****论文题目:****Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks (一种基于注意的置换不变神经网络框架)
会议:ICML2019
****摘要:****许多机器学习任务,如多实例学习、三维形状识别和少量图像分类,都是在实例集上定义的。由于这些问题的解不依赖于集合中元素的顺序,因此用于解决这些问题的模型应该是排列不变的。我们提出了一个基于注意力的神经网络模块,Set Transformer,专门用于模拟输入集中元素之间的相互作用。该模型由一个编码器和一个解码器组成,两者都依赖于注意机制。为了降低计算复杂度,我们从稀疏高斯过程文献中引入了一种受诱导点方法启发的注意力方案。它将自注意力机制的计算时间从集合中元素数量的二次元减少到线性元。我们证明了我们的模型在理论上是有吸引力的,我们在一系列任务上对它进行了评估,与最近的集结构数据方法相比,显示了更高的性能。
Set Transformer:用注意力机制处理集合数据的深度学习框架
引言
在深度学习的众多应用中,我们经常需要处理集合结构的数据------一组无序的元素。想象一下这些场景:
- 从一堆照片中判断有多少个不同的人物
- 分析一个3D物体的点云表示
- 在少样本学习中,从几个样本中学习新类别
这些任务有一个共同特点:输入是一个集合,元素的顺序不重要 。如果我们打乱这些元素的顺序,答案应该保持不变。这种性质被称为排列不变性(Permutation Invariance)。
然而,传统的深度学习模型(如CNN、RNN)都对输入顺序敏感,无法直接应用于集合数据。2019年ICML上发表的Set Transformer论文提出了一个优雅的解决方案,利用注意力机制来处理集合数据,在多个任务上取得了显著的性能提升。
本文将深入解析这篇论文的核心思想、技术创新和实验结果。
问题背景:集合数据处理的挑战
什么是集合数据?
集合(Set)是数学中的基本概念,它的定义特征是:
- 无序性:{1, 2, 3} 和 {3, 1, 2} 是同一个集合
- 元素唯一性:每个元素只出现一次
在机器学习中,很多任务天然地涉及集合结构:
多实例学习(Multiple Instance Learning):给定一包图片(一个集合),判断这包图片的标签。例如,医疗图像分析中,一个病人可能有多张不同角度的扫描图,我们需要综合这些图片做出诊断。
3D形状识别:3D物体通常表示为点云------三维空间中的一组点。这些点没有固定顺序,是一个典型的集合。
少样本学习:给定少量样本(支持集),学习识别新类别。支持集本质上是一个图片的集合。
现有方法:Set Pooling
在Set Transformer之前,处理集合数据的主流方法是Set Pooling架构,由Zaheer等人在2017年提出(DeepSets)。其基本思想非常简单:
f({x₁, x₂, ..., xₙ}) = ρ(pool({φ(x₁), φ(x₂), ..., φ(xₙ)}))具体步骤:
- 独立编码:用一个神经网络φ独立处理每个元素
- 池化聚合:用一个排列不变的操作(如mean、max、sum)聚合所有特征
- 后处理:用另一个神经网络ρ处理聚合后的特征得到最终输出
这个方法的优点是:
- ✅ 简单高效
- ✅ 满足排列不变性
- ✅ 理论上是通用近似器(可以近似任何排列不变函数)
但它有一个关键缺陷 :由于每个元素是独立编码的,模型无法有效地学习元素之间的交互关系。
为什么元素间交互很重要?
