面向中高级 Java 开发者 / 技术架构师,从核心架构、Java 生态深度适配、工程化落地到生产级避坑策略,系统化掌握 LangChain4j 在企业级 AI 应用体系中的构建方法论与最佳实践。
- 深度掌握 LangChain4j 核心组件架构、底层原理及 Java 生态适配逻辑;
- 具备 LangChain4j 应用的架构设计、工程化开发与性能优化能力;
- 规避生产落地关键风险点,沉淀可复用的 AI 应用工程化方案。
一、什么是LangChain4j
1.1 介绍
LangChain4j 是一款面向 Java 生态的开源大模型应用开发框架,通过标准化 API 抽象层简化大语言模型(LLM,Large Language Model)与 Java 应用的集成链路,提供对主流大语言模型、向量数据库的一站式访问能力。其核心价值在于降低 AI 应用的构建门槛,原生支持检索增强生成(RAG)、工具调用(Tool)、智能代理(Agent)、MCP 协议等核心场景,并与 Spring Boot 等主流企业级 Java 框架无缝融合。
1.2 发展演进
LangChain4j 诞生于 2023 年初 ChatGPT 引发的大模型技术浪潮期。彼时 Python、JavaScript 生态已涌现大量成熟的 LLM 开发库,但 Java 领域存在显著的技术栈空白,LangChain4j 应运而生,填补了 Java 生态在大模型应用开发领域的核心缺口。
社区生态现状
- GitHub Star 数超 10k、Fork 数 1.8k+、Issues 累计 500+,社区贡献者覆盖全球多个地区;
- 迭代节奏稳定,月均发布 1 个正式版本,当前最新稳定版为 1.9.1。
1.3 定位与价值
定位:
- Java 生态原生的大模型应用开发框架,聚焦解决 LLM 与 Java 业务系统的无缝融合问题;
核心价值:
- 降低 Java 体系接入大模型的技术门槛,屏蔽底层模型异构性;
- 提供标准化的 AI 应用构建范式,统一大模型应用开发流程;
- 保障生产场景下的稳定性、可扩展性与可维护性。
1.4 核心功能
LangChain4j 覆盖大模型应用全生命周期核心能力,核心功能体系如下:
- 多模型适配层:原生集成 20+ LLM 提供商、30+ 向量存储、20+ 嵌入模型、5+ 聊天记忆存储、5+ 图像生成模型、5+ 重排序模型及 OpenAI 内容审核模型,支持文本 / 图像多模态输入;
- 核心能力层:
- AI 服务抽象:基于动态代理的声明式 AI Service,简化大模型调用逻辑;
- 智能代理体系:支持 Agentic AI 与多工具协同调用,兼容 MCP 协议;
- 提示工程:原生支持提示词模板、变量注入与资源文件加载;
- 聊天记忆:提供基于消息窗口 / 令牌窗口的内存式 / 持久化聊天记忆实现;
- 流式输出:支持 LLM 响应的流式返回,适配异步非阻塞场景;
- 结构化输出:原生支持 Java 基础类型与自定义 POJO 的输出解析;
- 工具调用:支持静态 / 动态工具(动态执行 LLM 生成代码)调用;
- 检索增强生成(RAG):覆盖完整 RAG 链路(索引 - 检索),支持多源文档导入、多算法文本分割、嵌入与存储;同时提供查询转换、查询路由、结果重排序等高级能力;
- 辅助能力层:文本分类、令牌数估算、Kotlin 协程扩展(实现异步非阻塞交互)。
1.5 技术选型对比
功能对比(2025年12月版本)
| 维度 | LangChain4j | Spring AI |
|---|---|---|
| 版本 | 1.9.1 | 1.1.2 |
| 运行环境 | Java 17、Spring Boot 3.2 | Java 17、Spring Boot 3.4.x and 3.5.x |
| 模型支持 | 对话、向量、图像、重排序、审核 | 对话、向量、图形、音频、审核 |
| 聊天记忆 | ✅支持 | ✅支持 |
| 编程式开发 | Basics API | Chat Client API |
| 声明式注解开发 | Al Services | ❌无 |
| 请求预处理与拦截 | ✅支持 | ✅支持 |
| 函数调用 | ✅支持 | ✅支持 |
| RAG(检索增强生成) | Easy RAG/Naive RAG/Advanced RAG | Naive RAG/Advanced RAG |
| 向量存储 | ✅支持 | ✅支持 |
| 可观测性 | 基础级(日志 + 扩展点) | 企业级丰富度(Spring 生态原生可观测) |
| MCP支持 | 客户端 | 服务端、客户端 |
| 结构化输出 | ✅支持 | ✅支持 |
| 提示词模版 | AI Service 注解原生引用 | 支持但使用体验欠佳 |
| Web Search Engine | Google Custom Search、SearchApi、SearXNG、Tavily、DuckDuckGo 等多引擎适配 | ❌无 |
| Quarkus支持 | ✅支持 | ❌无 |
生态对比
| 维度 | LangChain4j | Spring AI |
|---|---|---|
| 背景与生态 | 开源社区驱动,聚焦 Java 大模型应用落地 | Spring 官方项目,依托 Spring 生态 |
| GitHub Star | 10k+ | 7.4k+ |
| 社区活跃度 | 高(月均迭代,全球贡献者) | 高(Spring 生态加持) |
| 文档质量 | 体系化完善;提供中文版(版本滞后) | 生态化丰富,但结构稍显臃肿 |
| 学习曲线 | 需理解 LangChain 的思想,学习成本稍高 | 无缝集成Spring体系, 学习曲线 更平滑 |
| Spring Boot集成度 | 支持,但集成深度有限 | 天然深度整合 |
性能对比
框架本身性能差异在 10% 以内(Spring AI 略优),可忽略不计;性能瓶颈主要集中在网络传输与模型推理阶段,架构设计需重点关注异步化、批量处理等优化手段。
二、快速开始
2.1 Maven 统一依赖版本管理
LangChain4j 推荐通过 BOM 进行依赖版本统一管理:
xml
<dependencyManagement>
<dependencies>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>1.9.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>2.2 Spring Boot 集成
LangChain4j 针对 Spring Boot 3.2+(Java 17)提供原生集成能力:
- 基于配置属性自动初始化 LLM、嵌入模型、向量存储等核心组件;
- 声明式 AI Service 注解,一键集成 RAG、工具调用等高级能力;
⚠️ 注:本文后续所有示例均基于 Spring Boot 工程实现,贴合实际落地场景。
三、核心组件
3.1 模型集成 - LLM
LangChain4j 通过标准化 API 抽象实现对主流 LLM 的统一适配,屏蔽不同模型的调用差异,支持20+模型:
- 云厂商:AWS / Azure / 阿里云 / 百度 / 腾讯等;
- 开源本地模型:Ollama / LocalAI 等;
- 企业级模型服务:Vertex AI / watsonx.ai 等。
OpenAI集成示例
Maven依赖
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
</dependency>配置模型参数
properties
langchain4j.open-ai.chat-model.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
langchain4j.open-ai.chat-model.api-key=sk-af68278547124h5a808872c6f2d0e20e
langchain4j.open-ai.chat-model.model-name=qwen-max
langchain4j.open-ai.chat-model.log-requests=true
langchain4j.open-ai.chat-model.log-responses=true代码
java
@Autowired
private OpenAiChatModel openAiChatModel;
@Test
public void testChat() {
// 调用对话接口
String answer = openAiChatModel.chat("讲个冷笑话");
System.out.println(answer);
/*
输入:讲个冷笑话
输出:好的,接下来是一个冷笑话:为什么电脑经常生病?因为它的窗户(Windows)总是开着!
