文章目录
- 程序初始化
- [init 和 main 函数](#init 和 main 函数)
- string
- string是什么
-
- [string 数据结构](#string 数据结构)
- string与\[\]byte的互相转换
- 字符串声明
- 为什么这么设计
-
- [**make slice的时候没有分配足够的capacity**](#make slice的时候没有分配足够的capacity)
- [make slice的时候分配足够的capacity](#make slice的时候分配足够的capacity)
- 字符串拼接
- 字符串拼接的6种方式及原理
程序初始化
Go应用程序的初始化是在单一的goroutine中执行的。对于包这一级别的初始化来说,在一个包里会先进行包级别变量的初始化。一个包下可以有多个init函数,每个文件也可以有多个init 函数,多个 init 函数按照它们的文件名顺序逐个初始化。但是程序不可能把所有代码都放在一个包里,通常都是会引入很多包。如果main包引入了pkg1包,pkg1包本身又导入了包pkg2,那么应用程序的初始化会按照什么顺序来执行呢?
对于这个初始化过程我粗略的画了一个示意图,理解起来更直观些。
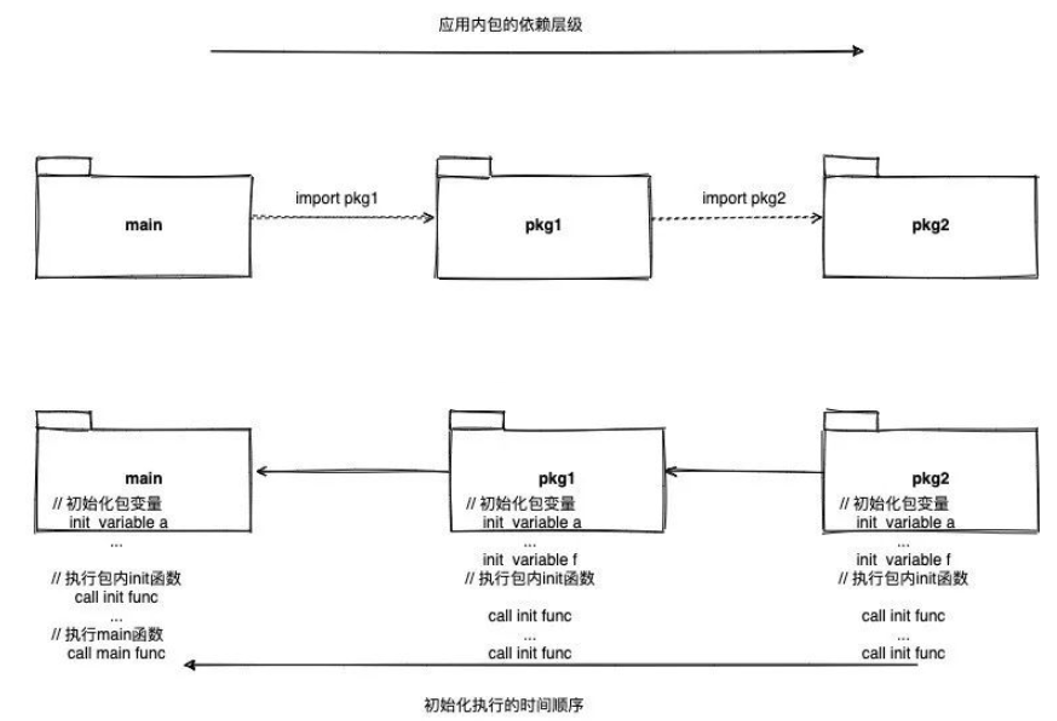
图的上半部分表示了main包导入了pkg1包,pkg1包又导入了pkg2包这样一个包之间的依赖关系。图的下半部分表示了,这个应用初始化工作的执行时间顺序是从被导入的最深层包开始进行初始化,层层递出最后到main包,每个包内部的初始化程序依然是先执行包变量初始化再进行init函数的执行。
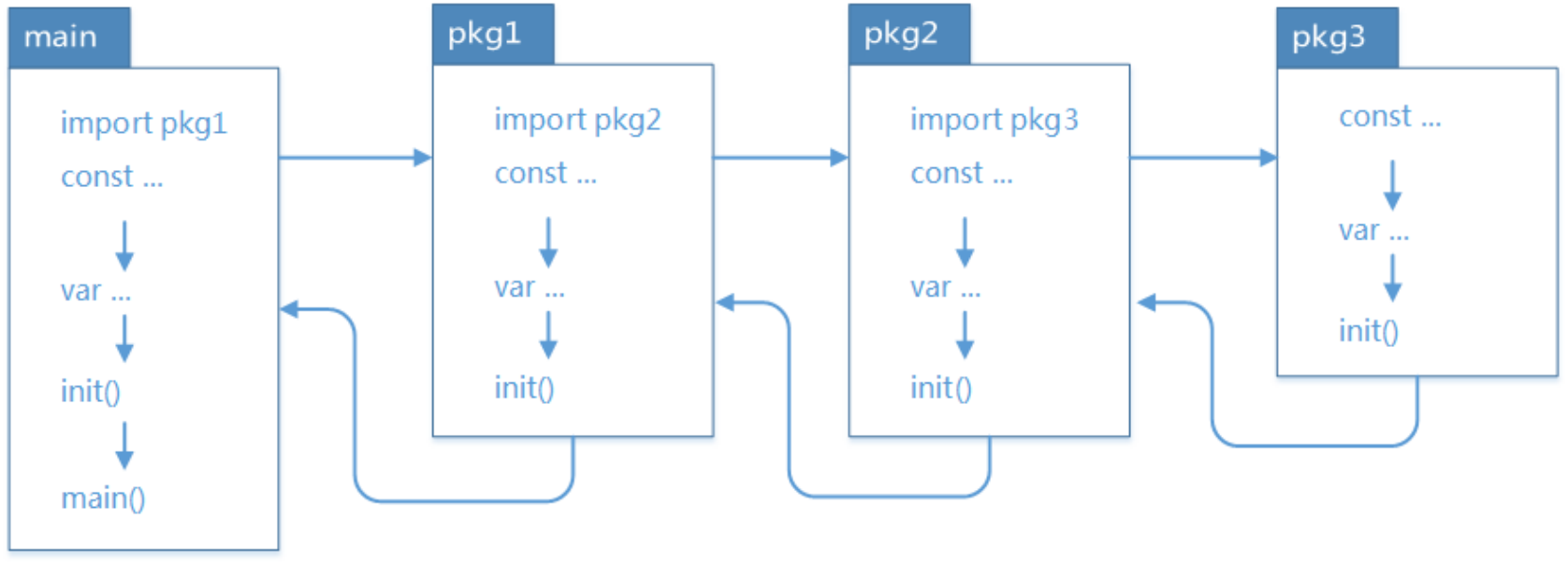
下面通过示例来验证一下这个初始化顺序
在go_tour目录下有三个包package1和package2和utils, 代码目录如下:
go
|--package1
|--package2
|--utils
分别定义测试函数,在 utils 包下有文件 utils.go
go
package utils
import "fmt"
func TraceLog(t string, v int) int {
fmt.Printf("TraceLog-----%s-------%d\n", t, v)
return v
}package1 包下有如下程序 package1.go:
handlebars
package package1
import (
"fmt"
"go_tour/package2"
"go_tour/utils"
)
var V1 = utils.TraceLog("init package1 value1", package2.Value1+10)
var V2 = utils.TraceLog("init package1 value2", package2.Value2+10)
func init() {
fmt.Println("init func in package1")
}package2 包下有如下程序 package2.go:
go
package package2
import (
"fmt"
"go_tour/utils"
)
var Value1 = utils.TraceLog("init package2 value1", 20)
var Value2 = utils.TraceLog("init package2 value2", 30)
func init() {
fmt.Println("init func1 in package2")