让我们通过一个具体例子来理解:聚类问题。
假设我们要学习一个神经网络,输入是2D平面上的一组点,输出是聚类中心。这个任务的难点在于:
- 每个点应该被分配到某个聚类中心
- 不同的聚类中心需要"explaining away"------它们不应该解释重叠的点集
- 聚类中心的位置应该依赖于点的分布,而不是固定的空间划分
如图所示,rFF+Pooling方法由于无法建模点之间的关系,聚类结果往往不理想。而Set Transformer能够通过注意力机制让不同的点"交流"信息,从而学习到更好的聚类。
论文作者在实验中发现,即使Set Pooling方法理论上能够近似任何函数,但在实践中它们容易欠拟合------难以学习到复杂的元素间交互模式。
Set Transformer的核心思想
Set Transformer的核心思想可以用一句话概括:用注意力机制让集合中的元素相互"交流"信息。
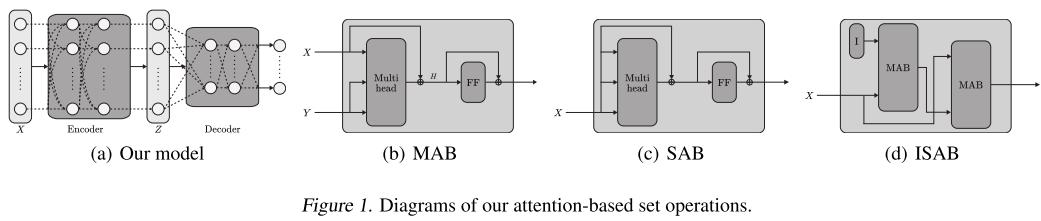
整体架构
Set Transformer采用经典的编码器-解码器结构:
-
编码器(Encoder):处理输入集合,输出特征表示
- 由多个注意力层堆叠而成
- 每一层都是排列等变的(输入顺序改变,输出顺序也相应改变)
-
解码器(Decoder):聚合特征,产生最终输出
- 使用基于注意力的池化操作
- 可以产生单个输出或多个相关输出
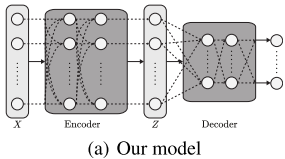
整个模型保持排列不变性,同时能够建模元素间的复杂交互。
技术创新详解
创新1:Multihead Attention Block (MAB)
MAB是Set Transformer的基础构建块,它改编自Transformer中的多头注意力机制。
给定两个集合的表示 X ∈ ℝⁿˣᵈ 和 Y ∈ ℝⁿˣᵈ,MAB定义为:
MAB(X, Y) = LayerNorm(H + rFF(H))
其中 H = LayerNorm(X + Multihead(X, Y, Y))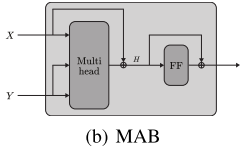
这里的关键点:
- Multihead注意力:允许模型从多个角度关注不同的特征
- 残差连接:帮助梯度流动,使模型更容易训练
- Layer Normalization:稳定训练过程
- 前馈网络rFF:进一步处理特征
创新2:Set Attention Block (SAB)
SAB是将MAB应用于自注意力的特殊情况:
SAB(X) = MAB(X, X)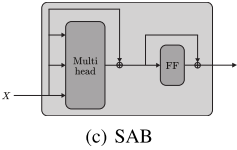
SAB让集合中的每个元素都能关注其他所有元素,从而捕获元素间的成对交互。通过堆叠多个SAB,模型可以学习到更高阶的交互模式。
但是 ,SAB有一个致命问题:计算复杂度是O(n²),其中n是集合大小。当集合很大时(比如点云有5000个点),这会变得非常昂贵。
创新3:Induced Set Attention Block (ISAB) ⭐
这是论文最重要的技术贡献!ISAB通过引入inducing points巧妙地解决了复杂度问题。
核心思想:不让所有元素直接相互注意,而是通过一组可学习的"中介"(inducing points)间接交互。
具体来说,ISAB引入m个d维向量 I ∈ ℝᵐˣᵈ 作为inducing points,然后:
ISAB_m(X) = MAB(X, H)
其中 H = MAB(I, X)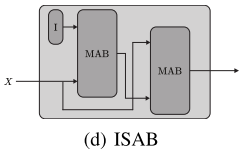
工作流程:
- Inducing points I 首先"总结"输入集合X的信息,得到H
- 输入集合X再通过关注这些总结后的信息H来更新自己
这样,复杂度从O(n²)降低到O(nm),其中m是一个小的固定超参数(如16或32)。
类比理解:就像开会时,不是所有人互相讨论(O(n²)次对话),而是先有几个代表总结大家的意见(m个代表),然后大家根据这些代表的总结更新自己的看法(O(nm)次对话)。
论文实验表明,即使只使用16个inducing points,ISAB的性能也能接近甚至超过完整的SAB!
