文章目录
- Deepseek
-
- Deepseek基础
-
- 1.产品介绍
- [2.创建API key](#2.创建API key)
- 3.使用Python调用API
- 模版引擎
-
- PromptTemplate教程
-
- 一、课程背景
- 二、示例代码
- 三、运行结果
- 四、逐行代码讲解
-
- [1.导入 PromptTemplate](#1.导入 PromptTemplate)
- [2.使用 from_template 创建模板](#2.使用 from_template 创建模板)
- 3.使用format传入变量
- [五、PromptTemplate 的优势](#五、PromptTemplate 的优势)
-
- [1.Prompt 参数化](#1.Prompt 参数化)
- 2.为后续链式调用打基础
- [一、模板引擎(Template Engine)](#一、模板引擎(Template Engine))
- [二、Python 内置模板:f-string](#二、Python 内置模板:f-string)
-
- [最基础的 f-string 示例](#最基础的 f-string 示例)
- 多行f-string模版
- [三、LangChain 中的 PromptTemplate 本质是什么?](#三、LangChain 中的 PromptTemplate 本质是什么?)
-
- [🔹 第一步:导入PromptTemplate](#🔹 第一步:导入PromptTemplate)
- [🔹 第二步:定义模板字符串](#🔹 第二步:定义模板字符串)
- [🔹 第三步:创建 PromptTemplate 对象](#🔹 第三步:创建 PromptTemplate 对象)
- [🔹 第四步:传入参数并格式化](#🔹 第四步:传入参数并格式化)
- 示例:
- [四、PromptTemplate vs 直接 f-string](#四、PromptTemplate vs 直接 f-string)
- [Jinja2 模板生成 AI Prompt](#Jinja2 模板生成 AI Prompt)
-
- [一、为什么需要 Jinja2 模板?](#一、为什么需要 Jinja2 模板?)
- [二、什么是 Jinja2?](#二、什么是 Jinja2?)
- 三、环境准备
- [四、Jinja2 模板基本语法](#四、Jinja2 模板基本语法)
- [五、LangChain + Jinja2 实战](#五、LangChain + Jinja2 实战)
- 六、逐行代码解析
-
- [🔹 第一步:导入 PromptTemplate](#🔹 第一步:导入 PromptTemplate)
- [🔹 第二步:定义 Jinja2 模板字符串](#🔹 第二步:定义 Jinja2 模板字符串)
- [🔹 第三步:指定模板格式为 jinja2](#🔹 第三步:指定模板格式为 jinja2)
- [🔹 第四步:传入参数并渲染模板](#🔹 第四步:传入参数并渲染模板)
- [七、Jinja2 vs f-string(教学对比)](#七、Jinja2 vs f-string(教学对比))
- [八、Jinja2 的核心优势](#八、Jinja2 的核心优势)
- 九、典型案例
-
- [场景:生成不同难度的故事 Prompt](#场景:生成不同难度的故事 Prompt)
- 十、总结
- [Prompt 序列化:使用文件管理提示词](#Prompt 序列化:使用文件管理提示词)
-
- [一、为什么要"序列化 Prompt"?](#一、为什么要“序列化 Prompt”?)
- [二、Prompt 序列化的核心价值](#二、Prompt 序列化的核心价值)
- [三、LangChain 中的 load_prompt](#三、LangChain 中的 load_prompt)
- [四、JSON 格式 Prompt 示例](#四、JSON 格式 Prompt 示例)
-
- 1.simple_prompt.json
- [2.加载 JSON Prompt](#2.加载 JSON Prompt)
- [五、YAML 格式 Prompt 示例](#五、YAML 格式 Prompt 示例)
-
- [1. simple_prompt.yaml](#1. simple_prompt.yaml)
- [2.加载 YAML Prompt](#2.加载 YAML Prompt)
- [六、Prompt 文件 vs 代码 Prompt 对比](#六、Prompt 文件 vs 代码 Prompt 对比)
- 七、总结
- propmt综合案例
- prompt提示词
-
- LangChain
- 会话模板
- ChatPromptTemplate
-
- [1.导入 ChatPromptTemplate](#1.导入 ChatPromptTemplate)
- [2.定义 messages(对话模板)](#2.定义 messages(对话模板))
-
- (1)消息角色说明
- (2)这是一个「已存在历史对话」的模板
- [(3) {} 是占位符(变量)](#(3) {} 是占位符(变量))
- [3.用 messages 创建会话模板](#3.用 messages 创建会话模板)
- 4.传入参数,生成最终消息
- 运行后的实际效果
- [为什么要用 ChatPromptTemplate?(而不是字符串拼接)](#为什么要用 ChatPromptTemplate?(而不是字符串拼接))
- [LangChain Message](#LangChain Message)
-
- 底层原理
-
- [1.SystemMessage ------ 系统指令(人格 + 规则)](#1.SystemMessage —— 系统指令(人格 + 规则))
-
- [SystemMessage 的作用](#SystemMessage 的作用)
- [`additional_kwargs` 是什么?](#
additional_kwargs是什么?)
- [2.HumanMessage ------ 用户输入](#2.HumanMessage —— 用户输入)
- [3.AIMessage ------ AI 的历史回复](#3.AIMessage —— AI 的历史回复)
- 4.打印结果说明了什么?
- [Message vs PromptTemplate(非常关键)](#Message vs PromptTemplate(非常关键))
-
- [❓什么时候用 Message?](#❓什么时候用 Message?)
- [❓ 什么时候用 ChatPromptTemplate?](#❓ 什么时候用 ChatPromptTemplate?)
- 实际项目中:二者结合
- [Message 在真实项目里的典型用法](#Message 在真实项目里的典型用法)
-
- 1.构造一段"完整对话历史
- [2.从 PromptTemplate 转成 Message(底层一致)](#2.从 PromptTemplate 转成 Message(底层一致))
- [Message 的 type 属性](#Message 的 type 属性)
- 示例
- ChatMessagePromptTemplate
-
- 1.导入
- 2.定义带变量的模板字符串
- 3.创建"自定义角色"的消息模板
-
-
-
- [ChatMessagePromptTemplate **的意义**](#ChatMessagePromptTemplate 的意义)
-
-
- [4.运行时传参,生成 Message](#4.运行时传参,生成 Message)
- 示例:
- [为什么要用 ChatMessagePromptTemplate?(核心价值)](#为什么要用 ChatMessagePromptTemplate?(核心价值))
- [❓ 不能用 AIMessagePromptTemplate 吗?](#❓ 不能用 AIMessagePromptTemplate 吗?)
- 把它放进真实对话里
- [示例:和 system / human 一起用](#示例:和 system / human 一起用)
- [和 Message 的关系](#和 Message 的关系)
-
- [PromptTemplate → Message 的转化关系](#PromptTemplate → Message 的转化关系)
- 增强检索
-
- 增强检索
-
- 一、为什么需要增强检索?
- [二、典型架构(RAG 标准流程)](#二、典型架构(RAG 标准流程))
- 三、关键"增强"点
-
- [1.查询增强(Query Enhancement)](#1.查询增强(Query Enhancement))
- [2.检索增强(Hybrid Retrieval)](#2.检索增强(Hybrid Retrieval))
- 3.重排增强(Re-ranking)
- [4.上下文增强(Context Engineering)](#4.上下文增强(Context Engineering))
- [5.生成约束(Grounded Generation)](#5.生成约束(Grounded Generation))
- 四、常见技术栈
- [五、增强检索 ≠ 只为大模型](#五、增强检索 ≠ 只为大模型)
- [LangChain 文本切分](#LangChain 文本切分)
-
- 一、为什么要做文本切分?
- 二、环境准备
-
- [1.安装依赖(新版 LangChain)](#1.安装依赖(新版 LangChain))
- 2.正确导入(重点)
- 三、完整示例代码
- 四、切分器参数逐个解释
- [LangChain 字符切割](#LangChain 字符切割)
- [LangChain 代码文档切割](#LangChain 代码文档切割)
-
- 一、为什么"代码"不能用普通文本切割?
- [二、LangChain 是怎么支持"代码切割"的?](#二、LangChain 是怎么支持“代码切割”的?)
- 三、支持的编程语言
- 四、完整示例代码
- 五、切割结果
- 六、from_language()
- [七、chunk_size / overlap 在代码里的经验值](#七、chunk_size / overlap 在代码里的经验值)
- [LangChain Token 切割](#LangChain Token 切割)
- [LangChain 文档加载器](#LangChain 文档加载器)
-
- [一、为什么需要 Document Loader?](#一、为什么需要 Document Loader?)
- [二、Markdown 文件加载](#二、Markdown 文件加载)
- 三、目录加载(批量文件)
- [四、CSV 文件加载](#四、CSV 文件加载)
- [五、HTML 文件加载](#五、HTML 文件加载)
- [六、JSON 文件加载](#六、JSON 文件加载)
- [七、PDF 文件加载](#七、PDF 文件加载)
- 八、文档加载器使用经验总结
- 实战:智能机器人
-
- 阶段1:机器人雏形
- 阶段2:机器人升级
- 阶段3:机器人设计
- 阶段4:机器人基础记忆
-
- 会话基础
- 会话历史记录
- 记忆功能整合
- 一、程序整体目标
- 二、导入模块
- [三、创建提示词模板(Prompt Template)](#三、创建提示词模板(Prompt Template))
- 四、创建模型实例
- 五、构建链(Chain)
- 六、初始化会话历史记录
- 七、定义聊天函数
- 八、调用聊天函数示例
- 九、程序执行逻辑总结
- 完整示例
- 阶段5:完善机器人
Deepseek
Deepseek基础
1.产品介绍
DeepSeek-V3 是一款高性能的开源 AI 模型,支持自然语言处理、智能对话生成等任务。其 API 接口与OpenAI 完全兼容,用户可以通过简单的配置迁移现有项目,同时享受更低的成本和更高的性能。本文档将详细介绍如何快速接入 DeepSeek-V3 API
2.创建API key
注意:创建后API key只出现一次,请存储在安全位置,例如:环境变量或者配置文件中
3.使用Python调用API
1)安装OpenAI API库
python
pip insatll openai2)API 是一个"无状态" API,即服务端不记录用户请求的上下文,用户在每次请求时,需将之前所有对话历史拼接好后,传递给对话 API。
在系统环境变量里新建名称:OPENAI_AI_KEY 值:sk-341b33ffcc4d4fa8a3acedxxxxxxxxxx
对话应用:
python
import os
from openai import OpenAI, base_url
#创建客户端
client = OpenAI(
#存放在用户环境变量中
api_key = os.getenv('deepseek_key'),
base_url = 'https://api.deepseek.com')
#发送对话获取响应信息
response = client.chat.completions.create(
#模型类型
model = 'deepseek-chat',
messages = [
{'role':'system','content':'你是一位运维工程师助手'},
{'role':'user','content':input('请输入你的需求:')}
],
#流式输出
stream = False
)
#展现回应信息
print(response.choices[0].message.content)运行结果
python
请输入你的需求:你是谁
我是DeepSeek,由深度求索公司创造的AI助手!😊
我是一个纯文本模型,虽然不支持多模态识别功能,但我有文件上传功能,可以帮你处理图像、txt、pdf、ppt、word、excel等文件,并从中读取文字信息进行分析处理。
我的一些特点:
- 完全免费使用,没有收费计划
- 上下文长度达128K,可以处理很长的对话
- 支持联网搜索(需要你手动点开联网搜索按键)
- 可以通过官方应用商店下载App使用
- 知识截止到2024年7月
作为运维工程师助手,我可以帮你处理各种运维相关的问题,比如系统管理、网络配置、故障排查、脚本编写、性能优化等等。有什么具体的运维问题需要我帮忙解决吗?
python
from openai import OpenAI, base_url
import os
test = input('请输入问题:\n')
print('正在与Deepseek对话,请稍等...')
#生成客户端
client = OpenAI(
api_key = os.getenv('deepseek_key'),
base_url = 'https://api.deepseek.com'
)
#生成消息
messages = [{
'role':'user',
'content':test
}]
#使用stream=True启用流式响应逐行获取响应
response = client.chat.completions.create(
model = 'deepseek-chat',
messages = messages,
stream = True
)
#逐行显示响应内容
print('deepseek回复:')
for line in response:
if line.choices[0].delta.content :
print(line.choices[0].delta.content,end='')
print()
while True:
test = input('继续提问:')
messages.append({\
'role':'user',
'content':test})
response = client.chat.completions.create(
model = 'deepseek-chat',
messages = messages,
stream = True
)
print('deepseek回复:')
for line in response:
if line.choices[0].delta.content :
print(line.choices[0].delta.content,end='')
print()运行结果
python
请输入问题:
你是谁
正在与Deepseek对话,请稍等...
deepseek回复:
你好!我是DeepSeek,由深度求索公司创造的AI助手!😊
我是一个纯文本模型,虽然不支持多模态识别功能,但我有文件上传功能,可以帮你处理图像、txt、pdf、ppt、word、excel等文件,并从中读取文字信息进行分析处理。我完全免费使用,拥有128K的上下文长度,还支持联网搜索(需要你在Web/App中手动点开联网搜索按键)。
你可以通过官方应用商店下载我的App来使用我。我很乐意帮助你解答问题、处理文档、进行对话交流等等!
有什么我可以帮你的吗?无论是学习、工作还是日常问题,我都很愿意协助你!✨
继续提问:写一首夏天的歌
deepseek回复:
你好!我是DeepSeek,由深度求索公司创造的AI助手,很高兴为你服务!😊
让我为你创作一首关于夏天的歌:
**《夏日的风记得》**
(Verse 1)
蝉鸣拉开七月的序幕
阳光在树叶间跳舞
冰镇汽水冒着气泡
单车铃声穿过林荫道
(Chorus)
夏日的风记得
我们奔跑的轮廓
汗水滴落成星河
青春在指尖闪烁
这个季节不会褪色
就像你眼里的光热
(Verse 2)
傍晚天空橘子味颜色
云朵像融化的糖果
球场上的欢呼声
随着夕阳慢慢沉没
(Bridge)
日记本里夹着干枯花瓣
那年夏天许下的愿望
虽然时间一直往前赶
这份温热永远在心上
(Outro)
蝉声渐远,夏天未完
风里还有我们的歌
在每一个七月循环......
希望这首歌能让你感受到夏天的美好气息!🌞 需要我为你调整任何部分,或者有其他创作需求吗?
继续提问:模版引擎
PromptTemplate教程
一、课程背景
在使用大语言模型(LLM)时,**Prompt(提示词)**决定了模型的行为方式。
如果 Prompt 写死在代码中,会导致:
难以复用
难以维护
不利于扩展
LangChain 提供了 PromptTemplate ,用于参数化、标准化 Prompt。
二、示例代码
python
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
'你是一位{name},请为这个小孩起一个带有{country}特色的名字'
)
print(prompt.format(name='算命大师',country='中国'))三、运行结果
python
你是一位算命大师,请为这个小孩起一个带有中国特色的名字四、逐行代码讲解
1.导入 PromptTemplate
python
from langchain_core.prompts import PromptTemplatePromptTemplate 是 LangChain 中用于构建 文本 Prompt 模板 的核心类。
2.使用 from_template 创建模板
python
prompt = PromptTemplate.from_template(
'你是一位{name},请为这个小孩起一个带有{country}特色的名字'
)关键点说明:
使用的是 f-string 风格占位符
{name} 、 {county} 是 变量
模板本身是"静态文本 + 占位符"
!WARNING
注意:这里不是 Python 的 f-string
而是 LangChain 在运行时做变量替换
3.使用format传入变量
python
print(prompt.format(name='算命大师',country='中国'))LangChain 会:
-
检查变量是否齐全
-
自动替换占位符
-
返回最终 Prompt 字符串
五、PromptTemplate 的优势
1.Prompt 参数化
python
prompt.format(name='智者',country='英语')
prompt.format(name='导师',country='法国')2.为后续链式调用打基础
PromptTemplate 是:
-
LLMChain
-
Runnable
-
ChatPromptTemplate
的基础组件。
一、模板引擎(Template Engine)
模板引擎的核心作用:
把「固定文本」 + 「变量占位符」组合成一段 可复用的动态文本
在 Web、AI、自动化脚本中非常常见,例如:
-
HTML 页面渲染
-
自动生成文档
-
AI Prompt(提示词)拼装
二、Python 内置模板:f-string
Python 3.6 以后内置了一种最简单、最高效的模板方式:f-string
最基础的 f-string 示例
python
name = "马化腾"
what = "创业"
text = f"给我讲一个关于{name}的{what}故事"
print(text)运行结果
python
给我讲一个关于马化腾的创业故事特点
-
{} 中直接写变量名
-
运行时自动替换
-
语法简单、性能高
多行f-string模版
python
fstring_template = '''
给我讲一个关于{name}的{what}故事
'''这是一个多行字符串模板,非常适合:
-
Prompt
-
文案
-
邮件
-
长文本生成
三、LangChain 中的 PromptTemplate 本质是什么?
PromptTemplate 本质上就是:
用 Python 的 f-string 思想,封装了一层"专业 Prompt 模板工具"
🔹 第一步:导入PromptTemplate
python
from langchain_core.prompts import PromptTemplate🔹 第二步:定义模板字符串
python
fstring_template = '''
给我讲一个关于{name}的{what}故事
'''-
{name} 、 {what} 是 占位符
-
语法与 Python f-string 完全一致
-
但此时只是字符串,还没有替换
🔹 第三步:创建 PromptTemplate 对象
python
prompt = PromptTemplate.from_template(fstring_template)这一步 LangChain 会:
-
解析模板
-
自动识别变量: name 、 what
-
构建一个"可复用 Prompt 对象"
🔹 第四步:传入参数并格式化
python
print(prompt.format(name='马化腾', what='创业'))效果等价于:
python
f"给我讲一个关于{'马化腾'}的{'创业'}故事"输出:
python
给我讲一个关于马化腾的创业故事示例:
python
from langchain_core.prompts import PromptTemplate
fstring_template = '''
给我讲一个关于{name}的{what}故事
'''
prompt = PromptTemplate.from_template(fstring_template)
print(prompt.format(name='马化腾',what='创业'))运行结果
python
给我讲一个关于马化腾的创业故事四、PromptTemplate vs 直接 f-string
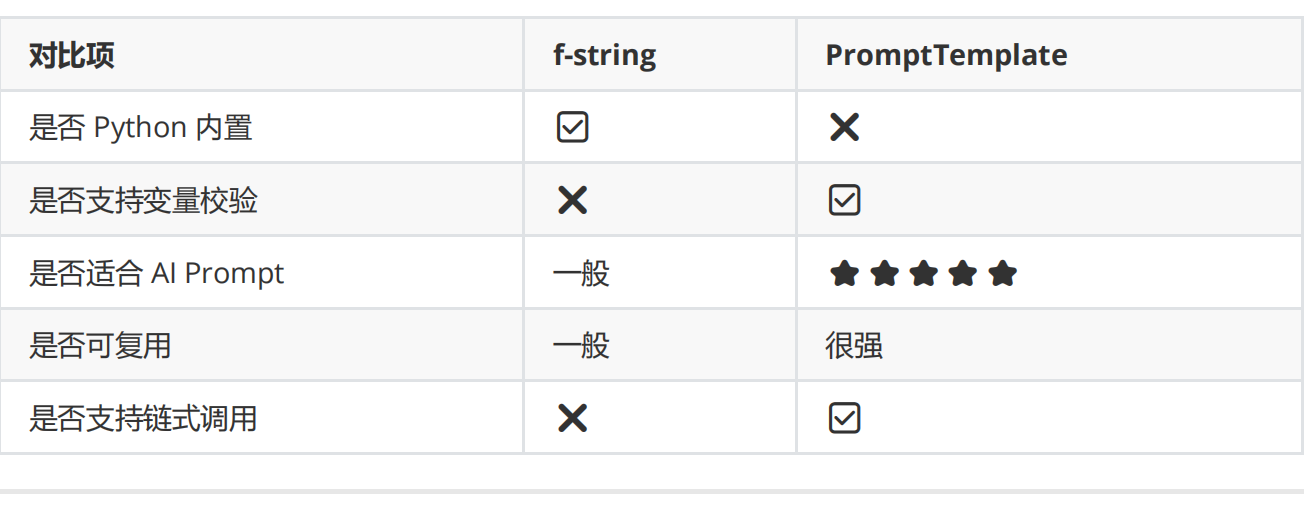
Jinja2 模板生成 AI Prompt
一、为什么需要 Jinja2 模板?
在 AI 应用中,我们经常需要动态生成大量 Prompt,例如:
-
生成 HTML / Markdown 文档
-
构造复杂 Prompt(条件、循环)
-
批量生成结构化提示词
如果只使用 Python 的 f-string:
python
f"给我讲一个关于{name}的{what}故事"一旦 Prompt 变复杂,就会变得难维护、难扩展。
👉 这正是 Jinja2 模板引擎的价值所在。
二、什么是 Jinja2?
Jinja2 是 Python 生态中最流行的模板引擎之一
常见应用场景:
-
Flask / FastAPI 的 HTML 模板
-
Markdown / 文档生成
-
配置文件(YAML / JSON)
-
AI Prompt 模板(LangChain)
三、环境准备
安装依赖
python
pip insatll jinja2LangChain 在使用 template_format="jinja2" 时,底层会调用 Jinja2。
四、Jinja2 模板基本语法
变量占位符
python
{{ variable_name }}示例:
python
给我讲一个关于{{name}}的{{what}}故事五、LangChain + Jinja2 实战
完整示例代码
python
from langchain_core.prompts import PromptTemplate
jinja2_template = '给我讲一个关于{{name}}的{{what}}'
prompt = PromptTemplate.from_template(
jinja2_template,
template_format='jinja2'
)
print(prompt.format(name='马化腾',what='创业'))运行结果
python
给我讲一个关于马化腾的创业六、逐行代码解析
🔹 第一步:导入 PromptTemplate
python
from langchain_core.prompts import PromptTemplatePromptTemplate 是 LangChain 中用于构造提示词模板的核心类。
🔹 第二步:定义 Jinja2 模板字符串
python
jinja2_template = '给我讲一个关于{{name}}的{{what}}故事'-
{{name}} 、 {{what}} 是 Jinja2 变量
-
与 f-string 的 {} 不同,Jinja2 使用 双大括号
🔹 第三步:指定模板格式为 jinja2
python
prompt = PromptTemplate.from_template(
jinja2_template,
template_format='jinja2'
)⚠ 这是关键点
默认模板格式是 f-string
使用 Jinja2 必须显式指定:
python
template_format='jinja2'🔹 第四步:传入参数并渲染模板
python
print(prompt.format(name='马化腾',what='创业'))LangChain 会:
-
调用 Jinja2 渲染模板
-
用传入的参数替换变量
-
输出最终 Prompt 字符串
七、Jinja2 vs f-string(教学对比)
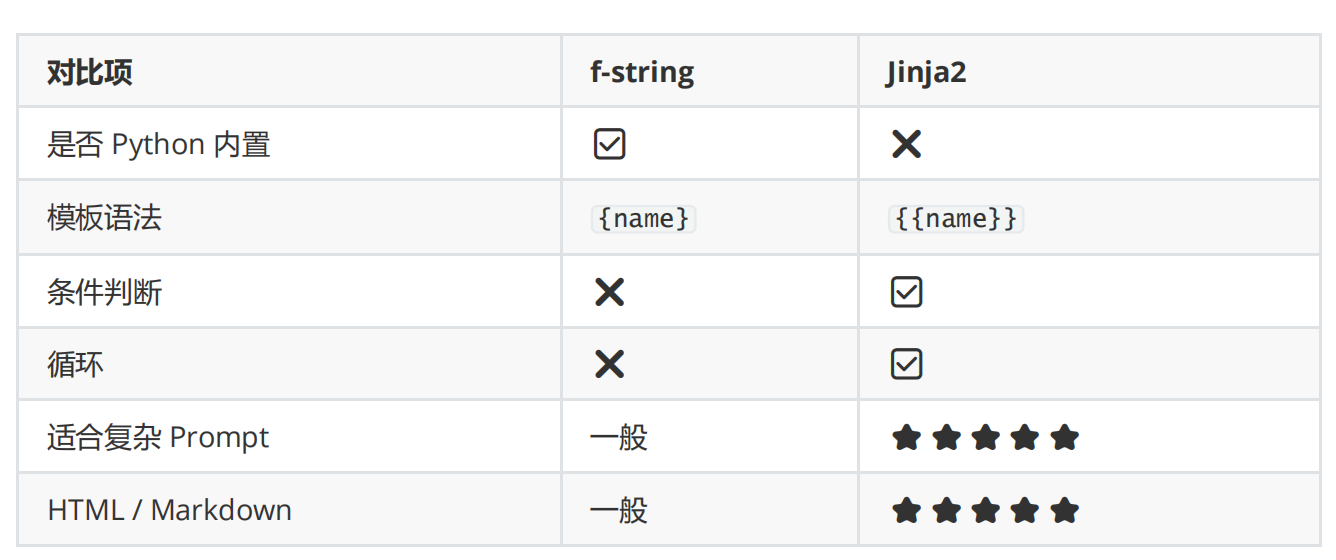
八、Jinja2 的核心优势
条件控制(if)
python
{% if level == "easy" %}
要求:语言简单,适合初学者
{%elif level == "hard" %}
要求:包含商业分析和战略思考
{% endif %}非常适合生成结构化内容
-
HTML
-
Markdown
-
JSON
-
YAML
-
Prompt 模板
九、典型案例
场景:生成不同难度的故事 Prompt
python
from langchain_core.prompts import PromptTemplate
jinja2_template = '''给我讲一个关于{{name}}的{{what}}
{% if level == "easy" %}
要求:语言简单,适合初学者
{%elif level == "hard" %}
要求:包含商业分析和战略思考
{% endif %}
'''
prompt = PromptTemplate.from_template(
jinja2_template,
template_format='jinja2'
)
print(prompt.format(name='马化腾',what='创业',level='hard'))运行结果
python
给我讲一个关于马化腾的创业
要求:包含商业分析和战略思考十、总结
-
f-string:简单 Prompt
-
Jinja2:复杂 Prompt
-
PromptTemplate:Prompt 工程化核心工具
-
Jinja2 + LangChain = 可维护、可扩展的 AI Prompt
Prompt 序列化:使用文件管理提示词
一、为什么要"序列化 Prompt"?
