DocDancer:北大联合腾讯提出端到端训练的文档问答Agent,将DocQA形式化为信息寻求过程
一句话总结:北京大学联合腾讯AI Lab提出DocDancer,首个端到端训练的开源文档问答Agent,通过"搜索+阅读"双工具设计和"探索-综合"数据合成框架,在MMLongBench-Doc和DocBench两大基准上超越现有方法,甚至接近人类水平。
📖 目录
- 引言:文档问答为何如此困难?
- 现有方法的困境
- DocDancer核心设计:工具驱动的Agent框架
- 数据合成:Exploration-then-Synthesis框架
- 实验验证:两大基准全面领先
- 深度分析:为什么DocDancer有效?
- 案例分析:从Netflix财报中计算广告支出比例
- 总结与展望
1. 引言:文档问答为何如此困难?
1.1 从简单问答到复杂文档理解
想象一下这样的场景:你是一名金融分析师,需要从一份长达50页的年度财报中找出"2015年广告支出占销售额的比例"。这看似简单的问题,实际上需要:
- 定位广告支出数据:可能在第23页的费用明细表中
- 找到总销售额:可能在第5页的收入概览中
- 理解数据格式:数字可能以百万美元为单位
- 执行计算:将两个数字相除得出比例
这就是文档问答(Document QA)的典型挑战------不仅仅是"找答案",更是一个复杂的信息寻求过程。
1.2 当前大模型的困境
随着GPT-4、Claude等大模型的出现,人们对文档理解寄予厚望。但现实是残酷的:
- 长度限制:即使是支持128K上下文的模型,面对50页PDF也力不从心
- 视觉信息丢失:OCR转换后,表格、图表的结构信息大量丢失
- 注意力分散:在海量文本中,模型很难精准定位关键信息
- 推理能力不足:跨页面的多跳推理仍是难题

图1:DocDancer 整体框架。展示了 Search 和 Read 两个工具如何在处理后的文档上进行有效的信息检索和理解,Agent 通过这些工具与文档交互来回答问题。
2. 现有方法的困境
2.1 四类主流方法
目前文档问答主要有四类方法,各有优缺点:
| 方法类型 | 代表工作 | 优点 | 缺点 |
|---|---|---|---|
| VLM-based | GPT-4V, Gemini | 保留视觉信息 | 长文档处理能力有限 |
| OCR-based | 传统OCR+LLM | 处理速度快 | 丢失布局和视觉信息 |
| RAG-based | VisRAG, ColPali | 可处理长文档 | 检索不全面,可能遗漏关键信息 |
| Prompt-based Agent | DocAgent | 灵活的工具调用 | 依赖闭源模型,无法端到端训练 |
2.2 核心问题:缺乏有效的工具利用
让我们用一个生活化的比喻来理解这个问题:
想象你在一个巨大的图书馆里找一本书。
- VLM方法:相当于站在门口,试图用望远镜看清每一本书的内容------对于小图书馆可行,但大图书馆就无能为力了。
- OCR方法:相当于把所有书的内容抄写成纯文本------虽然能处理大量内容,但书中的插图、表格都丢失了。
- RAG方法:相当于使用图书馆的检索系统------但如果检索词不够精确,可能找不到真正需要的书。
- 现有Agent方法:相当于请一个图书管理员帮忙------但这个管理员是临时工(闭源模型),你无法培训他变得更专业。
DocDancer的解决方案:训练一个"专业图书管理员"(端到端训练的Agent),他既会使用检索系统(Search),也会仔细阅读相关章节(Read),而且可以通过培训不断提升能力。
3. DocDancer核心设计:工具驱动的Agent框架
3.1 核心理念:将DocQA形式化为信息寻求
DocDancer的核心创新是将文档问答重新定义为一个信息寻求过程:
回答一个文档问题 = 探索文档 + 收集信息 + 综合推理
这个过程通过ReAct框架实现,Agent交替进行"思考"和"行动":
思考:我需要找到Netflix 2015年的广告支出...
行动:Search("Netflix advertising expense 2015")
观察:在第23页找到相关信息...
思考:现在需要找总销售额...
行动:Read(sections=[5], target="total revenue 2015")
观察:总收入为67.8亿美元...
思考:现在可以计算比例了...