创新4:Pooling by Multihead Attention (PMA)
传统的set pooling使用固定的操作(mean、max、sum),而PMA提出用可学习的注意力来聚合特征。
给定编码后的特征Z ∈ ℝⁿˣᵈ,PMA使用k个可学习的"seed vectors" S ∈ ℝᵏˣᵈ:
PMA_k(Z) = MAB(S, rFF(Z))关键优势:
- 模型可以学习关注哪些元素更重要
- 对于需要多个输出的任务(如k个聚类中心),可以自然地产生k个相关的输出
- 输出之间可以通过后续的SAB进一步交互,建模"explaining away"等模式
实验证据:在聚类任务中,rFF+PMA相比rFF+Pooling在CIFAR-100上的ARI从0.5593提升到0.7612,而SAB+PMA进一步提升到0.9015!
理论性质
Set Transformer具有优雅的理论性质:
性质1:排列不变性
命题1:Set Transformer是排列不变的。
这是因为:
- 编码器中的SAB和ISAB都是排列等变的
- 解码器中的PMA是排列不变的
- 两者组合保持排列不变性
性质2:通用近似性
命题2:Set Transformer是排列不变函数的通用近似器。
也就是说,给定足够的参数,Set Transformer理论上可以近似任何排列不变函数。
证明的关键思想:
- PMA可以表达sum pooling(引理3)
- rFF(sum(rFF(·))) 已被证明是通用近似器
- 因此Set Transformer也是通用近似器
这意味着Set Transformer不仅在实践中表现好,而且有坚实的理论基础。
实验结果
论文在5个不同类型的任务上评估了Set Transformer,展示了其广泛的适用性和优越性能。
实验1:最大值回归(玩具问题)
任务:给定一个实数集合{x₁, ..., xₙ},预测最大值max(x₁, ..., xₙ)。
目的:验证注意力池化相比固定池化的优势。
结果:
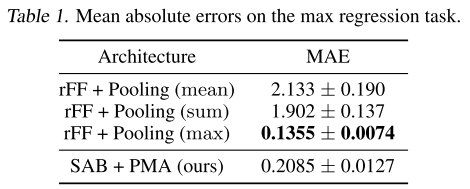
分析:
- max pooling能完美解决这个问题(学习恒等映射即可)
- mean和sum pooling完全失败
