文章目录
- 协程池模型
-
- 属性定义
-
- Task:有一个函数成员,表示这个task具体的执行逻辑
- [Pool:有两个成员,Capacity表示池子里的worker的数量,即工作的goroutine的数量,JobCh 表示任务队列用于存放任务,goroutine从这个JobCh 获取任务执行任务逻辑](#Pool:有两个成员,Capacity表示池子里的worker的数量,即工作的goroutine的数量,JobCh 表示任务队列用于存放任务,goroutine从这个JobCh 获取任务执行任务逻辑)
- worker
- 方法定义
- 协程池处理任务流程图:
- 协程池实现
- 协程池v2版本
- 反射
- [1. 什么是反射](#1. 什么是反射)
- [2. Go语言反射](#2. Go语言反射)
-
- [2.1 reflect.TypeOf()](#2.1 reflect.TypeOf())
- [2.2 reflect.ValueOf()](#2.2 reflect.ValueOf())
- [2.3 go语言数据种类](#2.3 go语言数据种类)
- [3. 反射使用](#3. 反射使用)
-
- [3.1 值对象](#3.1 值对象)
-
- [3.1.1 获取struct反射值](#3.1.1 获取struct反射值)
- [3.1.2 获取map反射值](#3.1.2 获取map反射值)
- [3.1.3 获取slice反射值](#3.1.3 获取slice反射值)
- [3.2 类型对象](#3.2 类型对象)
-
- reflect.Type
- reflect.Value
- [3.2.1 struct反射类型](#3.2.1 struct反射类型)
- [3.2.2 指针反射类型](#3.2.2 指针反射类型)
- [3.2.3 函数反射类型](#3.2.3 函数反射类型)
- [3.2.4 反射获取struct方法](#3.2.4 反射获取struct方法)
- [3.3 通过反射调用方法](#3.3 通过反射调用方法)
- [3.4 通过反射设置值](#3.4 通过反射设置值)
-
- [1. reflect.Value.Elem() 方法得到具体的类型可寻址](#1. reflect.Value.Elem() 方法得到具体的类型可寻址)
- [2. 对切片进行反射时,通过 reflect.Value.Index(i) 获取到的 reflect.Value 对象是可以寻址的](#2. 对切片进行反射时,通过 reflect.Value.Index(i) 获取到的 reflect.Value 对象是可以寻址的)
- [3. 通过结构体的指针获取到的字段也是可寻址](#3. 通过结构体的指针获取到的字段也是可寻址)
- [3.5 结构体标签](#3.5 结构体标签)
- [4. 反射的优缺点](#4. 反射的优缺点)
- 反射的应用场景
go语言虽然有着高效的GMP调度模型,理论上支持成千上万的goroutine,但是goroutine过多,对调度,gc以及系统内存都会造成压力,这样会使我们的服务性能不升反降。常用做法可以用 池化技术 ,构造一个协程池,把进程中的协程控制在一定的数量,防止系统中goroutine过多,影响服务性能。
协程池模型
协程池简单理解就是有一个池子一样的东西,里面装这个固定数量的goroutine,当有一个任务到来的时候,会将这个任务交给池子里的一个空闲的goroutine去处理,如果池子里没有空闲的goroutine了,任务就会阻塞等待 。所以协程池有三个角色Worker,Task,Pool。
属性定义
- Worker:用于执行任务的goroutine
- Task:具体的任务
- Pool:池子
下面看一下各个角色的定义
Task:有一个函数成员,表示这个task具体的执行逻辑
go
type Task struct {
f func() error // 具体的执行逻辑
}Pool:有两个成员,Capacity表示池子里的worker的数量,即工作的goroutine的数量,JobCh 表示任务队列用于存放任务,goroutine从这个JobCh 获取任务执行任务逻辑
go
type Pool struct {
RunningWorkers int64
Capacity int64 // goroutine数量
JobCh chan *Task // 用于worker取任务
sync.Mutex
}worker
go
// p为Pool对象指针
for task := range p.JobCh {
do ...
}执行任务单元,简单理解就是干活的goroutine,这个worker其实只做一件事情,就是不断的从任务队列里面取任务执行,而worker的数量就是协程池里协程的数量,由Pool的参数WorkerNum指定
方法定义
go
func NewTask(funcArg func() error) *TaskNewTask用于创建一个任务,参数是一个函数,返回值是一个Task类型
go
func NewPool(Capacity int, taskNum int) *PoolNewPool返回一个协程数量固定为workerNum 协程池对象指针,其任务队列的长度为taskNum(一开始workerNum就是taskNum)
接下来主要介绍协程池的各个方法
go
func (p *Pool) AddTask(task *Task)AddTask方法是往协程池添加任务,如果当前运行着的worker数量小于协程池worker容量,则立即启动一个协程worker来处理任务(直接开启一个goroutine来处理任务),否则将任务添加到任务队列
go
func (p *Pool) Run()将协程池跑起来,启动一个worker来处理任务
协程池处理任务流程图:
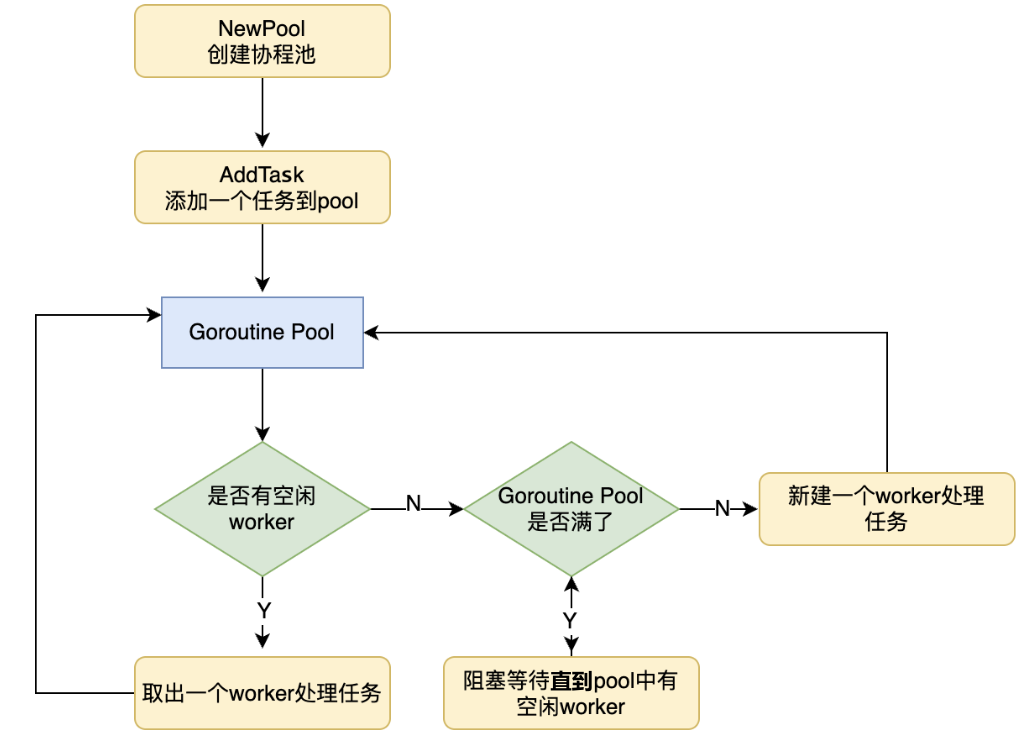
协程池实现
go
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
// 一个任务本质就是一个函数 f
type Task struct {
f func() error // 具体的任务逻辑
}
func NewTask(funcArg func() error) *Task {
return &Task{
f: funcArg,
}
}
type Pool struct {
RunningWorkers int64 // 运行着的worker数量
Capacity int64 // 协程池worker容量
JobCh chan *Task // 用于worker取任务
// 这里的 sync.Mutex 不需要手动初始化,零值就能用。
sync.Mutex // 防止多个 goroutine 同时 AddTask 时启动过多 worker
}
