过去 10 年,数据分析基准的成绩已经提升了数十倍。这种性能的提升造就了商业世界中更大的可能------从特定维度的 MOLAP 分析和周期报表,到随时随地从任意维度分析中发掘新范式的 Ad-hoc 查询,直到现在基于 Agent 派生出的复杂查询、高并发 + 高性能需求。基于日益实时、智能的 OLAP 引擎,企业的数据资产正在产生更大的价值。
从简单、固定、分钟到小时级别的查询,到亚秒级、PB 级数据、大宽表、高并发、复杂 JOIN 和聚合,我们为何在今天能够实现当初不敢想象的分析需求?
Apache Doris 的演进给我们提供了一个生动的答案------它不仅跟随硬件与编译器的发展而演进,更主动地通过向量化、模板化、指令级并行与精细的用户态调度模式,将每一代 CPU 的潜力推向理论极限。
1. Background:硬件与编译器的变迁
这十年硬件与编译器的发展轨迹,彻底改变了高性能数据库的设计哲学:
- CPU:从"更快"到"更宽、更多"
- 主频停滞,核心爆发 :单个核心的主频已在 3-5GHz 徘徊多年,性能提升转而依赖核心数量 (从个位数到百核级)和单核心的并行宽度(SIMD)。
- 内存墙加剧 :CPU 与主存的速度差距已超 300 倍。缓存命中率成为性能的生命线,一次缓存未命中(Cache Miss)的代价足以执行数百条指令。
- SIMD 成为标配 :AVX2(256 位)、AVX-512(512 位)及 ARM SVE 等指令集,允许单条指令处理 4 至 16 个数据单元。不用 SIMD,就等于主动浪费超过 80%的浮点算力。
- 编译器 :从"翻译者"到"优化合作伙伴"
- 激进的内联与向量化 :现代编译器(如 Clang/GCC)能在编译期进行循环展开、分支消除、自动向量化 ,但其优化能力极度依赖代码模式。虚函数、指针别名、分支预测失败会瞬间阻断其优化通路。
- 跨平台抽象:通过优良的代码模式,编译器能够自动为循环生成 SIMD 代码,无缝迁移不同平台。但对于复杂的数据处理逻辑,仍然需要手动生成 SIMD 代码。
- 新硬件下的 OLAP 性能陷阱
-
基础设施的升级迭代,意味着传统数据库引擎的微观开销被急剧放大:
-
火山模型 :每行的虚函数调用,导致指令缓存(I-Cache) 被频繁冲刷,核心处于"饥渴"状态。
-
动态分支:在数据密集的循环中,一次预测失败可能清空长达 15-20 级的指令流水线。
-
随机内存访问 :不连续的内存访问模式,让 CPU 的预取器(Prefetcher)失效,大部分时间在等待数据从内存加载。
-
因此,性能优化必须从"算法优化"下沉为"与硬件和编译器的对话"。Apache Doris(及其商业化版本)不断在各类主流 benchmark 上取得令人惊叹的领先(例如,ClickBench#1,JsonBench#1,RtaBench#1),背后正是这些与现代硬件体系协同进步的决心。
2. 向量化执行:从"行"到"列"的降维打击
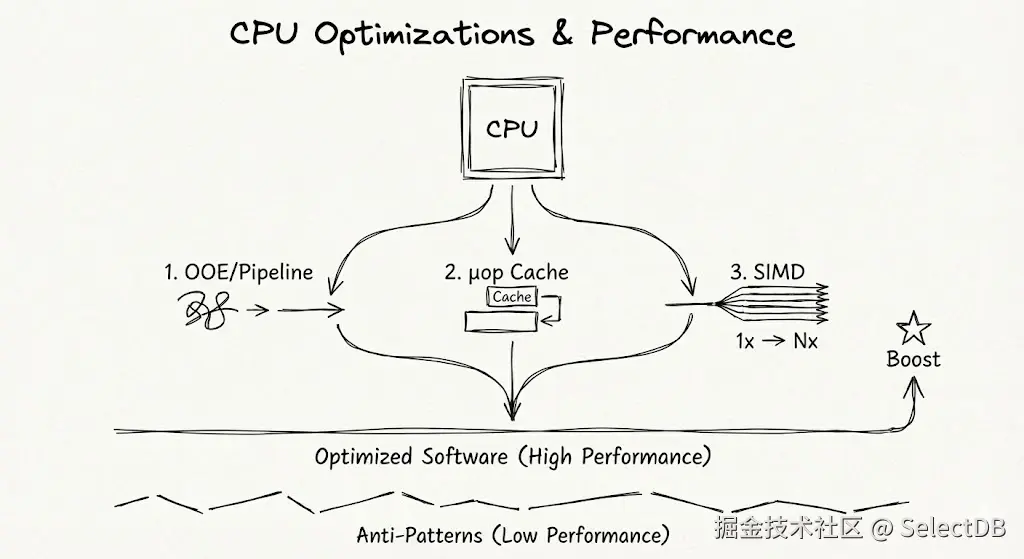
现代的 CPU 架构中,存在着大量激进如"黑科技"般的优化手段,例如指令乱序发射(OOE)、多级流水线、向量指令集(AVX、Neon、SVE)。它们能够使你的代码在同等的算力下性能倍增------前提是,你没有反模式。
- 指令乱序发射与流水线:现代 CPU 的流水线深度可达 15-20 级,并通过乱序执行引擎动态调度指令。互相没有依赖的指令虽然在汇编与机器码中有先后顺序,但实际可以完全并行。其性能发挥的关键在于指令流的连续性和可预测性。一次错误的分支预测会导致整个流水线被重置,带来约 15 个时钟周期的惩罚;而一次缓存未命中(Cache Miss) 导致的数百周期等待,更会让所有精巧设计瞬间归零。1
- 微指令缓存(μop Cache):μop Cache 是处理器前端的一种硬件缓存结构,能够缓存热指令,跳过解码阶段,提升每周期指令数(IPC)。根据常规统计,μop Cache 能够产生稳定、可观(2% ~ 10%)的 IPC 增加。但在目前常见的数据应用中,实际命中率从 30% 到 70% 差距很大2,是明显的性能提升点。
- 向量指令集(SIMD) :这是性能提升一个数量级的核心武器。从 SSE 的 128 位到 AVX2 的 256 位,再到 AVX-512 的 512 位,意味着单条指令可同时处理的数据量从 4 个 32 位整数跃升至 16 个。理论峰值算力因此呈倍数增长。例如,在理想的数据密集循环中,使用 AVX-512 相比标量代码可带来 10 倍以上的吞吐量提升。
早期的数据库执行引擎多基于火山模型(Volcano Model),以 Tuple(行)为单位进行处理。在 CPU 主频停滞、核心数增加的今天,这种方式导致了大量的虚函数调用 和糟糕的指令缓存命中率。这是因为在逐行处理的情况下,我们需要频繁地切换处理对象(列)的类型,执行不同的操作。这导致指令缓存命中率极低,且无法利用向量化指令进行批量处理,逐行的虚函数开销最高可达常规执行的数十倍35。