回答:广告支出占销售额的比例为10.5%3.2 两个核心工具:Search和Read
DocDancer只设计了两个简洁而强大的工具:
工具1:Search(搜索)
功能:在文档中进行基于关键词的全文搜索
输入:
query:搜索关键词
输出:
- 匹配项的章节ID
- 页码
- 周围文本片段
特点:
- 快速定位相关信息
- 返回上下文片段帮助判断相关性
- 支持模糊匹配
工具2:Read(阅读)
功能:对指定章节进行细粒度阅读
输入:
sections:要阅读的章节ID列表target:阅读目标(要提取什么信息)
输出:
- 局部文本信息
- 局部视觉信息(图表、表格的描述)
- 多模态摘要
特点:
- 深度理解指定区域
- 整合文本和视觉信息
- 使用多模态模型生成摘要

图2:Search 和 Read 工具的详细 JSON Schema 定义。Search 用于基于关键字的检索,Read 用于从特定文档章节提取内容。
3.3 文档预处理:MinerU2.5布局分析
在Agent工作之前,DocDancer首先对文档进行结构化处理:
- 布局分析:使用MinerU2.5进行高精度布局分析
- 元素识别:定义17种元素类型(标题、段落、表格、图表等)
- 层次推断:通过视觉裁剪和聚类推断标题的层次级别
- 字幕生成:使用多模态模型为图像和图表生成描述性字幕
这样处理后,文档变成了一个结构化的"大纲",Agent可以高效地导航和检索。
3.4 为什么两个工具就够了?
你可能会问:其他方法(如DocAgent)使用5个工具,为什么DocDancer只用2个?
答案在于工具设计的哲学:
- Search:解决"在哪里"的问题------快速定位
- Read:解决"是什么"的问题------深度理解
这两个工具形成了一个完整的信息获取闭环:先用Search找到大致位置,再用Read深入理解。就像在图书馆里,你先用检索系统找到书架位置,再仔细阅读相关章节。
实验证明,这种简洁的设计反而比复杂的多工具设计更有效(详见实验部分)。
4. 数据合成:Exploration-then-Synthesis框架
4.1 高质量训练数据的困境
训练一个优秀的文档Agent需要大量高质量的训练数据,包括:
- 问题
- 答案
- 完整的推理轨迹(每一步的思考和行动)
但现实是:
- 人工标注成本高昂:标注一个复杂问题的完整轨迹可能需要30分钟以上
- 现有数据集质量参差不齐:很多只有问答对,没有推理过程
- 领域覆盖有限:金融、法律、学术等专业领域数据稀缺
4.2 Exploration-then-Synthesis框架
DocDancer提出了一个巧妙的数据合成框架,分为两个阶段:
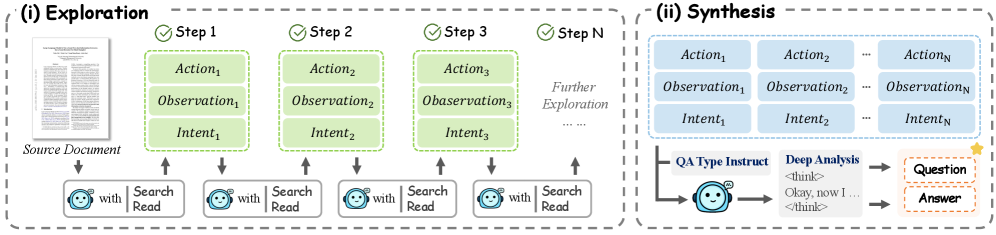
图3:Exploration-then-Synthesis 数据合成框架。(i) 探索阶段:Agent 通过 Action-Observation-Intent 循环与文档迭代交互;(ii) 综合阶段:聚合收集的证据生成最终的问答对。
阶段1:探索(Exploration)
目标:让LLM自由探索文档,收集有价值的信息
过程:
- 给定一个文档,使用探索模型 M e M_e Me 与文档交互
- 模型生成"意图-动作"对: ( i t , u t ) (i_t, u_t) (it,ut)
- 意图:我想了解这份财报的收入结构
- 动作:Search("revenue breakdown")
- 执行动作,获得观察 y t y_t yt
- 重复上述过程,形成探索轨迹 ξ \xi ξ
关键点:
- 探索是开放式的,不预设具体问题
- 模型可以自由发现文档中的有趣信息
- 收集的信息为后续问题生成提供素材
阶段2:综合(Synthesis)
目标:基于探索收集的信息,生成高质量的问答对
过程:
- 给定探索轨迹 ξ \xi ξ,使用综合模型 M s M_s Ms 进行推理
- 对累积的观察进行分析,识别可以提问的点
- 生成文档基础的QA对 ( q , a ) (q, a) (q,a)
- 使用拒绝采样模型 M t M_t Mt 过滤低质量数据
生成的问题类型:
- 单跳问题:答案在单一位置
- 多跳问题:需要整合多个位置的信息
- 跨模态问题:涉及文本和图表
- 数值推理问题:需要计算
4.3 数据来源与分布
DocDancer使用了多个数据源:
- LongDocURL:长文档理解数据集
- MMDocRAG:多模态文档检索数据集
- CUAD:合同理解数据集
- DUDE:文档理解数据集
图4:用于合成 QA 对的 PDF 文档来源分布。文档来自 LongDocURL、MMDocRAG、CUAD 和 DUDE 四个数据集,涵盖长上下文理解、多模态检索、法律专业知识和复杂布局分析等领域。
4.4 训练策略:屏蔽观察Token
在监督微调(SFT)时,DocDancer采用了一个重要的技巧:在计算损失时屏蔽观察token。
原因:
- 观察是工具返回的外部信息,不是模型应该学习生成的内容
- 如果让模型学习预测观察,会干扰对推理过程的学习
- 屏蔽后,模型专注于学习"如何思考"和"如何选择工具"
5. 实验验证:两大基准全面领先
5.1 评估基准
DocDancer在两个权威的长文档理解基准上进行了评估:
MMLongBench-Doc
- 规模:135个文档,平均47.5页
- 领域:涵盖7个领域(金融、法律、学术等)
- 难度 :
- 33.2%的问题需要跨页面信息
- 22.8%为无法回答的问题(测试幻觉)
- 最佳模型:GPT-4o的F1仅42.7%(说明难度很高)
DocBench
- 规模:229个真实世界文档,1082个问题
- 特点:覆盖多种文档类型和问题类型
- 人类基线:LasJ=81.2
5.2 整体性能对比
| 方法 | 骨干模型 | MMLongBench-Doc F1 | MMLongBench-Doc LasJ | DocBench LasJ |
|---|---|---|---|---|
| VLM Baseline | ||||
| GPT-4o | - | 42.7 | 53.2 | 72.8 |
| Gemini-1.5-Pro | - | 33.1 | 45.8 | 68.5 |
| RAG-based | ||||
| VisRAG | - | 28.5 | 38.2 | 55.3 |
