Confluent它不是一个单一工具,而是基于 Apache Kafka 打造的 "Kafka 全家桶 / 一站式流数据平台",目的是解决纯 Kafka 部署、使用、运维中的各种痛点,让企业能更便捷地落地流数据架构。
核心关系:Confluent Platform vs Apache Kafka
Apache Kafka 是一个开源的分布式流处理平台(核心是消息队列 + 流存储),但它只是一个 "核心引擎",就像一辆汽车的发动机。
而 Confluent Platform 5.2.4 是以 Apache Kafka 2.2.x 为核心引擎(版本强绑定,Confluent 的版本号和 Kafka 不是一一对应,但 5.2.4 内置了稳定版的 Kafka 2.2),额外封装、集成了一系列配套工具和组件的完整解决方案,相当于给发动机配上了底盘、车身、方向盘、导航等,直接变成一辆能上路的完整汽车。
Confluent 5.2.4 的核心价值(为什么企业不用纯 Kafka 而选它)
纯 Kafka 存在一些 "使用门槛":比如数据格式不统一、对接外部系统(数据库 / ES / 文件系统)麻烦、缺乏可视化运维工具、没有企业级的安全和监控能力等。
Confluent 5.2.4 就是为了解决这些问题而生,核心价值可以总结为:
- 降低使用门槛:提供开箱即用的配套工具,不用自己二次开发对接各种系统;
- 提升运维效率:提供可视化界面、监控告警、一键部署等能力,减少运维成本;
- 增强企业级能力:补充安全认证、数据校验、高可用保障等纯 Kafka 缺失的企业级特性;
- 完善生态闭环:从数据采集、传输、存储、处理、消费到监控,形成完整的流数据链路。
Confluent 5.2.4 的组件围绕 Kafka 形成完整生态,核心组件可以分为 "核心必备" 和 "生态配套" 两类,下面逐个通俗解释:
(一)核心必备组件(相当于汽车的核心部件,缺一不可)
-
Apache Kafka(内置核心) 这是整个 Confluent 平台的 "心脏",负责核心的消息接收、存储、转发。可以把它理解为一个 "分布式、高容量、高可靠的消息中转站":
- 上游系统(比如电商网站、物流系统)产生的实时数据(订单创建、物流轨迹更新),先发送到 Kafka;
- 下游系统(比如数据分析平台、报表系统、风控系统)从 Kafka 中订阅并消费这些数据;
- 它的核心优势是能扛住高并发、数据不丢失、支持海量数据存储和回溯。
-
**Confluent Schema Registry(模式注册表)**这是 Confluent 最核心的特色组件之一,解决纯 Kafka 的 "数据格式混乱" 问题,相当于一个 "流数据的格式说明书仓库"。
- 纯 Kafka 中的消息是 "二进制字节流",发送方和接收方如果没有约定好格式,接收方根本无法解析数据(就像两个人说话没有共同语言);
- Schema Registry 采用 Avro(主流)、Protobuf 等结构化数据格式,要求发送方先把数据格式(Schema,比如订单数据包含订单号、金额、创建时间等字段)注册到这个仓库;
- 接收方消费数据时,先从仓库获取对应的格式说明书,再解析数据,保证了 "发送方和接收方数据格式一致",同时还能支持格式的兼容升级(比如后续给订单添加 "支付方式" 字段,不影响老的接收方正常工作)。
-
**Confluent Rest Proxy(REST 代理)**解决 "非 Java 语言对接 Kafka 麻烦" 的问题,相当于一个 "Kafka 的 HTTP 翻译官"。
- 纯 Kafka 的原生客户端主要支持 Java/Scala 等 JVM 语言,而 Python、PHP、Go、前端等语言对接 Kafka 时,要么客户端不成熟,要么开发成本高;
- Rest Proxy 把 Kafka 的核心操作(发送消息、订阅消费消息、查询主题信息等)封装成 HTTP/REST API;
- 任何支持 HTTP 请求的语言 / 系统,都可以通过简单的 GET/POST 请求操作 Kafka,不用关心 Kafka 的原生协议,大大降低了跨语言对接门槛。
下边 就是针对Confluent的一个单机测试部署记录:
准备需求:
1,server:centos 7
安装包 :http://packages.confluent.io/archive/5.2/confluent-5.2.4-2.11.tar.gz
1. 解压安装包
tar -zxvf /opt/package/confluent-5.2.4-2.11.tar.gz -C /home/kafka/.local/
mv /home/kafka/.local/confluent-5.2.4 /home/kafka/.local/confluent
