
一、研究背景
- 针对传统TCN和Transformer模型在超参数选择上依赖经验的问题,引入粒子群优化算法自动寻优。
- 旨在提升模型在序列回归任务中的预测精度与泛化能力,适用于论文研究、竞赛建模和工程预测。
二、主要功能
- 数据预处理:归一化、划分训练/测试集。
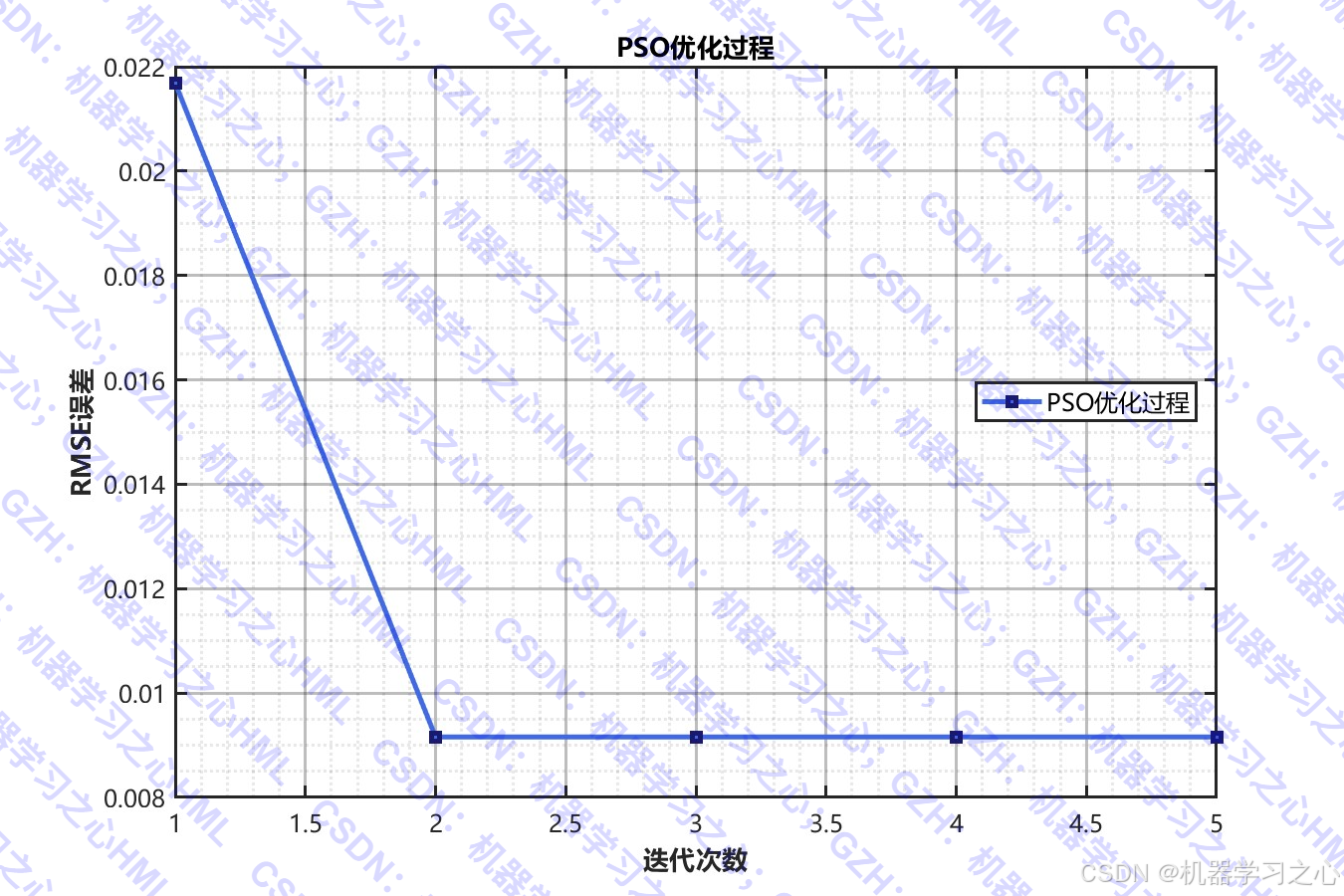
- 超参数自动优化:使用PSO优化TCN和Transformer的关键参数。
- 构建TCN-Transformer混合网络:结合TCN的时序特征提取与Transformer的注意力机制。
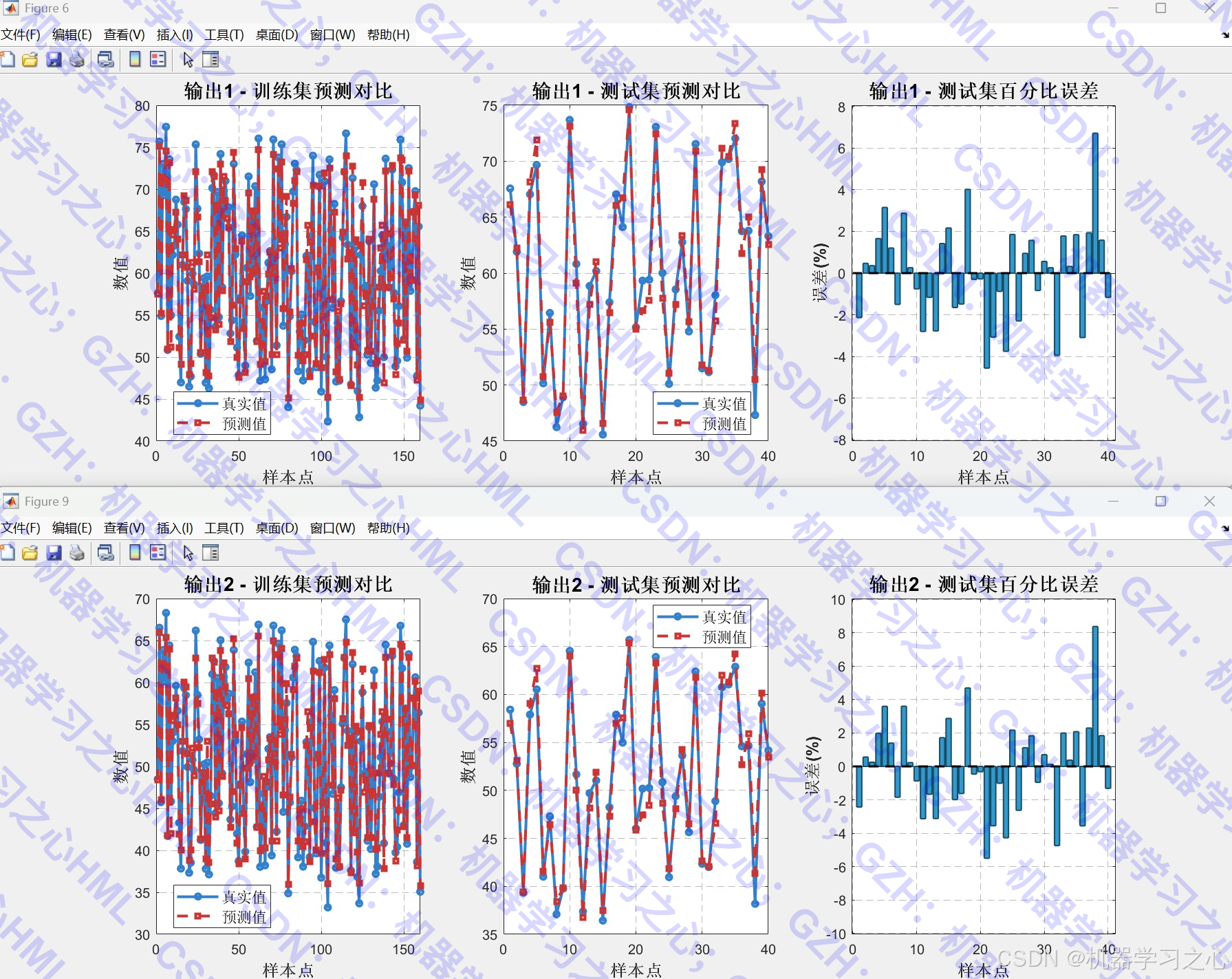
- 模型训练与预测:支持多输出回归任务。
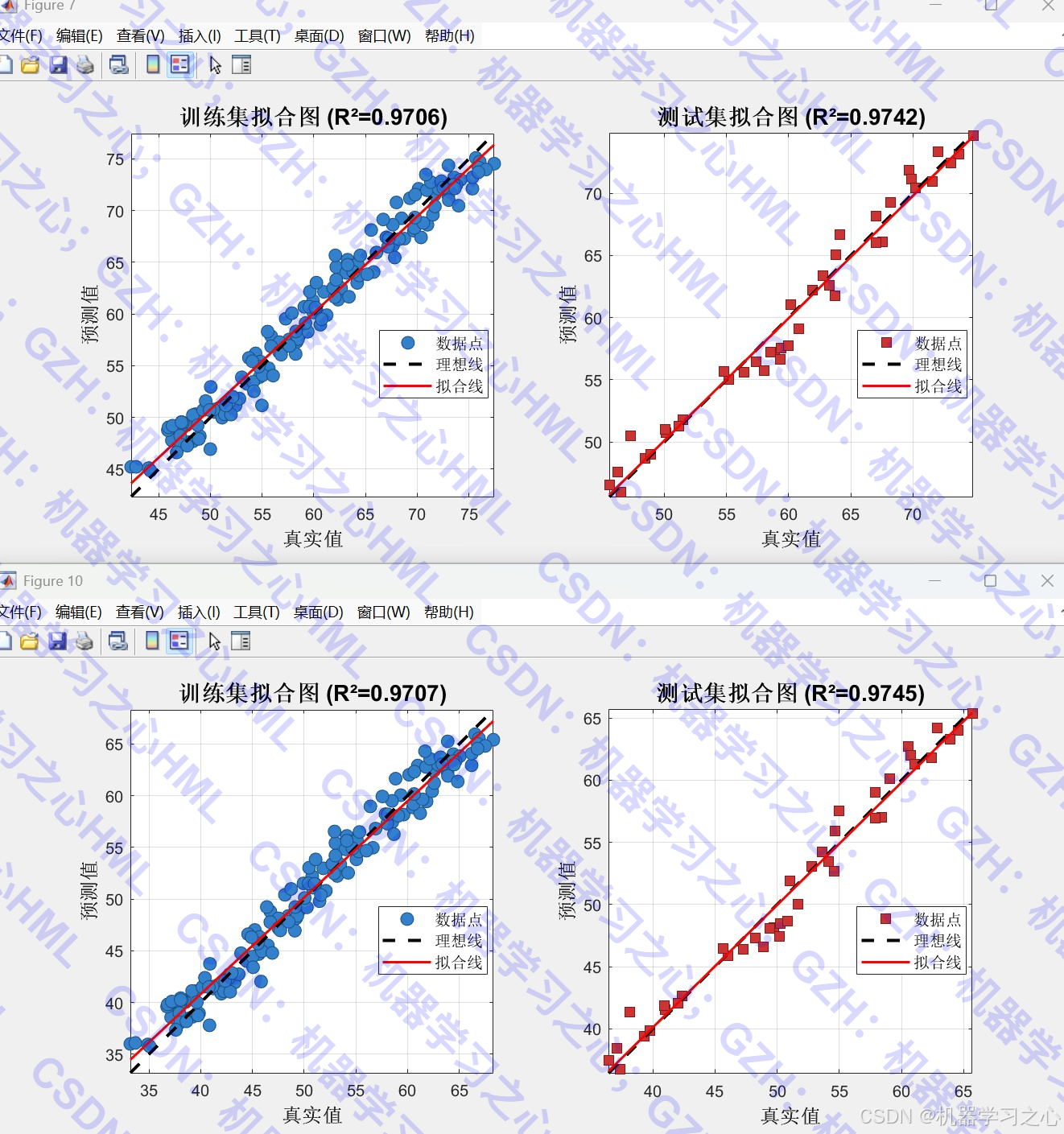
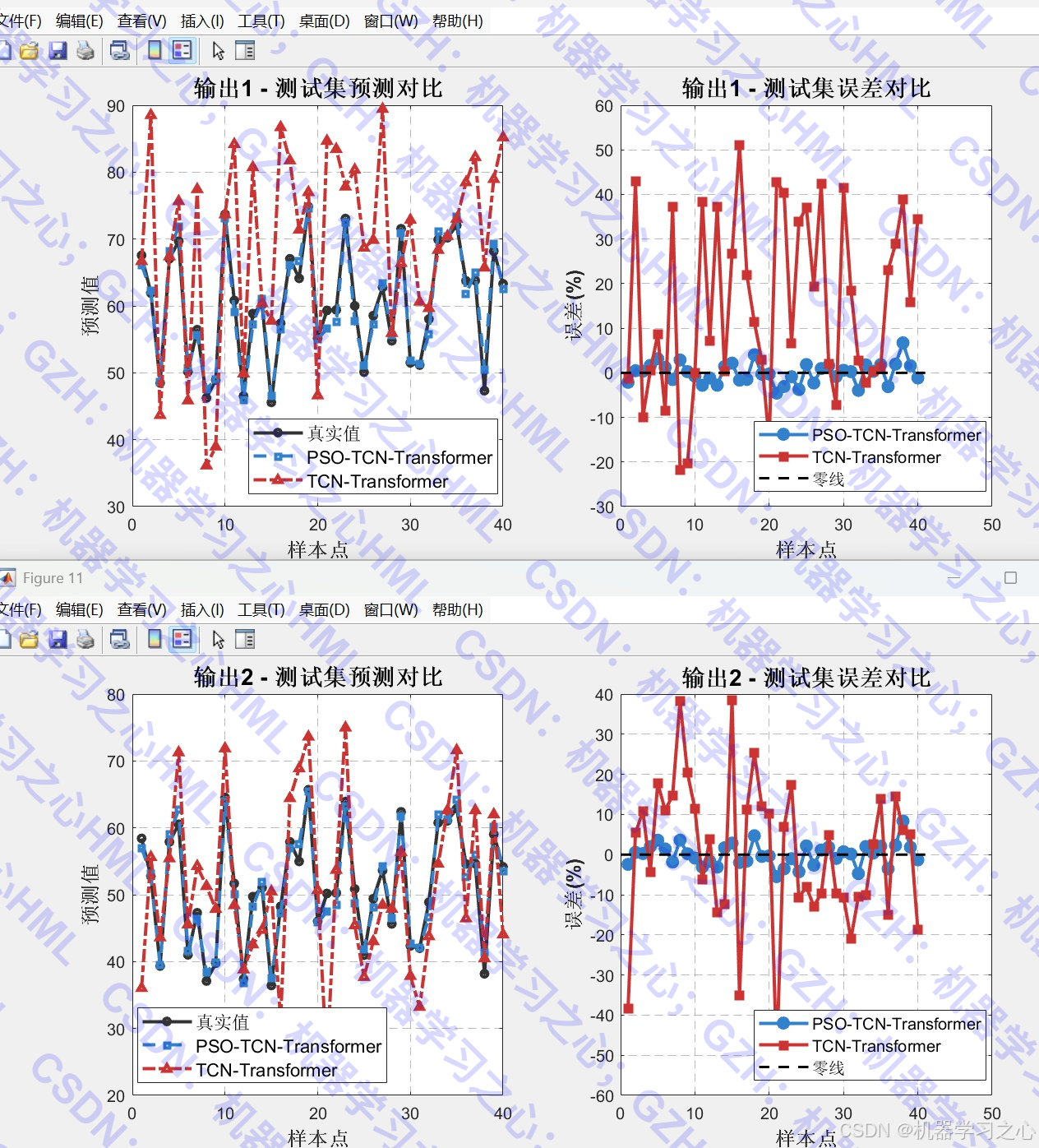
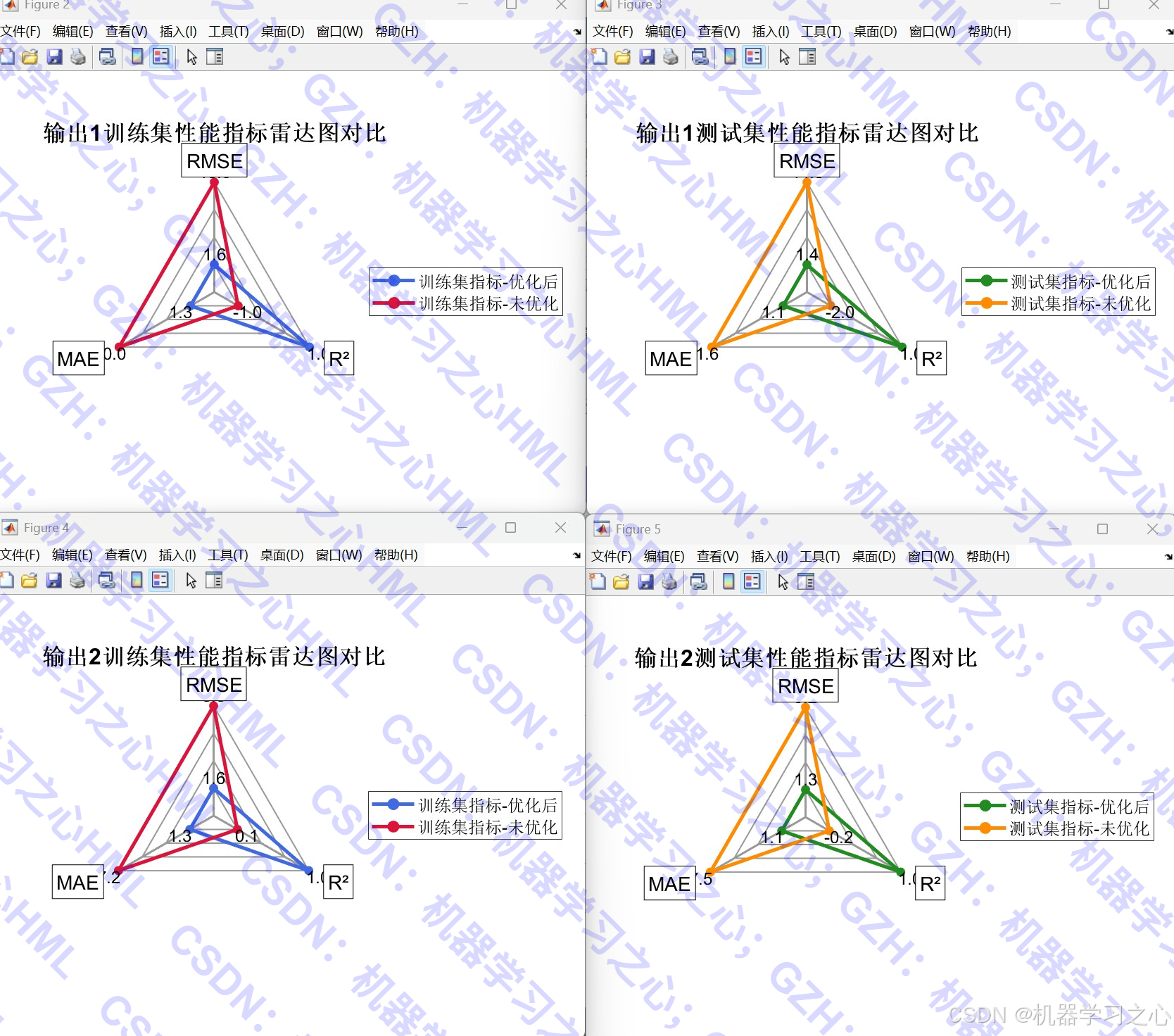
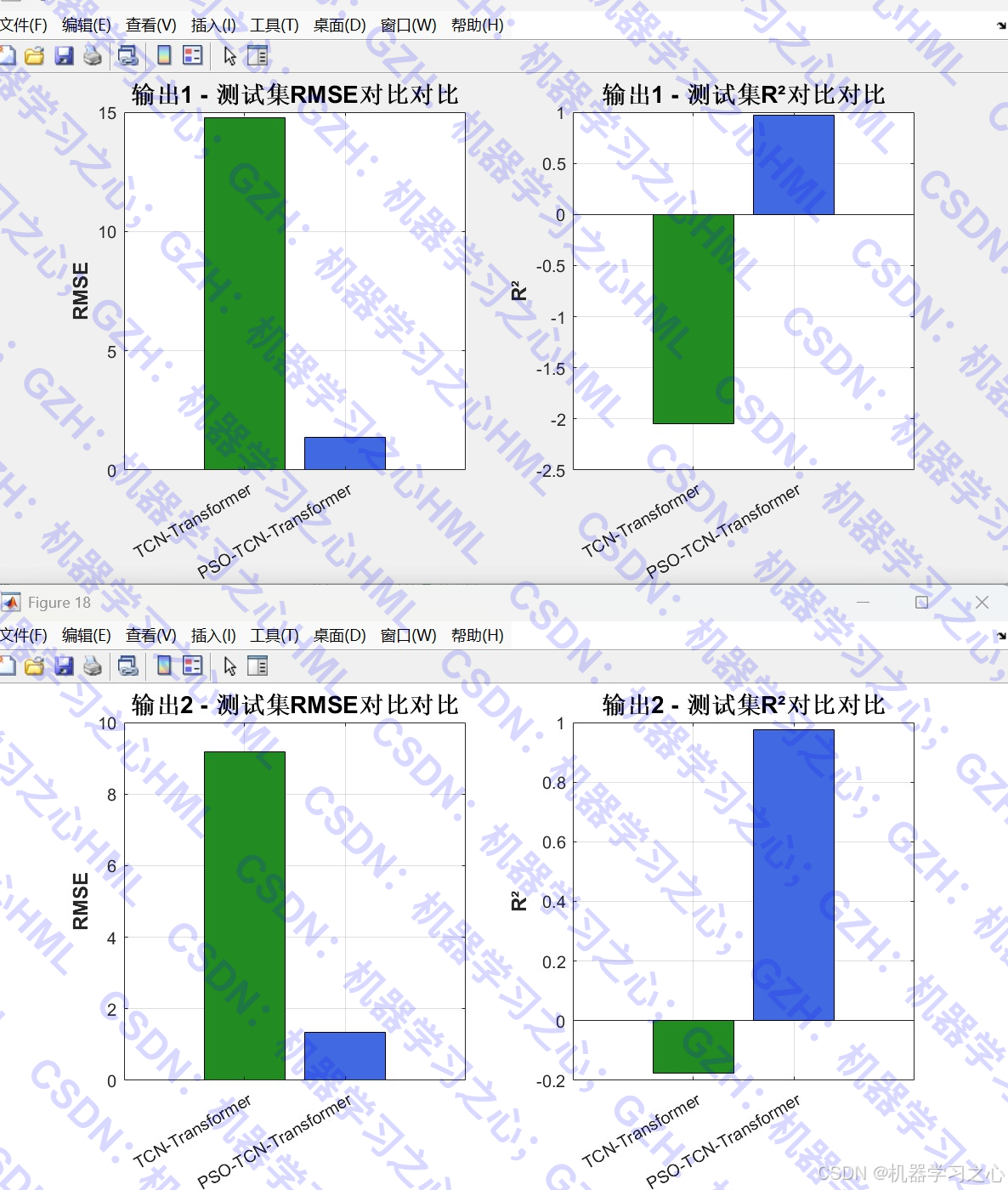
