文章目录
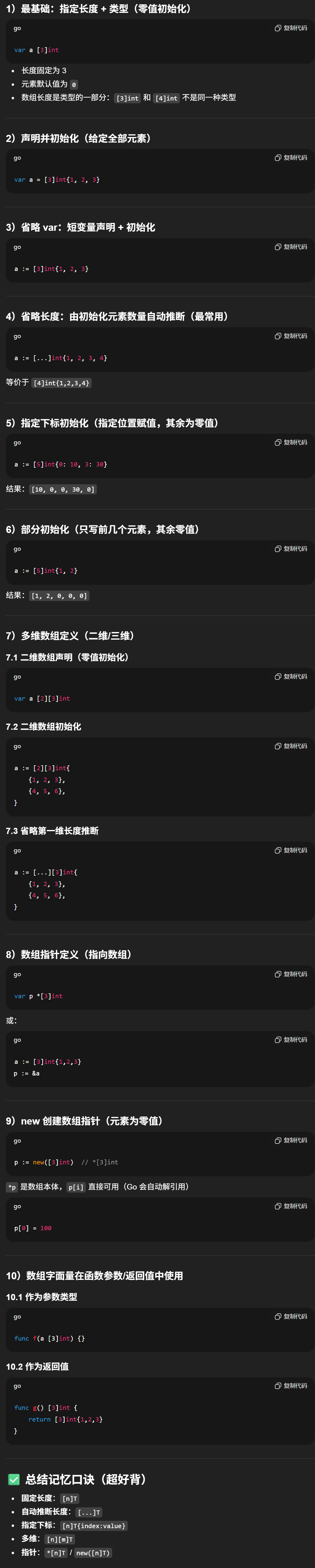
- go语言结构体
- go语言数组与切片
- go语言条件句
- go语言循环
-
- [1. for循环的形式](#1. for循环的形式)
-
- 第一种:类似于C语言的for循环
- 第二种:类似于C语言的while
- [第三种:类似于C语言的for( ; ; )](#第三种:类似于C语言的for( ; ; ))
- [2. for range](#2. for range)
- [3. for range的坑](#3. for range的坑)
- [3.1 for range 取不到所有元素的地址](#3.1 for range 取不到所有元素的地址)
-
- [第一种:使用局部变量 v1 拷贝 v](#第一种:使用局部变量 v1 拷贝 v)
- 第二种:直接使用索引获取原来的元素
- [3.2 循环是否会停止?](#3.2 循环是否会停止?)
- [3.3 使用迭代变量时的闭包问题](#3.3 使用迭代变量时的闭包问题)
-
- [【此输出结果仅适用于go1.22之前版本,go1.25输出还是0 1 2】](#【此输出结果仅适用于go1.22之前版本,go1.25输出还是0 1 2】)
- [3.3.1 问题](#3.3.1 问题)
- [3.3.2 解决方法](#3.3.2 解决方法)
- [3.4 修改切片中的元素](#3.4 修改切片中的元素)
-
- [3.4.1 问题](#3.4.1 问题)
- [3.4.2 解决方法](#3.4.2 解决方法)
- [3.5 遍历字典时的顺序](#3.5 遍历字典时的顺序)
-
- [3.5.1 问题](#3.5.1 问题)
- [3.5.2 解决方法](#3.5.2 解决方法)
- [3.6 字符串遍历](#3.6 字符串遍历)
-
- [3.6.1 问题](#3.6.1 问题)
-
- [关键区别:rune vs byte](#关键区别:rune vs byte)
- [3.6.2 解决方法](#3.6.2 解决方法)
- [3.7 总结](#3.7 总结)
go语言结构体
有时候内置的基本类型并不能满足我们的业务需求,我们需要一些复合结构。比如我们想要描述一个学生,1个学生既有学号,年龄,性别,分数等这些属性,而单一的数据类型往往只能描述其中一个属性,我们想要描述这个学生,就需要把这些属性都要描述出来,这个时候就需要用到结构体了。
结构体定义
像很多其他的高级语言一样,go语言也支持结构体来定义复合数据类型。
定义方式如下:
go
type Student struct {
ID int
Name string
Age int
Score int
}上述方法定义了一个Student类型的结构体,Student包含四个属性,分别是string类型的Name和int类型的ID,Age和Score。
结构体初始化
键值对初始化
在初始化的时候以属性:值的方式完成,如果有的属性不写,则为默认值
go
package main
import "fmt"
type Student struct {
ID int
Name string
Age int
Score int
}
func main() {
st := Student{
ID : 100,
Name : "zhangsan",
Age : 18,
Score : 98,
}
fmt.Printf("学生st: %v\n", st)
}运行结果:
bash
学生st: {100 zhangsan 18 98}值列表初始化
在初始化的时候直接按照属性顺序以属性值来初始化,看下面例子
go
package main
import "fmt"
type Student struct {
ID int
Name string
Age int
Score int
}
func main() {
st := Student{
101,
"lisi",
20,
97,
}
fmt.Printf("学生st: %v\n", st)
}运行结果:
bash
学生st: {101 lisi 20 97}注意:以值列表的方式初始化结构体,值列表的个数必须等于结构体属性个数,且要按顺序,否则会报错
结构体成员访问
使用点号 . 操作符来访问结构体的成员,. 前可以是结构体变量或者结构体指针
go
package main
import "fmt"
type Student struct {
ID int
Name string
Age int
Score int
}
func main() {
