一、先说结论:
在多卡 GPU服务器中(尤其是 A100),在坏卡后,可能导致各类应用对 CUDA 设备编号出现不一致。因此在检查各应用组件的安装状态都是正常后,尝试重启了 Fabric Manager:
bash
sudo systemctl restart nvidia-fabricmanager
sudo systemctl status nvidia-fabricmanager经重启 Fabric Manager后,少了显卡的服务器的CUDA在使用中恢复了正常。
二、查错过程
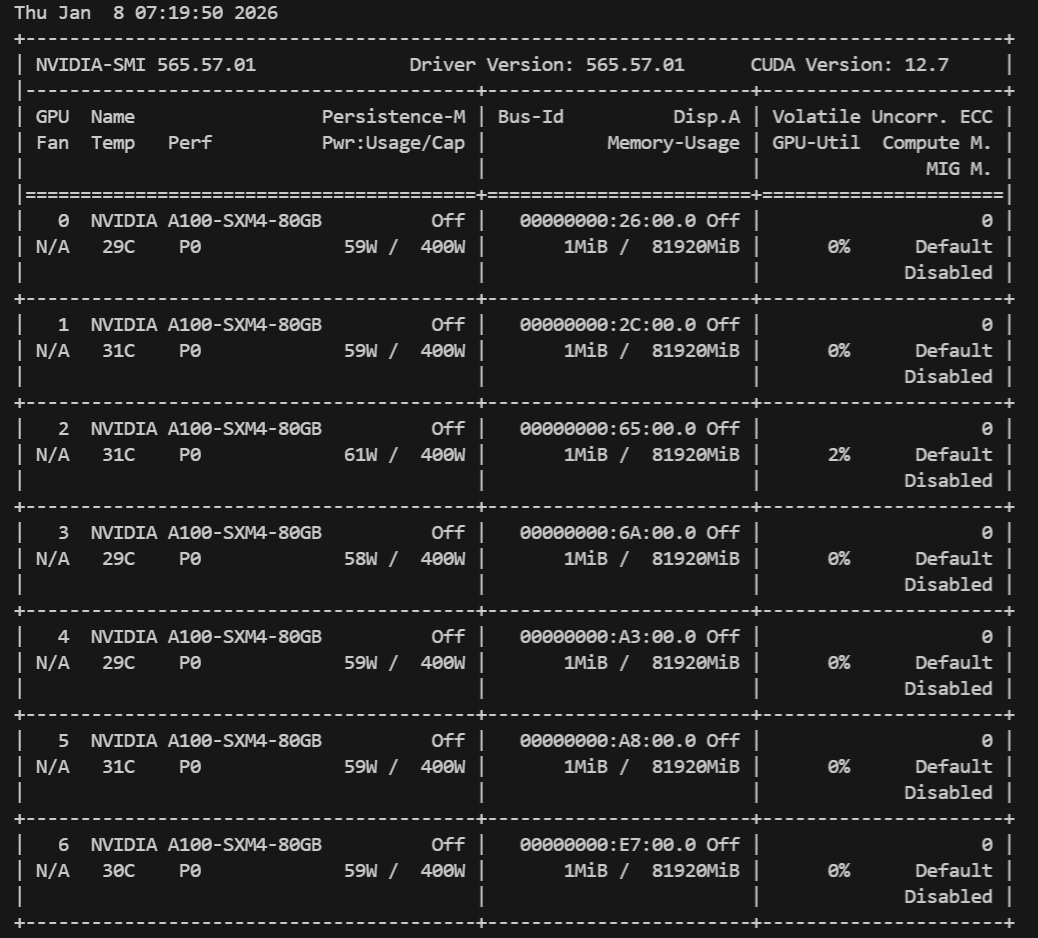
Ubuntu系统,排查发现CUDA的A100掉了一张。
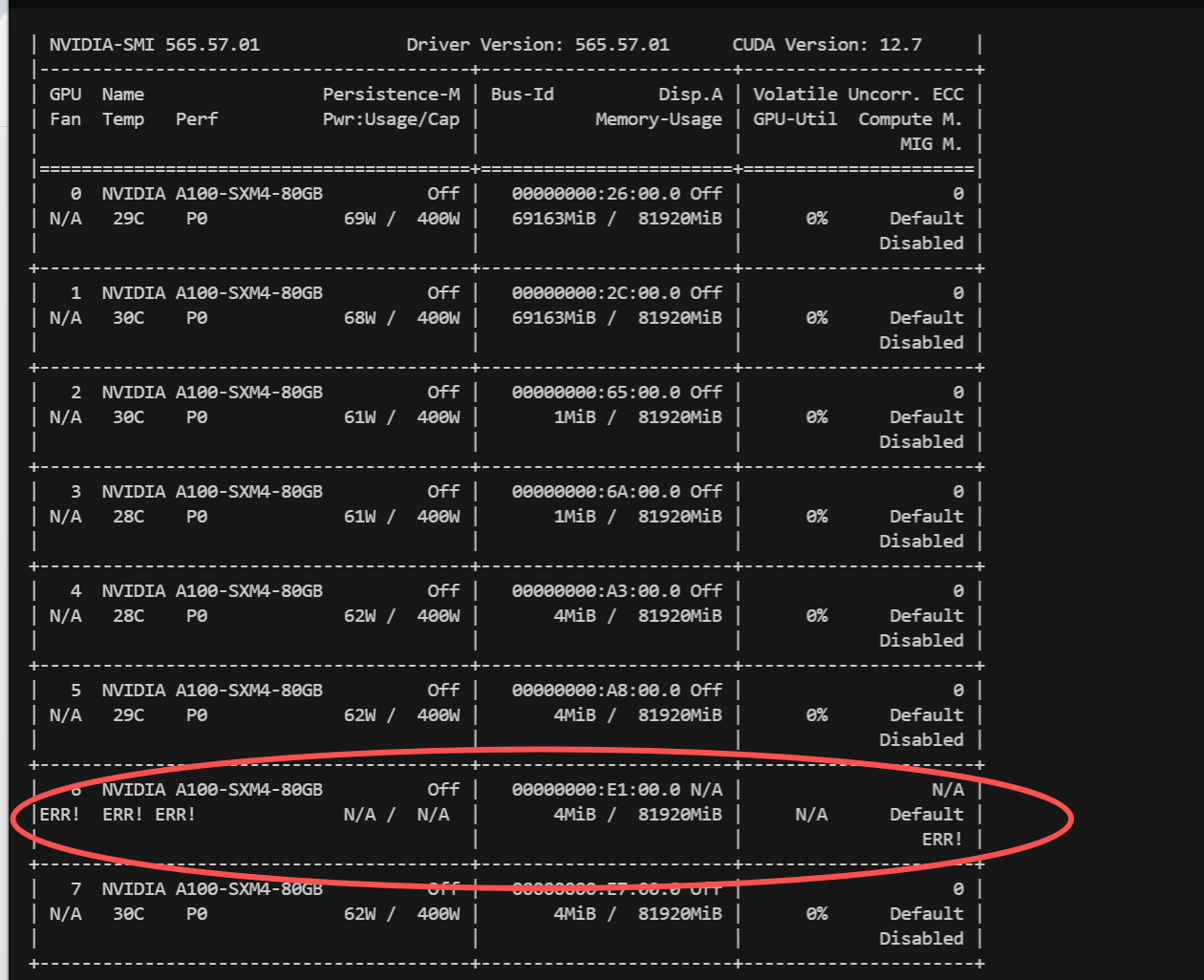
尝试重启后,仍有一张卡没有起来;联系运维后得知A100坏掉一张。
此时尝试重启docker服务,使用GPU的docker服务在重启时,均发现如下报错:
bash
ERROR: The NVIDIA Driver is present, but CUDA failed to initialize. GPU functionality will not be available.
[[ System not yet initialized (error 802) ]]
INFO 01-08 10:15:27 __init__.py:190] Automatically detected platform cuda.
/usr/local/lib/python3.10/dist-packages/torch/cuda/__init__.py:129: UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount().经排查NVIDIA 驱动、 CUDA Toolkit 、 CUDA Runtime甚至PCI 设备都是正常运行的。
NVSwitch :是 NVIDIA 开发的专用交换机芯片,用于实现多 GPU 系统间的高速全互联通信,提供高带宽、低延迟的数据传输。
NVLink 是英伟达(NVIDIA)开发并推出的一种总线及其通信协议。NVLink采用点对点结构、串列传输,用于中央处理器(CPU)与图形处理器(GPU)之间的连接,也可用于多个图形处理器之间的相互连接。
GPU Fabric 是 NVSwitch 平台中,由 Fabric Manager 管理的 GPU 互连拓扑,它决定了 GPU 之间是否可以高效、对称地进行点对点通信与协同计算。
Fabric Manager 是 NVSwitch 平台的控制平面(Control Plane),负责把多个 GPU 和 NVSwitch 组织成一个逻辑统一的计算网络,并将该网络的状态同步给 NVIDIA 驱动与 CUDA 运行时。
NVSwitch 是硬件,nvidia-fabricmanager 是负责管理 NVSwitch 与 GPU Fabric 的系统服务。
没有 Fabric Manager,NVSwitch 是通着电的交换芯片,GPU 无法组成可用的 CUDA Fabric。
在多卡 GPU服务器中(尤其是 A100),在坏卡后,可能导致各类应用对 CUDA 设备编号出现不一致。因此在检查各应用组件的安装状态都是正常后,尝试重启了 Fabric Manager:
bash
sudo systemctl restart nvidia-fabricmanager
sudo systemctl status nvidia-fabricmanager经重启 Fabric Manager后,少了显卡的服务器的CUDA在使用中恢复了正常。