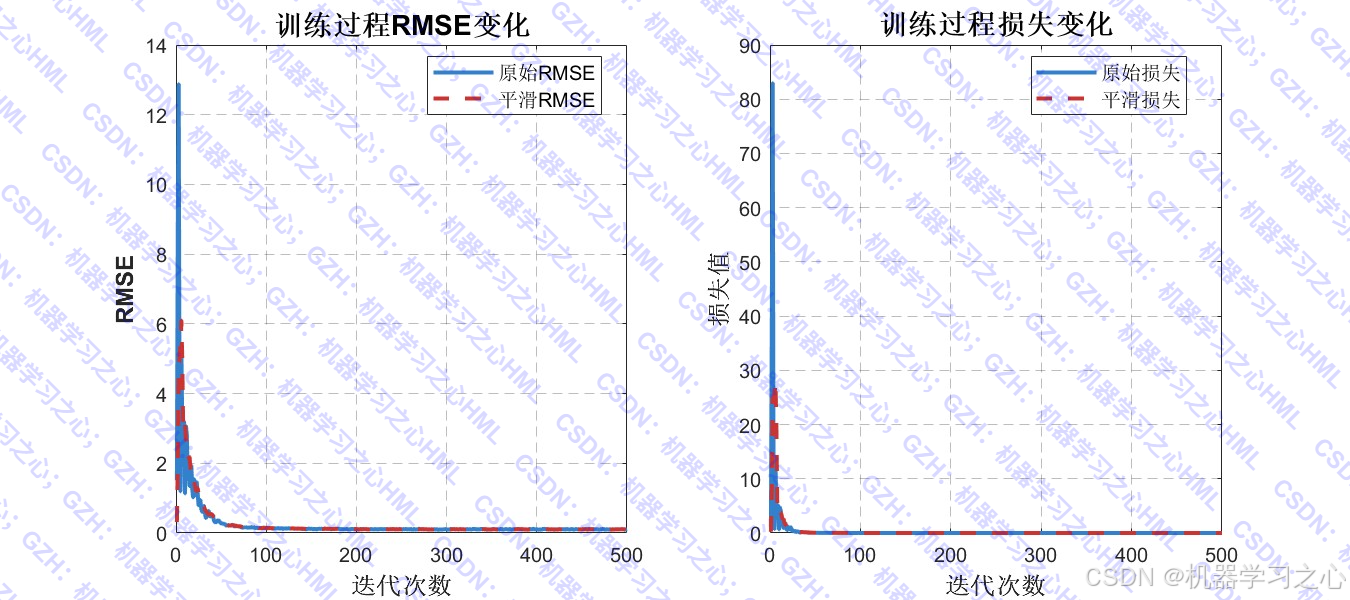
- 可视化分析:包括优化过程曲线、雷达图、拟合图、误差对比、特征重要性分析等。
- 新数据预测与结果保存:支持外部数据输入与预测结果导出。
三、算法步骤
- 读取数据并进行归一化。
- 划分训练集与测试集。
- 使用PSO优化以下超参数:
- TCN卷积核数量
- 卷积核大小
- 丢弃率
- TCN层数
- Transformer注意力头数
- 使用优化后的参数构建TCN-Transformer网络。
- 训练模型并进行预测。