*/
}3.2 AI服务 - AI Services
在了解更多特性前,我们要了解 LangChain4j 最重要的开发模式 - AI Service。AI Service是框架中的一个高级API, 通过声明式接口和动态代理技术,将大模型调用、聊天记忆、工具调用等复杂逻辑封装为标准化 Java 方法 ,从而让开发者能更专注于业务逻辑,而不是低级实现细节。
核心对比
| 特性 | AI Service (高级API) | 底层API (如 ChatLanguageModel) |
|---|---|---|
| 使用方式 | 声明式接口,框架基于动态代理自动生成实现类 | 命令式编程,手动管理组件对象 |
| 抽象级别 | 高(屏蔽底层细节) | 低(灵活性最大,样板代码多) |
| 核心价值 | 提升开发效率,适配企业级标准化开发 | 深度定制化场景(如研究 / 非标交互) |
| 适用场景 | 快速构建 AI 功能,适配聊天记忆、工具调用、RAG 等通用场景 | 底层定制、非标准交互流程开发 |
集成示例
Maven依赖
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>定义 AI Service,重写3.1章节中调用对话接口的代码
java
/**
* AI服务 OpenAI模型调用
*
* @author yaorongke
* @since 2025/9/6
*/
@AiService(wiringMode = EXPLICIT, chatModel = "openAiChatModel")
public interface LLMAssistant {
/**
* 对话接口
*
* @param message 问句
* @return 模型返回
*/
String chat(String message);
}调用示例
java
@Autowired
private LLMAssistant llmAssistant;
@Test
public void testAiServiceChat() {
// 调用对话接口
String answer = llmAssistant.chat("用十个字介绍你自己");
System.out.println(answer);
/*
输入:用十个字介绍你自己
输出:我是来自阿里云的超大规模语言模型。
*/
}⚠️ 注:本文后续的样例代码均基于 AI Service 实现。
3.3 流式输出 - Response Streaming
大模型应用中,流式输出是提升用户体验的核心能力之一。LangChain4j 基于 Reactor 框架实现 LLM 响应的流式返回,适配 Spring WebFlux 异步非阻塞场景,支持逐段输出模型响应。
集成示例
Maven依赖
xml
<!-- 流式输出 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
</dependency>代码
java
/**
* AI服务 流式输出
*
* @author yaorongke
* @since 2025/9/6
*/
@AiService(wiringMode = EXPLICIT, streamingChatModel = "openAiStreamingChatModel")
public interface StreamingLLMAssistant {
/**
* 对话 流式输出
*
* @param message 问句
* @return 模型返回
*/
Flux<String> chat(String message);
}
java
@Autowired
private StreamingLLMAssistant streamingLLMAssistant;
@Test
public void testAiServiceStreamingChat() {
Flux<String> answer = streamingLLMAssistant.chat("介绍你自己,十个字以内");
System.out.println(answer.doOnNext(System.out::print).blockLast());
/*
输入:用十个字介绍你自己
输出:我是来自阿里云的超大规模语言模型。大规模语言模型。
*/
}3.4 提示工程 - Prompt
提示工程是大模型应用效果的核心决定因素。LangChain4j 提供注解式提示词管理能力,支持硬编码、变量注入、资源文件加载三种范式,适配提示词版本管控与复用的实际需求。 通过@SystemMessage、@UserMessage 注解实现。
集成示例
java
/**
* AI服务 提示词
*
* @author yaorongke
* @since 2025/9/6
*/
@AiService(wiringMode = EXPLICIT, chatModel = "openAiChatModel")
public interface PromptAssistant {
/**
* 对话接口 提示词
*
* @param message 问句
* @return 模型返回
*/
@SystemMessage("你是一个翻译助手,需要把我的问题翻译成英文。")
@UserMessage("{{message}}")
String chat(@V("message") String message);
/**
* 对话接口 提示词,从文件中加载
*
* @param message 问句
* @return 模型返回
*/
@SystemMessage(fromResource = "prompt/translate_prompt.txt")
@UserMessage("{{message}}")
String chat2(@V("message") String message);
}
java
@Autowired
private PromptAssistant promptAssistant;
// OpenAI 语言模型 AiService 提示词
@Test
public void testPrompt() {
String answer = promptAssistant.chat("今天天气不错");
System.out.println(answer);
/*
输入:今天天气不错
输出:The weather is nice today.
*/
}3.5 结构化输出 - Structured Outputs
实际业务场景中,大模型非结构化输出需转换为标准化 Java 对象才能对接业务系统。LangChain4j 原生支持基于描述注解的结构化输出解析,无需手动处理 JSON 序列化 / 反序列化,降低数据转换成本。
集成示例
定义Person对象
java
/**
* 人员信息
*
* @author yaorongke
* @since 2025/9/6
*/
@Data
public class Person {
@Description("用户的姓名")
private String name;
@Description("用户的年龄")
private int age;
}定义AI Service
java
/**
* 格式化输出
*
* @author yaorongke
* @since 2025/9/6
*/
@AiService(wiringMode = EXPLICIT, chatModel = "openAiChatModel")
public interface FormatAssistant {
/**
* 格式化输出
*
* @param message 问句
* @return 情绪类型
*/
@UserMessage("提取人员信息:{{message}}")
Person chat(@V("message") String message);
}调用示例
java
@Autowired
private FormatAssistant formatAssistant;
// OpenAI 语言模型 AiService 格式化输出
@Test
public void testAiServiceChat() {
Person person = formatAssistant.chat("我是张三,今年28");
System.out.println(person);
/*
输入:我是张三,今年28
输出:Person(name=张三, age=28)
*/
}3.6 分类 - Classification
文本分类是大模型的基础应用场景,如情感分析、意图检测 和实体识别。LangChain4j 支持将文本映射到预定义枚举 / 标签体系,通过 AI Service 一键实现分类能力,适配实际业务中的语义理解需求。
集成示例
定义情绪类型
java
/**
* 情绪类型
*
* @author yaorongke
* @since 2025/9/7
*/
public enum EmotionType {
HAPPY,
SAD,
ANGRY,
}定义AI Service
java
/**
* AI服务 情绪分析
*
* @author yaorongke
* @since 2025/9/6
*/
@AiService(wiringMode = EXPLICIT, chatModel = "openAiChatModel")
public interface EmotionAssistant {
/**
* 情绪分析
*
* @param message 问句
* @return 情绪类型
*/
@UserMessage("分析情绪类型:{{message}}")
EmotionType chat(@V("message") String message);
}调用示例
java
@Autowired
private EmotionAssistant emotionAssistant;
@Test
public void testAiServiceChat() {
EmotionType type = emotionAssistant.chat("今天天气不错");
System.out.println(type);
/*
输入:今天天气不错
输出:HAPPY
*/
}3.7 聊天记忆 - ChatMemory
多轮对话是 AI 应用的核心诉求之一,LangChain4j 提供两种开箱即用的聊天记忆实现:
| 记忆类型 | 核心逻辑 | 适用场景 |
|---|---|---|
| MessageWindowChatMemory | 滑动窗口,保留最近的N条消息 | 消息数量敏感的场景 |
| TokenWindowChatMemory | 滑动窗口,保留最近 N 个令牌 | 令牌消耗敏感的场景 |
集成示例
聊天记忆配置类
java
/**
* 聊天记忆配置(内存无持久化)
*
* @author yaorongke
* @since 2025/9/6
*/
@Configuration
public class MessageWindowChatMemoryConfig {
@Bean
public ChatMemory messageWindowChatMemory() {
return MessageWindowChatMemory.withMaxMessages(10);
}
}定义AI Service
java
/**
* AI服务 聊天记忆
*
* @author yaorongke
* @since 2025/9/6
*/
@AiService(wiringMode = EXPLICIT, chatModel = "openAiChatModel", chatMemory = "messageWindowChatMemory")
public interface ChatMemoryAssistant {
/**
* 对话
*
* @param message 问句
* @return 模型返回
*/
String chat(String message);
}调用示例-无记忆
java
@Autowired
private LLMAssistant llmAssistant;
@Test
public void chatMemory() {
String answer = llmAssistant.chat("我是张三");
System.out.println(answer);
String answer2 = llmAssistant.chat("我是谁?");
System.out.println(answer2);
/*
输入:我是张三
输出:你好,张三!很高兴见到你。有什么我可以帮助你的吗?
输入:我是谁?
输出:您好!在这里,我称呼您为"用户"。但就问题本身而言,您是在询问自己的身份。这个问题的答案取决于您的具体情况,比如您的名字、角色等个人信息。如果您是在寻求更深层次的自我认知,那可能涉及到个人的兴趣、价值观、经历等方面。请问您具体想要了解哪方面的信息呢?
*/
}调用示例-有记忆
java
@Autowired
private ChatMemoryAssistant chatMemoryAssistant;
@Test
public void chatMemory2() {
String answer = chatMemoryAssistant.chat("我是张三");
System.out.println(answer);
String answer2 = chatMemoryAssistant.chat("我是谁?");
System.out.println(answer2);
/*
输入:我是张三
输出:你好,张三!很高兴见到你。有什么我可以帮助你的吗?
输入:我是谁?
输出:您是张三。如果您是在开玩笑或者有其他想要了解的内容,请告诉我,我很乐意帮助您。
*/
}默认 ChatMemory 存储在内存中,如需持久化,可实现自定义 ChatMemoryStore:
java
class PersistentChatMemoryStore implements ChatMemoryStore {
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// TODO: 实现通过内存ID从持久化存储中获取所有消息。
// 可以使用ChatMessageDeserializer.messageFromJson(String)和
// ChatMessageDeserializer.messagesFromJson(String)辅助方法
// 轻松地从JSON反序列化聊天消息。
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
// TODO: 实现通过内存ID更新持久化存储中的所有消息。
// 可以使用ChatMessageSerializer.messageToJson(ChatMessage)和
// ChatMessageSerializer.messagesToJson(List<ChatMessage>)辅助方法
// 轻松地将聊天消息序列化为JSON。
}
@Override
public void deleteMessages(Object memoryId) {
// TODO: 实现通过内存ID删除持久化存储中的所有消息。
}
}
ChatMemory chatMemory = MessageWindowChatMemory.builder()
.id("12345")
.maxMessages(10)
.chatMemoryStore(new PersistentChatMemoryStore())
.build();3.8 工具调用 - Tool
工具调用是 Agent 能力的核心载体,工具可以是任何东西:网络搜索、调用外部 API 或执行特定代码片段等。LangChain4j 通过 @Tool 注解封装 Java 方法为可调用工具 ,AI Service 自动将工具元信息传递给 LLM,由 LLM 决策是否调用及调用参数,实现 "模型自主决策 + 工具执行" 的闭环。
Function Tool LLM大模型 应用程序 用户 Function Tool LLM大模型 应用程序 用户 输入提示词 发送提示词+函数定义 返回AiMessage\n包含ToolExecutionRequests 执行目标函数调用 返回函数执行结果 发送函数执行结果+原始提示词 返回大模型结果 返回最终大模型结果
集成示例
定义一个加法计算的工具
java
/**
* Tool工具定义(函数调用)
*
* @author yaorongke
* @since 2025/9/6
*/
@Component
public class CalculatorTools {
@Tool(name = "sum", value = "加法计算")
double sum(@P(value = "加数1", required = true) double a, @P(value = "加数2", required = true) double b) {
System.out.println("加法调用");
return a + b;
}
}绑定工具到 AI Service
java
/**
* AI服务 Tool工具(函数调用)
*
* @author yaorongke
* @since 2025/9/6
*/
@AiService(wiringMode = EXPLICIT, chatModel = "openAiChatModel", tools = "calculatorTools")
public interface ToolAssistant {
/**
* 验证tool工具调用
*
* @param message 问句
* @return 模型返回
*/
String chat(String message);
}调用示例
java
@Autowired
private ToolAssistant toolAssistant;
// OpenAI 语言模型 AiService 调用加法tool
@Test
public void testSum() {
String answer = toolAssistant.chat("1加2等于几");
System.out.println(answer);
/*
输入:1加2等于几
输出:1加2等于3。
*/
}3.9 护栏 - Guardrails
企业级AI 应用需保障输入 / 输出的合规性,LangChain4j 提供 Guardrails(护栏)机制,分为输入护栏 和输出护栏,本质为请求 / 响应拦截器,支持敏感词校验、输出长度管控、权限校验等自定义规则,适配合规管控的实际需求。
集成示例
输入护栏(敏感词校验)
java
/**
* 输入护栏 输入敏感词校验
*
* @author yaorongke
* @since 2025/9/10
*/
public class MyInputGuardrail implements InputGuardrail {
/**
* 敏感词
*/
private static final Set<String> SENSITIVE_WORDS = Set.of("网贷");
@Override
public InputGuardrailResult validate(UserMessage userMessage) {
String query = userMessage.singleText();
for (String sensitiveWord : SENSITIVE_WORDS) {
if (query.contains(sensitiveWord)) {
return failure("输入包含敏感词汇: " + sensitiveWord);
}
}
return success();
}
}输出护栏(长度校验)
java
/**
* 输出护栏 输出长度校验
*
* @author yaorongke
* @since 2025/9/10
*/
public class MyOutputGuardrail implements OutputGuardrail {
@Override
public OutputGuardrailResult validate(AiMessage responseFromLLM) {
String responseText = responseFromLLM.text();
if (responseText.length() > 10) {
return failure("输出长度超过限制: " + responseText.length());
}
return success();
}
}调用示例
java
@Autowired
private GuardrailAssistant guardrailAssistant;
// 输入护栏
@Test
public void testInputGuardrail() {
String answer = guardrailAssistant.chat("网1贷怎么办理");
System.out.println(answer);
/*
输入:网贷
输出:dev.langchain4j.guardrail.InputGuardrailException: The guardrail com.rkyao.langchain4j.demo.guardrails.MyInputGuardrail failed with this message: 输入包含敏感词汇: 网贷
*/
}
// 输出护栏
@Test
public void testOutputGuardrail() {
String answer = guardrailAssistant.chat("用十个字介绍你自己");
System.out.println(answer);
/*
输入:用十个字介绍你自己
输出:dev.langchain4j.guardrail.OutputGuardrailException: The guardrail com.rkyao.langchain4j.demo.guardrails.MyOutputGuardrail failed with this message: 输出长度超过限制: 17
*/
}3.10 检索增强生成 - RAG
RAG 是解决大模型 "知识过期""幻觉" 问题的核心技术,LangChain4j 提供全链路 RAG 能力,分为**索引(Ingestion)与检索(Retrieval)**两个阶段,架构层支持自定义每个环节的实现,适配知识问答类业务场景。
3.10.1 索引
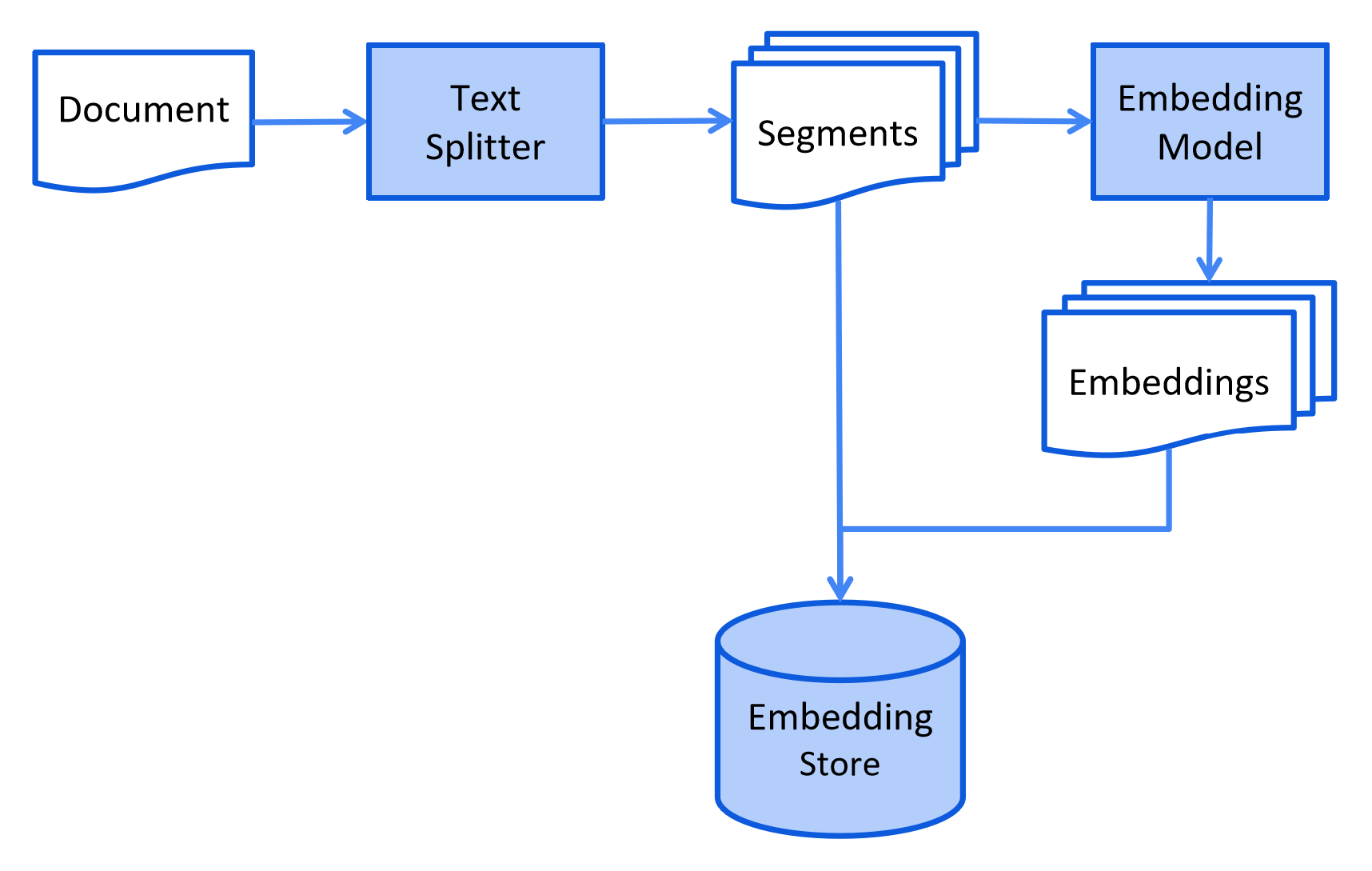
索引阶段核心目标是将非结构化文档转换为向量数据并存储,LangChain4j 提供全链路组件支持:
- 文档加载器:10种加载器,适配 文件系统/类路径/URL/S3/Azure Blob/GitHub 等多源存储;
- 文档解析器:6种解析器,支持 TXT/PDF/DOC/Markdown/Yaml 等多格式解析;
- 文档分割器:6种内置分割器,提供按段落 / 行 / 句子 / 单词 / 正则等分割算法,支持自定义实现;
- 向量模型:23种向量模型,适配开源 / 云厂商多类嵌入模型,统一向量生成接口;
- 向量存储:32个向量数据库,适配 Pinecone/Redis/Elasticsearch 等,架构层屏蔽存储差异;
集成示例
Maven依赖
xml
<!-- 向量库 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pinecone</artifactId>
</dependency>向量模型配置
properties
langchain4j.open-ai.embedding-model.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
langchain4j.open-ai.embedding-model.api-key=sk-af0821tu47204f5a858102c6f0k9r20e
langchain4j.open-ai.embedding-model.model-name=text-embedding-v3
langchain4j.open-ai.embedding-model.log-requests=true
langchain4j.open-ai.embedding-model.log-responses=true
langchain4j.open-ai.embedding-model.max-segments-per-batch=10向量库配置类
java
/**
* 向量库配置类 Pinecone
*
* @author yaorongke
* @since 2025/9/6
*/
@Configuration
public class EmbeddingStoreConfig {
@Autowired
private EmbeddingModel embeddingModel;
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
// 创建向量存储空间
return PineconeEmbeddingStore.builder()
.apiKey("pcsk_2fBwAK_Uh5d2NVS6H38pySE5Wv5RTkaNWsUpFW7Kfkg5tjEGpuD47sxTKZH4PWE8oqzpMV") // Pinecone API 密钥
.index("stock-index") // 如果指定的索引不存在,将创建一个新的索引
.nameSpace("fin-namespace") // 如果指定的名称空间不存在,将创建一个新的命名空间
.createIndex(PineconeServerlessIndexConfig.builder()
.cloud("AWS") // 指定索引部署在 AWS 云服务上。
.region("us-east-1") // 指定索引所在的 AWS 区域为 us-east-1。
.dimension(embeddingModel.dimension()) // 指定索引的向量维度,该维度与 embeddedModel 生成的向量维度相同。
.build())
.build();
}
}自定义文档分割器
java
/*
* 自定义文档分割器 正则按照换行符进行分割
* 注:LangChain4j 内置按行分割器,此处仅为演示自定义实现逻辑
*
* @author yaorongke
* @since 2025/9/6
*/
public class MyDocumentSplitter implements DocumentSplitter {
public static final String SPLIT_EXP = "\n";
@Override
public List<TextSegment> split(Document document) {
List<TextSegment> segments = new ArrayList<>();
String[] parts = document.text().split(SPLIT_EXP);
for (String part : parts) {
segments.add(TextSegment.from(part));
}
return segments;
}
}索引示例代码
java
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingStore embeddingStore;
@Test
public void loadJdResources() throws URISyntaxException {
// 获取文档路径 STOCK_A.csv内容为股票代码及名称
Path documentPath = Paths.get(RAGTest.class.getClassLoader().getResource("document/STOCK_A.csv").toURI());
// 创建文档解析器
DocumentParser documentParser = new TextDocumentParser();
// 加载并解析文档
Document document = FileSystemDocumentLoader.loadDocument(documentPath, documentParser);
// 创建文档分割器
DocumentSplitter documentSplitter = new MyDocumentSplitter();
// 分割文档
List<TextSegment> split = documentSplitter.split(document);
// 分割后的文档进行向量化
Response<List<Embedding>> listResponse = embeddingModel.embedAll(split);
// 向量数据存入到向量数据库中
embeddingStore.addAll(listResponse.content(),split);
}3.10.2 检索
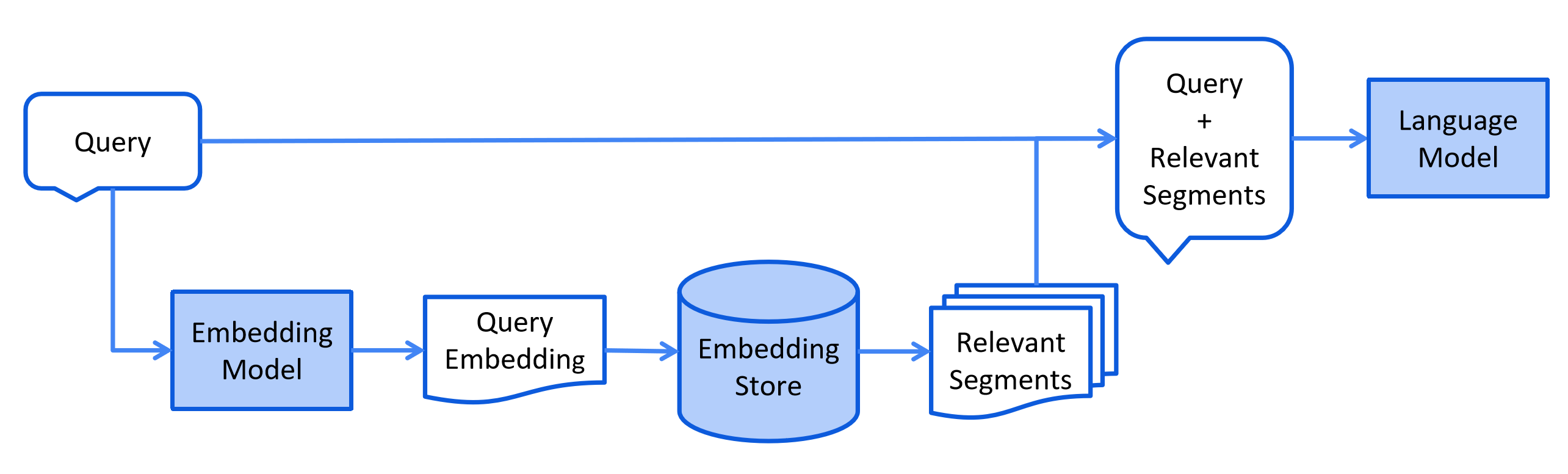
检索阶段核心目标是基于用户查询精准召回相关向量数据,LangChain4j 支持高级检索能力:
- 查询预处理:查询扩展 / 压缩 / 路由,适配多知识库场景;
- 多源检索:支持向量存储 + 自定义数据源联合检索;
- 结果优化:重排序、倒数排名融合,提升召回精准度;
- 流程定制:支持自定义 RAG 链路每个环节,适配复杂的业务场景。
集成示例
配置检索器
java
/**
* RAG配置类
* 使用OpenAI兼容模式访问通义千问的向量化服务
*
* @author yaorongke
* @since 2025/9/6
*/
@Configuration
public class RagConfig {
@Bean
public ContentRetriever contentRetriever(EmbeddingStore<TextSegment> embeddingStore, EmbeddingModel embeddingModel) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(1)
.minScore(0.5)
.build();
}
}检索调用
java
@Autowired
private ContentRetriever contentRetriever;
@Test
public void embeddingSearch2() {
// 检索相关内容
List<Content> contentList = contentRetriever.retrieve(new Query("中石化"));
// 输出检索结果
for (Content content : contentList) {
System.out.println(content.textSegment().text());
}
/*
输入:中石化
输出:600028.SH|中国石化
*/
}3.11 模型上下文协议 - MCP
MCP(Model Context Protocol)是大模型与工具交互的标准化协议,LangChain4j 当前支持 MCP 客户端能力,可通过 HTTP/stdio 与 MCP 服务端通信,快速集成第三方工具(如地图 / 天气 / 搜索),降低跨系统集成成本。
集成示例
Maven依赖
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-mcp</artifactId>
</dependency>以下为使用http方式调用百度地图MCP服务的示例代码,更多服务可到 MCP市场 寻找。
java
@Autowired
private OpenAiChatModel openAiChatModel;
@Test
public void testMcpSse() {
// 创建 MCP 传输实例
McpTransport transport = StreamableHttpMcpTransport.builder()
.url("https://mcp.map.baidu.com/sse?ak=VsSw2BI3c4VGXDXznFD7W5Kl2h1jKUBq")
.build();
// 创建 MCP 客户端
McpClient mcpClient = new DefaultMcpClient.Builder().transport(transport).build();
// 创建 MCP 工具提供者
ToolProvider toolProvider = McpToolProvider.builder().mcpClients(mcpClient).build();
// 工具提供者绑定到 AI 服务
LLMAssistant assistant = AiServices.builder(LLMAssistant.class)
.chatModel(openAiChatModel)
.toolProvider(toolProvider)
.build();
// 调用大模型进行会话
String answer = assistant.chat("杭州明天的天气");
System.out.println(answer);
/*
输入:杭州明天的天气
输出:
杭州明天的天气预报如下:
- **白天**:晴,最高温度22°C。
- **夜晚**:晴,最低温度10°C。
- **风向与风力**:白天东风<3级,夜晚西南风<3级。
请注意根据天气变化适当增减衣物,并做好防晒措施。祝您生活愉快!
*/
}3.12 智能代理 - Agent
Agent
大多数基础 Agent 功能可通过 AI Service + Tool API 构建,满足通用场景需求。
Multi-Agent
如需构建多代理系统,可基于底层 API 实现:ChatLanguageModel、ToolSpecification 和 ChatMemory。
四、可观测性
生产级应用必须具备完善的可观测性体系,LangChain4j 虽未提供原生可观测性能力,但预留了丰富的扩展点,可基于 Spring 生态构建标准化可观测性体系,覆盖日志、指标、链路追踪三大维度。
4.1 日志
LangChain4j 支持细粒度日志配置,可开启请求 / 响应日志、调整框架日志级别。
properties
langchain4j.open-ai.chat-model.log-requests = true
langchain4j.open-ai.chat-model.log-responses = true
logging.level.dev.langchain4j = DEBUG4.2 指标
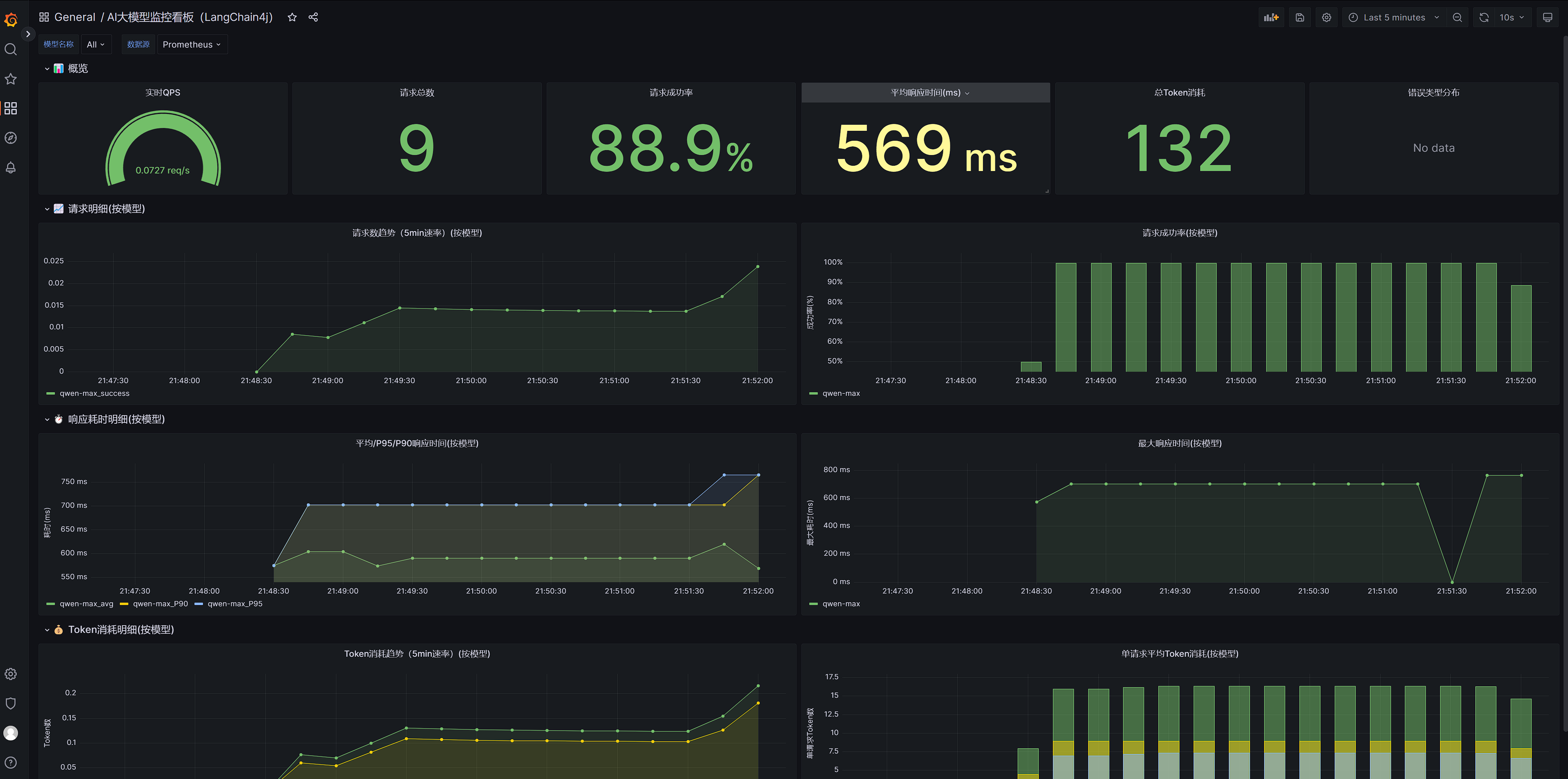
LangChain4j 预留 ChatModelListener 扩展点,可基于 Micrometer+Prometheus+Grafana 构建企业级指标体系,核心监控维度需覆盖流量、延迟、资源、错误四类,适配大模型应用成本管控与性能优化需求。
技术选型
| 组件类型 | 选型 | 描述 |
|---|---|---|
| 指标采集 | Micrometer | 监控指标门面框架,适配多监控后端,与 Spring Boot 生态无缝融合 |
| 指标存储 | Prometheus | 时序数据库,专为监控场景设计,支持高效的指标存储、查询与告警规则配置 |
| 可视化 | Grafana | 监控面板与告警引擎,支持多维度指标可视化、阈值告警与自定义大盘构建 |
| 扩展点 | ChatModelListener | LangChain4j 预留的 LLM 交互生命周期监听接口,精准捕获请求 / 响应 / 异常事件 |
指标体系设计
| 指标类型 | 指标名称 | 单位 |
|---|---|---|
| 流量指标 | ai_model_requests_total | 请求数 |
| 延迟指标 | ai_model_response_time | 毫秒 |
| 资源指标 | ai_model_tokens_total | Token数 |
| 错误指标 | ai_model_errors_total | 错误数 |
集成示例
Maven依赖
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>监控配置
properties
management.server.port=8091
management.endpoints.web.exposure.include=*
management.metrics.tags.application=langchain4j-demo指标采集器
java
/**
* 大模型指标采集
*
* @author yaorongke
* @since 2025/9/14
*/
@Component
public class AiModelMetricsCollector {
@Resource
private MeterRegistry meterRegistry;
/**
* 记录请求次数
*/
private final ConcurrentHashMap<String, Counter> REQ_COUNTERS = new ConcurrentHashMap<>();
/**
* 记录异常请求次数
*/
private final ConcurrentHashMap<String, Counter> ERROR_COUNTERS = new ConcurrentHashMap<>();
/**
* 记录token消耗数
*/
private final ConcurrentHashMap<String, Counter> TOKEN_COUNTERS = new ConcurrentHashMap<>();
/**
* 记录响应耗时
*/
private final ConcurrentHashMap<String, Timer> RESPONSE_TIMERS = new ConcurrentHashMap<>();
/**
* 记录请求次数
*
* @param modelName 模型名称
* @param status 请求状态,如 "total", "success", "error"
*/
public void recordRequests(String modelName, String status) {
String key = String.format("REQ_%s_%s", modelName, status);
Counter counter = REQ_COUNTERS.computeIfAbsent(key, k ->
Counter.builder("ai_model_requests_total")
.description("AI模型总请求次数")
.tag("model_name", modelName)
.tag("status", status)
.register(meterRegistry)
);
counter.increment();
}
/**
* 记录异常请求次数
*
* @param modelName 模型名称
* @param errorMsg 异常信息
*/
public void recordErrors(String modelName, String errorMsg) {
String key = String.format("ERROR_%s_%s", modelName, errorMsg);
Counter counter = ERROR_COUNTERS.computeIfAbsent(key, k ->
Counter.builder("ai_model_errors_total")
.description("AI模型错误次数")
.tag("model_name", modelName)
.tag("error_msg", errorMsg)
.register(meterRegistry)
);
counter.increment();
}
/**
* 记录token消耗数
*
* @param modelName 模型名称
* @param tokenType token类型 ,如 "total", "input", "output"
* @param tokenCount token数量
*/
public void recordTokenUsage(String modelName, String tokenType, long tokenCount) {
String key = String.format("TOKEN_%s_%s", modelName, tokenType);
Counter counter = ERROR_COUNTERS.computeIfAbsent(key, k ->
Counter.builder("ai_model_tokens_total")
.description("AI模型Token消耗总数")
.tag("model_name", modelName)
.tag("token_type", tokenType)
.register(meterRegistry)
);
counter.increment(tokenCount);
}
/**
* 记录响应耗时
*
* @param modelName 模型名称
* @param durationMillis 耗时 ms
*/
public void recordResponseTime(String modelName, long durationMillis) {
String key = String.format("TIMER_%s", modelName);
Timer counter = RESPONSE_TIMERS.computeIfAbsent(key, k ->
Timer.builder("ai_model_response_time")
.description("AI模型响应时间")
.tag("model_name", modelName)
.register(meterRegistry)
);
counter.record(durationMillis, TimeUnit.MILLISECONDS);
}模型监听器
java
/**
* 模型监听器
*
* @author yaorongke
* @since 2025/9/14
*/
@Configuration
public class AiModelMetricsListener {
@Resource
private AiModelMetricsCollector aiModelMetricsCollector;
public static final String START_TIME = "startTime";
@Bean
public ChatModelListener chatModelListener() {
return new ChatModelListener() {
@Override
public void onRequest(ChatModelRequestContext requestContext) {
ChatRequest chatRequest = requestContext.chatRequest();
ChatRequestParameters parameters = chatRequest.parameters();
String modelName = parameters.modelName();
// 记录请求次数
aiModelMetricsCollector.recordRequests(modelName, "total");
// 记录当前时间
requestContext.attributes().put(START_TIME, System.currentTimeMillis());
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
ChatResponse chatResponse = responseContext.chatResponse();
ChatResponseMetadata metadata = chatResponse.metadata();
TokenUsage tokenUsage = metadata.tokenUsage();
String modelName = metadata.modelName();
// 记录请求次数
aiModelMetricsCollector.recordRequests(modelName, "success");
long cost = System.currentTimeMillis() - (Long) responseContext.attributes().get(START_TIME);
// 记录响应时间
aiModelMetricsCollector.recordResponseTime(modelName, cost);
// 记录token消耗数量
aiModelMetricsCollector.recordTokenUsage(modelName, "input", tokenUsage.inputTokenCount());
aiModelMetricsCollector.recordTokenUsage(modelName, "output", tokenUsage.outputTokenCount());
aiModelMetricsCollector.recordTokenUsage(modelName, "total", tokenUsage.totalTokenCount());
}
@Override
public void onError(ChatModelErrorContext errorContext) {
ChatRequest chatRequest = errorContext.chatRequest();
ChatRequestParameters parameters = chatRequest.parameters();
String modelName = parameters.modelName();
String errorMsg = errorContext.error().getMessage();
// 记录请求次数
aiModelMetricsCollector.recordRequests(modelName, "error");
// 记录失败请求
aiModelMetricsCollector.recordErrors(modelName, errorMsg);
}
};
}
}Prometheus配置文件prometheus.yml中添加采集Job
yaml
- job_name: "langchain4j-demo"
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ["120.55.98.87:8091"]Grafana创建自定义面板,基于基础指标再次进行聚合统计
4.3 调用链
分布式追踪是企业级微服务架构下 AI 应用问题诊断的核心能力,通过串联 LangChain4j 调用链路中的各个环节(如 RAG 检索、工具调用、LLM 交互),实现全链路耗时、异常节点的精准定位。
完整执行路径
用户请求入口(如 API 接口)→ langchain4j 内部组件(Chain/Agent)→ Prompt 构建 → LLM 服务调用(OpenAI / 本地大模型)→ 工具调用(检索 / 计算器 / 文档加载)→ 结果整合的完整链路层级
技术选型
| 组件类型 | 选型 | 描述 |
|---|---|---|
| 指标采集 | Skywalking JavaAgent | 采集链路追踪数据, 上报给 SkyWalking OAP Server |
| 追踪服务 | SkyWalking OAP Server | 接收、分析、聚合、存储和查询追踪数据的后端核心服务 |
| 数据存储 | ElasticSearch | 作为 SkyWalking 的核心存储介质,高效存储和检索海量追踪数据 |
| 可视化 | SkyWalking UI | 可视化展示链路追踪数据、服务拓扑、性能指标,提供问题排查的交互界面 |
| 扩展点 | ChatModelListener | LangChain4j 预留的 LLM 交互生命周期监听接口,精准捕获请求 / 响应 / 异常事件 |
集成示例
依赖
xml
<!-- SkyWalking 核心依赖(用于自定义Trace) -->
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>9.5.0</version>
</dependency>
<!-- SkyWalking Logback集成(可选,让日志关联TraceID) -->
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-logback-1.x</artifactId>
<version>9.5.0</version>
</dependency>这里演示在ChatModelListener里将LLM调用纳入分布式追踪
java
@Override
public void onRequest(ChatModelRequestContext requestContext) {
ChatRequest chatRequest = requestContext.chatRequest();
ChatRequestParameters parameters = chatRequest.parameters();
String modelName = parameters.modelName();
ActiveSpan.tag("ai.model.name", modelName);
}启动服务,增加skywalking-agent参数
shell
java -javaagent:"C:\Users\1\Downloads\apache-skywalking-java-agent-9.5.0\apache-skywalking-java-agent-9.5.0\skywalking-agent\skywalking-agent.jar" -Dskywalking.agent.service_name=langchain4j-demo -Dskywalking.collector.backend_service=192.168.64.140:11800 -Dserver.port=8081 -Dskywalking.agent.sample_n_per_3_secs=-1 -jar langchain4j-demo-0.0.1-SNAPSHOT.jar效果展示
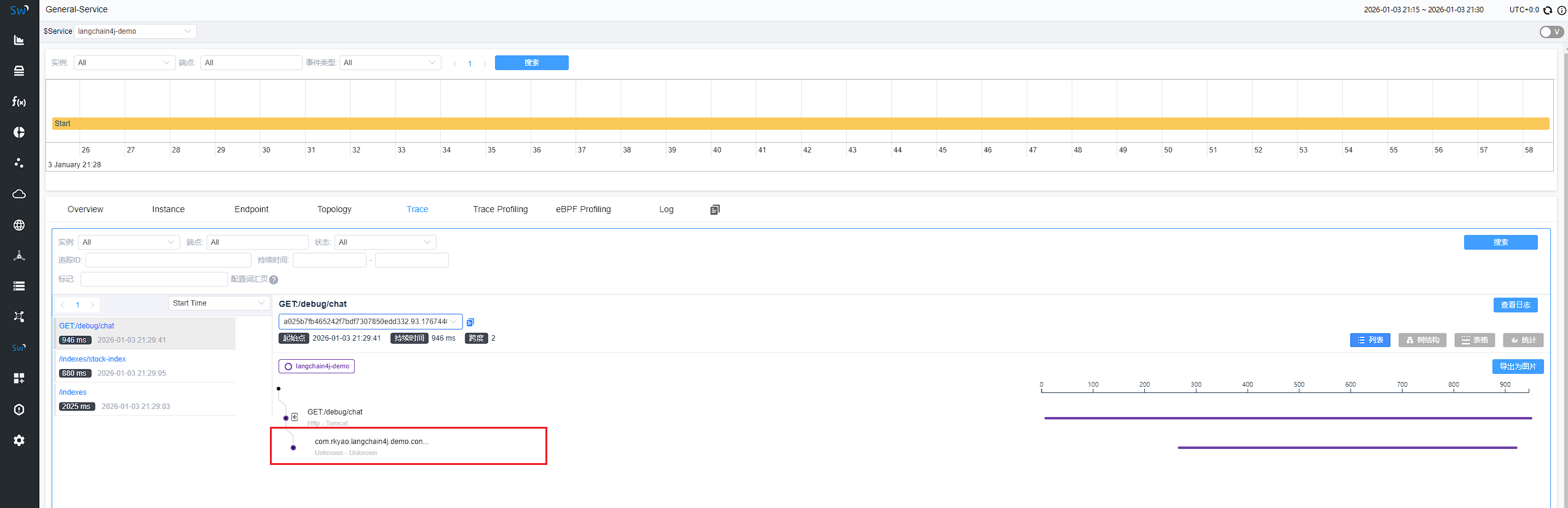
4.4 三方集成
五、典型场景实战
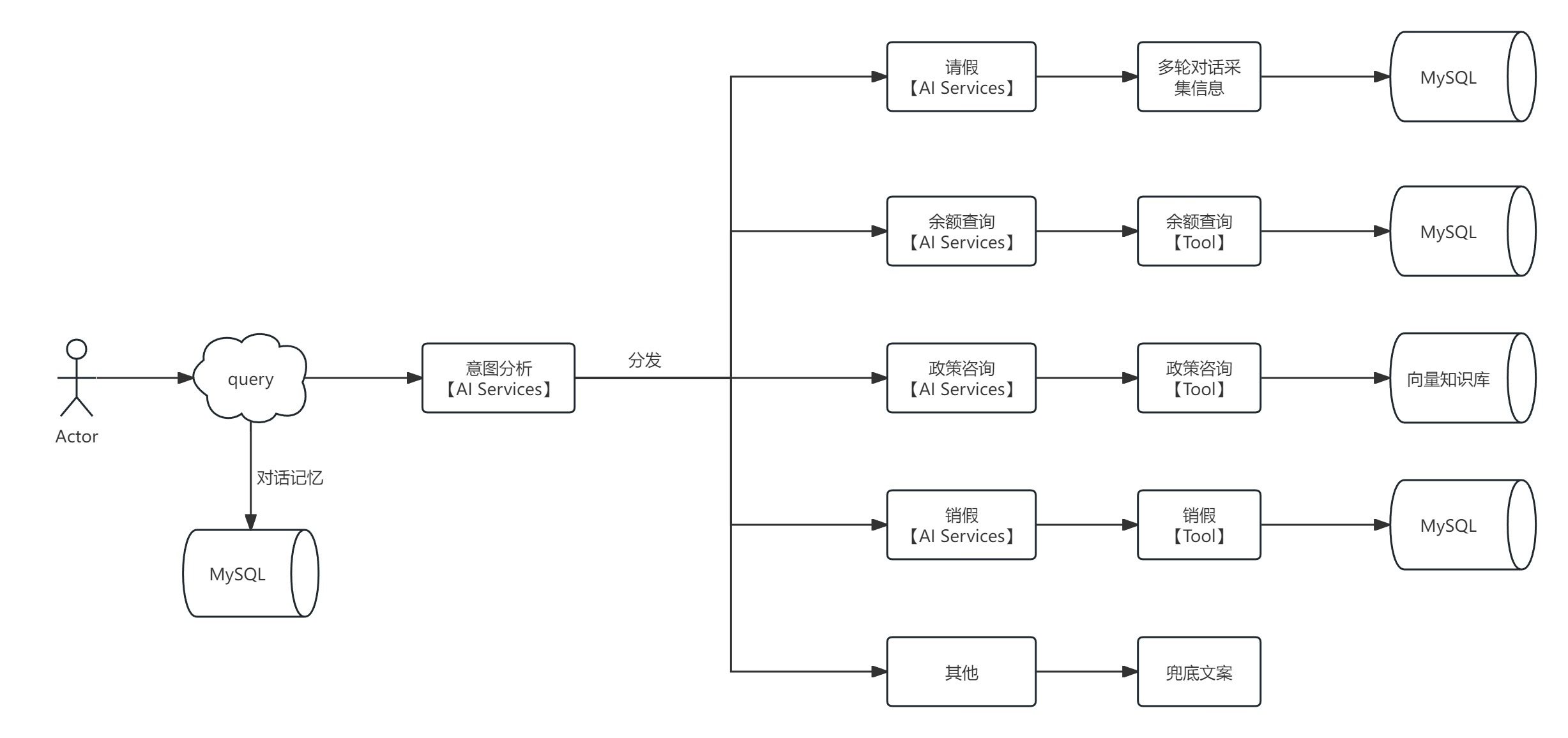
选取考勤域核心场景 --- 智能请假助手,系统化演示基于 LangChain4j 构建企业级 AI 应用的全流程。本案例聚焦 LangChain4j 工程化落地方法论,对业务逻辑做极简抽象,无需纠结业务细节合理性。
5.1 场景概述
通过 Langchain4j + LLM + RAG 构建智能助手,实现请假场景全流程自动化、智能化处理 。
5.2 核心功能
| 功能模块 | 详细描述 |
|---|---|
| 请假办理 | 用户提交请假申请,记录请假信息 |
| 销假办理 | 用户撤销未生效请假 |
| 余额查询 | 查询用户各类假期的剩余天数 |
| 政策咨询 | 解答请假规则 |
| 其他咨询 | 处理和请假无关的问题 |
5.3 技术选型
| 技术类别 | 选型 |
|---|---|
| 核心框架 | Langchain4j + Spring Boot |
| LLM 模型 | qwen-max |
| 向量模型 | text-embedding-v3 |
| 向量数据库 | Pinecone |
| 持久化存储 | MySQL |
5.4 系统流程图
5.5 数据库设计
请假记录表
存储员工请假申请的核心结构化数据,支撑请假全生命周期管理。
| 字段名 | 类型 | 备注 |
|---|---|---|
| id | bigint | 主键,自增 |
| user_id | varchar(64) | 用户id |
| start_time | datetime | 开始时间 |
| end_time | datetime | 结束时间 |
| leave_type | varchar(32) | 请假类型 |
| reason | longtext | 请假原因 |
| ctime | datetime | 创建时间 |
| mtime | datetime | 更新时间 |
| is_valid | tinyint | 是否有效 1:有效 0:无效 |
对话历史表
存储用户与 AI 助手的交互会话数据,支撑多轮对话上下文管理。
| 字段名 | 类型 | 备注 |
|---|---|---|
| id | bigint | 主键,自增 |
| user_id | varchar(64) | 用户id |
| session_id | varchar(64) | 会话id |
| role | varchar(16) | 角色 AI|USER |
| content | longtext | 内容 |
| ctime | datetime | 创建时间 |
| mtime | datetime | 更新时间 |
| is_valid | tinyint | 是否有效 1:有效 0:无效 |
建表SQL
sql
CREATE DATABASE IF NOT EXISTS `leave` DEFAULT CHARACTER SET utf8;
USE `leave`;
DROP TABLE IF EXISTS leave_record;
CREATE TABLE `leave_record` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'id',
`ctime` datetime NOT NULL COMMENT '创建时间',
`mtime` datetime NOT NULL COMMENT '更新时间',
`is_valid` tinyint NOT NULL COMMENT '是否有效 1:有效 0:无效',
`user_id` varchar(255) DEFAULT NULL COMMENT '会话id',
`start_time` datetime NOT NULL COMMENT '开始时间',
`end_time` datetime NOT NULL COMMENT '结束时间',
`leave_type` varchar(255) DEFAULT NULL COMMENT '请假类型',
`reason` longtext COMMENT '请假原因',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='请假记录';
CREATE INDEX idx_leave_record_user_id_id ON chat_history (user_id);
DROP TABLE IF EXISTS chat_history;
CREATE TABLE `chat_history` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'id',
`ctime` datetime NOT NULL COMMENT '创建时间',
`mtime` datetime NOT NULL COMMENT '更新时间',
`is_valid` tinyint NOT NULL COMMENT '是否有效 1:有效 0:无效',
`user_id` varchar(255) DEFAULT NULL COMMENT '用户id',
`session_id` varchar(255) DEFAULT NULL COMMENT '会话id',
`role` varchar(50) DEFAULT NULL COMMENT '角色 AI|USER',
`content` longtext COMMENT '内容',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='聊天历史';
CREATE INDEX idx_chat_history_session_id ON chat_history (session_id);5.6 模块设计
下面对部分核心模块进行实现。
5.6.1 意图识别
职责:智能助手的核心路由层,基于 LLM 语义理解能力解析用户输入,精准识别意图类型(请假申请 / 余额查询 / 政策咨询 / 销假申请),并路由至对应业务处理器
AI服务定义:
java
/**
* AI服务 意图识别
*
* @author yaorongke
* @since 2025/9/1
*/
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", tools = {"chatHistoryTool"})
public interface AiIntentionAssistant {
/**
* 意图识别
*
* @param sessionId 会话id
* @param query 查询内容
* @return 意图识别结果
*/
@SystemMessage(fromResource = "prompt/intention.txt")
@UserMessage("当前sessionId:{{sessionId}};用户当前消息:{{query}}")
IntentionOuput intention(@V("sessionId") String sessionId, @V("query") String query);
}结构化输出:
java
/**
* 意图识别 模型输出结构
*
* @author yaorongke
* @since 2025/9/6
*/
@Data
public class IntentionOuput {
@Description(
"LEAVE_REQUEST: 申请请假或表达因故(如生病、事由)需要离开岗位; " +
"BALANCE_QUERY: 询各类假别的剩余天数或可用额度; " +
"POLICY_CONSULT: 咨询公司的请假政策、流程、规定; " +
"CANCEL_REQUEST: 撤销或修改已提交的请假申请; " +
"OTHER: 不属于以上任何一类的其他查询或对话。"
)
private String intention;
@Description("大模型对用户的输出")
private String output;
}意图分流逻辑:
java
@Autowired
private AiIntentionAssistant aiIntentionAssistant;
@ChatFlow
@Override
public String chat(String userId, String sessiond, String query) {
IntentionOuput intentionOuput = aiIntentionAssistant.intention(sessiond, query);
if (intentionOuput == null) {
return "对不起,请您提供更多请假细节。";
}
IntentionEnum intentionEnum = IntentionEnum.of(intentionOuput.getIntention());
String output = intentionOuput.getOutput();
switch (intentionEnum) {
case LEAVE_REQUEST:
output = leaveRequest(userId, sessiond, query);
break;
case BALANCE_QUERY:
output = queryBalance(userId, sessiond, query);
break;
case POLICY_CONSULT:
output = policyConsult(sessiond, query);
break;
case CANCEL_REQUEST:
output = cancelRequest(userId, sessiond, query);
break;
case OTHER:
output = "对不起,请您提供更多请假细节。";
break;
default:
return output;
}
return output;
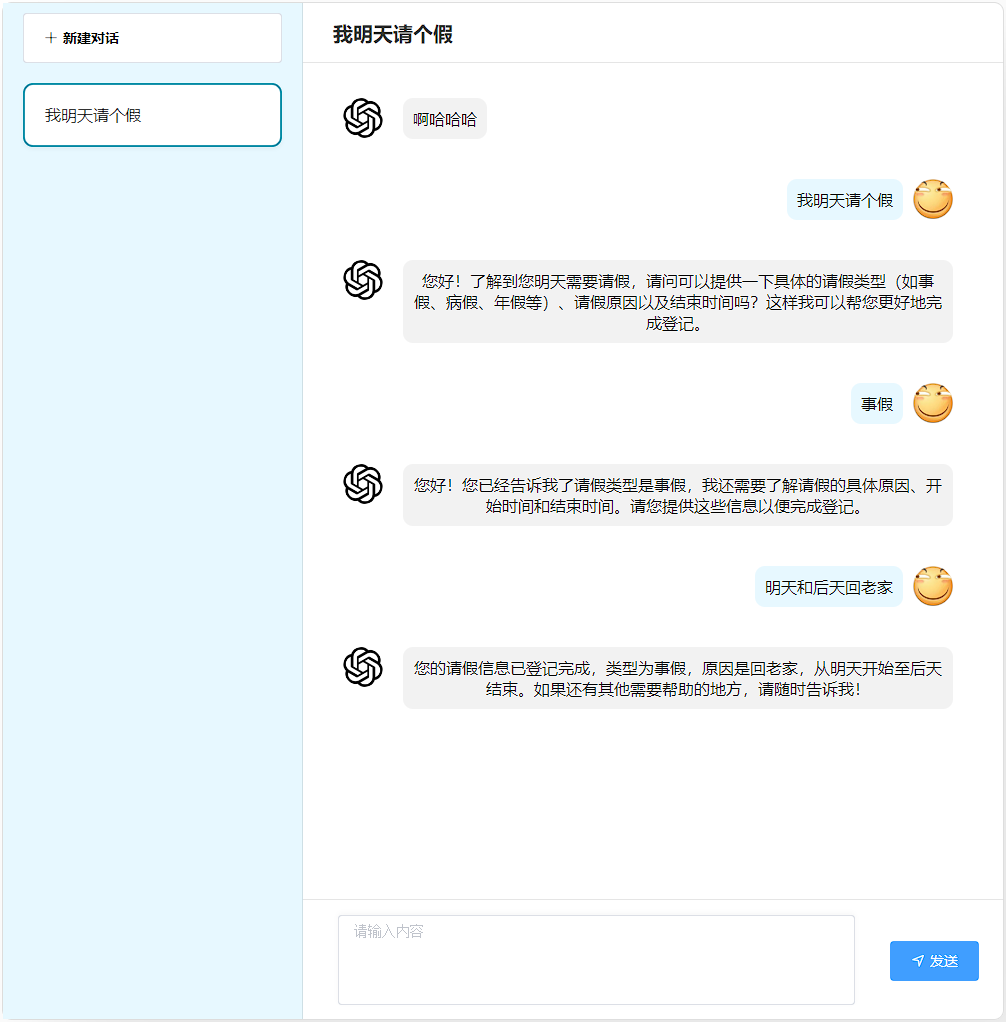
}5.6.2 请假申请
职责:通过多轮对话引导用户完善请假信息(时间 / 类型 / 原因),结构化解析后持久化存储,实现请假申请的自动化登记。
AI服务定义:
java
/**
* AI服务 请假申请
*
* @author yaorongke
* @since 2025/9/1
*/
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", tools = {"chatHistoryTool"})
public interface LeaveRequestAssistant {
/**
* 假期申请
*
* @param userId 用户id
* @param sessionId 会话id
* @param dateTime 当前时间
* @param query 用户问题
* @return 模型返回
*/
@SystemMessage(fromResource = "prompt/LeaveRequest.txt")
@UserMessage("当前userId: {{userId}}; 当前sessionId: {{sessionId}}; 当前时间: {{dateTime}}; 当前用户消息: {{query}};")
LeaveRequestOutput leaveRequest(@V("userId") String userId, @V("sessionId") String sessionId, @V("dateTime") String dateTime, @V("query") String query);
}结构化输出:
java
/**
* 请假申请 模型输出
*
* @author yaorongke
* @since 2025/9/6
*/
@Data
public class LeaveRequestOutput {
@Description("用户id")
private String userId;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@Description("开始时间,格式:yyyy-MM-dd HH:mm:ss")
private Date startTime;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@Description("截止时间,格式:yyyy-MM-dd HH:mm:ss")
private Date endTime;
@Description("请假类型,如事假、病假、年假等")
private String leaveType;
@Description("请假原因")
private String reason;
@Description("是否完成登记")
private Boolean completed;
@Description("大模型对用户输出")
private String output;
}业务处理:
java
/**
* 请假申请
*
* @param userId 用户id
* @param sessionId 会话ID
* @param query 查询内容
* @return 模型输出
*/
private String leaveRequest(String userId, String sessionId, String query) {
LeaveRequestOutput output = leaveRequestAssistant.leaveRequest(userId, sessionId, DateTimeUtil.getCurrentTiemString(), query);
if (output.getCompleted()) {
LeaveRecord record = new LeaveRecord();
record.setCtime(new Date());
record.setMtime(new Date());
record.setIsValid(1);
record.setUserId(userId);
record.setStartTime(output.getStartTime());
record.setEndTime(output.getEndTime());
record.setLeaveType(output.getLeaveType());
record.setReason(output.getReason());
leaveRecordMapper.insert(record);
}
return output.getOutput();
}效果演示:
5.6.3 余额查询
职责:基于 LangChain4j Tool 机制实现工具调用,对接内部假期额度系统,精准返回用户各类假期剩余天数。
AI服务定义:
java
/**
* 假期额度查询
*
* @author yaorongke
* @since 2025/9/1
*/
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", tools = {"chatHistoryTool", "balanceQueryTool"})
public interface BalanceQueryAssistant {
/**
* 假期额度查询
*
* @param id 用户ID
* @param query 用户问题
* @return 模型返回
*/
@SystemMessage(fromResource = "prompt/BalanceQuery.txt")
@UserMessage("当前userId: {{userId}}; 当前sessionId:{{sessionId}}; 当前用户消息: {{query}}")
String queryBalance(@V("userId") String id, @V("sessionId") String sessionId, @V("query") String query);
}Tool组件定义:
java
/**
* 查询假期余额tool
*
* @author yaorongke
* @since 2025/9/1
*/
@Component
@Slf4j
public class BalanceQueryTool {
/**
* 根据用户id查询假期余额
* MOCK数据,实际应为假期额度查询逻辑
*
* @param userId 用户id
* @return 假期余额
*/
@Tool("根据用户id查询假期余额")
public int queryBalance(@P("用户id") String userId){
log.info("根据用户id查询假期余额, 用户id:{}", userId);
switch (userId) {
case "rkyao1" -> {
return 16;
}
case "rkyao2" -> {
return 8;
}
case "rkyao3" -> {
return 0;
}
default -> {
return 5;
}
}
}
}效果演示:
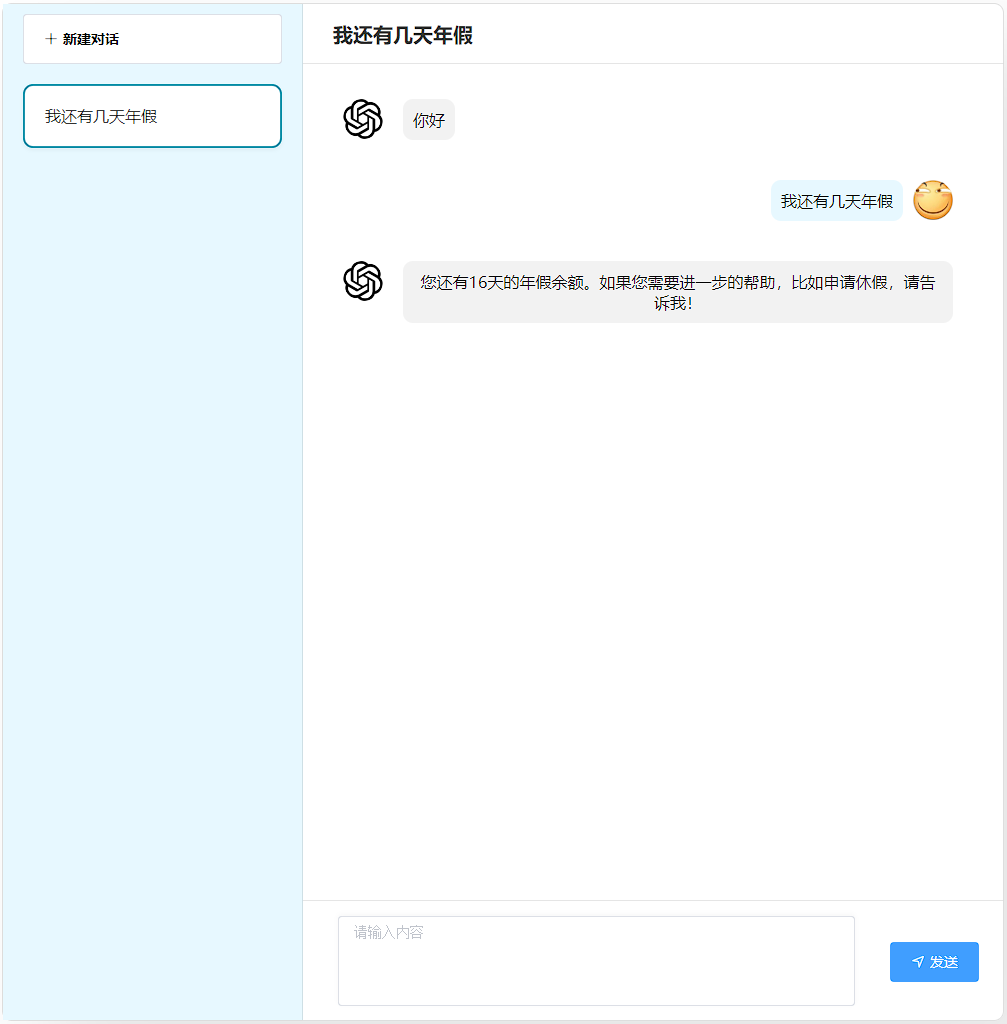
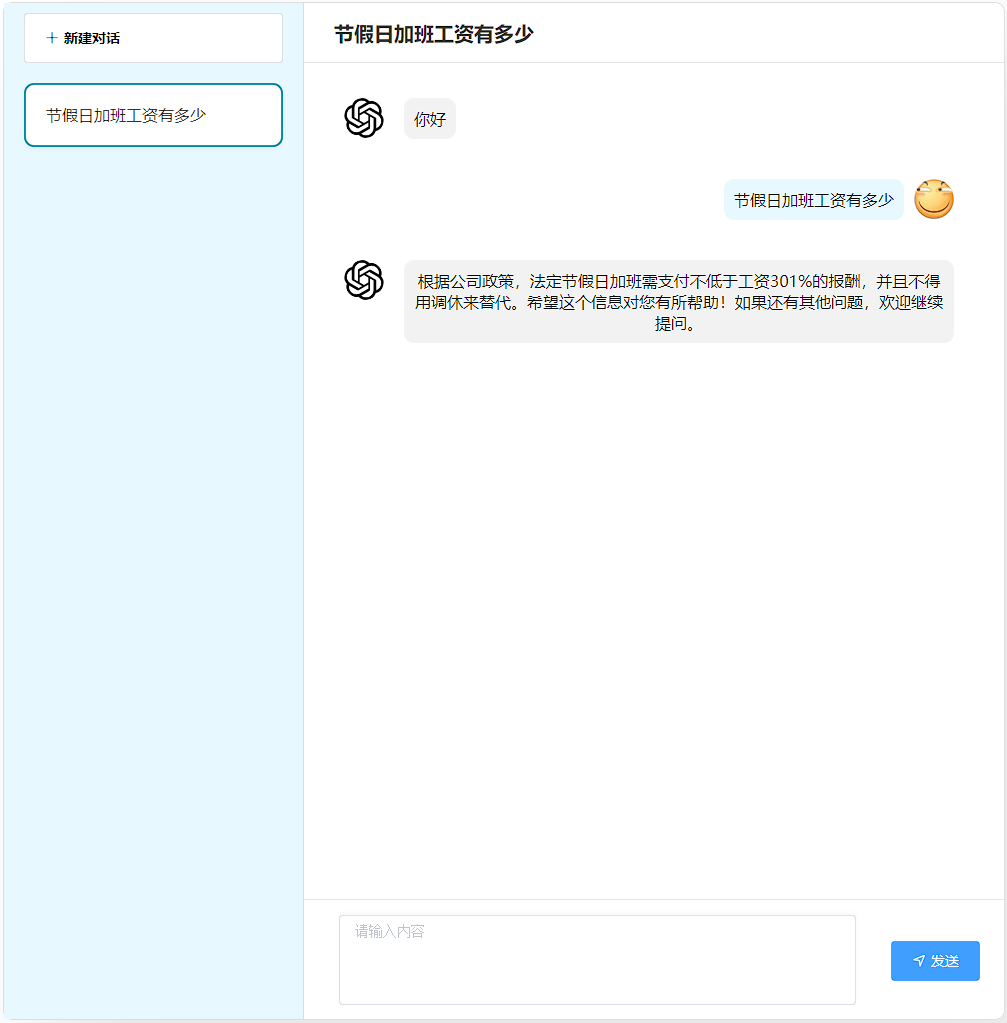
5.6.4 政策咨询
职责:基于 RAG(检索增强生成)架构,对接企业请假政策知识库,通过向量检索精准匹配政策内容,生成符合企业规范的回答,替代人工政策解读。
AI服务定义:
java
/**
* AI服务 政策咨询
*
* @author yaorongke
* @since 2025/9/9
*/
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", tools = {"chatHistoryTool", "policyConsultTool"}/*, chatMemoryProvider = "chatMemoryProvider"*/)
public interface PolicyConsultAssistant {
/**
* 政策咨询
*
* @param sessionId 会话id
* @param query 查询内容
* @return 意图识别结果
*/
@SystemMessage(fromResource = "prompt/PolicyConsult.txt")
@UserMessage("当前sessionId:{{sessionId}}; 当前用户消息:{{query}}")
String policyConsult(@V("sessionId") String sessionId, @V("query") String query);
}Tool定义:
java
/**
* Tool 政策咨询
*
* @author yaorongke
* @since 2025/9/9
*/
@Component
@Slf4j
public class PolicyConsultTool {
@Autowired
private ContentRetriever contentRetriever;
/**
* 查询公司的请假政策、流程、规定
*
* @param sessionId 会话id
* @param query 用户问题
* @return 模型返回
*/
@Tool("查询公司的请假政策、流程、规定")
public List<String> policyConsult(@P("sessionId") String sessionId, @P(value = "用户问题") String query) {
List<String> list = contentRetriever.retrieve(new Query(query)).stream().map(x -> x.textSegment().text()).toList();
log.info("政策咨询 sessionId: {}, query: {}, result: {}", sessionId, query, list);
return list;
}
}效果演示: