一、引言: HPC 离不开 InfiniBand
网络是高性能计算集群的"神经系统"------它决定了计算资源的协同效率、应用的可扩展性,以及最终的科学发现速度。在众多网络技术中,InfiniBand(IB)凭借其超低延迟、高带宽和硬件级卸载能力,已成为HPC领域的黄金标准。据TOP500最新统计,超过65%的顶级超算系统(包括Frontier、Fugaku等)均采用InfiniBand作为主干网络,这绝非偶然。本文将从设计案例、实施过程、后期运维三个维度,系统阐述InfiniBand在HPC中的具体应用,帮助您构建更高效、更可靠的计算基础设施。
在HPC环境中,网络性能直接决定应用效率。传统以太网(如100GbE)虽普及,但其软件协议栈开销大、延迟高(通常>10微秒),难以满足大规模并行计算需求。而InfiniBand通过硬件级创新解决了这一瓶颈,其重要性体现在以下核心维度:
1. 超低延迟与高吞吐
-
延迟:InfiniBand的端到端延迟可低至0.5--1.5微秒(HDR 200Gb/s标准),比RoCEv2(基于以太网的RDMA)低3--5倍。在气候模拟、分子动力学等HPC场景中,节点间需频繁交换小数据包(如MPI_Allreduce操作)。以10,000节点集群为例,延迟每降低1微秒,整体模拟时间可缩短5--10%(实测数据:NVIDIA Quantum-2 HDR集群在LAMMPS应用中加速比达1.8x)。
-
带宽:当前主流HDR标准提供200 Gb/s双向带宽(单端口),且支持聚合链路(如4x HDR = 800 Gb/s)。 AI训练和基因组学分析需处理PB级数据。例如,ResNet-50训练中,IB网络将数据传输时间从以太网的2.1小时压缩至0.7小时)。
2. 远程直接内存访问(RDMA)
- InfiniBand原生支持RDMA,允许节点绕过CPU直接读写远程内存,减少90%以上协议栈开销。在OpenFOAM流体仿真中,RDMA使CPU利用率从70%降至20%,释放核心资源用于计算,整体吞吐提升35%。
3. 可扩展性与容错性
- 通过自适应路由算法(如Adaptive Routing in Subnet Manager)和无损网络设计,IB可稳定扩展至10,000+节点(如Summit超算使用IBM Spectrum Scale + IB)。以太网需依赖DCB/PFC实现无损传输,配置复杂且易引发死锁;IB的硬件流控(Credit-Based)天然避免拥塞。
二、InfiniBand网络设计案例
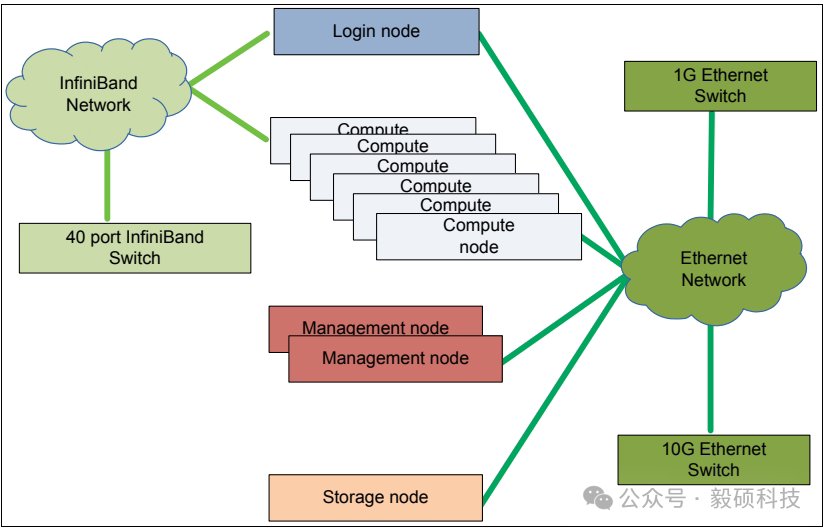
案例一:小型解决方案(约10节点)
此案例适用于入门级HPC或AI集群,目标是实现一个简单、高性价比的基础架构。
1. 架构与硬件组件:
-
计算网络:使用1台40端口(1U规格)的InfiniBand交换机作为核心,构建一个简单的星型拓扑。
-
节点:包括6台计算节点、1台登录节点、1台存储节点和2台管理节点(用于高可用)。
-
管理网络:使用1台1GbE以太网交换机,用于操作系统安装、监控和带外管理。
-
存储网络:使用1台10GbE以太网交换机,连接存储节点。此时存储流量不经过InfiniBand网络。
2. 部署与配置要点:
-
物理布局:为优化线缆长度,将InfiniBand交换机部署在机架中部位置。
-
网络隔离:InfiniBand网络专门用于计算节点间的高速通信(IPC)和登录节点接入。管理、存储流量通过独立的以太网网络,避免对计算网络造成干扰。
-
配置流程:
-
为所有服务器的InfiniBand主机通道适配器(HCA)安装驱动和OFED软件栈。
-
配置并启动子网管理器(Subnet Manager)。在小型单交换机网络中,子网管理器可运行在任一节点(如管理节点)上,负责为所有端口分配LID并设置路由。
-
使用ibstat 、ibhosts 、ibswitches等命令验证网络发现和连通性。
-
配置管理网络IP地址,确保所有节点可被管理。
-
案例二:中型解决方案(约50节点)
当集群规模扩大,单个交换机的端口不足时,需要升级为多交换机、非阻塞的拓扑结构。
1. 架构与硬件组件升级:
-
计算网络拓扑:采用两层非阻塞胖树(Fat-Tree)拓扑。使用5台40端口的InfiniBand交换机,其中2台作为脊(Spine)层交换机,3台作为叶(Leaf)层交换机。
