GPU架构和PTX/SASS到warp-tiling和深度异步张量核心管线
在这篇文章中,我们将逐步介绍支撑最先进的 NVIDIA GPU 矩阵乘法 (matmul) 内核的所有核心硬件概念和编程技术。
为什么选择矩阵乘法? Transformer 模型在训练和推理过程中,大部分浮点运算都消耗在矩阵乘法运算中(例如 MLP 中的线性层、注意力 QKV 投影、输出投影等)。这些运算具有极高的并行性,因此非常适合 GPU 处理。此外,理解矩阵乘法内核的工作原理,就能为你设计几乎任何其他高性能 GPU 内核提供必要的工具。
本文分为四个部分:
- NVIDIA GPU 架构基础知识:全局内存、共享内存、L1/L2 缓存、电源限制对 SOL 的影响等。
- GPU汇编语言:SASS和PTX
- 设计接近最先进的同步矩阵乘法核:扭曲平铺法
- 在 Hopper 上设计 SOTA 异步矩阵乘法内核:利用张量核心、TMA、重叠计算与加载/存储、希尔伯特曲线等。
我们的目标是让这篇文章内容完整:既要足够详细,能够独立成篇,又要足够简洁,避免变成教科书式的文章。
这是系列文章的第一部分。在接下来的文章中,我们(计划)涵盖以下内容:
- 在 Blackwell GPU 上设计最先进的 matmul 内核
- 通过微基准测试实验探索GPU架构
- 设计最先进的多GPU内核
- 揭秘内存一致性模型(GPU 中的分词器:这个关键组件默默地维持着系统的运行,但仍然让大多数开发者感到困惑)
NVIDIA GPU架构基础知识
要编写高性能的GPU内核,你需要对硬件有一个清晰的理解模型。随着我们深入探讨硬件架构,这一点很快就会变得显而易见。
本文主要介绍 Hopper H100 GPU。如果您对 Hopper 架构有深入的了解,那么将这些知识应用到未来的架构(Blackwell、Rubin)或更早的架构(Ampere、Volta)上就变得轻而易举了。
Hopper1和Ampere2白皮书是很好的信息来源。
从最高层面来看,GPU 执行两项基本任务:
- 移动和存储数据(内存系统)
- 利用数据进行有用的工作(计算管道)
下图所示的 H100 框图反映了这种划分:蓝色组件代表内存或数据移动,而红色组件是计算(热)单元。
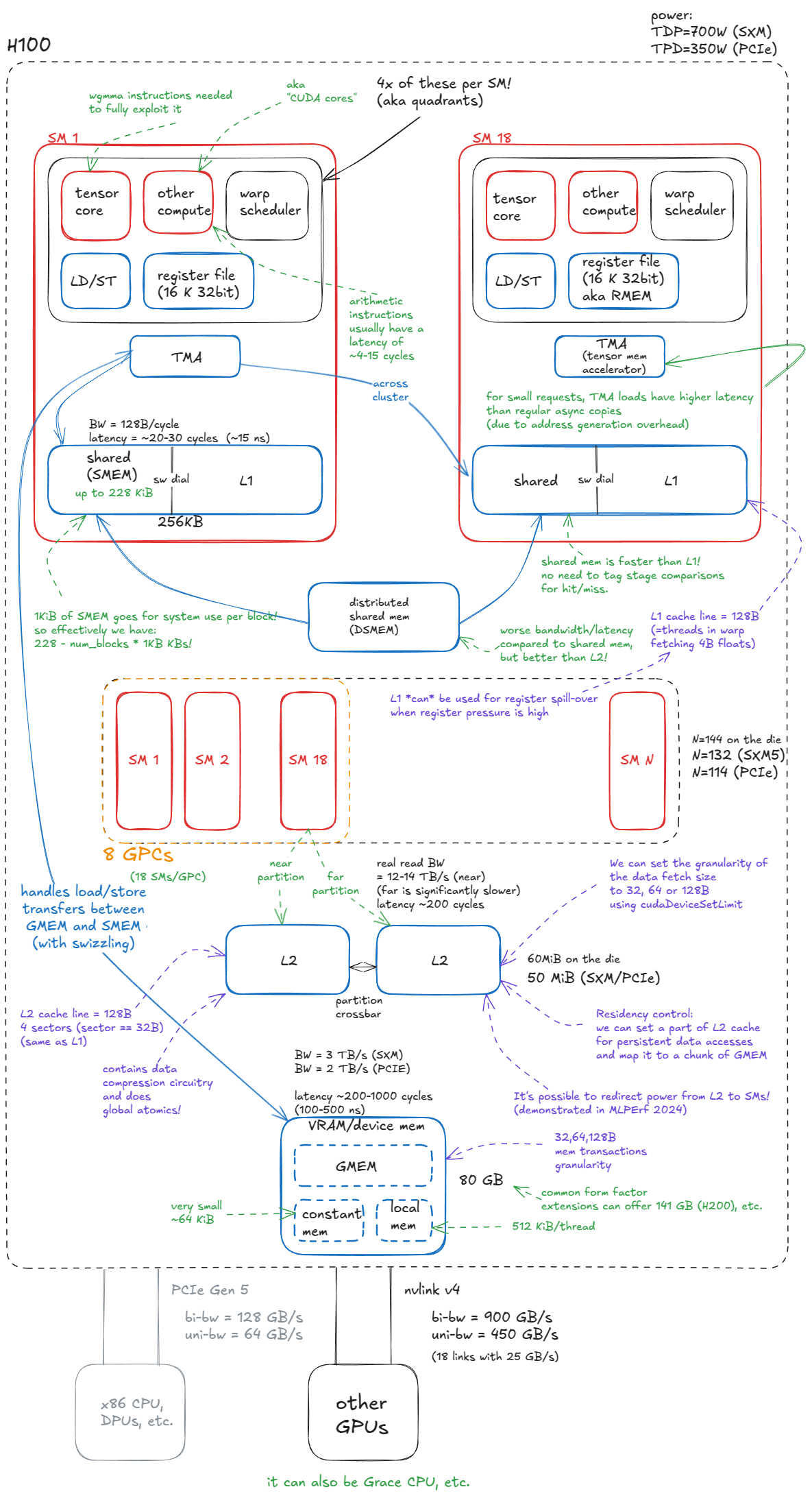
图 1:NVIDIA Hopper H100 GPU 模型
内存
GPU 中的内存系统是高度分层的,与 CPU 架构非常相似。
这种层级结构是由物理原理和电路设计决定的:SRAM 单元速度更快但体积更大(控制其速度的电路也会增加其面积),而 DRAM 单元体积更小、密度更高但速度更慢。因此,高速存储器的容量较小且价格昂贵,而低速存储器则可以提供更大的容量。我们将在后面更详细地介绍 DRAM 单元/存储器。
容量和延迟之间的这种权衡正是缓存层级结构存在的原因。理想情况下,每个计算单元都应该紧邻一个巨大的超高速内存池。但由于物理上不可能实现,GPU 设计者采取了折衷方案:在靠近计算单元的位置放置少量高速内存,并在更远的地方放置容量逐渐增大的低速内存池作为后盾。这种架构能够最大化系统的整体吞吐量。
GPU内存系统由以下部分组成:
- 设备内存(VRAM)。在 CUDA 术语中,"设备"内存指的是片外 DRAM------它与 GPU 芯片物理分离,但封装在同一块电路板上------采用堆叠式 HBM 实现。它包含全局内存 (GMEM)、每个线程的"局部"内存(寄存器溢出空间)等。
- 二级缓存。这是一个由 SRAM 构建的大型 k 路组相联缓存。它在物理上被划分为两个部分;每个 SM 直接连接到其中一个部分,并通过交叉开关间接连接到另一个部分。
- 分布式共享内存(DSMEM)。物理上紧密相邻的一组SM(GPC)的池化共享内存(SMEM)。
- L1缓存和共享内存
- L1 缓存。每个 SM 私有的较小的 k 路组相联 SRAM 缓存。
- 共享内存(SMEM)。由程序员管理的片上内存。SMEM 和 L1 共享同一物理存储空间,它们的相对分配可以通过软件进行配置。
- 寄存器文件(RMEM)。速度最快的存储介质,位于计算单元旁边。寄存器对各个线程是私有的。与 CPU 相比,GPU 包含的寄存器数量要多得多,RMEM 的总容量与 L1/SMEM 存储的总容量相同。

图 2:H100 (SXM5) GPU 的内存层次结构
📝notes:
还有一些较小的指令缓存,以及常量内存等等,但我们将忽略它们,因为这对我们的理解没有帮助。
从设备内存向下到寄存器(1-5 级),你会看到一个明显的趋势:带宽成倍增加,而延迟和容量则成倍下降。
以下会产生一些直接影响:
- 将访问频率最高的数据尽可能放在靠近计算单元的位置。
- 尽量减少对层次结构较低级别的访问,尤其是对设备内存(GMEM)的访问。
另一个值得一提的组件是Hopper 中引入的张量内存加速器 (TMA)。TMA 支持全局内存和共享内存之间,以及集群内共享内存之间的异步数据传输。它还支持内存交换 (swizzling) 以减少存储体冲突------我们稍后会详细介绍这些内容(此处双关)。
计算
从内存到计算,基本单元是流式多处理器(SM)。Hopper H100(SXM5)总共集成了132个SM。
SM(小型存储器)被分组到图形处理集群(GPC)中:每个GPC包含18个SM,GPU上有8个GPC。其中4个GPC直接连接到一个L2分区,另外4个GPC连接到第二个L2分区。
📝笔记:
GPC 也是 CUDA 中线程块集群抽象的基础硬件单元------我们稍后会回到编程模型。
关于集群,有一点需要说明:如之前说过每个 GPC 有 18 个 SM,所以 8 个 GPC 应该有 144 个 SM。但是 SXM/PCIe 封装只暴露了 132 或 114 个 SM。这是为什么呢?这是因为 18 × 8 的布局仅适用于完整的 GH100 芯片------在实际产品中,部分 SM 会被熔断。这会直接影响我们在编写内核时如何选择集群配置。例如,如果集群跨越超过 2 个 SM,就无法使用所有 SM。
最后需要注意的是,图形处理集群 (GPC) 中的"图形"一词是沿用至今的。在现代服务器级 GPU 中,这些集群纯粹用作计算/AI 加速单元,而非图形引擎。GPU 本身也是如此,去掉"G",它们就是 AI 加速器。
除了前面提到的 L1/SMEM/TMA/RMEM 组件(所有这些组件都物理位于 SM 内部)之外,每个 SM 还包含:
- 张量核心。 这些专用单元能够以高吞吐量在小块数据块(例如,1×2×3
64x16 @ 16x256)上执行矩阵乘法。大型矩阵乘法会被分解成许多这样的小块操作,因此有效利用张量核心对于达到最佳性能至关重要。 - CUDA 核心和特殊功能单元 (SFU)。 所谓的"CUDA 核心"(营销术语)执行标准浮点运算,例如 FMA(融合乘加运算
c = a * b + c)。特殊功能单元 (SFU) 处理超越函数,例如sinfcos( x)exp、 f(y)、f(z)、f(z)log,以及代数函数,例如sqrtf (x)rsqrt、f(y)、f(z) 等。 - **加载/存储 (LD/ST) 单元。**用于执行加载和存储指令的电路,与 TMA 引擎互补。
- **线程束调度器。**每个SM包含调度器,用于向32个线程组(在CUDA中称为线程束)发出指令。一个线程束调度器每个周期可以发出一条线程束指令。
每个 SM 在物理上分为四个象限,每个象限容纳上述计算单元的子集。
由此可得出以下结论:
📝并行与并发
SM 最多可以同时从四个线程束发出指令(即,在一个给定周期内,128 个线程可以真正并行执行)。
然而,一个SM最多可以支持2048个并发线程(64个线程束)。这些线程束是常驻的,并会随着时间的推移被调度进入和退出,从而使硬件能够隐藏内存/流水线延迟。
换句话说,指令并行性(在给定周期内开始执行指令的线程数)限制为每个 SM 一次最多 128 个线程(4 个 32 宽的 warp 指令),而并发性(调度器中跟踪并有资格运行的线程数)扩展到 2048 个线程。
光速与功率限制
既然我们购买NVIDIA GPU是为了进行计算,那么很自然地会问:GPU的上限------最大计算吞吐量是多少?这通常被称为"光速"(SoL)性能:由芯片的物理特性决定的上限。
根据数据类型的不同,存在多种上限。在 LLM 训练工作负载中,bf16近年来 bfloat16 ( ) 一直是主流格式,fp8而 4 位格式也变得越来越重要(对于推理而言,fp8 是相当标准的格式)。
峰值吞吐量计算如下:perf = freq_clk_max * num_tc * flop_per_tc_per_clk
或者用文字表述:最大时钟频率 × 张量核心数 × 每个张量核心每个周期的 FLOPs 数。
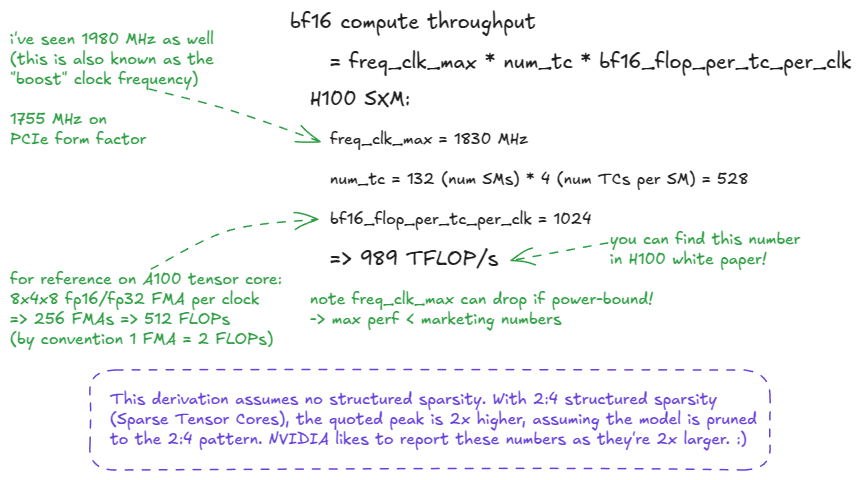
图 3:H100 SXM5 BF16 光速推导
📝FLOP vs FLOPs vs FLOPS vs FLOP/s
- FLOP = 单次浮点运算。
- FLOP/s = 吞吐量单位:每秒浮点运算次数。
- FLOPs(小写 s)= FLOP(操作)的复数形式。
- FLOPS(全部大写)经常被误用为吞吐量,但严格来说应该只读作"FLOPs"(FLOP 的复数形式)。FLOPS 用作 FLOP/s 是 SLOP!:)
我在上图中留下了一个提示:"光速"实际上并不是恒定的(我想这就是类比失效的地方)。
实际上,峰值吞吐量取决于实际时钟频率,而时钟频率会因功耗或过热而变化。如果GPU时钟频率下降,有效光速也会下降:
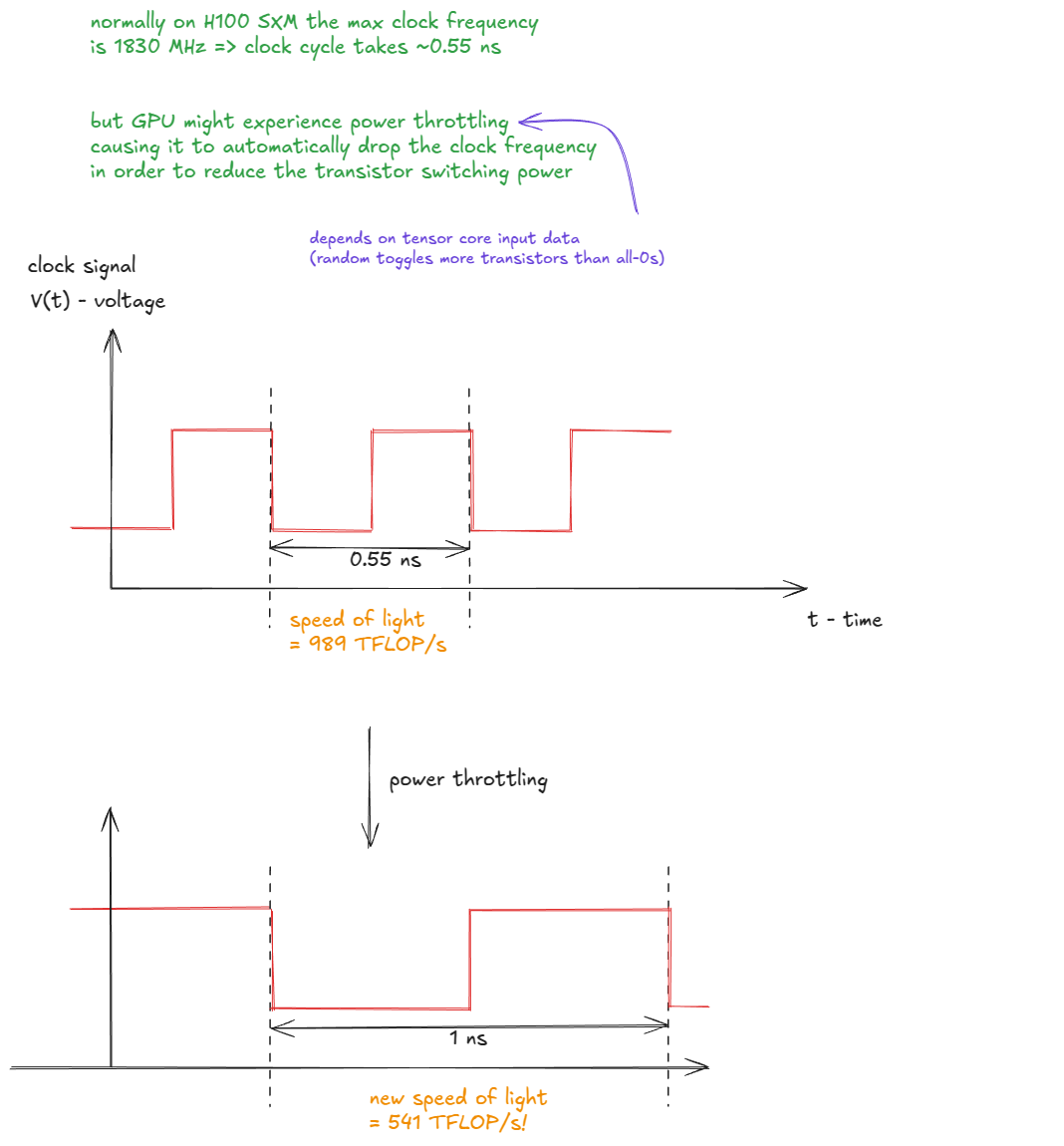
图 4:功率限制会降低时钟频率,从而降低有效"光速"。
📝延伸阅读:
Horace 在他的博客文章 3中更深入地探讨了这一现象。
目前我们只需要这些硬件细节信息。
接下来,我们将把重点转移到 CUDA 编程模型上,然后再深入硬件层面,最终达到 CUDA C++ 的境界。
CUDA编程模型
CUDA 编程模型自然而然地映射到 GPU 硬件和内存层次结构上。
关键抽象概念如下:
- 线
- 经线(32根线)
- 线程块
- 线程块集群
- 网格(线程块或线程簇)
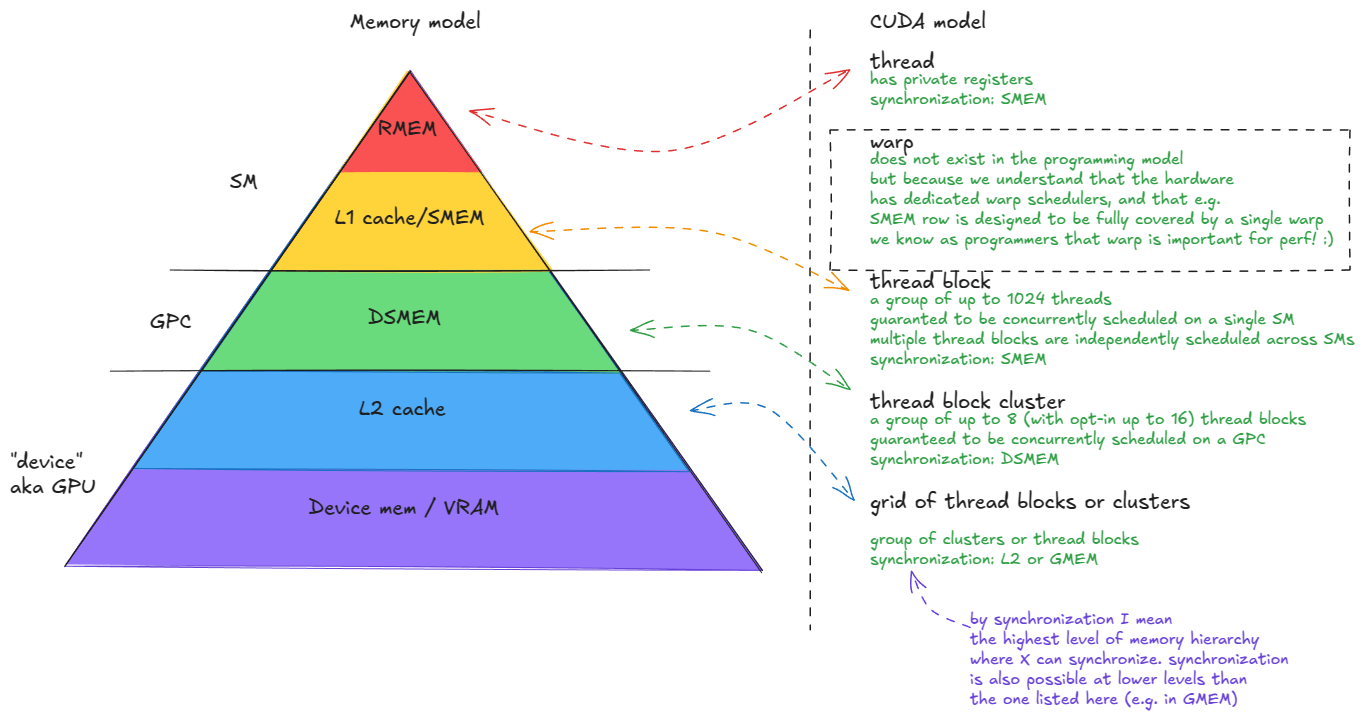
图 5:CUDA 编程模型:线程、线程束、块、集群、网格
每个线程都通过诸如 `<thread>` gridDim、blockIdx` blockDim<thread>`、`<thread>` 和threadIdx`<thread>` 之类的变量"感知"自己在 CUDA 层次结构中的位置。在内部,这些变量存储在特殊寄存器中,并在内核启动时由 CUDA 运行时初始化。
这种位置信息使得在GPU上分配任务变得容易。例如,假设我们要处理一张1024×1024的图像。我们可以将其分割成32×32个线程块,每个线程块包含32×32个线程。
每个线程随后都可以计算其全局坐标,例如
const` `int` x `=` blockIdx`.`x `*` blockDim`.`x `+` threadIdx`.`x `const` `int` y `=` blockIdx`.`y `*` blockDim`.`y `+` threadIdx`.`y `并使用这些像素从全局内存中获取其分配的像素(image[x][y]),执行一些逐点操作,并将结果存储回去。
以下是这些变量之间的关系:
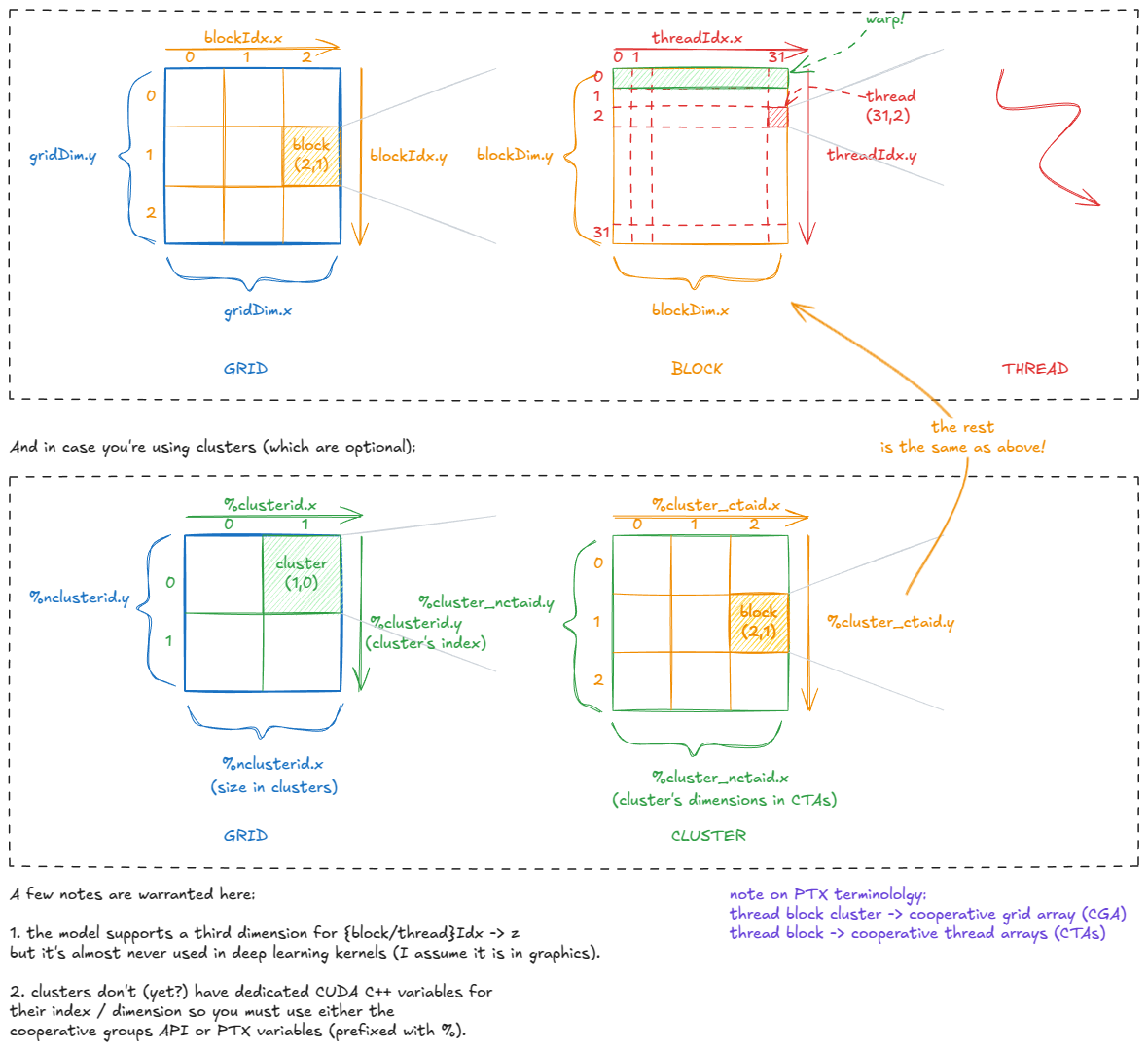
图 6:CUDA 的内置变量:线程如何知道它们的位置
如图所示,实际应用中我们主要使用一维或二维的网格/簇/块状结构。不过,在内部,它们可以根据需要进行逻辑上的重新组织。
例如,如果threadIdx.x运行范围从 0 到 1023(一个 1D 块,包含 1024 个线程),我们可以将其拆分为 0 到 1023 x = threadIdx.x % 32,从而y = threadIdx.x / 32有效地将该块重塑为 32×32 的逻辑 2D 布局。
将 CUDA 模型与硬件连接起来,现在应该很清楚一个事实:一个线程块应该至少包含 4 个线程束(即 128 个线程)。
为什么?