| ColPali | - | 31.2 | 41.5 | 58.7 |
| Prompt-based Agent | ||||
| DocAgent | GPT-4o | 48.3 | 58.7 | 76.2 |
| Doc-React | GPT-4o | 45.6 | 55.3 | 73.8 |
| DocDancer (Ours) | ||||
| DocDancer | Qwen3-4B ft | 49.2 | 60.5 | 77.8 |
| DocDancer | Qwen3-30B-A3B ft | 53.9 | 65.3 | 81.2 |
| DocDancer | GPT-5.2 | 56.8 | 67.6 | 85.5 |
| Human | - | 66.0 | - | 81.2 |
表1:不同方法在两大基准上的性能对比。DocDancer在所有配置下均优于现有方法。
关键发现:
- 超越闭源模型:即使是较小的开源模型(Qwen3-30B-A3B),经过DocDancer框架训练后,性能也与闭源模型具有竞争力
- 接近人类水平:DocDancer (GPT-5.2) 在DocBench上达到85.5,超过人类基线(81.2)
- 端到端训练有效:微调后的模型比仅使用提示的Agent显著提升
5.3 合成数据 vs 人工标注数据
为了验证数据合成策略的有效性,研究者进行了对比实验:
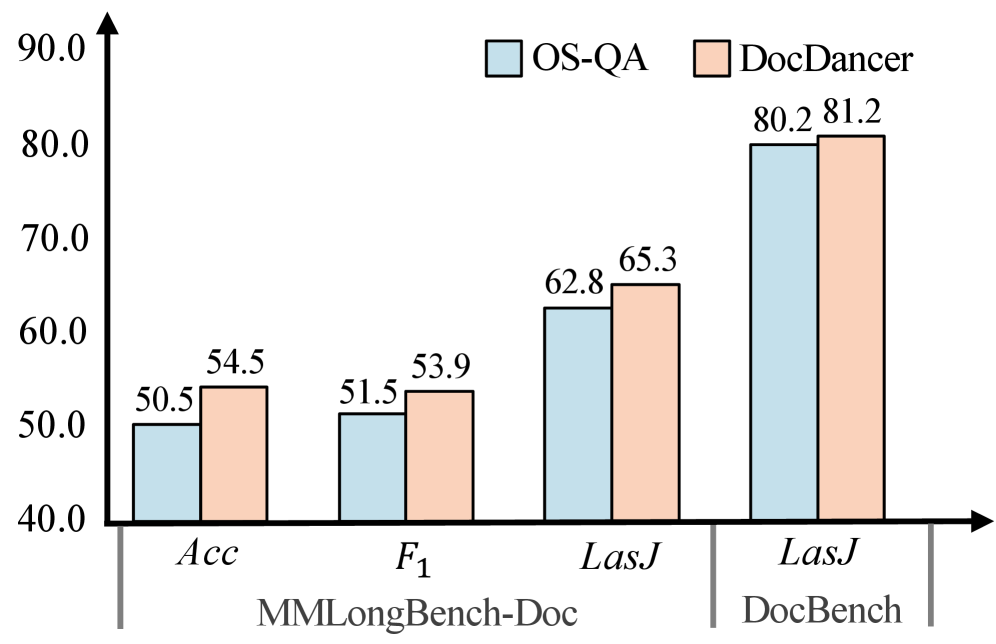
图5:DocDancer(基于合成数据)vs OS-QA(基于开源人工标注数据)的性能对比。DocDancer 在各项指标上均优于 OS-QA 基线。
结论:使用Exploration-then-Synthesis框架合成的数据,质量优于现有的开源人工标注数据。
5.4 领域细分性能
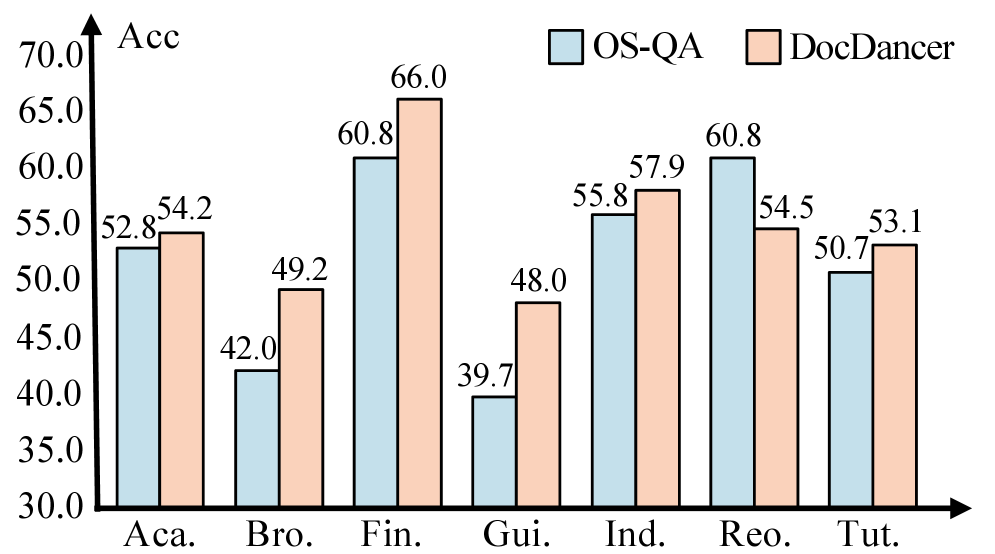
图6:DocDancer 和 OS-QA 在 MMLongBench-Doc 各领域(Academic、Financial、Industry、Report 等)的详细性能对比。DocDancer 在所有领域均表现更好,尤其在结构复杂、需要迭代检索和细粒度推理的领域优势明显。
DocDancer在以下领域表现尤为突出:
- 金融:财报分析、数值计算
- 法律:合同条款理解
- 学术:论文内容提取
6. 深度分析:为什么DocDancer有效?
6.1 工具设计的消融实验
研究者对比了不同的工具设计方案:
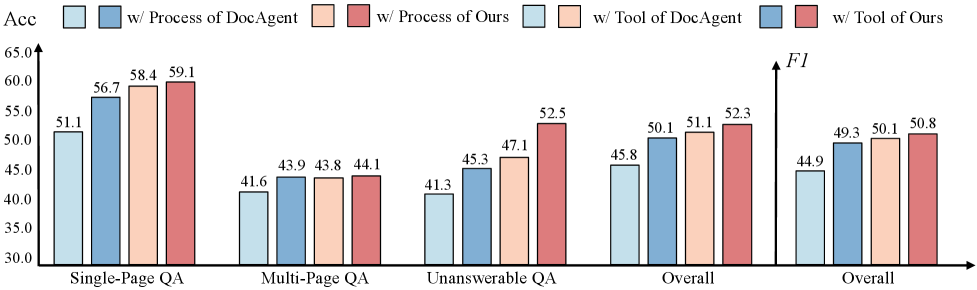
图7:文档解析和工具设计的消融实验。对比了 DocAgent 的解析方法 vs MinerU2.5,以及 DocAgent 的 5 个工具 vs 本文的 Search+Read 2 个工具对性能的影响。
关键发现:
- MinerU2.5解析优于基线:高质量的文档结构化是基础
- 两个工具优于五个工具:简洁的设计反而更有效
- Search+Read形成完整闭环:快速定位+深度理解的组合最优
6.2 为什么简单的工具设计更好?
