文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,私信获取! 麦麦大数据
编号: F052
视频
1 系统简介
系统简介:本系统是一个基于 Vue + Flask + Spark + Hadoop + Neo4j + Docker 构建的 中医古籍知识图谱可视化推荐系统 。其核心功能围绕中医病症知识的结构化存储、智能推荐与多维可视化分析,旨在通过大数据与图数据库技术实现对中医古籍内容的智能挖掘与个性化推荐服务。
主要功能模块包括:
- 用户登录与注册
- 主页展示与轮播推荐
- 基于Spark MLlib的个性化病症推荐
- 中医知识图谱构建与D3.js可视化
- ECharts动态图形分析(症候、疾病分类等)
- 关键词提取与统计分析(折线图、花瓣图)
- 药材与病症的卡片式搜索
- 个人信息修改与密码管理
2 功能设计
该系统采用前后端分离的B/S架构模式,基于 Vue + Flask + MySQL + Neo4j 技术栈实现。前端通过 Vue.js 框架搭建响应式界面,结合 Vuetify 组件库提供优雅的UI交互体验,使用 Vue-Router 进行页面路由管理,Axios 实现与后端的异步数据请求。后端基于 Python 3.8 ,使用 Flask 构建 RESTful API 服务,通过 SQLAlchemy 操作 MySQL 存储用户信息、操作日志等结构化数据,使用 Py2Neo 与 Neo4j 进行知识图谱的增删改查,同时集成 PySpark 调用 Spark MLlib 模型进行推荐计算。
在推荐系统 功能方面,系统采用 Spark MLlib (协同过滤或基于内容的推荐模型)对用户历史行为进行学习训练,并将模型保存至 HDFS (基于Hadoop),实现大规模数据下的高效训练与推理。推荐任务通过 Docker Compose 在虚拟机环境中启动 Spark 集群(1个Master + 2个Worker)运行,实现分布式计算能力。
2.1 系统架构图
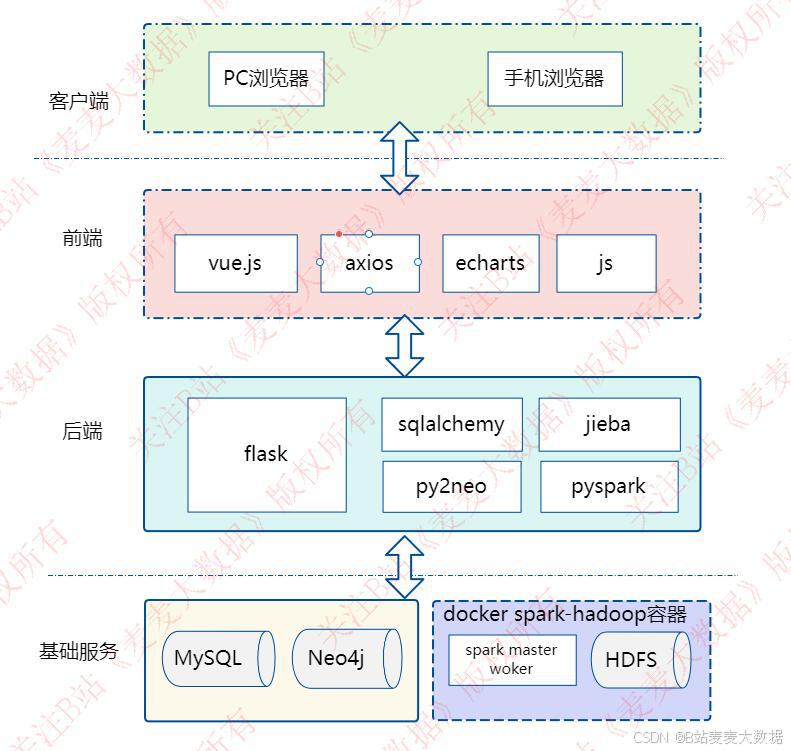
+-------------------+
| 用户端 (Web) |
| Vue + Vuetify + |
| Axios + D3.js |
+--------+----------+
|
| HTTP/REST
v
+--------+----------+
| Flask Web Server |
| Python + SQLAlchemy|
| Py2Neo + PySpark |
+--------+----------+
|
| Database & Service
v
+--------+----------+ +------------------+
| MySQL (Users) | | HDFS + Hadoop |
| (用户信息、日志)| | (推荐模型存储) |
+--------+----------+ +------------------+
| |
| |
v v
+--------+----------+ +------------------+
| Neo4j DB (KG) | | Spark Cluster |
| (知识图谱) | | (Master/Worker) |
+--------------------+ +------------------+2.2 功能模块图
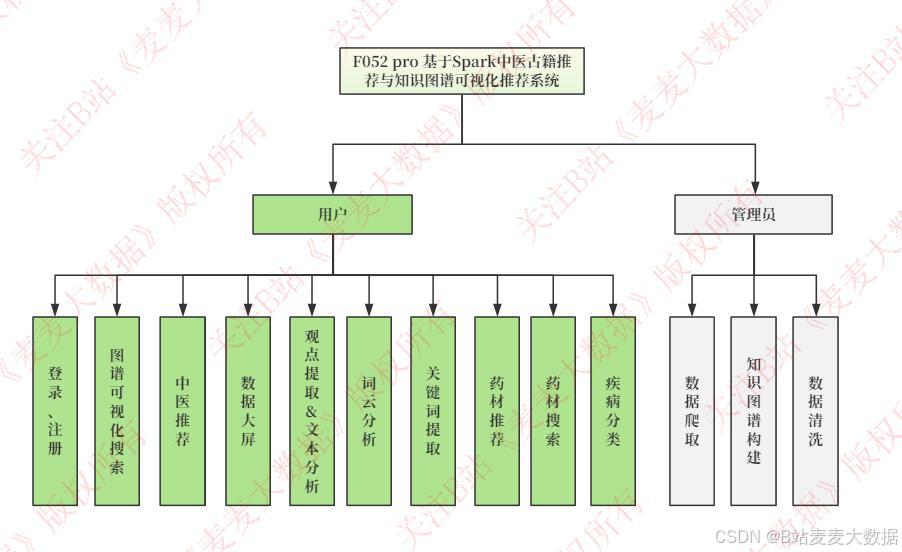
主要功能模块有:
- 登录与注册模块
- 主页展示模块
- 病症推荐模块
- 知识图谱模块
- 可视化分析模块
- 关键词统计模块
- 药材搜索模块
- 病症搜索模块
- 个人设置模块
3.1 登录 & 注册
登录注册采用 可切换的弹窗式界面 ,用户可点击"去登录"或"去注册"切换页面。登录时验证用户名和密码的正确性,后端通过 Flask+SQLAlchemy 验证用户信息是否存在,若验证成功则返回JWT令牌,前端保存到本地存储中用于后续访问。
注册时支持用户填写用户名、密码、基本信息(姓名、年龄、性别等),加密后存入 MySQL 数据库。


3.2 主页展示
主页提供 中医古籍主题轮播图 展示系统亮点内容,下方使用卡片式布局展示最近上线的方剂 ,每个方剂卡包含名称、主治、组成药物等信息,点击可查看详情。

3.3 病症推荐
系统利用 Spark MLlib 对用户历史浏览记录进行协同过滤训练,构建用户-病症-方剂的推荐模型,通过 PySpark 提交任务到 Spark集群 进行模型训练。
spark架构图:
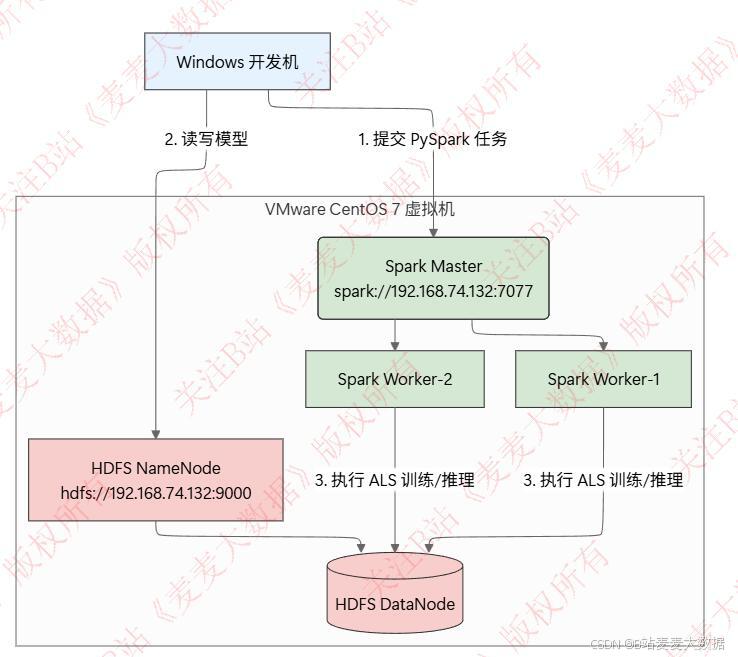
- 用户登录后,系统根据用户行为数据,通过训练模型给出个性化病症推荐。
- 推荐流程:
- 用户行为数据(如访问、收藏、点击)写入 MySQL;
- 每日或定时批处理任务加载数据,调用 Spark 进行模型训练;
- 训练结果保存至 HDFS;
- Flask服务启动时加载 HDFS 模型,通过 PySpark 提供推理接口;
- 推荐结果返回给前端,展示个性推荐列表。
通过 Docker Compose 部署 Spark 集群(
spark-master+2 spark-worker),实现高可用性与可扩展性。spark训练时序图:

spark推理时序图:
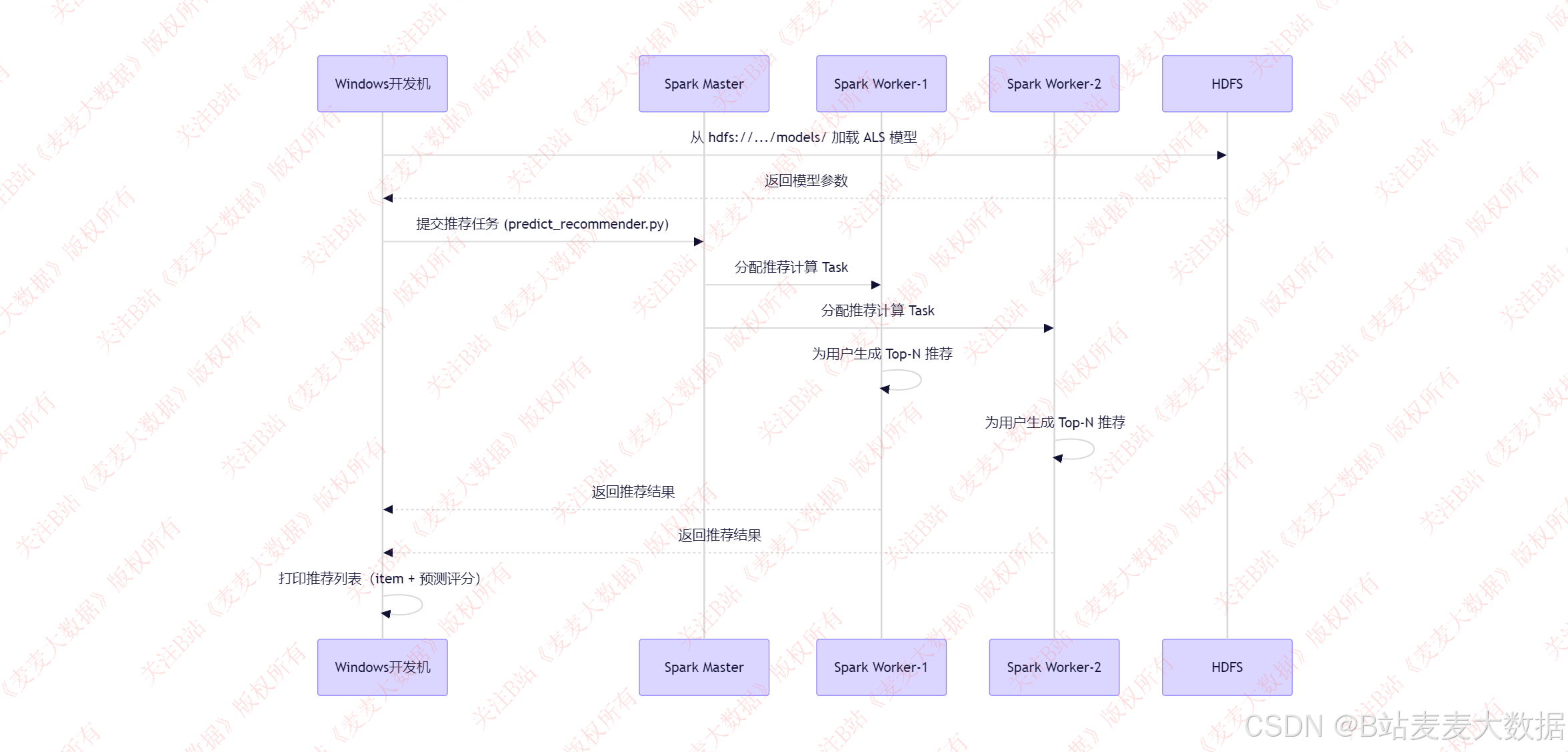
推荐加载中:

推荐结果:

3.4 知识图谱
系统构建 中医病症-症候-方剂-药材-性味归经-功效 等多维知识图谱,采用 Neo4j 存储,通过 Py2neo 与后端交互。
-
图谱结构示例:
疾病→ (has_symptom) →症候→ (uses_formula) →方剂→ (contains) →药材
药材→ (has_taste) →性味→ (is_rare) →归经→ (has_efficacy) →功效 -
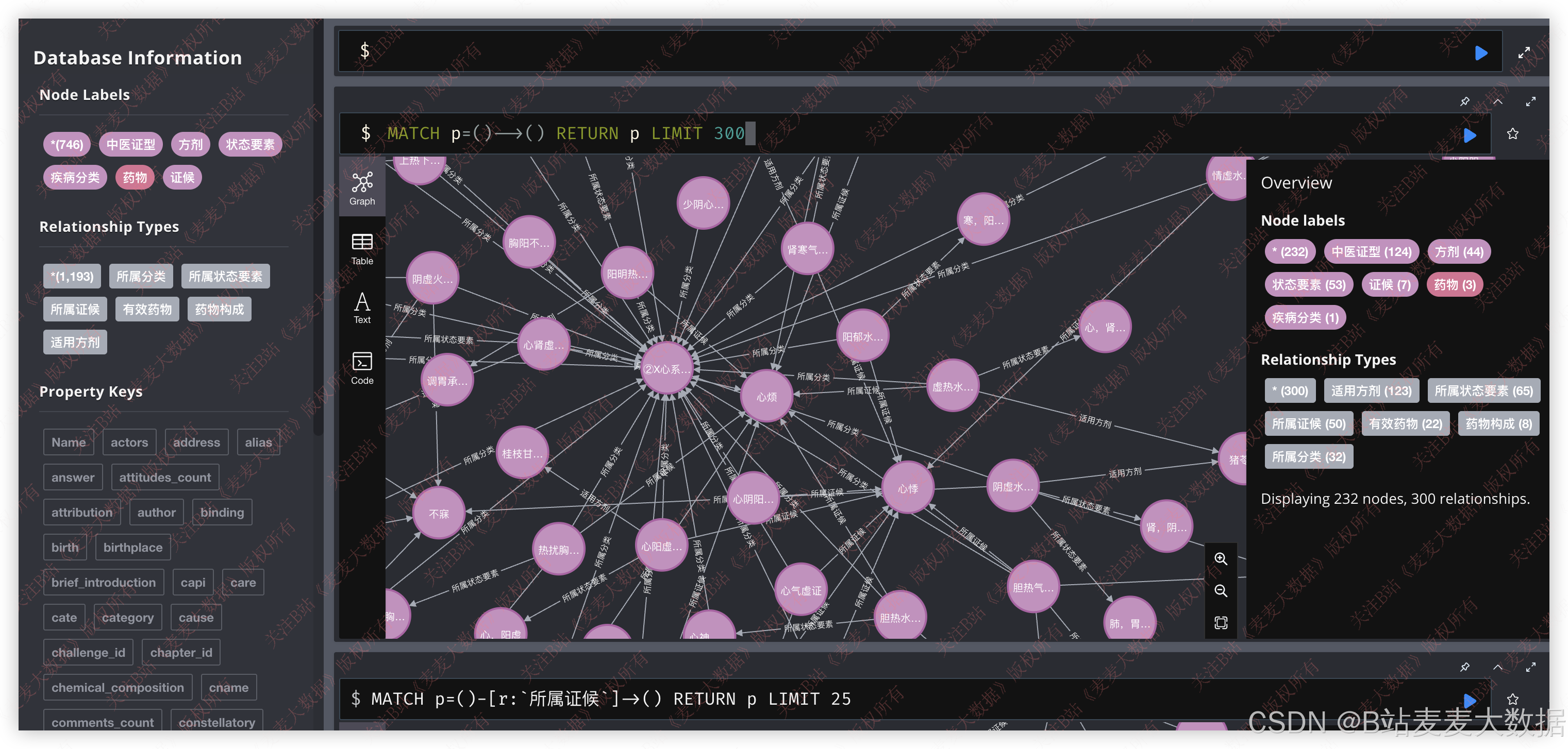
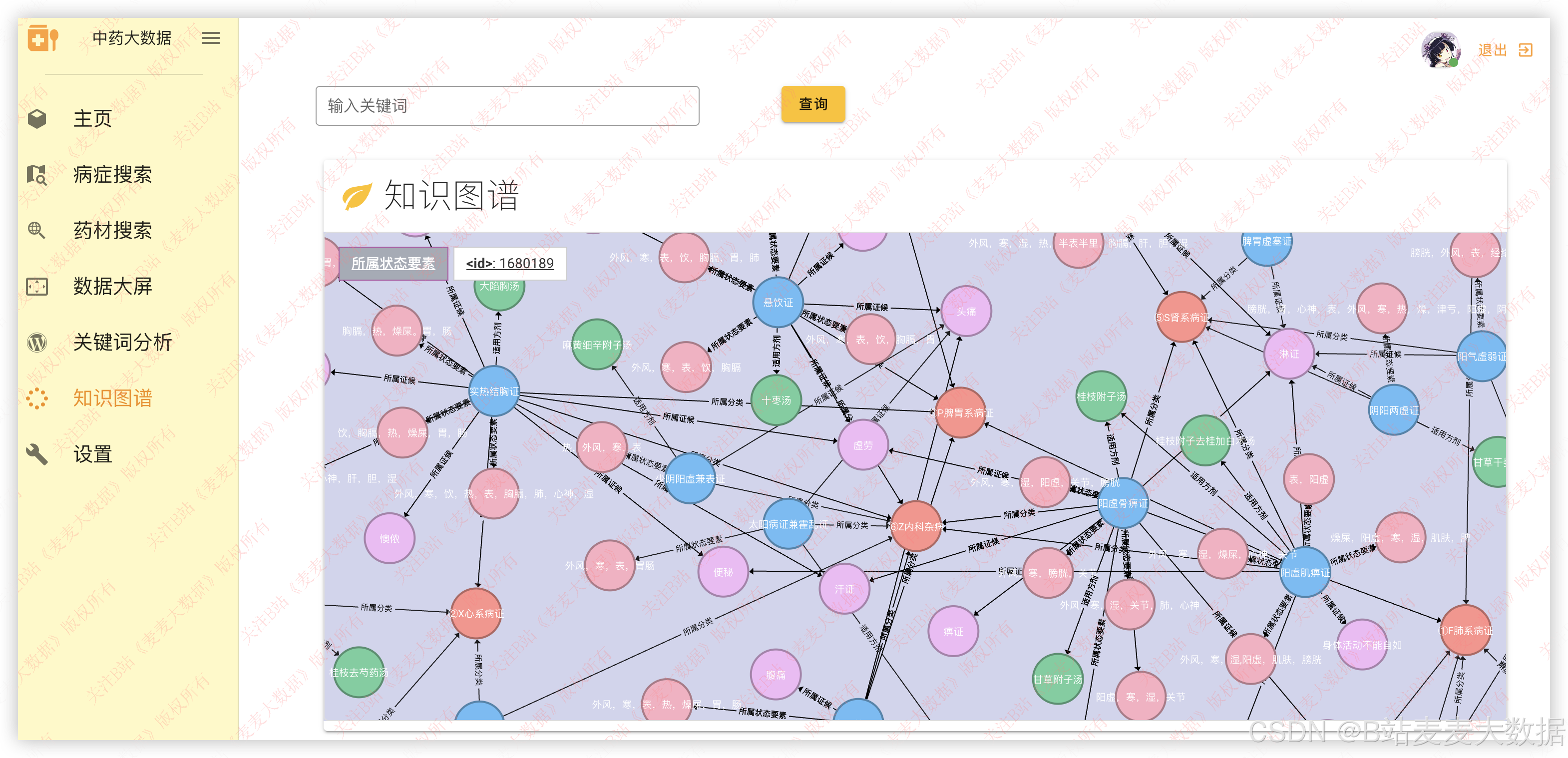
前端使用 D3.js 实现 力导向图 或 树状图 可视化,支持用户点击节点展开详细信息,具备高互动性。
知识图谱的构建:
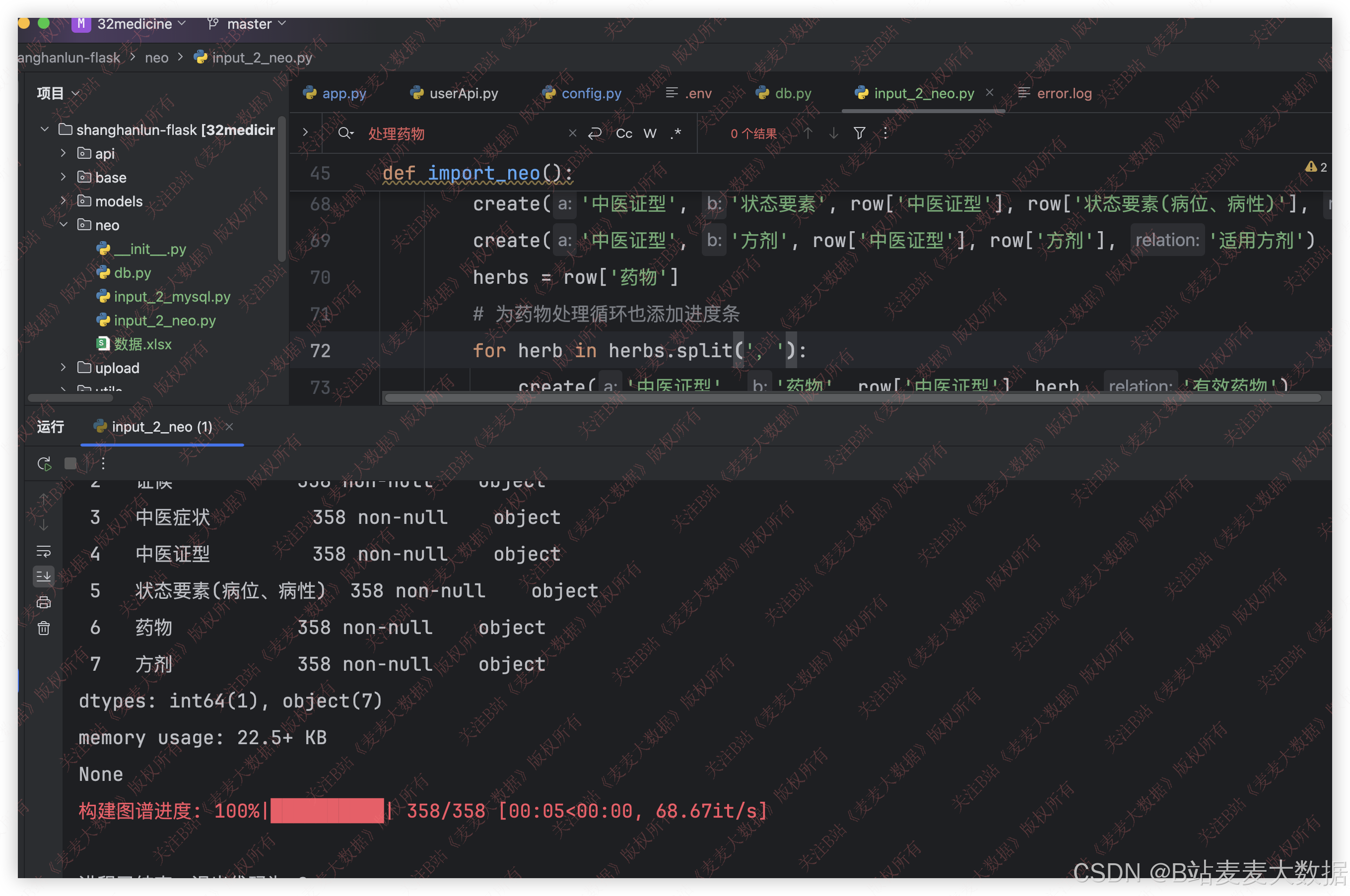
neo4j效果:
在系统内做的可视化效果:

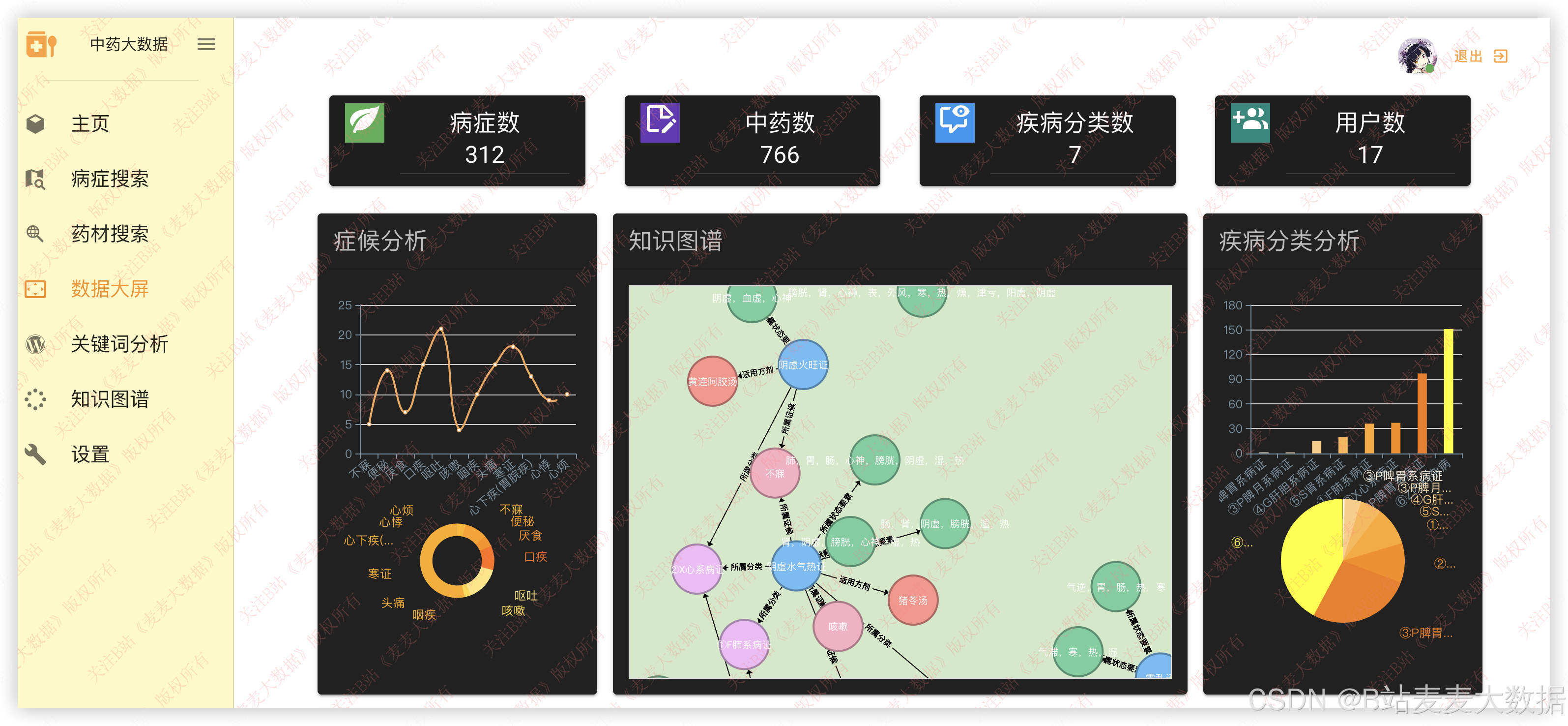
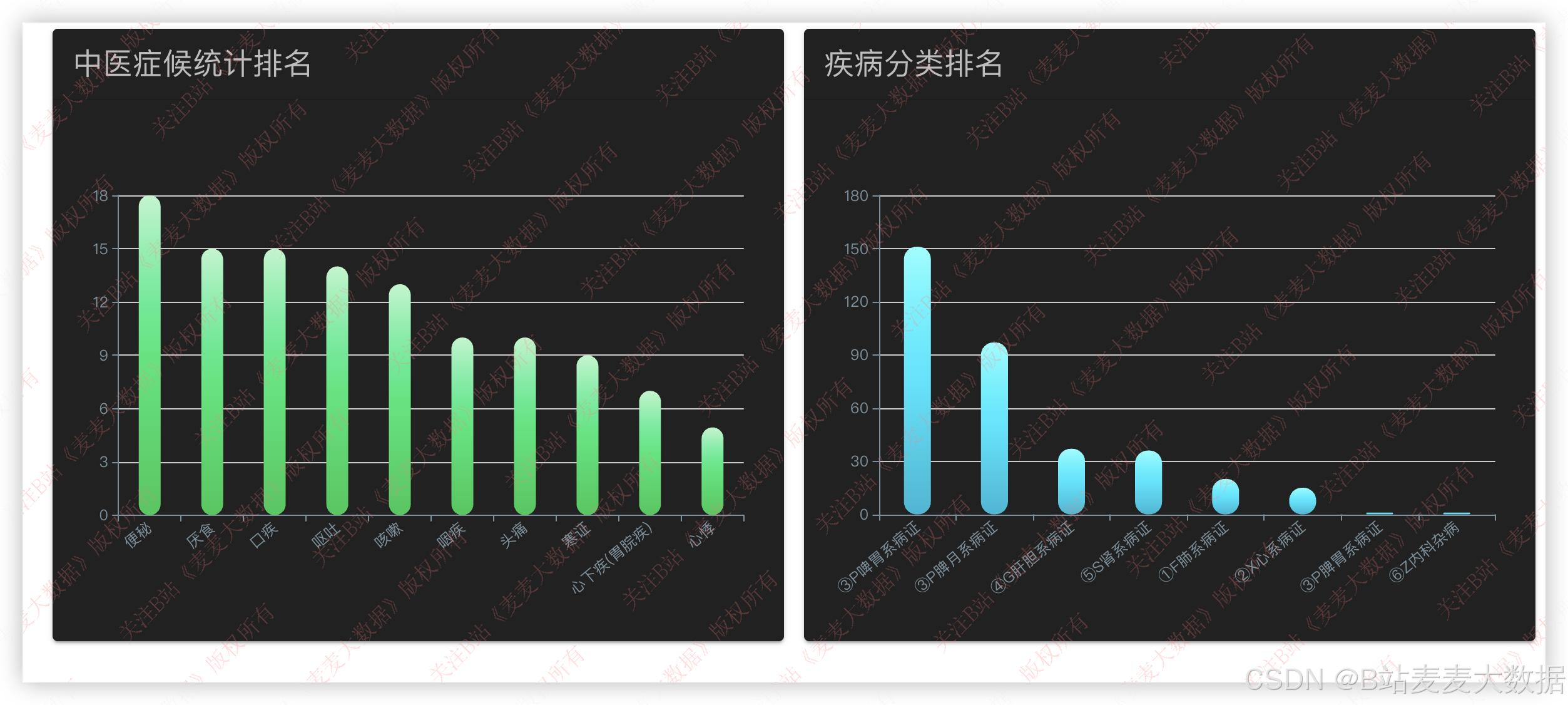
3.5 可视化分析
利用 ECharts 图形库实现多种统计分析图表:
- 症候分析图:饼图、条形图展示常见症候分布。
- 疾病分类排名:柱状图展示高频疾病类别。
- 症状热力图:显示症状在不同疾病中的出现频率。
分析数据来源为 Neo4j+MySQL 联合查询,后端通过 Flask APIs 提供接口,前端动态请求展示。
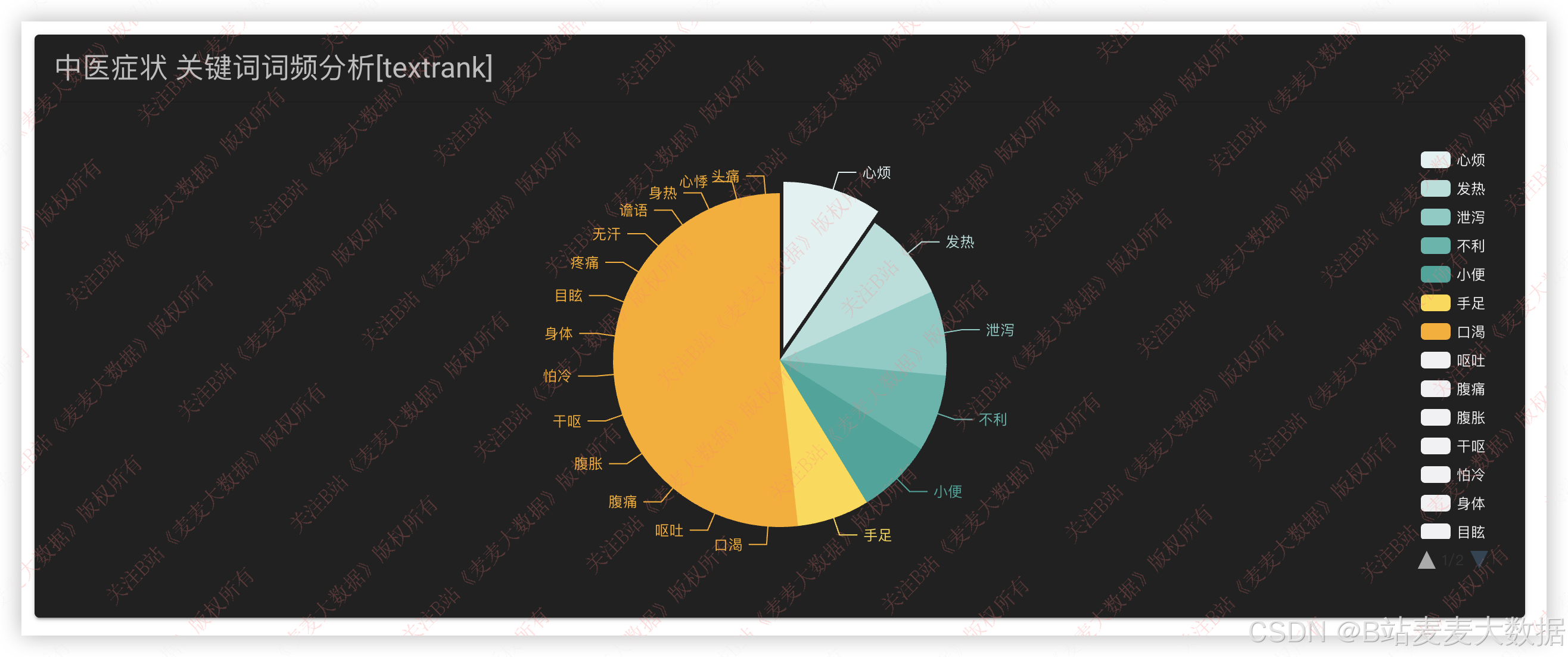
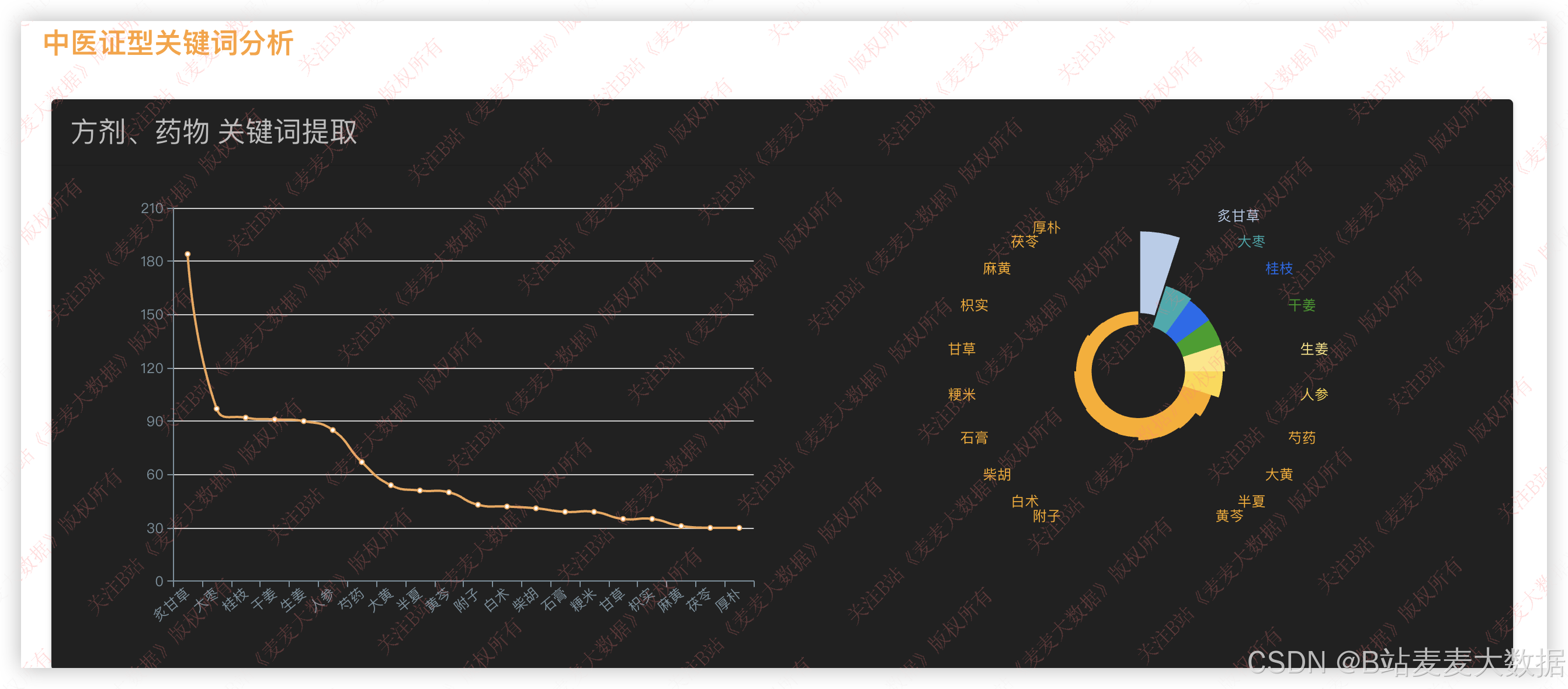
3.6 关键词分析
对中医证型中包含的药材进行 关键词提取 ,结合 TF-IDF 或 TextRank 算法,提取高频药物关键词,并生成:
- 折线图:展示关键词随时间(如不同古籍版本)的流行趋势。
- 花瓣图(Radial Chart) :展示药名与其在多个证型中出现的频次分布。
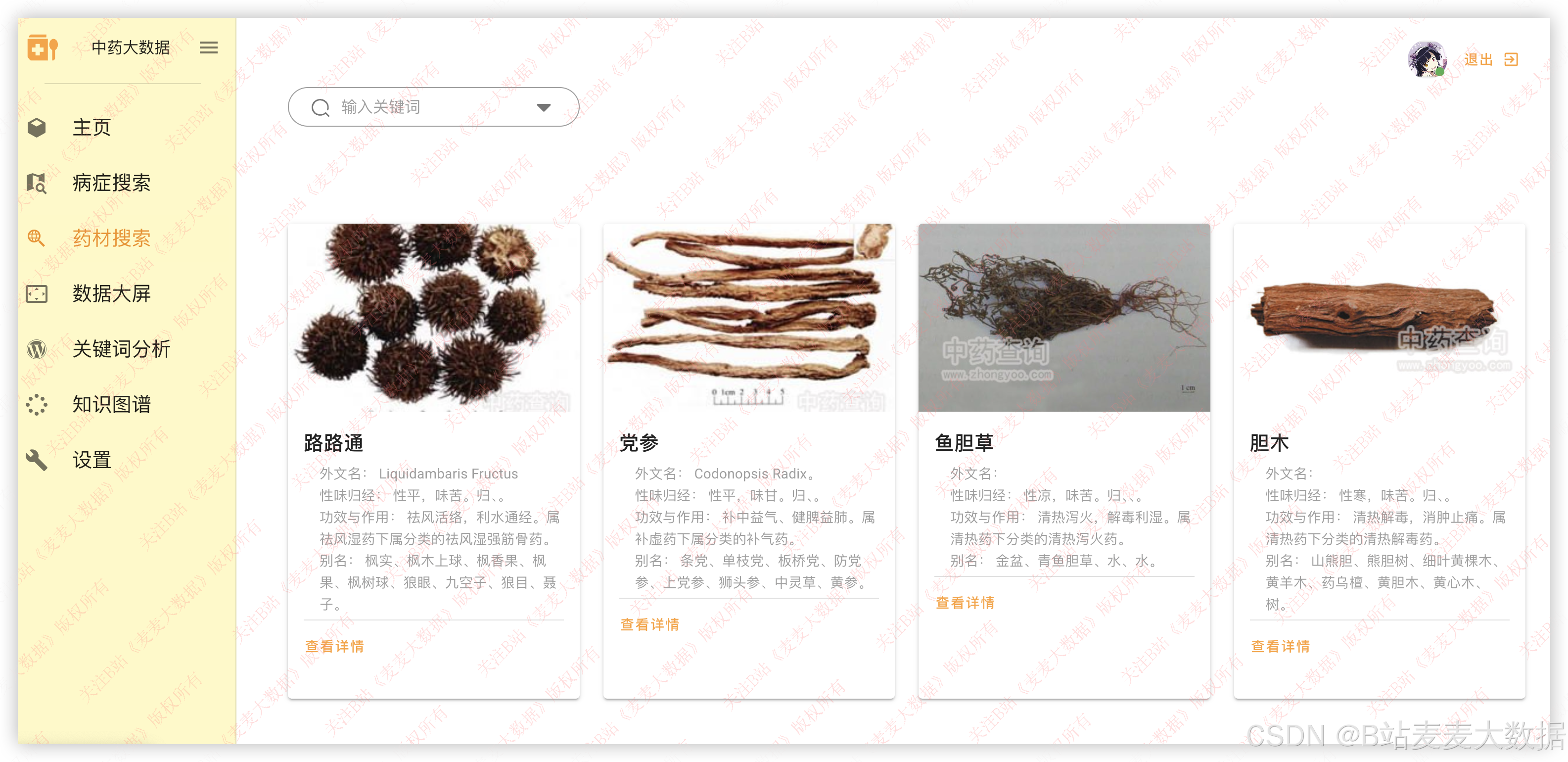
3.7 药材搜索
系统提供药材卡片查询功能:
- 每条药材以卡片形式展示:图片、名称、性味归经、主要功效。
- 点击卡片弹出详细信息对话框,展示:
- 药材分类
- 性味归经详情
- 功效与应用
- 配伍禁忌
- 后端通过 Neo4j + Py2neo 查询相关药材属性。
3.8 病症搜索
支持用户搜索病症或疾病,搜索结果以卡片展示:
- 卡片信息包括:
- 疾病分类
- 主要症候
- 典型症状
- 推荐方剂列表
- 点击方剂可跳转至方剂详情页,包含组成、功效与用法。
- 数据来自 Neo4j 知识图谱 。
)

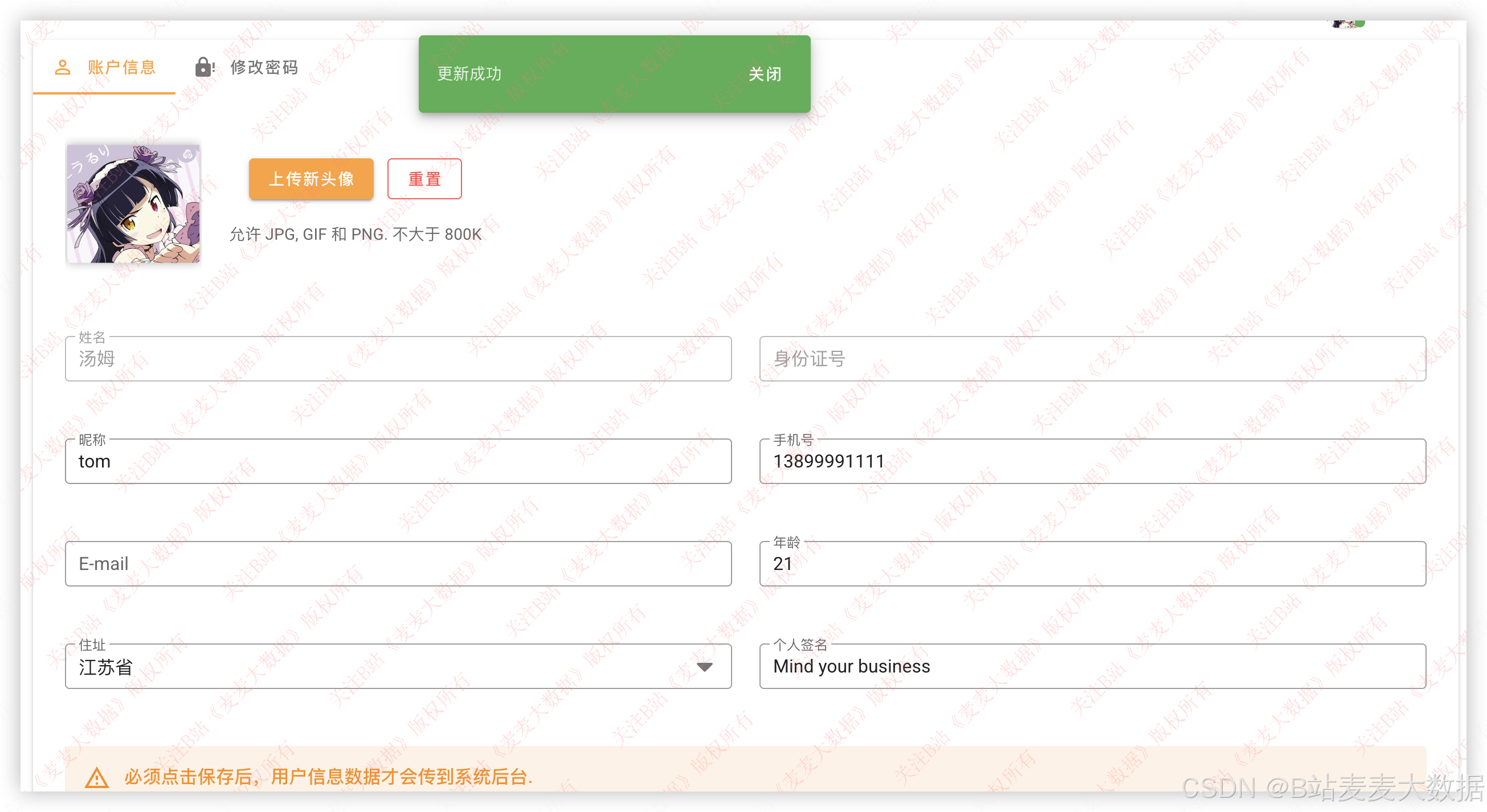
3.9 个人信息修改
用户可在个人设置界面进行信息修改,分为两个标签页:
- 基本信息页 :用户可上传头像(支持拖拽)、修改姓名、年龄、地址、性别等,保存至 MySQL。
- 密码修改页 :需输入旧密码、新密码,后端验证旧密码正确后更新加密密码(使用
bcrypt加密)。
3.11 推荐模型训练流程(补充)
推荐模型训练流程:
- 数据收集:从 MySQL 提取用户行为日志(浏览、收藏、点击);
- 数据预处理:使用 PySpark 清洗、转换数据格式,生成用户-方剂交互矩阵;
- 模型训练 :
- 使用 ALS(Alternating Least Squares) 协同过滤模型;
- 通过 Spark MLlib 运行训练;
- 模型存储 :将模型文件保存至 HDFS ,路径为
/models/recommend_model/; - 模型加载 :Flask 启动时,通过
spark_context加载模型,并提供预测接口; - 预测接口调用 :前端请求
/api/recommend,后端提供推荐列表。
4 程序核心算法代码
4.1 代码说明
系统核心包括:
- Spark 推荐模型训练代码(Python)
- Flask 推荐API接口
- Neo4j 图谱查询接口
- 前后端交互逻辑
4.2 流程图
是
否
用户登录
获取行为数据
是否可推荐?
调用Spark推荐模型
返回默认推荐
从HDFS加载模型
进行预测计算
返回推荐列表
前端展示推荐
4.3 代码实例
1. Spark 推荐模型训练代码 (recommendation_train.py)
python
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.ml.recommenders import ALS
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.sql.functions import col
import os
# 初始化 Spark
conf = SparkConf().setAppName("MedicalRecommendation")
sc = SparkContext(conf=conf)
spark = SparkSession.builder.appName("MedicalRecommendation").getOrCreate()
# 读取用户行为数据(假设数据已存在,结构为 user_id, formula_id, rating)
df = spark.read.format("csv").option("header", "true").load("hdfs://namenode:9000/data/user_actions.csv")
# 转换结构为 ALS 可接受格式
training_df = df.withColumn("user_id", col("user_id").cast("int")) \
.withColumn("formula_id", col("formula_id").cast("int")) \
.withColumn("rating", col("rating").cast("float"))
# 构建 ALS 模型
als = ALS(maxIter=10, regParam=0.1, userCol="user_id", itemCol="formula_id", ratingCol="rating")
model = als.fit(training_df)
# 保存模型到 HDFS
model.save("hdfs://namenode:9000/models/recommend_model/")
print("Model saved to HDFS!")2. Flask 推荐接口 (backend/app.py)
python
from flask import Flask, jsonify, request
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.ml.recommenders import ALSModel
import os
app = Flask(__name__)
# 初始化 Spark
conf = SparkConf().setAppName("FlaskRecommendation")
sc = SparkContext(conf=conf)
spark = SparkSession.builder.appName("FlaskRecommendation").getOrCreate()
# 加载模型
model_path = "hdfs://namenode:9000/models/recommend_model/"
model = ALSModel.load(model_path)
@app.route('/api/recommend', methods=['GET'])
def recommend():
user_id = int(request.args.get('user_id', 0))
# 获取 TopK 推荐
recommendations = model.recommendForUserSubset(spark.sparkContext.parallelize([(user_id,)]), 10)
result = []
for r in recommendations.collect():
result.extend([{"formula_id": row.formula_id, "rating": row.rating} for row in r.recommendations])
return jsonify(result)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)3. Neo4j 图谱查询示例 (backend/graph_query.py)
python
from py2neo import Graph
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password"))
def get_formula_by_disease(disease_name):
query = """
MATCH (d:Disease {name: $name})-[:USES]->(f:Formula)
RETURN f.name AS formula_name, f.components AS components
"""
result = graph.run(query, name=disease_name).data()
return result4. MySQL 用户表结构 (schema.sql)
sql
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL UNIQUE,
password_hash VARCHAR(128) NOT NULL,
name VARCHAR(50),
age INT,
gender VARCHAR(10),
address TEXT,
avatar_url VARCHAR(255),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);5. Docker Compose 部署 Spark 集群 (docker-compose.yml)
yaml
version: '3.8'
services:
spark-master:
image: bitnami/spark:3.3.0
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
volumes:
- ./data:/data
networks:
- spark-network
spark-worker1:
image: bitnami/spark:3.3.0
container_name: spark-worker1
ports:
- "8081:8081"
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark-master:7077
- SPARK_WORKER_MEMORY=1g
- SPARK_WORKER_CORES=1
depends_on:
- spark-master
networks:
- spark-network
spark-worker2:
image: bitnami/spark:3.3.0
container_name: spark-worker2
ports:
- "8082:8081"
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://spark-master:7077
- SPARK_WORKER_MEMORY=1g
- SPARK_WORKER_CORES=1
depends_on:
- spark-master
networks:
- spark-network
networks:
spark-network:
driver: bridge文章结尾部分有CSDN官方提供的学长 联系方式名片
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,私信获取! 麦麦大数据
编号: F052