- 关键发现:SAB+PMA接近max pooling的性能!这说明注意力机制能够学会"找到并关注最大元素"
这个简单实验有力地证明了注意力池化的灵活性和学习能力。
实验2:唯一字符计数
任务:给定一组手写字符图片(来自Omniglot数据集),判断其中有多少个不同的字符。

挑战:模型需要理解哪些图片属于同一个字符类别,这需要建模图片之间的相似性关系。
结果:
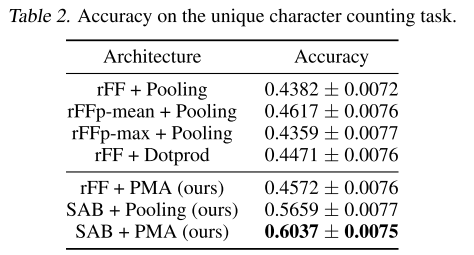
关键发现:
- SAB(编码器中的注意力)带来显著提升:从46%提升到56%
- 同时使用SAB和PMA达到最佳性能:60.37%
- 单独使用PMA(rFF+PMA)提升有限,说明编码器中的注意力更为关键
ISAB的表现:
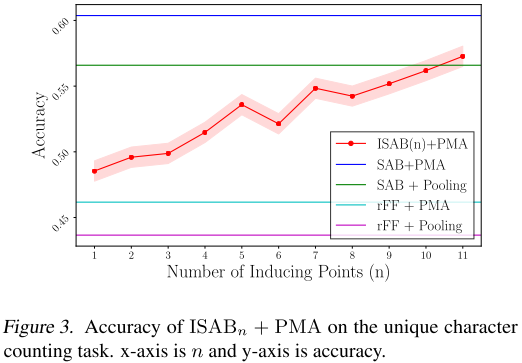
论文还测试了不同数量inducing points的影响:
- 即使只有1个inducing point,ISAB₁+PMA的准确率(约49%)也超过了rFF+Pooling
- 性能随inducing points数量增加而提升
- 在11个inducing points时接近SAB+PMA的性能
这证明了ISAB在保持低复杂度的同时能够有效建模元素交互。
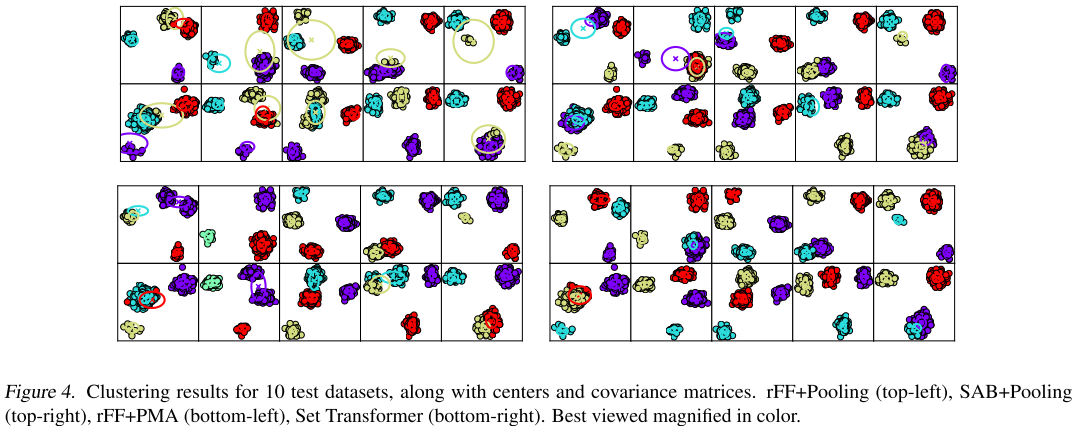
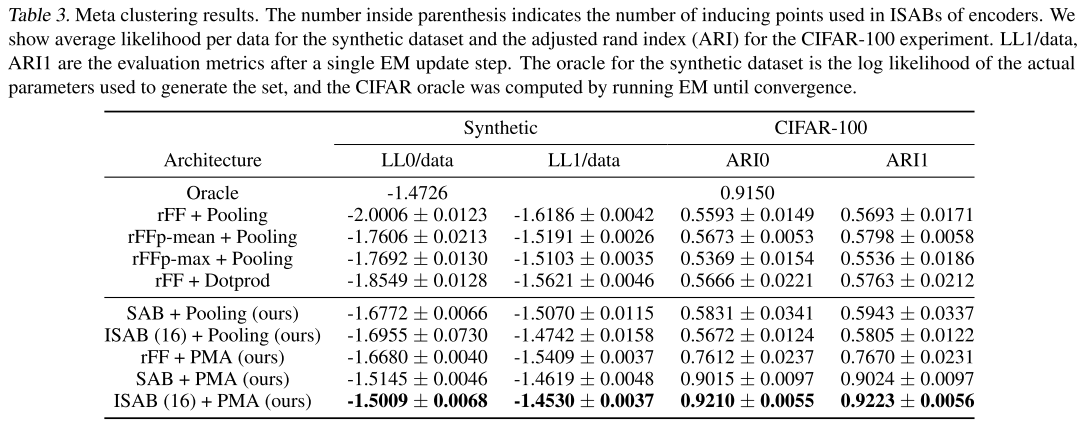
实验3:混合高斯分布的聚类
这是论文中最重要和最复杂的实验之一,充分展示了Set Transformer在需要复杂交互建模的任务上的优势。
任务:学习一个"元算法",输入一组点,直接输出聚类参数(均值、方差、混合系数),而不需要运行迭代算法(如EM)。
为什么这个任务困难?
- 传统方法需要迭代优化(如EM算法)
- 聚类中心之间需要"explaining away"------每个中心应该解释不重叠的点集
- 这需要建模点之间以及聚类中心之间的复杂关系
2D合成数据实验
数据:每个数据集包含100-500个2D点,来自4个高斯分布。
评估指标:平均对数似然(越高越好)
结果:

惊人发现:
- Set Transformer(SAB+PMA和ISAB+PMA)在单次EM更新后甚至超过了oracle!