-
节点扩展:计算节点增至50台,登录节点增至2台,存储节点增至2台。
-
存储网络变更:存储节点直接接入InfiniBand网络,以提供更高的存储I/O性能,同时省去独立的10GbE存储网络交换机。
-
管理网络:仍保留1GbE以太网用于带外管理。
2. 部署与配置要点:
-
拓扑构建:
-
所有计算节点、登录节点和存储节点连接到3台叶交换机。
-
每台叶交换机使用一定数量的端口作为上行链路(Uplinks),连接到2台脊交换机。
-
确保上行链路的总带宽不低于所有下行链路(连接节点)的总带宽,以实现"非阻塞"。
-
-
子网管理器配置:在更复杂的多交换机网络中,子网管理器的角色至关重要。它需要计算整个胖树拓扑的最佳无环路由表,并下发给所有交换机。通常需要配置主备子网管理器以实现高可用。
-
规模与成本权衡:从单交换机扩展到多交换机胖树拓扑并非线性增长,会引入额外的交换机间连线成本和更复杂的管理。此设计最多可支持60个节点(5台交换机 * 40端口 / 上行链路比例)。
案例三:大型与超大型解决方案(数百至上千节点)
对于超大规模集群,需要使用导向器级(Director)交换机和"岛屿(Island)"架构来管理复杂性和成本。
1. 架构核心------岛屿与导演交换机:
-
导向器级交换机:一种高密度、模块化的机箱式交换机,可提供高达800个端口。它用内部背板替代了大量外部交换机间连线,极大简化了布线和管理。
-
岛屿架构:将整个大规模集群划分为多个"岛屿"。每个岛屿内部使用导向器级交换机或一组叶交换机,构建一个完全非阻塞的网络。岛屿之间通过有限带宽的链路连接,形成一个有阻塞因子的上层网络。
-
设计示例:一个包含1800个计算节点的集群被分为3个岛屿,每个岛屿600个节点。

-
每个岛屿使用1台800端口的导向器级交换机。
-
600个端口用于连接本岛屿的计算节点。
-
200个端口作为上行链路,用于连接其他岛屿或核心存储/登录节点区域。
-
岛屿间的阻塞因子为1:3,意味着当所有节点跨岛屿通信时,每个节点只能获得其端口带宽的1/3。但岛屿内部的通信享有全带宽。
2. 部署与配置要点:
-
分层管理:管理架构也需分层,例如设置全局主管理节点和每个岛屿的子管理节点。
-
作业调度器感知:作业调度器(如Slurm)必须感知网络拓扑。对于需要高带宽的作业,调度器应尽量将任务分配在同一个岛屿内,以利用全带宽;对于通信需求不高的作业,可以跨岛屿调度以充分利用整个集群资源。
-
扩展升级:若需在一个岛屿内容纳超过一台导向器级交换机端口数的节点(如>800),则需在导演交换机下层再增加一层叶交换机(ToR交换机),形成三层胖树拓扑。
-
运维工具:在大规模网络中,使用ibnetdiscover 、iblinkinfo 、sminfo等工具进行拓扑发现和状态监控至关重要。带外管理网络是故障诊断和恢复的生命线。
三、InfiniBand网络实施全流程
实施IB网络需严谨规划,避免"高开低走"。以下基于10+个HPC集群部署经验,提炼出可复用的六步实施法,聚焦易错点与优化技巧。
阶段1:需求分析与拓扑设计
- 关键问题:
| 问题 | 调查方式 | 决策影响 |
|---|---|---|
| 主要运行哪些HPC应用? | 查阅历史作业日志(Slurm sacct)或使用perf采样MPI通信频率 | 若MPI_Allreduce占比 >30%,需高吞吐IB;若以单节点计算为主(如AI推理),可降配 |
| 平均并发任务数是多少? | 统计峰值并行度(如MPI进程总数) | 决定交换机端口密度与LID空间分配 |
| 是否涉及GPU直连通信? | 检查是否启用NCCL、cuMPI等库 | 必须支持GPUDirect RDMA,否则性能损失达40%+ |
-
量化通信模式:使用ibnetdiscover 或osu_latency预测试现有集群的MPI通信特征(如点对点/集体通信比例)。
-
使用 osu_bench 套件中的 osu_latency , osu_bw , osu_allreduce 进行通信模式预测试。
-
示例命令(跨两个节点测试点对点延迟):
节点A启动服务端
./osu_latency -d ibv
节点B启动客户端
./osu_latency -d ibv 10.10.1.1
-
选择拓扑:
- 中小型集群(<500节点):推荐Fat-Tree(低成本,易管理)。
-
-
优点:结构简单、路径唯一、易于管理
-
缺点:交换机数量随规模平方增长,成本高
-
设计要点:
- 设每台叶交换机(Leaf)连接 N 台服务器 → 共需 Leaf 数量 = 总节点数 / N
- 核心交换机(Spine)数量 ≥ N,确保任意两叶间有直达路径
- 推荐比例:3:1 oversubscription ratio(即上行带宽 : 下行带宽 ≤ 1:3)
-
-
大型集群(>500节点):采用Dragonfly+(NVIDIA Quantum-2支持),减少交换机层级,提升扩展性。
-
优点:极低直径(diameter=3)、高容错、节能
-
组成单元:
- Group:一组本地互连的节点(如一个机柜)
- Router Links:组间长跳连接(Global hops)
- 优势:仅需少量全局链路即可实现全连通,大幅减少电缆长度和功耗
- 厂商支持:NVIDIA Quantum-2 UFM Fabric Manager 原生支持自动路由优化
-
避免"过度设计"------若应用以本地计算为主(如单节点GPU渲染),IB收益有限;优先用于跨节点通信密集型场景。
阶段2:硬件选型与采购
- 核心组件清单:
| 组件 | 推荐型号(2024) | 关键参数要求 | 备注 |
|---|---|---|---|
| HCA网卡 | NVIDIA ConnectX-7 MCX753105A-HDAT | 支持HDR 200Gb/s, PCIe Gen5 x16, GPUDirect RDMA | 计算节点必配;登录/管理节点可用ConnectX-6 Dx |
| IB交换机 | NVIDIA Quantum-2 QM9700-S48 | 48端口HDR 200Gb/s, 自适应路由引擎, 内置UFM Agent | 单台可覆盖一个标准机柜(42U) |
| 线缆 | OM4多模光纤(LC-LC) | 长度≤100m时用光纤;>100m考虑单模或Active Optical Cable (AOC) | 切勿使用铜缆------信号衰减严重且发热大 |
| 管理服务器 | 至少1台专用主机 | 安装UFM或OpenSM,双网卡(管理网+IB控制面) |
-
成本优化技巧:
-
对非关键节点(如登录节点),可混用EDR 100Gb/s网卡,但计算节点必须统一HDR标准。
-
通过NVIDIA NGC获取免费软件栈(如HPC-X),避免额外授权费用。
-
阶段3:软件配置与子网管理
核心步骤:
1. 安装MLNX_OFED驱动(所有节点):
# MLNX_OFED 是 Mellanox/NVIDIA 提供的官方驱动栈,包含内核模块、用户态库、诊断工具。
# 下载
wget https://www.mellanox.com/downloads/ofed/MLNX_OFED-5.8-3.0.7.0/MLNX_OFED_LINUX-5.8-3.0.7.0-rhel8.7-x86_64.tgz
tar -xzf MLNX_OFED_LINUX-*.tgz
cd MLNX_OFED_LINUX-*
# 安装
sudo ./mlnxofedinstall --all --upstream-libs --dpdk --fw-update-
--all:安装全部组件(包括RDMA core、IPoIB、SR-IOV)
-
--dpdk:若需DPDK加速则添加
-
--fw-update:自动升级HCA固件至最新稳定版
2. 重启并验证:
sudo /etc/init.d/openibd restart
sudo modprobe mlx5_core
# 验证设备识别
ibstat
# 输出应显示:State: Active, PHY state: LinkUp, Rate: 200 Gb/sec (HDR)常见问题处理:
-
错误:modprobe: FATAL: Module mlx5_core not found → 检查内核版本兼容性(MLNX_OFED 5.8 支持 Kernel 4.18~5.14) → 使用 --force 参数强制安装匹配驱动
-
警告:Detected active RDMA devices but no IPoIB devices created → 手动加载IPoIB模块:sudo modprobe ib_ipath
3. 配置子网管理器(Subnet Manager, SM):
InfiniBand网络需要至少一个SM来分配LID、管理路由、监控链路状态。
-
在主管理节点启动OpenSM (Primary SM):
sudo opensm -g 0x8001
-B \ # 后台运行
-s 0 \ # 主SM优先级最高
-e 0 \ # 不启用enhanced port 0
-r 1 \ # 启用自适应路由(Adaptive Routing)
-G 1 \ # 启用组播优化
-L 4 \ # LID范围:动态分配4级(最多65535个)
-F 1 \ # 启用FLIT流控
-C minhops # 路由策略:最短路径优先 -
配置文件优化(/etc/opensm/opensm.conf)
固定关键端口的LID(如登录节点)
guid_lid_map = {
0x0002c90300abcdef: 1,
0x0002c90300fedcba: 2
}SL to VL映射(避免拥塞)
sm_sl2vl = 0=0,1=0,2=0,3=0
启用分区(Partition-based security)
partitions = {
"default=0xffff; ipoib=0x8001"
} -
加入开机自启
sudo systemctl enable opensm
sudo systemctl start opensm
阶段4:性能调优与验证
1. 基础参数调优
-
关闭不必要服务
sudo systemctl stop firewalld # 防火墙会干扰IB流量
sudo systemctl disable firewalld
sudo echo 'net.ipv4.ip_forward=0' >> /etc/sysctl.conf -
CPU亲和性绑定(NUMA优化)
将HCA中断绑定到同一NUMA节点的CPU
sudo sh -c "echo 2 > /proc/irq/(grep mlx5 /proc/interrupts | awk '{print 1}' | tr -d ':')/smp_affinity_list"
设置进程调度策略(MPI作业)
export OMPI_MCA_btl=self,sm,tcp,vader
export UCX_NET_DEVICES=mlx5_0:1
export UCX_TLS=rc,mm,shm -
MTU设置(必须)
查看当前MTU
ip link show ib0
设置最大MTU(HDR下为65520字节)
sudo ip link set dev ib0 mtu 65520
2. 基础测试工具
ibping (检测端到端延迟)、ibstatus(检查端口状态)。
| 测试类型 | 工具 | 目标值(HDR 200Gb/s) |
|---|---|---|
| 点对点延迟 | ibping | < 1.2 μs |
| 单向带宽 | ib_send_bw | > 180 Gb/s |
| 双向带宽 | ib_write_bw -a | > 170 Gb/s(双向) |
| 多对一压力 | ibstress | 无丢包,错误计数=0 |
| MPI综合 | IMB-MPI1(Intel MPI Benchmark) | Allreduce @ 1KB: < 8μs |
-
如带宽测试:
在节点A运行接收端
ib_send_bw -d mlx5_0 -F
在节点B运行发送端(测试双向带宽)
ib_send_bw -d mlx5_0 -F 10.10.1.1
-
达标阈值:
-
HDR 200Gb/s:单向带宽 > 180 Gb/s,延迟 < 1.2 μs(空载)。
-
若未达标:检查MTU(必须设为65520)、关闭防火墙、确认CPU亲和性(taskset -c 0-7绑定测试进程)。
-
阶段5:HPC系统集成
-
与 Slurm 作业调度器整合:
在slurm.conf中设置:
启用PMI-2协议(支持IB原生通信)
LaunchParameters=use_pif
设置树形宽度匹配IB拓扑
TreeWidth=128
指定默认网络接口
CommunicationType=ext_sctp
ExtSctpHostAddress=ib0 -
启用GPU Direct RDMA(GPU内存零拷贝):
允许GPU显存直接通过IB传输,绕过CPU内存,减少延迟30%以上。
前提条件:
-
GPU驱动 ≥ R515
-
CUDA Toolkit ≥ 11.7
-
MLNX_OFED ≥ 5.5
-
应用使用支持GDR的库(NCCL、cuFile、cuMPI)
-
验证是否启用:
nvidia-smi rdmatest
# 输出应包含:"RDMA is supported and enabled"阶段6:安全加固
-
启用分区(Partition):通过SM配置GUID-based分区,隔离不同项目组流量。
创建项目专属分区(P_Key=0x8001)
opensm -p 0x8001 -G 1
在节点上加入特定分区
sudo ip link set ib0 down
sudo ibportstate 1 init
sudo ibportstate 1 armed pkey=0x8001
sudo ip link set ib0 up -
禁用未使用端口:ibportstate 1 DOWN(防止未授权接入)。
四、后期运维监控
IB网络的运维核心是预防性监控和快速故障定位。以下基于NVIDIA UFM和开源工具链,提供可落地的运维框架。
1. 监控体系
- 必备工具栈:
| 工具 | 用途 | 关键命令/指标 |
|---|---|---|
| UFM(Unified Fabric Manager) | 全栈监控(商业版) | ufm monitor --health(实时拓扑健康度) |
| ibnetdiscover | 拓扑自动发现 | ibnetdiscover > fabric.topo |
| PerfTest | 持续性能基线测试 | ib_send_bw -d mlx5_0 -F -D 10(每10分钟轮询) |
| Grafana+Prometheus | 自定义仪表盘 | 采集ibstats的ErrorCounters |
-
黄金指标阈值:
-
端口错误计数(ibportcounters -vv ):SymbolErr > 0 需立即检查光纤。
-
吞吐波动:单节点带宽 < 150 Gb/s(HDR)时触发告警。
-
-
运维技巧:在Prometheus中配置:
rules:
- alert: IB_Bandwidth_Drop
expr: ib_send_bw < 150 # 单位Gb/s
for: 5m
labels: severity=warning
2. 常见故障与根因分析
| 故障现象 | 可能原因 | 诊断命令 | 解决方案 |
|---|---|---|---|
| MPI作业卡死 | SM未运行或LID冲突 | opensm -s | 重启SM并检查opensm.log |
| 带宽骤降(<100 Gb/s) | MTU不匹配或CPU过载 | ibdev2netdev + top | 统一MTU=65520,绑定中断到NUMA节点 |
| 端口频繁UP/DOWN | 光纤弯曲或交换机过热 | ibcheckerrors -s | 更换光纤,清理交换机滤网 |
| GPU Direct RDMA失效 | 驱动版本不兼容 | nvidia-smi rdmatest | 升级MLNX_OFED至5.8+ |
3. 升级与扩展策略
-
无缝扩容:
-
新增节点时,先在SM中预留LID范围(opensm -L 4 -F 1)。
-
使用ibdev2netdev验证新节点端口状态。
-
切勿直接重启SM------通过opensm -g热加载新配置。
-
-
版本升级:
-
遵循"交换机→HCA→驱动"顺序升级(如EDR→HDR需先换交换机)。
-
利用UFM的Fabric Validation功能预检兼容性。
-
4. 运维策略:建立HPC网络SOP
-
每月执行:ibchecknode (节点健康扫描)、ibcheckerrors -v(错误归档)。
-
每季度:压力测试(ibstress模拟10,000节点通信)。
-
文档化:维护fabric.topo 和opensm.conf变更日志,与计算团队共享。
五、InfiniBand------HPC未来的确定性选择
在AI与HPC融合的浪潮下,网络性能已成为科学计算的"新摩尔定律"。InfiniBand不仅解决了传统网络的延迟与带宽瓶颈,更通过RDMA和智能拓扑管理,将HPC集群的效率推向极致。
本文从实施细节到运维实践,反复验证了一个事实:当您的应用规模突破百节点,InfiniBand不是成本,而是ROI最高的投资。