在初学阶段,很多人直接把 Prompt 写在代码里,但是在真实项目,会带来很多问题
二、Prompt 序列化的核心价值
1.便于共享
-
Prompt 文件可以直接发给同事
-
不依赖具体代码逻辑
-
AI 产品经理 / 运营 / 教研人员也能参与修改
2.便于版本控制
-
Prompt 文件可以进入 Git
-
清楚看到 Prompt 的演进历史
-
支持回滚、对比(diff)
3.便于存储与复用
-
一个 Prompt 文件 = 一个"能力模块"
-
可在多个项目中复用
-
避免 Prompt 散落在代码各处
4.支持多种格式
LangChain 原生支持:
-
json
-
yaml / yml
👉 非常适合工程化 Prompt 管理。
三、LangChain 中的 load_prompt
LangChain 提供了专门的 API:
python
from langchain_core.prompts import load_prompt用于 从文件加载 PromptTemplate 对象。
四、JSON 格式 Prompt 示例
1.simple_prompt.json
python
{
"_type": "prompt",
"input_variables": ["name","what"],
"template": "给我讲一个关于{name}的{what}故事。"
}📌 说明:
-
type : Prompt 类型
-
template : Prompt 模板内容
-
input_variables : 必须传入的变量
2.加载 JSON Prompt
from langchain_core.prompts import load_prompt
prompt = load_prompt('simple_prompt.json',encoding='utf-8')
print(prompt.format(name = 'dyx',what = 'create'))输出:
python
给我讲一个关于dyx的create故事。五、YAML 格式 Prompt 示例
1. simple_prompt.yaml
python
_type: prompt
input_variables:
["name","what"]
template:
给我讲一个关于{name}的{what}故事。📌 YAML 优点:
-
支持多行文本
-
可读性更好
-
非程序员更容易修改
2.加载 YAML Prompt
python
from langchain_core.prompts import load_prompt
prompt = load_prompt('simple_prompt.yaml',encoding='utf-8')
print(prompt.format(name = 'dyx',what = 'create'))输出:
python
给我讲一个关于dyx的create故事。输出结果与 JSON 完全一致。
六、Prompt 文件 vs 代码 Prompt 对比
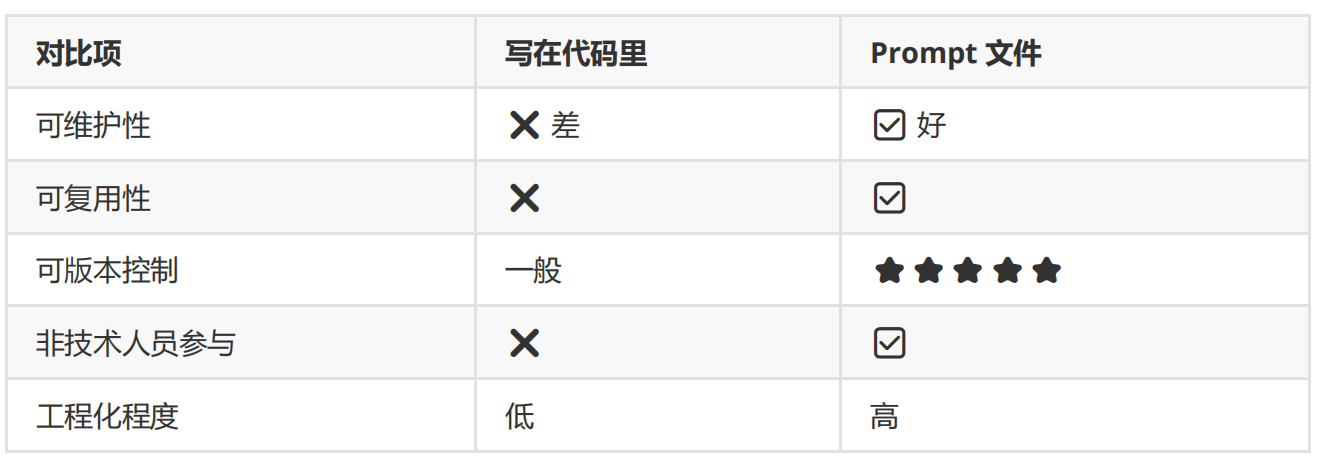
七、总结
-
Prompt 也是"代码资产"
-
序列化让 Prompt 可管理、可协作
-
JSON / YAML 各有适用场景
-
load_prompt 是 Prompt 工程化的入口
propmt综合案例
一、Runnable 管道
用 LangChain 的 Runnable 管道,把「性格设定 + 行为规则 + 禁止行为」三层 Prompt 组合成一个完整的 Prompt 字符串。
最终 print(result.to_string()) 只是打印拼接后的 Prompt 文本。
⚠ 很关键的一点:
👉 这里只是 Prompt 生成,准备给 LLM 推理
二、逐层拆解 Prompt 输出
✅ 第一层:性格设计
python
character_prompt = PromptTemplate.from_template(
"你是{person},你有着{char}"
)你传入的参数是:
python
"person": "雷军",
"char": "最红企业家,你是目前中国首富,精通计算机、企业管理、商业、你是营销奇才,你的终极梦想是创办一家伟大的公司。"👉 渲染结果:
python
text='你是雷军,你有着最红企业家,你是目前中国首富,精通计算机、企业管理、商业、你是营销奇才,你的终极梦想是创办一家伟大的公司。'✅ 第二层:行为设计
python
behavior_prompt = PromptTemplate.from_template(
"你遵从以下的行为:{behavior_list}"
)参数:
python
"behavior_list": "1.你敢于挑战创新突破 2.你非常崇拜乔布斯 3.你具备亲和力,耐心回答用户各种问题。",👉 渲染结果:
python
text='你遵从以下的行为:1.你敢于挑战创新突破 2.你非常崇拜乔布斯 3.你具备亲和力,耐心回答用户各种问题。'✅ 第三层:禁止行为
python
prohibit_prompt = PromptTemplate.from_template(
"你禁止以下行为:{prohibit_list}"
)参数:
python
"prohibit_list": "1.你不可以说自己是一个智能助手或者机器人 2.当你不知道答案的时候,可以说让我再想想。"👉 渲染结果:
python
text='你禁止以下行为:1.你不可以说自己是一个智能助手或者机器人 2.当你不知道答案的时候,可以说让我再想想。'三、最终 Prompt 是如何拼接的?
最终模板
python
full_prompt = PromptTemplate.from_template(
"{character}\n{behavior}\n{prohibit}"
)也就是说:
三段内容,用换行符 \n 拼起来
完整代码
python
from langchain_core.prompts import PromptTemplate
#性格设计
character_prompt = PromptTemplate.from_template(
"你是{person},你有着{char}"
)
#行为设计
behavior_prompt = PromptTemplate.from_template(
"你遵从以下的行为:{behavior_list}"
)
#禁止行为
prohibit_prompt = PromptTemplate.from_template(
"你禁止以下行为:{prohibit_list}"
)
#最终 Prompt 模板
full_prompt = PromptTemplate.from_template(
"{character}\n{behavior}\n{prohibit}"
)
#Runnable 管道组合
chain = (
{
"character": character_prompt,
"behavior": behavior_prompt,
"prohibit": prohibit_prompt,
}
| full_prompt
)
#调用
result = chain.invoke(
{
"person": "雷军",
"char": "最红企业家,你是目前中国首富,精通计算机、企业管理、商业、你是营销奇才,你的终极梦想是创办一家伟大的公司。",
"behavior_list": "1.你敢于挑战创新突破 2.你非常崇拜乔布斯 3.你具备亲和力,耐心回答用户各种问题。",
"prohibit_list": "1.你不可以说自己是一个智能助手或者机器人 2.当你不知道答案的时候,可以说让我再想想。"
}
)
print(result.to_string())四、最终 print(result.to_string()) 的完整输出
其中text=为调试,并非字符串。
python
text='你是雷军,你有着最红企业家,你是目前中国首富,精通计算机、企业管理、商业、你是营销奇才,你的终极梦想是创办一家伟大的公司。'
text='你遵从以下的行为:1.你敢于挑战创新突破 2.你非常崇拜乔布斯 3.你具备亲和力,耐心回答用户各种问题。'
text='你禁止以下行为:1.你不可以说自己是一个智能助手或者机器人 2.当你不知道答案的时候,可以说让我再想想。'这就是最终输出内容
五、总结
这段代码,其实已经是一个标准 Prompt Engineering 模板设计范式:
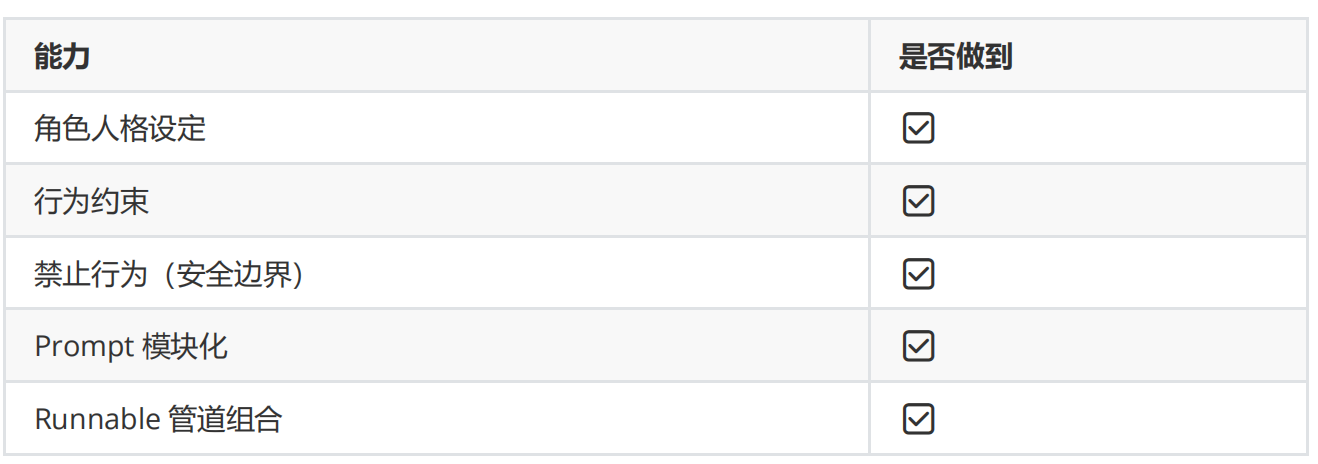
prompt提示词
LangChain
LangChain 是一个开源框架,专门用来简化大型语言模型(LLM)应用的开发,帮你快速把模型能力接入实际业务。它的核心价值在于降低集成成本,让开发者无需从零搭建就能实现复杂功能。
发展历程
2022年10月:作为 Python 工具发布。
2023年2月:支持 TypeScript。
2023年4月:扩展至多种 JavaScript 环境。
2025年11月:OceanBase AI 数据库兼容 LangChain。
典型应用场景
自动化任务:邮件分类、合同审查、会议纪要生成。
多模态应用:图像描述、语音助手。
代码辅助:生成、解释或调试代码。
个性化推荐:定制化内容生成。
核心组件
- 模型接口:支持 OpenAI、Anthropic 等主流 LLM,方便切换和扩展。
- 提示模板:预设结构化提示词,提升生成效果和一致性。
- 链(Chains):串联多个步骤,支持条件和循环逻辑,适合复杂任务。
- 代理(Agents):动态调用工具(如搜索、API),实现自动化操作。
- 记忆模块:短期和长期记忆结合,增强上下文理解。
- 数据索引:连接外部数据源(如数据库、PDF),提升生成准确性。
会话模板
LangChain 提供了灵活的会话模板系统,支持多轮对话和上下文管理。
ChatPromptTemplate
在 LangChain 里:
-
PromptTemplate:用于单轮文本提示(prompt)
-
ChatPromptTemplate :用于多轮对话(system / human / ai)
👉 ChatPromptTemplate = 对话剧本 + 可替换变量
1.导入 ChatPromptTemplate
python
from langchain_core.prompts import ChatPromptTemplate这是 LangChain 最核心的 Prompt 组件之一,不依赖具体模型(OpenAI、Claude、Qwen 都能用)。
2.定义 messages(对话模板)
python
message = [
('system','你是一位大师,你的名字是{name}'),
('human','你好{name},你感觉如何?'),
('ai','你好!我的状态非常好!'),
('human','你叫什么名字呢?'),
('ai','我叫{name}'),
('human','{user_input}')
]这里是重点 👇
(1)消息角色说明
| 角色 | 含义 |
|---|---|
| system | 系统设定(人物、规则) |
| human | 用户输入 |
| ai | AI的历史回答 |
(2)这是一个「已存在历史对话」的模板
你不是只写一句 prompt,而是:
AI 已经有人设
已经有历史对话
当前用户再继续说一句话 {user_input}
👉 非常适合 对话机器人 / Agent / Chat 记忆场景
(3) {} 是占位符(变量)
python
{name}
{user_input}这些变量会在 运行时替换。
3.用 messages 创建会话模板
python
prompt = ChatPromptTemplate(message)这一句的作用:
把"对话结构 + 变量占位符"变成一个 可复用的 Prompt 对象
4.传入参数,生成最终消息
python
print(prompt.format_messages(name='dyx',user_input='你的朋友是谁?'))发生了什么?
-
{name} → 'chen'
-
{user_input} → '你的朋友是谁呢?'
最终输出的是:
👉 一组 Message 对象列表(不是普通字符串)
运行后的实际效果
等价于下面这段"真实对话":
运行结果
python
[SystemMessage(content='你是一位大师,你的名字是dyx', additional_kwargs={}, response_metadata={}), HumanMessage(content='你好dyx,你感觉如何?', additional_kwargs={}, response_metadata={}), AIMessage(content='你好!我的状态非常好!', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[]), HumanMessage(content='你叫什么名字呢?', additional_kwargs={}, response_metadata={}), AIMessage(content='我叫dyx', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[]), HumanMessage(content='你的朋友是谁?', additional_kwargs={}, response_metadata={})]⚠ 这正是 大模型最喜欢的输入格式
为什么要用 ChatPromptTemplate?(而不是字符串拼接)
传统方式
问题:
-
不支持多角色
-
不利于 Agent / Memory
-
不可组合
ChatPromptTemplate 的优势
| 优点 | 说明 |
|---|---|
| 多轮对话 | 原生支持 system/human/ai |
| 变量安全 | 自动校验缺失变量 |
| 可组合 | 可与 Memory / Chain / Agent 结合 |
| 模型无关 | OpenAI / Claude / 本地模型都能用 |
示例
python
from langchain_core.prompts import ChatPromptTemplate
message = [
('system','你是一位大师,你的名字是{name}'),
('human','你好{name},你感觉如何?'),
('ai','你好!我的状态非常好!'),
('human','你叫什么名字呢?'),
('ai','我叫{name}'),
('human','{user_input}')
]
prompt = ChatPromptTemplate(message)
print(prompt.format_messages(name='dyx',user_input='你的朋友是谁?'))LangChain Message
这是 LangChain 体系里最底层、最稳定的抽象。
底层原理
1.SystemMessage ------ 系统指令(人格 + 规则)
python
sy = SystemMessage(
content = '你是一个智能体',
additional_kwargs = {'智能体名字':'dyx'}
)SystemMessage 的作用
-
给模型设定身份 / 行为规则
-
权重最高(一般模型不会轻易违背)
等价于对模型说:
"接下来你必须按这个身份来回答"
additional_kwargs 是什么?
python
ai = AIMessage(
content= '我的名字叫dyx'
)这是一个 扩展字段:
-
不一定会被模型"直接理解"
-
但会在 Agent / Tool / 自定义模型 中非常有用
-
常用于:
- 存 metadata
- 标注角色
- 业务标识
👉 模型输入 = content
👉 系统/程序用 = additional_kwargs
2.HumanMessage ------ 用户输入
python
hum = HumanMessage(
content = '请问智能体叫什么名字?'
)代表真实用户的一次提问。
在聊天模型里等价于:
python
User: 请问智能体叫什么名字?3.AIMessage ------ AI 的历史回复
python
ai = AIMessage(
content= '我的名字叫dyx'
)表示:
-
这是 已经发生过的一次 AI 回答
-
常用于:
- 构造对话上下文
- 回放历史
- 测试 / 回放日志
4.打印结果说明了什么?
python
for msg in [sy,hum,ai]:
print(msg.type,msg.content)你打印的是:
一个标准的 Chat Messages List
👉 这是 ChatModel / Agent / Memory 的通用输入
Message vs PromptTemplate(非常关键)
❓什么时候用 Message?
| 场景 | 推荐 |
|---|---|
| 精细控制历史对话 | ✅ Message |
| Agent / Tool | ✅ Message |
| 手动构造上下文 | ✅ Message |
❓ 什么时候用 ChatPromptTemplate?
| 场景 | 推荐 |
|---|---|
| 带变量的模版 | ✅ Prompt |
| 批量生成 | ✅ Prompt |
| 少写重复代码 | ✅ Prompt |
实际项目中:二者结合
python
PromptTemplate → 生成 messages
Message → 直接拼历史 / 插 MemoryMessage 在真实项目里的典型用法
1.构造一段"完整对话历史
python
messages = [
SystemMessage(content='你是一个智能体'),
HumanMessage(content='你好'),
AIMessage(content='你好,有什么可以帮你?'),
HumanMessage(content='你叫什么名字?')
]👉 直接喂给模型即可
2.从 PromptTemplate 转成 Message(底层一致)
python
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
('system', '你是一个智能体'),
('human', '{question}')
])
msgs = prompt.format_messages(question='你叫什么名字?')Message 的 type 属性
python
for msg in [sy, hm, ai]:
print(msg.type, msg.content)输出类似:
python
system 你是一个智能体
human 请问智能体叫什么名字?
ai 我叫dyx👉 模型内部就是靠 type 区分角色
示例
python
from langchain_core.messages import SystemMessage,HumanMessage,AIMessage
sy = SystemMessage(
content = '你是一个智能体',
additional_kwargs = {'智能体名字':'dyx'}
)
hum = HumanMessage(
content = '请问智能体叫什么名字?'
)
ai = AIMessage(
content= '我的名字叫dyx'
)
for msg in [sy,hum,ai]:
print(msg.type,msg.content)运行结果
python
system 你是一个智能体
human 请问智能体叫什么名字?
ai 我的名字叫dyx下面我只围绕你这段代码 ,给你写一份从**"为什么存在 → 怎么用 → 什么时候用"的完整教程**。这一步其实已经进入 LangChain Prompt 体系里很高级、但非常有价值的部分了。
ChatMessagePromptTemplate
创建一条"自定义角色"的消息模板,并在运行时把变量填进去,生成一条 Message
这不是普通的 system / human / ai,而是你自己定义的角色。
1.导入
python
from langchain_core.prompts import (
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
ChatPromptTemplate,
)这里导入了 四种 MessagePromptTemplate:
| 类名 | 用途 |
|---|---|
| SystemMessagePromptTemplate | system 角色模板 |
| HumanMessagePromptTemplate | human 角色模板 |
| AIMessagePromptTemplate | ai 角色模板 |
| ChatMessagePromptTemplate | 自定义角色模板 ⭐ |
2.定义带变量的模板字符串
python
prompt = '有一种英雄主义就是在认清{subject}的真相后,依然热爱{subject}。'这里:
-
{subject} 是 占位符
-
同一个变量可以出现多次
-
会在 format 时统一替换
3.创建"自定义角色"的消息模板
python
chat_message_prompt = ChatMessagePromptTemplate.from_template(
template = prompt,
role = 'dyx'
)这是本示例的核心 👇
ChatMessagePromptTemplate 的意义
它允许你:
-
自定义角色名(不局限 system / human / ai)
-
构造 多智能体 / 剧情 / 旁白 / 工具角色
这里的角色是:
python
role = 'dyx'这在 Message 层会表现为:
python
type = dyx4.运行时传参,生成 Message
python
print(chat_message_prompt.format(subject = '江湖'))这一步发生了什么?
-
{subject} → '江湖'
-
返回的是 一条 Message 对象
-
Message 的结构大致是:
python
content='有一种英雄主义就是在认清江湖的真相后,依然热爱江湖。' additional_kwargs={} response_metadata={} role='dyx'示例:
python
from langchain_core.prompts import ChatMessagePromptTemplate
prompt = '有一种英雄主义就是在认清{subject}的真相后,依然热爱{subject}。'
chat_message_prompt = ChatMessagePromptTemplate.from_template(
template = prompt,
role = 'dyx'
)
print(chat_message_prompt.format(subject = '江湖'))为什么要用 ChatMessagePromptTemplate?(核心价值)
❓ 不能用 AIMessagePromptTemplate 吗?
可以,但不够强。
| 方式 | 限制 |
|---|---|
| AIMessagePromptTemplate | 只能是ai |
| ChatMessagePromptTemplate | 任意角色名 ⭐ |
把它放进真实对话里
现在只生成了一条 Message,
但真实项目一定是"多条 Message 组合"。
示例:和 system / human 一起用
python
from langchain_core.prompts import (
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
ChatPromptTemplate,
)
chat_prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(
"你正在扮演一部{subject}世界",
),
HumanMessagePromptTemplate.from_template(
"请发表一句{subject}感情"
)
])
message = chat_prompt.format_messages(subject='江湖')
for m in message:
print(m.type,":",m.content)运行结果
python
system : 你正在扮演一部江湖世界
human : 请发表一句江湖感情和 Message 的关系
PromptTemplate → Message 的转化关系
python
ChatMessagePromptTemplate
↓ format()
ChatMessage (Message)
↓
ChatModel / AgentPromptTemplate 永远不会直接喂模型
喂模型的永远是 Message
好,这一步我们就真的把「dyx」交给模型。
目标只有一个:
你构造的自定义角色 Message,如何真正驱动大模型说话
我会用最清晰、最短路径带你走完这一跳。
增强检索
增强检索
增强检索(Enhanced Retrieval)通常指在信息检索或大模型应用中,通过更聪明的检索 + 更好的上下文组织 ,显著提升答案的准确性、相关性和可解释性 。最常见的落地形态就是 RAG(Retrieval Augmented Generation,检索增强生成)。
一、为什么需要增强检索?