- ISAB(16)+PMA用仅16个inducing points达到最佳性能
- rFF+Pooling的性能很差(-2.0006),证明了元素交互建模的重要性
为什么能超过oracle? 作者解释说,由于样本量较小(有些聚类只有不到10个点),样本统计量与总体统计量差异较大。Set Transformer能够适应这种情况,而oracle使用的是生成数据的真实参数。
视觉对比:
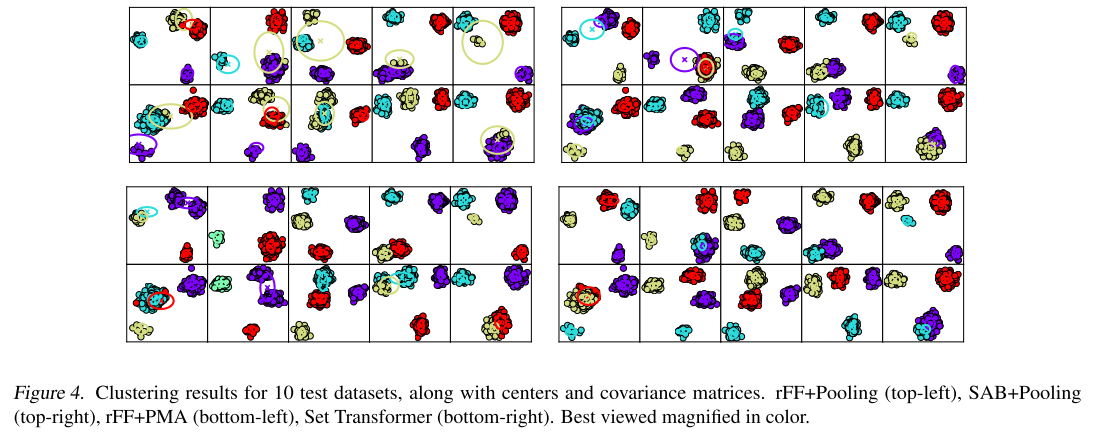
从图中可以清楚看到:
- rFF+Pooling:聚类中心位置不合理,没有很好地匹配点的分布
- SAB+Pooling:有所改善,但仍不够精确
- rFF+PMA:能够产生不同的聚类中心,但位置不够准确
- Set Transformer(SAB+PMA):聚类中心精确匹配点的分布,椭圆的方向和大小都很合理
CIFAR-100实验
数据:从CIFAR-100的4个随机类别中采样100-500张图片,用预训练VGG提取特征。
评估指标:调整兰德指数(Adjusted Rand Index, ARI),范围0-1,越高越好。
结果:
| 架构 | ARI₀ | ARI₁ |
|---|---|---|
| Oracle(EM收敛) | 0.9150 | - |
| rFF + Pooling | 0.5593 ± 0.0149 | 0.5693 ± 0.0171 |
| SAB + Pooling | 0.5831 ± 0.0341 | 0.5943 ± 0.0337 |
| rFF + PMA | 0.7612 ± 0.0237 | 0.7670 ± 0.0231 |
| SAB + PMA | 0.9015 ± 0.0097 | 0.9024 ± 0.0097 |
| ISAB(16) + PMA | 0.9210 ± 0.0055 | 0.9223 ± 0.0056 |
关键洞察:
- PMA的巨大作用:从rFF+Pooling(0.5593)到rFF+PMA(0.7612),提升了36%!
- SAB+PMA接近oracle:0.9015 vs 0.9150,差距很小
- ISAB甚至超过SAB:可能是因为inducing points提供了正则化和知识迁移
这个实验有力证明了:
- 编码器中的注意力(SAB/ISAB)很重要
- 解码器中的注意力(PMA)更为关键,特别是对于需要多个相关输出的任务
实验4:集合异常检测
任务:在CelebA人脸图片集合中,找出不属于该集合的"异常"图片。
设置:每个集合包含7张具有两个共同属性的正常图片,和1张两个属性都不具备的异常图片。

结果:
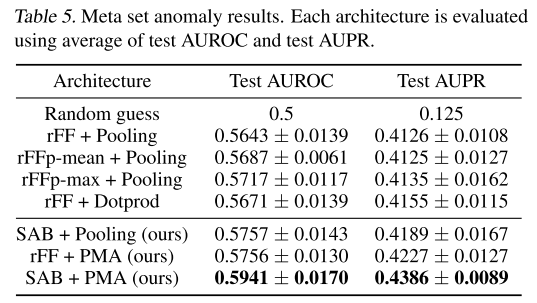
分析:
- 所有方法都显著超过随机猜测
- Set Transformer (SAB+PMA)在两个指标上都最优
- 性能提升虽然不如聚类任务那么显著,但一致性很好
实验5:点云分类
任务:对3D物体的点云表示进行分类(ModelNet40数据集,40个类别)。
挑战:点云数据通常包含大量点(实验中测试了100、1000、5000个点),这对计算效率提出了很高要求。
结果:
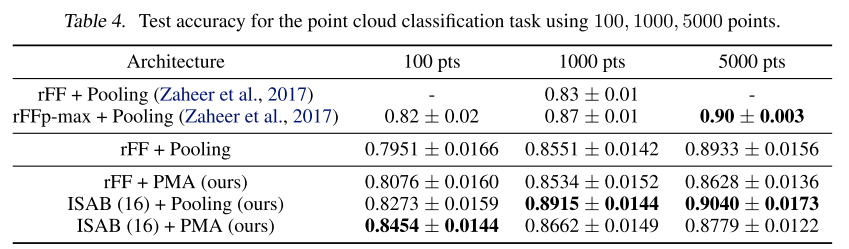
有趣的观察:
- 小集合上(100点):Set Transformer (ISAB+PMA)表现最好
- 大集合上(5000点):ISAB+Pooling超过了ISAB+PMA
作者的解释:
- 分类任务在点数多时变得更容易(信息更充分)
- 当信息已经足够时,复杂的交互建模反而不如简单聚合
- 但在信息不足时(100点),注意力机制的优势就体现出来了
这个结果提醒我们:不是所有任务都需要复杂的注意力机制,要根据任务特点选择合适的架构。
实验6:计算效率
论文还专门测试了SAB和ISAB的实际运行时间。
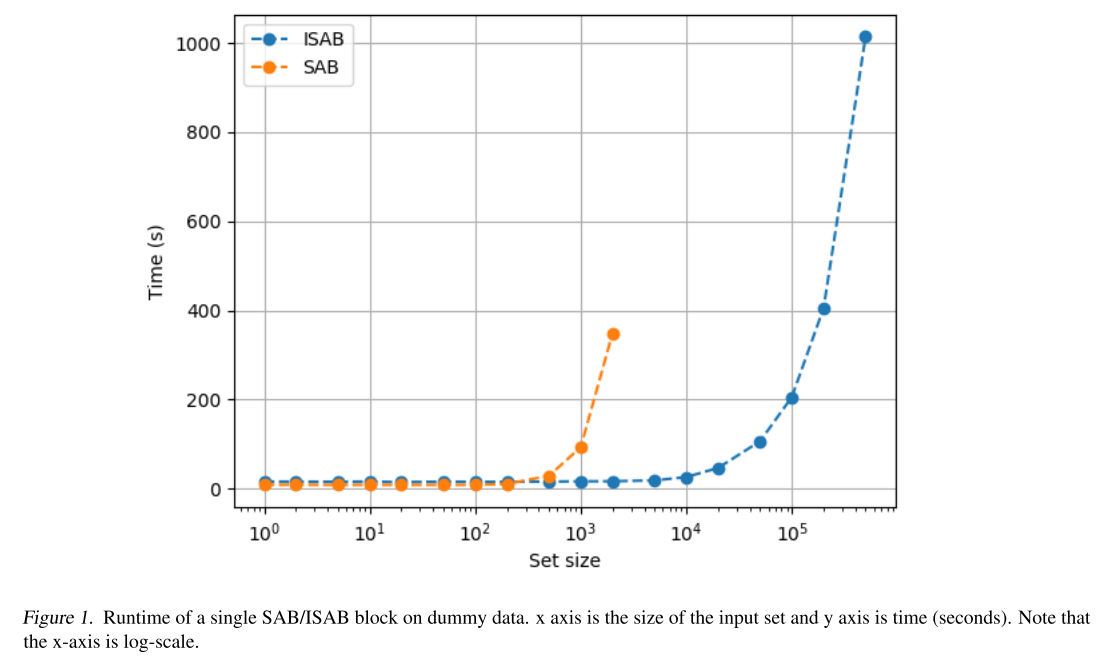
结果:
- SAB的时间随集合大小n呈二次增长(O(n²))
- ISAB的时间呈线性增长(O(n))
- 当n=2000时,SAB已经无法在单GPU上运行,而ISAB仍然高效
这验证了ISAB在大规模集合上的实用价值。
实现细节与建议
基于论文的实验,这里总结一些实践建议:
1. 何时使用SAB vs ISAB?
- 小集合(n < 500):使用SAB,性能略好
- 大集合(n > 1000):必须使用ISAB,否则计算开销太大
- Inducing points数量:通常16-32个就足够,更多不一定更好
2. 编码器 vs 解码器的注意力
- 编码器(SAB/ISAB):对需要理解元素关系的任务很重要
- 解码器 (PMA):对需要多个相关输出的任务至关重要(如聚类)
- 如果计算资源有限,优先保证解码器使用PMA
3. 架构选择
根据任务类型选择:
| 任务类型 | 推荐架构 | 原因 |
|---|---|---|
| 需要元素交互 + 单一输出 | SAB/ISAB + Pooling | 编码器建模交互,简单聚合 |
| 需要元素交互 + 多个输出 | SAB/ISAB + PMA | PMA能产生相关的多个输出 |
| 简单分类/回归 | rFF + Pooling | 有时简单方法就足够 |
| 大规模数据 | ISAB + Pooling/PMA | 保证计算效率 |
4. 训练技巧
- 使用较小的学习率(论文中用10⁻³到10⁻⁴)
- Layer normalization很重要,能稳定训练
- 可以使用学习率衰减策略
方法的局限性与未来方向
局限性
-
对有序序列不适用:Set Transformer假设输入无序,对于有时序信息的数据(如文本、时间序列),传统的Transformer更合适。
-
inducing points的解释性:虽然ISAB很有效,但inducing points学到了什么、如何选择最优数量,仍然不是很清楚。
-
大规模应用:虽然ISAB降低了复杂度,但对于超大规模集合(百万级元素),可能仍然具有挑战性。
未来方向
论文最后提出了一些有前景的研究方向:
1. 应用于元学习 Set Transformer天然适合元学习场景,因为元学习任务本质上是从一个任务集合中学习。特别是:
- 用于贝叶斯模型的后验推断
- 少样本学习中的更好特征聚合
2. 不确定性建模 在Set Transformer中引入噪声变量,建模集合函数的不确定性。这对于:
- 风险敏感的决策
- 主动学习(选择最有信息量的数据点)
3. 更高效的注意力机制 虽然ISAB已经很高效,但仍有改进空间:
- 自适应的inducing points数量
- 稀疏注意力模式
- 与其他高效注意力方法结合
4. 图神经网络的连接 Set Transformer可以看作是完全连接图上的消息传递。与图神经网络结合可能产生有趣的架构。
总结
Set Transformer为处理集合数据提供了一个优雅而有效的框架。它的核心贡献可以总结为:
理论贡献
- ✅ 证明了基于注意力的集合处理方法是通用近似器
- ✅ 保持了排列不变性的理论保证
技术贡献
- 🔧 ISAB:通过inducing points将复杂度从O(n²)降至O(nm)
- 🔧 PMA:用可学习的注意力替代固定池化,特别适合多输出任务
- 🔧 完整框架:编码器-解码器架构,灵活组合SAB/ISAB和PMA
实验贡献
- 📊 在5个不同任务上都取得显著提升
- 📊 特别在需要复杂交互建模的任务上(如聚类)表现出色
- 📊 证明了注意力机制在集合数据上的有效性
核心洞察
"并不是所有排列不变函数都能用简单的独立编码+池化很好地近似。当元素间的交互关系很重要时,让它们通过注意力机制'交流'信息是更好的选择。"
Set Transformer的思想已经影响了后续很多工作,包括:
- 点云处理(3D视觉)
- 图神经网络
- 元学习
- 多实例学习
如果你的任务涉及集合数据,特别是需要理解元素间关系时,Set Transformer是一个值得尝试的强大工具。
关于作者:本文详细解析了ICML 2019的Set Transformer论文。如果你对集合学习、注意力机制或深度学习感兴趣,希望这篇文章能帮助你理解这个优雅的框架。