
如果你在 PDF 解析里,哪怕只走过一次内容流路线,大概率都会在某个时刻和 pdfminer 正面相遇。不是因为它多完美,而是因为它几乎定义了一个事实:
只要你想从 PDF 的内容流里"读文本",就绕不开"文本布局计算"这件事。
而 pdfminer(pdfplumber直接依赖pdfminer的实现,所以是同一个算法),正是最经典、也最容易被误解的一种实现。
先说清一个前提:PDF 里根本没有"文本"
这一点,pdfminer 官方文档说得其实非常直白,只是很多人第一次读的时候没意识到它有多重要:
PDF 文件中,并不存在段落、句子,甚至不存在"词"。
PDF 只知道三件事:
- 画什么字(glyph)
- 在哪画(坐标)
- 用什么方式画(变换矩阵、字体)
"文本"是你后来推断出来的,不是 PDF 给你的。 也正因为如此:
- 正文、表格、页脚、图注,在内容流层面没有任何本质区别
- 对 PDF 来说,它们都是:一堆被画在页面某个位置的字符
这也是为什么:
文本布局计算,本质上是一种"逆向工程"。
如果你把 pdfminer 的文本布局算法压缩成一句话,它做的是:
用字符的几何关系,猜人类是怎么把这些字"读成一段话"的。
这不是语言问题,是一个纯几何 + 经验规则的问题。
pdfminer 的整体布局分析流程
pdfminer 的布局分析分成三个阶段(官方叫 Layout Analysis):
- 字符 → 行(TextLine)
- 行 → 文本框(TextBox)
- 文本框 → 层级结构(TextBox Hierarchy)
最终输出的是一个有序的布局对象树。
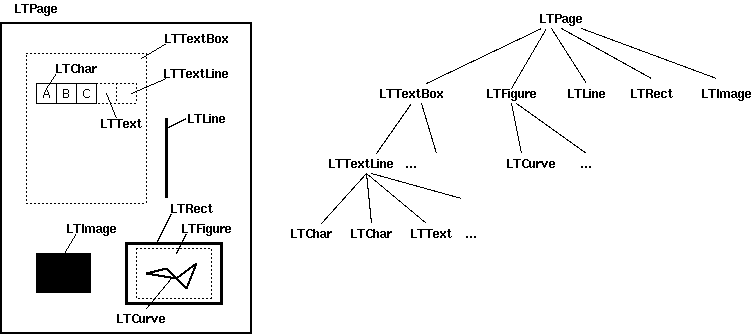
图:pdfminer的有序对象树
注意:这里的"有序",并不是阅读顺序保证,而只是算法生成顺序。
第一阶段:字符是怎么被拼成"行"的
这是 pdfminer 最核心、也是后面所有问题的起点。
从一开始,输入是一堆 LTChar,每个字符都有其BBox。pdfminer 完全基于这些 bbox 来做判断。
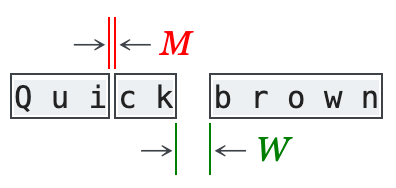
图:字符行内聚合示意(M 为 char_margin, W为word_margin)
什么时候两个字符被认为在"同一行"?
pdfminer 用了两个关键参数:
char_marginline_overlap
规则是:
- 水平距离足够近
- 垂直方向有足够重叠
更具体一点:
- 两个字符 bbox 之间的水平间距 小于
char_margin × max(char_width) - 两个字符 bbox 的垂直重叠高度 大于
line_overlap × min(char_height)
这里有一个非常重要但容易被忽略的点:
所有阈值,都是相对值,不是绝对像素。
这让算法对字体大小有一定自适应性,但也引入了不稳定性。
PDF 里没有"空格",那空格是怎么来的?