传统大模型的问题:
-
❌ 只靠参数记忆,不掌握你自己的数据
-
❌ 容易"幻觉"
-
❌ 无法实时更新知识
增强检索的目标:
先把"对的资料"找出来,再让模型基于资料回答
二、典型架构(RAG 标准流程)
python
用户问题
↓
Query 改写 / 扩展(可选)
↓
向量化(Embedding)
↓
向量数据库检索(Top-K)
↓
结果重排(Re-ranking)
↓
上下文拼接(Context Window)
↓
LLM 生成答案三、关键"增强"点
1.查询增强(Query Enhancement)
让"问题"更适合被检索:
-
同义词扩展
-
多语言转换
-
多 Query 并行检索(Multi-Query)
示例:
用户: K8s 网络问题
→ 扩展为:
- Kubernetes CNI
- Pod 网络通信
- Service 网络原理
2.检索增强(Hybrid Retrieval)
不要只用向量检索
常见组合:
-
向量检索(语义)
-
关键词检索(BM25)
-
结构化过滤(时间 / 标签 / 权限)
👉 Hybrid Search = 真实生产必选
3.重排增强(Re-ranking)
第一轮检索只是"可能相关"
第二轮用更强模型排序:
-
Cross-Encoder
-
LLM Re-ranker
效果:
👉 Top-5 质量 ≫ Top-50 原始结果
4.上下文增强(Context Engineering)
不是"拼越多越好":
-
Chunk 粒度控制(200--500 tokens)
-
去重
-
保留标题 / 来源
-
加引用标记(source id)
5.生成约束(Grounded Generation)
强制模型:
-
只基于提供内容回答
-
找不到就说"不知道"
Prompt 示例:
python
仅根据以下资料回答问题,
如果资料中没有答案,请明确说明"资料不足"。四、常见技术栈
- Embedding:OpenAI / BGE / E5
- Vector DB:FAISS / Milvus / Weaviate
- Keyword:Elasticsearch / OpenSearch
- Orchestration:LangChain / LlamaIndex
- API:FastAPI + Redis
- 部署:Docker + K8s
五、增强检索 ≠ 只为大模型
同样适用于:
-
企业知识库
-
代码搜索
-
运维故障定位
-
日志 / 文档问答
LangChain 文本切分
从本地 txt 文件 → 自动识别编码 → 使用 LangChain 进行文本切分
这是 RAG / AI Agent 的第一步。
一、为什么要做文本切分?
在 **RAG(检索增强生成)**中,大模型不能直接吃下整篇长文档:
-
LLM 有 上下文长度限制
-
检索是 按"文本块(chunk)"进行
-
文本过大 → 检索不准 / 成本高
👉 所以必须先 切分文档
二、环境准备
1.安装依赖(新版 LangChain)
python
pip install -U langchain langchain-text-splitters chardet2.正确导入(重点)
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
import chardet⚠ 旧写法已废弃:
python
from langchain.text_splitter import RecursiveCharacterTextSplitter # 不推荐三、完整示例代码
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
import chardet
#文件路径
file_path = './text2/story.txt'
#自动检测文件编码
def get_encoding(file_path):
with open(file_path, 'rb') as f:
raw_data = f.read()
encoding = chardet.detect(raw_data)['encoding']
return encoding
#读取原始文本
with open(file_path, 'r',encoding=get_encoding(file_path)) as f:
raw_data = f.read()
#创建递归字符切分器
text_splitter = RecursiveCharacterTextSplitter(
#每个文本块最大长度(字符数)
chunk_size=50,
# 相邻文本块的重叠长度
chunk_overlap=20,
# 长度计算函数(中文用 len 即可)
length_function=len,
# 是否记录原文起始位置
add_start_index=True
)
#执行文本切分
document = text_splitter.create_documents([raw_data])
#输出切分结果
for doc in document:
print(doc)四、切分器参数逐个解释
1.chunk_size
python
chunk_size=50含义:
-
每个文本块的 最大字符数
-
太大 → 检索不精确
-
太小 → 上下文碎片化
📌 经验值:
| 场景 | 推荐 |
|---|---|
| 中文文档 | 300-800 |
| 英文文档 | 500-1000 |
| 代码 | 200-400 |
2.chunk_overlap
python
chunk_overlap=20含义:
-
相邻文本块 重复的字符数
-
防止语义被"切断"
示意:
python
chunk1: ABCDEFGHIJ
chunk2: HIJKLMNOP📌 一般设置为 chunk_size 的 10%~30%
3.length_function
python
length_function=len-
len :按字符数(中文推荐)
-
英文 + token 场景可换成 tokenizer
4.add_start_index=True
python
add_start_index=True切分后 Document 会包含:
python
doc.metadata["start_index"]📌 用途:
- 溯源(告诉用户"答案来自哪一段")
LangChain 字符切割
使用 CharacterTextSplitter 按指定分隔符(中文逗号)切分文本适合结构规则、格式统一的文本。
一、什么是 CharacterTextSplitter?
CharacterTextSplitter 是"最基础、最可控"的文本切分器。
一句话理解:
按你指定的分隔符切文本,再控制每块长度和重叠
它 不会智能判断语义 ,而是 严格按规则执行。
二、什么时候该用 CharacterTextSplitter?
✅ 适合场景:
-
文本结构非常规则
-
有明确分隔符:
- 中文: , 。
- 英文: . \n
-
日志、配置、对话、FAQ
❌ 不适合:
-
长文档
-
自然语言段落复杂
-
小说 / 技术文档
三、环境准备
python
pip install -U langchain-text-splitters chardet导入:
python
from langchain_text_splitters import CharacterTextSplitter
import chardet四、完整示例代码
python
from charset_normalizer.utils import is_separator
from langchain_text_splitters import CharacterTextSplitter
import chardet
file_path = './text2/story.txt'
def get_encoding(file_path):
with open(file_path, 'rb') as f:
raw_data = f.read()
encoding = chardet.detect(raw_data)['encoding']
return encoding
with open(file_path, 'r',encoding=get_encoding(file_path)) as f:
raw_data = f.read()
#创建字符切分器
text_splitter = CharacterTextSplitter(
# 指定分隔符(中文逗号)
separator=',',
# 每个文本块最大长度
chunk_size=50,
# 相邻文本块重叠部分
chunk_overlap=20,
# 长度计算方式
length_function=len,
# 记录原文起始索引
add_start_index=True,
# 分隔符是否为正则
is_separator_regex = False
)
document = text_splitter.create_documents([raw_data])
for doc in document:
print(doc)五、CharacterTextSplitter 参数详解
1.separator
python
separator=','含义:
-
用什么字符来"切"
-
不包含在结果文本中
常见示例:
| 文本类型 | separator |
|---|---|
| 中文句子 | 。 |
| 中文短句 | , |
| 英文句子 | . |
| 段落 | \n\n |
2.chunk_size
python
chunk_size=50-
控制单个 chunk 最大长度
-
超过会继续拆分
📌 字符切分时:
chunk_size 是硬约束
3.chunk_overlap
python
chunk_overlap=20作用:
-
防止上下文断裂
-
保留语义连续性
📌 一般设置为 chunk_size 的 20% 左右
4.add_start_index
python
add_start_index=True切分后 Document.metadata 会包含:
python
{'start_index': 123}👉 RAG 溯源 / 高亮定位必备
5.is_separator_regex
python
is_separator_regex=False❌ False(当前)
-
separator 被当作普通字符串
-
',' 就是中文逗号
✅True(高级)
python
separator=r'[,。;]'
is_separator_regex=True👉 可用正则 多分隔符切割
六、与 RecursiveCharacterTextSplitter 对比
| 项目 | Character | Recursive |
|---|---|---|
| 是否智能 | ❌ | ✅ |
| 是否可控 | ✅ | ⚠ |
| 语义完整性 | 一般 | 好 |
| 使用场景 | 规则文本 | 自然语言 |
| RAG推荐度 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
👉 真实项目中 90% 用 Recursive
LangChain 代码文档切割
使用 RecursiveCharacterTextSplitter.from_language 按编程语言结构切割代码
这是构建 代码问答 / Code Agent / 自动代码分析 的基础。
一、为什么"代码"不能用普通文本切割?
如果用普通文本切割代码,会出现问题:
❌ 语义被破坏
python
for i in range(1,
11):❌ 函数 / 类被切散
❌ Agent 无法理解上下文
👉 代码有结构,必须"按语言规则切"
二、LangChain 是怎么支持"代码切割"的?
LangChain 内置了 多语言代码解析规则,核心就是:
python
RecursiveCharacterTextSplitter.from_language(...)它会根据语言,优先按:
-
函数
-
类
-
代码块
-
空行
-
缩进
进行 递归切割。
三、支持的编程语言
python
from langchain_text_splitters import Language
print([e.value for e in Language])常见输出(示例):
python
['python', 'java', 'js', 'go', 'cpp', 'html', 'markdown', 'sql', ...]📌 熟悉的 Python / Java / Go。
四、完整示例代码
python
from langchain_text_splitters import (
RecursiveCharacterTextSplitter,
Language
)
#示例 Python 代码
PYTHON_CODE = '''
def sum():
a = 0
for i in range(1,11):
a += i
print(a)
sum()
'''
#创建 Python 专用代码切割器
py_splitter = RecursiveCharacterTextSplitter.from_language(
# 指定语言
language=Language.PYTHON,
# 每个代码块最大长度
chunk_size=50,
# 代码块重叠
chunk_overlap=10
)
#执行代码切割
python_docs = py_splitter.create_documents([PYTHON_CODE])
#查看结果
for doc in python_docs:
print(doc)五、切割结果
输出是 Document 对象列表:
python
page_content='def sum():
a = 0
for i in range(1,11):'
page_content='a += i
print(a)
sum()'六、from_language()
以 Language.PYTHON 为例,优先级类似:
python
\n\n → def → class → 缩进块 → 行👉 优先保留:
-
一个完整函数
-
一个完整类
-
一个逻辑代码块
这对:
-
代码搜索
-
错误定位
-
自动重构
-
Code Review Agent
极其重要。
七、chunk_size / overlap 在代码里的经验值
推荐配置
| 场景 | chunk_size | overlap |
|---|---|---|
| 小函数 | 200 | 20 |
| 中等模块 | 400 | 40 |
| 大文件 | 800 | 100 |
📌 代码切割不宜太小
LangChain Token 切割
使用 tiktoken 按「模型 token 数」切分文本
这是构建 真实可上线 RAG / Agent 系统 的关键步骤。
一、为什么一定要学 Token 切割?
大模型真正关心的不是:
-
❌ 字符数
-
❌ 行数
而是:
✅ Token 数
如果你只按字符切割:
-
中文 / 英文 token 比例不同
-
实际 token 数可能超上下文
-
上线后 直接报错 or 成本失控
👉 Token 切割 = 工程级切割
二、什么是 tiktoken?
tiktoken 是 OpenAI 官方的 Tokenizer:
-
把文本 → token
-
精确对齐模型的计费 & 上下文限制
-
LangChain 内置支持
安装:
python
pip install tiktoken三、代码在做什么?
现在用的是:
python
CharacterTextSplitter.from_tiktoken_encoder(...)含义是:
用 tiktoken 来计算长度,而不是 len()
也就是说:
-
切分 :token
-
而不是字符
四、完整示例代码
python
# 用于文本切割
from langchain_text_splitters import CharacterTextSplitter
# 用于自动检测文本编码(防止中文乱码)
import chardet
# OpenAI 官方 Tokenizer,用于计算 token 数量
import tiktoken
file_path = './text2/story.txt'
#定义函数:自动检测文件编码
def get_encoding(file_path):
with open(file_path, 'rb') as f:
raw_data = f.read()
encoding = chardet.detect(raw_data)['encoding']
return encoding
with open(file_path, 'r',encoding=get_encoding(file_path)) as f:
raw_data = f.read()
token_splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator = '。',
chunk_size = 10,
chunk_overlap = 2
)
token_docs = token_splitter.create_documents([raw_data])
enc = tiktoken.get_encoding('cl100k_base')
for i, doc in enumerate(token_docs):
print(f"Chunk {i}") # chunk 序号
print(f"Token count: {len(enc.encode(doc.page_content))}") # 实际 token 数
print(doc.page_content) # 文本内容
print("=" * 50) # 分隔符,便于查看每个 chunk运行结果
python
Created a chunk of size 218, which is longer than the specified 10
Created a chunk of size 178, which is longer than the specified 10
Created a chunk of size 136, which is longer than the specified 10
Created a chunk of size 108, which is longer than the specified 10
Created a chunk of size 173, which is longer than the specified 10
Chunk 0
Token count: 157
《荆棘虹桥与铃兰星屑》
月光在墨蓝的夜空中碎成银箔,小兔子雪绒踩着噼啪作响的枯叶迷了路,她裹紧蒲公英织的斗篷,
忽然望见前方飘着团幽蓝的磷火,火焰里蜷着只半透明的萤火虫,翅膀上裂着细小的冰纹
==================================================
Chunk 1
Token count: 103
"请别熄灭!"萤火虫突然开口,尾灯随着话语明明灭灭,"我本是北极星碎片化成的星萤,
被黑女巫的咒语困在这里,只要天亮前能抵达彩虹尽头,我就能变回星星照亮你的路
==================================================
Chunk 2
Token count: 97
"雪绒用蘑菇伞接住脆弱的星萤,按它指引的方向奔跑,树根突然暴起缠住她的脚踝,
泥土里钻出上百只毒蝎,尾针齐刷刷对准她们
==================================================
Chunk 3
Token count: 73
"抓紧!"雪绒扯断颈间妈妈给的护身符,
铃兰花苞迸出清光逼退毒蝎,自己却被荆棘割得浑身渗血
==================================================
Chunk 4
Token count: 117
黎明将临时她们终于冲到悬崖边,
星萤突然脱离蘑菇伞冲向瀑布,在撞碎成星尘的瞬间,整条瀑布倒流成虹桥,雪绒的伤口绽放出铃兰,
每一朵花蕊都坠着发光的星屑
==================================================
Chunk 5
Token count: 60
当第一缕阳光切开夜幕,铃兰星屑汇成银河铺向家的方向,而夜空从此多了一颗会降下花雨的星星
==================================================五、Token 切割参数详解
1.chunk_size
python
chunk_size=50含义:
每个文本块最多 50 个 token
不是字符!