Doris 的全面向量化重构,核心在于引入了Block和Column的概念。这是内存布局的重大变革:
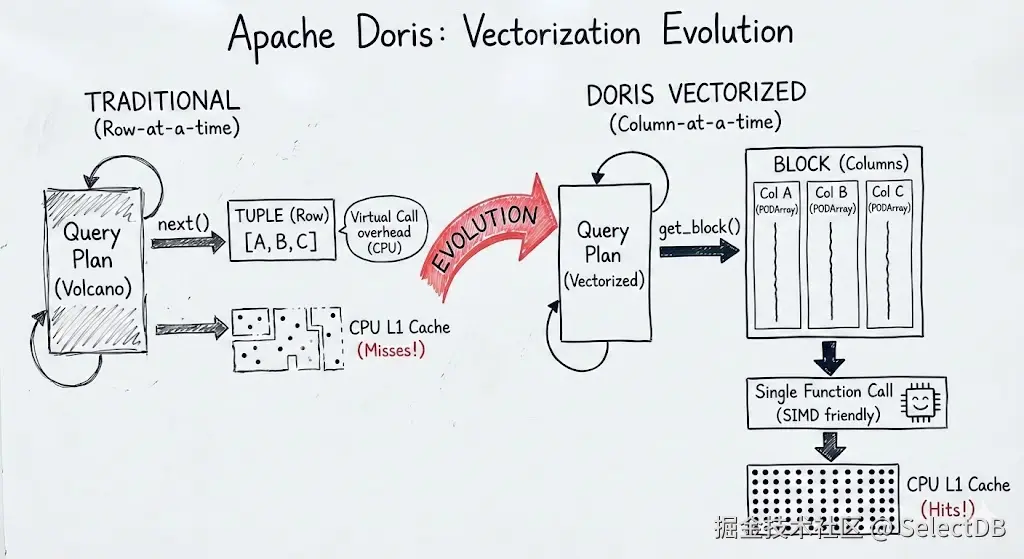
2.1 内存布局与 Cache Locality
在 Doris 的向量化引擎中,一列数据在内存中是连续存储的。例如一个INT类型的列,直接使用 Doris 中的PODArray(Plain Old Data Array)来存储数据。
C++
// 核心逻辑示意
template <typename T>
class ColumnVector final : public IColumn {
private:
// PaddedPODArray 保证了内存对齐,通常按 64 字节对齐以适配 Cache Line
PaddedPODArray<T> data;
public:
// 向量化计算入口,不再处理单行,而是处理整个 data 数组
void filter(const Filter& filt) override {
// ...
}
}这种布局保证了同一列的数据在物理上连续。当 CPU 从内存加载数据到 Cache 时,能够一次性加载多个数据项,极大提升了指令/数据缓存的局部性(Cache Locality)。由于近些年 CPU 数据 Cache 容量大幅提升,常规运算的完成较大程度依赖在 L2 cache 中完全装载数据。如果因为数据不连续频繁刷新缓存,可能带来 3~5 倍的局部性能损失36。
在传统批处理模型下,Next()接口一次返回的Block 通常包含 4096 行,那么就会发生 4096 次的虚函数调用。而在向量化代码中,整个 Column 每次一起处理,虚函数调用仅发生一次。在复杂算子(如 Hash Join、Aggregation)中,这种调用开销的降低是数量级的区别。
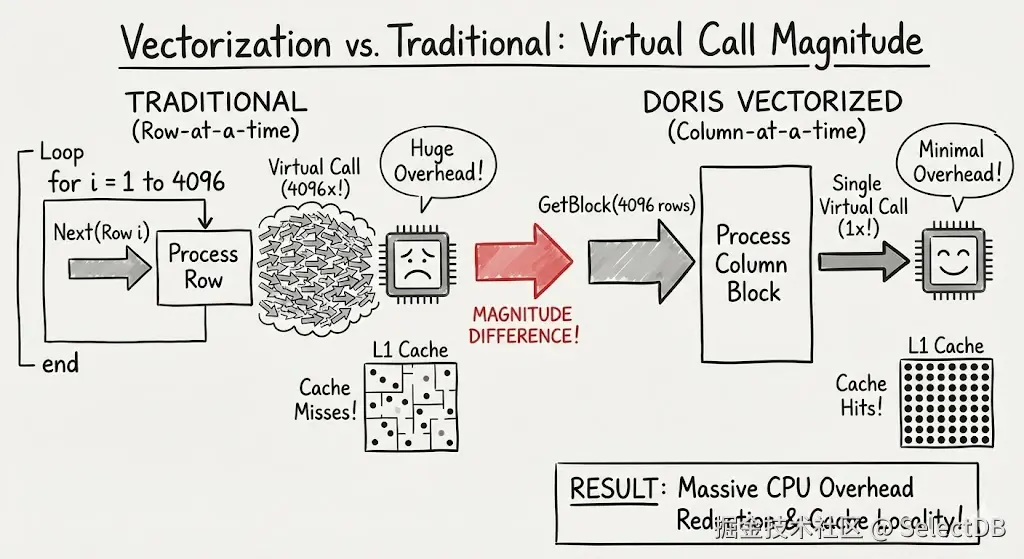
2.2 自动与手动向量化的结合
随着编译器进化至今,编译优化的技术同数据库一样有了飞跃式的进步。在更多的场景下,编译器已能实现以前无法自动进行的优化。自动向量化(Auto Vectorization)就是其中的重要方面。
在绝大多数情况下,利用编译器自动生成向量化的代码是最佳的方案------它天然带来了跨平台迁移的友好,代码也一目了然。而这并不意味着相关代码的工程难度降低,许多时候反而更加复杂------因为最终执行的代码向量化程度不再是编码时的"所见即所得",其中涉及到了复杂的编译器行为。要保证最高的代码生成质量,开发者编码时必须尽可能遵守良好的开发范式。
当然,在一些更为复杂的场景下,手动调用的向量化代码仍是不可避免的。因此 Doris 采用了"自动+手动"的双重策略:
- 自动向量化:对于绝大多数情况下,这是现代编译器提供给我们的最佳选择。核心在于,简化循环体,抽离控制流分支(Branch),让编译器识别出 Auto Vectorization 的机会。
- 手动向量化:对于实际汇编识别出未能正常 Auto Vectorization 的算子,或是那些热点路径上的向量化需求,Doris 工程师并不避讳直接手写 Intrinsic 代码。相比于自动生成的代码,此种方式往往拥有更加极致的性能,几乎没有指令浪费。
例如以下场景:
A. 谓词过滤(Filter)
在WHERE子句处理中,过滤结果通常是一个uint8_t的数组(0 或 1)。将过滤后的数据拷贝到新 Block 是高频操作。 Doris 利用 AVX2 的 _mm256_movemask_epi8 指令,快速生成选择掩码,并配合 _mm256_permutevar8x32_epi32 等指令进行数据重排(Shuffle),避免了传统分支判断带来的流水线冲刷。在相同的指令周期内,实现更大的数据吞吐量。
B. 字符串与 JSON 处理
字符串匹配(Like)、JSON 解析是 CPU 密集型操作。Doris 引入了特定的 SIMD 算法或者库:
- Volnitsky 算法:在子串查找中,利用 SIMD 并行比较多个字符,快速跳过不匹配区域。
- SimdJson :在解析 JSON Path 时,利用 SIMD 指令快速定位结构符(如
{,},:),大幅缩短解析路径。
C++
// SIMD 子串匹配
const uint8_t* _search(const uint8_t* haystack, const uint8_t* haystack_end) const {
......
while (haystack < haystack_end && haystack_end - haystack >= needle_size) {