}
func init() {
fmt.Println("init func2 in package2")
}主程序 main.go:
go
package main
import (
"fmt"
"go_tour/package1"
"go_tour/utils"
)
func init() {
fmt.Println("init func1 in main")
}
func init() {
fmt.Println("init func2 in main")
}
var MainValue1 = utils.TraceLog("init M_v1", package1.V1+10)
var MainValue2 = utils.TraceLog("init M_v2", package1.V2+10)
func main() {
fmt.Println("main func in main")
}运行结果:
go
TraceLog-----init package2 value1-------20
TraceLog-----init package2 value2-------30
init func1 in package2
init func2 in package2
TraceLog-----init package1 value1-------30
TraceLog-----init package1 value2-------40
init func in package1
TraceLog-----init M_v1-------40
TraceLog-----init M_v2-------50
init func1 in main
init func2 in main
main func in main实验与结论相符合,按照导入包的层次,最先被依赖的包最先被初始化,且初始化的顺序是先初始化包变量,再初始化 init 函数。初始化过程总结如下:
- 包级别变量的初始化先于包内 init 函数的执行。
- 一个包下可以有多个 init 函数 ,每个文件也可以有多个 init 函数。
- 多个 init 函数按照它们的文件名顺序逐个初始化,即同一个 package 里如果有多个文件(比如 a.go、b.go),这些文件里的初始化(包级变量初始化 + init())会按"文件名排序后的顺序"依次执行。【执行顺序(同一个包内)】先按文件名的字典序把文件排好:a.go → b.go → c.go
- 应用初始化时初始化工作的顺序是,从被导入的最深层包开始进行初始化,层层递出最后到 main 包。
- 不管包被导入多少次,包内的 init 函数只会执行一次。
- 应用在所有初始化工作完成后才会执行 main 函数。
init 和 main 函数
init()、main() 是 go 语言中的保留函数,两个函数在 go 语言中的区别如下:
相同点:
- 两个函数在定义时不能有任何的参数和返回值
- 该函数只能由 go 程序自动调用,不可以被引用
不同点:
- init 可以应用于任意包中,且可以重复定义多个。
- main 函数只能用于 main 包中,且只能定义一个。
两个函数的执行顺序:
- 对同一个 go 文件的 init( ) 调用顺序是从上到下的
- 对同一个 package 中的不同文件,将文件名按字符串进行"从小到大"排序,之后顺序调用各文件中的init()函数
- 对于不同的 package,如果不相互依赖的话,按照 main 包中 import 的顺序调用其包中的 init() 函数