- 评估模型性能,对比优化前后结果。
- 可视化展示与结果保存。
四、技术路线
- 数据流:输入 → 归一化 → TCN特征提取 → 位置编码 → Transformer自注意力 → 全连接输出。
- 优化方法:PSO作为外层优化器,以验证集RMSE为适应度函数。
- 模型融合:TCN提取局部时序特征,Transformer捕捉长距离依赖关系。
五、公式原理
-
TCN:使用因果卷积与膨胀卷积,数学形式为:
yt=∑k=1Kwk⋅xt−d⋅k y_t = \sum_{k=1}^{K} w_k \cdot x_{t - d \cdot k} yt=k=1∑Kwk⋅xt−d⋅k
其中 (d) 为膨胀因子。
-
Transformer自注意力:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
-
PSO更新公式:
vit+1=wvit+c1r1(pi−xit)+c2r2(g−xit) v_i^{t+1} = w v_i^t + c_1 r_1 (p_i - x_i^t) + c_2 r_2 (g - x_i^t) vit+1=wvit+c1r1(pi−xit)+c2r2(g−xit)
xit+1=xit+vit+1 x_i^{t+1} = x_i^t + v_i^{t+1} xit+1=xit+vit+1
六、参数设定
- PSO参数 :种群数
N=8,迭代次数Max_iteration=5。 - TCN参数范围 :
- 卷积核数量:232^323 ~ 272^727(即8~128)
- 卷积核大小:3~9
- 丢弃率:0.001~0.5
- TCN层数:2~5
- Transformer参数范围 :
- 注意力头数:2~6
- 训练参数:Adam优化器,初始学习率0.01,最大迭代500轮。
七、运行环境
- 软件环境:MATLAB(建议R2024a及以上)
- 依赖工具箱 :
- Deep Learning Toolbox
- Optimization Toolbox
- 自定义函数包:
OA_ToolBox\、spider_plot\
- 数据格式 :Excel文件(
回归数据.xlsx、新的多输入.xlsx)
八、应用场景
- 多输出回归预测:如气温与湿度预测、股票多指标预测、工程多目标优化等。
- 研究对比实验:提供优化前后对比,适合学术论文中的算法比较。