func NewPool(capacity int64, taskNum int) *Pool {
return &Pool{
Capacity: capacity,
JobCh: make(chan *Task, taskNum),
}
}
func (p *Pool) GetCap() int64 {
return p.Capacity
}
func (p *Pool) incRunning() { // runningWorkers + 1
atomic.AddInt64(&p.RunningWorkers, 1)
}
func (p *Pool) decRunning() { // runningWorkers - 1
atomic.AddInt64(&p.RunningWorkers, -1)
}
func (p *Pool) GetRunningWorkers() int64 {
return atomic.LoadInt64(&p.RunningWorkers)
}
func (p *Pool) run() {
p.incRunning()
go func() {
defer func() {
p.decRunning()
}()
for task := range p.JobCh {
task.f()
}
}()
}
// AddTask 往协程池添加任务
func (p *Pool) AddTask(task *Task) {
// 加锁防止启动多个 worker
p.Lock()
defer p.Unlock()
if p.GetRunningWorkers() < p.GetCap() { // 如果任务池满,则不再创建 worker
// 创建启动一个 worker
p.run()
}
// 将任务推入队列,等待消费
p.JobCh <- task
}
func main() {
// 创建任务池
// 最多 3 个 worker, JobCh 缓冲长度 taskNum = 10:最多能排队 10 个任务(超出会阻塞提交方)
pool := NewPool(3, 10)
for i := range 20 {
// 任务放入池中
pool.AddTask(NewTask(func() error {
fmt.Printf("I am Task[%v]\n", i)
return nil
}))
}
time.Sleep(1e9) // 等待执行
}运行结果:
go
root@GoLang:~/proj/goforjob# go run main.go
I am Task[0]
I am Task[1]
I am Task[2]
I am Task[3]
I am Task[4]
I am Task[5]
I am Task[6]
I am Task[7]
I am Task[8]
I am Task[9]
I am Task[10]
I am Task[13]
I am Task[14]
I am Task[15]
I am Task[16]
I am Task[17]
I am Task[18]
I am Task[19]
I am Task[11]
I am Task[12]
root@GoLang:~/proj/goforjob# 程序创建了一个WorkerNum为3,任务队列长度为10的协程池,这里面添加了20个任务,可以看到输出,一直只有3个worker在做任务,起到了控制goroutine数量的作用。
协程池的作用就是减少协程的创建与销毁带来的开销,让一个存活的协程能够处理股多个任务,但是是一个一个的处理,处理完一个之后接着处理下一个,而不是回收掉
协程池v2版本
go
package main
import (
"fmt"
"runtime"
"strconv"
"strings"
"sync"
"sync/atomic"
"time"
)
func goid() int64 {
var buf [64]byte
// 第二个参数 false:只获取当前 goroutine 的栈信息(不是所有 goroutine)
// 返回值 n:实际写入了多少字节
n := runtime.Stack(buf[:], false)
// "goroutine 123 [running]:"
// string(buf[:n]):把写入的内容转为 string
// strings.Fields(...):按空白字符切分(空格、换行、tab 都算)
fields := strings.Fields(string(buf[:n]))
// 取出 fields[1] 并转成数字, fields[1] 是 "18"(goroutine id 的数字部分)
id, _ := strconv.ParseInt(fields[1], 10, 64)
return id
}
type Task struct {
f func() error
}
func NewTask(f func() error) *Task {
return &Task{
f: f,
}
}
type Pool struct {
RunningWorkers int64
Capacity int64
JobCh chan *Task
sync.Mutex
}
func NewPool(capacity int64, taskNum int) *Pool {
return &Pool{
Capacity: capacity,
JobCh: make(chan *Task, taskNum),
}
}
func (p *Pool) GetCap() int64 { return p.Capacity }
func (p *Pool) incRunning() { atomic.AddInt64(&p.RunningWorkers, 1) }
func (p *Pool) decRunning() { atomic.AddInt64(&p.RunningWorkers, -1) }
func (p *Pool) GetRunningWorkers() int64 {
return atomic.LoadInt64(&p.RunningWorkers)
}
func (p *Pool) run() {
p.incRunning()
go func() {
defer p.decRunning()
workerID := goid()
fmt.Printf(">>> worker started, goid=%d\n", workerID)
for task := range p.JobCh {
_ = task.f()
}
fmt.Printf("<<< worker exit, goid=%d\n", workerID)
}()
}
func (p *Pool) AddTask(task *Task) {
needRun := false
p.Lock()
if p.GetRunningWorkers() < p.GetCap() {
needRun = true
}
p.Unlock()
if needRun {
p.run()
}
// 这里如果此时JobCh这个channel已经满了,调用了AddTask()方法的协程是会阻塞在这里
p.JobCh <- task
}
func main() {
fmt.Printf("main goid=%d\n", goid())
pool := NewPool(3, 10)
for i := range 20 {
// 关键点:Go 1.22 起,range 循环的迭代变量"每次迭代都是一份新的"
// 从 Go 1.22 开始,for ... range ... 的迭代变量(比如 i)在每一次迭代里都会是独立的变量,所以闭包捕获到的就是"当次的 i",不会出现以前那种"所有闭包最后都读到同一个 i"的问题。
pool.AddTask(NewTask(func() error {
fmt.Printf("task %02d running in goid=%d\n", i, goid())
time.Sleep(300 * time.Millisecond)
return nil
}))
}
time.Sleep(2 * time.Second)
}
go
root@GoLang:~/proj/goforjob# go run main.go
main goid=1
>>> worker started, goid=21
task 00 running in goid=21
>>> worker started, goid=19
task 01 running in goid=19
>>> worker started, goid=20
task 02 running in goid=20
task 04 running in goid=21
task 03 running in goid=20
task 05 running in goid=19
task 06 running in goid=19
task 07 running in goid=21
task 08 running in goid=20
task 09 running in goid=19
task 10 running in goid=20
task 11 running in goid=21
task 12 running in goid=21
task 13 running in goid=19
task 14 running in goid=20
task 15 running in goid=20
task 16 running in goid=21
task 17 running in goid=19
task 19 running in goid=20
task 18 running in goid=19
root@GoLang:~/proj/goforjob# 反射
1. 什么是反射
反射可以认为是程序在运行时的一种能力,反射可以在程序运行时访问、检测和修改它本身状态,比如在程序运行时可以检查变量的类型和值,调用它们的方法,甚至修改它们的值。使用反射可以增强程序的灵活性,简单来说,反射就是程序在运行时能够检测自身和修改自身的一种能力。
反射就是处理的程序运行时的动态类型,而静态类型是在编译的时候就确定了
2. Go语言反射
对于很多的高级语言都实现了反射,像java, python。在go语言中,反射在go语言内置的reflect包下实现。go语言中的反射建立在 Go 的类型系统之上,并且与接口密切相关。通过前面的学习我们知道go语言的空接口包含类型(Type)和值(Value)两个部分,在反射里,也要用到类型(Type)和值(Value)。
reflect 包中定义了 reflect.Type 和 reflect.Value,正好对应我们前面所说的Type和Value。要注意的是 reflect.Type 是一个接口而 reflect.Value 是一个具体的结构体。在 reflect.Type 接口中定义了很多跟类型相关的方法,而 reflect.Value 则是绑定了很多跟值相关的方法。
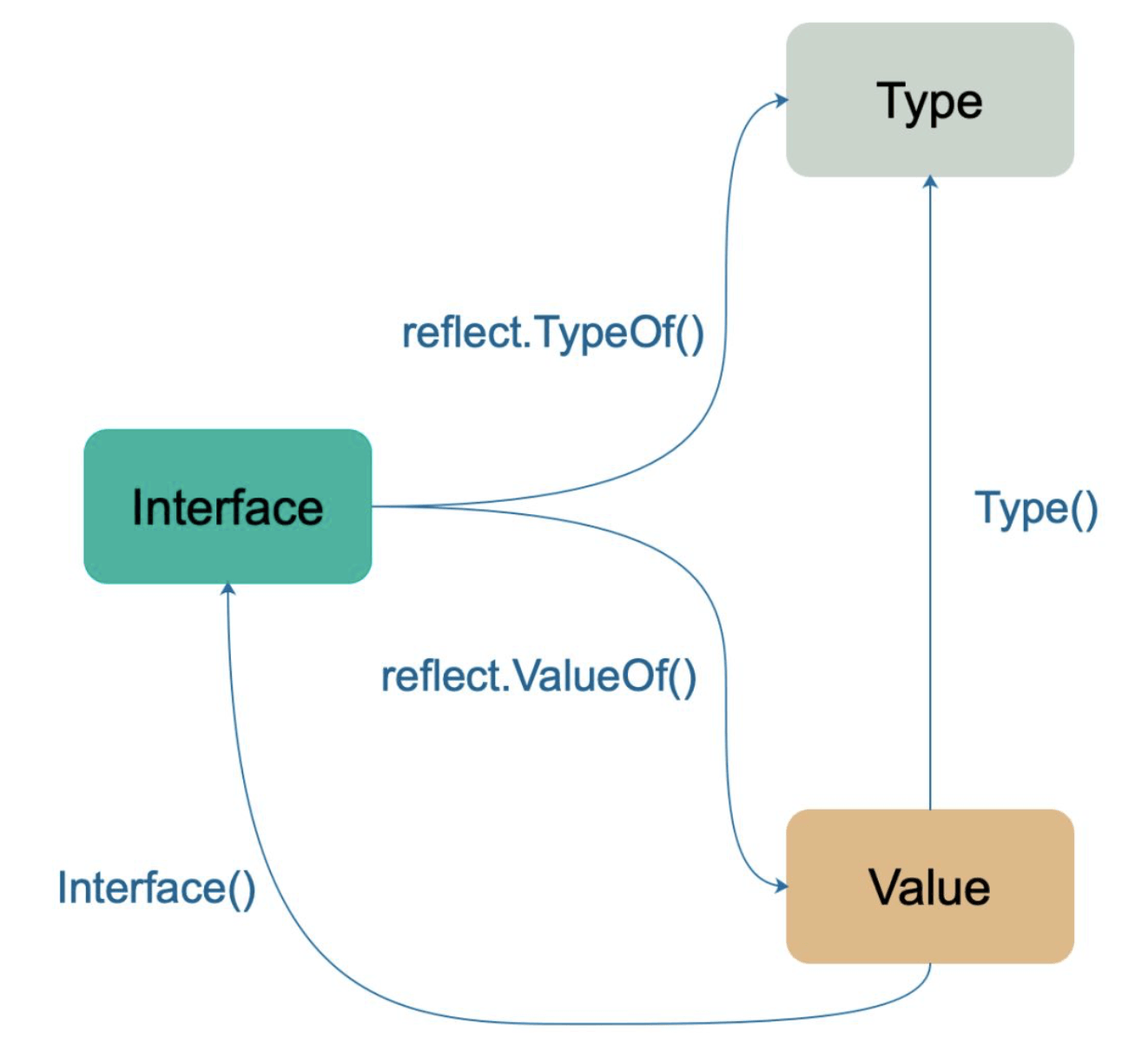
2.1 reflect.TypeOf()
reflect.TypeOf(x) 取到的是 x 在运行时的"动态类型"(更准确说:取的是把 x 当作 interface{} 传进去后,这个 interface 值里记录的具体类型)
由于 reflect.Type 是一个接口 ,所以只有当某个类型实现了这个接口,我们才能获取到它的类型 ,同时,在 reflect 包内,类型描述符是未导出类型 (就是小写字母开头的类型,这些类型对包外是不可见的,只能在定义的包内部使用),所以我们只能通过 reflect.TypeOf() 方法获取 reflect.Type 类型的值。
我们首先看一个例子,看看 reflect.TypeOf() 的常用用法
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
}
func main() {
var num int64 = 100
t1 := reflect.TypeOf(num)
fmt.Println(t1.String())
st := Student{
Name: "zhangsan",
Age: 18,
}
t2 := reflect.TypeOf(st)
fmt.Println(t2.String())
}代码输出:
go
int64
main.StudentTypeOf 接收参数类型是 any(即 interface{}),所以 num 会先被放进一个 interface 里。这个 interface 内部保存两部分:
- 动态类型(这里是 int64)
- 动态值(这里是 100)
TypeOf 就是把"动态类型"那部分拿出来。
可以看到对于基础类型和struct类型通过调用 reflect.TypeOf() 都打印出了对应的类型信息。注意 reflect.TypeOf 返回的是一个 reflect.Type 接口类型,我们通过调用这个接口的 String() 方法,得到最终的字符串信息
一个具体的数据类型是可以赋值给一个interface类型的,反过来则不行,要用到interface的断言。在一个interface赋值之后,其实是对应了两个类型,一个是静态类型,就是在程序编译期就确定的类型,interface的静态类型就是接口interface ,同时当interface赋值之后,他还有一个动态类型,就是被赋值的那个数据的具体类型,假设在上例中,我们将 st 赋值一个空 interface,那么这个 interface 的动态类型就是Student
举个例子
