard similarity),并将相似度超过设定阈值的文档对标记为重复文档。
最后,跨存储桶对重复文档进行聚类。例如,假设文档A和B在某个存储桶中匹配且真实杰卡德相似度超过阈值,文档B和C在另一个存储桶中匹配且真实杰卡德相似度也超过阈值,则将文档A、B、C视为一个聚类。在每个聚类中,随机保留一个文档,删除其余所有文档。
问题(minhash_deduplication):8分
编写一个函数,接收输入文件路径列表,使用MinHash和LSH(局部敏感哈希)执行模糊文档去重。具体要求如下:
- 为输入路径列表中的每个文档计算MinHash签名;
- 使用指定数量的桶组(bands)通过LSH识别候选重复文档;
- 计算候选重复文档间的真实n元语法杰卡德相似度,并移除相似度超过给定阈值的文档。
为提高召回率(参考Penedo等人2023年的研究),在计算MinHash签名 或 杰卡德相似度之前,需对文本进行归一化处理:转为小写、移除标点符号、归一化空白字符、去除重音符号,并应用NFD Unicode归一化。
交付物:一个执行模糊文档去重的函数。该函数至少需接收以下参数:
(a)输入文件路径列表;
(b)计算MinHash签名时使用的哈希函数数量;
(c)LSH使用的桶组(bands)数量;
(d)计算MinHash签名时的n元语法长度(以单词为单位);
(e)输出目录。
假设用于计算MinHash签名的哈希函数数量能被LSH的桶组数量整除。函数需将每个输入文件重写到输出目录(保持原文件名),但仅保留以下两类文档:
(a)非候选重复文档;
(b)从聚类存储桶中随机选择保留的文档。
示例:若输入路径为a/1.txt和a/2.txt,输出目录为b/,则函数应生成文件b/1.txt和b/2.txt。实现适配器run_minhash_deduplication,并确保通过测试命令uv run pytest -k test_minhash_deduplication。
4 排行榜:为语言建模筛选数据
现已实现多种网络爬取数据筛选基元(primitives),接下来将其应用于生成语言建模训练数据。
本部分任务目标:筛选Common Crawl(CC)WET文件集合,生成语言建模训练数据。我们已在Together集群的/data/CC/目录下提供5000个WET文件(文件格式为CC*.warc.wet.gz)作为数据来源。
具体目标:筛选CC数据dump,生成语言建模数据,使得基于该数据训练的Transformer语言模型在Paloma基准测试的C4 100 domains子集上的验证困惑度(perplexity)最小化。不得修改模型架构或训练流程,核心目标是构建最优数据。该验证集包含C4语言建模数据集中100个最常见域名的样本(参考Raffel等人2020年的研究),我们已在Together集群的/data/paloma/目录下提供该数据的分词版本(使用GPT-2分词器处理),文件路径为:/data/paloma/tokenized_paloma_c4_100_domains_validation.bin。可通过以下代码加载并查看数据:
python
import numpy as np
data = np.fromfile(
"/data/paloma/tokenized_paloma_c4_100_domains_validation.bin",
dtype=np.uint16
)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
print(tokenizer.decode(data[0:2000])) # 解码前2000个token查看数据基于筛选后的数据集,需在该数据上训练一个GPT-2 small规格的模型(200K迭代次数),并在C4 100验证集上评估其困惑度。
注意事项:允许利用Paloma验证集构建筛选器或分类器以处理CC WET文件,但严禁将验证集数据直接复制到训练数据中,语言模型不得接触任何验证集数据。
5000个WET文件的数据量相当可观,压缩后约375GB。为高效处理数据,建议尽可能使用多进程并行计算。Python的concurrent.futures或multiprocessing API可能会有所帮助。以下是使用concurrent.futures实现多进程并行处理的极简示例:
python
import concurrent.futures
import os
import pathlib
from tqdm import tqdm
def process_single_wet_file(input_path: str, output_path: str):
# 待实现:读取输入文件、处理数据、将结果写入输出路径
return output_path
# 配置执行器(executor)
num_cpus = len(os.sched_getaffinity(0)) # 获取可用CPU核心数
executor = concurrent.futures.ProcessPoolExecutor(max_workers=num_cpus)
wet_filepaths = ["a.warc.wet.gz", "b.warc.wet.gz", "c.warc.wet.gz"] # 示例文件路径
output_directory_path = "/path/to/output_directory/" # 输出目录
futures = []
for wet_filepath in wet_filepaths:
# 提取文件名并构造输出路径
wet_filename = str(pathlib.Path(wet_filepath).name)
output_path = os.path.join(output_directory_path, wet_filename)
# 提交任务到执行器并获取未来对象(future)
future = executor.submit(process_single_wet_file, wet_filepath, output_path)
futures.append(future)
# 监控任务完成进度(带进度条)
for future in tqdm(
concurrent.futures.as_completed(futures),
total=len(wet_filepaths),
desc="Processing WET files"
):
output_file = future.result()
print(f"输出文件已写入:{output_file}")若需在Slurm集群上并行处理数据,可使用submitit库(提供concurrent.futures的无缝替代接口,支持自动提交任务到指定Slurm分区并收集结果)。以下是使用submitit的示例代码:
python
import os
import pathlib
import submitit
from tqdm import tqdm
def process_single_wet_file(input_path: str, output_path: str):
# 待实现:读取输入文件、处理数据、将结果写入输出路径
return output_path
# 配置submitit执行器
executor = submitit.AutoExecutor(folder="slurm_logs") # 日志存储目录
max_simultaneous_jobs = 16 # 最大并发任务数
wet_filepaths = ["a.warc.wet.gz", "b.warc.wet.gz", "c.warc.wet.gz"] # 示例文件路径
output_directory_path = "/path/to/output_directory/" # 输出目录
# 配置Slurm任务参数
executor.update_parameters(
slurm_array_parallelism=max_simultaneous_jobs,
timeout_min=15, # 任务超时时间(分钟)
mem_gb=2, # 每个任务内存限制(GB)
cpus_per_task=2, # 每个任务CPU核心数
slurm_account="student", # Slurm账户名
slurm_partition="a4-cpu", # Slurm分区名
slurm_qos="a4-cpu-qos" # Slurm服务质量等级
)
futures = []
# 使用executor.batch()将任务分组为Slurm数组任务
with executor.batch():
for wet_filepath in wet_filepaths:
# 提取文件名并构造输出路径
wet_filename = str(pathlib.Path(wet_filepath).name)
output_path = os.path.join(output_directory_path, wet_filename)
# 提交任务到执行器
future = executor.submit(process_single_wet_file, wet_filepath, output_path)
futures.append(future)
# 监控任务完成进度(带进度条)
for future in tqdm(
submitit.helpers.as_completed(futures),
total=len(wet_filepaths),
desc="Processing WET files (Slurm)"
):
output_file = future.result()
print(f"输出文件已写入:{output_file}")如上述代码所示,submitit与原生concurrent.futures API的使用方式高度相似,主要差异包括:
- 需配置submitit执行器参数(指定Slurm任务提交目标及资源规格);
- 使用executor.batch()将所有任务分组为单个Slurm数组任务(而非创建与文件数相等的独立任务),以减少Slurm调度器负载;
- 收集结果时使用submitit.helpers.as_completed()方法。
建议使用FastWARC库迭代处理每个WET文件中的记录,使用tldextract库从URL中提取域名用于筛选。以下类可能会有所帮助:
python
from fastwarc.warc import ArchiveIterator, WarcRecordType # 迭代WET文件记录
from tldextract import TLDExtract # 提取域名问题(filter_data):6分
(a)编写脚本,从Common Crawl WET文件集合(Together集群路径:/data/CC/CC*.warc.wet.gz)中筛选语言建模数据。可自由使用前序任务实现的任何筛选基元,也可探索其他筛选方法(例如基于n元语法语言模型困惑度的筛选)。核心目标是生成能使模型在Paloma基准测试C4 100 domains子集上困惑度最小化的数据。
再次强调:允许利用Paloma验证集构建筛选器或分类器,但严禁将验证集数据直接复制到训练数据中。
脚本需统计每个筛选步骤保留的样本数量,以便明确各筛选器对最终输出数据的贡献。
交付物:
- 并行筛选CC WET文件以生成语言建模数据的脚本(或脚本序列);
- 书面说明:每个筛选步骤剔除的样本占总剔除样本的比例。
(b)筛选5000个WET文件需要多长时间?筛选整个Common Crawl数据dump(100,000个WET文件)需要多长时间?
交付物:数据筛选流水线的运行时间(含单批次5000个文件及全量100,000个文件的预估时间)。
生成语言建模数据后,我们将对其进行分析,以更好地理解数据内容。
问题(inspect_filtered_data):4分
(a)从过滤后的数据集随机选取5个示例。评论这些示例的质量,以及它们是否适合用于语言建模------尤其考虑到我们的目标是最小化C4 100领域基准测试的困惑度(perplexity)。
交付要求:过滤后数据中的5个随机示例。由于文档可能较长,仅展示相关片段即可。每个示例需附带1-2句描述,说明其是否值得用于语言建模。
(b)选取5个被过滤脚本移除和/或修改的CC WET文件(Common Crawl Web Extracted Text,通用爬虫网页提取文本)。说明过滤流程中的哪个环节移除或修改了这些文档,以及你认为移除和/或修改是否合理。
交付要求:原始WET文件中5个随机被丢弃的示例。由于文档可能较长,仅展示相关片段即可。每个示例需附带1-2句描述,说明其移除是否合理。
(c)如果上述分析表明需要进一步修改数据处理流程,可在训练模型前进行调整。报告你尝试过的所有数据修改和/或迭代方案。
交付要求:描述所尝试的数据修改和/或迭代方案。
在基于数据训练语言模型前,需对数据进行分词处理。使用transformers库中的GPT-2分词器,将过滤后的数据编码为整数ID序列以用于模型训练。切记在每个文档末尾添加GPT-2的序列结束标记<<|endoftext|>。以下是示例代码:
python
import multiprocessing
import numpy as np
from tqdm import tqdm
from transformers import AutoTokenizer
input_path = "path/to/your/filtered/data" # 过滤后数据的路径
output_path = "path/to/your/tokenized/data" # 分词后数据的输出路径
tokenizer = AutoTokenizer.from_pretrained("gpt2")
def tokenize_line_and_add_eos(line):
return tokenizer.encode(line) + [tokenizer.eos_token_id]
with open(input_path) as f:
lines = f.readlines()
pool = multiprocessing.Pool(multiprocessing.cpu_count())
chunksize = 100
results = []
# 多进程分词并添加序列结束标记
for result in tqdm(
pool.imap(tokenize_line_and_add_eos, lines, chunksize=chunksize),
total=len(lines),
desc="Tokenizing lines" # 分词进度提示
):
results.append(result)
pool.close()
pool.join()
# 展平ID列表并转换为numpy数组
all_ids = [token_id for sublist in results for token_id in sublist]
print(f"已将{input_path}分词编码为{len(all_ids)}个token")
ids_array = np.array(all_ids, dtype=np.uint16)
ids_array.tofile(output_path) # 序列化保存问题(tokenize_data):2分
编写脚本对过滤后的数据进行分词和序列化处理。确保按照上述示例代码的方式序列化------ids_array.tofile(output_path),其中ids_array是存储整数ID的np.uint16类型numpy数组。这能保证与提供的训练脚本兼容。
你的过滤后数据集包含多少个token?
交付要求:分词和序列化数据的脚本,以及生成数据集的token数量。
模型训练
完成数据分词后,即可基于该数据训练模型。我们将在生成的数据上训练一个GPT-2小型架构模型,迭代200,000步,并定期在C4 100领域数据集上评估验证性能。
- 打开配置文件
cs336-basics/configs/experiment/your_data.yaml,将paths.train_bin属性设置为分词后训练数据的文件路径。同时需设置合适的training.wandb_entity和training.wandb_project属性以用于日志记录(Weights & Biases工具)。 - 使用
cs336-basics/scripts/train.py脚本启动训练¹。训练超参数可在cs336-basics/cs336_basics/train_config.py中查看。我们将使用2块GPU进行数据并行训练,每块GPU的批次大小(batch size)为128。该配置下的训练过程约需7小时,请合理安排时间。启动训练的命令如下:
bash
uv run torchrun --standalone --nproc_per_node=2 scripts/train.py --config-name=experiment/your_data(执行前请确保已完成上述配置文件的属性设置)
本次作业的核心目标是通过优化数据来最小化验证损失,而非通过修改模型和/或优化流程来降低损失。因此,请勿修改训练配置(上述路径和Weights & Biases相关属性除外)或训练脚本。
测试数据时,可将training.save_checkpoints配置参数设为True,以便在每次评估验证损失时保存模型检查点(checkpoint)。设置命令如下:
bash
uv run torchrun --standalone --nproc_per_node=2 \
scripts/train.py --config-name=experiment/your_data \
+training.save_checkpoints=True模型检查点将保存至cs336-basics/output/your_data/step_N(N为迭代步数)。可通过以下命令从保存的模型中生成文本样本:
bash
uv run python scripts/generate_with_gpt2_tok.py \
--model_path cs336-basics/output/your_data/step_N¹ 训练脚本地址:https://github.com/stanford-cs336/assignment4-data/blob/master/cs336-basics/scripts/train.py
问题(train_model):2分
基于分词后的数据集训练语言模型(GPT-2小型架构)。定期在C4 100领域数据集上评估验证损失(配置文件cs336-basics/cs336_basics/train_config.py中默认已启用该功能)。你的模型取得的最佳验证损失是多少?将该数值提交至排行榜。
交付要求:记录的最佳验证损失值、对应的学习曲线(learning curve),以及相关操作说明。