#if defined(__SSE4_1__) || defined(__aarch64__)
if ((haystack + 1 + n) <= haystack_end && page_safe(haystack)) {
/// find first and second characters
const auto v_haystack_block_first =
_mm_loadu_si128(reinterpret_cast<const __m128i*>(haystack));
const auto v_haystack_block_second =
_mm_loadu_si128(reinterpret_cast<const __m128i*>(haystack + 1));
const auto v_against_pattern_first =
_mm_cmpeq_epi8(v_haystack_block_first, first_pattern);
const auto v_against_pattern_second =
_mm_cmpeq_epi8(v_haystack_block_second, second_pattern);
const auto mask = _mm_movemask_epi8(
_mm_and_si128(v_against_pattern_first, v_against_pattern_second));
/// first and second characters not present in 16 octets starting at `haystack`
if (mask == 0) {
haystack += n;
continue;
}
......
}3. 模板编译:消除运行时开销
前面我们讨论了分支预测、数据和指令缓存、指令流水线这些"看得见摸不着"的性能关键点。那么,一次虚函数调用究竟会产生多大的开销?可以用一个小例子来说明:
C++
class VirtualBase {
virtual int foo(int x);
};
class VirtualDerived : public VirtualBase {
int foo(int x) override;
};
class NonVirtual {
int bar(int x);
};
static void BM_VirtualCall(benchmark::State& state) {
VirtualBase* obj = new VirtualDerived();
for (auto _ : state) {
result = obj->foo(42);
}
}
static void BM_NonVirtualCall(benchmark::State& state) {
NonVirtualBase obj;
for (auto _ : state) {
result = obj.bar(42);
}
}
static void BM_DirectCall(benchmark::State& state) {
VirtualDerived obj;
for (auto _ : state) {
result = obj.foo(42);
}
}
以上结果产生自 Clang++ 17.0 -O3 -std=c++20 条件下的测试,可以看到,虚函数调用导致了普通函数 5 倍的性能开销。
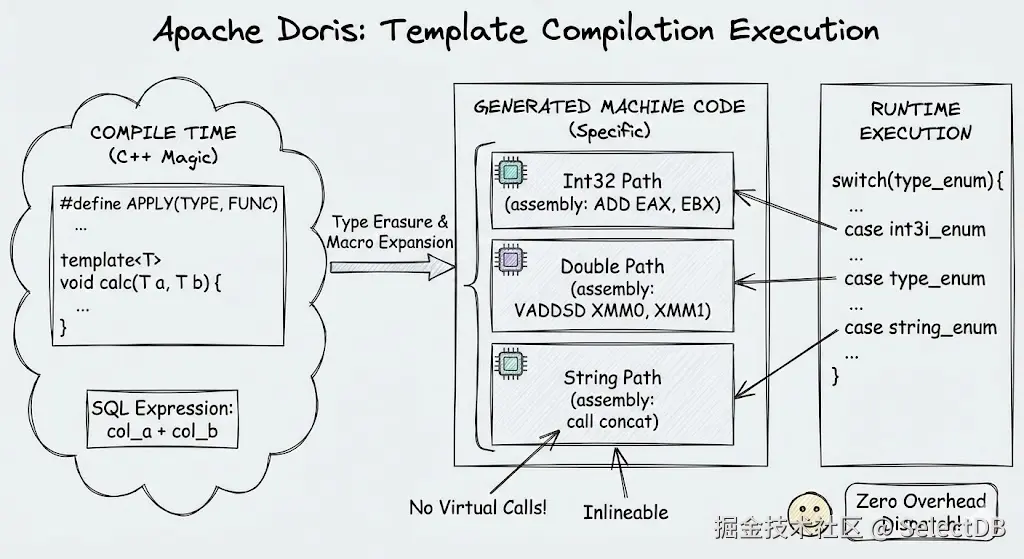
因此,如何尽可能消除虚函数是 OLAP 领域中的重要课题。过去的研究展现了两种常见的大方向:编译执行和向量化执行。Doris 选择的是向量化执行的方案 ,它通过一次处理一个 Block 的数据,将这些虚函数和分支的 overhead 均摊到数千行上。那么,有没有一种方式,能够在向量化执行的基础上,像编译执行一样彻底消除掉所有的分支 overhead 呢?答案是:有的。
3.1 模板的艺术
编译执行的本质是对于不同的类型、分支等代码路径,生成在当前条件下完全确定的代码,从而消去不同类型所需的判断和虚表访问。
例如对于一个a + b的操作,编译执行并没有一个通用的add(Value a, Value b)函数,而是为int + int、double + double生成了完全独立的机器码。CPU 在执行时,不仅没有虚函数指针跳转,甚至可以将简单的加法指令直接内联(Inline),从而充分利用指令流水线。
在"编译执行"框架下,这往往通过 LLVM JIT 等代码生成框架完成,针对用户的表达式现场生成一套完全固定的汇编并执行。但在"向量化执行"框架下,这同样可以通过 C++ 的模板编程实现。例如对于 days_add 函数:
C++
template <PrimitiveType PType>
struct AddDaysImpl {
......
static inline ReturnNativeType execute(const InputNativeType& t, IntervalNativeType delta) {
// PType 已经固定,不需要运行期判断
return date_time_add<TimeUnit::DAY, PType, IntervalNativeType>(t, delta);
// compare to
// if (t.is_date) {
// return date_time_add<TimeUnit::DAY, DATEV2, IntervalNativeType>(t, delta);
// } else {
// return date_time_add<TimeUnit::DAY, DATETIMEV2, IntervalNativeType>(t, delta);
// }
}
// 不同模板实例参数不同,函数匹配时直接命中对应实例
static DataTypes get_variadic_argument_types() {
return {std ::make_shared<typename PrimitiveTypeTraits<PType>::DataType>(),
std ::make_shared<typename PrimitiveTypeTraits<IntervalPType>::DataType>()};
}
}
using FunctionAddDays = FunctionDateOrDateTimeComputation<AddDaysImpl<TYPE_DATEV2>>;
using FunctionDatetimeAddDays = FunctionDateOrDateTimeComputation<AddDaysImpl<TYPE_DATETIMEV2>>;
factory.register_function<FunctionDatetimeAddDays>();
factory.register_function<FunctionAddDays>();可以看到,对于不同的入参类型(DATE 和 DATETIME),函数在参数匹配时已经命中了不同的实例,这些实例各自包含确定的类型信息,规避了运行期的虚表访问 ,使原本无法内联的函数变为可能。
4. 多线程内存分配:Jemalloc 与 Arena 的协同
这些年 CPU 发展的新趋势是------主频、单核心性能增长相对缓慢,CPU 核心数却在不断增长4。尤其是在逐渐占领市场的 ARM 架构下,核心数量更是呈指数级倍增,从 2018 年之前的 16 核以内,一路达到了现在 192 核的高峰7。这意味着我们必须把更多的目光投向高并发(High Concurrency)场景。
这种场景中,系统的瓶颈往往不在计算,而在 malloc/free 锁竞争 (Lock Contention)以及 TLB (Translation Lookaside Buffer)的刷新开销。典型 OLAP 查询会创建大量短生命周期对象(Hash Key、聚合状态、临时字符串)。如果这些都通过 glibc malloc/free 申请:
- 每次都走系统分配器,锁竞争严重;
- 碎片多,RSS(常驻内存集,Resident Set Size)难以控制。
由于锁护送(Lock Convoy)等效应的存在,随着 CPU 核心数增加,多线程竞争甚至可能导致多核吞吐不升反降8。一旦 L1、L2 缓存被驱逐,就又是 3-5 倍的数据访问开销。在内存分配上,这种性能瓶颈尤为突出。为避免全局竞争、有锁分配是 Doris 必须解决的技术问题。
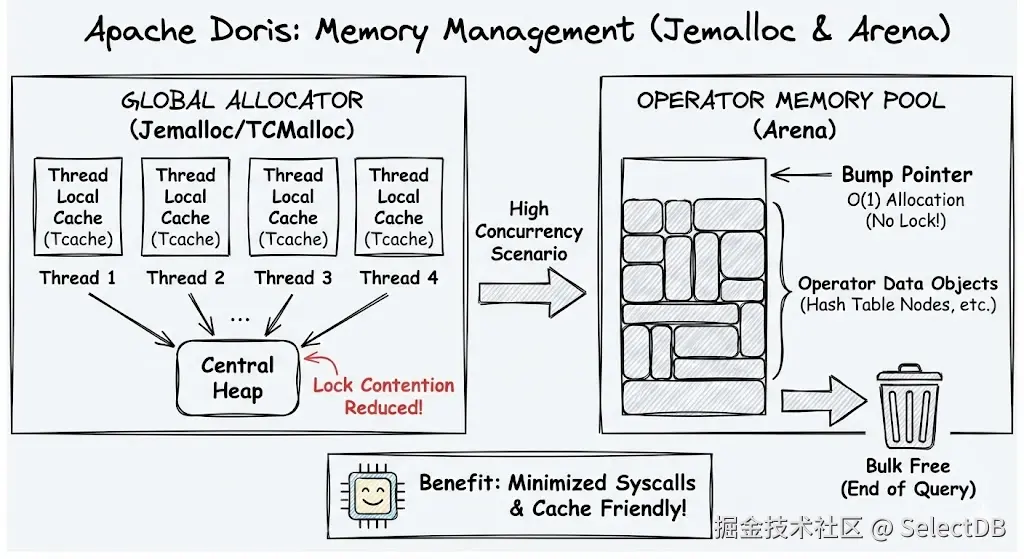
4.1 接管全局分配器
因此,Doris 后端进程(BE)选择了链接 Jemalloc 进行内存分配。其核心优势在于 Thread Local Cache (Tcache)。每个执行线程拥有独立的内存分配缓存,绝大多数小对象的申请无需加锁,消除了全局锁竞争。许多小对象申请直接通过 Jemalloc 缓存解决,不进行系统调用。
4.2 Arena 内存池
但在查询执行内部,Doris 并没有止步于此。在执行算子(如 Hash Join、Aggregation)时,Doris 使用 Arena(区域内存池)模式,这是因为很多对象的生命周期和"查询"绑定,完全可以在查询结束时统一回收。这直接带来了若干收益:
- 无锁分配:算子内部申请内存通常只是当前线程缓存内的指针简单移动(Bump Pointer),完全无锁。
- 批量释放:查询结束后,整块 Arena 统一释放,避免了数百万次小对象的析构开销。
- Cache 友好:同一算子使用的对象在内存中紧凑排列,极大提升了 CPU 缓存命中率。
C++
class Arena : private boost::noncopyable {
struct Chunk : private Allocator<false> {
......