cd /home/kafka/.local/confluent2. 创建数据目录
sudo mkdir -p /data/confluent/{zookeeper,kafka-logs,control-center}
sudo chown -R kafka:kafka /data/confluent3. 修改配置文件(单节点192.168.123.129)
3.1 Zookeeper配置
vim /home/kafka/.local/confluent/etc/kafka/zookeeper.properties
# 数据存放目录
dataDir=/data/confluent/zookeeper
clientPort=2181
maxClientCnxns=0
initLimit=5
syncLimit=2
# 单节点ZK配置
server.1=192.168.123.129:2888:3888创建myid文件:
echo 1 > /home/kafka/.local/confluent/etc/kafka/myid修改confluent启动脚本,确保myid被正确复制:
vim /home/kafka/.local/confluent/bin/confluent在config_zookeeper()方法块最后一行,添加:
cp ${confluent_conf}/kafka/myid $confluent_current/zookeeper/data/3.2 Kafka配置
vim /home/kafka/.local/confluent/etc/kafka/server.properties
broker.id=0
advertised.listeners=PLAINTEXT://192.168.123.129:9092
num.network.threads=8
num.io.threads=8
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
socket.request.max.bytes=104857600
fetch.purgatory.purge.interval.requests=100
producer.purgatory.purge.interval.requests=100
# Kafka数据存储位置
log.dirs=/data/confluent/kafka-logs
num.partitions=12
num.recovery.threads.per.data.dir=1
message.max.bytes=10000000
replica.fetch.max.bytes=10485760
auto.create.topics.enable=true
auto.leader.rebalance.enable=true
# 重要:单节点环境需将复制因子设置为1
default.replication.factor=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.messages=20000
log.flush.interval.ms=10000
log.flush.scheduler.interval.ms=2000
log.retention.check.interval.ms=300000
log.cleaner.enable=true
log.retention.hours=48
# ZK连接地址
zookeeper.connect=192.168.123.129:2181
zookeeper.connection.timeout.ms=6000
zookeeper.sync.time.ms=2000
confluent.metrics.reporter.bootstrap.servers=192.168.123.129:9092
confluent.metrics.reporter.topic.replicas=1
confluent.support.metrics.enable=true
confluent.support.customer.id=anonymous
delete.topic.enable=true
group.initial.rebalance.delay.ms=03.3 Kafka-REST配置
vim /home/kafka/.local/confluent/etc/kafka-rest/kafka-rest.properties
id=kafka-rest-server-001
schema.registry.url=http://192.168.123.129:8081
