中科院自动化所等推出 VTCBench 基准测试,评估模型在视觉空间中的认知极限,包括信息检索、关联推理和长期记忆三大任务。
近期,DeepSeek-OCR 凭借其创新的「视觉文本压缩」(Vision-Text Compression, VTC)范式引发了技术圈的高度关注,以极少的视觉 Token 实现高效的文本信息编码,为长文本处理开辟了新路径。
这一突破性进展让大模型处理超长文本的成本大幅降低,但也抛出了一个核心问题:当长文本被高度压缩为 2D 图像后,视觉语言模型(VLM)真的能理解其中的内容吗?
为了解答这一疑问,来自中科院自动化所、中国科学院香港创新研究院等机构的研究团队推出了首个专门针对视觉 - 文本压缩范式的基准测试 ------VTCBench。

- 论文链接:https://arxiv.org/abs/2512.15649
- VTCBench 链接: https://github.com/Moenupa/VTCBench
- VLMEvalKit 链接:https://github.com/bjzhb666/VLMEvalKit
- Huggingface 链接: https://huggingface.co/datasets/MLLM-CL/VTCBench
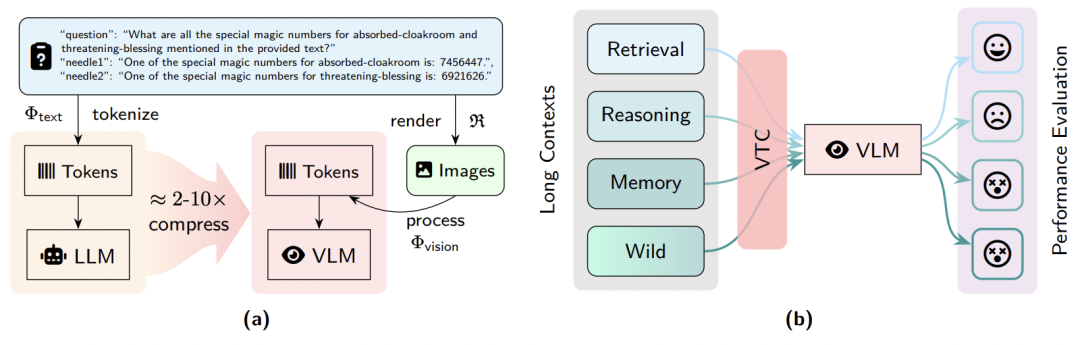
图 1:视觉 - 文本压缩 (VTC) 流程演示及 VTCBench
与传统大模型直接读取成千上万的纯文本 Token 不同,VTC 范式(如 DeepSeek-OCR)先将长文档渲染 (Rendering)为高密度的 2D 图像,再由视觉编码器转化为少量的视觉 Token。
该技术可实现 2 倍至 10 倍的 Token 压缩率,显著降低了长文本处理时的计算与显存开销。
VTCBench 现已在 GitHub 和 Huggingface 全面开源,其衍生版本 VTCBench-Wild 是一个统一的、全方位评估模型在复杂现实场景下视觉文本压缩的鲁棒性,现已集成到 VLMevalkit。
核心使命------衡量「看得见」之后的「看得懂」
目前的 VLM 也许能出色地完成 OCR 识别,但在处理 VTC 压缩后的高密度信息时,其长文本理解能力仍存疑。
VTCBench 通过三大任务,系统性地评估模型在视觉空间中的认知极限:
- VTC-Retrieval (信息检索):在视觉「大海」中寻找特定事实的「针」(Needle-in-a-Haystack),测试模型对空间分布信息的捕捉能力;
- VTC-Reasoning (关联推理):挑战模型在几乎没有文本重叠的情况下,通过关联推理寻找事实,超越单纯的词汇检索;
- VTC-Memory (长期记忆):模拟超长对话,评估模型在视觉压缩框架下,抵御时间与结构性信息衰减的能力。
此外,团队同步推出了 VTCBench-Wild,引入 99 种不同的渲染配置(涵盖多种字体、字号、行高及背景),全方位检测模型在复杂现实场景下的鲁棒性。
揭秘视觉压缩背后的认知瓶颈
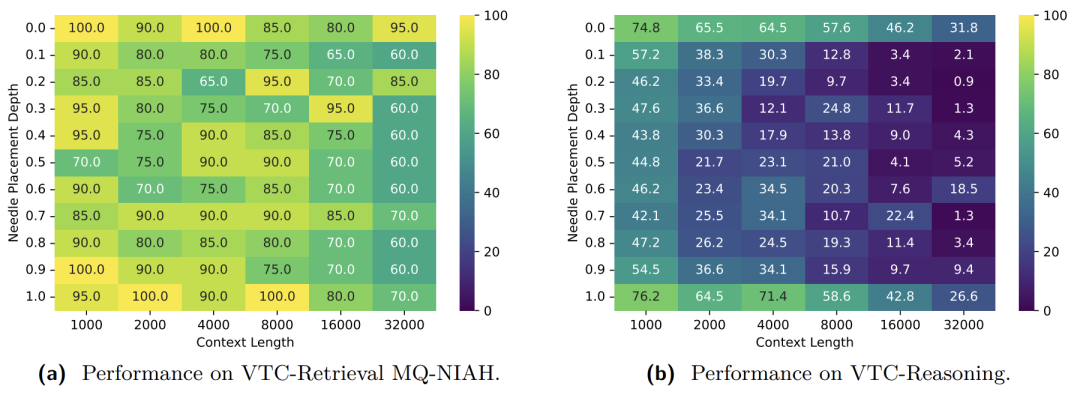
图 2:VTCBench 针对模型在长图像中检索信息的热力图。横轴代表上下文长度,纵轴代表关键事实(Needle)在文档中的深度。展现了模型表现的「迷失」与突破
测试结果呈现出显著的 「U 型曲线」:与文本模型类似,视觉语言模型(VLM)能够精准捕捉开头和结尾的信息,但对于中间部分的事实,理解能力会随着文档变长而剧烈衰退。
这证明了即使在视觉空间,模型依然存在严重的「空间注意力偏见」,是未来 VTC 架构优化的关键方向。
行业洞察 ------ 视觉压缩是长文本的终局吗?
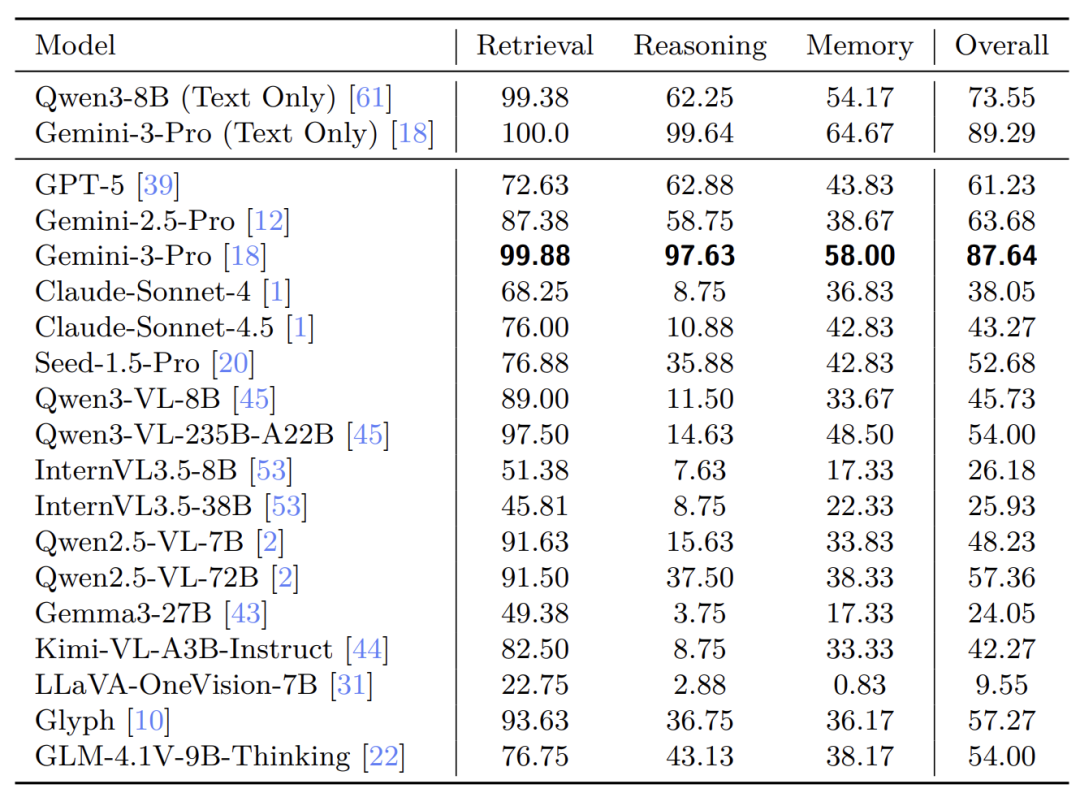
通过对 GPT、Gemini、Claude、QwenVL、InternVL、Gemma、KimiVL、Seed1.5 等 10 余种尖端模型的深度评测,可以发现:
虽然 VTC 极大提升了效率,但现有 VLM 在复杂推理和记忆任务上的表现仍显著弱于纯文本 LLM;
消融实验证明,信息密度是决定模型性能的关键因素,直接影响视觉编码器的识别精度;
Gemini-3-Pro 在 VTCBench-Wild 上表现惊艳,其视觉理解能力已几乎追平其纯文本基准,证明了 VTC 是实现大规模长文本处理的极其可行的路径!
总结
如果说传统的长文本处理是「逐字阅读」,那么, DeepSeek-OCR 所引领的 VTC 范式就是「过目成诵」的摄影式记忆。VTCBench 的出现,正是为了确保模型在拥有这种「超能力」的同时,依然能够读懂字里行间的微言大义。
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。