
一、研究背景
- 目的:对比五种主流深度学习模型在分类任务中的性能,为模型选择提供实证依据。
- 背景:随着深度学习发展,多种网络结构(如Transformer、BiLSTM、CNN等)被提出,但其在不同任务上的表现差异缺乏系统对比。
二、主要功能
- 数据预处理:支持数据读取、归一化、类别平衡划分、格式转换。
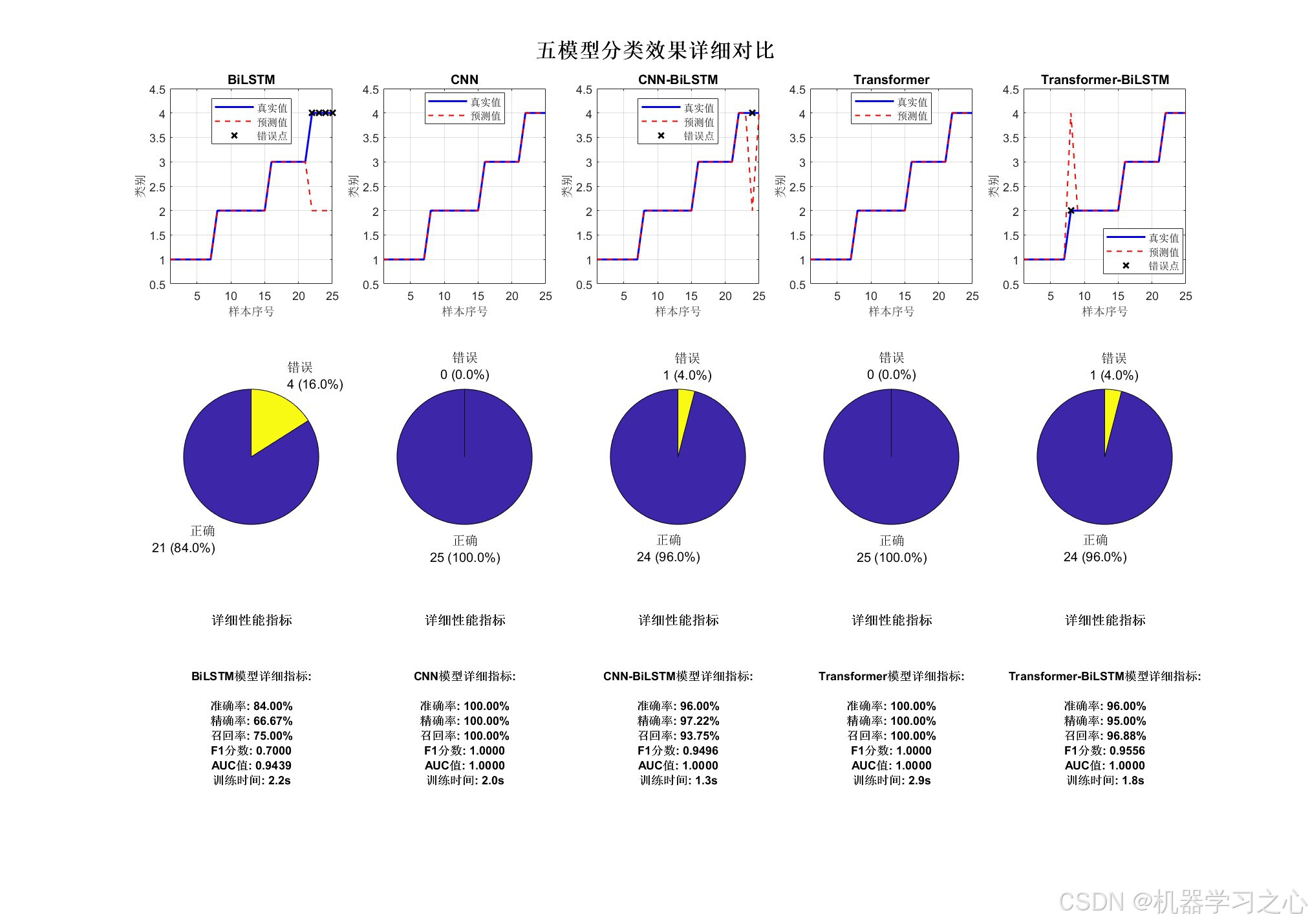
- 模型构建 :实现五种模型:
- BiLSTM
- CNN
- CNN-BiLSTM
- Transformer
- Transformer-BiLSTM
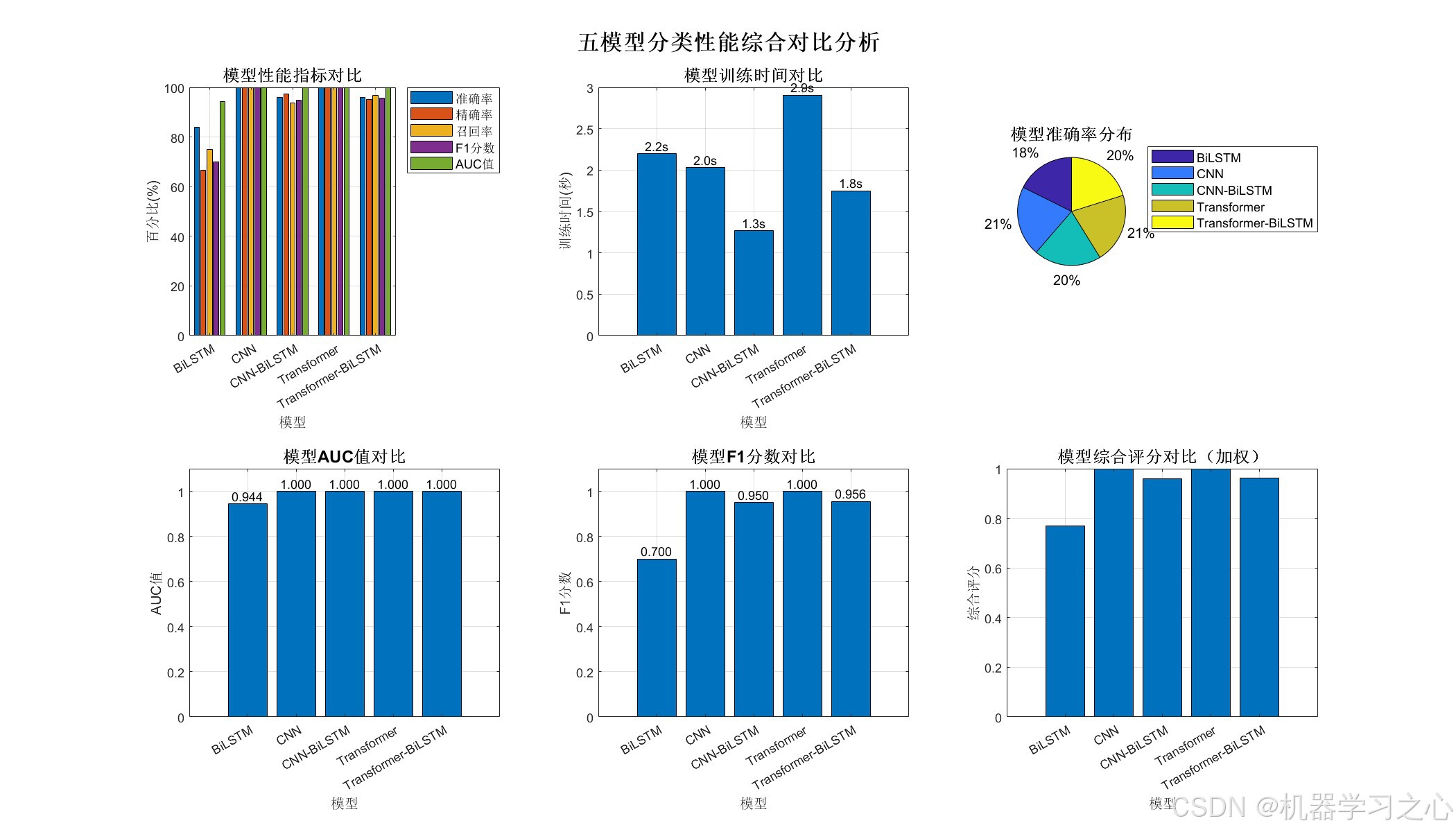
- 训练与评估:自动训练并计算多项性能指标(准确率、精确率、召回率、F1、AUC)。
- 可视化对比:生成综合对比图、分类效果图、混淆矩阵等。
- 结果保存:保存模型、预测结果和评估指标。
三、算法步骤
- 数据准备 :
- 读取Excel数据 → 按类别分层划分训练/测试集 → 归一化处理。
- 为不同模型转换为对应输入格式(cell数组、4D数组等)。
- 模型定义 :
- 使用MATLAB的
layerGraph或layer数组构建五种网络。
- 使用MATLAB的
- 训练循环 :
- 使用
trainNetwork训练每个模型。 - 记录训练时间、损失变化。
- 使用
- 预测与评估 :
- 使用测试集预测 → 计算多项分类指标。
- 可视化与报告 :
- 绘制性能对比图、混淆矩阵、分类效果图。
- 输出最佳模型及综合报告。
四、技术路线
-
平台:MATLAB + Deep Learning Toolbox。
-
数据流 :
原始数据 → 预处理 → 格式转换 → 模型训练 → 预测 → 评估 → 可视化 -
模型结构 :
- CNN:卷积层 + 池化层 + 全连接层。
- BiLSTM:双向LSTM + Dropout。
- Transformer:位置编码 + 自注意力层 + 全连接层。
- 混合模型:CNN提取特征 + BiLSTM/Transformer处理时序依赖。
五、公式原理(核心算法)
-
BiLSTM :
ht=LSTM(xt,ht−1)(正向) h_t = \text{LSTM}(x_t, h_{t-1}) \quad \text{(正向)} ht=LSTM(xt,ht−1)(正向)
ht′=LSTM(xt,ht+1′)(反向) h_t' = \text{LSTM}(x_t, h_{t+1}') \quad \text{(反向)} ht′=LSTM(xt,ht+1′)(反向)
Ht=ht;ht′ H_t = h_t; h_t' Ht=ht;ht′ -
自注意力(Transformer) :
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V -
CNN卷积操作 :
yi,j=∑m∑nwm,n⋅xi+m,j+n+b y_{i,j} = \sum_{m} \sum_{n} w_{m,n} \cdot x_{i+m, j+n} + b yi,j=m∑n∑wm,n⋅xi+m,j+n+b -
评估指标:
- 准确率:TP+TN总样本数\frac{TP+TN}{总样本数}总样本数TP+TN
- F1分数:2⋅精确率⋅召回率精确率+召回率\frac{2 \cdot \text{精确率} \cdot \text{召回率}}{\text{精确率} + \text{召回率}}精确率+召回率2⋅精确率⋅召回率
- AUC:ROC曲线下面积。
六、参数设定
| 参数 | 说明 | 默认值 |
|---|---|---|
data_file |
数据文件路径 | data.xlsx |
train_ratio |
训练集比例 | 0.7 |
max_epochs |
最大训练轮数 | 100 |
mini_batch_size |
批大小 | 64 |
initial_learn_rate |
初始学习率 | 0.001 |
numHeads(Transformer) |
注意力头数 | 4 |
numKeyChannels |
注意力键通道数 | 128 |
七、运行环境
- 软件:MATLAB R2024b 或更高版本。
- 数据格式:Excel文件,最后一列为标签,其余列为特征。
八、应用场景
- 学术研究:用于对比新型网络结构与传统模型的性能差异。
- 教学演示:展示不同深度学习模型的工作原理与效果。
- 工程选型:在实际分类任务中快速评估哪种模型更适合当前数据。