go
var hello interface{} = struct{}{}hello 的静态类型是 interface{}
hello 这个 interface 值当前保存的:
动态类型是 struct{}
动态值是 struct{}{}
对一个数据对象进行反射操作,其实是首先将具体对象类型转化为一个interface类型,然后再将interface类型转化为reflect包下的反射类型,反射类型里的类型信息和值信息其实是对应着这个中间类型interface的类型和值。

reflect.TypeOf() 方法获取的就是这个 interface{} 中的类型部分。
2.2 reflect.ValueOf()
同理,reflect.ValueOf() 方法自然就是获取接口中的值部分,reflect.ValueOf() 的返回值其实是一个 reflect.Value 结构
go
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
}
func main() {
var num int64 = 100
v1 := reflect.ValueOf(num)
fmt.Println(v1)
fmt.Println(v1.String())
st := Student{
Name: "zhangsan",
Age: 18,
}
v2 := reflect.ValueOf(st)
fmt.Println(v2)
fmt.Println(v2.String())
}程序输出
go
100
<int64 Value>
{zhangsan 18}
<main.Student Value>注意到这里 fmt.Println(v1) 和 fmt.Println(v1.String()) 打印的不一样,上面说了 reflect.ValueOf() 的返回值就是一个 reflect.Value 结构,但是 fmt.Println(v1) 却打印出了具体的值,这是因为 fmt.Println 的参数是一个接口类型,在执行过程中有一些类型转换,对 reflect.Value 结构做了特殊处理。
因为 fmt.Println 在打印参数时,会先走 fmt 包的格式化规则: 它会检查这个值有没有实现一些"可打印接口",而 reflect.Value 实现了 fmt.Stringer(也就是有 String() string 方法),所以 fmt 会优先调用它的 String() 来输出。
2.3 go语言数据种类
在go语言中常用的数据类型有26中,以枚举的方式定义在 src/reflect/type.go 文件中
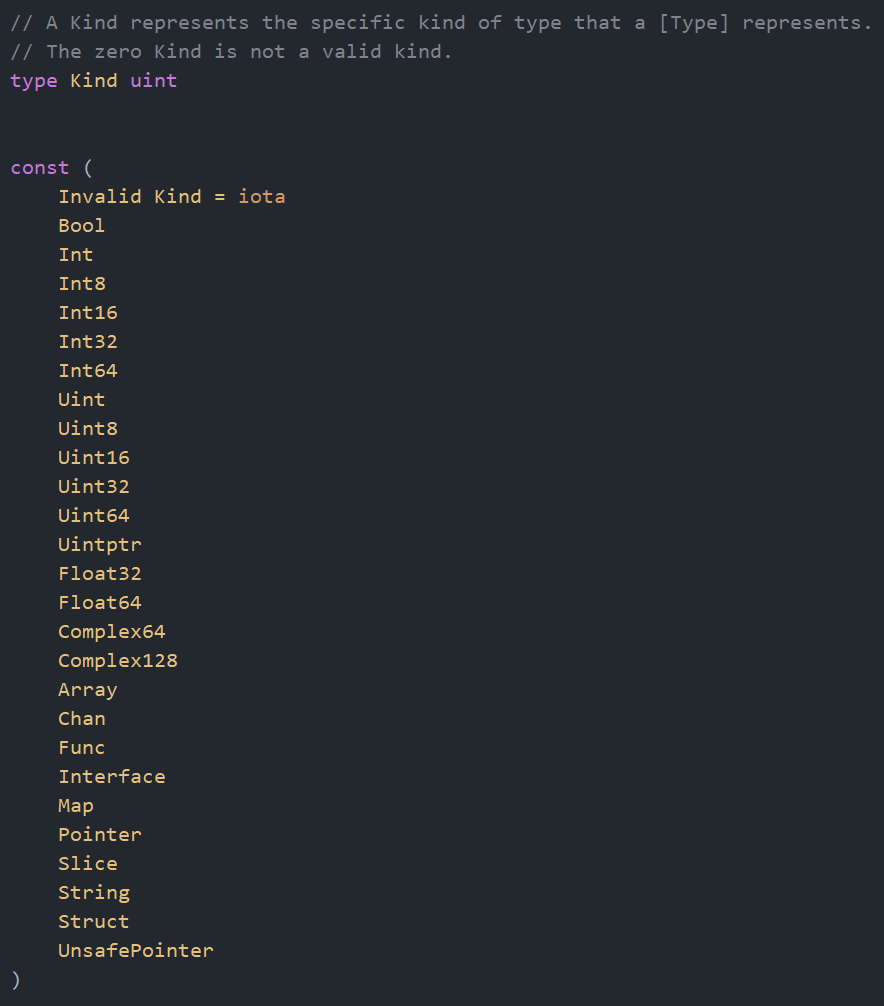
这些类型中包含int,bool之类的基础数据类型,也包含Struct,Array,Map等复合类型,有了这些类型,我们用type struct自定义的任何类型都可以由他们组合完成
看个type struct定义的数据类型使用反射的例子
go
package main
import (
"fmt"
"reflect"
)
type WrapInt int
func main() {
var num1 int = 100
var num2 WrapInt = 1000
num1 = int(num2) // 不同类型的type赋值,这里要强转
typeNum1 := reflect.TypeOf(num1)
fmt.Printf("type of num1 is %s\n", typeNum1.String())
typeNum2 := reflect.TypeOf(num2)
fmt.Printf("type of num2 is %s\n", typeNum2.String())
fmt.Printf("kind of num1 is %v\n", typeNum1.Kind())
fmt.Printf("kind of num2 is %v\n", typeNum2.Kind())
}程序输出:
go
type of num1 is int
type of num2 is main.WrapInt
kind of num1 is int
kind of num2 is int通过 WrapInt 的定义可以看到,WrapInt 其实就是用 type 给 int 取了个别名,二者底层其实都是 int 类型,但是通过 reflect.TypeOf 获取到各自的 type 其实是不一样的,不同 type 之间的变量赋值需要类型强制转换的,但是深层次的去分析 type 的种类,即 Kind 却是一样的。
reflect.TypeOf(x) 得到的是 "具体类型(Type)":带包名、带自定义名字、带完整信息的那个类型对象。
t.Kind() 得到的是 "类型的种类(Kind)":把很多具体类型归到少数几类里的"分类标签"。
3. 反射使用
3.1 值对象
reflect 包下跟值对象相关的常用函数或方法

3.1.1 获取struct反射值
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func main() {
st := Student{
Name: "zhangsan",
Age: 18,
Score: 95.5,
}
v := reflect.ValueOf(st)
fmt.Printf("the field num of Student is %d\n", v.NumField())
fmt.Printf("field1 type is %v, value is %s\n", v.Field(0).Type().Name(), v.Field(0).String())
fmt.Printf("field2 type is %v, value is %d\n", v.Field(1).Type().Name(), v.Field(1).Int())
fmt.Printf("field2 type is %v, value is %f\n", v.Field(2).Type().Name(), v.Field(2).Float())
}程序输出
go
the field num of Student is 3
field1 type is string, value is zhangsan
field2 type is int, value is 18
field2 type is float64, value is 95.500000v := reflect.ValueOf(st),v是一个Student类型的反射值对象,通过v.NumField()可以得出Student类型的字段个数,然后v.Field(i).Type().Name()打印出各个字段值的类型,v.Field(i)打印出各个字段值
注意:NumField()和Field()方法只有原对象是结构体时才能调用,否则会panic
3.1.2 获取map反射值
go
package main
import (
"fmt"
"reflect"
)
func main() {
m := map[int]uint32{
1: 100,
2: 200,
}
v := reflect.ValueOf(m)
for _, k := range v.MapKeys() {
field := v.MapIndex(k)
fmt.Printf("key type is %v, key = %d; value type is %v, value = %d\n", k.Type().Name(), k.Int(), field.Type().Name(), field.Uint())
}
}程序输出
go
key type is int, key = 1; value type is uint32, value = 100
key type is int, key = 2; value type is uint32, value = 200v := reflect.ValueOf(m)对map类型的对象m进行反射,通过v.MapKeys()得到m中所有key的reflect.Value对象 ,然后通过v.MapIndex(k)得到对应key反射值对象的value反射值对象 ,然后通过reflect.Value的Type().Name()方法获取map中key,value的类型,然后打印出对应值
用 reflect.ValueOf(m) 得到它的反射对象 v
通过 v.MapKeys() 拿到所有 key(每个 key 都是一个 reflect.Value)
对每个 key:
v.MapIndex(k) 拿到 value(也是 reflect.Value)
3.1.3 获取slice反射值
go
package main
import (
"fmt"
"reflect"
)
func main() {
slice := []int{1, 2, 3}
v1 := reflect.ValueOf(slice)
for i := 0; i < v1.Len(); i++ {
// Index(i) 返回的是 第 i 个元素的 reflect.Value
elem := v1.Index(i)
fmt.Printf("%v ", elem.Interface())
}
fmt.Println()
nums := [3]int{4, 5, 6}
v2 := reflect.ValueOf(nums)
for i := 0; i < v2.Len(); i++ {
elem := v2.Index(i)
fmt.Printf("%v ", elem.Interface())
}
fmt.Println()
}程序输出
go
1 2 3
4 5 6v1, v2分别是切片和数组的反射值对象,通过Len()获取到数组或切片中的元素个数,然后通过v.Index(i)获取对应元素的reflect.value对象,打印出其值
注意:Len()和Index(i)方法只能在原对象是切片,数组或字符串时才能调用,其他类型会panic。
Interface() 就是"拆盒子,拿出里面的东西"
3.2 类型对象
reflect.Value.NumField() --- 获取结构体的反射值对象中的字段个数,只对结构体类型有效
reflect.Value.Field(i) --- 获取结构体的反射值对象中的第i个字段,只对结构体类型有效
reflect.Value.Elem() --- 根据指针获取对应的具体类型
reflect.Value.NumIn() --- 获取函数反射类型的参数个数
reflect.Value.In(i) --- 获取函数反射类型的第i个参数
reflect.Value.NumOut() --- 获取函数反射类型的返回值个数
reflect.Value.Out(i) --- 获取函数反射类型的第i个返回值
reflect.Value.NumMethod() --- 获取struct上绑定的方法个数
reflect.Value.Method(i) --- 获取struct上绑定的第i个方法
reflect.Type
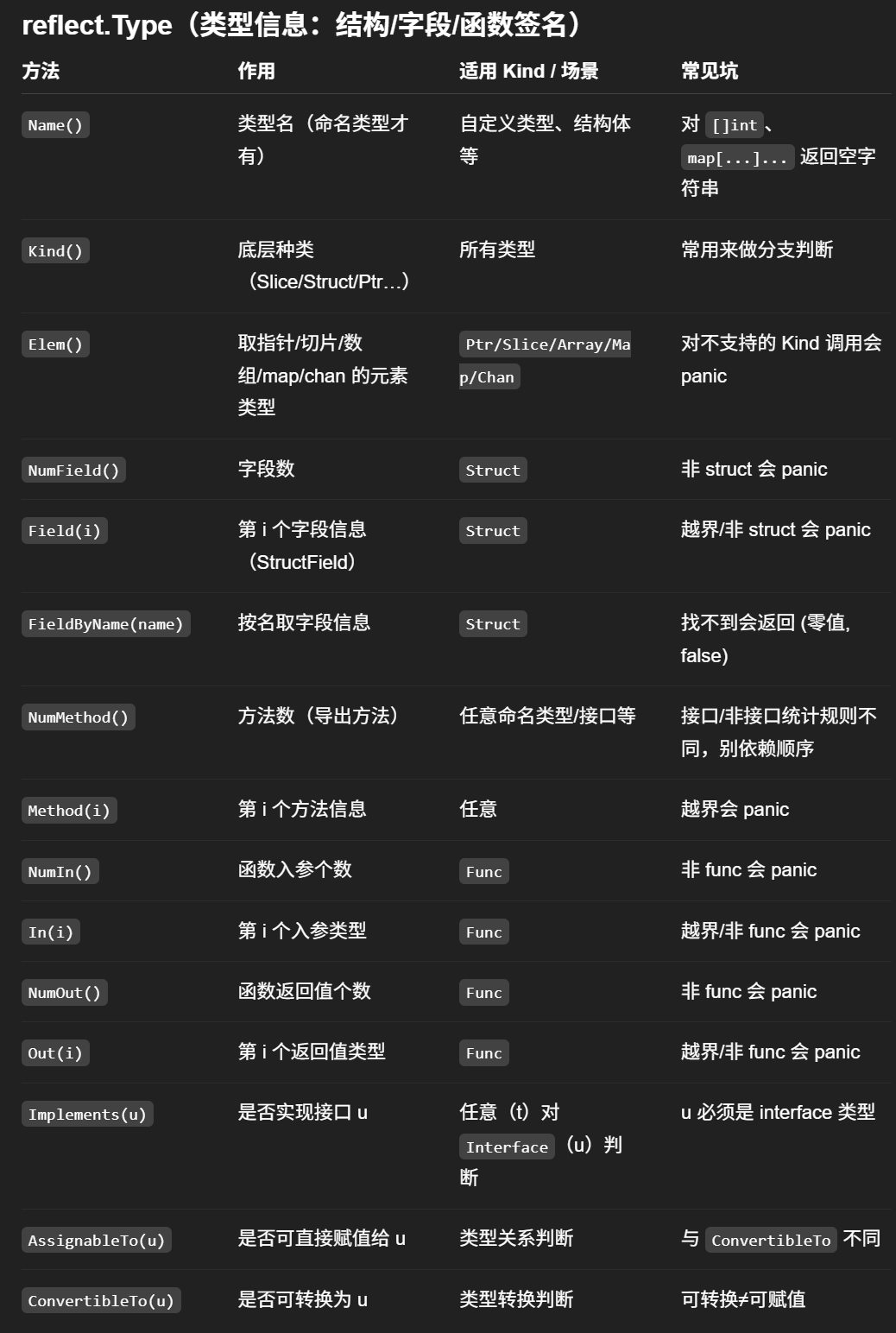
reflect.Value

3.2.1 struct反射类型
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func main() {
st := Student{
Name: "zhangsan",
Age: 18,
Score: 90.5,
}
t := reflect.TypeOf(st)
fmt.Println(t.Name())
fmt.Println(t.Kind())
fmt.Println(t.NumField())
for i := 0; i < t.NumField(); i++ {
fmt.Printf("field1 name is %s, field1 type is %s\n", t.Field(i).Name, t.Field(i).Type.String())
}
}程序输出
go
Student
struct
3
field1 name is Name, field1 type is string
field1 name is Age, field1 type is int
field1 name is Score, field1 type is float64通过reflect.Type的Name()方法可以获取对应的Type类型,Kind()方法获取底层的数据种类,即kind,跟reflect.Value一样,reflect.Type也提供了NumField()方法用于获取结构体对象中的字段个数,通过t.Field(i).Name可以获取对应字段的名字
同样,Field(i)和NumField()也只能对结构体反射使用
对于reflect.TypeOf()的返回值,需要使用Name()
对于 Field(i)的返回值,需要使用Name
3.2.2 指针反射类型
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func main() {
st := &Student{
Name: "zhangsan",
Age: 18,
Score: 90.5,
}
t := reflect.TypeOf(st)
fmt.Println(t.Kind())
fmt.Println(t.Elem().Name()) // 这里一定要加Elem(),根据指针获取到具体类型后,才能或者具体的type名
fmt.Println(t.Elem().NumField()) // 这里一定要加Elem(), 根据指针获取到具体类型后,才能字段个数
for i := 0; i < t.Elem().NumField(); i++ {
fmt.Printf("field1 name is %s, field1 type is %s\n", t.Elem().Field(i).Name, t.Elem().Field(i).Type.String())
}
}程序输出
handlebars
ptr
Student
3
field1 name is Name, field1 type is string
field1 name is Age, field1 type is int
field1 name is Score, field1 type is float64可以看到,跟上面直接获取struct有一点点小小的区别,那就是fmt.Println(t.Kind())打印出的是一个ptr指针类型,而不再是struct类型,正是因为这里是一个ptr,所以我们不能直接在这个ptr上调用.Name()以及其他的.NumField()之类的方法,要根据ptr的.Elem()获取到具体类型之后,才能用这些方法,否则程序就会报panic,这点一定要注意
3.2.3 函数反射类型
go
package main
import (
"fmt"
"reflect"
)
func Add(num1, num2 int) (int, error) {
return num1 + num2, nil
}
func main() {
fmt.Println("input:")
t := reflect.TypeOf(Add)
for i := 0; i < t.NumIn(); i++ {
tIn := t.In(i)
fmt.Print(tIn.Name())
fmt.Printf(" ")
}
fmt.Printf("\n---------------------------------\n")
fmt.Println("output:")
for i := 0; i < t.NumOut(); i++ {
tOut := t.Out(i)
fmt.Print(tOut.Name())
fmt.Print(" ")
}
fmt.Println()
}程序输出
go
root@GoLang:~/proj/goforjob# go run main.go
input:
int int
---------------------------------
output:
int error t := reflect.TypeOf(Add)获取到Add函数的type类型,然后通过NumIn()方法获得Add函数的参数个数,依次打印出参数的类型。通过NumOut()方法获得Add函数的返回值个数,依次打印出返回值的类型
3.2.4 反射获取struct方法
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func (s *Student) GetName() string {
return s.Name
}
func (s *Student) SetName(name string) {
s.Name = name
}
func (s *Student) GetAge() int {
return s.Age
}
func (s *Student) SetAge(age int) {
s.Age = age
}
func (s *Student) GetScore() float64 {
return s.Score
}
func (s *Student) SetScore(score float64) {
s.Score = score
}
func main() {
st := &Student{
Name: "zhangsan",
Age: 18,
Score: 90.5,
}
t := reflect.TypeOf(st)
for i := 0; i < t.NumMethod(); i++ {
m := t.Method(i)
fmt.Printf("%+v\n", m)
}
}程序输出
go
root@GoLang:~/proj/goforjob# go run main.go
{Name:GetAge PkgPath: Type:func(*main.Student) int Func:<func(*main.Student) int Value> Index:0}
{Name:GetName PkgPath: Type:func(*main.Student) string Func:<func(*main.Student) string Value> Index:1}
{Name:GetScore PkgPath: Type:func(*main.Student) float64 Func:<func(*main.Student) float64 Value> Index:2}
{Name:SetAge PkgPath: Type:func(*main.Student, int) Func:<func(*main.Student, int) Value> Index:3}
{Name:SetName PkgPath: Type:func(*main.Student, string) Func:<func(*main.Student, string) Value> Index:4}
{Name:SetScore PkgPath: Type:func(*main.Student, float64) Func:<func(*main.Student, float64) Value> Index:5}
root@GoLang:~/proj/goforjob# - reflect.Type.NumMethod():返回struct所绑定的方法个数
- reflect.Type.Method(i):返回第 i 个方法的 reflect.Method 对象
reflect.Method 定义在 src/reflect/type.go 文件:
go
type Method struct {
Name string // 方法名
PkgPath string
Type Type // 方法类型 (
Func Value // 方法值 (方法的接收器作为第一个参数)
Index int // 是结构体中的第几个方法
}所以,通过 reflect.Method 对象,我们可以获取到struct所绑定的对应方法的方法名,方法类型等信息
3.3 通过反射调用方法
reflect.Type.Method(i) 可以获取到struct所绑定的具体的方法对象 reflect.Method,通过这个对象,我们不仅可以获取方法的详细信息,还可以动态的调用方法。
其实在 reflect.Value 里我们也可以使用 NumMethod() / Method(i) 方法获取到对应的方法信息,不同的是 reflect.Value.Method(i) 返回的是一个 reflect.Value 对象,但是同样可以根据这个对象来动态调用方法,只是两者调用方法的方式有所区别
请看具体例子
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func (s *Student) GetName() string {
return s.Name
}
func (s *Student) SetName(name string) {
s.Name = name
}
func (s *Student) GetAge() int {
return s.Age
}
func (s *Student) SetAge(age int) {
s.Age = age
}
func (s *Student) GetScore() float64 {
return s.Score
}
func (s *Student) SetScore(score float64) {
s.Score = score
}
func main() {
st := &Student{
Name: "zhangsan",
Age: 18,
Score: 90.5,
}
fmt.Printf("st === %+v\n", st)
t := reflect.TypeOf(st)
v := reflect.ValueOf(st)
m1, ok := t.MethodByName("SetName") // 获取SetName方法
fmt.Printf("t get func by name:%t\n", ok)
argsV1 := make([]reflect.Value, 0)
// 要手动传 receiver
argsV1 = append(argsV1, v)
argsV1 = append(argsV1, reflect.ValueOf("lisi"))
// 等价于st.SetName("lisi")
m1.Func.Call(argsV1)
fmt.Printf("st === %+v\n", st)
m2 := v.MethodByName("SetName") // 获取SetName方法
argsV2 := make([]reflect.Value, 0)
// 不需要传 receiver
argsV2 = append(argsV2, reflect.ValueOf("wangwu"))
m2.Call(argsV2)
fmt.Printf("st === %+v\n", st)
}程序输出
go
root@GoLang:~/proj/goforjob# go run main.go
st === &{Name:zhangsan Age:18 Score:90.5}
t get func by name:true
st === &{Name:lisi Age:18 Score:90.5}
st === &{Name:wangwu Age:18 Score:90.5}可以看到通过 reflect.Type.MethodByName() 方法获取到的 reflect.Method 对象和 reflect.Value.MethodByName() 方法获取到的 reflect.Method 获取到的 reflect.Value 对象都可以在程序运行时动态的调用方法修改结构体本身,student的name由zhangsan----->lisi----->wangwu。
但是二者的调用存在一个区别:
通过这个 reflect.Method 调用方法,必须使用 Func 字段,而且要传入接收器的 reflect.Value 作为第一个参数:
go
m1.Func.Call(argsV1)reflect.Value.MethodByName() 返回一个 reflect.Value 对象,它不需要接收器的 reflect.Value 作为第一个参数,而且直接使用 Call() 发起方法调用:
go
m2.Call(argsV2)第一个是通过reflect.Type.MethodByName()获取到reflect.Method()对象,然后调用方法,所以需要使用func字段,第二个是reflect.Value()对象,所以不需要Func字段
3.4 通过反射设置值
在介绍通过反射设置或者说是修改值的方法之前,首先介绍一个概念,反射寻址 。简单的说,可寻址就是可以根据地址找到值 ,在反射里面,reflect.Value 由 reflect.ValueOf() 方法得到,根据命名就可以知道 reflect.ValueOf() 是得到一个值对象,显然他不能得到这个值的地址 。所以通过 reflect.ValueOf() 方法得到的 reflect.Value 都是不可寻址的。在 reflect 包下有一个 CanAddr() 方法可以用于验证一个对象是否可寻址
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func main() {
st := &Student{
Name: "zhangsan",
Age: 18,
Score: 90.5,
}
v := reflect.ValueOf(st)
fmt.Println(v.CanAddr())
}程序输出
go
false尽管这里st是一个 Student 类型的指针,但是经过 reflect.ValueOf() 之后得到的对象v,仍然是不能寻址的,st他只能反映出当前指针指向的具体元素的地址,而当前指针自身所在的内存地址是无从得知的。
假设 reflect.ValueOf() 返回的是一个指针的 reflect.Value 对象,那么我们可以调用 reflect.Value.Elem() 方法得到具体的类型,而此时得到的这个反射具体类型就是可寻址的,我们可以知道他的地址,道理很简单,因为 reflect.Value.Elem() 获取到的值,记录了根据指针获取到值这个获取路径,显然我们可以根据值追溯到地址。
1. reflect.Value.Elem() 方法得到具体的类型可寻址
通过代码验证一下:
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func main() {
st := &Student{
Name: "zhangsan",
Age: 18,
Score: 90.5,
}
v := reflect.ValueOf(st)
fmt.Println(v.Elem().CanAddr())
}程序输出
go
true2. 对切片进行反射时,通过 reflect.Value.Index(i) 获取到的 reflect.Value 对象是可以寻址的