}
public:
char* alloc(size_t size) {
_init_head_if_needed();
if (UNLIKELY(head->pos + size > head->end)) {
_add_chunk(size);
}
// 直接 bump pointer,开销无限小
char* res = head->pos;
head->pos += size;
return res;
}
// 一次性统一回收
void clear(bool delete_head = false) {
......
}
};
5. Pipeline 执行引擎:解决多核时代的调度瓶颈
传统的火山模型对于每个 Instance 使用独立的线程进行处理,每个线程需要处理一个完整 Fragment(查询计划片段)的部分数据。显然,这时的任务调度完全依赖操作系统的线程调度,而这在 OLAP 场景下存在很多根本性问题:
- 如果一个线程因为网络或磁盘 IO 阻塞,操作系统就会进行线程的上下文切换(Context Switch),开销在微秒级别。随着查询数量和规模增长,系统线程数暴涨,导致上下文切换频繁,overhead 明显增加;
- 无法细粒度实现 query 之间的公平调度。大小查询混合场景下,小查询被调度到的机会明显下降,延迟大幅增高;
- 线程频繁迁移,丧失 NUMA 和 Cache 亲和性,影响查询性能;
- 依赖底层数据分布,无法交换数据,数据倾斜对性能影响巨大
......
核心问题是,依附于线程模型的 Instance 执行,其调度完全依赖操作系统,无法进行更细粒度的调整。由阻塞、亲和性、优先级带来的影响随着现代 CPU 核数不断增加、系统负载不断增高,严重性也逐步提升。在现代 CPU 上,单次 Context Switch 往往带来上千个指令周期的时间成本,近似于上千次浮点运算 3。而这还不是最糟糕的------如果发生了跨核心迁移,更是会花费数微秒 的代价用于缓存重建和 CPU Core 之间同步。高竞争环境下,CPU 可能有数个百分点的时间都花在这些非运算代价中。9