- 如果 package 存在依赖,调用顺序为最后被依赖的最先被初始化,例如:导入顺序 main --> A --> B --> C,则初始化顺序为 C --> B --> A --> main,一次执行对应的 init 方法。
在同一个文件中,常量、变量、init()、main() 依次进行初始化。
string
string是什么
在我们编程过程中,字符串可以说是我们使用的最多的一个数据结构了,凡是涉及到文本处理的地方,我们都会用到字符串。在go语言中,字符串其实就是一串由UTF-8编码的字符序列。
接下来我们看一下官方库对string的一个描述
go
var text string在IDE里面定义一个text的string变量,点击string跳转到其类型定义的地方,可从源代码看到对string的描述,源代码的位置在src/builtin/builtin.go,描述如下:
type string string 它其实只是 Go 在 builtin 包里对"内建类型 string"的一种声明方式。
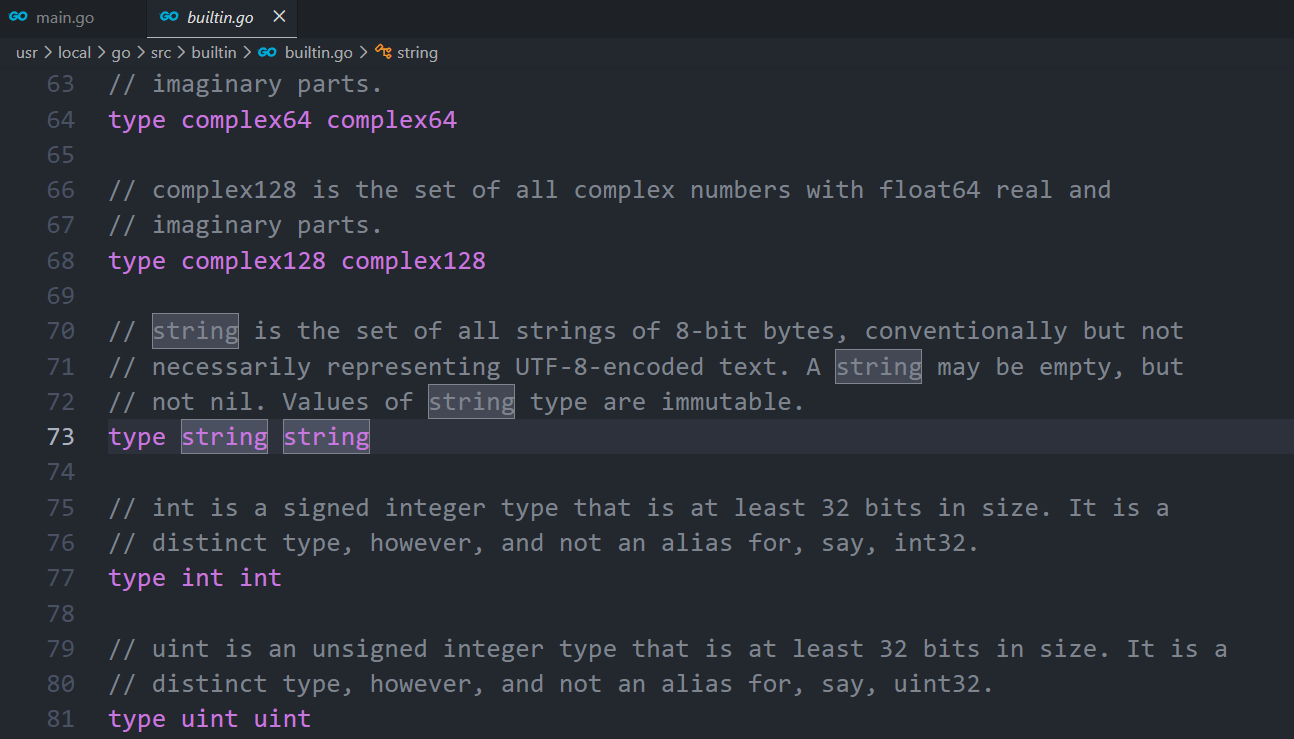
go
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string翻译一下,可以这样理解:
- 字符串是所有8bit 字节的集合,但不一定是 UTF-8 编码的文本,字符串你可以看作是一个字节数组,一个字节8bit,但是我们的文本有不同的编码,不一样的编码,一个字符可能会占用多个字节
- 字符串可以为空empty,但不能为 nil,empty字符串就是一个没有任何字符的空串""
- 字符串不可以被修改,所以字符串类型的值是不可变的,在 Go 里,一个 string 一旦创建,它里面那段"字节内容"就不能被原地改动。你可以让变量指向另一个新字符串,但不能改旧字符串本身。
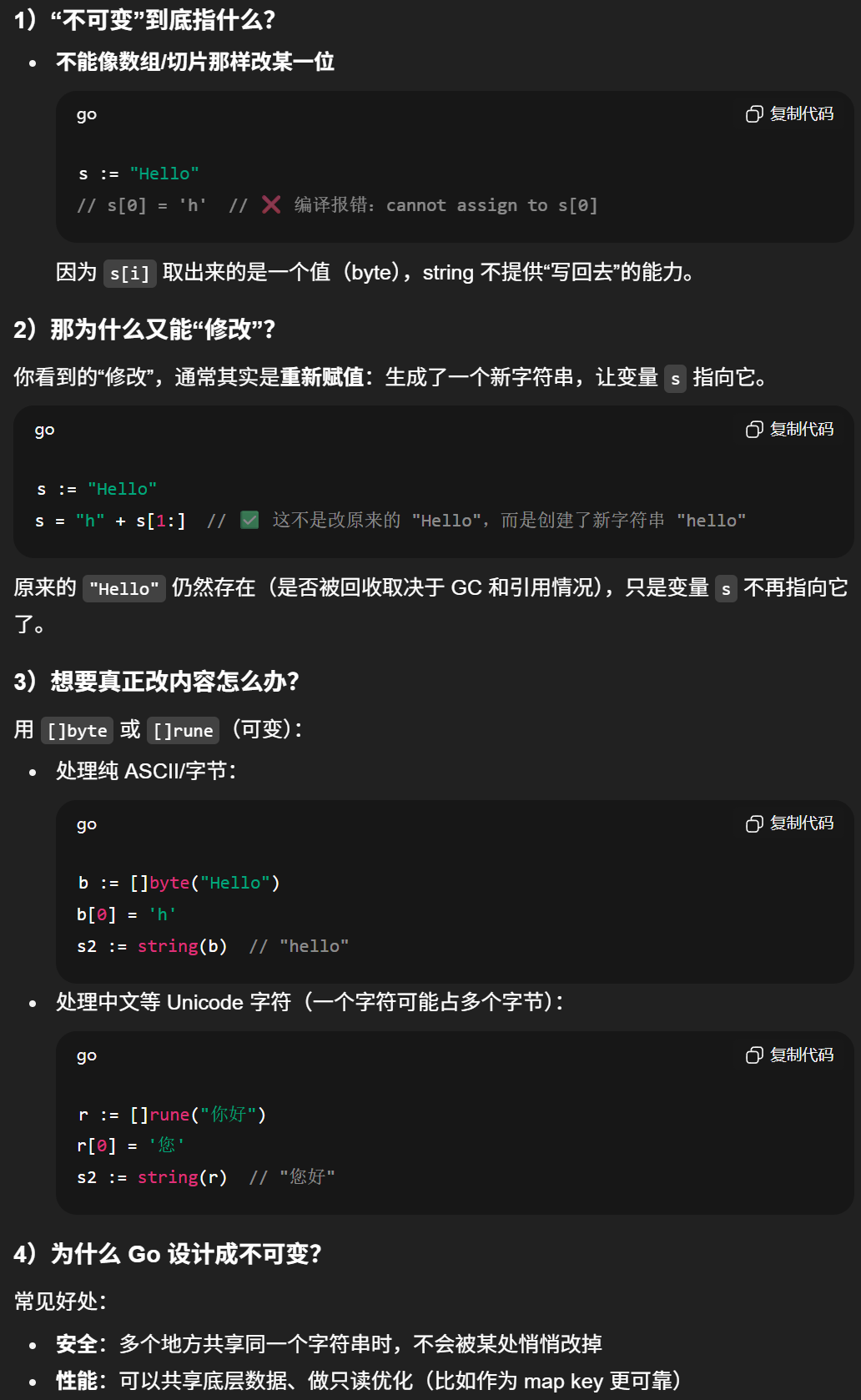
所以字符串的本质是一串字符数组,每个字符在存储时都对应一个整数,也有可能对应多个整数,具体要看字符串的编码方式
可以看个例子:
go
package main
import (
"fmt"
)
func main() {
ss := "Hello"
for _, v := range ss {
fmt.Printf("%d\n", v)
}
}运行结果:
go
72
101
108
108
111可以看到,字符串的位置每个字符对应这个1个整数
string 数据结构
go语言在src/runtime/string.go文件中对string的结构进行了定义
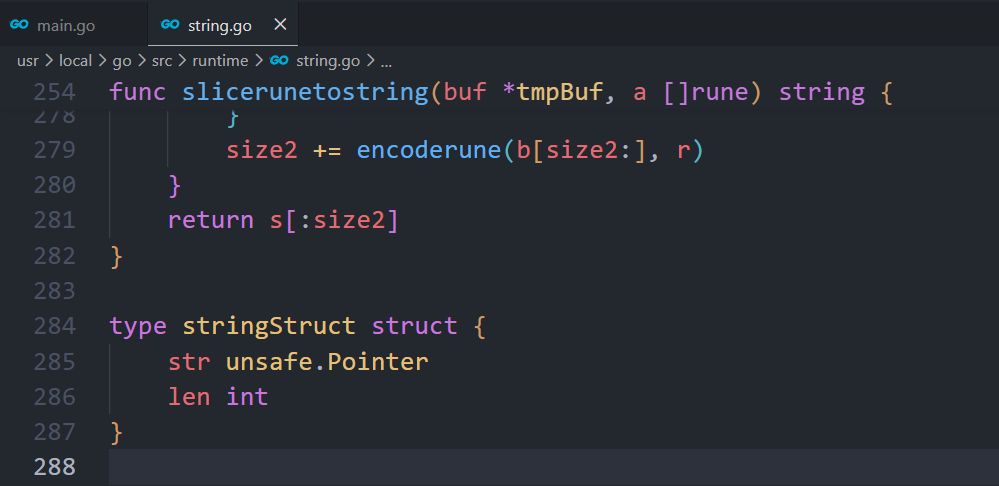
go
type stringStruct struct {
str unsafe.Pointer
len int
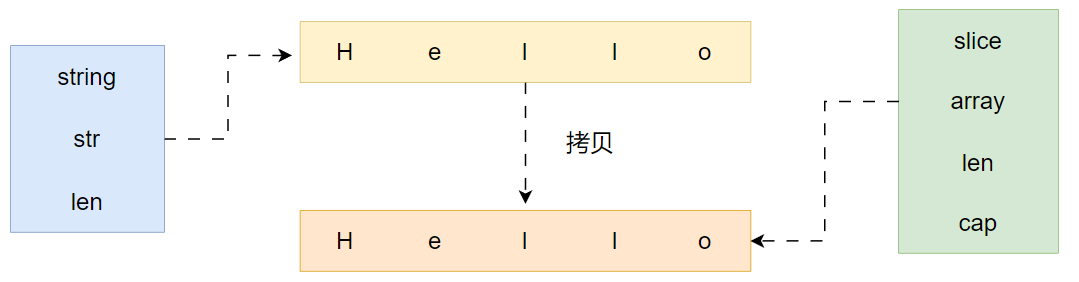
}stringStruct 包含两个字段,str 类型为unsafe.Pointer,还有一个int类型的len字段。
- str指向字符串的首地址
- len表示字符串的长度
定义一个word字符串
go
word := "Hello"其底层结构如下图:
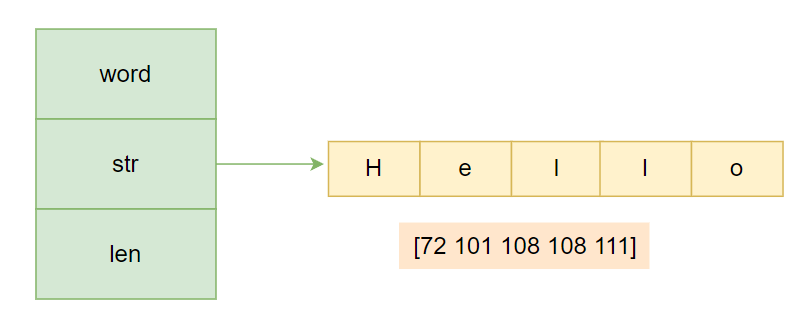
在本例中,len的长度为5,表示word这个字符串占用的字节数,每个字节的值如图中所示。这里需要注意,len字段存储的是实际的字节数,而不是字符数,所以对于非单字节编码的字符,其结果可能多于字符个数
我们知道了在runtime里string的定义,但是我们平常写代码似乎并没有用到stringStruct结构,它是在什么地方被用到呢?
其实stringStruct 是字符串在运行时状态下的表现,当我们创建一个string的时候,可以理解为有两步:
- 根据给定的字符串创建出stringStruct 结构
- 将stringStruct 结构转化为string类型
通过观察字符串的结构定义我们可以发现,其定义中并没有一个表示容量(Cap)的字段,所以意味着字符串类型并不能被扩容,字符串上的写操作包括拼接,追加等都是通过拷贝来实现的。
go
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
// 示例字符串,包含 ASCII 字符和中文字符
str := "Hello, 世界"
// 使用 len 函数获取字节数
byteCount := len(str)
fmt.Printf("字节数: %d\n", byteCount) // 输出: 字节数: 13
// 使用 utf8.RuneCountInString 获取字符数(按 Unicode 字符计数)
charCount := utf8.RuneCountInString(str)
fmt.Printf("字符数: %d\n", charCount) // 输出: 字符数: 9
}
go
root@GoLang:~/proj/goforjob# go run main.go
字节数: 13
字符数: 9
root@GoLang:~/proj/goforjob# 中文就是3个字节,试试就知道了,比如"abc号"就是6个字节,因为"号"占3个字节
UTF-8编码的字符长度由首字节确定,开头是110就是两个字节,开头是1110就是三个字节,依次类推。除首字节外均以"10"开始。
首字节的开头模式决定长度:
0xxxxxxx → 1字节(ASCII,0~127)
110xxxxx → 2字节
1110xxxx → 3字节
11110xxx → 4字节
string与\[\]byte的互相转换
string是只读的,不可以被改变,但是我们在编码过程中,进行重新赋值也是很正常的,既然可以重新赋值,为什么说不能被修改呢,这不是互相矛盾吗?
这里要弄清楚一个概念,字符串修改并不等于重新赋值。我们在开发中所使用的,其实是对字符串的重新赋值
go
str := "Hello"
str = "Golang" // 重新赋值
str[0] = "I" // 修改,不允许一开始str这个变量指向 hello 的内存地址 ,然后新增 golang字符串,重新分配str这个变量指向golang的内存地址。但是hello这个实例其实还在内存,只是不再使用
示例:
go
package main
import "fmt"
func main() {
var ss string
ss = "Hello"
ss[1] = "A"
fmt.Println(ss)
}运行结果:
go
# command-line-arguments
./main.go:8:2: cannot assign to ss[1] (neither addressable nor a map index expression)程序会报错,提示string是不可修改的。
这样一分析,那么可不可以将字符串转化为\[\]byte切片,然后通过下标修改切片,再转化回字符串呢,答案是可行的。
相互转化的语法如下例所示:
go
package main
import "fmt"
func main() {
var ss string
ss = "Hello"
strByte := []byte(ss)
strByte[1] = 65
fmt.Println(string(strByte))
}运行结果:
go
HAlloHello变成了HAllo,好像达到了我们的目的。这里需要注意,虽然这种方式看似可行,修改了字符串Hello,但其实并不是我们所见的这样。最终得到的只是ss字符串的一个拷贝,原字符串并没有变化。
go
package main
import (
"fmt"
"unsafe"
)
func main() {
b := []byte{'H', 'e', 'l', 'l', 'o'}
// &b 取切片变量 b 的地址(注意:这是"切片头"这三个字段所在的地址,不是底层数组地址)
// unsafe.Pointer(&b) 把这个地址转成"无类型指针",方便做各种不安全转换
// (*string) 把它当成 "指向 string 的指针"
// *(*string)(...) 解引用,拿到一个 string 值
s := *(*string)(unsafe.Pointer(&b)) // 强制将 []byte 转换为 string
fmt.Println(s)
// b[0] = 'h' 把底层数组第一个字节从 'H' 改成 'h'。
// 因为 s 的 Data 也指向同一块底层数组,所以此时 s 实际"看到"的内容也变了。
b[0] = 'h'
fmt.Println(s)
}
string与\[\]byte的转化原理
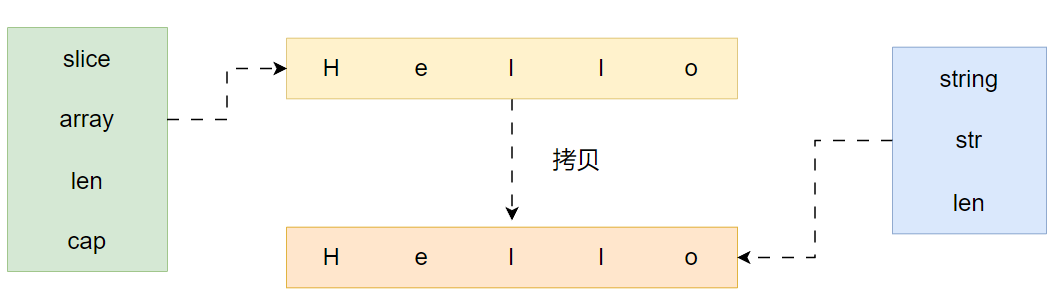
string与\[\]byte的转化其实会发生一次内存拷贝,并申请一块新的切片内存空间
byte切片转化为string,大致过程分为3步:
- 转成 string 时申请的是字符串的数据区(一段 bytes),构建内存地址为addr,长度为len
- 构建 string对象,指针地址为addr,len字段赋值为len(string.str = addr; string.len = len;)
- 将原切片中数据拷贝到新申请的string中指针指向的内存空间
string转化为byte数组同样简单,大致分为2步:
- 分配一块新的 \[\]byte 底层数组(大小 = len(s)),并建立切片头(Data/Len/Cap)指向它
- 把 string 底层数据拷贝到这块新数组里(copy/memmove)
\[\]byte转化为string是否一定会发生内存拷贝
很多场景中会用到\[\]byte转化为string,但是并不是每一次转化,都会像上述过程一样,发生一次内存拷贝。在什么情况下不会发生拷贝呢?
转化为的字符串被用于临时场景
举几个例子:
- 字符串比较: string(ss) == "Hello"
- 字符串拼接:"Hello" + sting(ss) + "world"
- 用作查找,比如map的key,val := mapstring(ss)
这几种情况下,\[\]byte转化成的字符串并不会被后面程序用到,只是在当前场景下被临时用到,所以并不会拷贝内存,而是直接返回一个 string,这个 string 的指针 (string.str) 指向切片的内存。
字符串声明
go语言中以字面量来声明字符串有两种方式,双引号和反引号:
go
str1 := "Hello World"
str2 := `Hello
Golang`使用双引号声明的字符串和其他语言中的字符串没有太多的区别,但是这种使用双引号的字符串只能用于单行字符串的初始化 ,当字符串里使用到一些特殊字符,比如双引号,换行符等等需要用 \ 进行转义。但是,反引号声明的字符串没有这些限制,字符串内容即为字符串里的原始内容,所以一般用反引号来声明的比较复杂的字符串,比如json串。
go
json := `{"hello": "golang", "name": ["zhangsan"]}`为什么这么设计
可能大家都会考虑到,为什么一个普通的字符串要设计这么复杂,还需要使用指针。暂时没找到官方文档的说明,个人猜想,当遇到一个非常长的字符串时,这样做使得 string 变得非常轻量,可以很方便的进行传递而不用担心内存拷贝 。虽然在 Go 中,不管是引用类型还是值类型参数传递都是值传递 。但指针明显比值传递更节省内存。
go
package main
import (
"fmt"
)
func main() {
arr := make([]int, 0)
arr = append(arr, 1, 2, 3)
fmt.Printf("outer1: %p, %p\n", &arr, &arr[0])
modify(arr)
fmt.Println(arr) // 10, 2, 3
}
func modify(arr []int) {
fmt.Printf("inner1: %p, %p\n", &arr, &arr[0])
arr[0] = 10
fmt.Printf("inner2: %p, %p\n", &arr, &arr[0])
}
go
root@GoLang:~/proj/goforjob# go run main.go
outer1: 0xc000010048, 0xc0000180f0
inner1: 0xc000100000, 0xc0000180f0
inner2: 0xc000100000, 0xc0000180f0
[10 2 3]
root@GoLang:~/proj/goforjob# 因为slice是引用类型,指向的是同一个数组。
可以看到,在函数内外,arr本身的地址&arr变了,但是两个指针指向的底层数据,也就是&arr0数组首元素的地址是不变的。
所以在函数内部的修改可以影响到函数外部,这个很容易理解。
再来看另外一个稍微复杂的例子,函数内部使用append。这个会稍微不一样。
go
package main
import (
"fmt"
)
func main() {
arr := make([]int, 0)
//arr := make([]int, 0, 5)
arr = append(arr, 1, 2, 3)
fmt.Printf("outer1: %p, %p, len:%d, capacity:%d\n", &arr, &arr[0], len(arr), cap(arr))
//modify(arr)
appendSlice(arr)
fmt.Printf("outer2: %p, %p, len:%d, capacity:%d\n", &arr, &arr[0], len(arr), cap(arr))
fmt.Println(arr)
}
func appendSlice(arr []int) {
fmt.Printf("inner1: %p, %p, len:%d, capacity:%d\n", &arr, &arr[0], len(arr), cap(arr))
//modify(arr)
arr = append(arr, 1)
fmt.Printf("inner2: %p, %p, len:%d, capacity:%d\n", &arr, &arr[0], len(arr), cap(arr))
//modify(arr) //&arr[0]的地址是否相等,取决于初始化slice的时候的capacity是否足够
}这个问题就相对复杂的多了。
分两种情况:
make slice的时候没有分配足够的capacity
arr := make(\[\]int, 0) 像这种写法,那么输出就是:
go
root@GoLang:~/proj/goforjob# go run main.go
outer1: 0xc00009c030, 0xc0000a0000, len:3, capacity:3
inner1: 0xc00009c048, 0xc0000a0000, len:3, capacity:3
inner2: 0xc00009c048, 0xc0000a4030, len:4, capacity:6
outer2: 0xc00009c030, 0xc0000a0000, len:3, capacity:3
[1 2 3]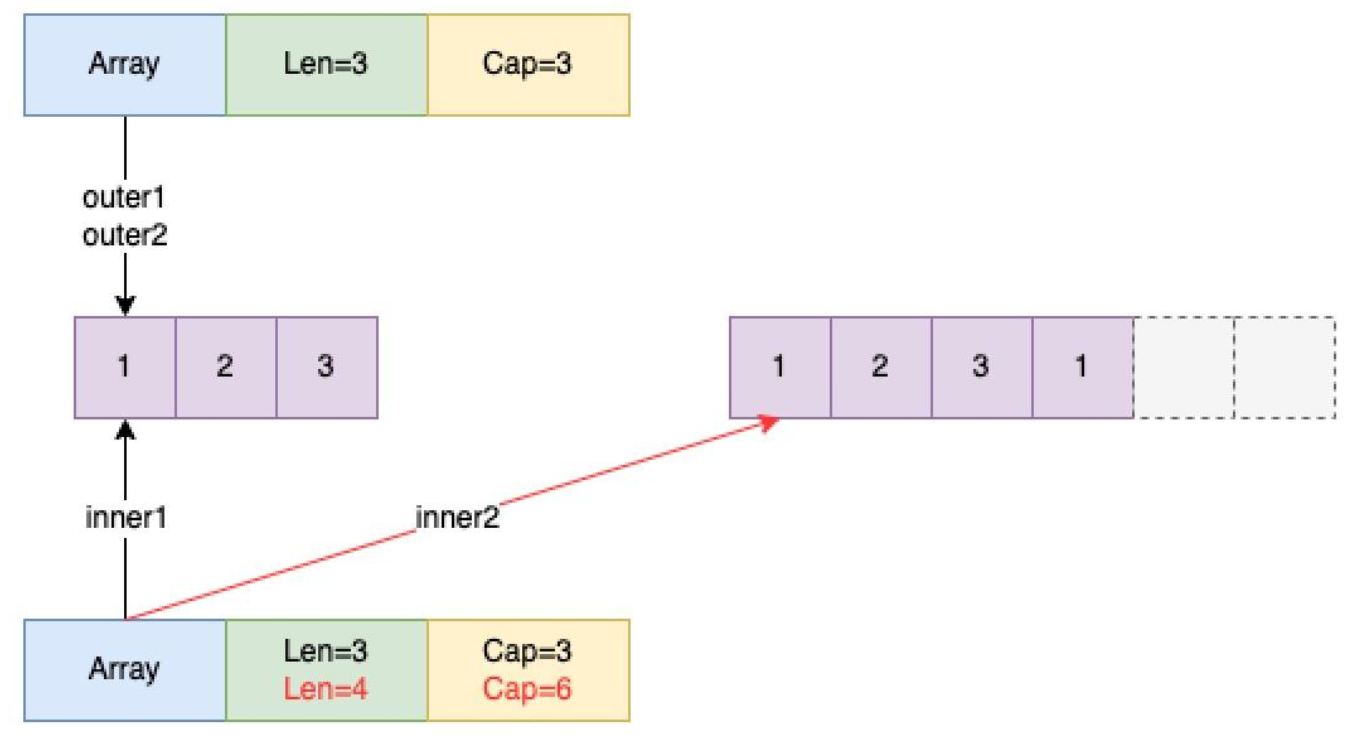
- outer1: 外部传入一个slice,引用类型,值传递。
- inner1: 由于是值传递,所以arr的地址&arr变了,但是两个arr指向的底层数组首元素&arr0,也就是array unsafe.Pointer。
- inner2: 在内部调用append后,由于cap容量不够,所以扩容,cap=cap*2,重新在新的地址空间分配底层数组,所以数组首元素的地址改变了。
- 回到函数外部,外部的slice指向的底层数组为原数组,内部的修改不影响原数组。
make slice的时候分配足够的capacity
arr := make(\[\]int, 0, 5)
go
package main
import (
"fmt"
)
func main() {
// arr := make([]int, 0)
arr := make([]int, 0, 5)
arr = append(arr, 1, 2, 3)
fmt.Printf("outer1: %p, %p, len:%d, capacity:%d\n", &arr, &arr[0], len(arr), cap(arr))
//modify(arr)
appendSlice(arr)
fmt.Printf("outer2: %p, %p, len:%d, capacity:%d\n", &arr, &arr[0], len(arr), cap(arr))
fmt.Println(arr)
}
func appendSlice(arr []int) {
fmt.Printf("inner1: %p, %p, len:%d, capacity:%d\n", &arr, &arr[0], len(arr), cap(arr))
//modify(arr)
arr = append(arr, 1)
fmt.Printf("inner2: %p, %p, len:%d, capacity:%d\n", &arr, &arr[0], len(arr), cap(arr))
//modify(arr) //&arr[0]的地址是否相等,取决于初始化slice的时候的capacity是否足够
}像这种写法,那么输出就是:
go
root@GoLang:~/proj/goforjob# go run main.go
outer1: 0xc000010048, 0xc0000240c0, len:3, capacity:5
inner1: 0xc000010060, 0xc0000240c0, len:3, capacity:5
inner2: 0xc000010060, 0xc0000240c0, len:4, capacity:5
outer2: 0xc000010048, 0xc0000240c0, len:3, capacity:5
[1 2 3]虽然函数内部append的结果同样不影响外部的输出,但是原理却不一样。
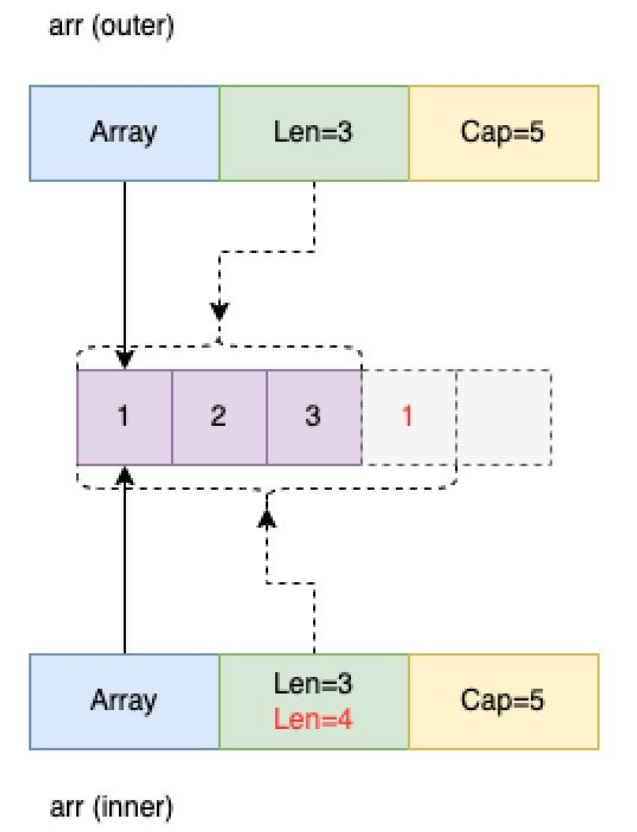
不同点:
- 在内部调用append的时候,由于cap 容量足够,所以不需要扩容,在原地址空间增加一个元素,底层数组的首元素地址相同。
- 回到函数外部,打印出来还是1 2 3,是因为外层的len是3,所以只能打印3个元素,实际上第四个元素的地址上已经有数据了。只不过因为len为3,所以我们无法看到第四个元素。

字符串拼接
go语言中字符串是不可改变的,所以我们在对字符串进行拼接的时候会有内存的拷贝,存在性能损耗。常见的字符串拼接有以下几种方式:
- +操作符
适合少量拼接、代码最直观
go
s := "a" + "b"
s += "c"- fmt.Sprintf
适合需要格式化(插变量、控制格式),但性能相对一般
go
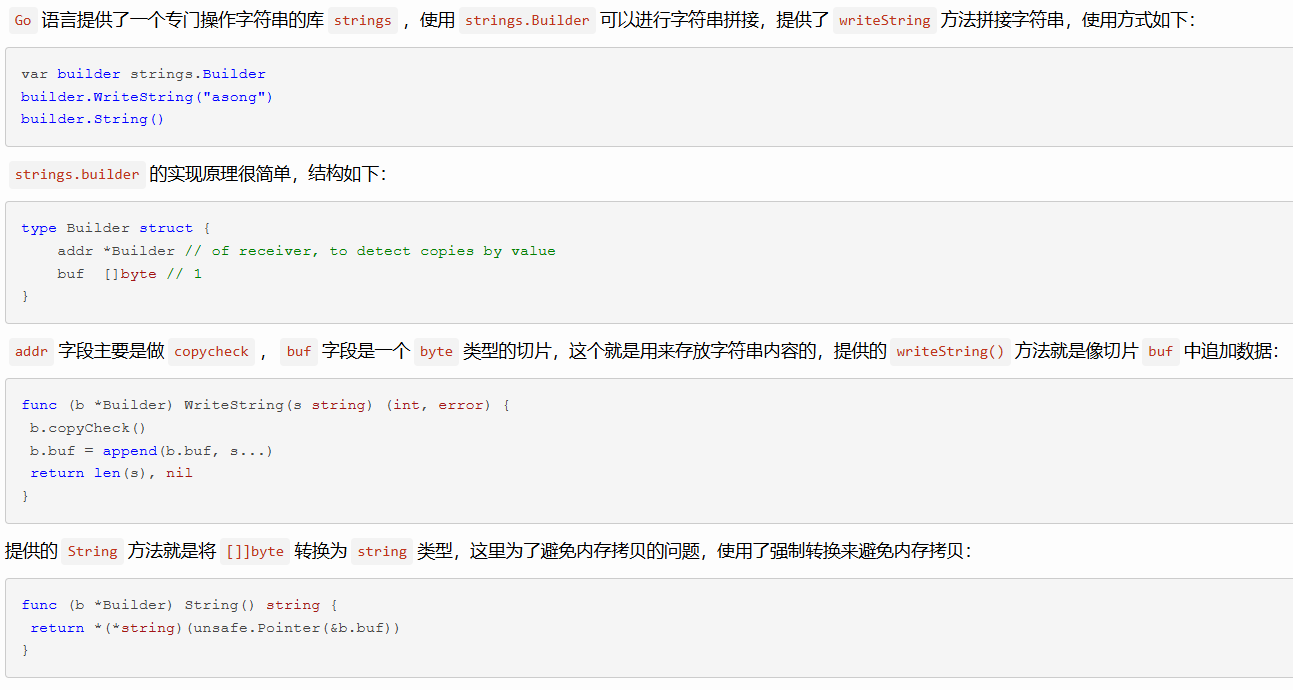
s := fmt.Sprintf("%s-%d", "id", 10)- strings.Builder(推荐:循环/大量拼接)
专门为拼接设计,性能好,写法也简单
go
var b strings.Builder
b.WriteString("a")
b.WriteString("b")
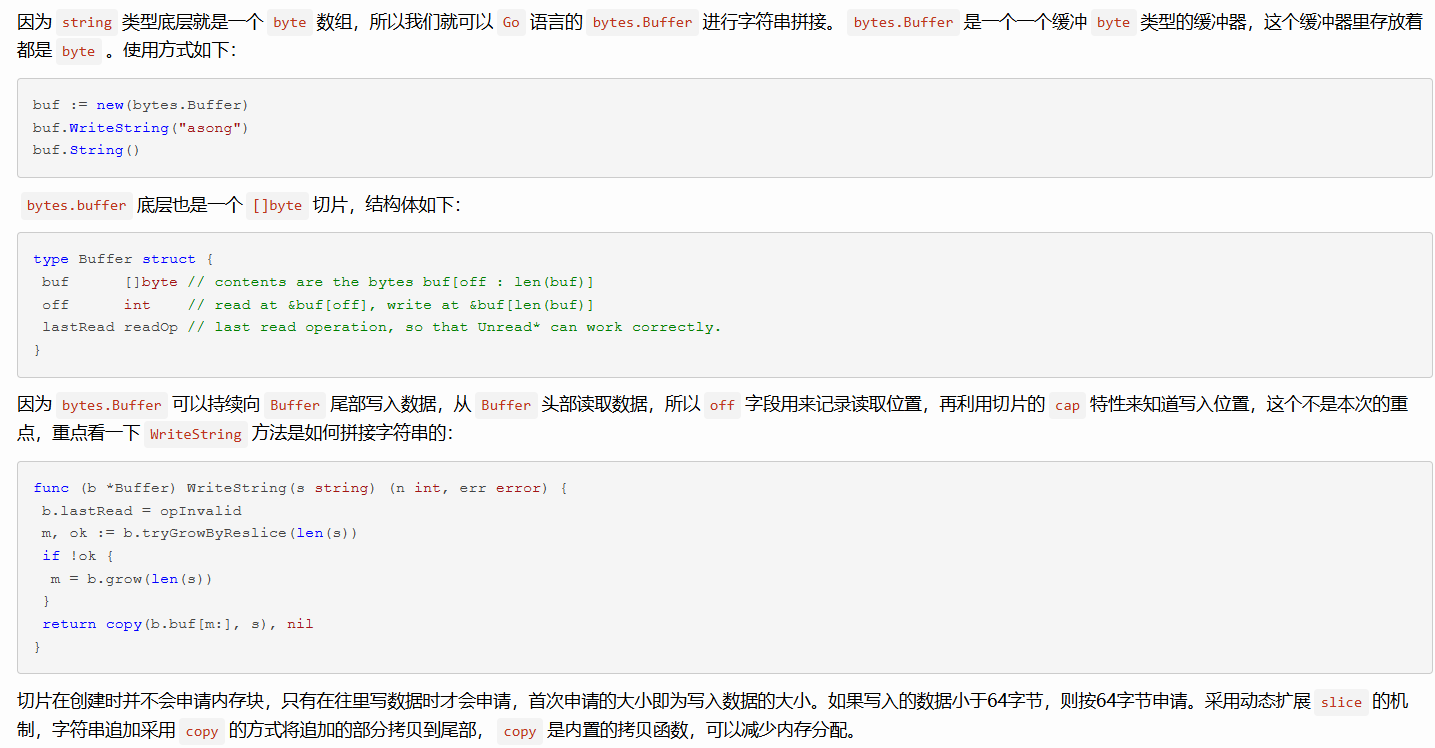
s := b.String()- bytes.Buffer
类似 Builder,更偏向处理 \[\]byte,也常用于拼接
WriteString 只是把数据写进 buf 里,此时结果还"在 buf 里面"
buf.String() 才是"取最终拼接结果"的一步
go
var buf bytes.Buffer
buf.WriteString("a")
buf.WriteString("b")
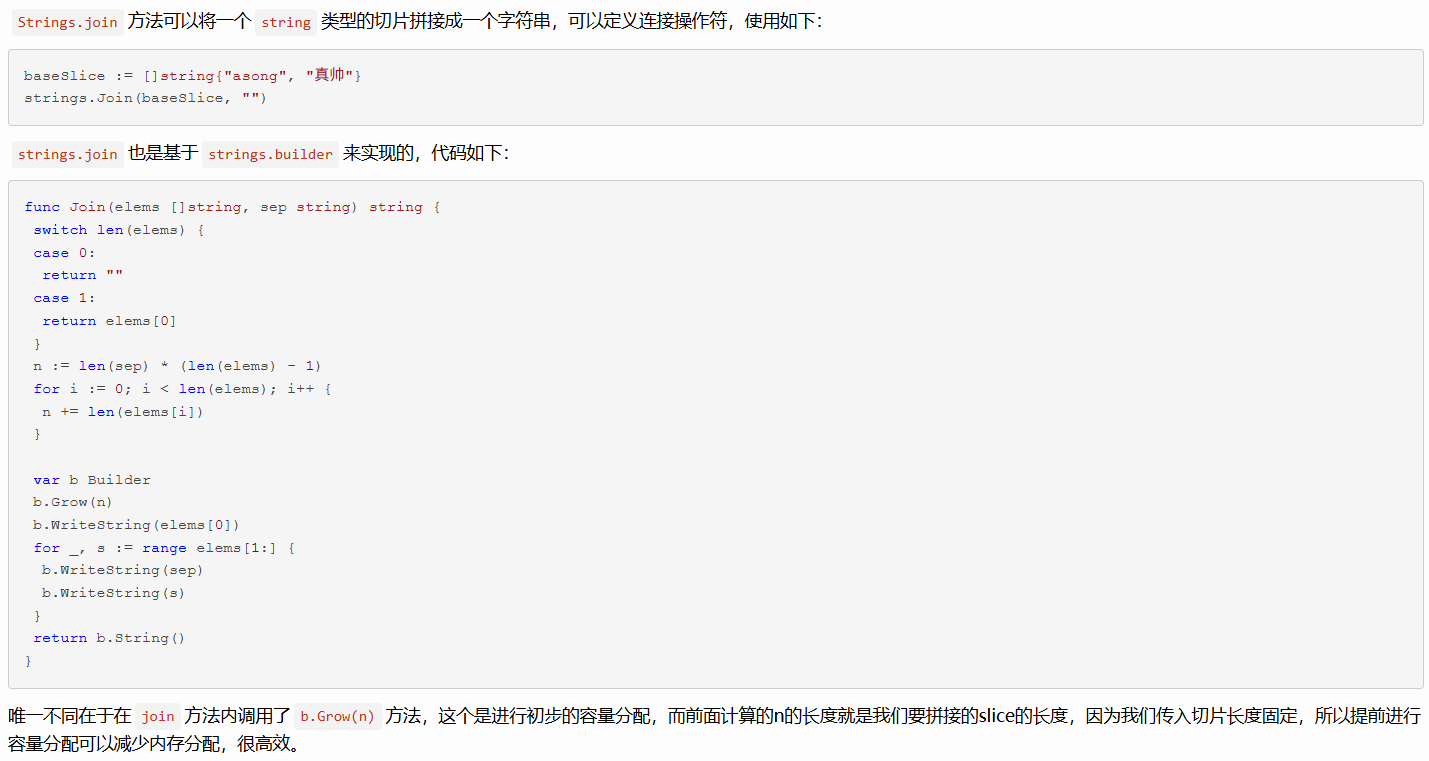
s := buf.String()- strings.Join
已经有 \[\]string 时最方便,通常也很高效
go
package main
import (
"fmt"
"strings"
)
func main() {
parts := []string{"a", "b", "c"}
// 用空分隔符把数组里的字符串连起来
result := strings.Join(parts, "")
fmt.Println(result) // 输出: abc
}- append 拼 \[\]byte 再转 string
适合你本来就在处理字节、或拼接的是字节数据
go
var b []byte
b = append(b, "a"...)
b = append(b, "b"...)
s := string(b)- copy 预分配后手动拷贝(更底层)
极致性能场景才用,代码更复杂(不算最常用,但确实存在)
性能测试
采用testing包下benchmark测试其性能
测试文件必须以:*_test.go 结尾
例如:string_test.go
测试代码和被测代码通常放在同一个包目录下
go
package main
import (
"bytes"
"fmt"
"strings"
"testing"
)
var loremIpsum = `
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Maecenas non odio eget quam gravida laoreet vitae id est. Cras sit amet porta dui. Pellentesque at pulvinar ante. Pellentesque leo dolor, tristique a diam vel, posuere rhoncus ex. Mauris gravida, orci eu molestie pharetra, mi nibh bibendum arcu, in bibendum augue neque ac nulla. Phasellus consectetur turpis et neque tincidunt molestie. Vestibulum diam quam, sodales quis nulla eget, volutpat euismod mauris.
`
var strSlice = make([]string, LIMIT)
const LIMIT = 1000
func init() {
for i := 0; i < LIMIT; i++ {
// 这里每个 strSlice[i] 指向的是 同一个字符串值(同一份底层只读数据),不是拷贝 1000 份内容
strSlice[i] = loremIpsum
}
}
func BenchmarkKConcatenationOperator(b *testing.B) {
// b.N 会由 Go 测试框架自动调整到合适的次数,以保证统计稳定。
for i := 0; i < b.N; i++ {
var q string
for _, v := range strSlice {
q = q + v
}
}
b.ReportAllocs()
}
func BenchmarkFmtSprint(b *testing.B) {
for i := 0; i < b.N; i++ {
var q string
for _, v := range strSlice {
q = fmt.Sprint(q, v)
}
}
b.ReportAllocs()
}
func BenchmarkBytesBuffer(b *testing.B) {
for i := 0; i < b.N; i++ {
var q bytes.Buffer
q.Grow(len(loremIpsum) * len(strSlice))
for _, v := range strSlice {
q.WriteString(v)
}
_ = q.String()
}
b.ReportAllocs()
}
func BenchmarkStringBuilder(b *testing.B) {
for i := 0; i < b.N; i++ {
var q strings.Builder
q.Grow(len(loremIpsum) * len(strSlice))
for _, v := range strSlice {
q.WriteString(v)
}
_ = q.String()
}
b.ReportAllocs()
}
func BenchmarkAppend(b *testing.B) {
for i := 0; i < b.N; i++ {
// var q = make([]byte, 0, len(loremIpsum)*len(strSlice))
var q []byte
for _, v := range strSlice {
q = append(q, v...)
}
_ = string(q)
}
b.ReportAllocs()
}
func BenchmarkJoin(b *testing.B) {
for i := 0; i < b.N; i++ {
var q string
q = strings.Join(strSlice, "")
_ = q
}
b.ReportAllocs()
}运行结果:
bash
root@GoLang:~/proj/goforjob# go test -bench=. -benchmem
goos: linux
goarch: amd64
pkg: test
cpu: Intel(R) Xeon(R) Platinum
BenchmarkKConcatenationOperator-2 4 263736315 ns/op 238062240 B/op 1002 allocs/op
BenchmarkFmtSprint-2 2 540483366 ns/op 488018376 B/op 4278 allocs/op
BenchmarkBytesBuffer-2 1057 1182670 ns/op 950272 B/op 2 allocs/op
BenchmarkStringBuilder-2 2941 367078 ns/op 475136 B/op 1 allocs/op
BenchmarkAppend-2 339 3531836 ns/op 3011168 B/op 24 allocs/op
BenchmarkJoin-2 3049 340660 ns/op 475136 B/op 1 allocs/op
PASS
ok test 9.184s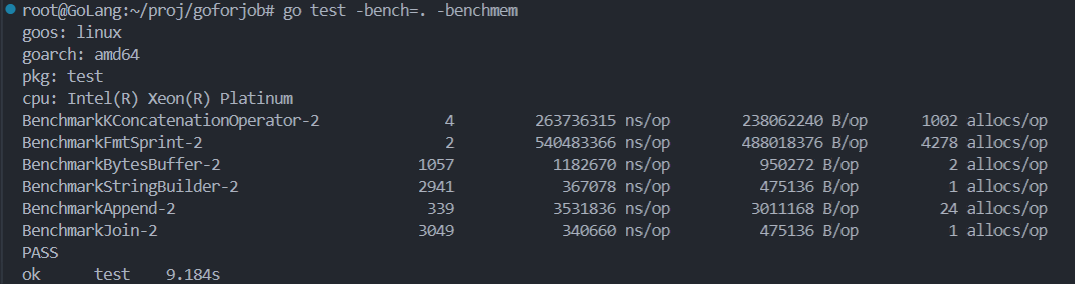
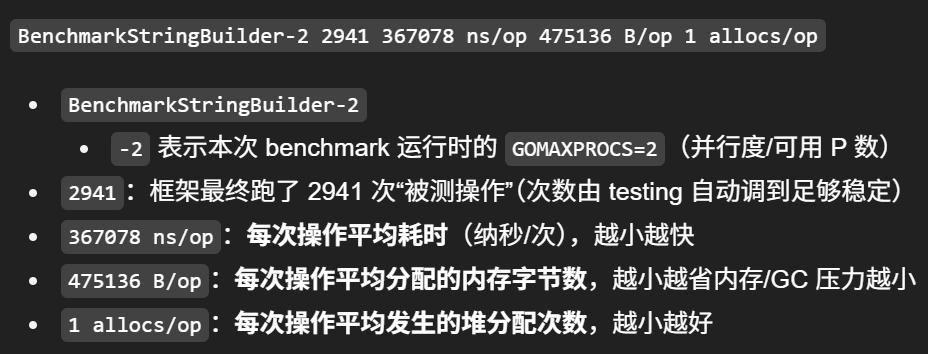
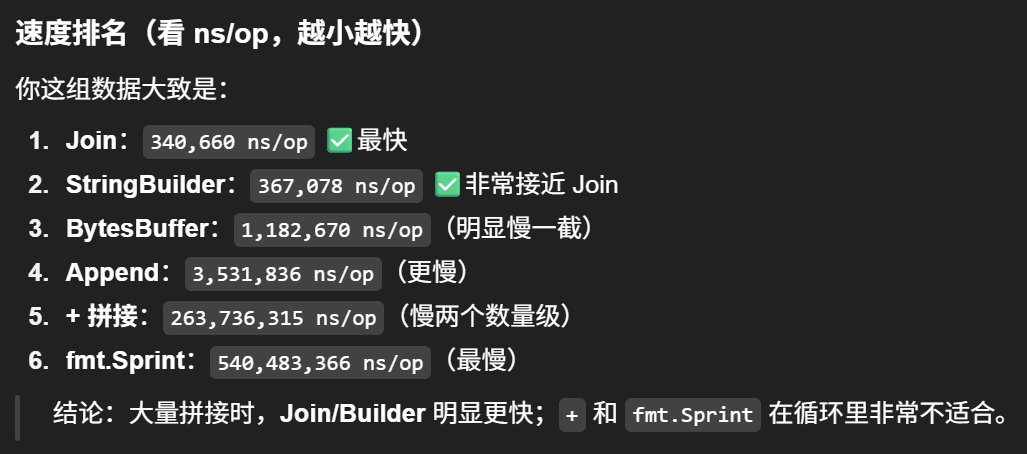



可以看到,采用sprintf拼接字符串性能是最差的,性能最好的方式是string.Builder和string.Join
所以平时代码中,我们在拼接字符串的时候,最好采用后面几种方式,不要直接采用+或者sprintf,sprintf一般用于字符串的格式化而不用于拼接。
性能原理分析

最终做一下总结:
性能对比:strings.builder ≈ strings.join > bytes.buffer > append > "+" > fmt.sprintf
如果进行少量的字符串拼接时,直接使用 + 操作符是最方便也算是性能最高的,就无需使用 strings.builder
至于为什么拷贝次数少,是因为使用的第一个\[\]byte在make的时候先预估最后拼接的长度,后面做拼接则直接将需要拼接的内容写入就行,实在cap不够了才扩容然后发生拷贝。
字符串拼接的6种方式及原理
原生拼接方式"+"

字符串格式化函数fmt.Sprintf

Strings.builder
bytes.Buffer

strings.join
切片append

之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!