这是内容流文本解析里最容易被误解的一点。
PDF 并没有"空格字符"的语义。(但是确实有可能会画空白字符)
pdfminer 插入空格的规则是:
- 如果两个字符在同一行
- 但它们的水平间距 大于
word_margin × max(char_width / char_height) - 那就人为插入一个空格
这一步产生的是 LTAnno(" "),而不是原始字符。
这一阶段的结果是一组 LTTextLine,每一行是字符 + 插入的空格;行尾会插入一个换行符。每一行的 bbox,是该行内所有字符 bbox 的并集。
注意:此时的"行",只是几何上的行,不是语义上的句子。
第二阶段:行是怎么被拼成 TextBox 的
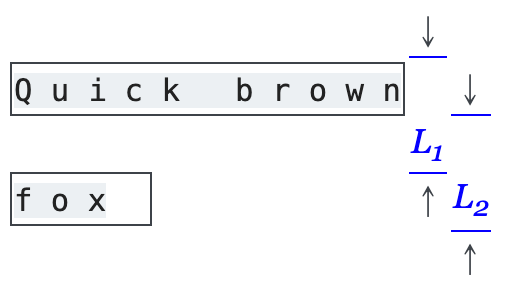
图:行到 TextBox 的合并示意
字符成行之后,pdfminer 要解决的问题变成了:
哪些行,属于同一个"文本块"?
行如何被合并成 TextBox?
pdfminer 的规则依然是几何启发式:
- 水平方向有重叠
- 垂直方向足够接近
关键参数是:
line_margin
判断方式是:
- 相邻两行 bbox 之间的上下间距
- 小于
line_margin × 行高
满足条件的行,会被合并到同一个 TextBox。
是
否
Line_1 bbox
与下一行水平重叠且
垂直间距 < line_margin * line_height ?
Line_2 bbox
归入同一 TextBox
merge lines
新建 TextBox
start new box
继续比较下一行
到此为止,会得到一组 TextBox,每个 TextBox包含若干行,完全不理解:段落、列表、标题、语义结构。
第三阶段:TextBox 的层级合并
这是 pdfminer 最"玄学"的一层,pdfminer会不断找 "最近的两个 TextBox",把它们合并。

图:TextBox 间距离计算(蓝色区域)
"近"是怎么定义的?
直到无法合并/满足条件
TextBox 集合
计算两两距离
(包围矩形面积 - 各自面积)
选择距离最小的一对
(Box_a, Box_b)
合并为父节点
new group node
输出层级结构
Hierarchy
- 计算两个 TextBox 的包围矩形
- 用:
- 包围矩形面积
- 减去两个 TextBox 自身面积
- 得到一个"空白面积"
- 空白越小 → 越近
这一步的目标是:
构建一个层级结构,用于"阅读顺序"的一种近似表达。
但请注意:
这不是阅读顺序算法,只是空间聚类。
这里随便找了篇英文论文,用pdfminer的默认布局参数画了下文本布局分析结果:

图:pdfminer提取文本和分析结果示例
图中第二部分是提取出来的字符和bbox,第三部分是布局分析出来的LTTextLine,第四部分是布局分析出来的LTTextBox。
可以看到,还是有一些不尽如人意的地方的,但起码在这个文档上,整体还是基本可用。
pdfminer 的参数,为什么"调了也不一定有用"
所有这些布局分析规则,都由 LAParams 控制:
char_marginword_marginline_overlapline_margindetect_vertical
这些参数确实能影响结果,但它们有一个共同的问题:
它们在"边界情况"上,几乎必然失效。
现实问题一:空格插入是最大的不稳定源
这是我在工程中见过影响文本质量最大的问题。pdfminer 的逻辑是:
"如果字符间距大于经验阈值,那大概是一个词间空格。"
但现实中:
- 原文本可能本来就包含空白字符
- 字间距本身可能就比较大(论文、公式、等宽字体)
- 英文、数字、公式混排时尤为明显
结果就是,在一些文档中会出现:
- 每个字符之间都被插了空格
- 或者连续多个空格
我的工程改进思路
第一层:去重
- 把连续多个空格合并为一个
- 不把"空白字符"当作普通字符再参与空格推断
第二层:降低插入空格的主动性
- 把
word_margin设得更大一点 - 尽量减少"猜出来的空格"