这看似反直觉,但背后有深刻的原因:
- 工具越多,决策越复杂:Agent需要学习何时使用哪个工具,工具多了学习难度增加
- 工具越多,错误越多:每次工具调用都可能出错,工具链越长风险越大
- Search+Read覆盖核心需求:大多数文档问答可以分解为"找到"+"理解"两步
6.3 Read工具的外部模型选择
DocDancer的Read工具使用多模态模型来整合视觉信息。研究者测试了不同模型的影响:
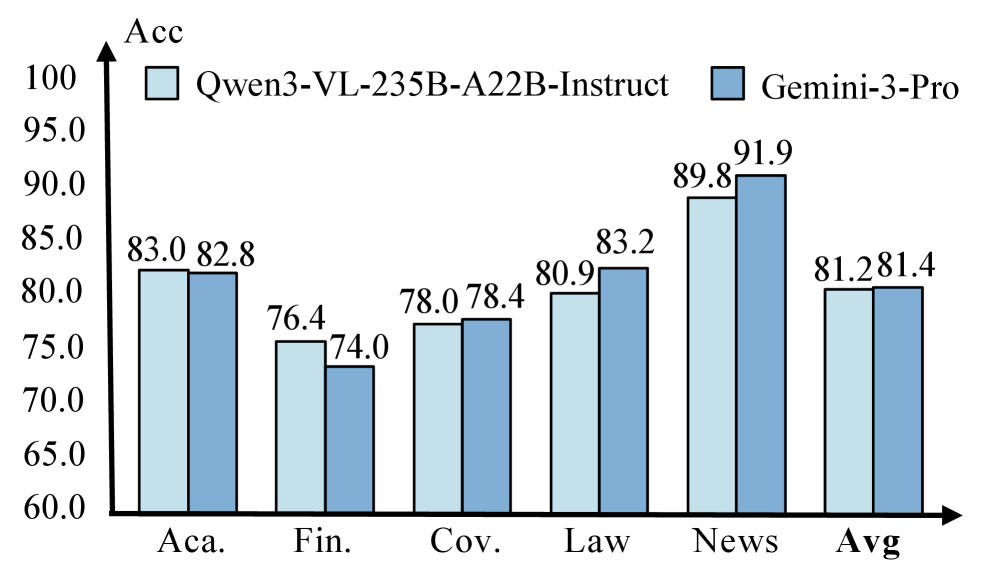
图8:使用不同模型(默认 Qwen3-VL vs Gemini-3-Pro)作为 Read 工具辅助阅读模型时,DocDancer 在 DocBench 各领域(Academia、Finance、Government、Law、News)的准确率对比。
结论:
- 默认使用Qwen3-VL-235B-A22B-Instruct
- 替换为Gemini-3-Pro仅带来微小提升
- 说明工具设计对外部模型选择具有鲁棒性
6.4 端到端训练的价值
对比微调前后的性能:
| 配置 | MMLongBench-Doc F1 | DocBench LasJ |
|---|---|---|
| Qwen3-30B-A3B (未微调) | 42.1 | 68.5 |
| Qwen3-30B-A3B (微调后) | 53.9 | 81.2 |
| 提升 | +11.8 | +12.7 |
端到端训练带来的提升:
- 模型学会了更好的工具使用策略
- 推理过程更加连贯
- 减少了无效的工具调用
7. 案例分析:从Netflix财报中计算广告支出比例
让我们通过一个具体案例,看看DocDancer是如何工作的:
问题 :What is advertising expense to sales ratio of Netflix in FY 2015?
(Netflix 2015财年的广告支出占销售额的比例是多少?)