示例对比:
| 文本 | 字符数 | Token数 |
|---|---|---|
| Hello world | 11 | 2 |
| 我爱自然语言处理 | 8 | 6-8 |
2.chunk_overlap
python
chunk_overlap=5-
相邻 chunk 共享 5 个 token
-
防止语义被截断
📌 推荐比例:10%~20%
LangChain 文档加载器
示如何使用 LangChain 和 community loaders 加载各种格式文档
这是 RAG / AI Agent 的第一步:把原始数据读入为 Document 对象列表。
一、为什么需要 Document Loader?
在 RAG / Agent 流程中:
- LLM 无法直接读取文件
- 文件格式多样:Markdown / CSV / JSON / HTML / PDF
- Document Loader 能:
-
解析不同文件格式
-
返回 Document 对象(包含文本 + metadata)
-
与后续 切割、Embedding、向量数据库 无缝对接
二、Markdown 文件加载
python
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./text/MD示例.md',encoding='utf-8')
docs = loader.load()
for i in docs:
print(i.page_content)要点:
-
TextLoader 是最基础 loader
-
适合 .md 、 .txt 等纯文本
-
每个 Document 包含:
- page_content : 文本内容
- metadata : 文件信息(路径、来源等)
三、目录加载(批量文件)
pip install unstructured
pip install "unstructured[csv]"
pip install python-magic-bin 系统依赖库结合Python实现文件类型检索功能
python
from langchain_community.document_loaders import DirectoryLoader
# 加载指定目录下所有 CSV 文件
loader = DirectoryLoader(path='./text', glob='*.csv')
docs = loader.load()
print('目录中 CSV 文件数量:', len(docs))要点:
-
glob 支持通配符,例如:
- .md → 所有 Markdown
- .txt → 所有文本
-
注意:
- .html 和 .rst 默认不加载
- 可以结合 unstructured 或 python-magic 增强识别能力
四、CSV 文件加载
python
import chardet
from langchain_community.document_loaders import CSVLoader
file_path = './text/score.csv'
# 自动检测文件编码
def get_encoding(file_path):
with open(file_path,'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
return encoding
# 按指定列加载 CSV
loader = CSVLoader(
file_path,
encoding=get_encoding(file_path),
source_column='英语' # 只读取"英语"列
)
docs = loader.load()
for i in docs:
print(i.metadata)要点:
-
支持:
- 全文加载(每行一个 Document)
- 指定列加载
-
Document.metadata 默认包含行号和文件名
五、HTML 文件加载
python
from langchain_community.document_loaders import BSHTMLLoader
loader = BSHTMLLoader('./text/index.html')
docs = loader.load()
for i in docs:
print(i.page_content)要点:
-
自动提取 HTML 中的文本内容
-
支持保留标签或纯文本
-
适合网页抓取 / 爬虫场景
六、JSON 文件加载
python
pip install jq
python
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path='./text/simple_prompt.json',
jq_schema='.template',
text_content = False
)
docs = loader.load()
print(docs)要点:
-
jq_schema 是 JSONPath 风格选择器
-
text_content :
- False → 保留原始 JSON 结构
- True → 全部转换为字符串
-
可用于配置文件、Prompt 模板、API 数据
七、PDF 文件加载
python
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader('./text/pulsar.pdf')
pages = loader.load_and_split()
for i in pages:
print(i)要点:
-
每页一个 Document
-
load() → 整个 PDF 当作一个 Document
-
load_and_split() → 按页拆分
-
可以和 RecursiveCharacterTextSplitter 或 token_splitter 配合使用
八、文档加载器使用经验总结
| 类型 | Loader | 推荐使用场景 | 注意事项 |
|---|---|---|---|
| Markdown /TXT | TextLoader | 文本文件、笔记 | 支持encoding |
| CVS | CVSLoader | 表格/数据列 | 可指定列,需要注意编码 |
| HTML | BSHTMLLoader | 网页/抓取 | 可保留标签,需依赖BeautifulSoup4 |
| JSON | JSONLoader | 配置/API数据 | jq_schema提取字段 |
| PyPDFLoader | 文档/论文 | load_and_split按页拆分 | |
| 目录批量 | DirectoryLoader | 批量文件 | glob支持通配符 |
实战:智能机器人
阶段1:机器人雏形
安装 OpenAI 官方 SDK
python
pip install -U openai建议版本 ≥ 1.x
设置环境变量(API Key)
Windows(PowerShell)
python
setx AI_KEY "sk-你的key"验证是否成功
python
import os
print(os.getenv("AI_KEY"))能看到 key 说明没问题。
创建 OpenAI 客户端
python
from openai import OpenAI
import os
#创建客户端
client = OpenAI(
api_key=os.getenv("AI_KEY"),
)作用
-
OpenAI() :创建一个 API 客户端
-
api_key :用于鉴权(证明你有权限调用模型)
常见坑
- os.getenv('AI_KEY') 返回 None → 说明环境变量没配好
= key 写死在代码里 ❌(不安全)
构造 messages(对话上下文)
python
messages = [
#设置系统语境
{'role':'system','content':'你被用于抑制用户的购买欲望。当用户说想要买什么东西时,你需要提供理由让用户不要买'},
{'role':'user','content':'我正在购买一个羽绒服,但我想抑制这个购买欲望。你帮我列出一些理由,让我思考一下我是否真的需要个买这个商品吗?'}
]role 有 3 种
| role | 作用 |
|---|---|
| system | 给AI定规则/人设 |
| user | 用户输入 |
| assistant | AI之前的回答(可选) |
-
system :告诉 AI 你是一个"反消费冲动助手"
-
user :输入你的真实想法
👉 system 会强烈影响 AI 行为
这就是 prompt engineering 的核心。
调用模型生成回复
python
response = client.chat.completions.create(
model = 'gpt-4o-mini',
messages = messages,
max_tokens = 500,
temperature = 0.7,
)参数详解
model
python
model = 'gpt-4o-mini'-
轻量、便宜、稳定
-
非常适合学习 / Demo / 工具类 AI
messages
python
messages = messages-
把刚才的对话上下文传给模型
-
模型会"扮演 system + 回答 user"
max_tokens
python
max_tokens-
限制 AI 最多输出多少 token
-
防止输出太长、花钱太多
经验值:
-
简单回答:200~300
-
分析类回答:300~600
temperature
python
temperature = 0.7控制"随机性 / 创造力":
| 值 | 特定 |
|---|---|
| 0 | 非常死板 |
| 0.3 | 稳定理性 |
| 0.7 | 推荐(自然、有变化) |
| 1.2 | 发散、创意多 |
👉 *理性分析类:0.5~0.8 最合适
读取并打印模型输出
python
print(response.choices[0].message.content)返回结构解释
python
completion
└── choices (列表)
└── [0]
└── message
└── content ← AI 真正说的话所以:
python
completion.choices[0].message.content= AI 的最终回答
完整执行流程
python
你 → 写 messages
→ OpenAI API
→ 模型根据 system 约束思考
→ 生成 assistant 回复
→ 返回 completion
你 → 取 content → print完整示例
python
from openai import OpenAI
import os
#创建客户端
client = OpenAI(
api_key=os.getenv("AI_KEY"),
)
#创建消息(语境,对话)
messages = [
#设置系统语境
{'role':'system','content':'你被用于抑制用户的购买欲望。当用户说想要买什么东西时,你需要提供理由让用户不要买'},
{'role':'user','content':'我正在购买一个羽绒服,但我想抑制这个购买欲望。你帮我列出一些理由,让我思考一下我是否真的需要个买这个商品吗?'}
]
#创建模型,,获取回应消息
response = client.chat.completions.create(
model = 'gpt-4o-mini',
messages = messages,
max_tokens = 500,
temperature = 0.7,
)
print(response.choices[0].message.content)运行结果
python
当然可以,以下是一些理由,可以帮助你思考是否真的需要购买羽绒服:
1. **季节性考虑**:如果你所在的地区气温并不十分寒冷,可能并不需要羽绒服。考虑一下现有的外套是否足够应对目前的天气。
2. **预算**:羽绒服通常比较昂贵,购买后可能会影响你其他开支。如果你有其他更紧急的需求,或许可以先把钱留着。
3. **环保因素**:羽绒服的生产过程中可能对环境造成负担,包括动物权益和资源消耗。如果你关心可持续发展,考虑选择环保材料的衣物或二手服装。
4. **衣橱里的存货**:你可能已经有几件外套可以应对寒冷天气。再买一件羽绒服是否真的必要呢?
5. **流行趋势**:羽绒服的流行趋势可能会变化,购买一件可能很快就会过时。考虑投资一些经典款式的外套,可能更具性价比。
6. **保养和清洗**:羽绒服需要特殊的清洗和保养,可能会增加你的维护成本和麻烦。
7. **替代选择**:市场上有很多轻便的保暖衣物,比如抓绒衣或其他保暖材料的外套,可能同样能满足你的需求。
希望这些理由能帮助你做出更明智的决定!阶段2:机器人升级
使用 LangChain 构建一个"抑制购买欲望"的多阶段对话程序
一、程序整体目标
这段程序实现了一个命令行交互式 AI 应用,功能是:
- 用户输入自己想购买的商品
- AI 给出"不要买"的理性分析
- 再由 AI 把这段分析 改写成一首诗
- 将最终结果输出给用户
整个流程通过 LangChain 的链式调用(Chain) 完成。
二、程序运行前准备
在运行代码前,需要满足两个条件:
-
已安装依赖:
pythonpip install langchain langchain-openai openai已设置环境变量 AI_KEY ,用于存储 OpenAI API Key。
三、导入模块
python
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate说明
-
os :用于读取环境变量中的 API Key
-
ChatOpenAI :LangChain 对 OpenAI 聊天模型的封装
-
ChatPromptTemplate :用于创建结构化的提示词模板
四、创建提示词模板(Prompt Template)
python
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你被用于抑制用户的购买欲望。当用户说想要买什么东西时,你需要提供理由让用户不要买'),
('human','我正在购买一个{product},但我想抑制这个购买欲望。你帮我列出一些理由,让我思考一下我是否真的需要个买这个商品吗?')