st1 := Student{
ID : 100,
Name : "zhangsan",
Age : 18,
Score : 98,
}
fmt.Printf("学生1的姓名是: %s\n", st1.Name)
st2 := &Student{
ID : 101,
Name : "lisi",
Age : 20,
Score : 97,
}
fmt.Printf("学生2的分数是: %d\n", st2.Score)
}运行结果:
bash
学生1的姓名是: zhangsan
学生2的分数是: 97go语言数组与切片
本小节只是简单介绍一下数组,切片以及map的使用方法,将在后续章节中详细介绍各个数据结构的原理
go
package main
import "fmt"
func main() {
//数组初始化
var strAry = [10]string{"aa", "bb", "cc", "dd", "ee"}
//切片初始化
// []string代表切片元素的类型
// 0 表示这个切片被初始化的长度
var sliceAry = make([]string, 0)
sliceAry = strAry[1:3]
//字典初始化
var dic = map[string]int{
"apple": 1,
"watermelon": 2,
}
// Structs formatted with %v show field values in their default formats.
// The %+v form shows the fields by name, while %#v formats the struct in
// Go source format.
fmt.Printf("strAry %+v\n", strAry)
fmt.Printf("sliceAry %+v\n", sliceAry)
fmt.Printf("dic %+v\n", dic)
}运行结果
bash
strAry [aa bb cc dd ee ]
sliceAry [bb cc]
dic map[apple:1 watermelon:2]形式:alow:high
包含 low,不包含 high(左闭右开)
make(\[\]string, 0) 得到的是一个空切片:len=0
cap 通常也是 0(实现细节上可能是 0),而且它不包含任何元素。
go语言条件句
go
package main
import "fmt"
func main() {
localStr := "case3" //是的,还可以通过 := 这种方式直接初始化基础变量
if localStr == "case3" {
fmt.Printf("into ture logic\n")
} else {
fmt.Printf("into false logic\n")
}
//字典初始化
var dic = map[string]int{
"apple": 1,
"watermelon": 2,
}
if num, ok := dic["orange"]; ok {
fmt.Printf("orange num %d\n", num)
}
if num, ok := dic["watermelon"]; ok {
fmt.Printf("watermelon num %d\n", num)
}
switch localStr {
case "case1":
fmt.Println("case1")
case "case2":
fmt.Println("case2")
case "case3":
fmt.Println("case3")
default:
fmt.Println("default")
}
}输出结果
bash
into ture logic
watermelon num 2
case3if语句在Golang和其他语言中的表现形式一样,没啥区别。上面的例子同时也展示了用if判断某个key在map是否为空的写法。
第17行, num表示map中对应key的值, ok表示key是否存在
switch中,每个case都默认break。即如果是case1,那么执行完之后,就会跳出switch条件选择。如果希望从某个case顺序往下执行,可以使用fallthrough关键字。
go语言循环
go语言的循环不像其他语言一样有多种,比如C++有for,while,do-while。在Go语言中循环就只有for一种,所以用起来也是十分的方便。
1. for循环的形式
Go语言的 for 循环有 3 种形式,只有其中的一种使用分号。
第一种:类似于C语言的for循环
go
for init; condition; post {
}-
init:一般为赋值表达式,给控制变量赋初值;
-
condition:关系表达式或逻辑表达式,循环控制条件;
-
post:一般为赋值表达式,给控制变量增量或减量。
go
for i := 0; i < 10; i++ {
fmt.Println(i)
}第二种:类似于C语言的while
go
for condition {
}第三种:类似于C语言的for( ; ; )
go
for {
}2. for range
for 循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环。格式如下:
go
for key, value := range oldMap {
newMap[key] = value
}以上代码中的 key 和 value 是可以省略。
如果只想读取 key,格式如下:
go
for key := range oldMap如果只想读取 value,格式如下:
go
for _, value := range oldMap代码展示:
go
package main
import "fmt"
func main() {
for i := 0; i < 5; i++ {
fmt.Printf("current i %d\n", i)
}
j := 0
for {
if j == 5 {
break
}
fmt.Printf("current j %d\n", j)
j++
}
var strAry = []string{"aa", "bb", "cc", "dd", "ee"} //是的,不指定初始个数也ok
//切片初始化
var sliceAry = make([]string, 0)
sliceAry = strAry[1:3]
for i, str := range sliceAry {
fmt.Printf("slice i %d, str %s\n", i, str)
}
//字典初始化
var dic = map[string]int{
"apple": 1,
"watermelon": 2,
}
for k, v := range dic {
fmt.Printf("key %s, value %d\n", k, v)
}
}输出如下:
bash
current i 0
current i 1
current i 2
current i 3
current i 4
current j 0
current j 1
current j 2
current j 3
current j 4
slice i 0, str bb
slice i 1, str cc
key apple, value 1
key watermelon, value 2数组的多种定义方式
3. for range的坑
这块可能需要点golang基础,也可以把后面的先看了再来看这块内容。
通过上面例子不难发现for range对于数组,map的遍历非常方便,但是for range也有不好的坑,其中不乏一些熟悉golang的开发人员,往往也会掉到坑里,下面就给大家来捋一捋golang for range中那些容易遇到的坑,这也是面试golang基础时通常会被面试官问到的。
3.1 for range 取不到所有元素的地址
PS:如果你用的是 Go 1.22 版本以及之后的话,那是能取到地址的,而且要注意,这个地址是临时变量的地址,不是原元素的地址(也就是得到结果是 1 2)
go
package main
import "fmt"
func main() {
arr := [2]int{1, 2}
res := []*int{}
for _, v := range arr {
res = append(res, &v)
}
// expect: 1 2 预期的结果
// but
// result: 2 2 实际的结果
fmt.Println(*res[0], *res[1])
}
上述代码通过定义一个数组 arr,数组元素为 1,2。然后试图通过取到数组的这两个元素的地址放到切片 res 中,最后通过取地址操作符 *res0 和 *res1 打印出切片中的元素,希望结果输出 1 和 2,但结果恰恰不是我们所预期的那样。
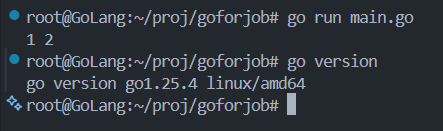
实际代码输出:
bash
2, 2实际输出的是两个 2,那么问题在哪里呢?
我们可以在每次 for range 循环打印出 v 的地址,会发现 v 是不变的,那么我们每次将 v 的地址加入到 res 中,res 中最终所有的元素都是一个地址,这个地址最终指向的是 v 最后遍历得到的值 ------ 也就是 2。
go
package main
import "fmt"
func main() {
arr := [2]int{1, 2}
res := []*int{}
for _, v := range arr {
fmt.Println(&v)
res = append(res, &v)
}
// expect: 1 2 预期的结果
// but
// result: 2 2 实际的结果
fmt.Println(*res[0], *res[1])
}
bash
root@GoLang:~/proj/goforjob# go run main.go
0xc000088008
0xc000088030
1 2
root@GoLang:~/proj/goforjob# go run main.go
0xc000088008
0xc000012090
1 2
root@GoLang:~/proj/goforjob# go run main.go
0xc000012098
0xc0000120c0
1 2
root@GoLang:~/proj/goforjob# 在 for range 中,迭代变量 v 不是每次都新分配一个地址;Go 1.22 之前 v 的地址通常是固定的(同一个),导致 &v 一直相同 ;说白了就是一个编译器的优化机制,既然都是一个for循环里面的临时元素,如果每一个元素都用一个不同的地址去存放明显就没有做内存优化
而 Go 1.22+ 改变了 range 变量的语义,v 更像"每次迭代一个新变量",但 &v 仍然不是原数组元素的地址,而是迭代变量的地址。
go
package main
import "fmt"
func main() {
arr := [2]int{1, 2}
res := []*int{}
fmt.Println(&arr[0])
fmt.Println(&arr[1])
for _, v := range arr {
fmt.Println(&v)
res = append(res, &v)
}
// expect: 1 2 预期的结果
// but
// result: 2 2 实际的结果
fmt.Println(*res[0], *res[1])
}
bash
root@GoLang:~/proj/goforjob# go run main.go
0xc000088020
0xc000088028
0xc000088008
0xc000088040
1 2如何得到预期结果 1 和 2?两种方式
第一种:使用局部变量 v1 拷贝 v
go
for _, v := range arr {
// 局部变量 v1 替换了 v,也可用别的局部变量名
v1 := v
res = append(res, &v1)
}第二种:直接使用索引获取原来的元素
go
for k := range arr {
res = append(res, &arr[k])
}3.2 循环是否会停止?
go
v := []int{1, 2, 3}
for i := range v {
v = append(v, i)
}在循环遍历的同时往遍历的切片添加元素,循环会停止吗 ?
答案是:会。
在 Go 语言中,for i := range v 语句会在循环开始前对切片 v 的长度进行一次评估,并将这个长度用于控制循环的迭代次数。之后,如果在循环体内修改了切片 v 的长度(比如通过 append 函数),这个修改并不会影响已经确定的循环迭代次数。
range 只会对 集合类型(特别是切片和数组) 在循环开始前评估长度,以确保循环次数是固定的。对于 Map 和 Channel,它依赖迭代器机制,不会评估长度。

go
package main
import "fmt"
func main() {
v := []int{1, 2, 3}
for i := range v {
v = append(v, i)
fmt.Println("hh")
}
v2 := make(map[int]int)
v2[1] = 1
for i := range v2 {
v2[i+1] = i + 1
}
fmt.Println(v2)
}
bash
root@GoLang:~/proj/goforjob# go run main.go
hh
hh
hh
map[1:1 2:2 3:3 4:4 5:5 6:6 7:7]
root@GoLang:~/proj/goforjob# 上述例子可以看作是下面这个代码:
go
v := []int{1, 2, 3}
length := len(v)
for i := 0; i < length; i++ {
v = append(v, i)
}3.3 使用迭代变量时的闭包问题
在 Go 里,闭包(closure)就是:一个函数值,它不仅包含函数代码,还"捕获/记住"了它创建时所在作用域里的变量,即使那个外层函数已经返回了,这些变量仍然能被它继续访问和修改。
最常见的例子:返回一个"带状态"的函数
go
func counter() func() int {
x := 0
return func() int {
x++
return x
}
}
func main() {
c := counter()
fmt.Println(c()) // 1
fmt.Println(c()) // 2
fmt.Println(c()) // 3
}这里返回的匿名函数就是闭包,它"捕获"了 x,所以每次调用都在同一个 x 上累加。
闭包捕获的是"变量本身",不是当时的值
这点很关键,容易踩坑:
go
func main() {
fs := make([]func(), 0)
for i := 0; i < 3; i++ {
fs = append(fs, func() { fmt.Println(i) })
}
for _, f := range fs { f() }
}很多人以为会输出 0 1 2,但实际上通常输出:
【此输出结果仅适用于go1.22之前版本,go1.25输出还是0 1 2】
bash
3
3
3因为闭包捕获的是同一个 i 变量,循环结束后 i==3,所以都打印 3。
修正方式(让每次迭代都有自己的变量副本):
go
for i := 0; i < 3; i++ {
i := i // 关键:新建一个同名局部变量
fs = append(fs, func() { fmt.Println(i) })
}闭包有什么用?
- 做"带状态"的函数(计数器、缓存、限流器)
- 回调函数/函数式写法(sort.Slice、http.HandlerFunc)
- 并发中给 goroutine 传递固定参数(避免循环变量坑)
3.3.1 问题
在 for range 循环中,如果在闭包中使用迭代变量 ,可能会遇到意想不到的结果。因为闭包会捕获迭代变量的引用,而不是它的值。
示例:
go
package main
import (
"fmt"
)
func main() {
var funcs []func()
for i := 0; i < 3; i++ {
funcs = append(funcs, func() {
fmt.Println(i)
})
}
for _, f := range funcs {
f()
}
}输出:
bash
3
3
33.3.2 解决方法
使用局部变量保存当前迭代变量的值:
go
package main
import (
"fmt"
)
func main() {
var funcs []func()
for i := 0; i < 3; i++ {
i := i // 创建新的局部变量 i
funcs = append(funcs, func() {
fmt.Println(i)
})
}
for _, f := range funcs {
f()
}
}输出:
bash
0
1
2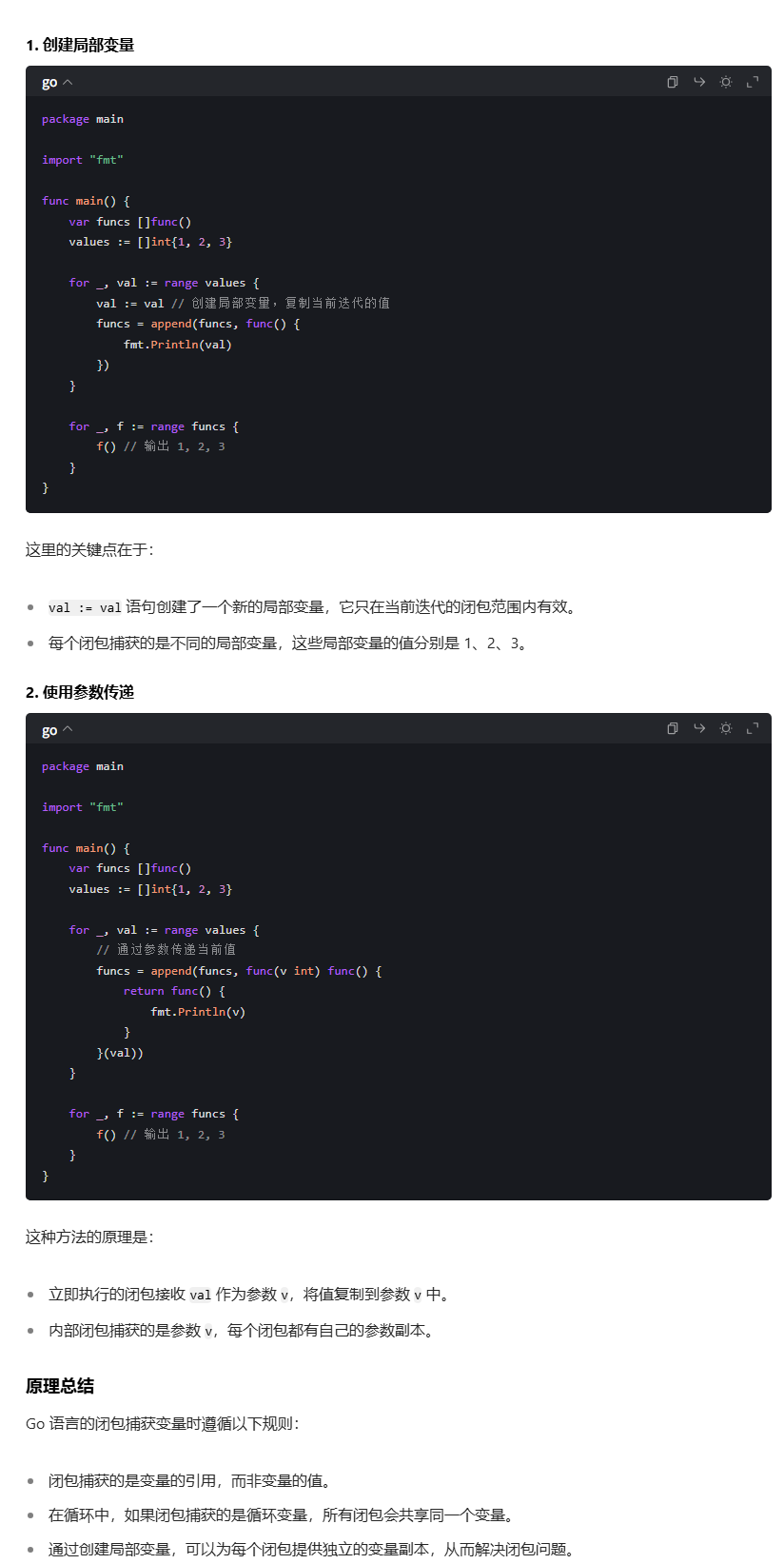
go
funcs = append(funcs,
func(v int) func() {
return func() { fmt.Println(v) }
}(val),
)定义一个匿名函数:func(v int) func() { ... }
马上用 (val) 调用它
3.4 修改切片中的元素
3.4.1 问题
for range 会创建每个元素的副本,而不是直接操作原始切片中的元素。因此,修改迭代变量不会影响原始切片。
示例
go
package main
import (
"fmt"
)
func main() {
slice := []int{1, 2, 3}
for _, v := range slice {
v *= 10
}
fmt.Println(slice) // 输出: [1 2 3]
}3.4.2 解决方法
使用索引访问并修改原始切片中的元素。
go
package main
import (
"fmt"
)
func main() {
slice := []int{1, 2, 3}
for i := range slice {
slice[i] *= 10
}
fmt.Println(slice) // 输出: [10 20 30]
}3.5 遍历字典时的顺序
3.5.1 问题
在 Go 中,使用 for range 遍历字典时,遍历顺序是随机的。每次运行程序时,顺序可能不同。
示例:
go
package main
import (
"fmt"
)
func main() {
dic := map[string]int{"a": 1, "b": 2, "c": 3}
for k, v := range dic {
fmt.Printf("key: %s, value: %d\n", k, v)
}
}输出,每次运行的输出顺序可能不同:
bash
key: a, value: 1
key: c, value: 3
key: b, value: 23.5.2 解决方法
如果需要特定的顺序,可以先对键进行排序,然后再遍历。
go
package main
import (
"fmt"
"sort"
)
func main() {
dic := map[string]int{"a": 1, "b": 2, "c": 3}
keys := make([]string, 0, len(dic))
for k := range dic {
keys = append(keys, k)
}
sort.Strings(keys)
for _, k := range keys {
fmt.Printf("key: %s, value: %d\n", k, dic[k])
}
}对比学习
C++:
- std::map:有序容器,遍历顺序是键的升序。(内部使用红黑树实现)
- std::unordered_map:无序容器,遍历顺序不可预测。(内部使用哈希表实现)
Python:
- Python 3.7 及更高版本:字典遍历顺序是插入顺序。
- Python 3.6 及更早版本:字典遍历顺序可能是插入顺序,但并不保证。
3.6 字符串遍历
3.6.1 问题
for range 遍历字符串时,每次迭代会返回 Unicode 代码点(rune),而不是字节。如果字符串包含多字节字符,这一点尤其重要。
rune 在 Go 里就是 "Unicode 码点" 的类型名(别名),用来表示一个字符的编号。
go
// rune 是 int32 的别名,在所有方面都与 int32 等效。按照惯例,它用于区分字符值和整数值。
type rune = int32关键区别:rune vs byte
一句话:rune 是用 int32 存储的 Unicode 码点,用来表示"字符"的值;而字符串底层是 UTF-8 字节。
- byte = uint8:表示 一个字节
- rune = int32:表示 一个 Unicode 码点(通常相当于你理解的"一个字符")
因为 Go 的字符串 string 是 UTF-8 字节序列:
- '世' 在 UTF-8 里占 3 个字节(e4 b8 96)
- 但它对应的 rune 只有一个值:U+4E16(一个 int32)
go
fmt.Println('世') // 输出一个整数:19990(就是 U+4E16)
fmt.Printf("%U\n", '世') // 输出:U+4E16
fmt.Println([]byte("世")) // [228 184 150] (3 个字节)
fmt.Println([]rune("世")) // [19990] (1 个 rune)示例:
go
package main
import (
"fmt"
)
func main() {
str := "hello 世界"
for i, r := range str {
fmt.Printf("index: %d, rune: %c\n", i, r)
}
}输出:
bash
index: 0, rune: h
index: 1, rune: e
index: 2, rune: l
index: 3, rune: l
index: 4, rune: o
index: 5, rune:
index: 6, rune: 世
index: 9, rune: 界
3.6.2 解决方法
理解 for range 返回的是 Unicode 代码点,而不是字节。如果需要按字节遍历,可以使用常规的 for 循环。
go
package main
import (
"fmt"
)
func main() {
str := "hello 世界"
for i := 0; i < len(str); i++ {
fmt.Printf("index: %d, byte: %x\n", i, str[i])
}
}输出:
bash
index: 0, byte: 68
index: 1, byte: 65
index: 2, byte: 6c
index: 3, byte: 6c
index: 4, byte: 6f
index: 5, byte: 20
index: 6, byte: e4
index: 7, byte: b8
index: 8, byte: 96
index: 9, byte: e7
index: 10, byte: 95
index: 11, byte: 8c3.7 总结
- Go 1.22之前通过 for _, v := range arr 遍历切片取不到所有变量的地址,而是同一个临时变量的地址
- 闭包中的迭代变量:迭代变量在闭包中被捕获,导致所有闭包共享同一个变量。
- 切片元素修改:for range 会创建元素的副本,直接修改迭代变量不会影响原切片。
- 字典遍历顺序:遍历字典时,顺序是随机的,每次运行可能不同。
- 字符串遍历:for range 遍历字符串时返回的是 Unicode 代码点(rune),而不是字节,可能导致多字节字符处理复杂。
- 删除切片元素:在 for range 中删除切片元素可能导致意外行为或漏掉某些元素。
- 遍历修改映射(字典):在 for range 循环中修改字典(如添加或删除键值对)可能导致未定义行为或错误。
之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!