目录
-
-
- [x86_64 的虚拟地址空间](#x86_64 的虚拟地址空间)
- [直接映射区和 vmalloc 区域](#直接映射区和 vmalloc 区域)
- [I/O 统一编址与 ioremap](#I/O 统一编址与 ioremap)
- [alloc_pages 内存](#alloc_pages 内存)
-
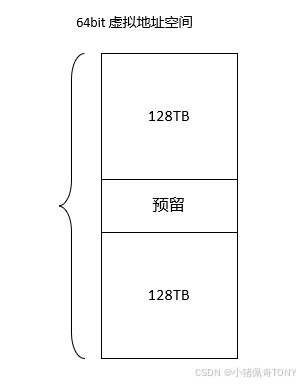
x86_64 的虚拟地址空间
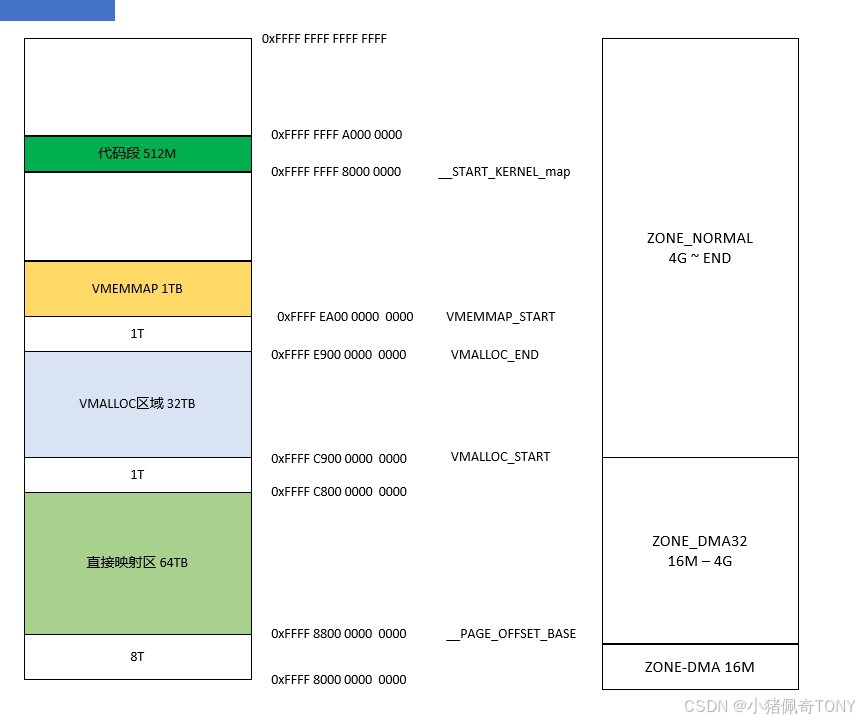
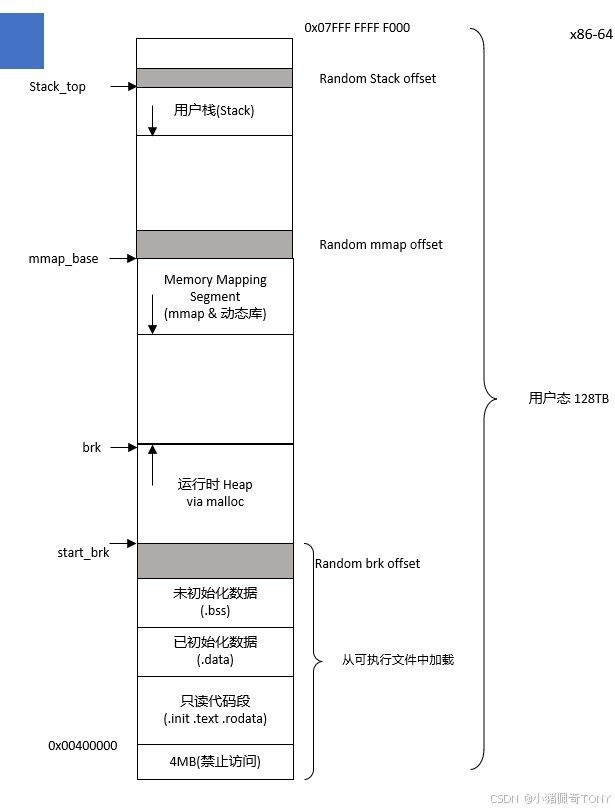
直接映射区和 vmalloc 区域
内核虚拟地址空间直接映射区:
- 直接映射区是内核虚拟地址空间中一段连续的区域,将物理内存按固定偏移(通常是
PAGE_OFFSET)线性地映射到虚拟地址空间 - 在
x86_64架构上,物理地址0x0对应的内核虚拟地址通常是0xffff888000000000(即PAGE_OFFSET)
设计内核直接映射区原则:
- 高效访问物理内存:通过简单的加/减偏移即可完成物理地址 ↔ 虚拟地址的转换,无需查页表
- 用于大块连续物理内存的管理:内核初始化时会将大部分物理内存(如低端内存)通过直接映射区映射,便于快速分配(如伙伴系统分配的页)
- 性能优化:避免频繁创建/销毁页表项,提高内存访问速度
局限性:
要求物理内存连续:直接映射区只能映射物理上连续的内存页
地址空间有限:在 32 位系统上,直接映射区大小受限(如 896MB),无法覆盖全部物理内存(尤其在大内存系统中)
无法处理不连续物理内存:当需要大块虚拟连续但物理不连续的内存时,直接映射区无能为力
vmalloc 内存区域:
vmalloc是内核提供的一个函数,它分配的内存在虚拟地址上连续,但物理地址可以不连续- 这些内存通过页表动态映射到
vmalloc区域,通常位于直接映射区之上(在 64 位系统中位于较高地址)
设计原则 :
解决物理内存碎片问题:当系统运行一段时间后,物理内存可能碎片化,难以分配大块连续物理内存,vmalloc 允许用多个不连续的物理页拼成一个虚拟连续区域
支持大内存分配:适用于需要大块虚拟地址空间(如模块加载、I/O 映射、某些驱动缓冲区)但不要求物理连续的场景
局限性 :
性能开销:每次访问都需要查页表;分配时需修改页表,可能触发 TLB 刷新
地址空间碎片:频繁的 vmalloc/free 可能导致 vmalloc 区域本身碎片化
不能用于原子上下文:因为可能睡眠(需分配页表等)
举例说明:
kmalloc: 小内存分配通常使用直接映射区(slab/slob/slub分配器基于伙伴系统,返回直接映射的页)vmalloc: 加载内核(代码/数据可能较大而且无法保证物理连续)、某些 GPU/设备驱动的缓冲区ioreamp: 将设备I/O内存映射到vmalloc区域,因为设备地址不属于普通物理内存
I/O 统一编址与 ioremap
在 ARM 架构处理器中,I/O 地址通常是与内存统一编址的(memory-mapped I/O,简称 MMIO)
ARM 架构 没有 为 I/O 操作提供独立的 I/O 地址空间(不像 x86 架构那样有专门的 in/out 指令和独立的 I/O 端口地址空间,
相反,ARM 使用 内存映射 I/O(Memory-Mapped I/O, MMIO) 的方式
外设的寄存器(如 UART、GPIO、定时器等)被映射到系统的物理内存地址空间中
CPU 通过普通的加载(load) 和 存储(store) 指令(如 LDR、STR)来访问这些地址,从而读写外设寄存器
这些地址通常位于系统地址空间的特定区域(例如,SoC 厂商会指定外设寄存器位于 0x40000000 到 0x5FFFFFFF 等范围)
- 如何在内核空间读写 I/O 地址
ioremap(phys_addr, size) 将一段物理 I/O 地址映射到内核的虚拟地址空间;
返回一个虚拟地址(void __iomem * 类型),后续通过 readl()、writel()、ioread32()、iowrite32() 等专用函数访问;
这些函数确保正确的内存访问语义(如禁止编译器优化、保证访问顺序、处理弱内存模型等)
举例如下:
c
// 使用 ioremap 的情况
void __iomem *reg = ioremap(0xFED40000, 4); // 映射4字节
writel(0x12345678, reg); // 正确!通过虚拟地址访问使用的物理空间如下:
shell
物理地址空间:
[0x00000000 - 0x3FFFFFFF] : 系统 RAM(已线性映射)
[0xFED40000 - 0xFED40FFF] : PCI 设备配置空间
[0xFEC00000 - 0xFEC00FFF] : APIC 寄存器
[0xFEE00000 - 0xFEE00FFF] : IOAPIC 寄存器
虚拟地址空间(内核部分):
[0xffff888000000000] : 直接映射区(RAM)
[0xffffc90000000000] : vmalloc/ioremap 区域 ← ioremap 在这里分配虚拟地址
│
↓ 建立页表映射
[0xFED40000] 物理 I/O 地址alloc_pages 内存
alloc_pages() 分配的物理内存,其对应的内核虚拟地址位于直接映射区(Direct Mapping Region),也叫线性映射区
alloc_pages() 系列函数(包括 __get_free_pages,kmalloc 的底层也用它)的主要目的是分配连续的物理页面
为了能让内核代码访问这些物理内存,必须将它们映射到内核的虚拟地址空间
直接映射是一种最简单的映射方式:在系统启动早期,内核会建立一个从物理地址到虚拟地址的固定偏移映射。在大多数架构(如 x86-64)上,这个偏移是固定的(例如 0xffff888000000000)
它在内核虚拟地址空间中的典型起始地址是 __PAGE_OFFSET(例如 0xffff888000000000)
地址转换:
当你调用 alloc_pages(GFP_KERNEL, order) 并获得一个 struct page* 指针后,可以通过 page_to_virt(page) 宏来获取这块内存对应的内核虚拟地址
虽然 alloc_pages() 默认返回直接映射区的虚拟地址,但通过使用不同的标志,可以改变其行为,使其映射到其他区域:
-
GFP_HIGHUSER:当用于用户空间内存分配时(例如通过page fault处理程序),分配的物理页面最终会被映射到用户进程的虚拟地址空间,而不是内核的直接映射区。 -
__GFP_HIGHMEM(在 32 位系统上重要):在 32 位系统上,直接映射区大小有限(通常约896MB),无法映射所有物理内存超出部分称为"高端内存",使用此标志分配的页面,其物理地址可能没有固定的内核虚拟地址。内核需要通过 kmap 等临时映射机制来访问它们但在 64 位系统上,由于虚拟地址空间极其庞大,已经废除了高端内存的概念,所有物理内存都可以线性映射