Paper Card
论文标题 :: a VLA That Learns From Experience
作者/机构 :Physical Intelligence (Pi) Team (核心作者包括 Kevin Black, Sergey Levine 等)
发布时间 :2025年11月 (arXiv:2511.14759v2)
项目主页 :https://pi.website/blog/pistar06
Keywords:VLA, Flow Matching, Offline RL, Advantage Conditioning, Real-world Robotics
摘要
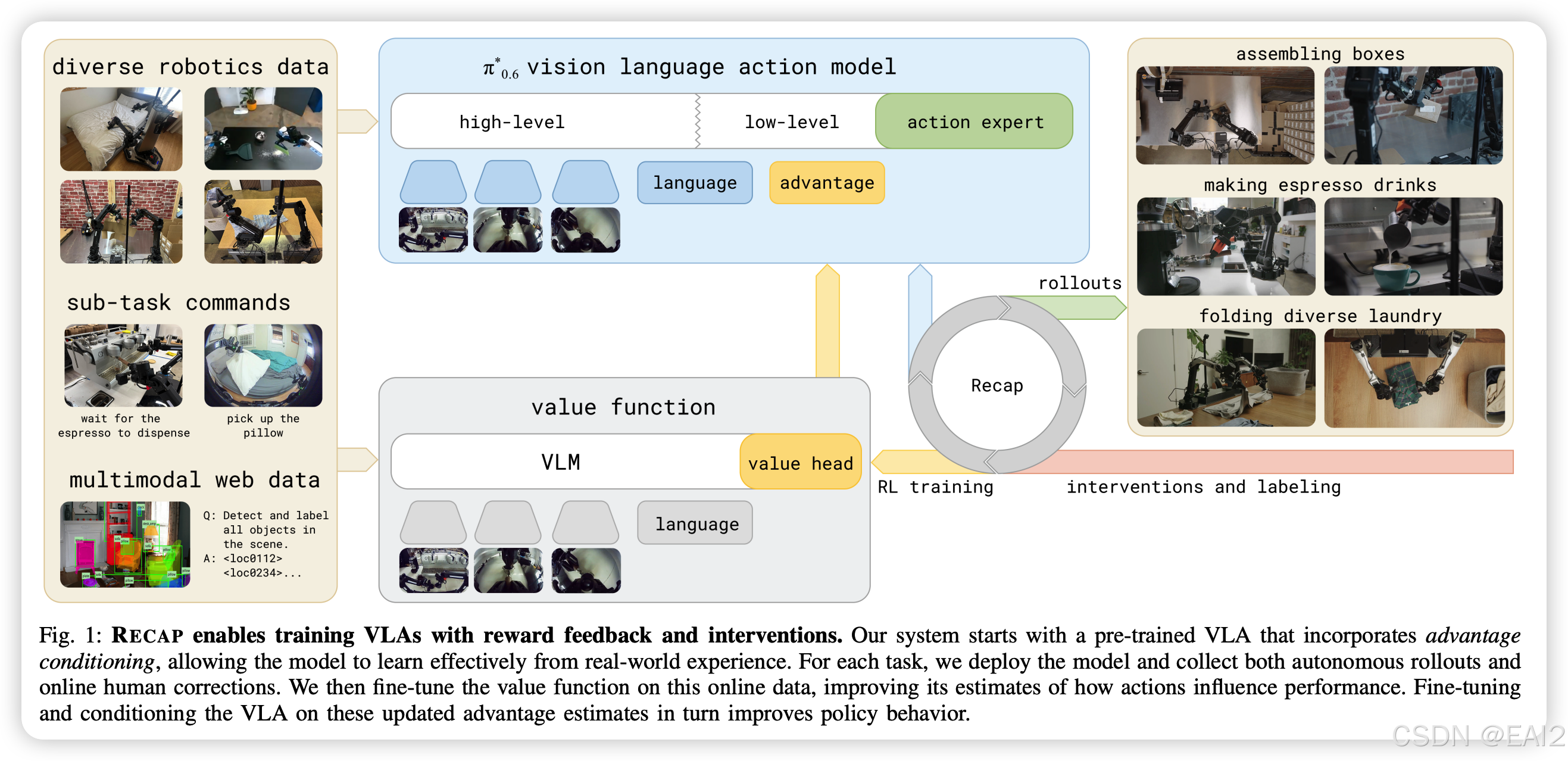
本文提出了一种名为 RECAP (RL with Experience and Corrections via Advantage-conditioned Policies) 的通用方法,旨在通过强化学习(RL)提升视觉-语言-动作(VLA)模型在真实世界任务中的性能。该方法通过训练一个价值函数(Value Function)来评估混合数据(演示、自主探索、人工干预)的质量,并将优势(Advantage)作为条件输入引导策略优化 。
TL;DR:Physical Intelligence 将 Flow Matching Action Head 与基于优势函数的 Conditioning 结合,回避了传统 PPO 在扩散/流匹配模型上训练不稳定的问题。在叠衣物、组装纸箱和制作浓缩咖啡等长程复杂任务上,实现了吞吐量翻倍和故障率减半的效果 。
2. 背景与痛点
背景:通用的 VLA 模型通过模仿学习(Imitation Learning)已经展现了强大的零样本/少样本能力,能够通过 Prompt 执行多种任务 。
未解问题:
- 模仿学习的局限:仅靠离线演示数据训练的模型会遭受累积误差(Compounding Errors)的影响,且性能上限被演示数据锁死 。
- RL 在 VLA 上的落地难:传统的 RL 方法(如 PPO)难以直接扩展到含有几十亿参数且采用 Flow Matching/Diffusion 动作头的 VLA 模型上。PPO 需要计算准确的 Log-likelihood,而 Flow Matching 的似然计算计算量大且不稳定 。
- 数据异构性:如何有效利用专家演示、自主探索的失败数据以及人类介入(Intervention)的数据是一个难题 。
本文动机 :作者试图解决如何设计一种可扩展的 RL 配方,既能处理 Flow Matching 的连续动作空间,又能利用各种质量的数据(好数据和坏数据)来持续改进策略,提升机器人的鲁棒性和速度 。
3. 核心方法
3.1 模型架构
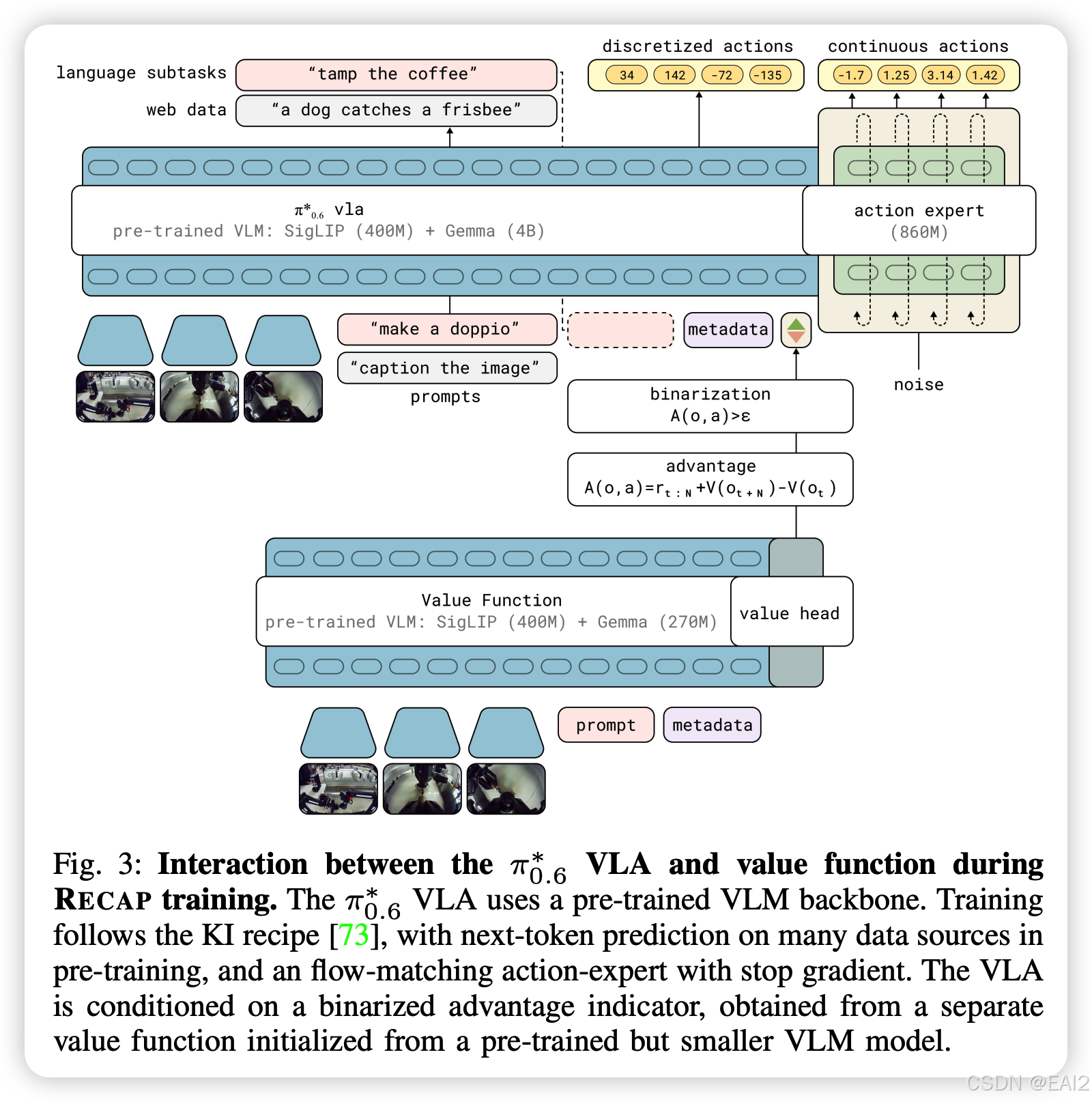
Backbone:
- Gemma 3 (4B)
输入输出模态:
- 输入 :多视角图像(Base + Wrist cameras)、机器人状态 q t q_t qt、语言指令 l l l 以及新增的 Advantage Indicator ( I t I_t It) 。
- 输出 :离散的语言 Token(用于高层决策,如 "pick up the coffee cup")和连续的动作块(Action Chunk a t : t + H a_{t:t+H} at:t+H) 12。
特殊的模块设计:
- Action Expert :8.6亿参数 (860M) 的独立模块,专门用于动作生成。采用 Flow Matching 对连续动作进行建模,训练时使用 Stop Gradient 防止 Action Loss 破坏 VLM 的语言能力(Knowledge Insulation 策略) 。
- Advantage Indicator :文本 Token,形式为
"Advantage: positive"或"Advantage: negative",插入在动作 Token 序列之前 。
3.2 训练策略
训练分几个阶段?
Pre-training (Generalist Phase) :在海量多任务数据上训练 V p r e V_{pre} Vpre (Value Function) 和 π p r e \pi_{pre} πpre (Policy)。Value Function 预测任务成功的剩余步数的负值。
Fine-tuning (Specialist Phase):
- SFT 初始化 :针对特定下游任务,固定 I t = True I_t = \text{True} It=True 进行微调。
- RECAP 循环:收集数据(自主+干预) -> 训练 Value Function -> 重新计算优势 -> 利用 Advantage Conditioning 微调 Policy。
损失函数(Loss Function):
- Policy Loss : min θ E D − log π θ ( a t ∣ o t , l ) − α log π θ ( a t ∣ I t , o t , l ) \min_{\theta} \mathbb{E}_{\mathcal{D}} -\\log \\pi_{\\theta}(a_t \| o_t, l) - \\alpha \\log \\pi_{\\theta}(a_t \| I_t, o_t, l) minθED−logπθ(at∣ot,l)−αlogπθ(at∣It,ot,l)。
- Flow Matching Loss :基于向量场的回归损失,近似于 Log-likelihood 的下界: L f l o w = ∣ ∣ c i t e s t a r t ω − a − f θ ( a η , ω , I t , ... ) ∣ ∣ 2 \mathcal{L}{flow} = || cite_start\omega - a - f\theta(a^{\eta, \omega}, I_t, \dots) ||^2 Lflow=∣∣citestartω−a−fθ(aη,ω,It,...)∣∣2。
关键的超参数或优化技巧:
- Advantage Threshold ():预训练时设为数据分布的 30% 分位点,微调时设为 40% 。
- Condition Dropout :训练时以 30% 的概率丢弃 I t I_t It,从而在推理时支持类似 Classifier-Free Guidance (CFG) 的技巧(通过调整 β > 1 \beta > 1 β>1 来锐化策略分布) 。
3.3 数据构建
使用了哪些数据集?
Pre-training:数万小时的多机器人演示数据 + Web 视觉语言数据 。
Fine-tuning:针对特定任务收集的几百条轨迹(例如 Laundry 任务收集了约 300-600 条) 。
数据混合策略:
- 对于人类专家介入修正(Intervention)的数据片段,强制标记 I t = True I_t = \text{True} It=True。
- 自主运行的数据根据 Value Function 算出的优势值动态分配 Positive/Negative 标签。
数据预处理 :奖励设计采用稀疏奖励(成功 r = 0 r=0 r=0,失败 r = − 1 r=-1 r=−1 或大负值),Value Function 实际上预测的是归一化后的"距离成功的步数"。
4. 实验与评测
4.1 评测设置

环境:真实世界双臂 6-DoF 机器人系统 。

场景:三个高难度长程任务(Figure 6):
- Laundry (Diverse): 折叠 11 种不同类型的衣物。
- Cafe: 使用商用咖啡机制作 Double Espresso。
- Box Assembly: 纸箱成型、粘贴标签、堆叠 。
4.2 主要结果
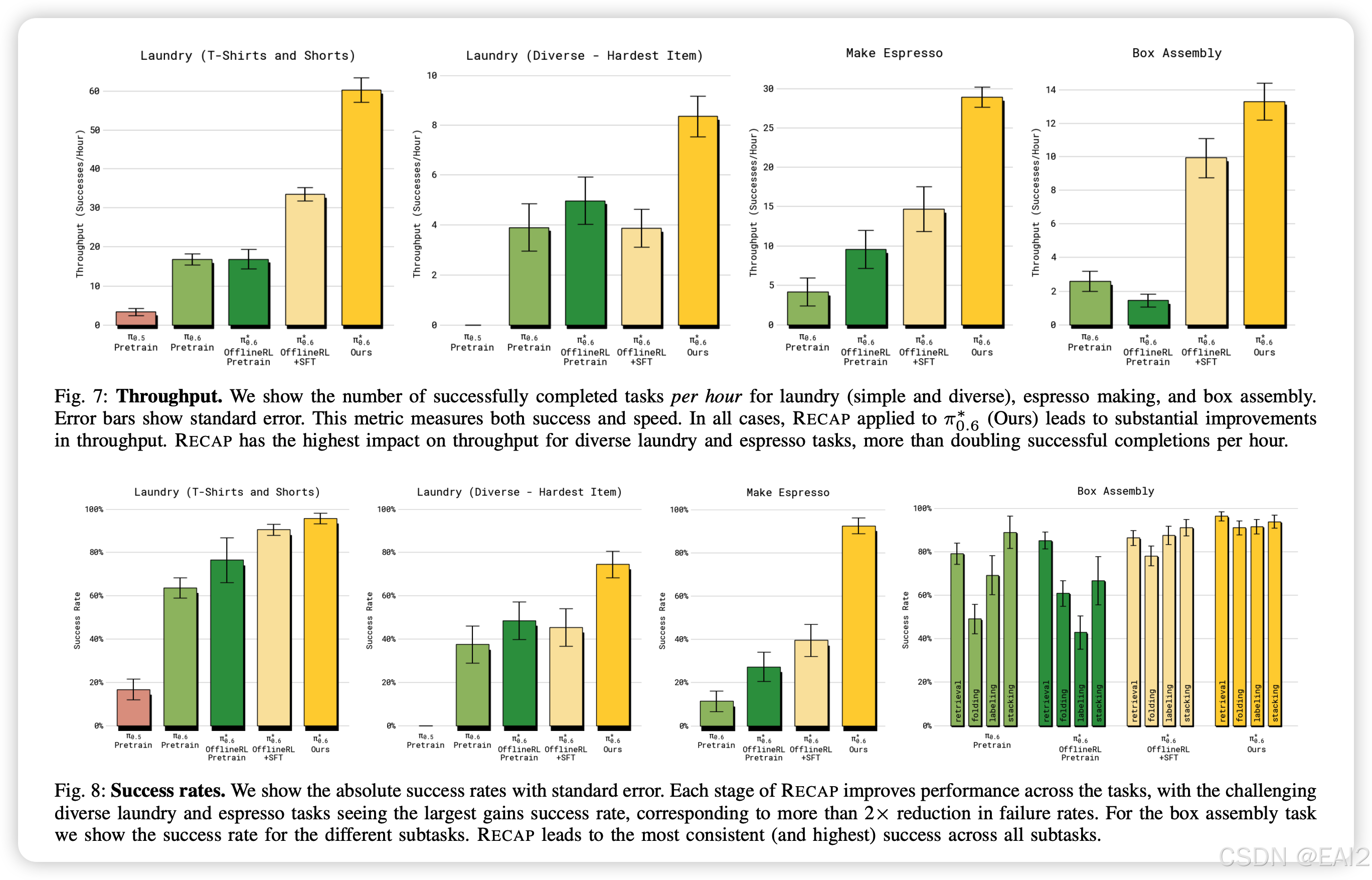
吞吐量 (Throughput) :相比于 Offline RL + SFT 基线,RECAP 在困难任务(Diverse Laundry 和 Espresso)上的吞吐量翻了一倍以上 。
成功率 :在大多数任务上达到了 90%+ 的成功率 。
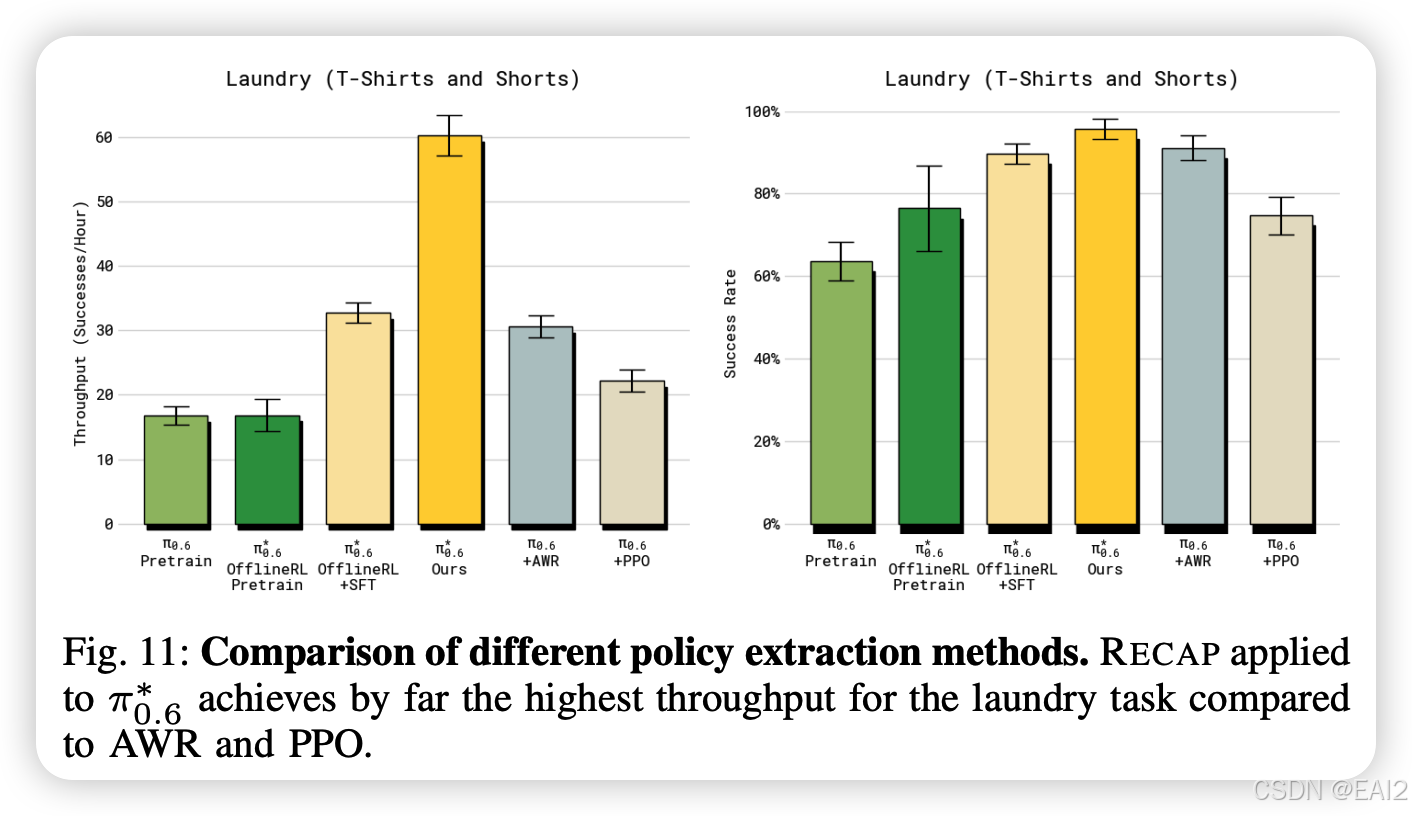
SOTA 比较 :与 AWR 和 PPO 相比,RECAP 表现出显著优势。PPO 在此设置下极难调优,必须使用极小的 Trust Region 才能稳定,且收敛慢 。
4.3 消融实验
消除特定失效模式:在一个特定设置的"困难T恤折叠"任务中,RECAP 能够通过 RL 消除"领口朝下"的特定错误行为,成功率从 ~30% 提升至 97% 。
迭代次数 :随着数据收集和训练的迭代(Iteration 1 -> 2),吞吐量持续上升,证明了方法的闭环改进能力 。
4.4 关键发现
Value Function 是核心:通过训练一个强力的 Critic 来区分数据的"好坏",比单纯模仿所有数据更有效 。
Advantage Conditioning 有效性:这种简单的条件监督学习方法比复杂的策略梯度(Policy Gradient)更适合大参数量的 VLA 模型 。
5. 结论与思考
5.1 关键结论
在 VLA 时代,复杂的 On-policy RL (如 PPO) 可能不是最优解。通过训练一个强力的 Critic (Value Function),然后利用简单的 Supervised Learning 配合 Advantage Conditioning (类似 CFG),可以更稳定、更高效地 Scaling Up 机器人学习,显著提升模型的鲁棒性和执行速度 。
5.2 局限性
论文不足:系统仍依赖人工重置环境(Reset)和人工标注奖励(Labeling success/failure),这限制了大规模自动化;探索策略主要依赖随机性和人类介入,较为初级 。
潜在弱点:目前的流程是"收集一批 -> 训练一批"的 Batch 模式(Iterated Offline RL),而不是完全实时的 Online RL,数据反馈循环有延迟 。
5.3 未来方向
架构层面 :在 Input Token 中加入 [Advantage] token 是一个低成本高回报的架构改动,值得在其他 VLA 模型中推广。
数据利用:不要丢弃失败的数据。训练一个 Value Function 来利用负样本,是提升模型鲁棒性的关键。
自动化:未来的研究应致力于减少人工介入(如自动 Reset、自动奖励模型),以实现真正的全自动终身学习 。