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func main() {
slice := []int{1, 2, 3, 4, 5}
v := reflect.ValueOf(slice)
// 拿到 slice[0] 这个元素(用反射拿)
fmt.Println(v.Index(0).CanAddr())
fmt.Println(v.Index(1).CanAddr())
}程序输出
go
true
true但是对数组 reflect.Value.Index(i) 获取到的 reflect.Value 对象是不可寻址的
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func main() {
nums := [3]int{1, 2, 3}
v1 := reflect.ValueOf(nums)
fmt.Println(v1.Index(0).CanAddr())
}程序输出
go
false通过 reflect.ValueOf 得到的其实是原始数据的一份拷贝 ,切片底层实现其实是一个 struct 类型,struct 里包含一个执行具体数组的指针 ,对切片拷贝,虽然拷贝了这个 struct,自然 struct 里的指针也拷贝了一份,但是两个指针执行同一个内存区域,所以修改拷贝的切片,也会影响原值
3. 通过结构体的指针获取到的字段也是可寻址
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func main() {
st := &Student{
Name: "zhangsan",
Age: 18,
Score: 90.5,
}
v := reflect.ValueOf(st)
f := v.Elem().Field(0)
fmt.Println(f.CanAddr())
}程序输出
go
true通过上面分析,可寻址就是可以找到数据本身,而不是找到数据的副本,既然我们找到了数据本身,那么就可以对原数据修改,即设置值了吗?
大体上是这样,但是条件可能还要更严格一些,光是可寻址还不够,比如当 struct 里含有未导出字段时(未导出字段就是首字母小写,只能被包内部访问),这个未导出字段时不可设置的。所以,在 reflect 包下有一个专门的方法用于判断这个值是否可修改:CanSet()
假设我们将 Student 的 score 字段改为未导出的
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
score float64
}
func main() {
st := &Student{
Name: "zhangsan",
Age: 18,
score: 90.5,
}
v := reflect.ValueOf(st)
f := v.Elem().Field(0)
fmt.Println(f.CanSet())
f2 := v.Elem().Field(2)
fmt.Println(f2.CanSet())
}程序输出
go
true
false可以看到,可导出字段 Name 是可设置的,而不可导出字段 score 是不可设置的
当我们判定一个值是可设置之后,接下来要怎么修改这个值呢?
reflect.Value 为基础类型提供了一系列特殊的 Set 方法:SetInt、SetUint、SetFloat 等在反射的时候修改对应类型值
下面看个具体例子
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string
Age int
Score float64
}
func main() {
st := &Student{
Name: "zhangsan",
Age: 18,
Score: 90.5,
}
v := reflect.ValueOf(st)
f := v.Elem().Field(0)
f.SetString("lisi")
fmt.Printf("st = %+v\n", st)
}程序输出
go
st = &{Name:lisi Age:18 Score:90.5}可以看到,通过调用第一个字段 reflect.value 的 SetString 方法,将 st 对象的 Name 改为了 lisi
3.5 结构体标签
我们在定义结构体的时候,可以为每个字段后面加一个标签,即 StructTag,标签其实就是一组键值对,每个键值对用空格分开,这些标签信息可以通过反射获取。
go
package main
import (
"fmt"
"reflect"
)
type Student struct {
Name string `json:"name"`
Age int `json:"age"`
Score float64 `json:"score"`
}
func main() {
st := &Student{
Name: "zhangsan",
Age: 18,
Score: 90.5,
}
t := reflect.TypeOf(st).Elem()
for i := 0; i < t.NumField(); i++ {
f := t.Field(i)
fmt.Println(f.Tag)
}
}程序输出
go
json:"name"
json:"age"
json:"score"4. 反射的优缺点
-
优点:
可以提升程序代码的灵活性,根据条件在程序运行时灵活的调用函数,并且修改源代码结构
-
缺点:
主要是性能影响,反射过程中会有大量的内存开辟和gc过程,导致程序的性能降低
反射的应用场景
- 结构体标签解析(Struct Tags),如:获取结构体字段的 tag
- 动态字段赋值 / 映射 map 到结构体,如:map 转 struct
- ORM 框架(如 GORM)
ORM 使用反射来:
解析结构体字段的标签(如 gorm:"column:id;type:bigint")
动态创建数据库查询
自动迁移表结构
查询结果扫描到结构体 - 配置加载(Viper + mapstructure)
- RPC 框架(如 Go 官方 net/rpc)
Go 的 net/rpc 框架:
使用反射查找结构体中的方法
验证方法是否符合 func(args, reply) error 签名
动态调用方法
你注册一个对象,RPC 框架用反射来发现它有哪些方法可以远程调用。 - 数据验证库(如 validator)
使用反射读取 struct tag,并对字段值进行校验。 - 自动生成代码辅助工具
有些工具在运行时需要动态处理未知类型,比如:
自动生成文档
数据导出引擎
日志记录器(记录结构体字段值)
这些场景中,类型在写代码时未知,只能用反射处理。
之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!