我的经验是:
在论文、技术文档中, 更应该相信原文自带的空白,而不是算法猜的。
现实问题二:上下行之间只插一个 \n,语义非常差
pdfminer 在行与行之间的处理非常简单:
直接插一个换行符
\n。
这在很多场景下效果很糟:
- 英文段落被拆成碎行
- 中英文混排时断句非常奇怪
- RAG 下游效果明显受损
我的经验算法(非常好用)
在把 TextBox 转成最终文本时:
- 对每一行:
strip()首尾空白 - 比较:
- 上一行最后一个字符
- 下一行第一个字符
- 规则:
- 只要有中文字符→ 直接拼接,不加空格
- 否则→ 插一个空格
这条规则在绝大多数中英混排文档中,效果异常稳定。
现实问题三:TextBox 合并得太"贪心"
pdfminer 的 TextBox 合并逻辑,只看几何关系,不看形状,也不看语义。这会导致:
- 列表项被合成一整段
- 明显的段落分隔被吞掉
- 标题 + 正文被硬合
我的处理方式
在 pdfminer 生成 TextBox 之后,我通常会:
- 再做一次 TextBox 拆分
- 判断:
- 行宽变化
- 首行缩进
- 是否符合常见列表头(如
1.、-、•) - 段落"形状"是否合理
目标只有一个:
让 TextBox 更像"人类理解的段落"。
实际的算法异常复杂,不适合在博客中说,这里只提一下思路。
现实问题四:字符是"连续画"的,但 pdfminer 没告诉你
这是 pdfminer 架构上的一个天然限制。
它只暴露了:
- 单个字符
- 单个字符 bbox
但在 PDF 内容流里:
字符往往是"连续画"的。
这一信息,对判断:
- 竖排文本
- 装饰性文本
- 水印
- 特殊排版
极其有价值。
推荐一个替代库:playa
如果你需要更底层的控制,我非常推荐playa。
https://github.com/dhdaines/playa
它提供了 TextObject 概念:
- 能感知连续画字
- 能暴露更多绘制上下文
- 更适合做高级内容流分析
这一步,会直接打开很多原本"做不了"的能力,比如:
- 更可靠的竖排检测
- 更精细的字符级过滤
同一页pdf,我们用playa进行提取:

图:playa和pdfminer的提取结果对比
第二部分仍然是pdfminer的LTChar,第三部分是playa的TextObject的内容和bbox位置。第4部分是TextObject迭代到字符级别的结果。
可以看到,playa的TextObject对象本身的结果就已经接近布局分析后的文本行的结果了。甚至在竖排文本那里,直接给出了正确的文本行内容和正确的方向。这对于解析结果是一个重大的参考。
实际上,我目前已经完全切到了playa库,其提供pdfminer兼容的功能,同时提供很多高级能力,能够更精细的读取pdf内容。最关键的是,作者十分活跃,提的issue都会在一定时间内解决。你如果看这个库的issue历史,会看到很多我提的issue哦。
小结:pdfminer 不是"错",但它停在了一个很早的时代
写到这里,其实可以对 pdfminer 给一个非常公允的评价:
- 它解决了一个极难的问题
- 在纯内容流世界里
- 用几何启发式,重建了"文本"的假象
但问题也同样清晰:
- 它假设世界是规整的
- 假设字符间距是可信信号
- 假设几何关系 ≈ 语义关系
而真实 PDF 世界,恰恰相反。也正因为如此,在现代 PDF 解析系统里:
pdfminer 更像是一个"基础能力",而不是终极答案。
它给你字符、给你行、给你文本块------但什么时候信它,什么时候绕开它,才是真正的工程能力。
下一章,我们就来聊一个内容流路线中最让人困惑、也最常见的失败形态:
CID 字符。 你明明"读到了字",但就是不知道它是什么。
参考
1 Converting a PDF file to text. pdfminer官方文档; https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html