- 线程块驻留在单个SM上。
- 每个 SM 有 4 个 warp 调度器------因此,为了充分利用硬件,你不希望它们闲置。
📝4次传送的更多理由:
我们稍后会深入探讨这一点,但请注意,在 Hopper 上,warp 组(4 个 warp)是 WGMMA(矩阵乘法)张量核心指令的执行单元。
此外,对于持久内核,我们通常每个 SM 只启动一个线程块,因此组织工作以使所有 warp 调度器保持忙碌非常重要。
掌握了 CUDA 编程模型术语后,我们现在可以继续深入了解 GPU 的架构。
GMEM模型
让我们深入了解一下GMEM。如前所述,它由多层DRAM堆叠而成,最底层是逻辑层(HBM)。但DRAM究竟是什么呢?

图 7:DRAM 单元内部结构:晶体管 + 电容器,字线 + 位线
现在我们了解了单个比特的存储方式,接下来让我们放大到整个内存矩阵。从宏观上看,它看起来像这样:
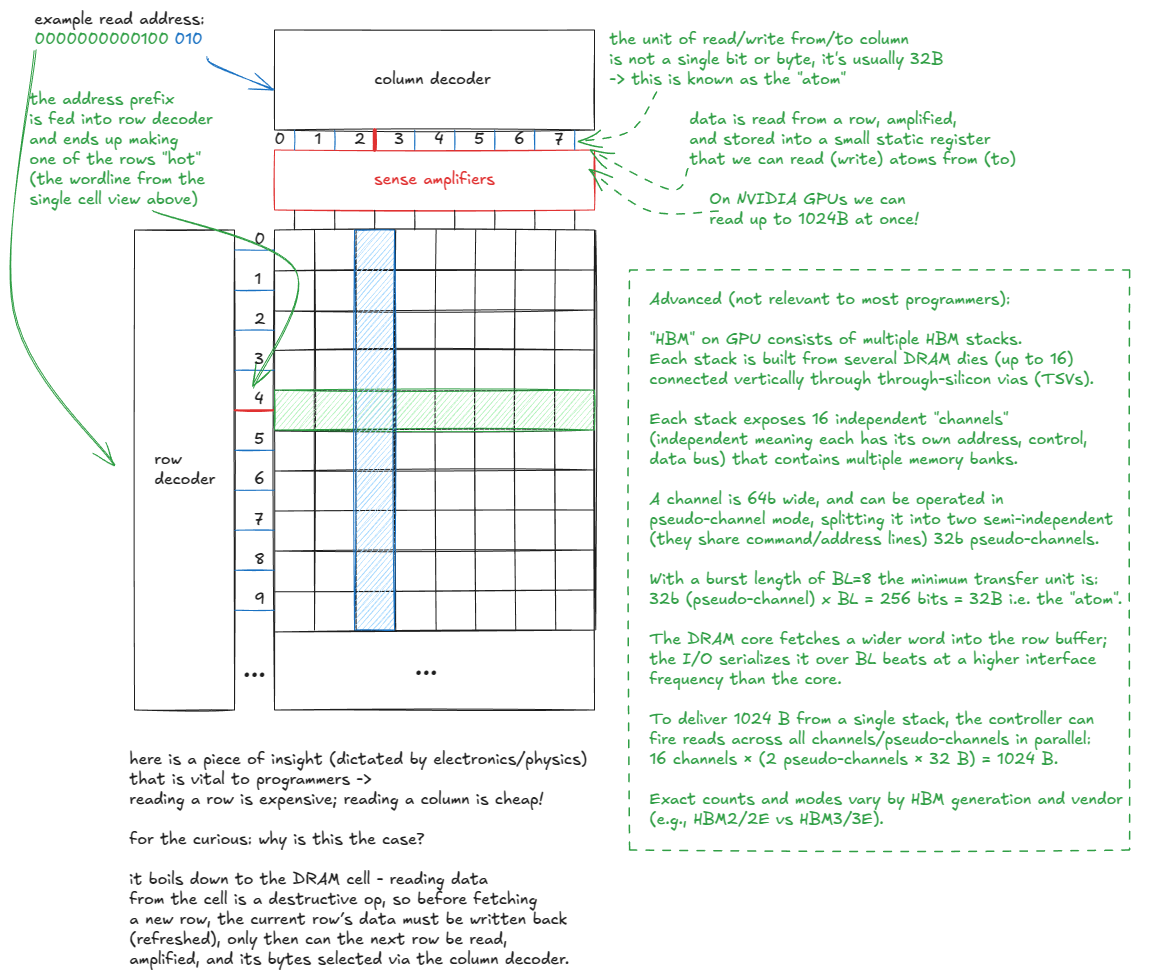
图 8:GMEM 模型
📝关于 HBM 的更多阅读材料:
如果你想深入了解 HBM,我发现论文"揭秘实时系统高带宽内存的特性"21相当有启发性。
因此,我们可以得出结论:访问模式之所以重要,是因为DRAM单元的物理特性。以下是一个示例:
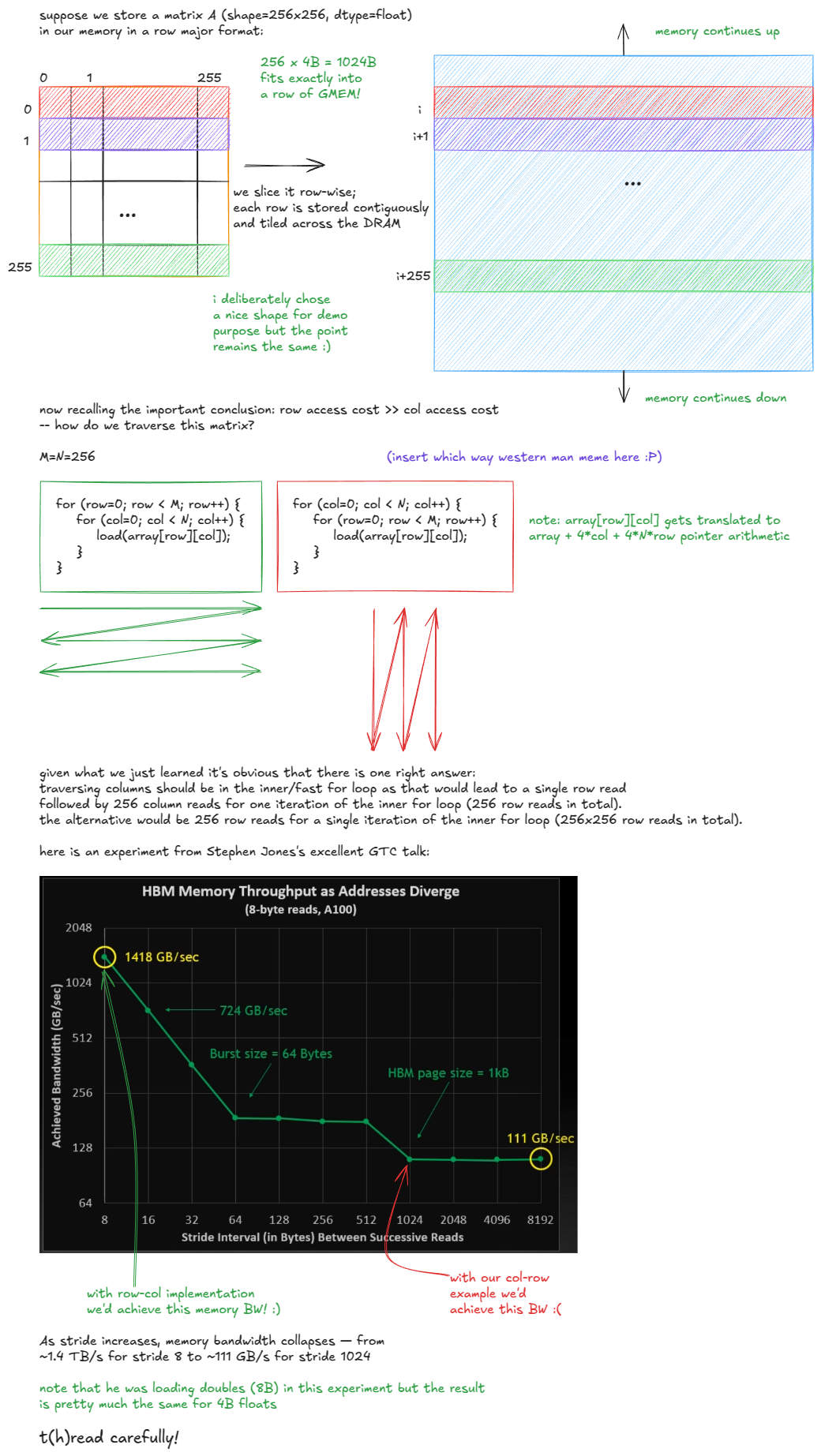
图 9:GMEM 中访问模式的影响
Stephen Jones 的演讲"CUDA 编程的工作原理"4值得一看。
如果示例中的矩阵是列优先的,情况就会颠倒过来:一列中的元素将连续存储,因此有效的选择是在内循环中遍历行,以避免 DRAM 开销。
所以当人们说"GMEM 合并非常重要"时,他们的意思是:线程应该访问连续的内存位置,以最大限度地减少访问的 DRAM 行数。
接下来,让我们把注意力转向SMEM的工作原理。
SMEM模型
共享内存(SMEM)与全局内存(GMEM)的特性截然不同。它由SRAM单元而非DRAM构成,这使其在速度和容量方面存在根本性的权衡。
SRAM单元的具体设计并不重要------只需说明存储一位信息需要更多的晶体管即可。您可以自行搜索"SRAM单元"。
SMEM 由 32 个存储体组成,每个存储体宽 32 位(4 字节):
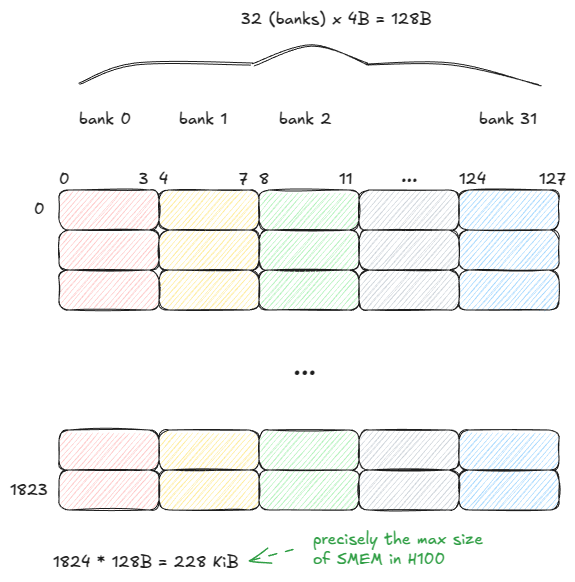
图 10:SMEM 模型
SMEM可以在一个周期内提供来自所有32家银行(1280亿)的数据------但前提是必须遵守一条规则:
同一线程束中的线程不能访问同一内存库中的不同地址。否则,这些请求将被串行化,跨越多个时钟周期执行。
这种情况被称为内存冲突。如果 N 个线程访问同一个内存库的不同地址,就会发生 N 路内存冲突,线程束的内存请求需要 N 个周期才能完成。
最坏的情况下,所有 32 个线程都针对同一银行中的不同地址,吞吐量下降 32 倍。
例如,假设线程束大小为 5。以下两种访问模式分别需要 3 个时钟周期和 1 个时钟周期才能完成服务:
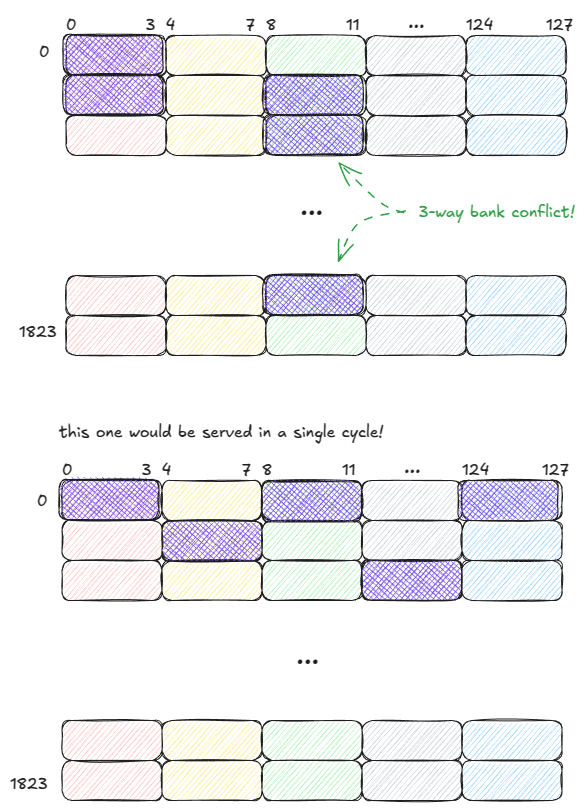
图 11:SMEM:良好与不良的访问模式
重要的是:如果一个 warp 中的多个线程访问 bank 中的同一地址,SMEM 可以将该值广播(或多播)给所有这些线程。
在以下示例中,请求在一个周期内即可完成处理:
- Bank 1 可以将一个值多播给 2 个线程。
- Bank 2 可以将一个值多播给 3 个线程。
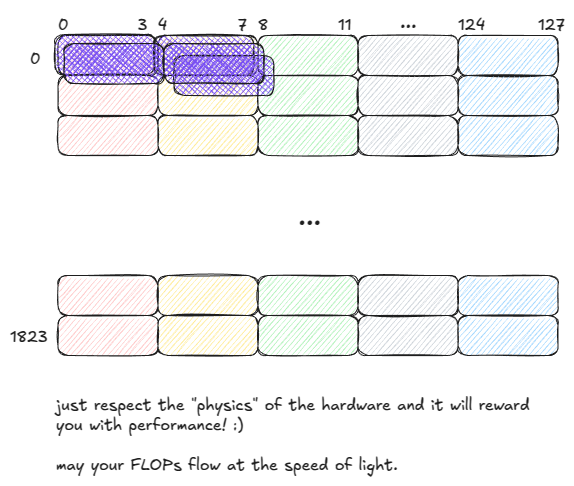
图 12:SMEM:多播(在单个周期内提供服务)
现在,我们来看看硬件拼图的最后一块:L1 缓存。
这是Axel 撰写的关于 SMEM 微基准测试的一篇优秀的博客文章 5 。
L1 型号
我们已经看到 L1 和 SMEM 共享相同的物理存储,但 L1 在此存储周围添加了一个硬件管理的脚手架层。
从宏观层面来看,L1缓存的逻辑流程如下:
- warp 发出内存请求(向 SMEM 或 GMEM)。
- 请求进入 MIO 管道并被分派到 LSUIN 路由器。
- 路由器指示请求:SMEM 访问立即从数据阵列提供服务,而 GMEM 访问则进入标签比较阶段。
- 在标记阶段,将 GMEM 地址标记与目标集中存储的标记进行比较,以确定数据是否驻留在 L1 中。
- 命中后**,**请求直接从数据数组中提供(就像 SMEM 一样)。
- 如果缓存未命中**,**请求会传播到 L2 缓存(如有必要,甚至会传播到更高层级的 GMEM 或对等 GPU 内存)。当数据返回时,它会被缓存到 L1 缓存中,并清空现有缓存行,然后并行地将其发送回请求的 warp。
这就是我刚才描述的系统:
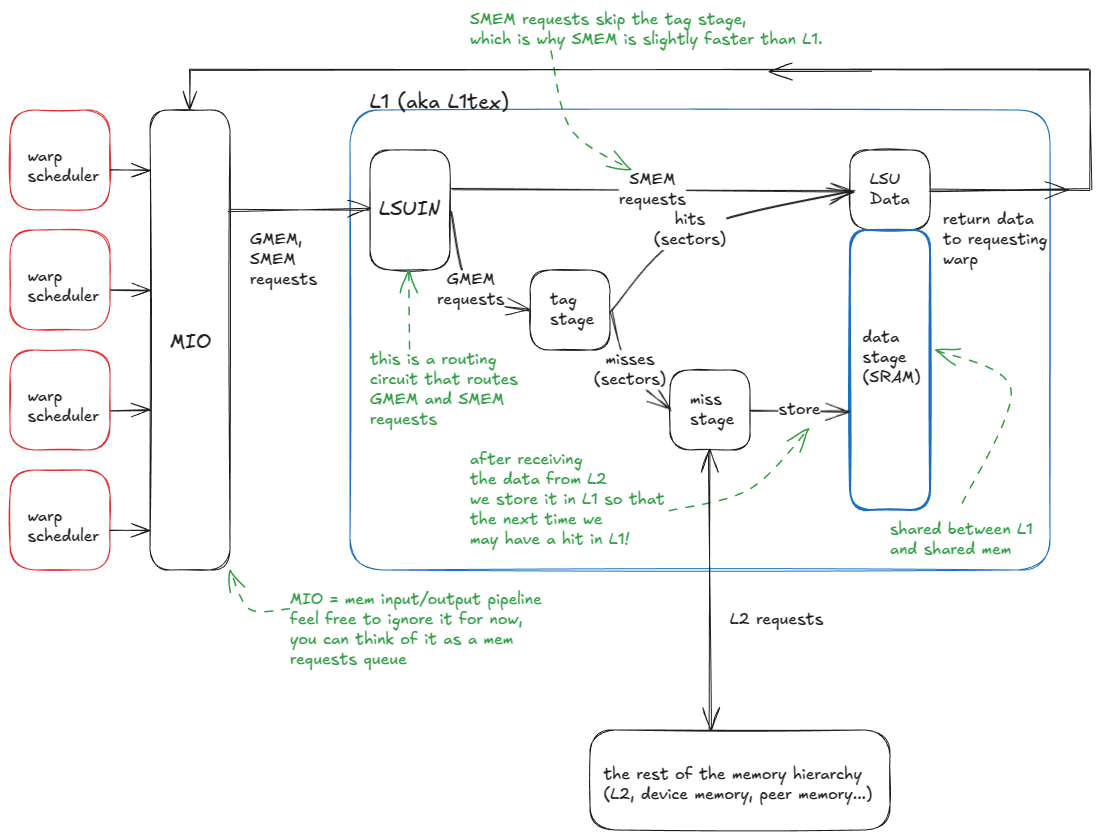
图 13:L1 缓存模型
让我们更深入地了解一下标签阶段和数据阶段:
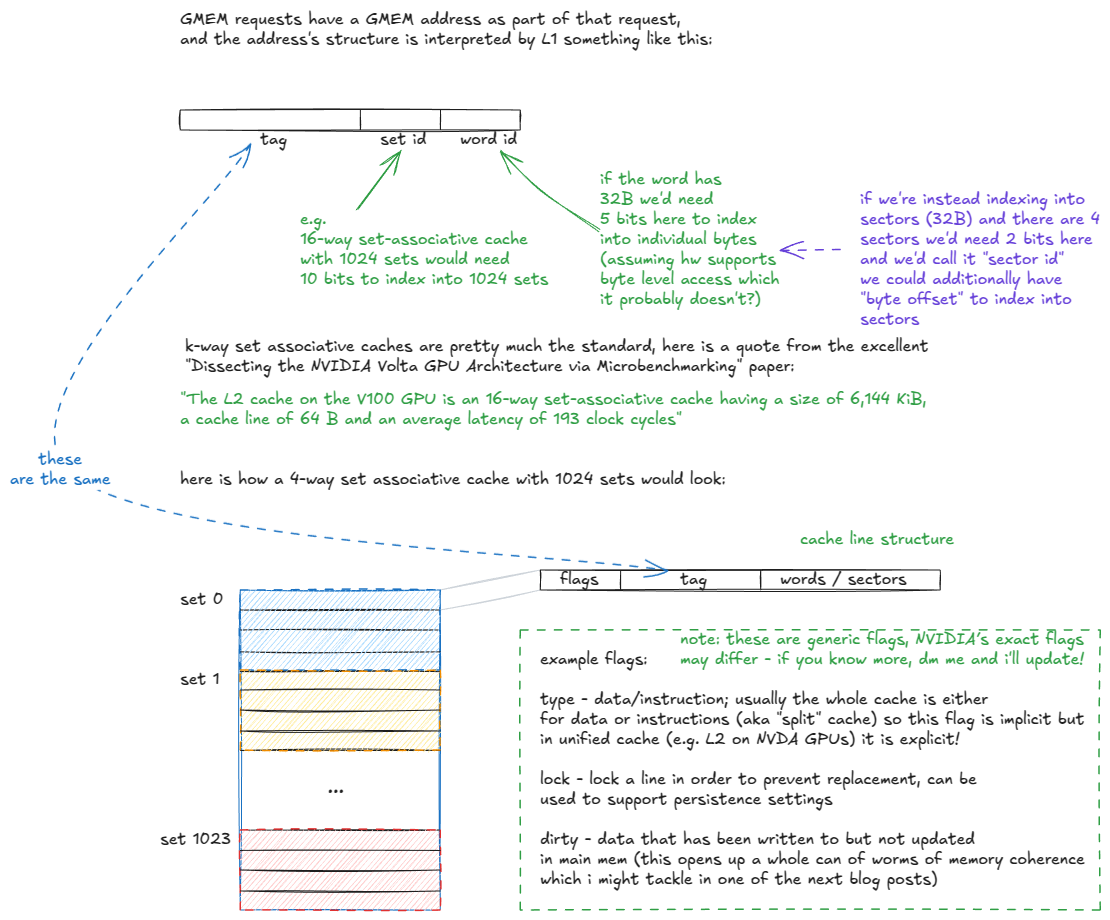
图 14:k路组相联缓存组织结构分解
当 GMEM 地址进入标记阶段时,命中/未命中逻辑按如下方式展开:
- 标签阶段接收 GMEM 地址。
- 提取集合 ID 位,并检查该集合中的所有缓存行(标签)。
- 如果找到匹配的标签(可能命中缓存):
- 检查该行的有效性标志。
- 如果无效 → 则视为缓存未命中(继续执行步骤 4)。
- 如果有效 → 从数据数组中获取请求的扇区并将其传递给跃迁寄存器。
- 检查该行的有效性标志。
- 如果找不到匹配项(缓存未命中),则请求将路由到内存层次结构的其余部分(L2 及更高层)。
- 当数据从 L2 返回时,它会被存储在集合中,根据替换策略(例如,伪 LRU)驱逐现有行,并并行地交付给请求的 warp。
请注意,L2 与 L1 并没有太大的区别,只是它是全局的(而不是每个 SM 的),更大(关联性更高),被划分为两个通过交叉开关连接的切片,并且支持更细致的持久性和缓存策略。
至此,我们已经介绍了理解接下来章节所需的关键 GPU 硬件组件。
📝不同GPU世代间的梯度:
我之前提到过,了解 Hopper 是理解未来和过去几代 NVIDIA GPU 的绝佳基础。
迄今为止最大的代际飞跃是从安培架构到霍珀架构,引入了以下技术:
- 分布式共享内存 (DSMEM):在整个 GPC 的 SMEM 之间进行直接的 SM 到 SM 通信,以执行加载、存储和原子操作。
- TMA:用于异步张量数据移动的硬件单元(GMEM ↔ SMEM、SMEM ↔ SMEM)。
- 线程块集群:一种新的 CUDA 编程模型抽象,用于对跨 SM 的块进行分组。
- 异步事务屏障:将屏障拆分,以事务(字节)而非线程为单位进行计数。
安培架构(例如 A100)本身引入了几个关键特性:
- Tensor Core 支持 tf32 和 bf16。
- 异步复制(GMEM → SMEM)有两种模式:绕过 L1 和访问 L1。
- 异步屏障(在共享内存中进行硬件加速)。
- CUDA 任务图是 PyTorch 中 CUDA 图的基础,它减少了 CPU 启动和网格初始化开销。
- 通过 CUDA 协作组公开 Warp 级归约指令(支持在单个步骤中对 Warp 范围内的整数 dtype 进行归约,而无需 shuffle 模式)。
GPU汇编语言:PTX和SASS
让我们从硬件层面向上看,深入到它的指令集架构(ISA)。简单来说,ISA 就是处理器(例如 NVIDIA GPU)可以执行的指令集,以及它们的二进制编码(操作码、操作数等)和行为语义。这些共同定义了程序员如何指导硬件完成有用的工作。
ISA 的人类可读形式称为汇编**:** 0x1fff...3B程序员不用像写原始二进制代码那样编写指令,而是使用助记符FMA R12, R13, R14, R15来表达相同的指令。
在 NVIDIA GPU 上,原生指令集架构 (ISA) 被称为 SASS。遗憾的是,它的文档非常匮乏,尤其是对于最新一代的 GPU 而言。虽然一些老一代的 GPU 已经被部分或全部逆向工程,但官方文档仍然有限。您可以在这里找到相关文档 6。
PTX 是 NVIDIA 的虚拟 ISA: 一个用于抽象 GPU 的指令集。PTX 代码不会直接执行;而是会被编译ptxas成原生 ISA(SASS)。
PTX 的主要优势在于向前兼容性。十年前用 PTX 编译的 CUDA 程序仍然可以在像 Blackwell 这样的现代 GPU 上运行。虽然它可能无法高效利用最新的硬件特性,但仍然可以正确执行。
之所以能实现这一点,是因为 PTX 与原生 SASS 一起嵌入到 CUDA 二进制文件中。当该二进制文件在未来的 GPU 上运行时,如果匹配的 SASS 代码尚未存在,则 PTX 会被即时编译成适用于目标架构的 SASS:
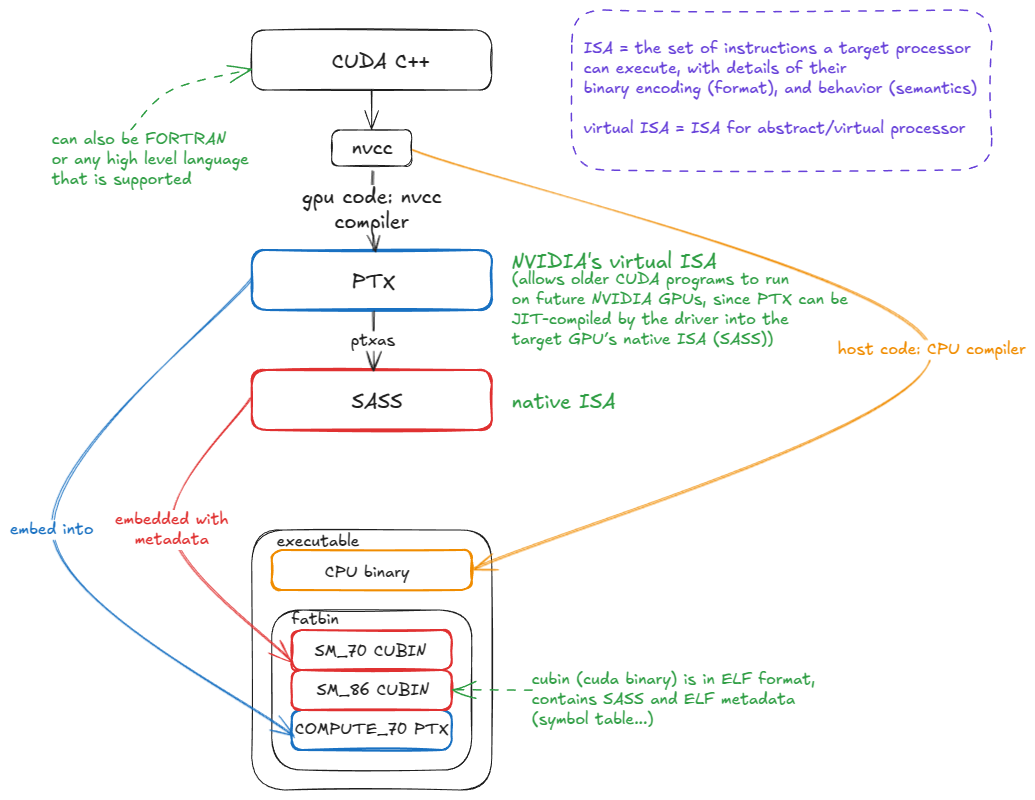
图 15:CUDA 编译流程:从 CUDA C++ → PTX → SASS
为什么要关注 PTX/SASS?
因为性能提升的最后几个百分点就在这里。在如今的规模下,这"几个百分点"意义重大:如果你要训练一个跨越 3 万个 H100 实例的 LLM 模型,即使核心内核的性能只提升 1%,也能节省数百万美元。
正如我的朋友Aroun喜欢说的那样:在编写大规模训练/推理内核时,我们关注的是性能O(NR),而不是复杂度O(N)。(这里,NR 指的是核反应堆。)换句话说,可能已经没有新的渐近复杂度类别等待我们去发现------大幅提升的性能提升(基本)已经过去了。但是,在数百万个 GPU 上挤出约 1% 的效率,就相当于节省了几个小型模块化反应堆(SMR)的能源。
要深入了解 SASS,我推荐 Aroun 的"SASS 和 GPU 微架构简介"7视频。
理解 SASS 并不意味着你就可以直接用 SASS 编写 CUDA 内核。相反,在编写 CUDA C++ 时,你需要与编译器的输出(PTX/SASS)保持紧密联系。这样可以让你仔细检查你的提示(例如,#pragma unroll展开循环或向量化加载)是否真的被转换成了预期的指令(例如,LDG.128)。
一个很好的例子可以说明这些底层细节中隐藏的性能,那就是现在著名的 Citadel 论文"通过微基准测试剖析 NVIDIA Volta GPU 架构"8。作者调整了 SASS 以避免内存库冲突,并将性能从 132 GFLOP/s 提升到 152 GFLOP/s,提高了 15.4%。
另请注意,某些指令在 CUDA C++ 中没有等效项;您只能直接编写内联 PTX!我们将在第 4 章中看到相关示例。
既然我已经(希望如此)说服了您 PTX/SASS 的重要性,那么让我们来介绍一个最简单的矩阵乘法内核,它将作为本章剩余部分的运行示例。之后,我们将深入分析它的汇编代码。
让我们从最简单的情况开始:一个用于像 CPU 这样的"串行处理器"的简单矩阵乘法内核:
for` `(int` m `=` `0;` m `<` M`;` m`++)` `{` `for` `(int` n `=` `0;` n `<` N`;` n`++)` `{` `float` tmp `=` `0.0f;` `// accumulator for dot product` `for` `(int` k `=` `0;` k `<` K`;` k`++)` `{` tmp `+=` A`[`m`][`k`]` `*` B`[`k`][`n`];` `// A and B are input matrices` `}` C`[`m`][`n`]` `=` tmp`;` `// C is the output matrix` `}` `}` `我们遍历输出矩阵的每一行( m)和每一列( ) ,并在每个位置计算点积()。这就是矩阵乘法的教科书定义:n``C``C[m,n] = dot(a[m,k],b[k,n])
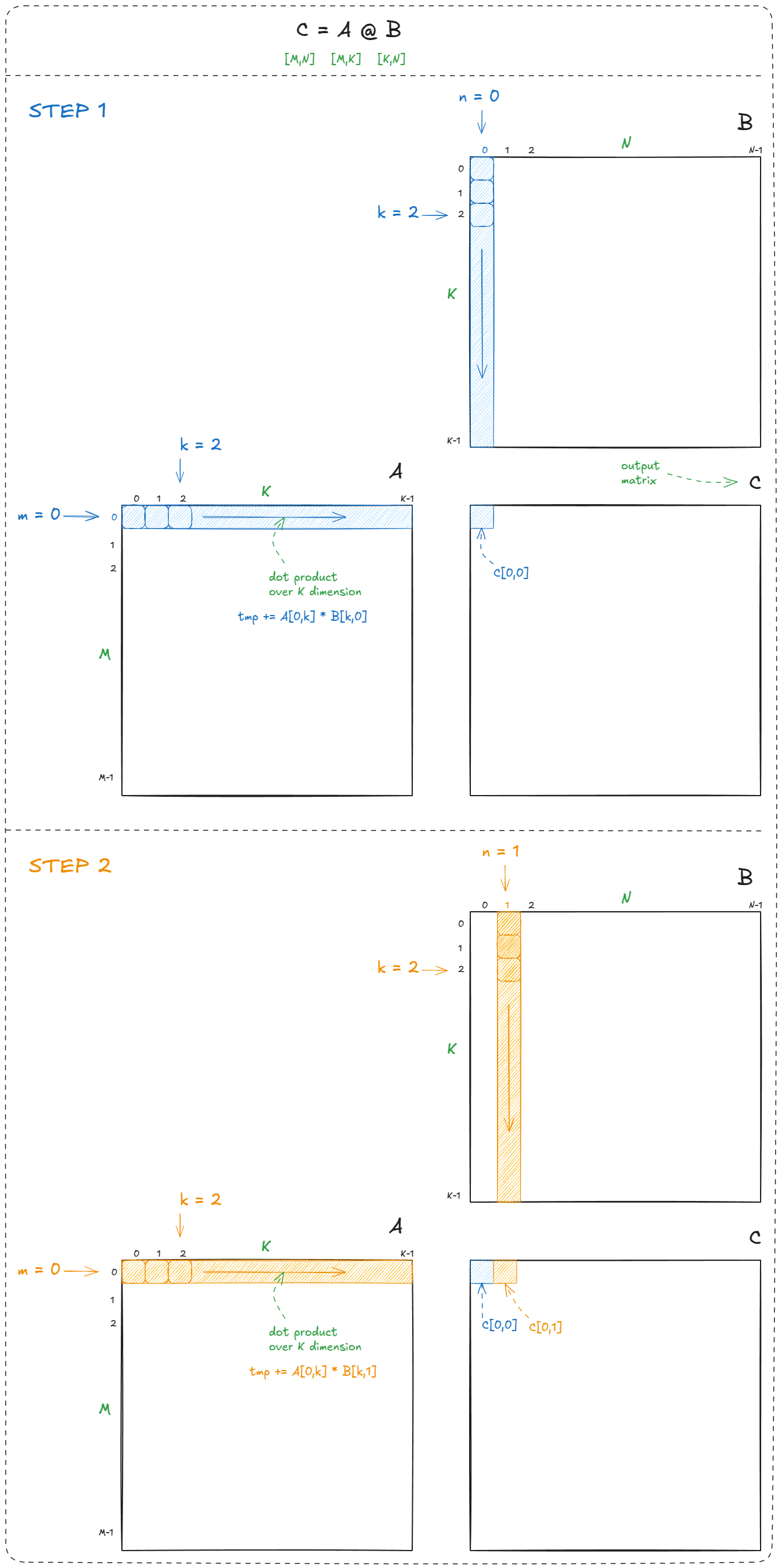
图 16:简单的 CPU 矩阵乘法示例
矩阵乘法总共需要进行M × N点积运算。每次点积运算都执行K乘加运算,因此总运算量为2 × M × N × KFLOPs(因子为 2,因为按照惯例,我们计算 FMA = 乘法 + 加法)。
平行结构在哪里?
所有这些点积都是独立的。计算无需C[0,1]等待C[0,0]。这种独立性意味着我们可以并行化两个外层循环(遍历m和n)。
有了这样的认识,我们来看看最简单的 GPU 内核。我们将使用一个稍微通用一些的形式:C = alpha * A @ B + beta * C。这是经典的 GEMM(通用矩阵乘法)。设置alpha = 1.0并beta = 0.0恢复更简单的形式C = A @ B。
内核代码:
// __global__ keyword declares a GPU kernel` __global__ `void` `naive_kernel(int` M`,` `int` N`,` `int` K`,` `float` alpha`,` `const` `float` `*`A`,` `const` `float` `*`B`,` `float` beta`,` `float` `*`C`)` `{` `int` BLOCKSIZE`=32;` `const` `int` row `=` blockIdx`.`x `*` BLOCKSIZE `+` `(`threadIdx`.`x `/` BLOCKSIZE`);` `const` `int` col `=` blockIdx`.`y `*` BLOCKSIZE `+` `(`threadIdx`.`x `%` BLOCKSIZE`);` `if` `(`row `<` M `&&` col `<` N`)` `{` `// guard in case some threads are outside the range` `float` tmp `=` `0.0;` `// compute dot product` `for` `(int` i `=` `0;` i `<` K`;` `++`i`)` `{` tmp `+=` A`[`row `*` K `+` i`]` `*` B`[`i `*` N `+` col`];` `}` `// GEMM: C = alpha * A @ B + beta * C` C`[`row `*` N `+` col`]` `=` alpha `*` tmp `+` beta `*` C`[`row `*` N `+` col`];` `}` `}` `我们是这样推出的:
// create as many blocks as necessary to map all of C` dim3 `gridDim(CEIL_DIV(`M`,` `32),` `CEIL_DIV(`N`,` `32),` `1);` `// 32 * 32 = 1024 thread per block` dim3 `blockDim(32` `*` `32);` `// launch the asynchronous execution of the kernel on the device` `// the function call returns immediately on the host` naive_kernel`<<<`gridDim`,` blockDim`>>>(`M`,` N`,` K`,` alpha`,` A`,` B`,` beta`,` C`);` `您可以在这里观察到以下几点:
- 内核是从单个线程的角度编写的。这遵循 SIMT(单指令多线程)模型:程序员编写一个线程的工作,而 CUDA 则负责网格、集群和块的启动和初始化。(其他编程模型,例如 OpenAI 的Triton22 ,则允许你从图块的角度进行编写。)
- 每个线程使用其块索引和线程索引(我们之前讨论过的变量)来计算其在中的(
row,col)坐标C,并写出相应的点积。 - 我们使用尽可能多的 32×32 线程块(1024 个线程)来平铺输出矩阵。
- 如果线程
M数或N线程数不能被 32 整除,则某些线程会超出函数的有效输出区域C。这就是为什么我们在代码中添加了一个保护机制。
最后两点结合起来,就产生了一种通常被称为瓦片量化的现象:
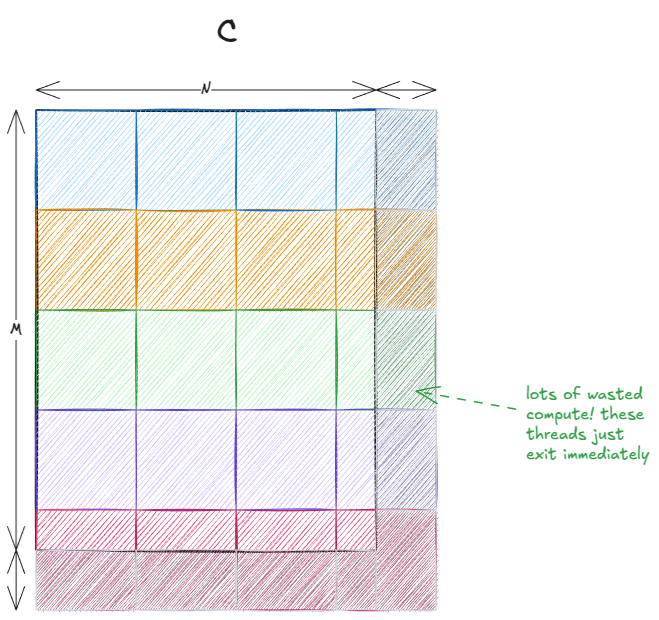
图 17:瓦片量化
当图块相对于输出矩阵较大时,这种效应尤为明显。在我们的例子中,由于 32 正好能整除 4096,所以不存在问题。但如果矩阵大小为 33×33,那么大约 75% 的线程最终将无法执行任何有效工作。
如果传递的是二维数据块而不是一维数据块,代码就可以写得更简洁。这样一来,我们就无需硬编码数据块大小 32,并且可以使用 ` threadIdx.xand` 和 ` threadIdx.y。在内部,一维结构实际上是通过索引运算转换为二维结构的:`and`threadIdx.x / BLOCKSIZE和 `,threadIdx.x % BLOCKSIZE因此在实际应用中差别不大。
我最初是从Simon 的博客 9中改编了这段代码,并专注于对其进行深入的 PTX/SASS 分析(即将推出),所以我不想重复这项艰苦的工作,因为代码的细微变化都会导致不同的 PTX/SASS。
让我们仔细看看这个内核实际做了什么。在本文的其余部分,我们将假设M = N = 4096所有矩阵都是行优先格式(在后面的某些示例B中将采用列优先格式------这是标准惯例)。
线程的逻辑组织结构如下:
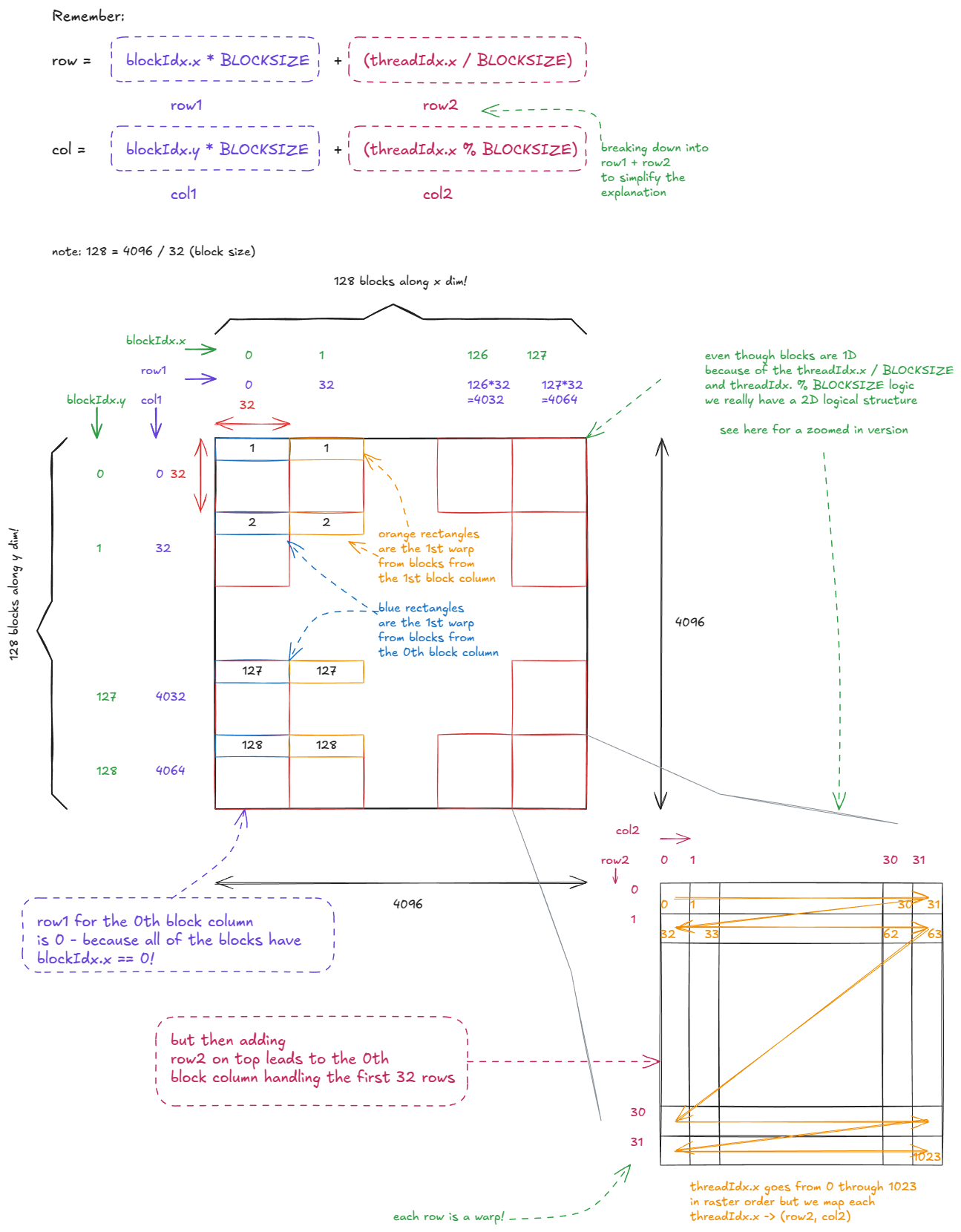
图 18:朴素矩阵乘法内核中的线程组织
矩阵乘法逻辑本身如下所示:

图 19:朴素矩阵乘法核
当我们的 GMEM 访问被合并时,硬件会自动进行一些有趣的优化:
- (矩阵 A)对于从 读取的 warp
A,32 条线程LDG.32指令(全部来自同一地址)合并为一个 warp 级别的指令LDG.32,其结果广播到 warp 中的所有线程。 - (矩阵 B)对于从 读取数据束
B,32 条连续的线程LDG.32指令被合并成一条 128 字节的束级加载指令。这依赖于线程沿连续维度读取数据。如果线程沿列向下读取(非连续),硬件则需要发出多条束级指令。
请注意,我们总共启动了 (4096/32) * (4096/32) = 16,384 个线程块。然而,我使用的 H100 PCIe 卡只有 114 个 SM(流处理器)。
这就引出了一个问题:每个SM上可以同时运行多少个区块?
一般来说,有三种资源限制并发性:
- 登记册
- 共享内存(SMEM)
- 线/经线
从 Nsight 计算分析器(ncu --set full -o out.ncu-rep naive_kernel参见下图)可以看出,内核每个线程使用 32 个寄存器。每个块有 1024 个线程,因此每个块需要 1024 × 32 = 32,768 个寄存器。由于每个 SM 有 65,536 个寄存器(这些常量可以在CUDA C 编程指南 10中找到),因此每个 SM 最多只能处理 2 个块。
📝笔记:
提示:编译时还可以传递参数--ptxas-options=-v,让编译器报告寄存器使用情况和其他资源计数。nvdisasm这也是一个很有用的小工具。
在 Hopper(计算能力 9.0)上,每个 SM 的最大线程数为 2048。每个块有 1024 个线程,这再次限制了每个 SM 最多只能处理 2 个块。
回顾硬件章节,即使内核没有显式使用SMEM,每个块也始终存在1024B的系统级开销。默认的SMEM分配为每个SM 8192B(未调至228 KiB),这最多允许8个块。
综合起来max blocks/SM = min(2,2,8) = 2:
因此,在任何给定时间,该内核最多可以有 114×2 = 228 个线程块驻留在 GPU 上。
这意味着我们需要 16,384 / 228 = ~71.86 个所谓的波才能完成 matmul 运算。
📝占用
在 CUDA 术语中,占用率通常指的是可以在 SM 上并发运行的块的数量。还有一个密切相关的定义:
占用率(跃迁):活跃跃迁与每个SM最大跃迁数的比率。
这里,"活动线程束"指的是线程块在启动时分配了资源(寄存器、SMEM 等)之后的线程束。

图 20:Nsight 计算:占用率、波浪信息
这里有一个关于使用 Nsight Compute 分析器的优秀教程 11 。
值得一提的是:与瓦片量化 类似,也存在波量化的概念。当波的数量较少时,这种效应尤为明显。
例如,假设我启动一个包含 114 个块的内核(正好是我 H100 PCIe 上的 SM 数量)。假设我们一次只能运行每个 SM 一个块。每个 SM 只运行一个块,内核在一个波次内完成。现在假设我将启动的块数增加到 115 个。突然,执行时间几乎翻了一番------因为我们需要两个波次------然而,第二个波次中的大部分资源都处于空闲状态,只有一个块在运行:
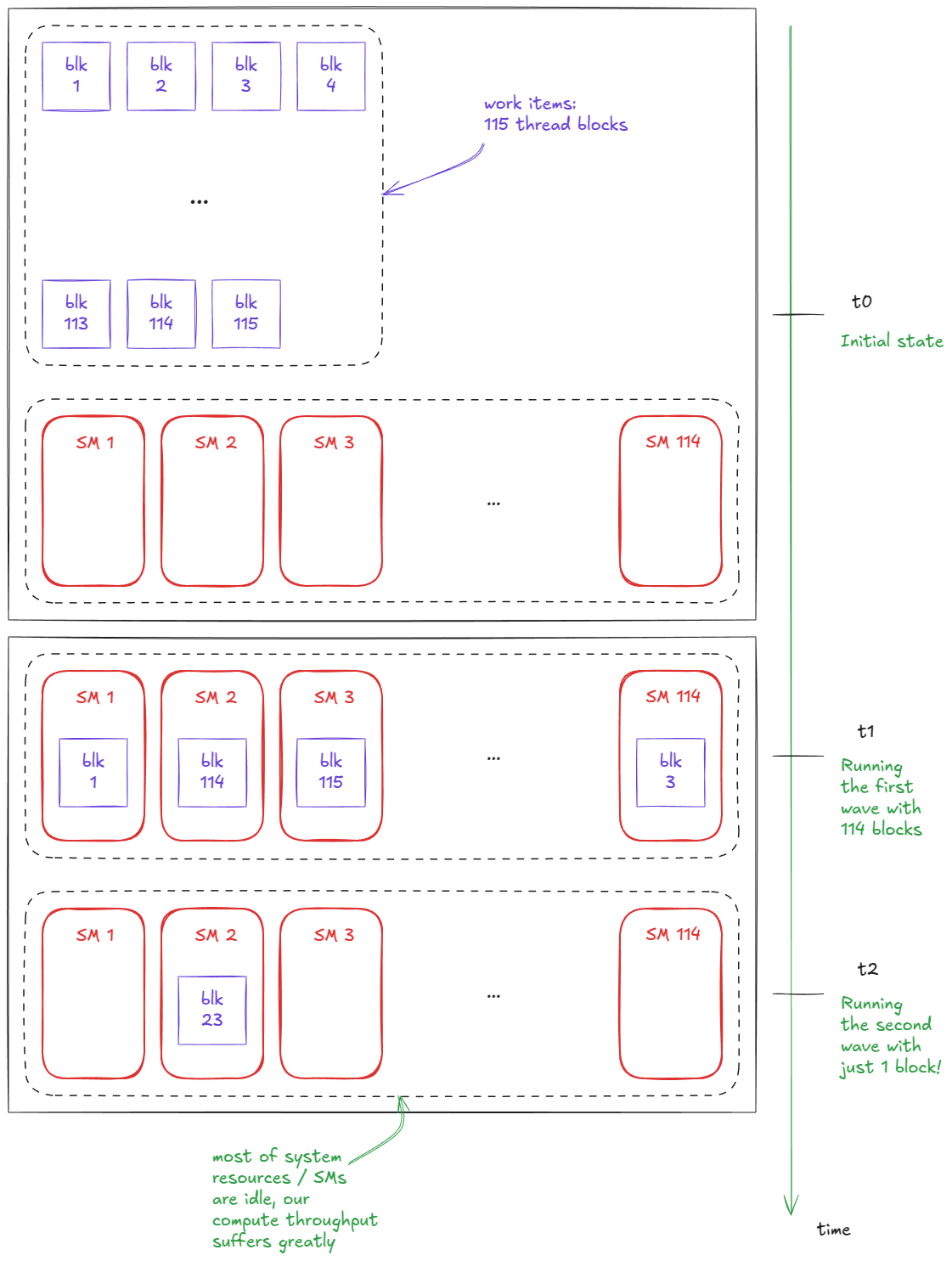
图 21:波的量子化
在对简单的矩阵乘法内核进行上述基本分析之后,我们现在转向 PTX/SASS 视角。以下是我使用的编译设置(Godbolt):
`compilation settings`:` nvcc `12.5.1` `-`O3 `# the most aggressive standard-compliant optimization level, add loop unrolling, etc.` `-`DNDEBUG `# turn assert() into noop, doesn't matter for our simple kernel` `--`generate`-`code`=`arch`=`compute_90`,`code`=[`compute_90`,`sm_90a`]` `# embed PTX/SASS for H100` `--`ptxas`-`options`=-`v `# makes ptxas print per-kernel resource usage during compilation` `-`std`=`c`++17` `# compile the code according to the ISO C++17 standard, doesn't matter` `# --fast-math # not using, less important for this kernel` `另一个重要的设置是--use_fast_math。它以数值精度换取速度,主要影响 fp32 操作。例如,它会将标准数学函数替换为快速的近似内部函数(例如sinf -> ),启用非规格化数(远小于最小"正常"可表示幅度的极小浮点数)的清零 (ftz) 功能,等等。 __sinf
下方是上面所示的 CUDA C++ 内核的带注释的 PTX 文件。我手动解码了它,以便更好地理解其指令集架构 (ISA)。您可以放大并花点时间理解其结构(或者,您可以直接跳到图后阅读我的摘要,然后再返回查看图):

图 22:对应于朴素矩阵乘法 CUDA 内核的 PTX 代码
综上所述,PTX 代码的高级流程如下:
- 计算变量 x
row和 ycol。有趣的是,编译器使用位bfi域插入(bit field insert)指令来计算 x 和y,col而不是简单地将寄存器 x 和y 相加。这可能是为了平衡执行流水线,将工作路由到利用率较低的单元------但请注意,位域插入本身并不比加法指令更快。r2``r3``bfi - 如果此线程超出有效范围
C(守卫逻辑),则提前退出。 - 如果
K < 1直接跳转到存储C(tmp将为 0.0)。 - 如果
K <= 3跳转到尾部循环。 - 否则,如果:在进入主循环之前计算
K > 3基本偏移量。A``B - 主循环(展开 ×4)。每次迭代执行 4 个 FMA 步骤,与加载和地址运算交错进行。
- 尾循环(
<= 3迭代次数)。执行剩余的点积步骤,无需展开。 - 尾声:加载 的输出值
C,应用 GEMM 更新(alpha * A @ B + beta * C),并将结果写回全局内存st.global.f32。
这里可以看到一些编译器优化:提前退出、循环展开、拆分为主循环和尾循环,以及看起来像是流水线负载均衡(假设我的bfi假设是正确的)。
展开过程尤其重要,因为它暴露了指令级并行(ILP)的优势。由于每个线程束仍然拥有独立的指令要执行,因此无需频繁地将其替换为另一个线程束------这有助于隐藏延迟。
什么是ILP(教学级并行)?
指令级并行性 (ILP) 指的是单个线程束能够通过连续发送独立指令来同时"运行"的工作量。高 ILP 使得线程束调度器能够在之前的指令仍在等待延迟完成时,每个周期都发送一条新指令。
考虑以下两个指令流(假设 FMA 需要 4 个周期):
1)低ILP(完全依赖链)
`y `=` a `*` b `+` `1.0;` `// uses a,b` z `=` y `*` c `+` `1.0;` `// depends on y` w `=` z `*` c `+` `1.0;` `// depends on z` `每个 FMA 都依赖于前一个结果=>不能并行调度=>总延迟 = 12 (3*4) 个周期。
- 高独立运行率 (ILP)
`c0 `=` a0 `*` b0 `+` `1.0;` c1 `=` a1 `*` b1 `+` `1.0;` c2 `=` a2 `*` b2 `+` `1.0;` `三个独立的FMA =>调度器可以在连续的周期内发出它们。在第0、1、2周期发出,结果在第4、5、6周期准备就绪=>总延迟 = 6个周期。
这就是循环展开/指令级并行处理(ILP)重要的原因。
为了方便调试,您可能需要禁用循环展开,以便更轻松地进行 PTX/SASS 分析。只需添加:#pragma unroll 1。
展开还可以减少分支()指令的数量,bra使程序更加简洁/高效。
我还观察到一些编译器效率低下的问题,例如:
- 不必要的变量初始化为 0。
A计算地址过于复杂。- 冗余的部分偏移计算,原本两条指令可以合并成一条。
真有趣!现在让我们看看对应的 SASS 代码:

图 23:对应于朴素矩阵乘法 CUDA 内核的 SASS 代码
我将重点指出与 PTX 代码的不同之处:
- 循环现在已经展开了16倍!
- LDG 指令被移至循环顶部,使计算与数据加载重叠。FMA 指令大多集中在每个展开块的末尾。
- 共有 2 个尾部循环:一个展开 8 次,一个展开 4 次,最后一个循环涵盖最后 3 次迭代。
我在 SASS 中也发现了一些有趣的编译器怪癖和效率低下之处:
- 程序计数器(
R1寄存器)已加载但从未被使用。原因不明? - 仍然存在冗余的零初始化。
L_x_2其中一个谓词是空操作:它始终为真,因此永远不会执行跳转到标签(4×展开循环)。- 4×展开循环包含一条多余的
BRA指令------它永远不会迭代超过一次。 - 执行完最后一个语句后
EXIT,代码陷入了无限循环。这是实现细节上的疏忽还是程序故障? - 最后(这不是故障),代码中填充了
NOPs内存对齐信息。
真有趣!我们体会到了编译器在幕后所做的工作。
现在,了解了这些背景知识后,让我们转换思路,深入了解一些SOTA内核。
📝下一章的补充阅读材料:
我强烈推荐 Simon 的这篇精彩博文。它最初激发了我深入研究内核的兴趣。在本章中,我将以他的内核 1012代码为参考。虽然这段代码本身似乎源自 CUTLASS(例如,参见](https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/ "[ ")[13和14 ),但 我首先分析的是 Simon 的版本------因此,我将以他的版本为准。
设计接近最先进的同步矩阵乘法内核
在本章中,我们将分析一个在以下约束条件下接近最新技术水平的fp32内核:
- 无 TMA
- 没有异步内存指令
- 没有张量核心
- 仅支持fp32(不支持bf16)
换句话说,这是 Volta 架构之前的 GPU 模型所达到的 SOTA(在 Volta/Ampere 架构上接近 SOTA):
- Volta引入了张量核心
- 安培架构引入了异步内存指令
- Hopper引入了TMA
我们将要学习的技术叫做扭曲平铺。
在深入探讨之前,让我们稍作修改,重新审视一下之前的内核,看看会发生什么。具体来说,我们将改变 ` rowand`col变量的计算方式。
原文:
const` `int` row `=` blockIdx`.`x `*` BLOCKSIZE `+` `(`threadIdx`.`x `/` BLOCKSIZE`);` `const` `int` col `=` blockIdx`.`y `*` BLOCKSIZE `+` `(`threadIdx`.`x `%` BLOCKSIZE`);` `修改版:
const` `int` row `=` blockIdx`.`x `*` BLOCKSIZE `+` `(`threadIdx`.`x `%` BLOCKSIZE`);` `const` `int` col `=` blockIdx`.`y `*` BLOCKSIZE `+` `(`threadIdx`.`x `/` BLOCKSIZE`);` `换句话说,我们只需交换%and/运算符即可。
与前一个例子相比,逻辑结构上唯一的变化就是交换了row2"and"的位置:col2
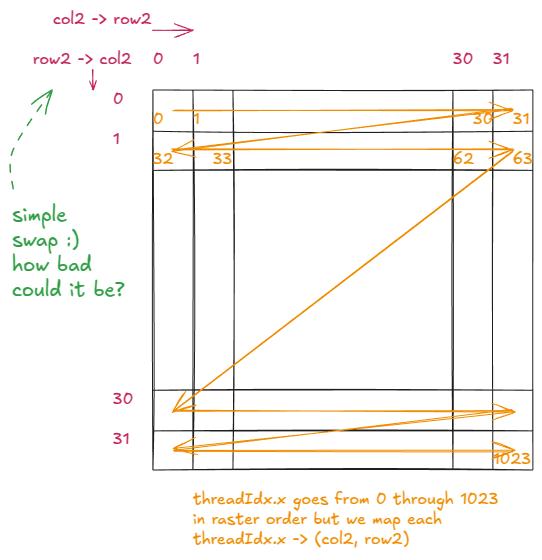
图 24:row2 和 col2 变量的新逻辑组织
以下是修改后的内核现在的功能:
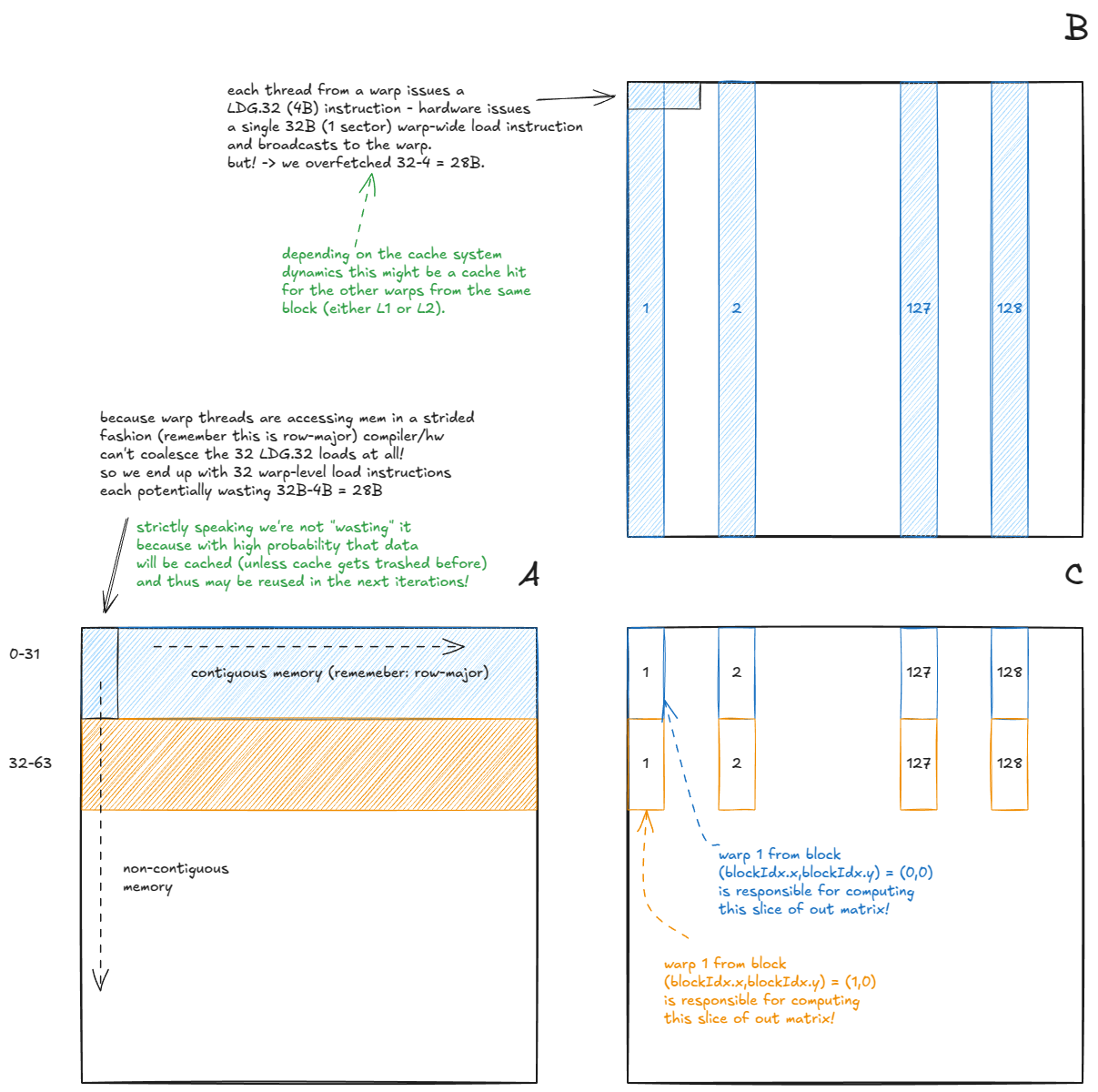
图 25:未合并 GMEM 访问的朴素内核
这个看似无害的调整使我们的 GMEM 访问不再合并。
在我的 H100 PCIe 卡上,性能从 3171 GFLOP/s 下降到仅 243 GFLOP/s------速度下降了 13 倍。这正是我们在前面 GMEM 部分看到的性能下降(Stephen Jones 的 GMEM 访问实验)。
从表面上看,这似乎只是两个操作员之间的一次简单交换。但如果你对硬件没有概念,就绝对想不到会产生如此巨大的影响。
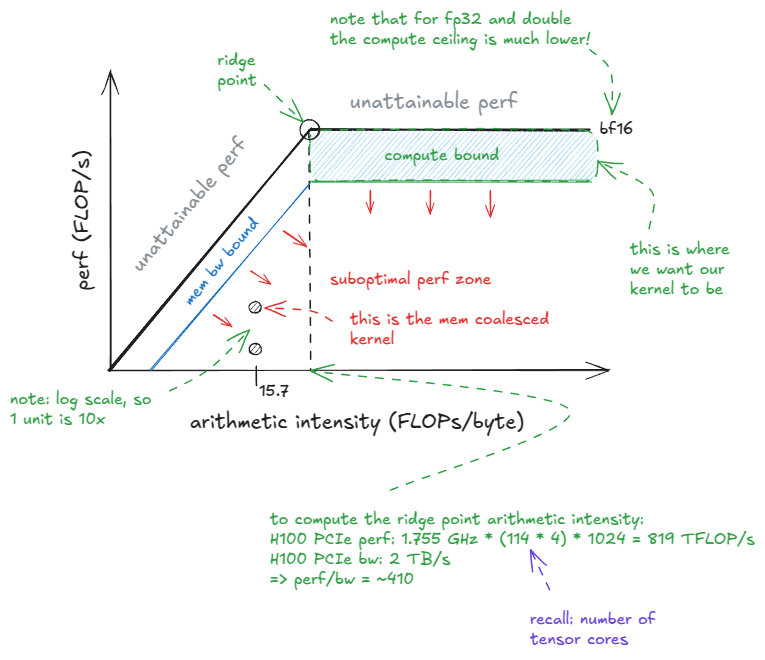
图 26:屋顶线模型
从屋顶线模型可以看出,我们的内核位于图中内存带宽受限区域的深处。我们花了大价钱从 NVIDIA 购买计算资源,所以最好还是瞄准计算资源受限的区域。
📝屋顶线模型
屋顶线模型以性能(FLOP/s) 为纵轴,以**算术强度(AI)**为横轴绘制图形。
算术强度定义为从设备内存/GMEM(默认)加载的每个字节执行的 FLOP 次数。
"脊点"出现在:peak perf / GMEM bw。对于我的 H100 PCIe 显卡来说,这个值约为 410。只有当 AI 性能超过这个值时,内核才能进入计算密集型状态。
在继续之前,让我们先回顾一下顺序矩阵乘法代码。供参考:
for` `(int` m `=` `0;` m `<` M`;` m`++)` `{` `for` `(int` n `=` `0;` n `<` N`;` n`++)` `{` `float` tmp `=` `0.0f;` `// accumulator for dot product` `for` `(int` k `=` `0;` k `<` K`;` k`++)` `{` tmp `+=` A`[`m`][`k`]` `*` B`[`k`][`n`];` `}` C`[`m`][`n`]` `=` tmp`;` `}` `}` `我在这里想强调的关键点是,语义与循环顺序无关。换句话说,我们可以用 3! = 6 种方式排列这三个嵌套循环,结果仍然是正确的矩阵乘法运算。
在这六种排列中,最有趣的是以K作为最外层环的排列。(m 和 n 的相对顺序并不重要,所以我们假设它们是"标准"m-n顺序):
for` `(int` k `=` `0;` k `<` K`;` k`++)` `{` `for` `(int` m `=` `0;` m `<` M`;` m`++)` `{` `float` a `=` A`[`m`][`k`];` `// reuse this load across N (think GMEM access minimization)` `for` `(int` n `=` `0;` n `<` N`;` n`++)` `{` C`[`m`][`n`]` `+=` a `*` B`[`k`][`n`];` `}` `}` `}` `如果这些负载来自 GMEM,那么通过将负载数量A从N^3减少到,我们节省了大约 2 倍的带宽N^2。
但更重要的见解在于算法层面:这个版本将矩阵乘法计算为外积的部分和。这种视角对于理解扭曲平铺法至关重要,我们接下来将深入探讨该方法:
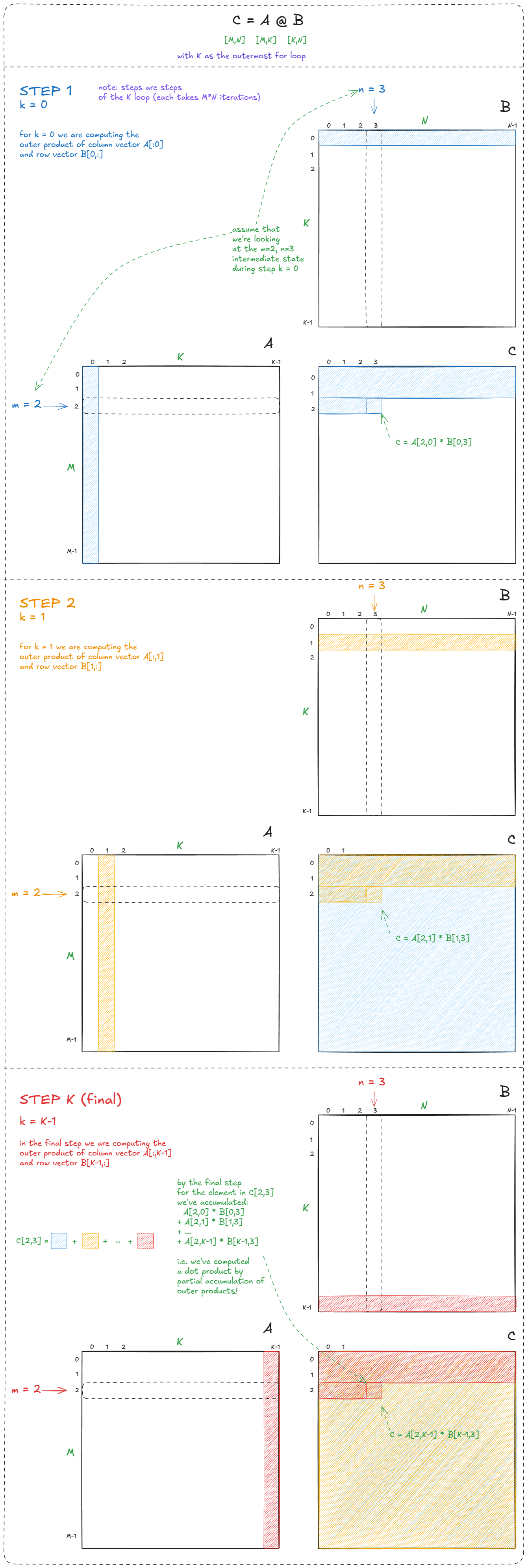
图 27:Matmul 表示为部分外积之和
这或许显而易见,但值得强调:点积等价于部分点积之和:

图 28:点积等价于部分点积之和
这一点至关重要,因为它允许我们将计算分解成一系列块矩阵乘法运算(每个运算产生部分点积)。通过在执行计算之前将这些块移至SMEM,我们可以减少GMEM的流量并显著提高速度。
如果不将其分成若干块,我们不可能将其装入SMEM中。
还要记住,我们最初的内核运算强度非常低------每个加载字节的运算量很小。为了改进这一点,我们需要:
- 每个线程计算多个输出元素。
- 尽量使输出瓷砖呈正方形。
下面用直观的方式解释为什么这很重要:
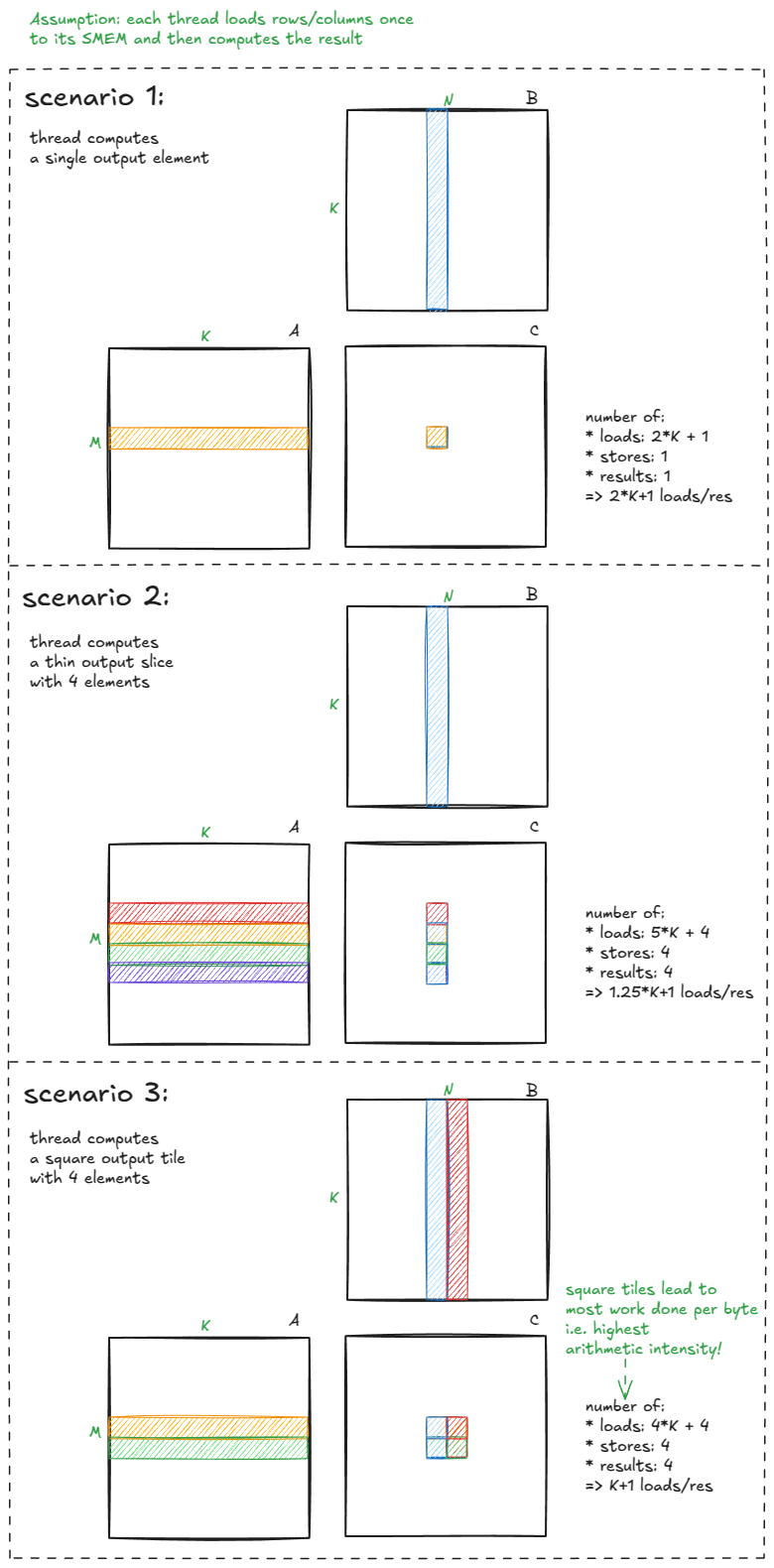
图 29:当每个线程计算多个输出且图块接近正方形时,算术强度会降低。
至此,我们已经收集到了理解扭曲平铺所需的大部分信息。让我们把它们整合起来。
我们了解两件关键的事情:
- 输出图块应为正方形(以最大限度地提高运算强度)。
- 计算应该分成若干子步骤,以便中间部分可以放入 SMEM 中。
基于以上考虑,该算法的高级结构如下所示:
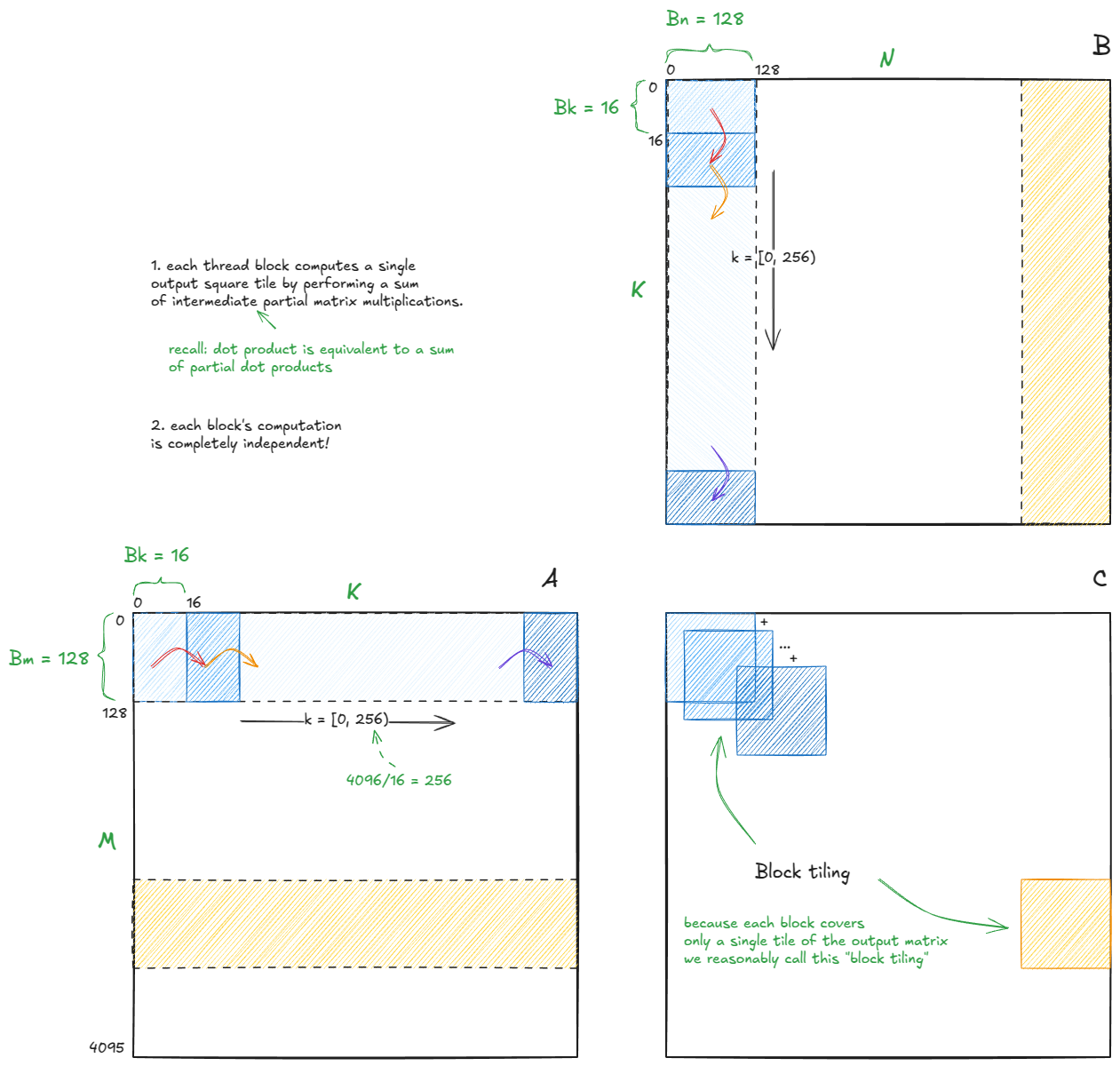
图 30:扭曲平铺算法(也称为块平铺)的高级结构。
参考代码在这里。我建议先看我的图表,然后再打开代码,把所有细节联系起来。
📝笔记:
我将使用与 Simon 博客文章中相同的图块尺寸(未针对我的 H100 进行自动调整):
Bm = Bn = 128, Bk = 16
由于每个块的计算都是独立的------而且我们已经确认部分点积累加起来等于总点积------所以我们只需要关注单个块的单个步骤。其余的块(另外 1023 个块,共 4096/128 * 4096/128 = 32 * 32 = 1024 个块)将遵循相同的逻辑。
📝记下来
不知为何,我总是很难忽略其他代码块。所以,是时候默念咒语了:"其他一切都是正确的;我只需要专注于下一步。局部正确性最终会带来全局正确性。" :)
带着这种思路,让我们放大到蓝色块的第一步(红色箭头过渡之前的计算),它对应于输出图块C[0,0](注意 - 图块 - 而不是元素)。
块维度分别Bm × Bk为矩阵A和Bk × Bn矩阵。B这些被加载到SMEM缓冲区中As。Bs
由于数据没有转置,因此加载/存储B操作Bs非常简单Bs。4 个线程束分别B从 GMEM 中获取一行数据,每个线程先执行向量化的加载操作(LDG.128),然后执行向量化的存储操作(STS.128)。每个线程束循环 4 次,每次循环 4 行。
对应的代码(我添加了注释并删除了 Simon 注释掉的代码):
for` `(`uint offset `=` `0;` offset `+` rowStrideB `<=` BK`;` offset `+=` rowStrideB`)` `{` `// we need reinterpret_cast to force LDG.128 instructions (128b = 4 4B floats)` `reinterpret_cast<float4 *>(` `&`Bs`[(`innerRowB `+` offset`)` `*` BN `+` innerColB `*` `4])[0]` `=` `reinterpret_cast<const float4 *>(` `&`B`[(`innerRowB `+` offset`)` `*` N `+` innerColB `*` `4])[0];` `}` `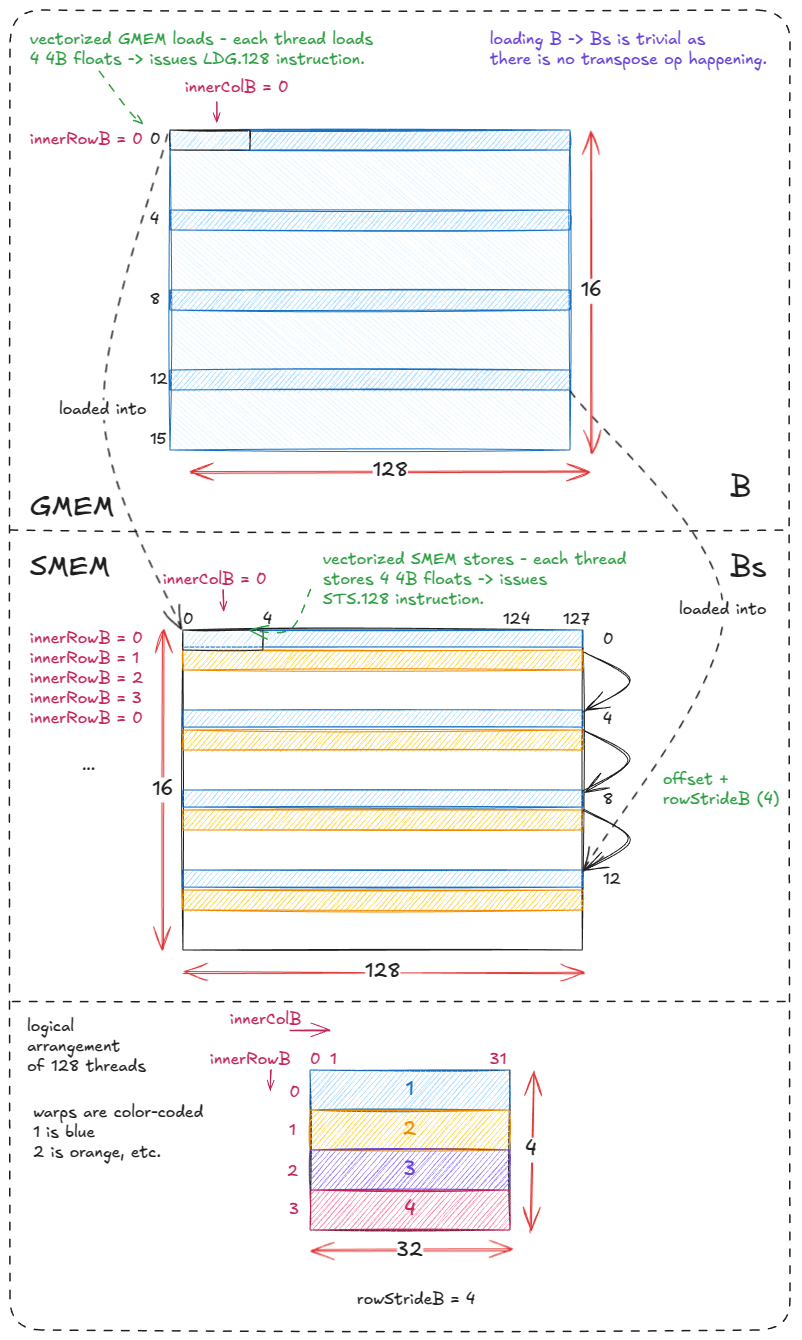
图 31:将 B 块(GMEM)加载到 Bs(SMEM)中
加载A→ As。这一步比较复杂,因为As需要转置。转置的原因是为了LDS.128在后续的计算阶段实现向量化加载()。
这样做的缺点是存储操作无法向量化:从一行中取出的 4 个浮点数A现在必须分散到一列中As,而这一列映射到同一个内存库。这可以接受,因为我们优先考虑快速加载------在计算过程中,每个元素As都会被多次访问,而存储操作只会执行一次。
图中的"and "和" innerRowXand "注释准确地显示了每个线程负责的具体工作。innerColX
对应代码:
for` `(`uint offset `=` `0;` offset `+` rowStrideA `<=` BM`;` offset `+=` rowStrideA`)` `{` `// we need reinterpret_cast to force LDG.128 instructions` `const` float4 tmp `=` `reinterpret_cast<const float4 *>(` `&`A`[(`innerRowA `+` offset`)` `*` K `+` innerColA `*` `4])[0];` As`[(`innerColA `*` `4` `+` `0)` `*` BM `+` innerRowA `+` offset`]` `=` tmp`.`x`;` As`[(`innerColA `*` `4` `+` `1)` `*` BM `+` innerRowA `+` offset`]` `=` tmp`.`y`;` As`[(`innerColA `*` `4` `+` `2)` `*` BM `+` innerRowA `+` offset`]` `=` tmp`.`z`;` As`[(`innerColA `*` `4` `+` `3)` `*` BM `+` innerRowA `+` offset`]` `=` tmp`.`w`;` `}` `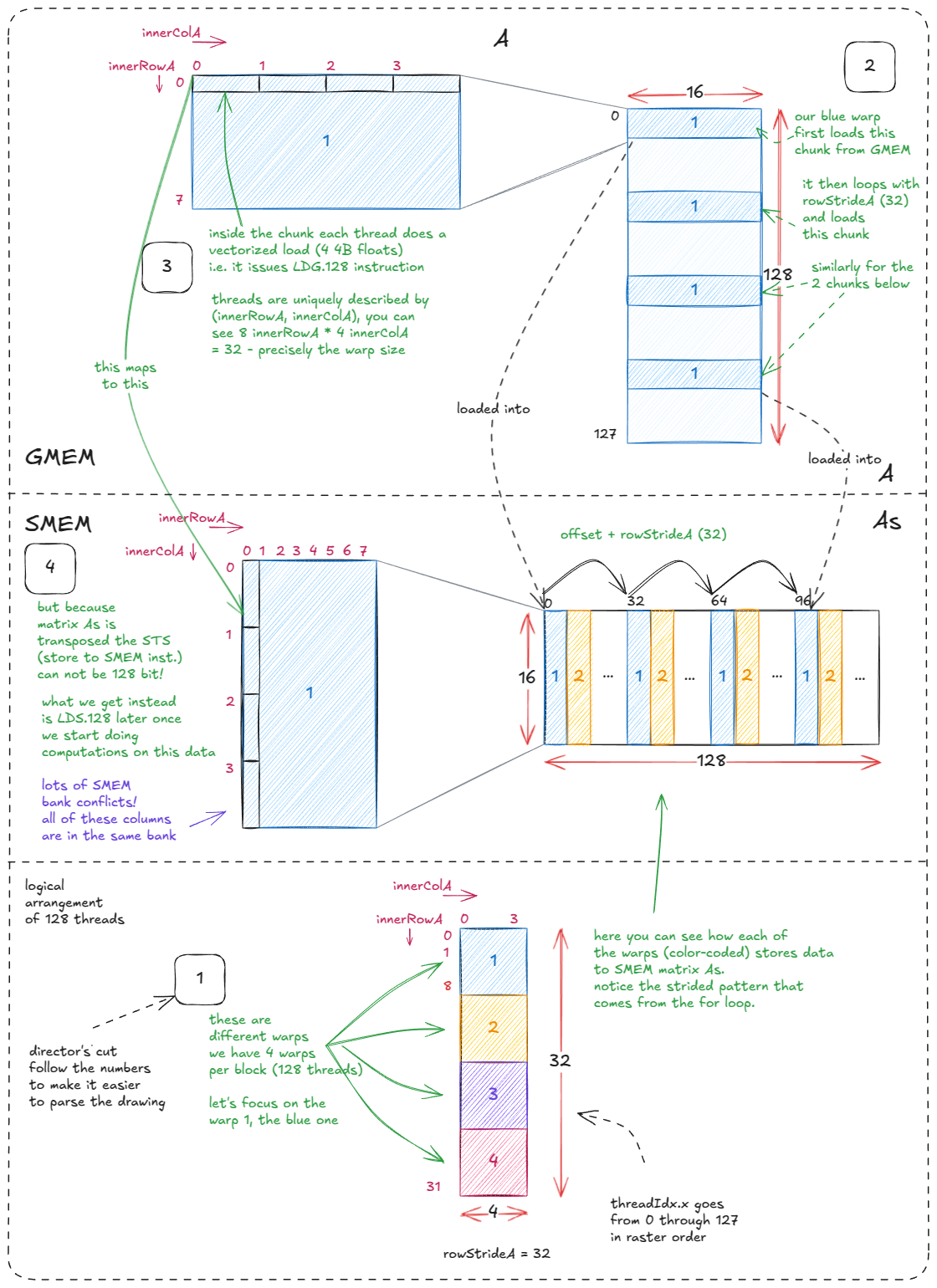
图 32:将 A (GMEM) 数据块加载到 As (SMEM) 中
加载完成后,我们同步线程块(__syncthreads()),以确保所有数据在As和中都可用Bs。
现在进入计算阶段。
对应的代码(我建议快速浏览一下,然后对比几次绘制出来的图形:)):
for` `(`uint dotIdx `=` `0;` dotIdx `<` BK`;` `++`dotIdx`)` `{` `// dotIdx is the outer most loop` `// WM = 64, that's why As is broken into 2x64 parts` `// TM = 8, that's why thread processes 8 rows from As` `// WMITER = 1, that's why only single slice in As (2 in the appendix of the drawing)` `for` `(`uint wSubRowIdx `=` `0;` wSubRowIdx `<` WMITER`;` `++`wSubRowIdx`)` `{` `// load from As into register regM` `for` `(`uint i `=` `0;` i `<` TM`;` `++`i`)` `{` regM`[`wSubRowIdx `*` TM `+` i`]` `=` As`[(`dotIdx `*` BM`)` `+` warpRow `*` WM `+` wSubRowIdx `*` WSUBM `+` threadRowInWarp `*` TM `+` i`];` `}` `}` `// WN = 64, that's why Bs is broken into 2x64 parts` `// TN = 4, that's why 4 columns per slice of Bs` `// WNITER = 4, that's why four slices in Bs` `// WSUBN = WN/WNITER = 16 (used to iterate over slices)` `for` `(`uint wSubColIdx `=` `0;` wSubColIdx `<` WNITER`;` `++`wSubColIdx`)` `{` `for` `(`uint i `=` `0;` i `<` TN`;` `++`i`)` `{` `// load from Bs into register regN` regN`[`wSubColIdx `*` TN `+` i`]` `=` Bs`[(`dotIdx `*` BN`)` `+` warpCol `*` WN `+` wSubColIdx `*` WSUBN `+` threadColInWarp `*` TN `+` i`];` `}` `}` `// execute warptile matmul via a sum of partial outer products` `for` `(`uint wSubRowIdx `=` `0;` wSubRowIdx `<` WMITER`;` `++`wSubRowIdx`)` `{` `for` `(`uint wSubColIdx `=` `0;` wSubColIdx `<` WNITER`;` `++`wSubColIdx`)` `{` `for` `(`uint resIdxM `=` `0;` resIdxM `<` TM`;` `++`resIdxM`)` `{` `for` `(`uint resIdxN `=` `0;` resIdxN `<` TN`;` `++`resIdxN`)` `{` threadResults`[(`wSubRowIdx `*` TM `+` resIdxM`)` `*` `(`WNITER `*` TN`)` `+` `(`wSubColIdx `*` TN`)` `+` resIdxN`]` `+=` regM`[`wSubRowIdx `*` TM `+` resIdxM`]` `*` regN`[`wSubColIdx `*` TN `+` resIdxN`];` `}` `}` `}` `}` `}` `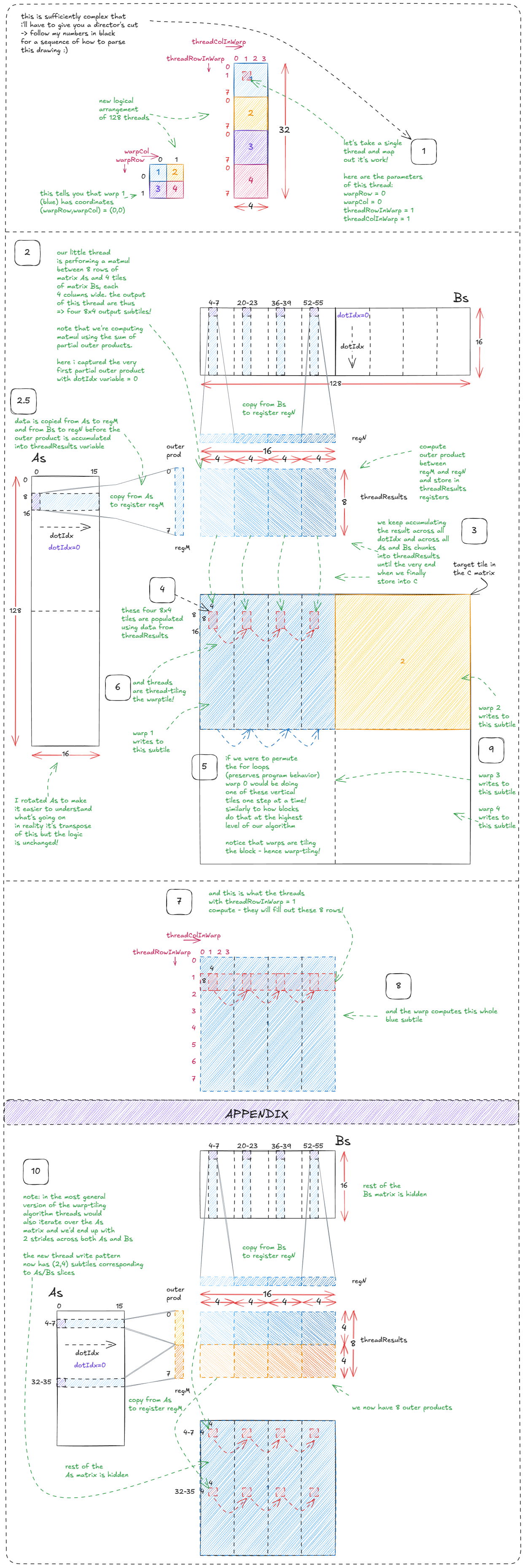
图 33:在 A 和 B 之间执行 matmul,作为一系列线级外积(经线平铺 + 线平铺)。
数据块处理完毕后,我们会再次进行同步。这可以防止竞态条件------如果没有同步,一些线程可能在其他线程仍在处理当前数据块时就开始写入As下一个数据块。Bs
同步之后,我们将指针向前移动A,B算法Bk重复执行,直到所有数据块都被处理完毕。
`A `+=` BK`;` `// move BK columns to right` B `+=` BK `*` N`;` `// move BK rows down` `最后,当循环完成后,128 个线程将它们的私有threadResults寄存器刷新到相应的矩阵输出块中C(此时矩阵已包含完整的点积!)。
实际上,你需要针对特定的GPU自动调整该算法的参数。但正如前面提到的,这种内核方式已不再是首选------现代GPU拥有异步内存机制和张量核心,其性能远超单纯的线程束分割技术所能达到的水平。
接下来,让我们进入Hopper上的真正SOTA(山顶天文台)阶段。
📝下一章的补充阅读材料:
我强烈推荐 Pranjal 的精彩博文 15,它更像是一篇工作日志。在本章中,我将遵循他工作日志中的内核。与 Simon 的工作一样,很多代码似乎都受到了 CUTLASS 的启发(例如,参见以下文章:CUTLASS ping pong 内核 16和高效 GEMM)。
值得注意的是,魔鬼藏在细节中,Pranjal 成功地超越了 cuBLAS SOTA------在几个目标矩阵维度上达到了 cuBLAS 性能的约 107%。
在 Hopper 上设计最先进的异步矩阵乘法内核
现在是时候发挥所有硬件功能,在 Hopper 上实现真正的 SOTA 通关了。我们将使用:
- TMA同步加载/存储操作
- 张量核心
- bf16 精密
这些硬件特性既大大简化了扭曲平铺方法,又将性能提高了近一个数量级------Pranjal 报告称,性能从 32 TFLOP/s 提升了 10 倍,达到 317 TFLOP/s。
📝参考代码:
我将以内核 217为参考(另见我的PR)。请注意,符号与 Simon 的略有不同:As→sA和Bs→ sB。
这种简化之所以有效,是因为 TMA 和 Tensor Cores 抽象化了我们之前遇到的许多手动复杂性。
作为 Hopper SOTA 的第一步,让我们修改扭曲平铺基线。
我们保留完全相同的程序结构,唯一的区别是:
- 现在每个线块只需要 128 根线(4 根经线)。
- 图块大小设置为
BM = BN = BK = 64。
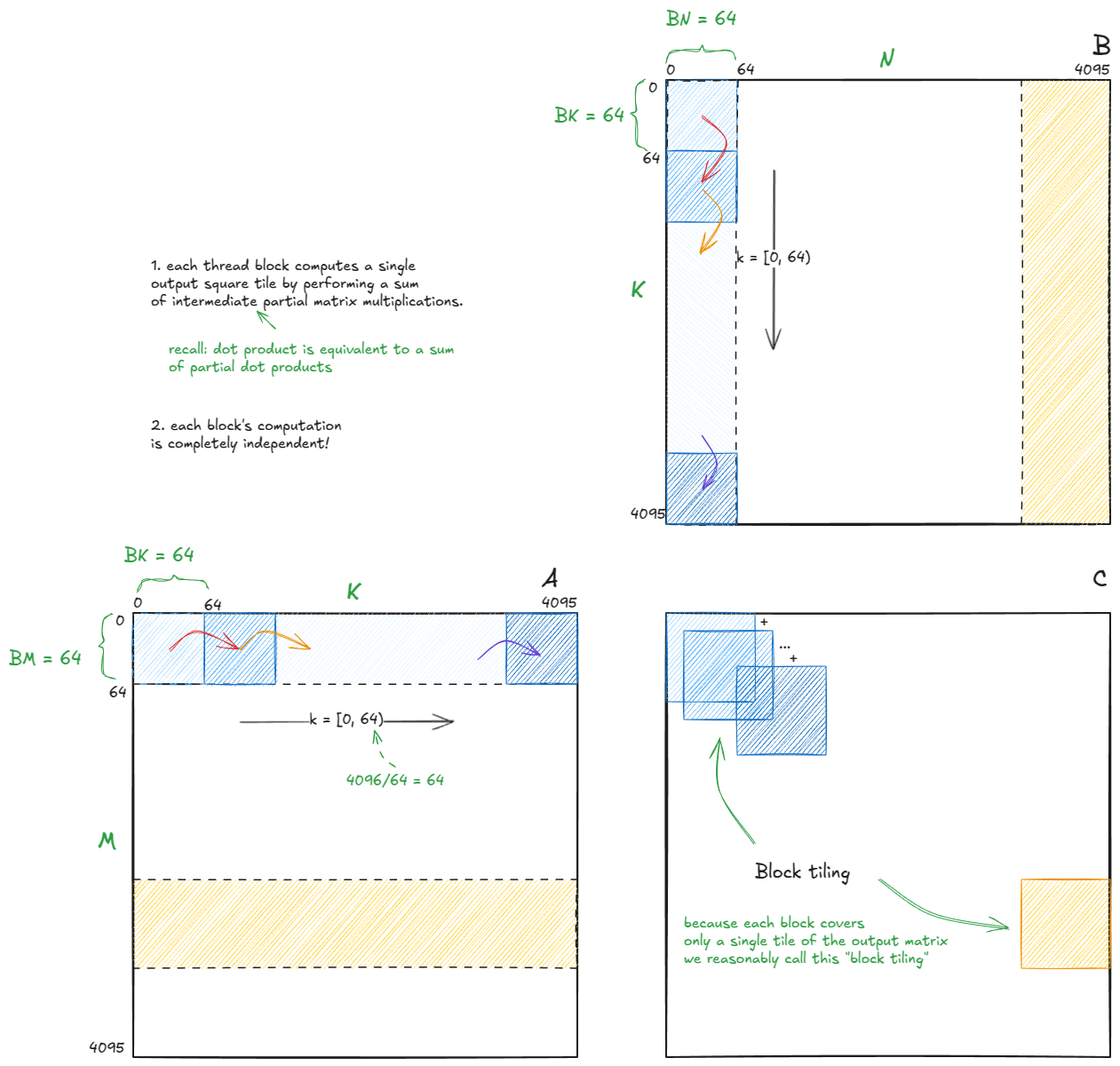
图 34:我们保持了扭曲平铺算法(块平铺)的相同高级结构。
💡矩阵格式更改:
重要提示:A 仍然是行优先格式,但 B 现在是列优先格式。
通过 TMA 将异步数据加载到 SMEM 中
在第二阶段------将数据加载到SMEM中------TMA用一种更简单的方法取代了复杂的层级加载模式。我们只需要这样做:
A为和构造张量映射B。- 触发 TMA 操作(由代码块中的单个线程执行)。
- 使用共享内存屏障进行同步。
TMA不仅会移动数据,还会自动应用数据交换,从而解决我们之前在扭曲分割中遇到的银行冲突。(我将在后面的专门章节中详细介绍数据交换。)
要生成张量映射,我们使用cuTensorMapEncodeTiled(参见文档A)。此函数对将 GMEM和SMEM 的数据块传输到 SMEM 所需的所有元数据进行编码。每个GMEM 和BSMEM 都需要一个张量映射,但它们的结构相同。对于 GMEM ,我们指定:A``B``A
- 数据类型:bf16
- 排名:2(矩阵)
- 指针:
A - 形状:(
(K,M)首先是步幅最快的维度) - 划船步幅:
K * sizeof(bf16) sA形状:(BK, BM)- 混洗模式:加载时使用 128B 模式
sA
下一个:
`__shared__ barrier barA`;` `// SMEM barriers for A and B` __shared__ barrier barB`;` `if` `(`threadIdx`.`x `==` `0)` `{` `// initialize with all 128 threads` `init(&`barA`,` blockDim`.`x`);` `init(&`barB`,` blockDim`.`x`);` `// make initialized barrier visible to async proxy` cde`::fence_proxy_async_shared_cta();` `}` `__syncthreads();` `// ensure barriers are visible to all threads` `在这里,我们初始化 SMEM 屏障,以同步写入操作sA。sB由于我们期望块中的每个线程在切换到"就绪"状态之前都到达屏障,因此我们使用所有 128 个线程初始化屏障。
该调用cde::fence_proxy_async_shared_cta()是 Hopper 代理内存模型的一部分。它在 CTA(块)作用域内对"异步代理"(TMA)和"通用代理"(普通线程 ld/st)的可见性进行排序。这里我们在初始化后立即发出此调用,以便异步引擎能够看到屏障的初始化状态。(异步复制的完成将由 mbarrier 本身发出信号。)
坦白说,我也没完全搞懂内存一致性的所有细节------而且官方文档也没帮上什么忙。这或许值得单独写一篇后续文章。如果有人知道这方面的学习资料,请告诉我!
在外层K循环中:
for` `(int` block_k_iter `=` `0;` block_k_iter `<` num_blocks_k`;` `++`block_k_iter`)` `{` `if` `(`threadIdx`.`x `==` `0)` `{` `// only one thread launches TMA` `// Offsets into GMEM for this CTA's tile:` `// A: (block_k_iter * BK, num_block_m * BM)` cde`::cp_async_bulk_tensor_2d_global_to_shared(` `&`sA`[0],` tensorMapA`,` block_k_iter`*`BK`,` num_block_m`*`BM`,` barA`);` `// update barrier with the number of bytes it has to wait before flipping:` `// sizeof(sA)` tokenA `=` cuda`::`device`::barrier_arrive_tx(`barA`,` `1,` `sizeof(`sA`));` `// B: (block_k_iter * BK, num_block_n * BN)` cde`::cp_async_bulk_tensor_2d_global_to_shared(` `&`sB`[0],` tensorMapB`,` block_k_iter`*`BK`,` num_block_n`*`BN`,` barB`);` tokenB `=` cuda`::`device`::barrier_arrive_tx(`barB`,` `1,` `sizeof(`sB`));` `}` `else` `{` tokenA `=` barA`.arrive();` `// threads-only arrival (no byte tracking)` tokenB `=` barB`.arrive();` `}` barA`.wait(`std`::move(`tokenA`));` `// blocks until: all threads arrived AND TMA finished` barB`.wait(`std`::move(`tokenB`));` `具体步骤如下(适用于两者A)B:
- 线程 0 启动 TMA
cp_async_bulk_tensor_2d_global_to_shared(...),指定 SMEM 目标(sA/sB)、张量映射和 GMEM 偏移量,指定源 GMEM 块。 - 它立即调用
barrier_arrive_tx(bar, 1, sizeof(sX)),该调用:- 统计线程到达次数(此处为 1,来自线程 0),
- 向屏障注入**预期的字节计数,**以便它知道异步复制何时完成。
- 所有其他线程都会调用
bar.arrive(),并贡献它们的到达(没有字节)。 - 然后每个线程都会调用此方法
bar.wait(token)。只有当两个条件都为真时,此等待才会完成:- 全部128个帖子都已收到,
- 异步引擎已将所有
sizeof(sX)字节写入共享内存。
这种加载模式是标准的 Hopper 惯用法------你会在现代内核中到处看到它。
在异步复制过程中,TMA 还使用128B swizzle 格式对数据进行了 swizzle 操作。
我们不妨花点时间来解释一下"swizzling"到底是什么意思。我在网上找不到清晰的解释,所以这里我尝试解释一下------一部分是为了你们,一部分是为了以后的自己。:)
搅拌
让我们先来看一个能激发思考的例子:
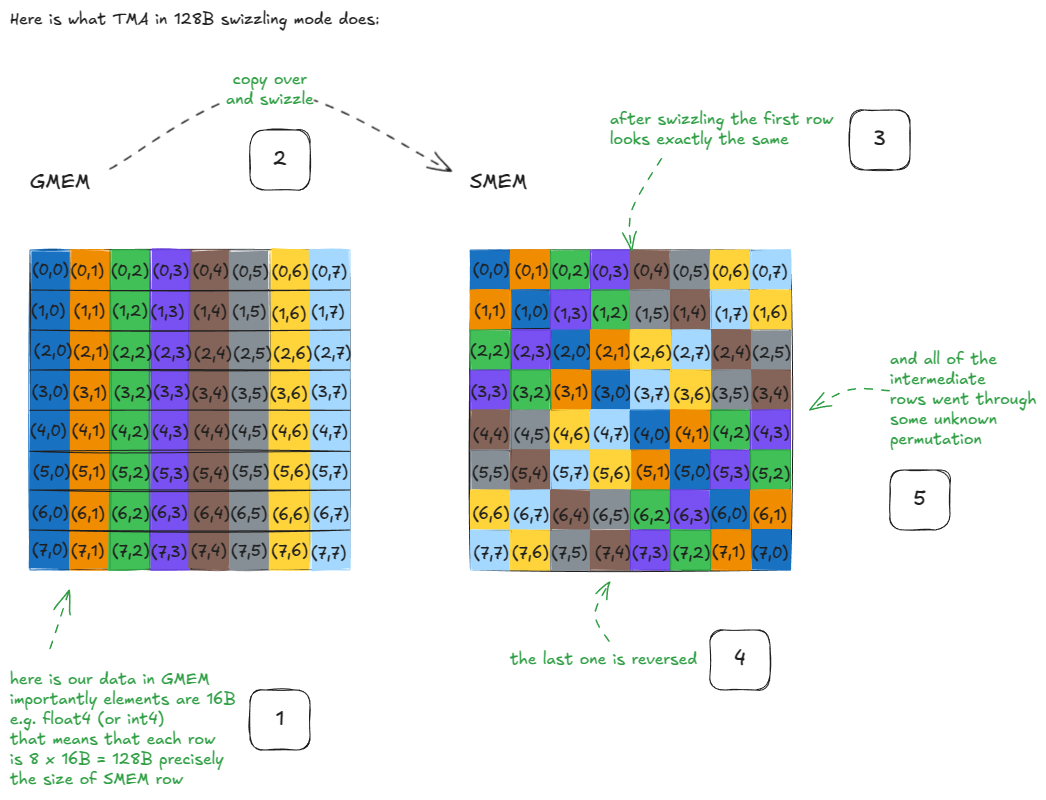
图 35:搅拌示例
这里发生了什么事?
假设我们要加载原始GMEM矩阵第一行的所有元素。经过交换之后,这仍然很简单:只需读取SMEM矩阵的第一行即可。没什么特别的。
现在,假设我们需要原始 GMEM 矩阵的第一列。请注意,这些元素现在位于 SMEM 的对角线上。这意味着我们可以用一个周期加载它们,因为没有两个线程会访问同一个存储体------零存储体冲突。
如果不进行交换,这种访问方式会将所有这些列元素映射到同一个存储体但不同的地址,从而产生 8 路存储体冲突,并将吞吐量降低 8 倍。
对于任何行或列,同样的性质也成立:经过交换后,它们都可以在一个循环中全部供应!
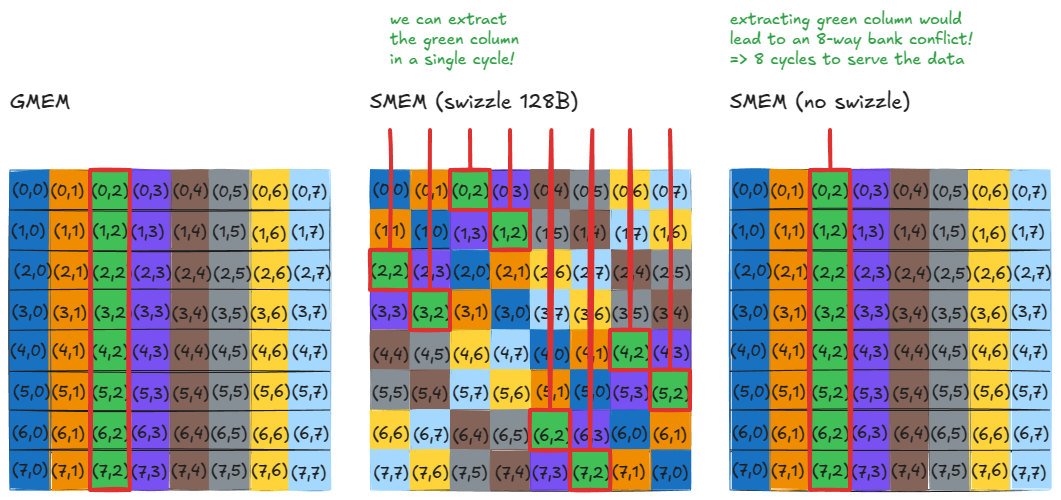
图 36:加载行或列时无银行冲突
同样的性质也适用于存储操作。例如,如果要在 SMEM 中转置一个矩阵,最简单的方法是:加载一行,然后将其作为一列写回。如果不进行数据交换,这将导致 8 路存储冲突。
启用替换功能后,我们可以避免这个问题,但必须小心索引。
📝笔记
TMA 在将数据从 SMEM 移回 GMEM 时会自动进行反校验。
既然动机已经明确,那么让我们提出以下问题:TMA 究竟是如何生成混音模式的?
原来答案很简单:与特定的掩码模式进行异或运算。
快速回顾一下异或运算,以下是真值表:
- 0, 0 映射到 0
- 0, 1 映射到 1
- 1, 0 映射到 1
- 1,1 映射到 0
值得注意的是:当其中一个位为 1 时,异或运算会翻转另一个位。
和往常一样,我们可以在 CUTLASS 中找到答案。另一位 Simon(不是之前提到的那位)也对掩码图案的生成方式给出了很好的解释 18 ------尽管他并没有具体说明这种图案是如何导致我们刚才看到的那些特定混音布局的。
所以,还有两个重要问题需要解答:
- XOR掩码是如何生成的?
- 如何实际应用遮罩来产生搅拌图案?
生成异或掩码
NVIDIA 将每种 swizzle 模式与特定的"swizzle 函数"关联起来:
- 128B 旋转模式与
Swizzle<3,4,3> - 64B 混洗模式与
Swizzle<2,4,3> - 32B 搅拌模式与
Swizzle<1,4,3>
我们来拆解一下Swizzle<3,4,3>。之后我会把异或掩码分享给其他人。
// To improve readability, I'll group bits in 8s with underscores.` `// Swizzle<3, 4, 3>` `// -> BBits = 3` `// -> MBase = 4` `// -> SShift = 3` `// Given the decoded arguments from above here are the steps that the swizzling function does:` `// Step 1. Compute bit_msk = (1 << BBits) - 1` bit_msk `=` `(0b00000000`_00000001 `<<` `3)` `-` `1` `=` `0b00000000`_00000111 `// keep 16 bit resolution` `// Step 2. Compute yyy_msk = bit_msk << (MBase + max(0, SShift))` yyy_msk `=` `0b00000000`_00000111 `<<` `7` `=` `0b00000011`_10000000 `// Step 3. Mask the input number (annotated bits A-P for clarity)` input_number `=` `0`bABCDEFGH_IJKLMNOP masked `=` input_number `&` yyy_mask `=` `0`bABCDEFGH_IJKLMNOP `&` `0b00000011`_10000000 `=` `0b000000`GH_I0000000 `// Step 4. Shift right by SShift (masked >> SShift)` shifted `=` masked `>>` `3` `=` `0b000000`GH_I0000000 `>>` `3` `=` `0b00000000`_0GHI0000 `// Step 5. XOR with the original input` output `=` input_number `^` shifted `=` `0`bABCDEFGH_IJKLMNOP `^` `0b00000000`_0GHI0000 `=` `0`bABCDEFGH_IwyzMNOP `// Replace unchanged bits with x for legibility.` `// I'll also uppercase "wyz" to make it stand out and keep GHI around as they have an impact on wyz:` output `=` `0`bxxxxxxGH_IWYZxxxx `// where WYZ = GHI ^ JKL (XOR)` `简单来说:交换函数会检查GHI第 9、8、7 位(从 0 开始索引)。如果其中任何一位的值为 1,则翻转对应的第JKL6、5、4 位,得到 1。WYZ所有其他位保持不变。
让我们来建立一些关于交换函数行为的直观理解:

图 37:Swizzle 函数直观理解
对于 32B 和 64B 交换模式,交换函数分别为0bxxxxxxxx_IxxZxxxx和0bxxxxxxxH_IxYZxxxx。
这些运算遵循相同的带掩码的异或运算思想,只是不同的控制位决定了哪些低位会被翻转。
这一切与我们最初举的那个激励人心的例子有何关联?
链接如下:
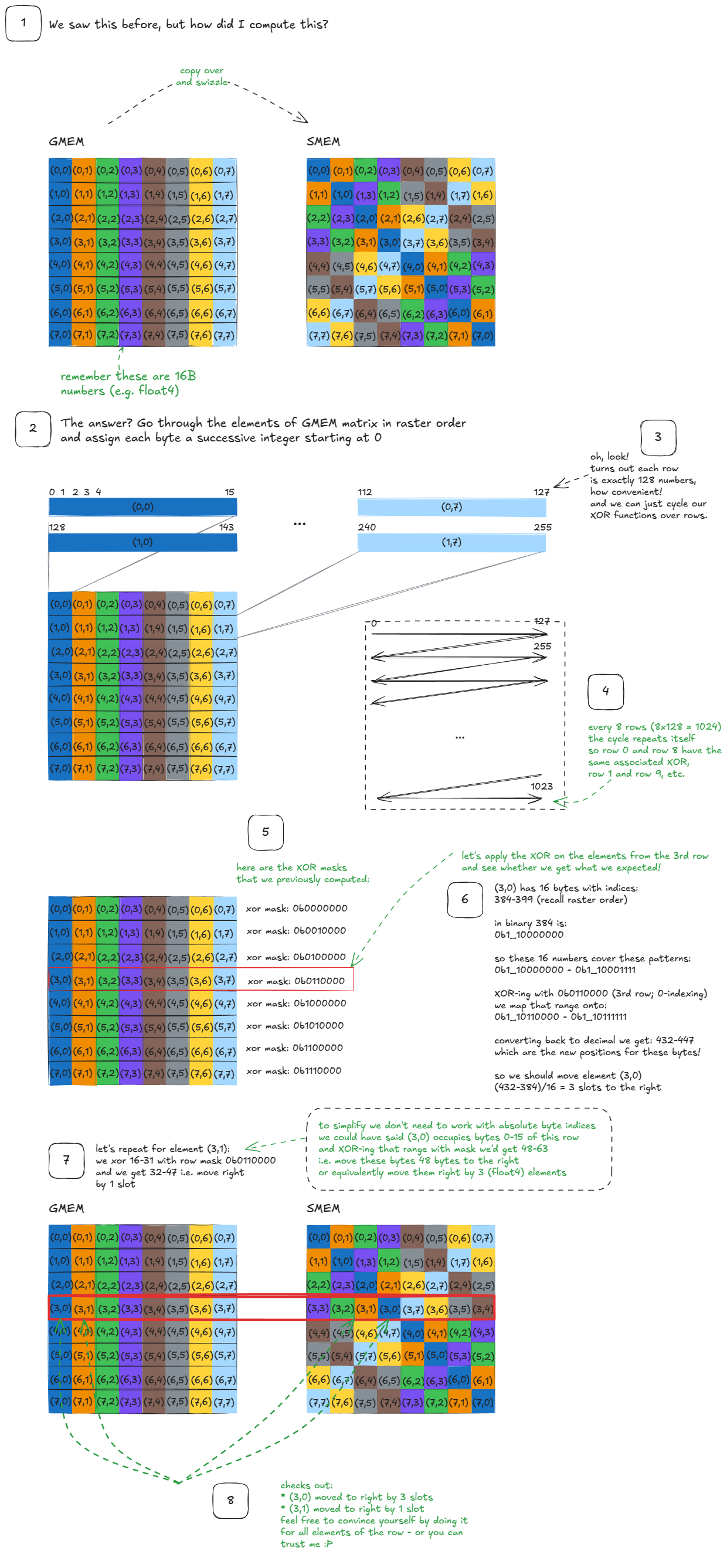
图 38:将 swizzle 函数连接到矩阵 swizzle 示例
这就是搅拌的原理和方法。:)
张量核心
回到张量核心。此时,我们已经将GMEM 中的数据块提取到ASMEM中。它们已经过数据交换,可以供张量核心使用了。B``sA``sB
NVIDIA 公开了多个矩阵乘加 (MMA) 指令:
wmma--- 扭曲合作,同步(老一代)。mma.sync--- 扭曲协作,同步(安培)。wgmma.mma_async--- warp-group 合作,异步(Hopper)。
📝笔记:
在 CUDA 中,一个线程束组= 4 个线程束 = 128 个线程。
我们将重点关注wgmma.mma_async(文档 19),因为它随 Hopper 一起引入,并且是目前为止功能最强大的。它是异步的,并利用 4 个协作 warp 共同计算矩阵乘法;这正是我们选择块大小为 128 的原因。
对于 bf16 操作数,wgmma支持形如 的形状m64nNk16,其中N ∈ {8, 16, 24, ..., 256}。在当前的示例中,我们将使用m64n64k16,但一般来说,更大的N值性能更高(只要你有足够的寄存器和 SMEM 来支持它们)。
📝笔记:
m64n64k16这意味着张量核心一次性计算出一个64×16乘法矩阵。16×64
以下是操作数放置规则:sA可以驻留在寄存器或SMEM中,sB必须驻留在SMEM中,累加器(BM x BN)始终驻留在寄存器中。
由于单个线程需要的寄存器数量太多,因此累加器被分配到 warp 组中的各个线程中。
在我们的参考内核中,你会看到它是这样初始化的:
float` d`[`WGMMA_N`/16][8];` `// d is the accumulator; GEMM: D = A @ B + D` `memset(`d`,` `0,` `sizeof(`d`));` `// init to all 0s` `我们设定了WGMMA_M = WGMMA_N = BM = BN = 64以下条件:
- 经纱组共有 128 根线
- 每个线程都持有
WGMMA_N/16 × 8寄存器。 - 总共:128 × (64/16) × 8 = 64 × 64 个寄存器
......这与累加器大小(BM × BN = 64 × 64)完全匹配,只是分布在整个组中。
以下是我们将要分析的相应张量核心代码片段:
asm` `volatile("wgmma.fence.sync.aligned;"` `:::` `"memory");` `wgmma64<1,` `1,` `1,` `0,` `0>(`d`,` `&`sA`[0],` `&`sB`[0]);` `wgmma64<1,` `1,` `1,` `0,` `0>(`d`,` `&`sA`[`WGMMA_K`],` `&`sB`[`WGMMA_K`]);` `wgmma64<1,` `1,` `1,` `0,` `0>(`d`,` `&`sA`[2*`WGMMA_K`],` `&`sB`[2*`WGMMA_K`]);` `wgmma64<1,` `1,` `1,` `0,` `0>(`d`,` `&`sA`[3*`WGMMA_K`],` `&`sB`[3*`WGMMA_K`]);` `asm` `volatile("wgmma.commit_group.sync.aligned;"` `:::` `"memory");` `asm` `volatile("wgmma.wait_group.sync.aligned %0;"` `::"n"(0)` `:` `"memory");` `📝notes:
- 有些 Hopper 指令在 CUDA C++ 中没有公开,所以我们使用内联 PTX
asm(...);。 ::: "memory"这是一个内存阻塞,它会阻止 asm 语句周围的任何内存优化,它向编译器发出"不要将周围的内存访问移动到此点之后"的提示;禁止编译器围绕此语句移动内存操作。volatile告诉编译器汇编块*不能*被删除或提升,即使它看起来是冗余的(参见文档)20。
我们首先来解开围绕实际 matmul 调用的开头和结尾指令( wgmma.fence,,commit_group) ,wait_group
wgmma.fence.sync.aligned;-文档解释得很清楚:"wgmma.fence 指令建立了对任何 warpgroup 寄存器的先前访问与 wgmma.mma_async 指令对同一寄存器的后续访问之间的顺序。"
实际上,传送组中的所有四个传送都必须在第一个传送之前执行此栅栏wgmma.mma_async。
之后,一切就绪。尽管累加器寄存器在四次 wgmma 调用期间都会更新,但我们不需要在它们之间添加更多隔离层------对于连续两个相同形状的 MMA 调用累加到同一寄存器的情况,有一个特殊例外。这正是我们目前遇到的情况。
这其实只是些样板代码。事实上,如果你把它注释掉,编译器会自动把它添加回去。
wgmma.commit_group- 另一个样板操作:文档中写道:"将所有先前未提交的 wgmma.mma_async 操作提交到一个 wgmma 组中"。它将wgmma.mma_async我们刚刚启动的所有操作(上面四个调用)合并到一个"组"中。
wgmma.wait_group 0意思是:在之前所有组都完成之前,不要继续进行下去。因为我们这里只启动了一个组,所以它的意思是"等到这四个MMA都完成,结果实际显示在累加器寄存器中之后再进行"。
所以标准节奏是:击剑 → 发射一批异步 MMA → 执行 → 等待完成。
现在来看 wgmma 本身。wgmma64该函数是对内联 PTX 调用的封装:
`wgmma`.`mma_async`.`sync`.`aligned`.`m64n64k16`.`f32`.`bf16`.`bf16`操作码的结构使其含义相当透明:f32 是累加器数据类型,bf16 是输入sA和sB矩阵的数据类型。
语义是常见的融合乘加运算:D = A @ B+D即将 GEMM 运算结果累加到现有的 fp32 数据块中。(有一个标志可以将其转换为另一种形式D=A @ B,我们稍后会用到。)
sA我特意略过了SMEM描述符的生成和sB传递细节。这些描述符编码了SMEM基地址、交换模式(本例中为128字节)以及LBO/ SBO(前导/步长维度字节偏移)值,以便张量核心能够正确导航布局。在此赘述描述符的构造会使这篇已经很长的文章显得冗长,或许值得单独撰写一篇专门的文章。需要注意的是,这里还存在一个额外的元数据层,我(暂时)省略了对此的解释。
以下是我们需要 4 次 wgmma 调用的原因:
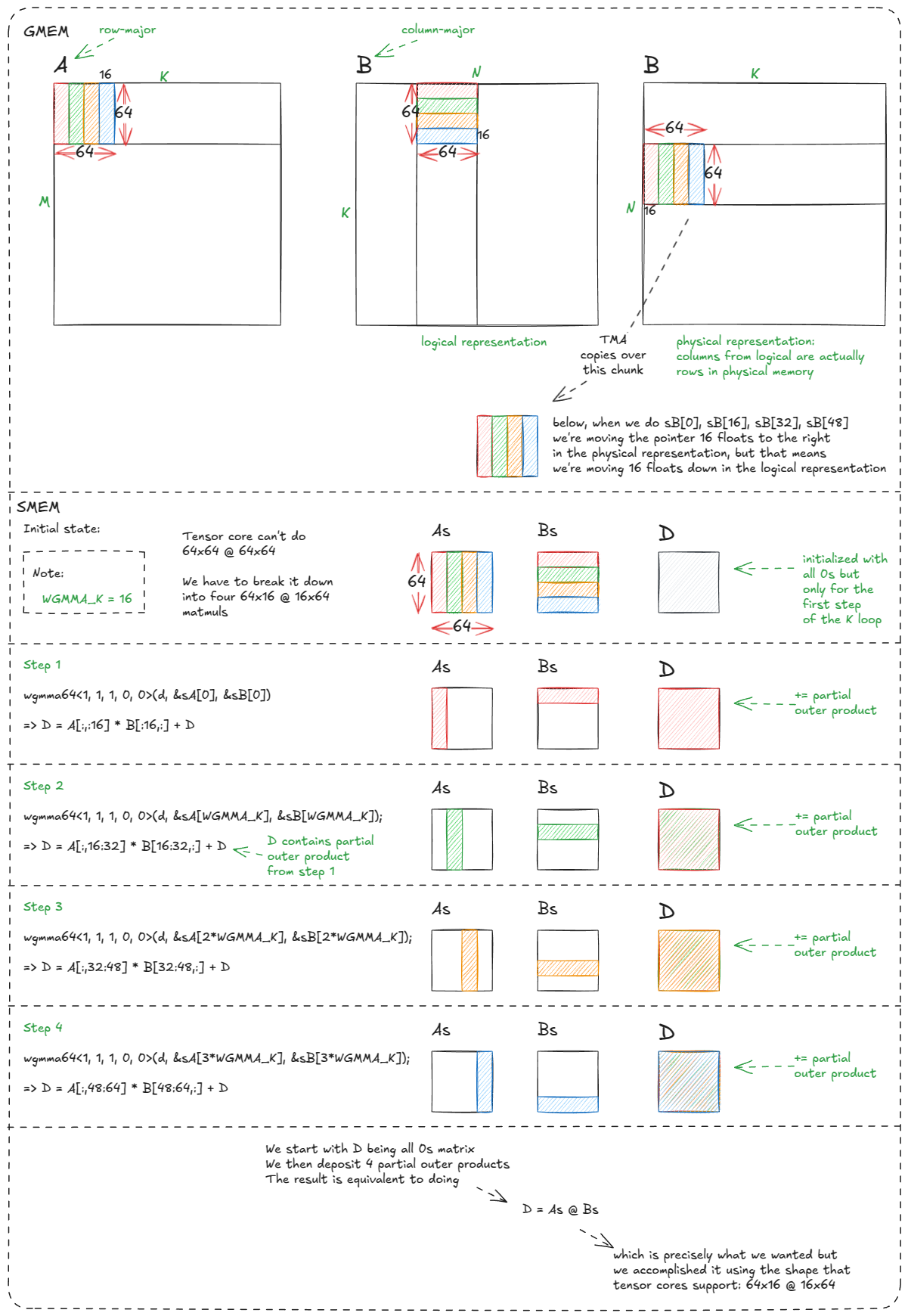
图 39:执行四次 64x16 @ 16x64 wgmma 调用等效于执行一次 64x64 @ 64x64 matmul 调用
这里稍微令人费解的部分是列优先表示:sB[0] ... sB[48]最终如何映射到正确的逻辑位置/切片。
但关键在于,我们之前遇到的许多线程束分块和线程分块的复杂性现在都已在硬件层面抽象化。过去需要跨线程束精心编排的操作,现在只需少量样板指令和几个声明式的 wgmma 调用即可完成。
也就是说,这仅仅是个开始。我们仍然在浪费 TMA 和张量核心的计算周期:
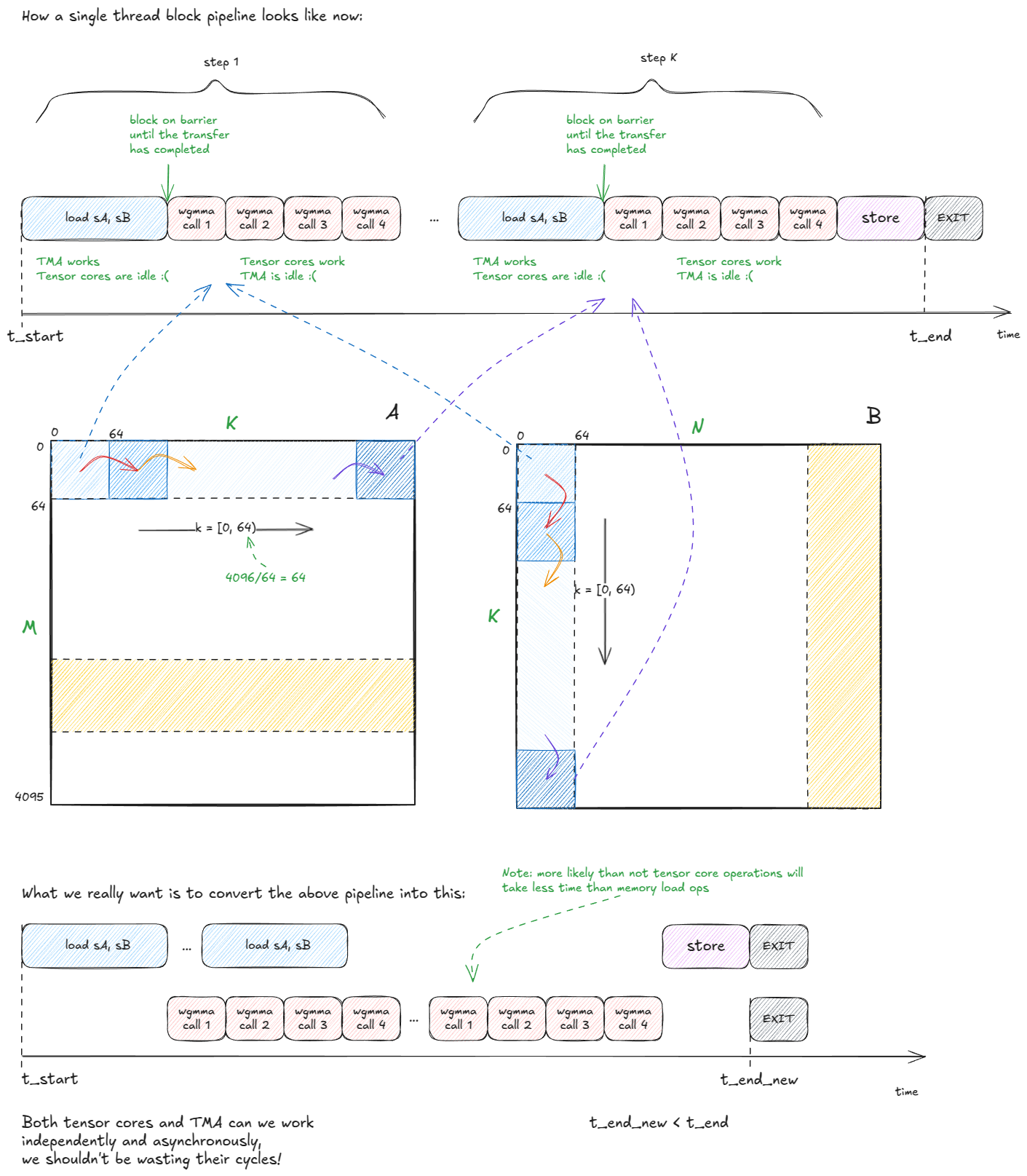
图 40:我们浪费了 TMA 和 TC 循环------我们可以做得更好。
我们解决计算周期浪费的方法是采用流水线式计算和数据传输方式。具体来说,我们将SMEM中的数据块转换成一个数据块队列------例如,每个数据块的长度为5 sA。sB
然后我们将工作分配给两个线程组:
- 一个跃迁组充当
producer,负责通过将新的数据块流式传输到队列中来保持 TMA 的忙碌A状态B。 - 另一个 warp 组充当
consumer,从队列中抽取数据以保持张量核心饱和。
当然,这需要协调。我们使用的机制是SMEM屏障队列,队列中每个槽位放置一个full[i]/对屏障,用于同步生产者和消费者。empty[i]
参考:内核 4代码。
以下是设置情况:
// queue of barriers` __shared__ barrier full`[`QSIZE`],` empty`[`QSIZE`];` `// use the largest MMA shape available` `constexpr` `int` WGMMA_M `=` `64,` WGMMA_K `=` `16,` WGMMA_N`=`BN`;` `初始化过程与之前类似:
if` `(`threadIdx`.`x `==` `0)` `{` `for` `(int` i `=` `0;` i `<` QSIZE`;` `++`i`)` `{` `// num_consumers == 1 in this example;` `// 128 threads from consumer wg + 1 producer thread` `init(&`full`[`i`],` num_consumers `*` `128` `+` `1);` `init(&`empty`[`i`],` num_consumers `*` `128` `+` `1);` `}` cde`::fence_proxy_async_shared_cta();` `// same as before` `}` `__syncthreads();` `// same as before` `需要注意两点:
- 我们升级到了更大的张量核心 MMA(从
m64n64k16到m64nBNk16),因为经验表明,这有助于最大限度地提高计算吞吐量。 - 因为队列是多槽的,所以屏障初始化必须遍历所有条目。
主要逻辑如下:
- 在生产者(
wg_idx = 0)中,一个线程负责将 TMA 副本编入队列。它使用empty[qidx].wait()阻塞机制,直到缓冲区槽位空闲,然后cp_async_bulk_tensor_2d_global_to_shared同时发出sA和的请求sB。最后,它使用发出完成信号barrier_arrive_tx,该信号将屏障与副本的字节数关联起来。 - 在消费者端(
wg_idx > 0),所有线程首先将每个队列槽标记为"空"(准备填充)。然后,对于每个K步骤,它们等待full[qidx],对该缓冲区运行张量核心 MMA,完成后,再次将该槽标记为空。
// Producer` `if` `(`wg_idx `==` `0)` `{` `// wg_idx = threadIdx.x / 128` `if` `(`tid `==` `0)` `{` `// only thread 0 issues TMA calls` `int` qidx `=` `0;` `// index into the circular buffer` `for` `(int` block_k_iter `=` `0;` block_k_iter `<` num_blocks_k`;` `++`block_k_iter`,` `++`qidx`)` `{` `if` `(`qidx `==` QSIZE`)` qidx `=` `0;` `// wrap around` `// wait until this buffer is marked empty (ready to be written into)` empty`[`qidx`].wait(`empty`[`qidx`].arrive());` `// copy over chunks from A and B` cde`::cp_async_bulk_tensor_2d_global_to_shared(` `&`sA`[`qidx`*`BK`*`BM`],` tensorMapA`,` block_k_iter`*`BK`,` num_block_m`*`BM`,` full`[`qidx`]);` cde`::cp_async_bulk_tensor_2d_global_to_shared(` `&`sB`[`qidx`*`BK`*`BN`],` tensorMapB`,` block_k_iter`*`BK`,` num_block_n`*`BN`,` full`[`qidx`]);` `// mark barrier with the expected byte count (non-blocking)` barrier`::`arrival_token _ `=` cuda`::`device`::barrier_arrive_tx(` full`[`qidx`],` `1,` `(`BK`*`BN`+`BK`*`BM`)*sizeof(`bf16`));` `}` `}` `}` `else` `{` `// Consumer warp-group` `for` `(int` i `=` `0;` i `<` QSIZE`;` `++`i`)` `{` `// i initially, all buffers are considered empty; ready for write` `// all 128 consumer threads arrive on each barrier` barrier`::`arrival_token _ `=` empty`[`i`].arrive();` `}` `// distributed accumulator registers, zero-initialized` `float` d`[`BM`/`WGMMA_M`][`WGMMA_N`/16][8];` `memset(`d`,` `0,` `sizeof(`d`));` `int` qidx `=` `0;` `for` `(int` block_k_iter `=` `0;` block_k_iter `<` num_blocks_k`;` `++`block_k_iter`,` `++`qidx`)` `{` `if` `(`qidx `==` QSIZE`)` qidx `=` `0;` `// wrap around` `// wait until TMA has finished filling this buffer` full`[`qidx`].wait(`full`[`qidx`].arrive());` `// core tensor core loop` `warpgroup_arrive();` `// convenience wrapper around the PTX boilerplate` `#pragma` `unroll // compiler hint (we saw this in PTX/SASS section)` `// submit as many tensor core ops as needed to compute sA @ sB (see drawing)` `for` `(int` m_it `=` `0;` m_it `<` BM`/`WGMMA_M`;` `++`m_it`)` `{` bf16 `*`wgmma_sA `=` sA `+` qidx`*`BK`*`BM `+` BK`*`m_it`*`WGMMA_M`;` `#pragma` `unroll` `for` `(int` k_it `=` `0;` k_it `<` BK`/`WGMMA_K`;` `++`k_it`)` `{` `wgmma<WGMMA_N,` `1,` `1,` `1,` `0,` `0>(` d`[`m_it`],` `&`wgmma_sA`[`k_it`*`WGMMA_K`],` `&`sB`[`qidx`*`BK`*`BN `+` k_it`*`WGMMA_K`]);` `}` `}` `warpgroup_commit_batch();` `warpgroup_wait<0>();` `// all 128 consumer threads mark buffer as consumed so producer can reuse it` barrier`::`arrival_token _ `=` empty`[`qidx`].arrive();` `}` `// finally: write accumulator d back to output matrix C` `}` `可视化效果应该能更清晰地展现出来:
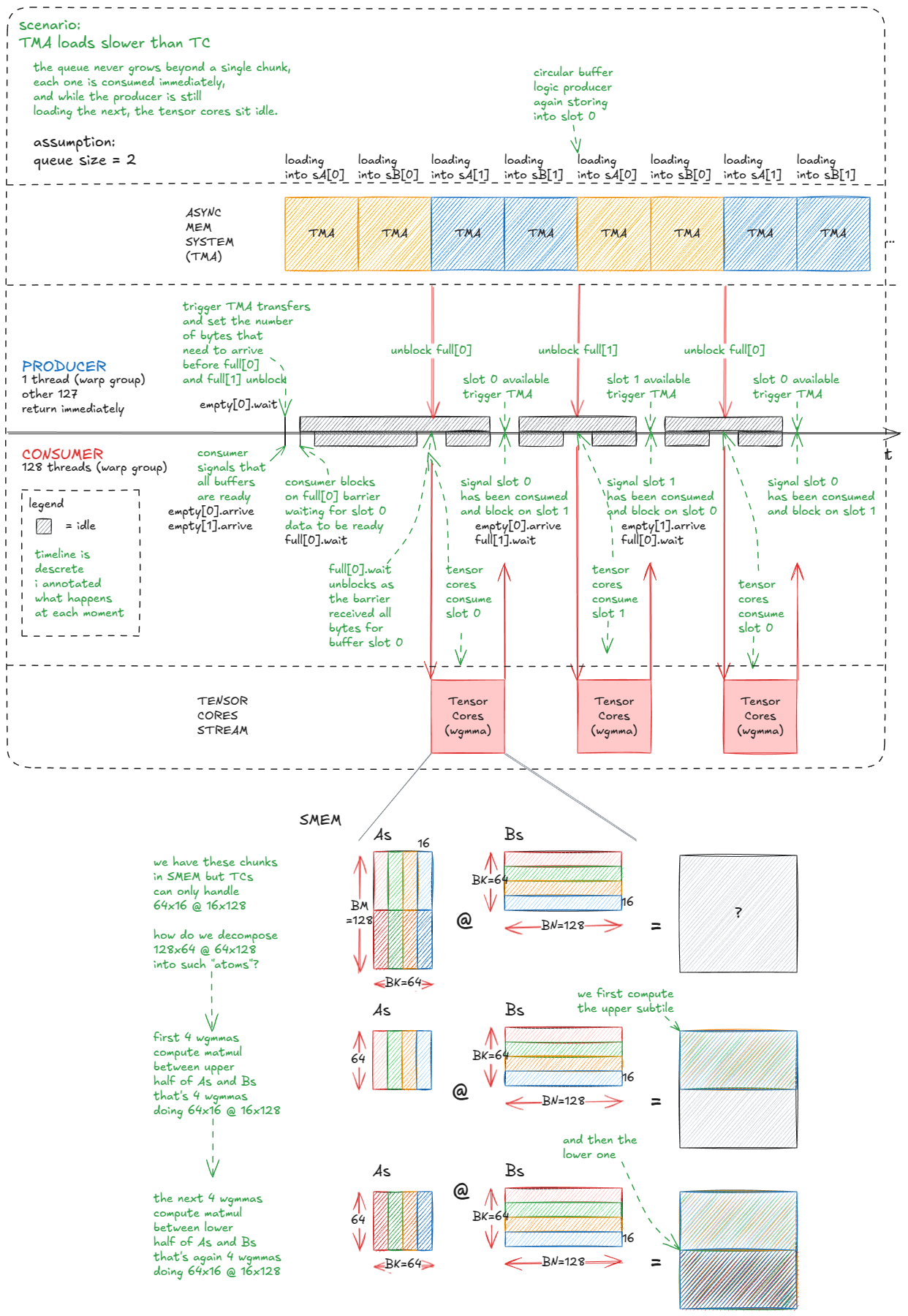
图 41:更高效的 TC/TMA 流水线:生产者 warp-group 将 tile 流式传输到循环缓冲区;消费者 warp-group 将 tile 排入张量核心。
一个很自然的调整是将输出图块从 128×128 增加到 128×256。但问题是,在这种大小下,单个消费者 warp 组中每个线程的累加器分片会变得太大------每个线程仅累加器就需要 256 个 fp32 寄存器,这远远超出了每个线程的寄存器预算(并引发寄存器溢出到设备内存------这对性能非常不利)。
解决方法是添加另一个消费者线程束组,这样累加器就可以跨两个线程束组而不是一个线程束组进行分片。我们保留一个生产者(用于驱动 TMA),并使用 3×128 = 384 个线程启动区块/CTA:
- WG0:生产者(TMA)
- WG1:消费者 A(计算 128×256 图块的上半部分)
- WG2:消费者 B(计算下半部分)
每个消费者拥有输出的 64×256 半块,因此每个线程的累加器占用空间减半,避免溢出。
以下是 matmul 运算的执行方式:
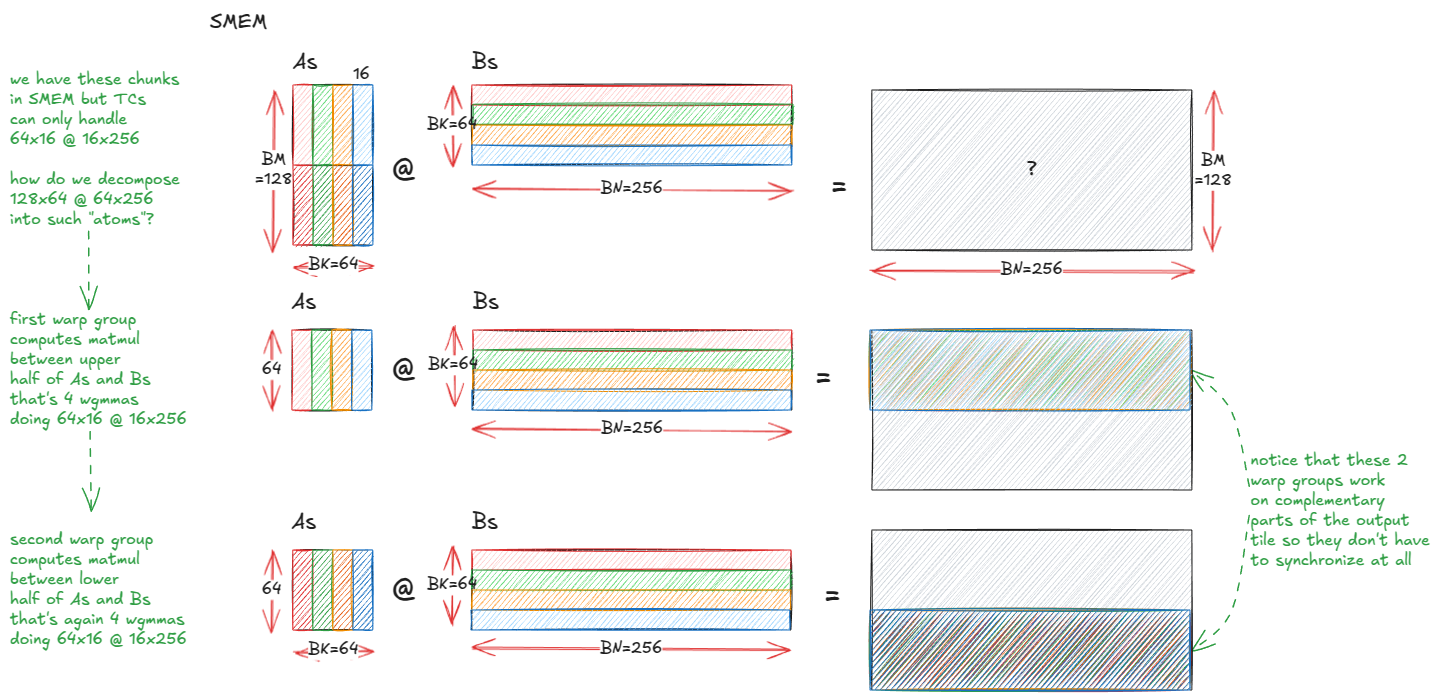
图 42:两个消费者线程组允许我们将图块从 128x128 扩展到 128x256,而不会发生寄存器溢出。
下一个重要的想法是,我们也可以隐藏写入输出图块的延迟:
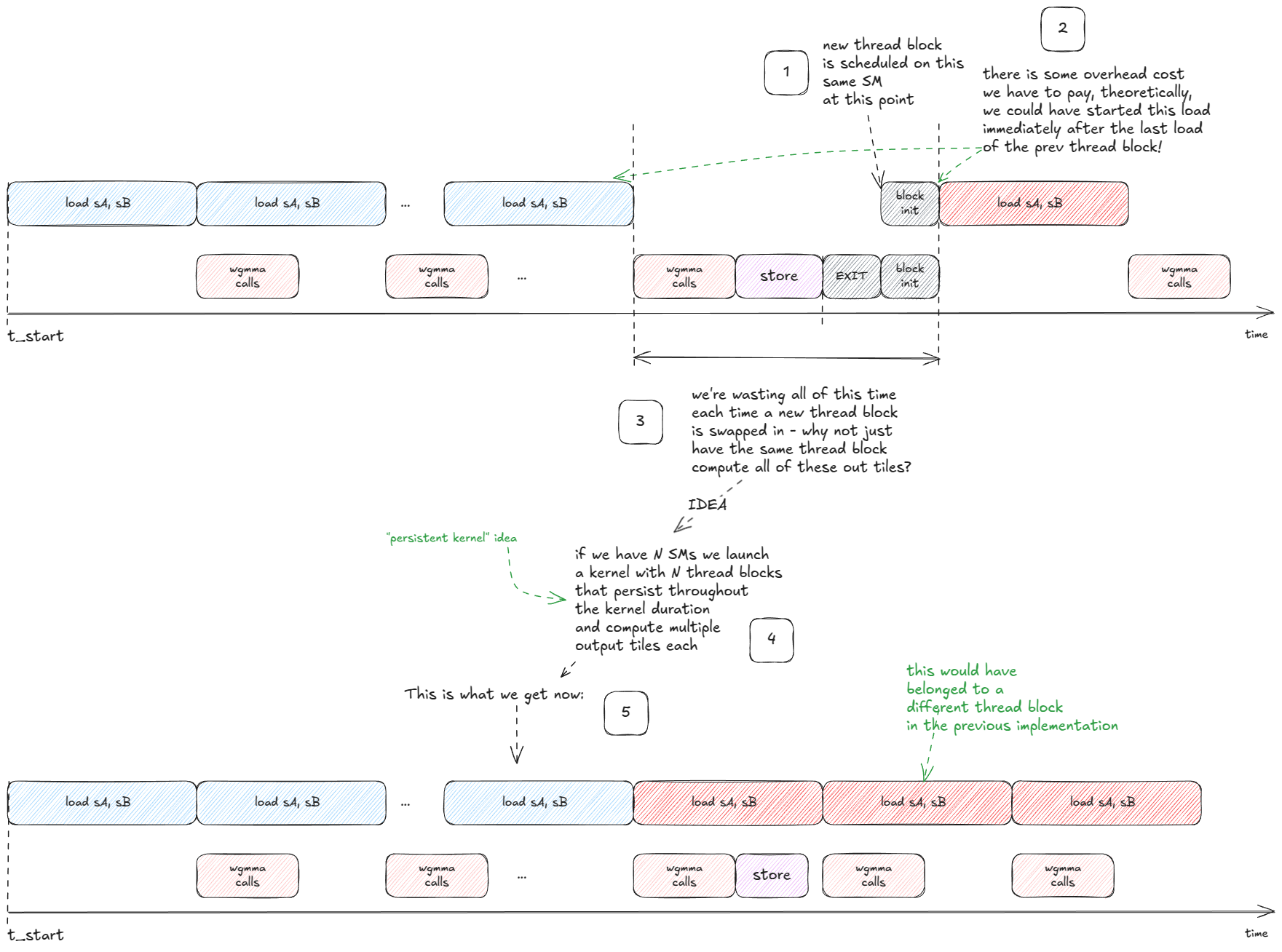
图 43:持久内核:通过为每个 SM 启动一个处理多个图块的长期存在的块,将输出存储与传入的加载重叠。
💡持久内核
持久内核会启动少量固定数量的线程块(通常每个SM一个),并让这些线程块在整个工作负载期间保持运行。与为每个瓦片启动一个线程块不同,每个线程块运行一个内部循环,从队列中取出新的瓦片,直到工作完成。
这就引出了一个自然的问题:每个SM应该处理输出图块的哪个子集,以及处理顺序是什么?
这种排班策略是怎样的?
让我们先从一个简单的模型开始,来探讨各种方案:
- 输出图块总数:64。
- SM数量:10。
- 因此,每个SM平均需要处理约6.4个数据块。
第一次尝试可能如下所示:
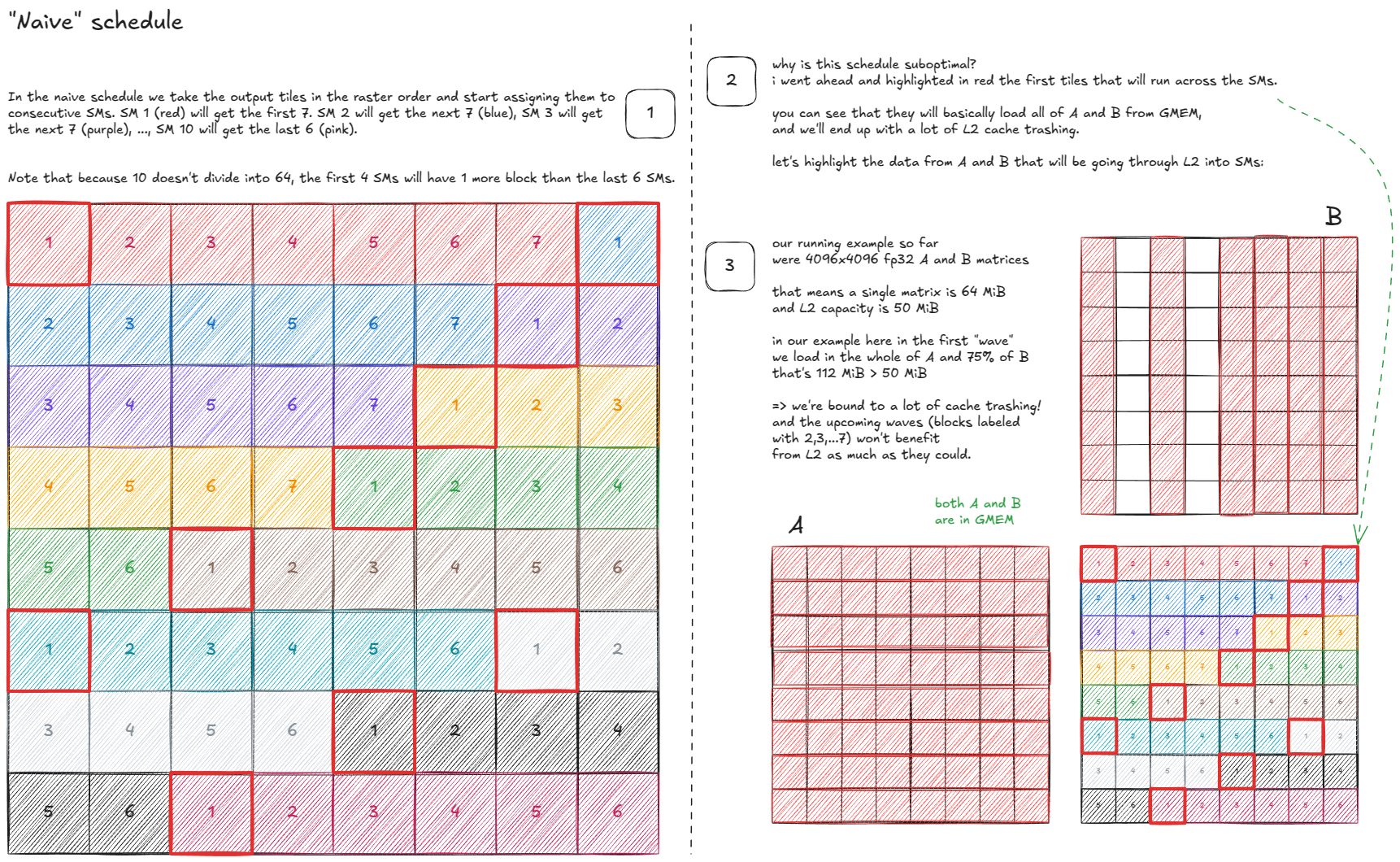
图 44:朴素时间表
我们还能做得更好吗?可以------通过让调度程序能够感知缓存:
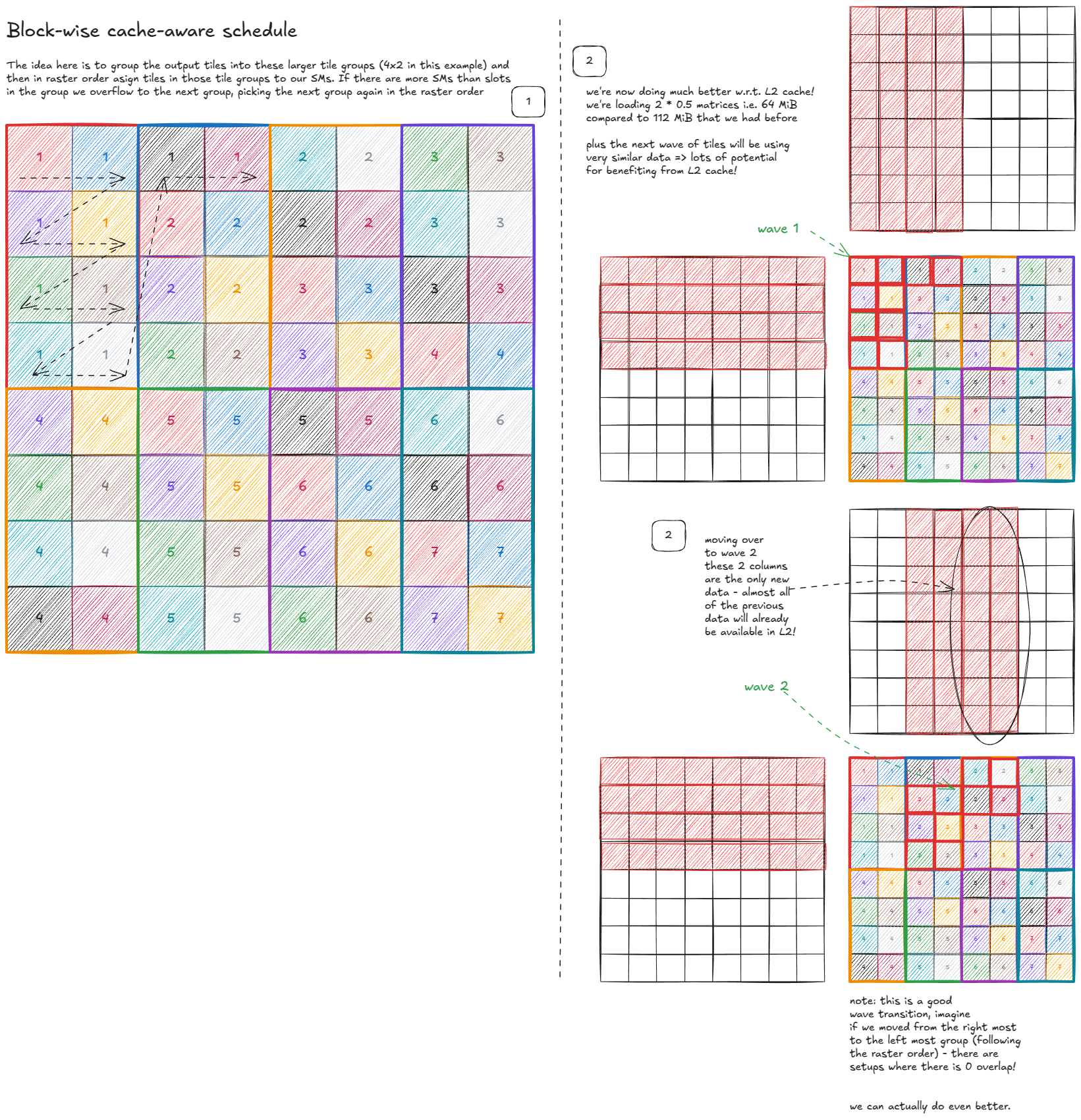
图 45:分块缓存感知调度
但我们还能做得更好吗?令人惊讶的是,答案是肯定的------通过使用空间填充曲线:
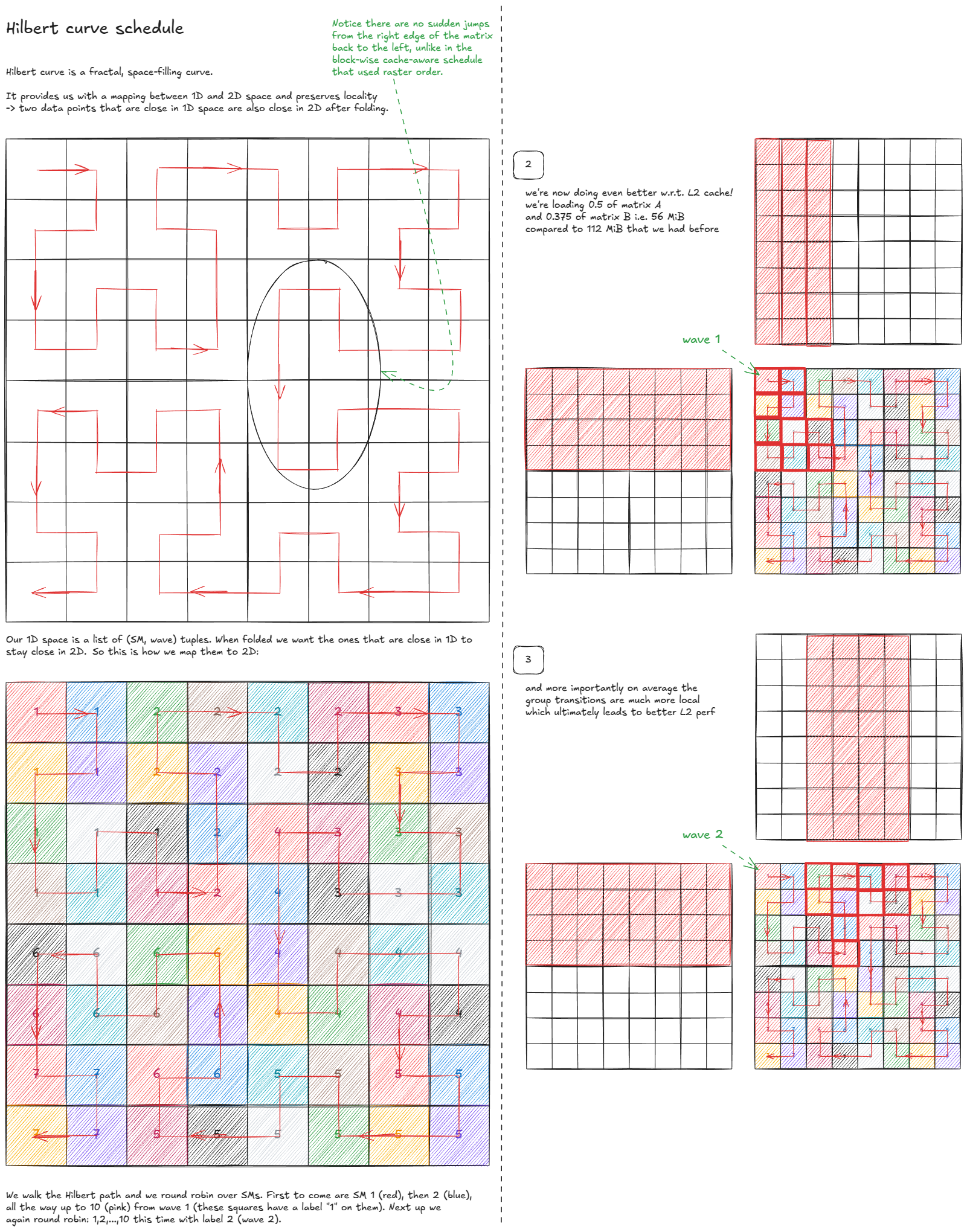
图 46:希尔伯特曲线调度
最后,我要深入探讨的是利用 Hopper 新的集群级 CUDA 执行模型来减少 L2/GMEM 流量:
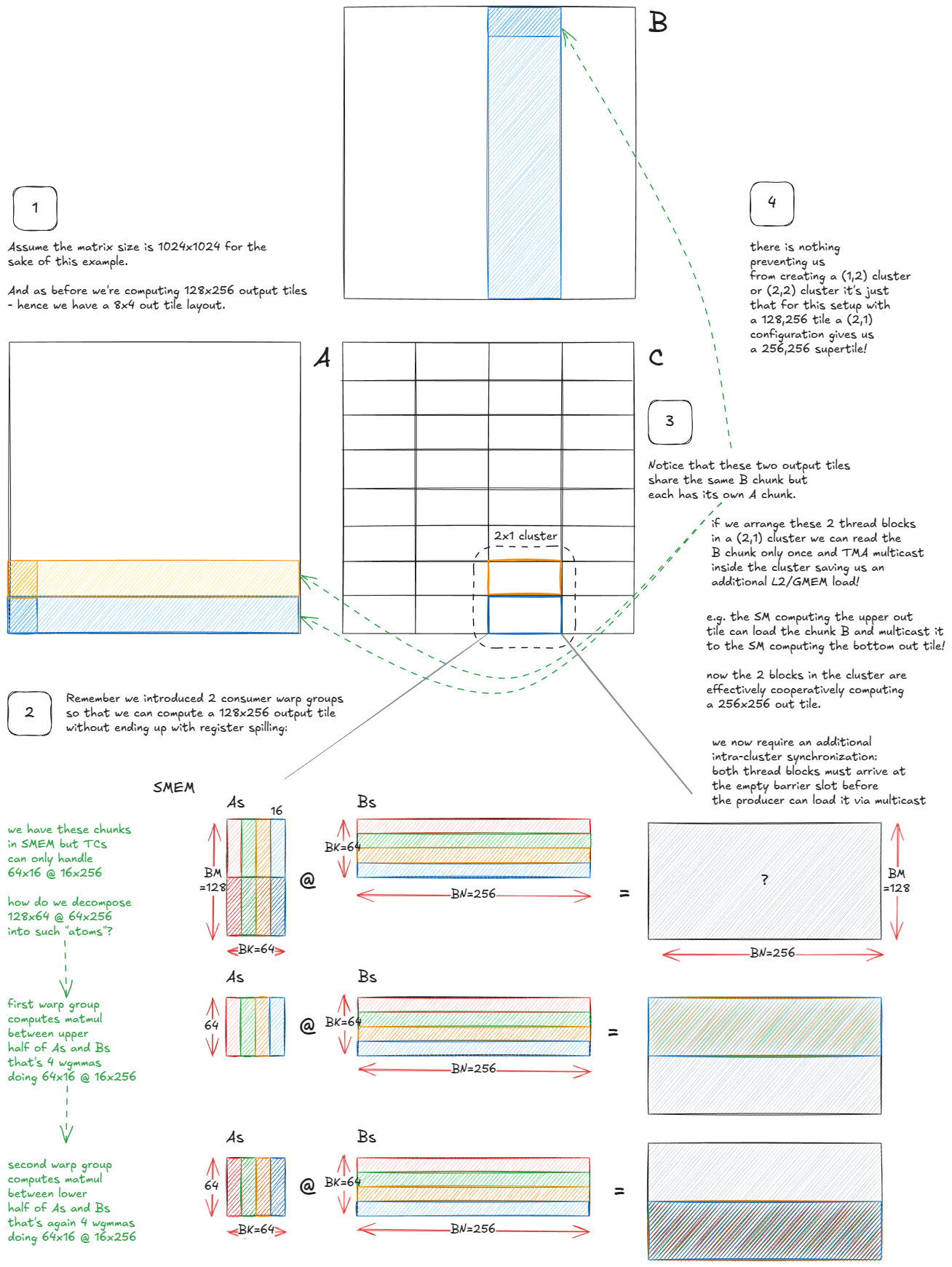
图 47:使用线程块簇来减少 L2/GMEM 加载次数。
关键的观察结果是,集群内的多个SM可以直接共享它们的SMEM(通过DSMEM),这使我们能够将集群视为一种"超级SM"。
从调度角度来看,并没有根本性的变化:不再是每个SM各自独立处理输出块,而是整个集群协作处理一个更大的"超级块"。算法的运行机制保持不变,但现在这些SM需要协调负载并重用彼此的数据。
由于希尔伯特曲线遍历的设计初衷就是为了最大化局部性,因此超级标准模型可以遵循相同的遍历模式------只是粒度更粗一些。
最后,为了绕过cuBLAS,我们必须加强同步本身。到目前为止,我们在屏障上的到达/等待调用方面存在浪费。
例如,消费者线程实际上不需要发出到达信号full[qidx]。唯一重要的条件是"所有字节都已到达"。丢弃这些冗余的到达信号每次迭代可以节省 256 个令牌。类似地,对于empty[qidx]:一旦消费者tid==0到达,生产者就可以安全地开始填充,因为消费者端(wgmma)在所有线程中同步执行。
一些额外的、更底层的技巧,在实践中也能发挥作用(遵循 O(NR) 原则):
- 重新平衡寄存器:用于
asm volatile("setmaxnreg.{inc,dec}.sync.aligned.u32 %0;\n" : : "n"(RegCount));将寄存器预算从生产者线程组(轻量级)转移到消费者线程组(在 wgmma 期间的重度用户)。 - 避免在出站时污染缓存。要么
__stwt绕过 L1/L2 缓存,要么更好的办法是进行异步存储:先将数据溢出到 SMEM,然后让 TMA 异步复制到 GMEM。这样就实现了写回和计算的重叠,就像我们在输入端所做的那样。 - 跳过冗余初始化:不要将累加器寄存器清零,而是调整张量核心序列,使第一个 MMA 执行
C = A @ B,后续 MMA 执行C = A @ B + C。
作为参考,以下是性能数据(来自 Pranjal 的博客),显示了每个想法相对于前一个想法的性能提升情况:
| 优化 | 穿孔前性能(TFLOP/s) | 性能(TFLOP/s) |
|---|---|---|
| 基线(扭曲平铺)→ 张量核心 + TMA | 32 | 317 |
| 增大输出瓦片尺寸 | 317 | 423 |
| 管道:将 TMA 负载与 TC 计算重叠 | 423 | 498 |
| 图块扩展:128×128 → 128×256(2 个消费者传送组) | 498 | 610 |
| 持久内核(隐藏存储延迟) | 610 | 660 |
| 更快的PTX屏障 | 660 | 704 |
| 集群;TMA 多播 | 704 | 734 |
| 微优化 | 734 | 747 |
| TMA 异步存储(regs → SMEM → GMEM) | 747 | 758 |
| 希尔伯特曲线调度 | 758 | 764 |
此外,Aroun 提交了一个PR,使用该方法优化了异步存储stmatrix,性能又提升了 1%。一些核反应堆因此幸免于难。
结语
我们首先对GPU本身进行了剖析,重点关注其内存层次结构------构建GMEM、SMEM和L1的思维模型,然后将它们与CUDA编程模型联系起来。在此过程中,我们也研究了"光速"及其受功耗限制的情况------硬件的实际情况也渗透到了我们的模型中。
从那以后,我们向上学习:学习如何通过 PTX/SASS 与硬件通信,以及如何引导编译器生成我们真正想要的东西。
我们一路学习了一些关键概念------瓦片和波的量化、占用率、整数线性规划、屋顶线模型------并围绕基本等价性建立了直觉:点积可以表示为部分外积之和,或者表示为点积的部分和,以及为什么正方形瓦片会产生更高的算术强度。
在此基础上,我们构建了一个接近最先进的内核(warp tiling),仅使用 CUDA 核心、寄存器和共享内存就榨取了性能。
最后,我们进入了 Hopper 的世界:TMA、交换、张量核心和指令wgmma、异步加载/存储流水线、希尔伯特曲线等调度策略、具有 TMA 多播的集群、更快的 PTX 屏障等等。
最后,我想重申贯穿整个系列文章的一个信念:计算机是可以理解的。
参考资料
- Inside NVIDIA GPUs: Anatomy of high performance matmul kernels
- NVIDIA Hopper架构深度解析https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/
- NVIDIA Ampere架构深度解析https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/
- 奇怪的是,在GPU上进行矩阵乘法运算,如果数据"可预测",运行速度反而更快!短文 https://www.thonking.ai/p/strangely-matrix-multiplications
- CUDA编程工作原理https://www.nvidia.com/en-us/on-demand/session/gtcfall22-a41101/
- 关于英伟达GPU共享内存库的说明https://feldmann.nyc/blog/smem-microbenchmarks
- CUDA 二进制工具https://docs.nvidia.com/cuda/cuda-binary-utilities/index.html
- 第37讲:SASS和GPU微架构简介https://www.youtube.com/watch?v=we3i5VuoPWk
- 通过微基准测试剖析NVIDIA Volta GPU架构https://arxiv.org/abs/1804.06826
- 如何优化 CUDA Matmul 内核以达到类似 cuBLAS 的性能:工作日志https://siboehm.com/articles/22/CUDA-MMM
- CUDA C 编程指南https://docs.nvidia.com/cuda/cuda-c-programming-guide/
- 第 44 讲:NVIDIA 分析https://www.youtube.com/watch?v=F_BazucyCMw&ab_channel=GPUMODE
- https://github.com/siboehm/SGEMM_CUDA/
- CUTLASS:CUDA C++ 中的快速线性代数https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/
- CUDA 中的高效 GEMM https://github.com/NVIDIA/cutlass/blob/b0e09d7cd371eded41f7c1e057caf1593c27ba55/media/docs/efficient_gemm.md
- 在 H100 上超越 cuBLAS:工作日志https://cudaforfun.substack.com/p/outperforming-cublas-on-h100-a-worklog
- 深入探究 CUTLASS Ping-Pong GEMM 内核https://pytorch.org/blog/cutlass-ping-pong-gemm-kernel/
- https://github.com/pranjalssh/fast.cu/
- 理解 CuTe Swizzling------32B、64B 和 128B 模式背后的数学原理https://veitner.bearblog.dev/understanding-cute-swizzling-the-math-behind-32b-64b-and-128b-patterns/
- 并行线程执行https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
- CUDA 中的内联 PTX 汇编https://docs.nvidia.com/cuda/inline-ptx-assembly/
- 揭秘实时系统高带宽内存的特性https://upcommons.upc.edu/server/api/core/bitstreams/b843de39-f32f-4069-8843-48f74c030213/content
- https://github.com/triton-lang/triton