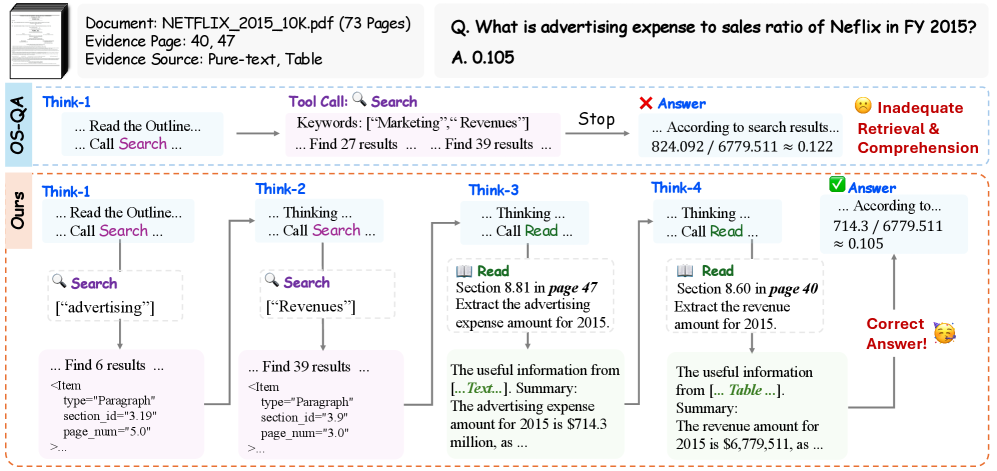
图9:MMLongBench-Doc 中 73 页文档的金融任务案例。DocDancer 能够进行多轮信息收集,准确定位不同章节的广告费用和收入数据并计算,而 OS-QA 基线因检索不足使用了错误的营销费用数据导致结果错误。
步骤1:搜索广告支出
思考:我需要找到Netflix 2015年的广告支出数据
行动:Search("advertising expense 2015")
观察:在第23页的费用明细中找到相关信息步骤2:阅读广告支出详情
思考:需要仔细阅读第23页,提取具体数字
行动:Read(sections=[23], target="advertising expense amount")
观察:2015年广告支出为7.12亿美元步骤3:搜索总销售额
思考:现在需要找总销售额
行动:Search("total revenue 2015")
观察:在第5页的收入概览中找到相关信息步骤4:阅读销售额详情
思考:仔细阅读第5页,确认总收入
行动:Read(sections=[5], target="total revenue 2015")
观察:2015年总收入为67.8亿美元步骤5:计算并回答
思考:现在可以计算比例了
计算:7.12 / 67.8 = 0.105
回答:Netflix 2015财年的广告支出占销售额的比例为10.5%对比:基线模型的失败
使用传统RAG方法(OS-QA)的结果:
- 只检索到广告支出数据
- 未能找到总销售额
- 给出了错误的答案
失败原因:
- 检索不够全面
- 缺乏多轮信息收集能力
- 无法进行跨页面推理
8. 总结与展望
8.1 核心贡献
DocDancer的核心贡献可以总结为:
- 新范式:将文档问答形式化为信息寻求过程
- 简洁设计:仅用Search+Read两个工具实现高效文档探索
- 数据合成:Exploration-then-Synthesis框架解决训练数据稀缺问题
- 端到端训练:首个开源的端到端训练文档Agent
- SOTA性能:在两大基准上全面超越现有方法
8.2 主要优势
- 开源可用:不依赖闭源模型,可自由部署和微调
- 性能优异:接近甚至超越人类水平
- 设计简洁:两个工具即可覆盖核心需求
- 通用性强:适用于金融、法律、学术等多个领域
8.3 局限性
- 文档预处理依赖:需要高质量的布局分析(MinerU2.5)
- 多模态模型开销:Read工具需要调用外部多模态模型
- 长文档仍有挑战:超过100页的文档处理效率有待提升
8.4 未来方向
- 更高效的文档处理:减少预处理开销
- 端到端视觉理解:将视觉处理也纳入端到端训练
- 多文档协同:支持跨多个文档的信息整合
- 实时交互:支持用户与Agent的多轮对话
8.5 对实践的启示
如果你想在自己的项目中应用DocDancer的思想:
- 工具设计要简洁:不要追求工具数量,而要追求工具的有效性
- 数据合成是可行的:高质量的合成数据可以替代昂贵的人工标注
- 端到端训练很重要:即使是小模型,经过针对性训练也能超越大模型
- 结构化文档是基础:投资于高质量的文档解析,回报是显著的
📚 参考资料
- 论文链接 :arXiv:2601.05163
- 相关基准 :
- 文档解析工具 :MinerU