视频演示
基于深度学习的驾驶行为检测系统
目录
[1. 前言](#1. 前言)
[2. 项目演示](#2. 项目演示)
[2.1 用户登录界面](#2.1 用户登录界面)
[2.2 新用户注册](#2.2 新用户注册)
[2.3 主界面布局](#2.3 主界面布局)
[2.4 个人信息管理](#2.4 个人信息管理)
[2.5 多模态检测展示](#2.5 多模态检测展示)
[2.6 检测结果保存](#2.6 检测结果保存)
[2.7 多模型切换](#2.7 多模型切换)
[4. 技术栈](#4. 技术栈)
[5. YOLO模型对比与识别效果解析](#5. YOLO模型对比与识别效果解析)
[5.1 YOLOv5/YOLOv8/YOLOv11/YOLOv12模型对比](#5.1 YOLOv5/YOLOv8/YOLOv11/YOLOv12模型对比)
[5.2 数据集分析](#5.2 数据集分析)
[5.3 训练结果](#5.3 训练结果)
[6. 源码获取方式](#6. 源码获取方式)
1. 前言
大家好,欢迎来到Coding茶水间!
在智能驾驶安全领域,驾驶员行为监测是预防事故的关键环节。传统方式依赖人工观察或单一传感器,存在实时性差、漏检率高、无法多行为同步分析等问题。而基于计算机视觉的目标检测技术,尤其是YOLO(You Only Look Once)算法,凭借其实时性强、精度高的特点,已成为驾驶行为分析的主流方案。
今天给大家介绍的,正是这样一套基于YOLO算法的驾驶行为检测系统------它能精准识别驾驶员行车过程中的多种典型行为,包括分心(如看手机、喝水、吃东西)、异常姿态(手离方向盘、手放头上)、注意力分散(左右张望、看手套箱)、正常驾驶等,为安全驾驶提供实时预警与数据支持。
接下来带大家快速了解系统的核心功能:主界面采用三区布局设计,左侧是功能按钮区(支持图片/视频/文件夹批量检测/摄像头实时检测/模型切换),中间是检测展示区(含置信度/交并比参数调节、实时画面预览、检测目标列表及语音播报),右侧是统计与详情区(类别统计、单项数据详情展示)。系统还集成了结果保存(带标注的图片/视频)、数据导出(Excel表格)、用户登录管理(个人中心/信息修改)等实用模块。
现在,我们就从主界面开始,带大家一步步体验这套系统的实际检测效果!
2. 项目演示
2.1 用户登录界面
登录界面布局简洁清晰,左侧展示系统主题,用户需输入用户名、密码及验证码完成身份验证后登录系统。

2.2 新用户注册
注册时可自定义用户名与密码,支持上传个人头像;如未上传,系统将自动使用默认头像完成账号创建。

2.3 主界面布局
主界面采用三栏结构,左侧为功能操作区,中间用于展示检测画面,右侧呈现目标详细信息,布局合理,交互流畅。

2.4 个人信息管理
用户可在此模块中修改密码或更换头像,个人信息支持随时更新与保存。
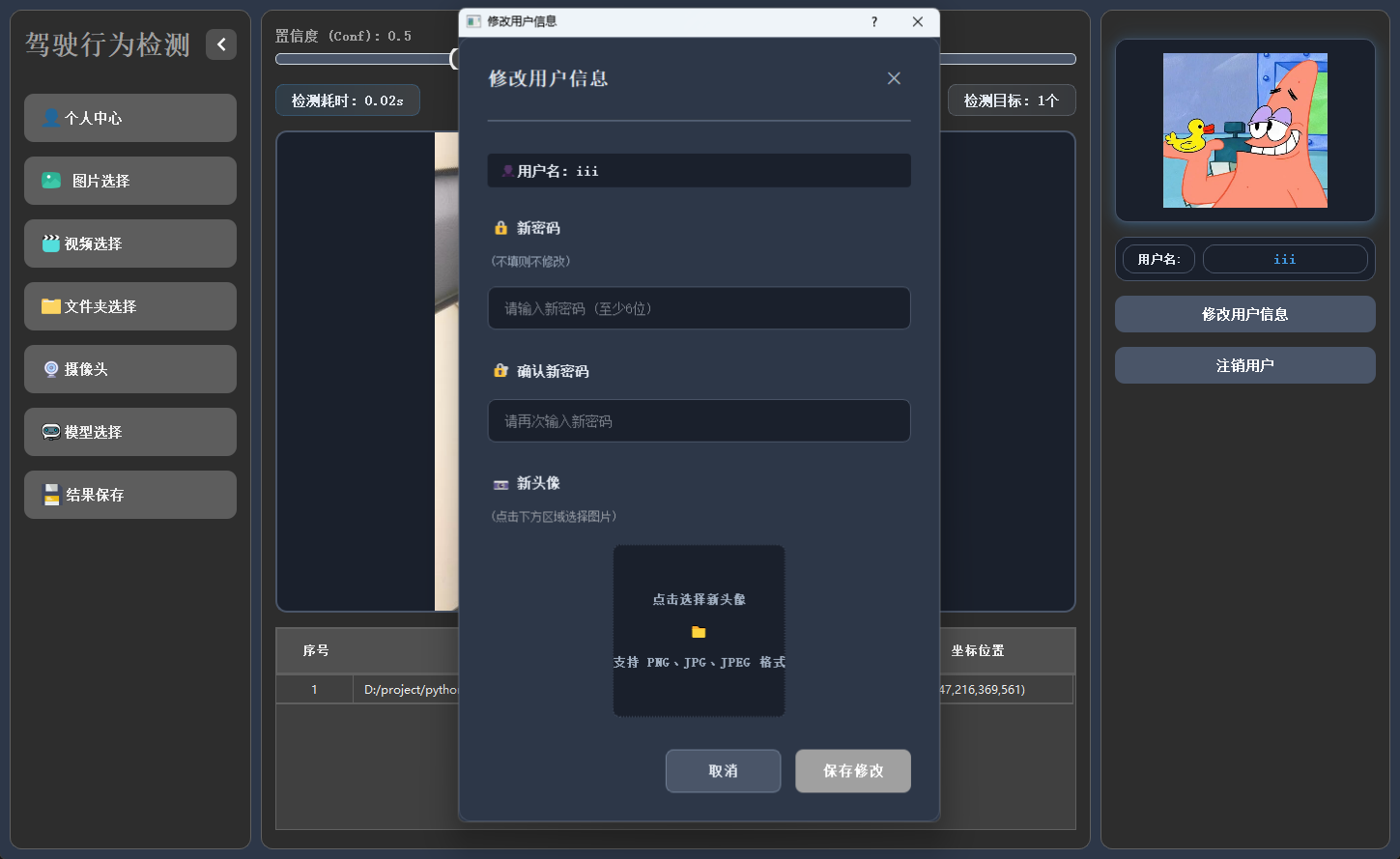
2.5 多模态检测展示
系统支持图片、视频及摄像头实时画面的目标检测。识别结果将在画面中标注显示,并且带有语音播报提醒,并在下方列表中逐项列出。点击具体目标可查看其类别、置信度及位置坐标等详细信息。
2.6 检测结果保存
可以将检测后的图片、视频进行保存,生成新的图片和视频,新生成的图片和视频中会带有检测结果的标注信息,并且还可以将所有检测结果的数据信息保存到excel中进行,方便查看检测结果。
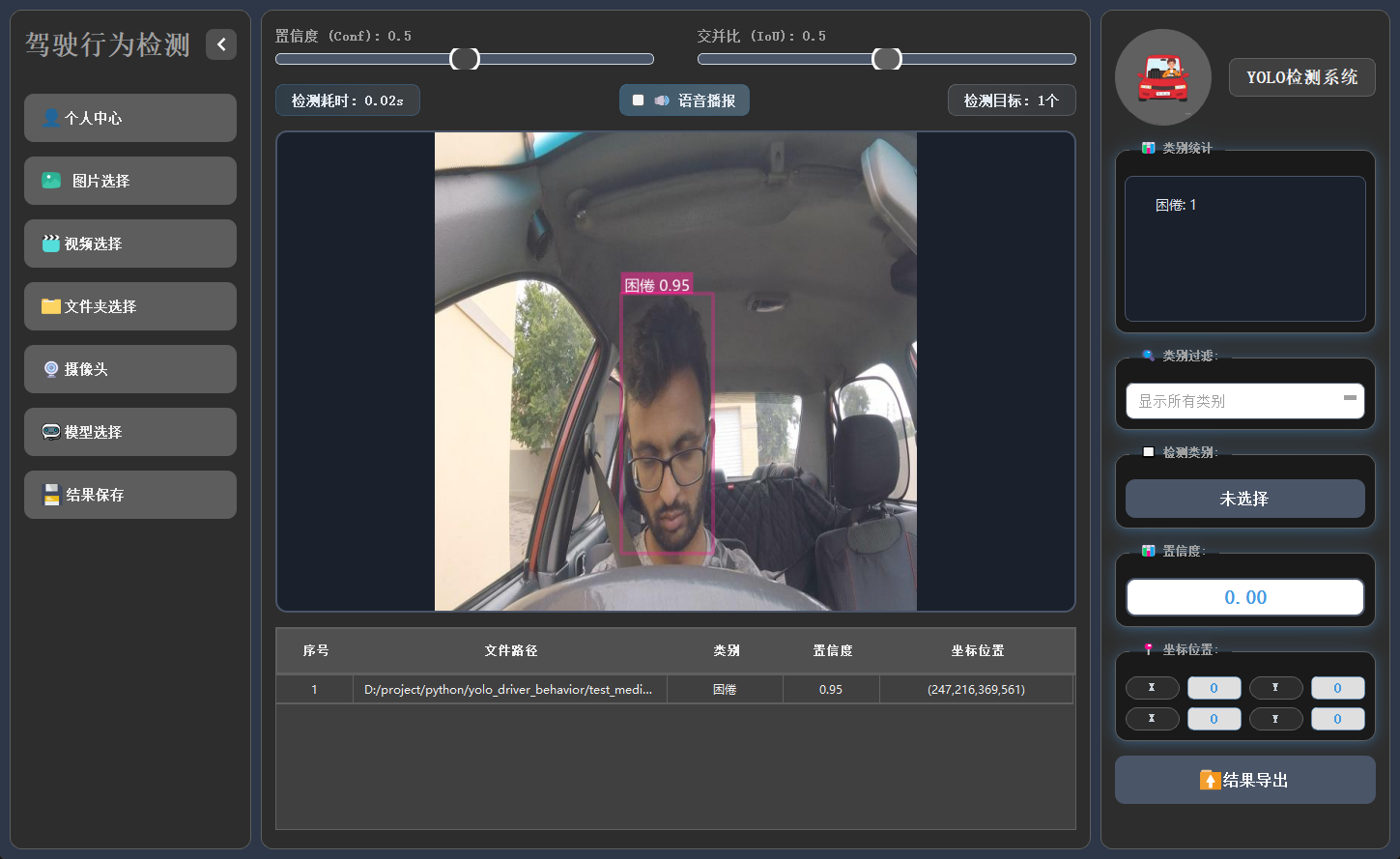
2.7 多模型切换
系统内置多种已训练模型,用户可根据实际需求灵活切换,以适应不同检测场景或对比识别效果。
3.模型训练核心代码
本脚本是YOLO模型批量训练工具,可自动修正数据集路径为绝对路径,从pretrained文件夹加载预训练模型,按设定参数(100轮/640尺寸/批次8)一键批量训练YOLOv5nu/v8n/v11n/v12n模型。
python
# -*- coding: utf-8 -*-
"""
该脚本用于执行YOLO模型的训练。
它会自动处理以下任务:
1. 动态修改数据集配置文件 (data.yaml),将相对路径更新为绝对路径,以确保训练时能正确找到数据。
2. 从 'pretrained' 文件夹加载指定的预训练模型。
3. 使用预设的参数(如epochs, imgsz, batch)启动训练过程。
要开始训练,只需直接运行此脚本。
"""
import os
import yaml
from pathlib import Path
from ultralytics import YOLO
def main():
"""
主训练函数。
该函数负责执行YOLO模型的训练流程,包括:
1. 配置预训练模型。
2. 动态修改数据集的YAML配置文件,确保路径为绝对路径。
3. 加载预训练模型。
4. 使用指定参数开始训练。
"""
# --- 1. 配置模型和路径 ---
# 要训练的模型列表
models_to_train = [
{'name': 'yolov5nu.pt', 'train_name': 'train_yolov5nu'},
{'name': 'yolov8n.pt', 'train_name': 'train_yolov8n'},
{'name': 'yolo11n.pt', 'train_name': 'train_yolo11n'},
{'name': 'yolo12n.pt', 'train_name': 'train_yolo12n'}
]
# 获取当前工作目录的绝对路径,以避免相对路径带来的问题
current_dir = os.path.abspath(os.getcwd())
# --- 2. 动态配置数据集YAML文件 ---
# 构建数据集yaml文件的绝对路径
data_yaml_path = os.path.join(current_dir, 'train_data', 'data.yaml')
# 读取原始yaml文件内容
with open(data_yaml_path, 'r', encoding='utf-8') as f:
data_config = yaml.safe_load(f)
# 将yaml文件中的 'path' 字段修改为数据集目录的绝对路径
# 这是为了确保ultralytics库能正确定位到训练、验证和测试集
data_config['path'] = os.path.join(current_dir, 'train_data')
# 将修改后的配置写回yaml文件
with open(data_yaml_path, 'w', encoding='utf-8') as f:
yaml.dump(data_config, f, default_flow_style=False, allow_unicode=True)
# --- 3. 循环训练每个模型 ---
for model_info in models_to_train:
model_name = model_info['name']
train_name = model_info['train_name']
print(f"\n{'='*60}")
print(f"开始训练模型: {model_name}")
print(f"训练名称: {train_name}")
print(f"{'='*60}")
# 构建预训练模型的完整路径
pretrained_model_path = os.path.join(current_dir, 'pretrained', model_name)
if not os.path.exists(pretrained_model_path):
print(f"警告: 预训练模型文件不存在: {pretrained_model_path}")
print(f"跳过模型 {model_name} 的训练")
continue
try:
# 加载指定的预训练模型
model = YOLO(pretrained_model_path)
# --- 4. 开始训练 ---
print(f"开始训练 {model_name}...")
# 调用train方法开始训练
model.train(
data=data_yaml_path, # 数据集配置文件
epochs=100, # 训练轮次
imgsz=640, # 输入图像尺寸
batch=8, # 每批次的图像数量
name=train_name, # 模型名称
)
print(f"{model_name} 训练完成!")
except Exception as e:
print(f"训练 {model_name} 时出现错误: {str(e)}")
print(f"跳过模型 {model_name},继续训练下一个模型")
continue
print(f"\n{'='*60}")
print("所有模型训练完成!")
print(f"{'='*60}")
if __name__ == "__main__":
# 当该脚本被直接执行时,调用main函数
main()4. 技术栈
-
语言:Python 3.10
-
前端界面:PyQt5
-
数据库:SQLite(存储用户信息)
-
模型:YOLOv5、YOLOv8、YOLOv11、YOLOv12
5. YOLO模型对比与识别效果解析
5.1 YOLOv5/YOLOv8/YOLOv11/YOLOv12模型对比
基于Ultralytics官方COCO数据集训练结果:
| 模型 | 尺寸(像素) | mAPval 50-95 | 速度(CPU ONNX/毫秒) | 参数(M) | FLOPs(B) |
|---|---|---|---|---|---|
| YOLO12n | 640 | 40.6 | - | 2.6 | 6.5 |
| YOLO11n | 640 | 39.5 | 56.1 ± 0.8 | 2.6 | 6.5 |
| YOLOv8n | 640 | 37.3 | 80.4 | 3.2 | 8.7 |
| YOLOv5nu | 640 | 34.3 | 73.6 | 2.6 | 7.7 |
关键结论:
-
精度最高:YOLO12n(mAP 40.6%),显著领先其他模型(较YOLOv5nu高约6.3个百分点);
-
速度最优:YOLO11n(CPU推理56.1ms),比YOLOv8n快42%,适合实时轻量部署;
-
效率均衡:YOLO12n/YOLO11n/YOLOv8n/YOLOv5nu参数量均为2.6M,FLOPs较低(YOLO12n/11n仅6.5B);YOLOv8n参数量(3.2M)与计算量(8.7B)最高,但精度优势不明显。
综合推荐:
-
追求高精度:优先选YOLO12n(精度与效率兼顾);
-
需高速低耗:选YOLO11n(速度最快且精度接近YOLO12n);
-
YOLOv5nu/YOLOv8n因性能劣势,无特殊需求时不建议首选。
5.2 数据集分析

数据集中训练集和验证集一共3300张图片,数据集目标类别两种:正常肾脏,肾结石,数据集配置代码如下:
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 15
names: ['Distracted_Behind', 'Distracted_Foward', 'Distracted_Glovebox', 'Distracted_HandOffWheel', 'Distracted_HandOnHead', 'Distracted_Left', 'Distracted_Radio', 'Distracted_Right', 'Normal_Driving', 'awake', 'drinking', 'drowsy', 'eating', 'mobile use', 'smoking']

上面的图片就是部分样本集训练中经过数据增强后的效果标注。
5.3 训练结果
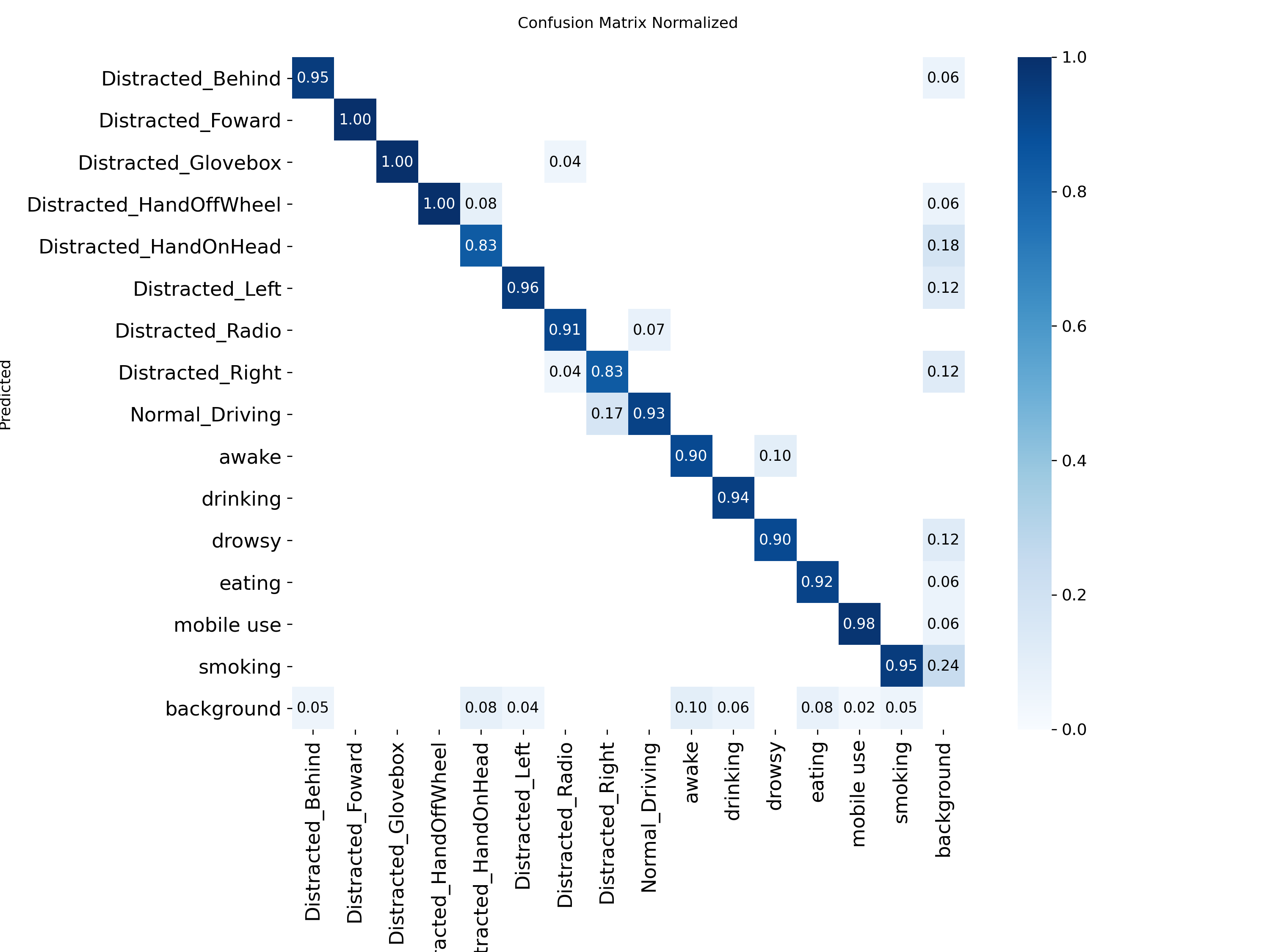
混淆矩阵显示中识别精准度显示是一条对角线,方块颜色越深代表对应的类别识别的精准度越高。

F1指数(F1 Score)是统计学和机器学习中用于评估分类模型性能的核心指标,综合了模型的精确率(Precision)和召回率(Recall),通过调和平均数平衡两者的表现。
当置信度为0.403时,所有类别的综合F1值达到了0.94(蓝色曲线)。
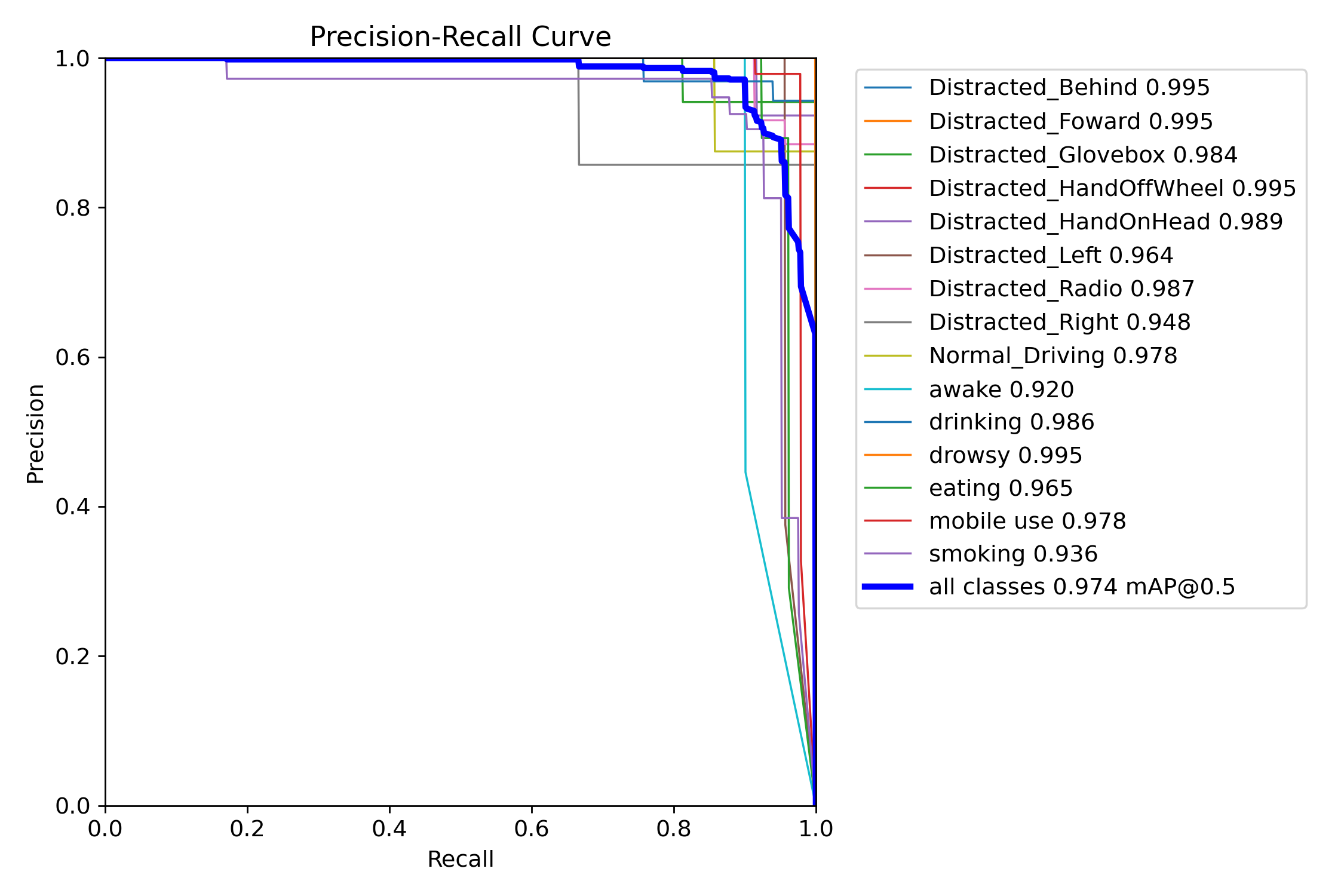
mAP@0.5:是目标检测任务中常用的评估指标,表示在交并比(IoU)阈值为0.5时计算的平均精度均值(mAP)。其核心含义是:只有当预测框与真实框的重叠面积(IoU)≥50%时,才认为检测结果正确。
图中可以看到综合mAP@0.5达到了0.974(97.4%),准确率非常高。