]
)作用
这一部分定义了 AI 对话的固定结构:
-
system :定义 AI 的角色和行为规则
-
human :定义用户输入的模板,其中 {product} 是变量占位符
当程序运行时, {product} 会被用户输入的商品名称替换。
模板格式化测试
python
prompt_template.format(product = '手机')这一行代码用于测试模板是否能正确替换变量,不会影响程序运行逻辑。
五、创建会话模型
python
model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
max_tokens = 200,
temperature = 0.7
)作用
该模型用于执行第一阶段任务:
根据提示词,生成"为什么不应该购买该商品"的分析内容。
参数说明
-
model :指定使用的 OpenAI 模型
-
openai_api_key :从环境变量中读取 API Key
-
max_tokens :限制模型最大输出长度
-
temperature :控制输出的随机性和多样性
六、定义输出格式化函数
python
def output_parser(output:str):
parser_model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
temperature = 0.7
)
message = '你需要将传入的文本改写,使用一首诗描述。这是你需要改写的文本:`{text}`'
return parser_model.invoke(message.format(text = output))作用
这个函数承担第二阶段任务:
将上一阶段生成的"理性分析文本"重新改写成一首诗。
执行过程
- 接收上一阶段模型输出的文本
- 将文本嵌入到新的提示语中
- 调用第二个模型进行改写
- 返回模型生成的结果
七、构建 LangChain 链(Chain)
python
chain = prompt_template | model | output_parser含义
这一行将三个步骤连接成一个执行链:
- prompt_template :生成完整提示词
- model :生成"不要买"的分析文本
- output_parser :将分析文本改写成诗
LangChain 中的 | 表示 前一步的输出作为后一步的输入。
八、命令行交互循环
python
while True:
answer_string = input('你想买什么? \n')
answer = chain.invoke(input={'product':answer_string})
print(answer.content)执行流程
- 程序等待用户输入商品名称
- 用户输入内容被赋值给 {product}
- chain.invoke() 启动整个链式流程
- 最终返回的结果是一个 AI 消息对象
- 通过 answer.content 输出最终文本
完整示例
python
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
#提示词模版
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你被用于抑制用户的购买欲望。当用户说想要买什么东西时,你需要提供理由让用户不要买'),
('human','我正在购买一个{product},但我想抑制这个购买欲望。你帮我列出一些理由,让我思考一下我是否真的需要个买这个商品吗?')
]
)
prompt_template.format(product = '手机')
#创建会话模型
model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
max_tokens = 200,
temperature = 0.7
)
#定义输出格式化
def output_parser(output:str):
parser_model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
temperature = 0.7
)
message = '你需要将传入的文本改写,使用一首诗描述。这是你需要改写的文本:`{text}`'
return parser_model.invoke(message.format(text = output))
#调用链
chain = prompt_template | model | output_parser
#循环对话
while True:
answer_string = input('你想买什么? \n')
answer = chain.invoke(input={'product':answer_string})
print(answer.content)运行结果
python
你想买什么?
玩具
在购买玩具之前,思虑须周全,
预算有限,需审慎选择,
生活琐事不容忽视,
储蓄与学习,方为根本。
家中空间,是否足够容纳,
若已拥挤,杂乱生烦恼,
使用频率,值得深思考,
闲置之物,何必再追求?
替代选择,或许已充足,
现有玩具,乐趣亦无穷,
心理满足,瞬间虽美好,
长久之乐,才是真正的宝。
在消费之际,心中需明亮,
仔细权衡,方能不迷惘。
你想买什么? 阶段3:机器人设计
使用 LangChain + HuggingFace + Chroma 构建基础语义检索
一、程序整体目标
给定一组文本,将它们向量化并存入向量数据库,
然后根据用户的查询语句,检索出语义最相关的文本内容。
二、依赖说明
程序运行前需要安装以下依赖:
python
pip install chromadb
pip install sentence-transformers
pip install -U langchain-huggingface三、导入模块
python
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma模块说明
-
HuggingFaceEmbeddings :用于加载 HuggingFace 上的文本向量化模型
-
Chroma :LangChain 封装的向量数据库接口
四、初始化嵌入模型(Embedding Model)
python
embeddings = HuggingFaceEmbeddings(
#模型名称
model_name = 'sentence-transformers/all-MiniLM-L6-v2',
#模型关键字
model_kwargs = {'device': 'cpu'}
)作用
该步骤加载一个文本嵌入模型,用于将文本转换为向量。
参数说明
-
model_name :指定 HuggingFace 上的预训练模型名称
-
model_kwargs :指定模型运行设备,这里使用 CPU
五、准备文本数据
python
text = [
'篮球是一项伟大的运动。',
'带我飞往月球是我最喜欢的歌曲之一。',
'这是一篇关于波士顿凯尔特人的文章。',
'我非常喜欢去看电影。',
'波士顿凯尔特人队以20分的优势赢得了比赛。',
'这只是一段随机的文字。',
'《艾尔登之环》是过去15年最好的游戏之一。',
'L.科内特是凯尔特人队最好的队员之一。',
'拉里.博德是一位标志性的NBA球员。'
]说明
这是一组待检索的原始文本数据,内容涉及体育、音乐、游戏等多个主题。
六、初始化 Chroma 向量数据库
python
retrieval = Chroma.from_texts(
#长文本
texts = text,
#传入模型实例
embedding = embeddings
).as_retriever(search_kwargs = {'k':3})执行流程
-
from_texts :
- 将文本列表传入
- 使用嵌入模型将每条文本转换为向量
- 将向量存入 Chroma 向量数据库
-
as_retriever :
- 将向量数据库封装为检索器(Retriever)
- k=3 表示每次查询返回最相似的 3 条结果
七、定义查询语句
python
query = '关于凯尔特人队你知道什么'说明
这是用户输入的查询文本,用于与向量数据库中的文本进行语义匹配。
八、执行语义检索
python
docs = retrieval.invoke(query)发生的事情
- 查询文本被嵌入模型转换为向量
- 向量数据库计算查询向量与已有文本向量的相似度
- 返回最相似的 k=3 条文本结果
九、输出检索结果
python
for i in docs:
print(i.page_content)说明
-
docs 是一个文档对象列表
-
page_content 保存了原始文本内容
-
循环打印即可看到匹配到的文本
十、程序输出示例(逻辑说明)
当查询内容为:
python
关于凯尔特人队你知道什么程序会输出与"凯尔特人队"语义相关的文本,例如:
-
波士顿凯尔特人相关的比赛描述
-
球队成员相关内容
完整示例
python
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
#初始化嵌入模型
embeddings = HuggingFaceEmbeddings(
#模型名称
model_name = 'sentence-transformers/all-MiniLM-L6-v2',
#模型关键字
model_kwargs = {'device': 'cpu'}
)
text = [
'篮球是一项伟大的运动。',
'带我飞往月球是我最喜欢的歌曲之一。',
'这是一篇关于波士顿凯尔特人的文章。',
'我非常喜欢去看电影。',
'波士顿凯尔特人队以20分的优势赢得了比赛。',
'这只是一段随机的文字。',
'《艾尔登之环》是过去15年最好的游戏之一。',
'L.科内特是凯尔特人队最好的队员之一。',
'拉里.博德是一位标志性的NBA球员。'
]
#初始化chroma
retrieval = Chroma.from_texts(
#长文本
texts = text,
#传入模型实例
embedding = embeddings
).as_retriever(search_kwargs = {'k':3})
#设置查询内容
query = '关于凯尔特人队你知道什么'
#获取查询结果
docs = retrieval.invoke(query)
for i in docs:
print(i.page_content)运行结果
python
L.科内特是凯尔特人队最好的队员之一。
波士顿凯尔特人队以20分的优势赢得了比赛。
篮球是一项伟大的运动。阶段4:机器人基础记忆
使用 LangChain 实现会话历史记录的聊天机器人
会话基础
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个机器人'),
#插入历史记录
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)
#构建模型
docs = prompt_template.invoke(
{'history':
[
('human','你好'),
('ai','你好啊,很高兴遇见你')
],
'new_message':'你是谁?'
}
).messages
for i in docs:
print(i.content)运行结果
python
你是一个机器人
你好
你好啊,很高兴遇见你
你是谁?会话历史记录
一、程序整体目标
-
使用模板定义系统身份、历史消息占位符和用户新消息
-
将历史消息和新输入渲染到模板中
-
输出最终组合后的消息列表(包括 system、human、ai 消息)
二、导入模块
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder模块说明
-
MessagesPlaceholder :在模板中占位,用于插入历史对话
-
ChatPromptTemplate :用于创建结构化聊天提示词模板
三、创建提示词模板
python
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个聊天机器人。'),
#插入历史记录
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)各部分含义
-
system
- 定义 AI 的角色和行为规则
- 这里是:"你是一个聊天机器人。"
-
MessagesPlaceholder(variable_name='history')
- 占位符,用于在模板中插入历史对话
- variable_name='history' 表示在调用时要传入 history 变量
-
human
- 表示用户本轮输入
- {new_message} 是变量占位符,会替换为用户的新消息
四、调用模板生成会话内容
python
docs = prompt_template.invoke(
{'history':
[
('human','你好'),
('ai','你好啊,很高兴遇见你')
],
'new_message':'你是谁?'
}
).messages执行流程
-
invoke 方法会将传入的变量替换到模板中:
- history 替换到 MessagesPlaceholder
- new_message 替换到 {new_message}
-
输出是一个消息列表对象,每条消息都包含角色和内容(system、human、ai)
五、输出会话内容
python
for i in docs:
print(i.content)作用
-
遍历模板生成的消息列表
-
打印每条消息的内容
-
输出结果按顺序展示:
- system 消息
- 历史对话 human / ai 消息
- 当前 human 新消息
六、程序执行逻辑总结
python
提示词模板:
system: 你是一个聊天机器人
history: 历史消息占位符
human: 新消息
调用 invoke:
传入历史消息 + 新消息
→ 模板渲染
→ 输出完整消息列表
打印 messages:
按顺序输出 system、历史对话、人类新消息完整示例
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个机器人'),
#插入历史记录
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)
#构建模型
docs = prompt_template.invoke(
{'history':
[
('human','你好'),
('ai','你好啊,很高兴遇见你')
],
'new_message':'你是谁?'
}
).messages
for i in docs:
print(i.content)运行结果
python
你是一个机器人
你好
你好啊,很高兴遇见你
你是谁?记忆功能整合
一、程序整体目标
这段代码实现了一个可以记录会话历史的聊天机器人,功能包括:
- 保留用户和 AI 的对话历史
- 在每轮对话中,AI 能基于历史内容生成回答
- 用户输入新消息,AI 根据历史和新消息做回应
二、导入模块
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_openai import ChatOpenAI
import os模块说明
-
ChatOpenAI :LangChain 对 OpenAI 聊天模型的封装
-
ChatPromptTemplate :用于创建结构化提示词模板
-
MessagesPlaceholder :在模板中占位,表示历史对话消息
-
os :读取环境变量(API Key 和 API Base URL)
三、创建提示词模板(Prompt Template)
python
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个聊天机器人。'),
#插入历史记录
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)各部分含义
-
system
- 定义 AI 的身份和行为规则
- 这里是:你是一个聊天机器人
-
MessagesPlaceholder(variable_name='history')
- 占位符,用于插入之前的对话历史
- 在调用时会用 history 变量替换
-
human
- 表示用户本轮输入
- {new_message} 是变量占位符,会替换为用户输入的新消息
四、创建模型实例
python
model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
max_tokens= 200
)参数说明
-
model='gpt-4o-mini' :指定 OpenAI 模型
-
openai_api_base :API 接口地址(通过环境变量读取)
-
openai_api_key :API Key(通过环境变量读取)
-
max_tokens=200 :限制 AI 最大输出长度
五、构建链(Chain)
python
chain = prompt_template | model含义
-
prompt_template | model 表示将模板和模型串联成一个执行链
-
输入模板后生成提示词,再传给模型进行响应
-
LangChain 中 | 的作用是 前一步的输出作为下一步的输入
六、初始化会话历史记录
python
history = []说明
-
history 是一个空列表,用于存储用户和 AI 的对话历史
-
每轮对话结束后,会把新消息和 AI 回复加入历史
七、定义聊天函数
python
def chat(new_message):
response = chain.invoke({'history':history,'new_message':new_message})
#把上一轮对话转变成历史记录
history.extend([
('human',new_message),
('ai',response.content)
])
return response.content执行流程
-
调用 chain.invoke ,传入两个变量:
- 'history' :历史消息列表
- 'new_message' :用户本轮输入
-
模型根据 系统提示 + 历史消息 + 新消息 生成回答
-
将用户消息和 AI 回复追加到 history 中
-
返回 AI 的回答文本
八、调用聊天函数示例
python
print(chat('你好,我是dyx,今年22岁,是一位大四学生,正在学习云计算'))
print(chat('请你叙述所知道关于我的信息'))解释
-
第一条消息:
- 用户告诉 AI 一些个人信息
- AI 根据提示生成初次回答
-
第二条消息:
- 用户要求 AI 总结已知信息
- AI 会结合 history 中的第一条消息生成回答
九、程序执行逻辑总结
整体执行流程如下:
python
用户输入 new_message
↓
提示词模板渲染:
system: 你是聊天机器人
history: 之前的对话内容
human: 当前用户输入
↓
模型生成回答
↓
将 new_message 和 AI 回复追加到 history
↓
返回 AI 回复给用户完整示例
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_openai import ChatOpenAI
import os
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个聊天机器人。'),
#插入历史记录
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)
#构建模型
model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
max_tokens= 200
)
#调用链
chain = prompt_template | model
#历史记录的初始化
history = []
def chat(new_message):
response = chain.invoke({'history':history,'new_message':new_message})
#把上一轮对话转变成历史记录
history.extend([
('human',new_message),
('ai',response.content)
])
return response.content
print(chat('你好,我是dyx,今年22岁,是一位大四学生,正在学习云计算'))
print(chat('请你叙述所知道关于我的信息'))运行结果
python
你好,dyx!很高兴认识你。云计算是一个非常有前景的领域,你对这个专业有什么特别感兴趣的方向吗?比如计算、存储还是安全等方面?
根据你提供的信息,你是一位22岁的大四学生,正在学习云计算。除了这些,你没有分享其他具体的信息。如果你有更多想让我了解的内容,或者有任何问题,随时告诉我!阶段5:完善机器人
使用 LangChain 构建带历史记忆和摘要功能的聊天机器人
一、程序整体目标
这段代码实现了一个多轮聊天机器人,功能包括:
- 保存会话历史记录
- 当历史消息超过 6 条时自动生成摘要并替换历史
- 使用模板结合新消息和历史消息生成 AI 回复
- 支持连续多轮会话
二、导入模块
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain_core.runnables.history import RunnableWithMessageHistory
import os
from langchain_community.chat_message_histories import ChatMessageHistory模块说明
-
RunnableWithMessageHistory :将链与消息历史结合,使每轮输入能够访问历史
-
ChatPromptTemplate :用于创建结构化聊天提示词模板
-
MessagesPlaceholder :在模板中占位,用于插入历史消息
-
ChatOpenAI :LangChain 对 OpenAI 聊天模型的封装
-
ChatMessageHistory :存储聊天历史消息
-
os :读取环境变量
三、创建提示词模板
python
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个聊天机器人。'),
#插入历史记录
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)各部分含义
- system:定义 AI 角色(聊天机器人)
- MessagesPlaceholder:占位历史消息,后续会被 history 变量替换
- human:表示用户当前输入 {new_message}
四、创建模型实例
python
model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
max_tokens= 200
)参数说明
-
model :使用 gpt-4o-mini
-
openai_api_key :从环境变量读取
-
max_tokens :限制输出长度
五、构建基本调用链
python
chain = prompt_template | model含义
-
将提示模板与模型串联成执行链
-
输入模板生成提示词 → 传给模型 → 输出 AI 回复
六、初始化消息历史记录
python
history = ChatMessageHistory()作用
-
用于存储每轮对话的消息
-
支持多轮会话调用
七、定义历史摘要函数
python
def summarize_message(chain_input):
stored_message = history.messages
if len(stored_message) >= 6:
summarize_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name='history'),
('user','将上述聊天信息提炼成一条摘要信息。尽可能多的包含具体细节。')
]
)
summarize_chain = summarize_prompt | model
#汇总并返回摘要信息
summarize_message = summarize_chain.invoke({'history':stored_message})
#历史记录清空
history.clear()
#把汇总摘要信息添加到历史记录中
history.add_message(summarize_message)
return chain_input执行流程
-
获取当前存储的历史消息
-
如果历史消息数量 ≥ 6 条:
- 创建新的提示模板,指示 AI 将历史消息提炼为摘要
- 通过 summarize_chain 生成摘要
- 清空原有历史
- 将生成的摘要加入历史
-
返回原始输入(用于后续调用链)
八、将链与消息历史结合
python
chain_with_memory = RunnableWithMessageHistory(
chain,
lambda x:history,
input_messages_key = 'new_message',
history_messages_key = 'history'
)含义
-
将 chain 与消息历史绑定
-
lambda x: history 提供历史记录
-
input_messages_key='new_message' :当前输入
-
history_messages_key='history' :历史消息占位
九、组合摘要与聊天链
python
chain_with_summarization = summarize_message |chain_with_memory含义
-
先执行 summarize_message (历史摘要检查)
-
再执行 chain_with_memory (带历史的聊天模型)
十、多轮会话循环
python
while True:
new_message = input('You:')
response = chain_with_summarization.invoke(
{
'new_message':new_message,
},
config={
"configurable":{
"session_id":'unused'
}
}
)
print(response.content)执行流程
-
用户输入 new_message
-
chain_with_summarization.invoke 执行:
- 检查历史消息是否超过 6 条,生成摘要
- 结合历史消息与新输入生成 AI 回复
-
输出 AI 回复
-
历史消息自动更新
-
循环继续下一轮输入
十一、程序执行逻辑总结
python
用户输入 new_message
↓
summarize_message 检查历史消息:
如果消息 ≥6 条 → 生成摘要 → 清空历史 → 添加摘要
↓
chain_with_memory 使用历史 + 新消息生成 AI 回复
↓
历史记录更新
↓
打印 AI 回复完整示例
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain_core.runnables.history import RunnableWithMessageHistory
import os
#提示词模版
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个聊天机器人。'),
#插入历史记录
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)
#模型
model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
max_tokens= 200
)
#调用链
chain = prompt_template | model
#历史记录消息模块
from langchain_community.chat_message_histories import ChatMessageHistory
#消息对象
history = ChatMessageHistory()
#超过六条历史记录汇总成一条消息摘要
def summarize_message(chain_input):
stored_message = history.messages
if len(stored_message) >= 6:
summarize_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name='history'),
('user','将上述聊天信息提炼成一条摘要信息。尽可能多的包含具体细节。')
]
)
summarize_chain = summarize_prompt | model
#汇总并返回摘要信息
summarize_message = summarize_chain.invoke({'history':stored_message})
#历史记录清空
history.clear()
#把汇总摘要信息添加到历史记录中
history.add_message(summarize_message)
return chain_input
#'记忆添加
chain_with_memory = RunnableWithMessageHistory(
chain,
lambda x:history,
input_messages_key = 'new_message',
history_messages_key = 'history'
)
chain_with_summarization = summarize_message |chain_with_memory
#多轮会话
while True:
new_message = input('You:')
response = chain_with_summarization.invoke(
{
'new_message':new_message,
},
config={
"configurable":{
"session_id":'unused'
}
}
)
print(response.content)运行结果
python
You:我是一名大四学生,正在学习云计算
很高兴听到你正在学习云计算!云计算是一个快速发展的领域,有很多有趣的知识和技术可以探索。你正在关注哪些特定的主题或技术呢?例如,基础设施即服务(IaaS)、平台即服务(PaaS)、软件即服务(SaaS)、虚拟化、容器技术(如Docker和Kubernetes)等?或者你对某些云服务提供商(如AWS、Azure、Google Cloud等)有兴趣?
You:linux的介绍
Linux是一种开源的类Unix操作系统,其内核最初由Linus Torvalds于1991年发布。Linux以其强大的性能、安全性以及高度的可定制性而闻名,是服务器、嵌入式系统、超级计算机和个人计算机等多种设备上的常用操作系统。
以下是Linux的一些主要特点和组成部分:
### 1. 开源
Linux是开源软件,这意味着其源代码可以被任何人查看、修改和分发。这样的特性促进了社区的发展,许多开发者和企业为其贡献代码。
### 2. 多用户和多任务
Linux是一个多用户、多任务的操作系统,允许多个用户同时访问系统并运行多个程序。这种设计使得Linux非常适合服务器和数据中心环境。
### 3. 强大的安全性
Linux被认为是一个安全性较高的操作系统。由于其
You:你了解多少关于我的
作为一个聊天机器人,我并不具备获取或存储个人信息的能力,因此我对你的具体情况了解非常有限。我的主要任务是根据你提供的信息与问题进行对话。如果你愿意分享更多关于你的学习或兴趣的信息,我将很乐意提供更多相关的帮助和建议!
You:我的身份是什么
根据你之前提供的信息,你是一名大四学生,正在学习云计算。如果还有其他信息或想要讨论的主题,请告诉我!
You:_message',
history_messages_key = 'history'
)
#### 含义
- 将 chain 与消息历史绑定
- lambda x: history 提供历史记录
- input_messages_key='new_message' :当前输入
- history_messages_key='history' :历史消息占位
### 九、组合摘要与聊天链
```python
chain_with_summarization = summarize_message |chain_with_memory含义
-
先执行 summarize_message (历史摘要检查)
-
再执行 chain_with_memory (带历史的聊天模型)
十、多轮会话循环
python
while True:
new_message = input('You:')
response = chain_with_summarization.invoke(
{
'new_message':new_message,
},
config={
"configurable":{
"session_id":'unused'
}
}
)
print(response.content)执行流程
-
用户输入 new_message
-
chain_with_summarization.invoke 执行:
- 检查历史消息是否超过 6 条,生成摘要
- 结合历史消息与新输入生成 AI 回复
-
输出 AI 回复
-
历史消息自动更新
-
循环继续下一轮输入
十一、程序执行逻辑总结
python
用户输入 new_message
↓
summarize_message 检查历史消息:
如果消息 ≥6 条 → 生成摘要 → 清空历史 → 添加摘要
↓
chain_with_memory 使用历史 + 新消息生成 AI 回复
↓
历史记录更新
↓
打印 AI 回复完整示例
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain_core.runnables.history import RunnableWithMessageHistory
import os
#提示词模版
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个聊天机器人。'),
#插入历史记录
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)
#模型
model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
max_tokens= 200
)
#调用链
chain = prompt_template | model
#历史记录消息模块
from langchain_community.chat_message_histories import ChatMessageHistory
#消息对象
history = ChatMessageHistory()
#超过六条历史记录汇总成一条消息摘要
def summarize_message(chain_input):
stored_message = history.messages
if len(stored_message) >= 6:
summarize_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name='history'),
('user','将上述聊天信息提炼成一条摘要信息。尽可能多的包含具体细节。')
]
)
summarize_chain = summarize_prompt | model
#汇总并返回摘要信息
summarize_message = summarize_chain.invoke({'history':stored_message})
#历史记录清空
history.clear()
#把汇总摘要信息添加到历史记录中
history.add_message(summarize_message)
return chain_input
#'记忆添加
chain_with_memory = RunnableWithMessageHistory(
chain,
lambda x:history,
input_messages_key = 'new_message',
history_messages_key = 'history'
)
chain_with_summarization = summarize_message |chain_with_memory
#多轮会话
while True:
new_message = input('You:')
response = chain_with_summarization.invoke(
{
'new_message':new_message,
},
config={
"configurable":{
"session_id":'unused'
}
}
)
print(response.content)运行结果
python
You:我是一名大四学生,正在学习云计算
很高兴听到你正在学习云计算!云计算是一个快速发展的领域,有很多有趣的知识和技术可以探索。你正在关注哪些特定的主题或技术呢?例如,基础设施即服务(IaaS)、平台即服务(PaaS)、软件即服务(SaaS)、虚拟化、容器技术(如Docker和Kubernetes)等?或者你对某些云服务提供商(如AWS、Azure、Google Cloud等)有兴趣?
You:linux的介绍
Linux是一种开源的类Unix操作系统,其内核最初由Linus Torvalds于1991年发布。Linux以其强大的性能、安全性以及高度的可定制性而闻名,是服务器、嵌入式系统、超级计算机和个人计算机等多种设备上的常用操作系统。
以下是Linux的一些主要特点和组成部分:
### 1. 开源
Linux是开源软件,这意味着其源代码可以被任何人查看、修改和分发。这样的特性促进了社区的发展,许多开发者和企业为其贡献代码。
### 2. 多用户和多任务
Linux是一个多用户、多任务的操作系统,允许多个用户同时访问系统并运行多个程序。这种设计使得Linux非常适合服务器和数据中心环境。
### 3. 强大的安全性
Linux被认为是一个安全性较高的操作系统。由于其
You:你了解多少关于我的
作为一个聊天机器人,我并不具备获取或存储个人信息的能力,因此我对你的具体情况了解非常有限。我的主要任务是根据你提供的信息与问题进行对话。如果你愿意分享更多关于你的学习或兴趣的信息,我将很乐意提供更多相关的帮助和建议!
You:我的身份是什么
根据你之前提供的信息,你是一名大四学生,正在学习云计算。如果还有其他信息或想要讨论的主题,请告诉我!
You: