背景
目标
比较DDPG、PPO、SAC算法
实验结果展示:
|-----------|----|--------------------|---------------|
| 算法 | 在线 | 收敛速度(连续环境) | 收敛速度(离散环境) |
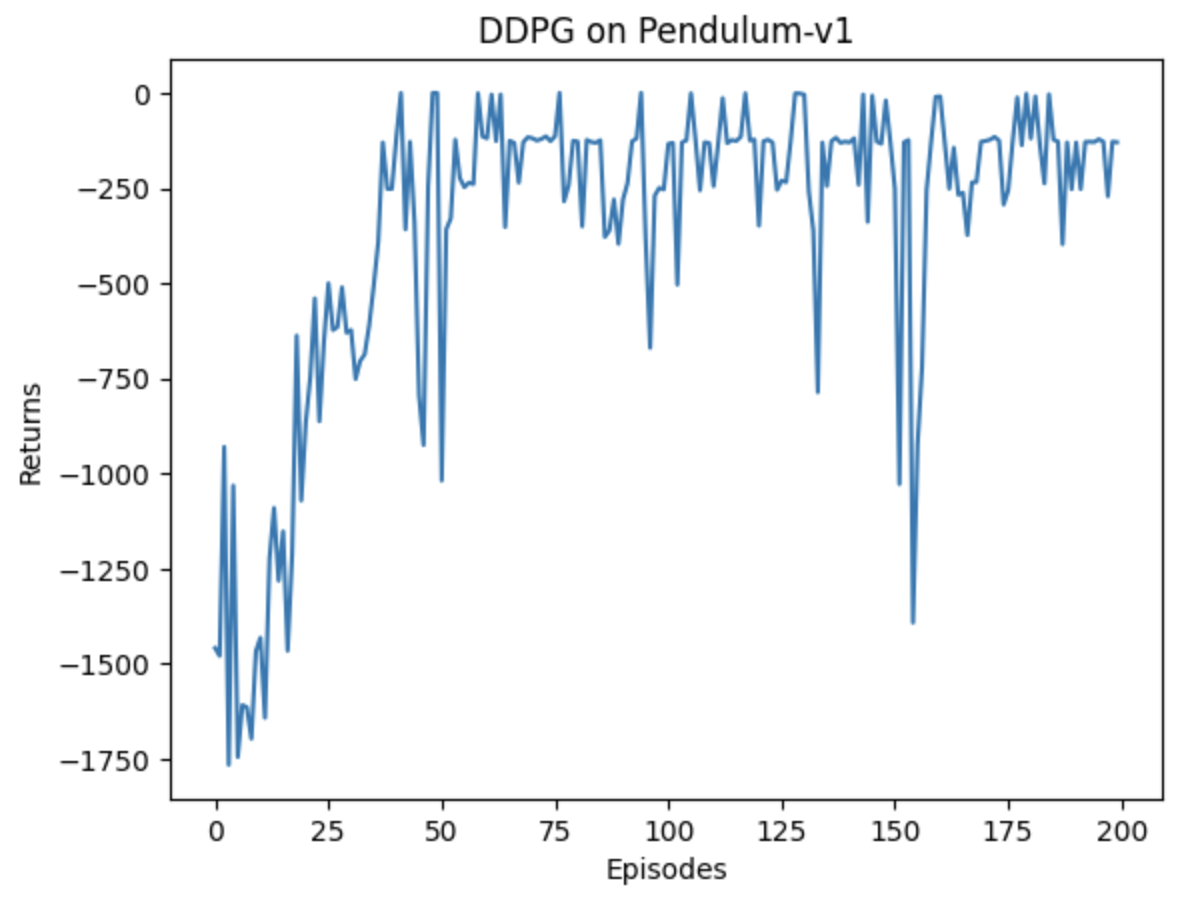
| DDPG | 否 | 100/200圈、100s、抖动大 | - |
| PPO | 是 | 1500/2000圈、120s、平稳 | 150/200、平稳 |
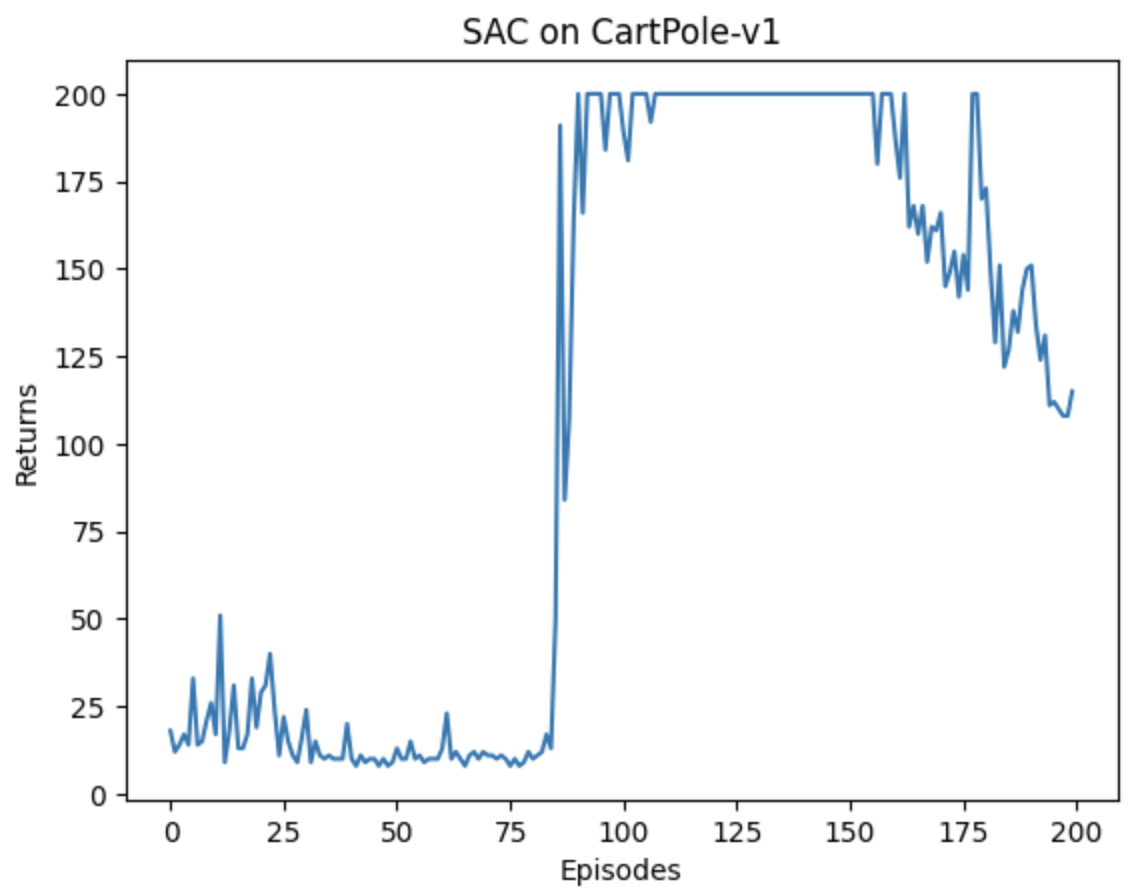
| SAC | 否 | 60/100圈、100s、平稳 | 150/200、抖动大 |
| AC | 是 | - | 600/1000、抖动较大 |
| Reinforce | 是 | - | 800/1000、抖动大 |
算法提出背景与特点
|------------|----|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 算法 | 在线 | 特点/背景 |
| Reinforce | 是 | 相较于Q-learning,直接显式地学习一个目标策略。 优点: ① 直接:优化的目标(即策略期望回报)正是最终所使用策略的性能,这比基于价值的强化学习算法的优化目标(一般是时序差分误差的最小化)要更加直接。 ② 无偏: REINFORCE 算法理论上是能保证局部最优的,它实际上是借助蒙特卡洛方法采样轨迹来估计动作价值,这种做法的一大优点是可以得到无偏的梯度。 缺点: ① 方差大: 因为使用了蒙特卡洛方法,REINFORCE 算法的梯度估计的方差很大,可能会造成一定程度上的不稳定,这也是 Actor-Critic 算法要解决的问题。 |
| DDPG(TD3) | 否 | Actor-Critic算法大部分是在线算法,样本效率比较低,DDPG结合AC+DQN思想进行离线学习。 优点:引入了目标网络和软更新的方法,这对深度模型构建的价值网络和策略网络的稳定学习起到了关键的作用。DDPG 算法也被引入了多智能体强化学习领域,催生了 MADDPG 算法。 缺点:本质仍是确定性策略,需依赖外部噪声(如高斯噪声)实现探索,未从算法层面解决探索与利用的平衡问题。 |
| AC | 是 | 基于值函数的方法和基于策略的方法的叠加。 价值模块 Critic 在策略模块 Actor 采样的数据中学习分辨什么是好的动作,什么不是好的动作,进而指导 Actor 进行策略更新。 随着 Actor 的训练的进行,其与环境交互所产生的数据分布也发生改变,这需要 Critic 尽快适应新的数据分布并给出好的判别。 |
| TRPO / PPO | 是 | 基于策略的方法包括策略梯度算法和 Actor-Critic 算法。这些方法虽然简单、直观,但在实际应用过程中会遇到训练不稳定的情况。明显的缺点:当策略网络是深度模型时,沿着策略梯度更新参数,很有可能由于步长太长,策略突然显著变差,进而影响训练效果。 信任区域策略优化(trust region policy optimization,TRPO)它在理论上能够保证策略学习的性能单调性,并在实际应用中取得了比策略梯度算法更好的效果。 直觉性地理解,TRPO 给出的观点是:由于策略的改变导致数据分布的改变,这大大影响深度模型实现的策略网络的学习效果,所以通过划定一个可信任的策略学习区域,保证策略学习的稳定性和有效性。 TRPO计算过程非常复杂,每一步更新的运算量非常大。于是,TRPO 算法的改进版------PPO 算法在 2017 年被提出,PPO 基于 TRPO 的思想,但是其算法实现更加简单。并且大量的实验结果表明,与 TRPO 相比,PPO 能学习得一样好(甚至更快),这使得 PPO 成为非常流行的强化学习算法。如果我们想要尝试在一个新的环境中使用强化学习算法,那么 PPO 就属于可以首先尝试的算法。 |