zookeeper.connect=192.168.123.129:2181
bootstrap.servers=PLAINTEXT://192.168.123.129:9092
port=8082
consumer.threads=8
access.control.allow.methods=GET,POST,PUT,DELETE,OPTIONS
access.control.allow.origin=*3.4 KSQL配置
vim /home/kafka/.local/confluent/etc/ksql/ksql-server.properties
ksql.service.id=default_
bootstrap.servers=192.168.123.129:9092
listeners=http://0.0.0.0:8088
ksql.schema.registry.url=http://192.168.123.129:8081
ksql.sink.partitions=43.5 Confluent Control Center配置
vim /home/kafka/.local/confluent/etc/confluent-control-center/control-center-dev.properties
bootstrap.servers=192.168.123.129:9092
zookeeper.connect=192.168.123.129:2181
confluent.controlcenter.rest.listeners=http://0.0.0.0:9021
# 单节点唯一ID
confluent.controlcenter.id=1
confluent.controlcenter.data.dir=/data/confluent/control-center
confluent.controlcenter.connect.cluster=http://192.168.123.129:8083
confluent.controlcenter.ksql.url=http://192.168.123.129:8088
confluent.controlcenter.schema.registry.url=http://192.168.123.129:8081
# 重要:单节点环境下复制因子设为1
confluent.controlcenter.internal.topics.replication=1
confluent.controlcenter.internal.topics.partitions=2
confluent.controlcenter.command.topic.replication=1
confluent.monitoring.interceptor.topic.partitions=2
confluent.monitoring.interceptor.topic.replication=1
confluent.metrics.topic.replication=1
confluent.controlcenter.streams.num.stream.threads=103.6 Schema Registry配置
vim /home/kafka/.local/confluent/etc/schema-registry/schema-registry.properties
listeners=http://0.0.0.0:8081
kafkastore.bootstrap.servers=PLAINTEXT://192.168.123.129:9092
kafkastore.topic=_schemas
# 重要:单节点环境下复制因子设为1
kafkastore.topic.replication.factor=1
debug=false3.7 Connect配置
vim /home/kafka/.local/confluent/etc/kafka/connect-distributed.properties
bootstrap.servers=192.168.123.129:9092
group.id=connect-cluster
key.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schemas.enable=true
# 重要:单节点环境下schema registry也要指向本机
value.converter.schema.registry.url=http://192.168.123.129:8081
config.storage.topic=connect-configs