Doris 通过全新设计的 Pipeline 引擎,在用户态实现精细化的调度控制,终于解决了以上全部问题。本质上讲,它实现了一套完整的协程(Coroutine)语义,也就是用户态调度。极其符合 OLAP 负载的实际。
5.1 阻塞等待?Pipeline Task 拆分
查询计划根据阻塞算子拆解为多个 Pipeline,每个 Pipeline 包含一组算子(Operator)。所有阻塞算子的多个上游均被拆分至不同的 Pipeline,所以 Pipeline 内部完全不发生阻塞 。每个逻辑 Pipeline 被实例化为多个物理 PipelineTask,可被多核同时调度以充分利用 CPU 资源。
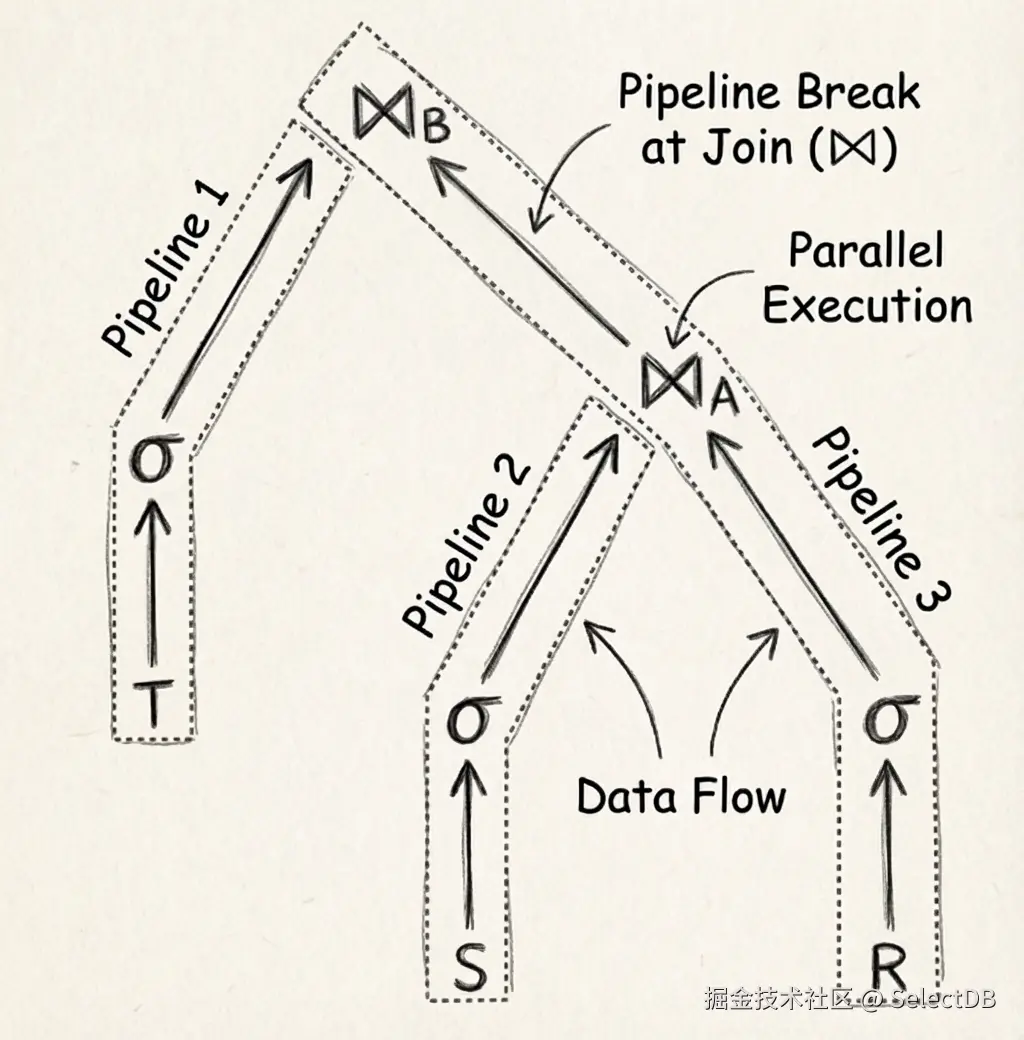
这保证了所有阻塞的操作不会占用执行线程,而是标记自身阻塞状态后,将当前线程交回给 Pipeline 调度器重新调度。因此,我们不再需要随着查询数量增多的线程了。
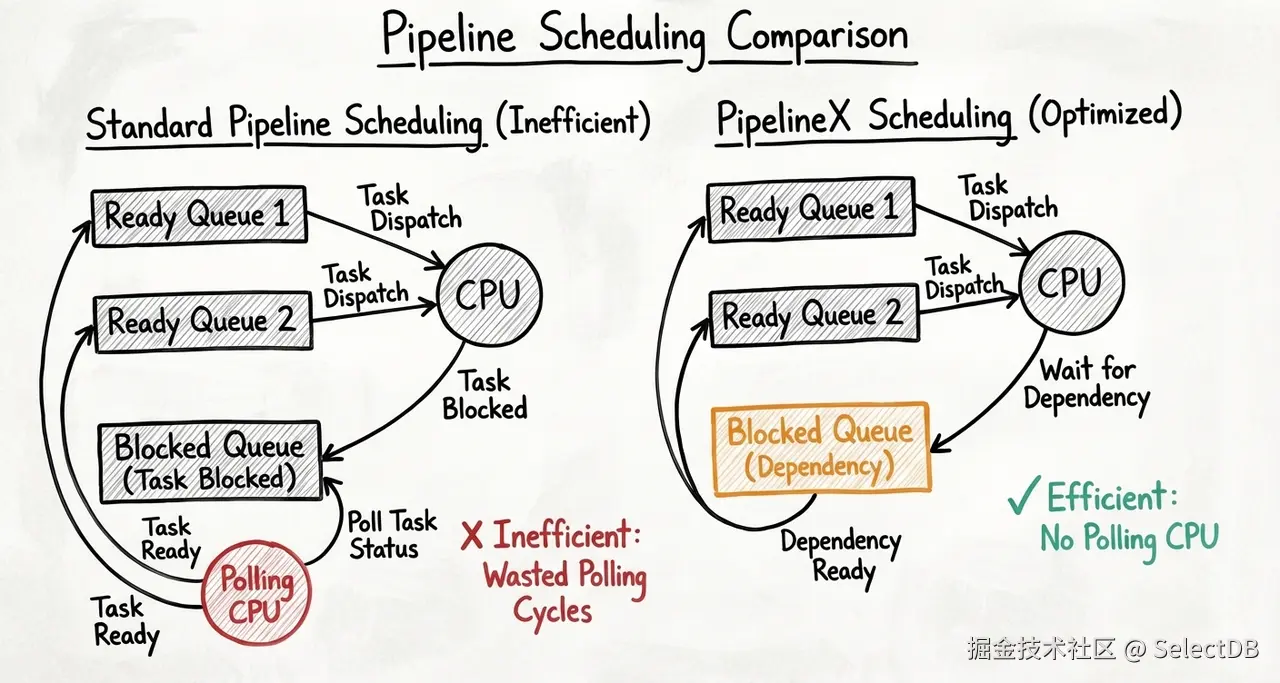
5.2 上下文切换?线程迁移?用户态调度器
Doris 实现了一个类似于 Go Runtime(协程)的用户态调度器(Task Scheduler),它包含:
- 就绪队列(Runnable Queue):一旦数据就绪,依赖被满足,Task 转移至就绪队列。可以随时被调度执行。
- 阻塞队列(Blocked Queue) :当 Task 需要等待 IO 或 RPC 数据时,它被放入阻塞队列,不占用操作系统线程。
- 执行线程池 :一组固定数量的线程不断从就绪队列取出 Task 执行。执行线程绑核以保证 Cache 命中率。
在此基础上,我们更进一步地迭代了新的 PipelineX 执行引擎,也就是 Doris 当前所使用的执行引擎。通过设置上下游 PipelineTask 之间依赖的方式进一步规避了对阻塞任务的轮询,实现了自动唤醒下游可执行任务。
5.3 数据倾斜?细粒度数据均衡
我们前面说到,近年来 CPU 发展的特点是什么?更多的核心、更多的系统线程数。这意味着我们的同一个查询,可以同时拆分成更多份进行并行。这是个好事儿......吧?
一般来说是的。更多的线程意味着单位时间更大的吞吐。但这明显受到"短板效应"的制约------如果扫描的每个存储分桶(Bucket/Tablet)数据量不一致,上层每个 PipelineTask 的执行时间也必然不一致。在不同的查询负载下,仅通过调整分桶策略几乎无法找到最优解。
在 Doris 的新 Pipeline 引擎中,解决这一问题却很简单:通过添加 Local Shuffle 算子,对 PipelineTask 之间的数据进行重新分布,"数据倾斜"问题被全自动化地消解了。

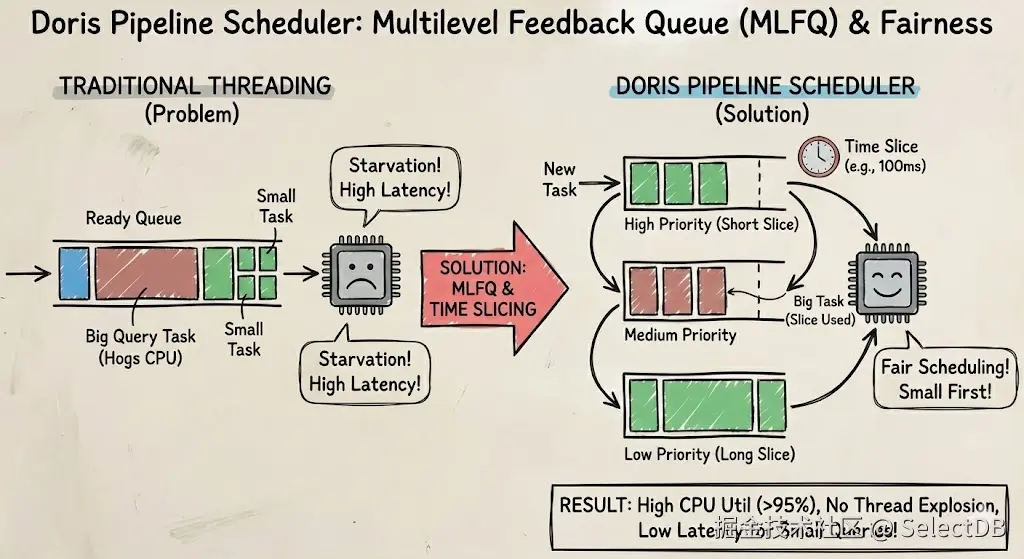
5.4 小查询饿死?分时复用与抢占
为了防止大查询饿死小查询,Pipeline 引擎引入了基于多级反馈队列 的时间片轮转机制。一个 Task 每次在 CPU 上执行的时间有限(例如 100ms),如果当前时间片运行完,必须出让 CPU 给其他任务。同时,根据执行时间的累计,大的 Task 会被逐渐降级调度,保证小查询比大查询有更高的优先级,防止延迟被影响。
这种机制使得 Doris 在高并发混合负载下,CPU 利用率能够稳定维持在 95% 以上,且完全避免了线程爆炸(Thread Explosion)导致的系统抖动。
6. 落地:可验证的性能提升结果
所以,我们罗列的这些技术,到底有用没有?是高大上的花活,还是真正能够落地到成熟系统中的关键优化呢?
来吧,让我们看一下 Apache Doris(及 VeloDB 等商业发行版)在各个优化前后的直接性能对比结果。经过长久的迭代,它们现在均已成为 Doris 坚实的架构基础。
6.1 向量化执行
首先是向量化部分。在 1.2 版本,Doris 的向量化彻底成熟。相比于过去的火山模型,这是一次里程碑式的性能跃升------根据实验,开启向量化之后的 Doris 1.2 相比早期的 Doris 0.15,在 SSB-Flat 上性能提升了近 10 倍10,在 TPC-H 上提升了超过 11 倍,最显著的单个 SQL 提速更是达到了近 70 倍11。
6.2 Pipeline 执行引擎
在 Doris 2.0 版本上,我们实现了 Pipeline 执行引擎,并在 2.1 版本进行了大的重构,使全部实现达到理想状态。在 Apache Doris 2.0 上的测试结果表明,Pipeline 引擎配合合理的 SQL 优化,达到了相比火山模型 100% 的 TPC-H 性能提升,相比于 Trino/Presto 更是有 3-5 倍的性能领先12。基于 Pipeline 引擎,Doris 更是引入了 Workload Group 进行资源划分和负载控制,有效解决了大型公司中面对大量用户复杂场景的稳定性问题。
在 Doris 2.1 中,我们的 Pipeline 引擎达到了最终形态,它具备了自适应解决数据倾斜的能力。相比于已经达到业内领先水平的 Doris 2.0,它在 TPC-DS 上进一步实现了 100% 的性能提升。在数据不均衡、分桶数极不合理的极端情况下重新测试 ClickBench 和 TPC-H,也几乎不产生性能损失13。
6.3 ARM 架构优化
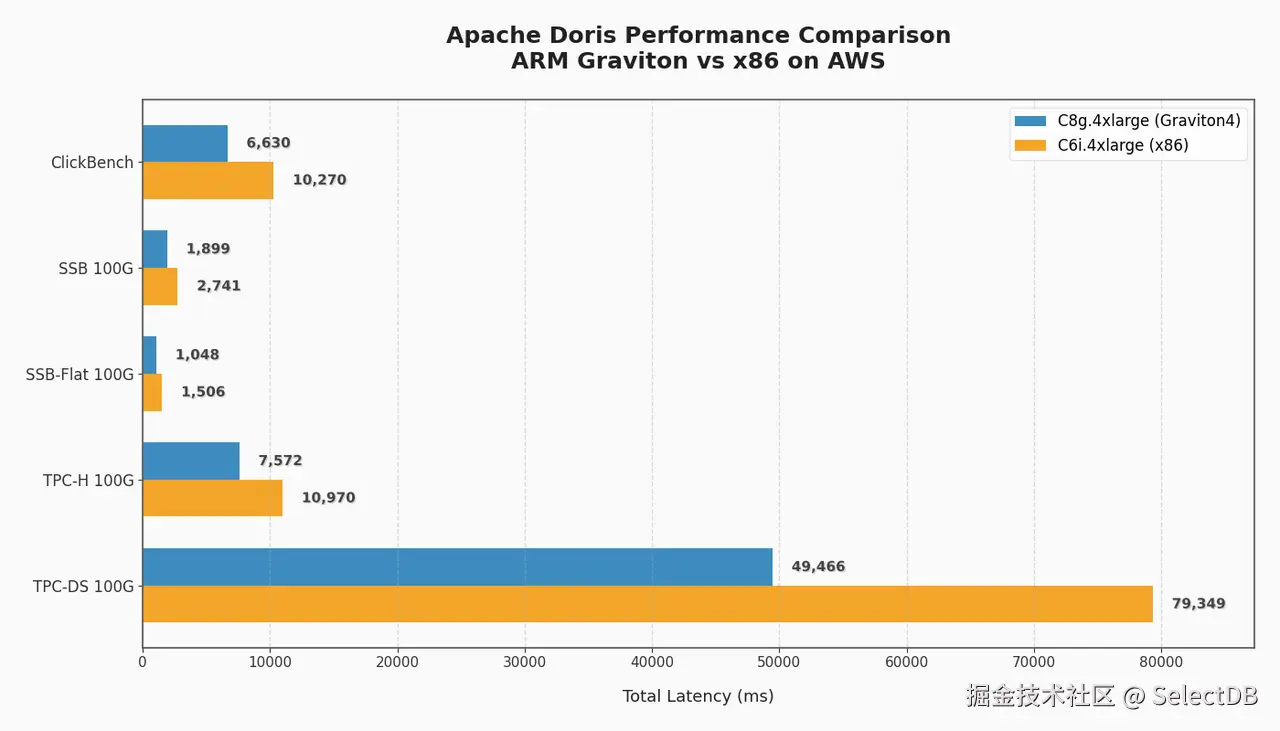
得益于 Doris 精细的向量化实现,ARM 架构下 Doris 的性能相比于其他产品,产生了比 X86 平台更大的领先优势。Doris 2.1 是第一个针对 ARM 架构深度优化的版本。相比于前一个版本,ARM 下的 Doris 2.1 在 ClickBench 上的成绩提升了 230%,TPC-H 上也达到了接近 1 倍的性能提升。14
尤其是在 AWS Graviton4 架构下,Doris 凭借卓越的优化,相比于 X86 在 ClickBench、SSB、SSB-Flat、TPC-H、TPC-DS 上分别取得了 65%、54%、53%、54%、60% 的性价比提升14。昭示着 ARM 俨然成为了数据分析领域高性价比的选择。
6.4 整体性能领先
相比于 Clickhouse、Trino 等其他 OLAP 分析引擎,Doris 的横向对比成绩究竟如何?经历了这么多优化之后,是否真正取得了领先?以下是一些事实结果:
- 相比于 Clickhouse,Doris 在其自家维护的 ClickBench 上曾多次取得领先,上一次提交的成绩位列第 2 名 ,领先于 Clickhouse 的第三名 2% 的总分。在 SSB、TPC-H 上,更是分别有 3 倍和 60 倍的性能领先 。在 TPC-DS 上,Clickhouse 在同等资源下只能执行约 50% 的查询,这部分成绩比 Doris 的总成绩还落后 1 倍 15。
- 而在实时更新场景中,二者差距更大。根据发行商 VeloDB 的测试结果,在比 Clickhouse 更差的硬件条件下,25% 更新率场景下 Doris 比 Clickhouse 快 14 倍;100% 更新率时领先更是达到了 18 倍16。
- 相比于 Trino/Presto,Doris 在 TPC-DS 1TB 测试中使用同等条件进行数据湖查询,达到了 3 倍的性能领先 ;使用 Doris 内表性能领先更是达到 10 倍之多 。在实际用户场景中,查询延时更是降低了最多 20 倍17。
- 与 Spark 对比,Doris 在其擅长的复杂查询下性能领先 4-6 倍,实时场景下更是实现了代际级别的延迟优势13。
- 对比擅长半结构化数据存储的 ElasticSearch,Doris 在半结构化测试集 JsonBench 上达到了 2 倍性能领先,同时超越了 Clickhouse。相比于 Postgresql 领先幅度更是达到 80 倍之多18。
总结
过去十年,OLAP 性能需求的演进,本质上是向底层要算力的一场硬仗。当查询变得复杂、数据量暴涨、并发攀升时,传统执行引擎在硬件层面的低效被无限放大。Apache Doris 团队面对的,正是如何驾驭现代多核 CPU 与智能编译器,将每一份硬件潜能转化为稳定的性能提升。
挑战是明确的:如何消除虚函数和分支预测带来的开销?如何让内存访问模式更适配 CPU 缓存?如何在高并发下避免锁与调度成为瓶颈?Doris 的应对策略清晰而系统:
- 针对计算效率,我们通过全面的向量化重构和模板化编程,将处理单元从"行"升级为"列",并在编译期固化类型与分支,让生成的代码近乎直接匹配 CPU 的高效流水线。
- 针对内存效率,我们引入专用的内存分配器与池化技术,大幅削减高并发下的锁竞争与碎片,确保数据在缓存中紧凑排列。
- 针对多核调度,我们自研 Pipeline 执行引擎,在用户态实现精细的任务调度与数据均衡,彻底解决操作系统线程模型在 OLAP 场景下的固有缺陷。
这些优化不是孤立的技术堆砌,而是一套贯穿数据从加载到计算全链路的系统性工程。其核心在于,团队始终保持着对硬件行为与编译器逻辑的深刻理解,并以此驱动架构演进------让代码的写法顺应硬件的"脾气",让执行路径契合编译器的"优化逻辑"。
最终,这使 Doris 能够持续地将每一代 CPU 的理论算力,稳定地转化为用户场景下的实际吞吐与低延迟。性能的极致,来自于对底层细节的持续深耕与系统化掌控。
参考文献
- www.abhik.xyz/concepts/pe...
- webs.um.es/aros/papers...
- blog.codingconfessions.com/p/context-s...
- www.servethehome.com/updated-amd...
- faculty.cs.niu.edu/~winans/not...
- pikuma.com/blog/unders...
- www.phoronix.com/review/ampe...
- grokipedia.com/page/Non-bl...
- www.systemoverflow.com/learn/os-sy...
- doris.apache.org/blog/ssb
- doris.apache.org/blog/tpch
- www.velodb.io/blog/milest...
- www.velodb.io/blog/apache...
- www.velodb.io/blog/apache...
- doris.apache.org/docs/3.x/ge...
- www.velodb.io/blog/apache...
- doris.apache.org/docs/3.x/ge...
- medium.com/@VeloDB_pow...