| SAC | 否 | 之前的章节提到过在线策略算法的采样效率比较低,我们通常更倾向于使用离线策略算法。然而,虽然 DDPG 是离线策略算法,但是它的训练非常不稳定,收敛性较差,对超参数比较敏感,也难以适应不同的复杂环境。2018 年,一个更加稳定的离线策略算法 Soft Actor-Critic(SAC)被提出。SAC属于最大熵强化学习的范畴。 目前,在无模型的强化学习算法中,SAC 是一个非常高效的算法,它学习一个随机性策略,在不少标准环境中取得了领先的成绩。 优点:有扎实的理论基础和优秀的实验性能,SAC 算法已经成为炙手可热的深度强化学习算法,很多新的研究基于 SAC 算法,第 17 章将要介绍的基于模型的强化学习算法 MBPO 和第 18 章将要介绍的离线强化学习算法 CQL 就是以 SAC 作为基本模块构建的。 |
| | | |
算法实现关键
|------------|----|---------------------------------------------------------------------------------------------------------------------------------------|
| 算法 | 在线 | 算法要点 |
| Reinforce | 是 | ① 蒙特卡鲁采样 ② loss=概率*收益,模型收敛慢波动大。 |
| DDPG(TD3) | 否 | ① TD算法、基于均方误差训练Q网络 ② 链式求导:actor_loss = -torch.mean(self.critic(states, self.actor(states))) ③ 策略模型:添加噪声 ④ 价值模型:使用目标网络计算Q的目标 ⑤ 目标网络然更新 |
| AC | 是 | ① TD算法、基于均方误差训练V网络 ② 引入优势加权:actor_loss = torch.mean(-log_probs * td_delta.detach()) |
| TRPO / PPO | 是 | ① 引入置信 |
| SAC | 否 | ① 引入熵 |
| | | |
附录:
SAC算法缺陷:离散环境尾部崩溃
DDPG算法缺陷:连续环境收敛效果不佳