offset.storage.topic=connect-offsets
status.storage.topic=connect-statuses
# 重要:单节点环境下复制因子设为1
config.storage.replication.factor=1
offset.storage.replication.factor=1
status.storage.replication.factor=1
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
rest.port=8083
rest.advertised.host.name=192.168.123.129
plugin.path=/home/kafka/.local/confluent/share/java,/usr/share/java4. 启动服务
4.1 全部服务启动
# 启动所有服务
bin/confluent start
# 检查服务状态
bin/confluent status4.2 服务启动顺序(如需单独启动)
# 1. 启动Zookeeper
bin/zookeeper-server-start -daemon etc/kafka/zookeeper.properties
# 2. 启动Kafka
bin/kafka-server-start -daemon etc/kafka/server.properties
# 3. 启动Schema Registry
bin/schema-registry-start -daemon etc/schema-registry/schema-registry.properties
# 4. 启动Kafka REST
bin/kafka-rest-start -daemon etc/kafka-rest/kafka-rest.properties
# 5. 启动Connect
bin/connect-distributed -daemon etc/kafka/connect-distributed.properties
# 6. 启动KSQL Server
bin/ksql-server-start -daemon etc/ksql/ksql-server.properties
# 7. 启动Control Center
bin/control-center-start -daemon etc/confluent-control-center/control-center-dev.properties5. 验证访问
- Control Center: http://192.168.123.129:9021
- Schema Registry: http://192.168.123.129:8081
- Kafka REST: http://192.168.123.129:8082
- Connect: http://192.168.123.129:8083
- KSQL Server: http://192.168.123.129:8088
6. 常用操作
# 查看日志目录
confluent current
# 列出所有连接器
confluent list connectors
# 创建文件源连接器示例
curl -X POST http://192.168.123.129:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file-source-test",
"config": {
"connector.class": "FileStreamSource",
"tasks.max": "1",
"file": "/tmp/test.txt",
"topic": "file-source-test"
}
}'
# 查看连接器状态
confluent status file-source-test7. 重要注意事项
- 复制因子调整:单节点部署时,所有复制因子(replication factor)必须设置为1,否则服务将无法启动。
- 资源分配:单节点运行所有服务需要足够的系统资源(建议至少8GB内存,4核CPU)。
- 生产环境:此配置仅适用于开发/测试环境,在生产环境中应使用多节点集群以确保高可用性。
- 防火墙设置:确保相关端口(2181, 9092, 8081-8083, 8088, 9021)在防火墙中开放。
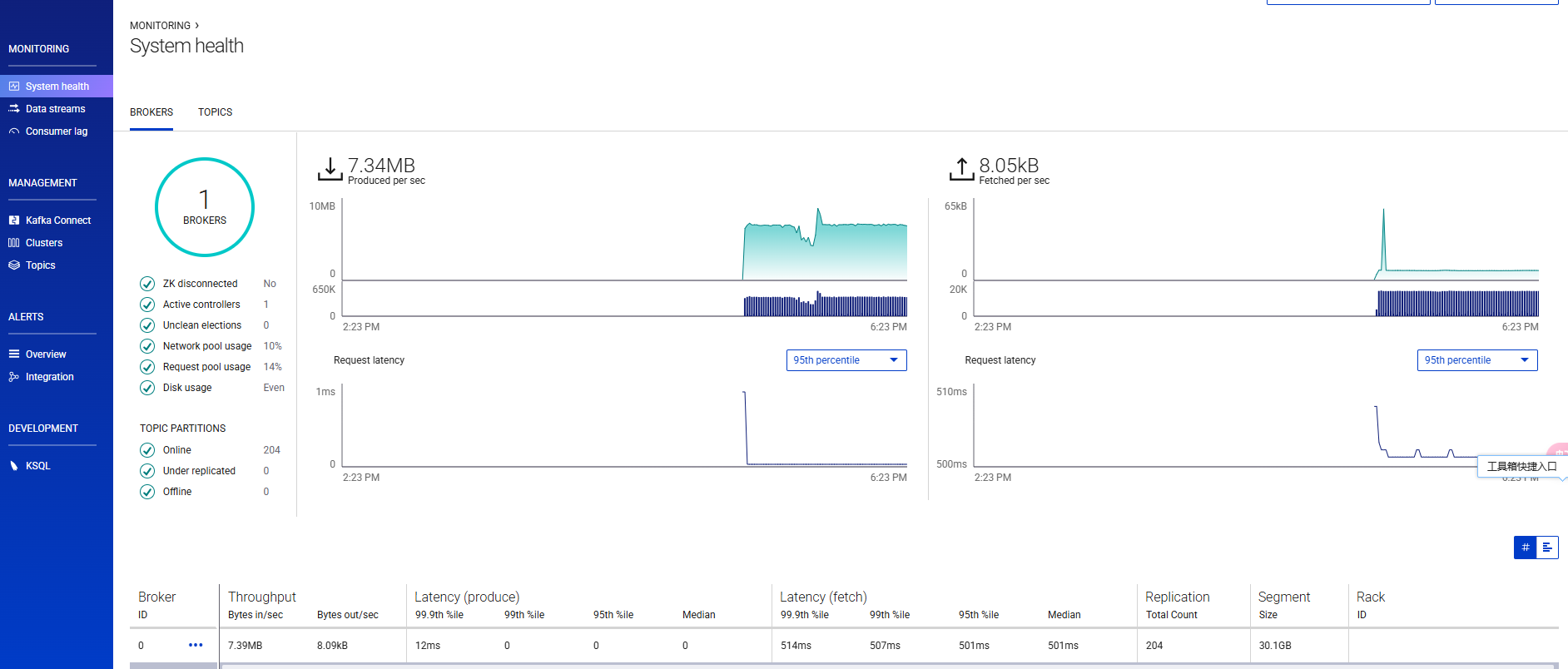
完成以上配置后,就像我一样在测试的192.168.123.129上成功部署完整的Confluent平台,包含所有核心组件。
效果如下: