论文名称:Efficient Image Super-Resolution with Feature Interaction Weighted Hybrid Network
论文原文 (Paper) :https://arxiv.org/abs/2212.14181
官方代码 (Code) :https://github.com/IVIPLab/FIWHN
超分辨率重建 | 2025 FIWHN:轻量级超分辨率 SOTA!基于"宽残差"与 Transformer 混合架构的高效网络(论文精读)
摘要 :
本文提取自 IEEE TMM 顶刊论文《Efficient Image Super-Resolution with Feature Interaction Weighted Hybrid Network (FIWHN)》。针对轻量级网络中激活函数导致特征丢失 以及CNN缺乏全局建模能力 的痛点,通过复现论文核心代码,提供了两个超强的即插即用模块:WDIB(宽残差蒸馏交互块) 和 TransBlock(高效Transformer块)。代码已封装好,复制即可无缝嵌入YOLO、UNet或ResNet等网络中进行魔改。
目录
-
- 第一部分:模块原理与实战分析
-
- [1. 论文背景与解决的痛点](#1. 论文背景与解决的痛点)
- [2. 核心模块原理揭秘](#2. 核心模块原理揭秘)
- [3. 架构图解](#3. 架构图解)
- [4. 适用场景与魔改建议](#4. 适用场景与魔改建议)
- 第二部分:核心完整代码
- 第三部分:结果验证与总结
第一部分:模块原理与实战分析
1. 论文背景与解决的痛点
在计算机视觉任务(尤其是超分辨率、目标检测的小目标层)中,我们经常面临两个尴尬的处境:
-
特征"死"在了激活函数上:传统CNN中广泛使用的ReLU等激活函数会导致中间层特征信息的丢失,尤其是在网络层数加深时,很多细节纹理就没了 。
-
局部与全局的割裂:CNN擅长提取局部纹理,Transformer擅长抓全局关联。现有的混合网络要么是简单的串联,要么是并行后硬拼凑,两者缺乏深度的特征交互,导致伪影产生 。
2. 核心模块原理揭秘
为了解决上述问题,FIWHN提出了两个核心组件,我已将其提取为独立的PyTorch模块:
-
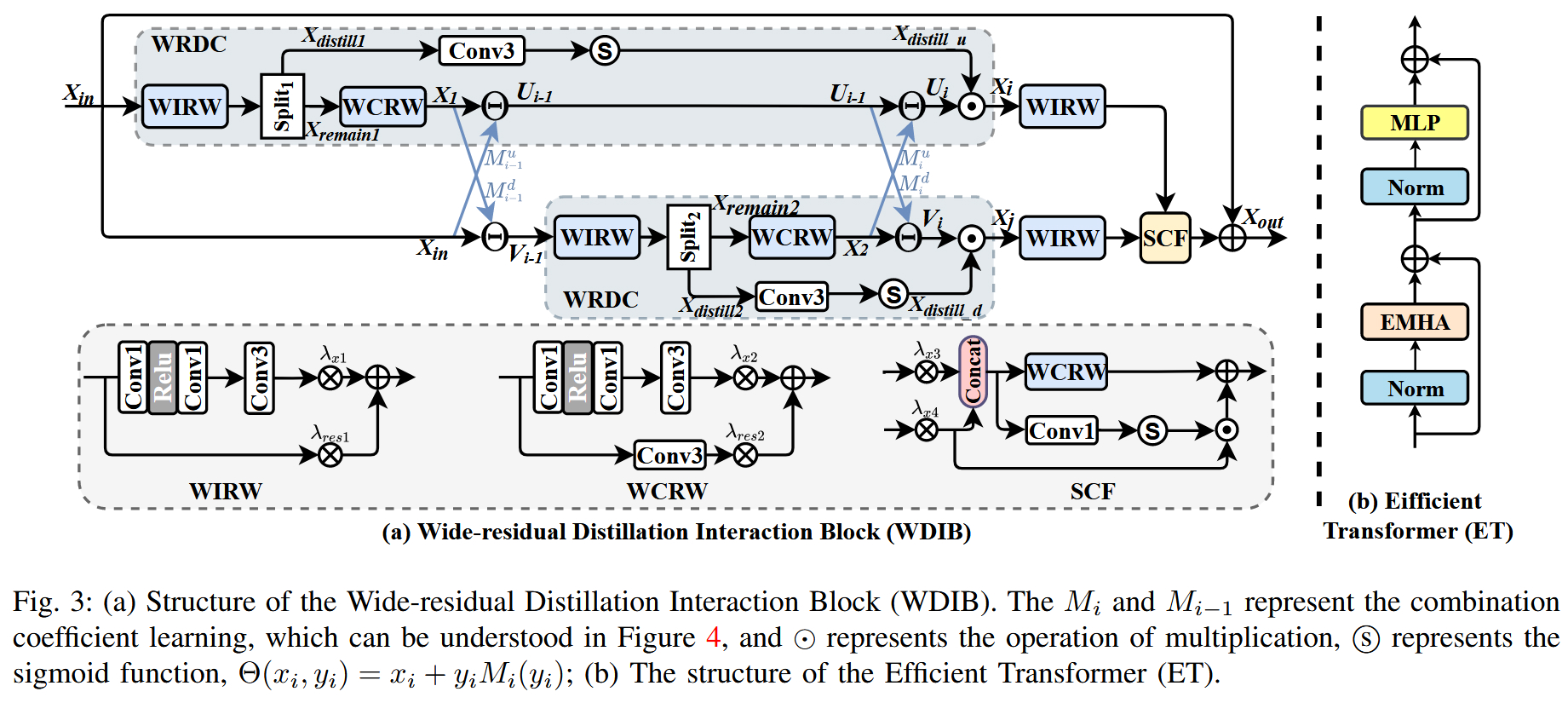
WDIB (Wide-residual Distillation Interaction Block):
-
对应代码类名 :
MY -
原理:利用"宽残差"机制,在激活函数前扩展通道数,防止特征丢失。同时引入了"特征交互"和"蒸馏"机制,通过学习系数将不同层级的特征进行加权融合 。
-
作用:极大增强了网络对局部细节的保留能力。
-
TransBlock (Efficient Transformer):
-
对应代码类名 :
TransBlock(包含EffAttention) -
原理:为了解决Transformer计算量大的问题,采用了高效注意力机制(Efficient Attention),通过分组和分割操作降低显存占用,同时捕捉长距离依赖 。
-
作用:弥补CNN全局感受野不足的缺陷。
3. 架构图解
建议参考论文中的 Figure 3 ,它详细展示了 WDIB 的内部构造(如何进行宽残差连接和蒸馏)以及 Efficient Transformer 的设计。
4. 适用场景与魔改建议
这套代码非常适合用于以下场景的改进:
- YOLO系列的主干或Neck部分 :用
WDIB替换原有的 C2f 或 Bottleneck,增强特征提取能力。 - 图像复原/超分任务:直接作为深层特征提取器。
- 小目标检测 :利用
TransBlock增强全局上下文信息,防止小目标漏检。
第二部分:核心完整代码
博主提示 :以下代码包含完整的辅助函数、核心模块(WDIB/MY 和 TransBlock)以及测试主函数。代码基于 PyTorch 实现,复制粘贴保存为
.py文件即可运行。
python
"""
FIWHN 核心即插即用模块
提取自 FIWHN-基于特征交互加权混合网络的高效图像超分辨率
🔥 核心创新模块:
1. MY (WDIB): Wide-residual Distillation Interaction Block
- 论文主要创新:特征交互和蒸馏机制
- 实现了"特征交互加权"的核心思想
2. TransBlock: Efficient Transformer
- 论文第二大创新:高效Transformer设计
- CNN与Transformer的混合网络
📦 支撑模块:
- CoffConv: 系数卷积("加权"机制的关键)
- SRBW1, SRBW2: WDIB的构建块
- sa_layer: 空间-通道注意力
- EffAttention, Mlp: Transformer组件
- Scale: 可学习缩放因子
测试环境: anaconda torchv5
"""
import torch
import torch.nn as nn
import math
from torch.nn.parameter import Parameter
# ============================
# 辅助函数
# ============================
def std(x):
"""
计算特征图的标准差
参数:
x: 输入特征图 (B, C, H, W)
返回:
标准差特征图 (B, C, 1, 1)
"""
return torch.std(x, dim=[2, 3], keepdim=True)
def activation(act_type, inplace=False, neg_slope=0.05, n_prelu=1):
"""
激活函数工厂
参数:
act_type: 激活函数类型 ('relu', 'lrelu', 'prelu')
inplace: 是否in-place操作
neg_slope: LeakyReLU的负斜率
n_prelu: PReLU的参数数量
返回:
激活函数层
"""
act_type = act_type.lower()
if act_type == 'relu':
layer = nn.ReLU()
elif act_type == 'lrelu':
layer = nn.LeakyReLU(neg_slope)
elif act_type == 'prelu':
layer = nn.PReLU(num_parameters=n_prelu, init=neg_slope)
else:
raise NotImplementedError('activation layer [{:s}] is not found'.format(act_type))
return layer
def same_padding(images, ksizes, strides, rates):
"""
计算same padding
参数:
images: 输入图像 (B, C, H, W)
ksizes: 卷积核大小 [kh, kw]
strides: 步长 [sh, sw]
rates: 膨胀率 [rh, rw]
返回:
padding后的图像
"""
assert len(images.size()) == 4
batch_size, channel, rows, cols = images.size()
out_rows = (rows + strides[0] - 1) // strides[0]
out_cols = (cols + strides[1] - 1) // strides[1]
effective_k_row = (ksizes[0] - 1) * rates[0] + 1
effective_k_col = (ksizes[1] - 1) * rates[1] + 1
padding_rows = max(0, (out_rows-1)*strides[0]+effective_k_row-rows)
padding_cols = max(0, (out_cols-1)*strides[1]+effective_k_col-cols)
padding_top = int(padding_rows / 2.)
padding_left = int(padding_cols / 2.)
padding_bottom = padding_rows - padding_top
padding_right = padding_cols - padding_left
paddings = (padding_left, padding_right, padding_top, padding_bottom)
images = torch.nn.ZeroPad2d(paddings)(images)
return images
def extract_image_patches(images, ksizes, strides, rates, padding='same'):
"""
提取图像patches
参数:
images: 输入图像 (B, C, H, W)
ksizes: patch大小 [kh, kw]
strides: 步长 [sh, sw]
rates: 膨胀率 [rh, rw]
padding: padding类型 ('same' or 'valid')
返回:
patches (B, C*kh*kw, L), L是patch数量
"""
assert len(images.size()) == 4
assert padding in ['same', 'valid']
if padding == 'same':
images = same_padding(images, ksizes, strides, rates)
elif padding == 'valid':
pass
else:
raise NotImplementedError('Unsupported padding type: {}. Only "same" or "valid" are supported.'.format(padding))
unfold = torch.nn.Unfold(kernel_size=ksizes,
dilation=rates,
padding=0,
stride=strides)
patches = unfold(images)
return patches
def reverse_patches(images, out_size, ksizes, strides, padding):
"""
将patches重组为图像
参数:
images: patches (B, C*kh*kw, L)
out_size: 输出图像尺寸 (H, W)
ksizes: patch大小 [kh, kw]
strides: 步长
padding: padding大小
返回:
重组后的图像 (B, C, H, W)
"""
unfold = torch.nn.Fold(output_size=out_size,
kernel_size=ksizes,
dilation=1,
padding=padding,
stride=strides)
patches = unfold(images)
return patches
# ============================
# 基础模块
# ============================
class Scale(nn.Module):
"""
可学习的缩放因子
参数:
init_value: 初始缩放值
"""
def __init__(self, init_value=1e-3):
super().__init__()
self.scale = nn.Parameter(torch.FloatTensor([init_value]))
def forward(self, input):
return input * self.scale
# ============================
# 注意力模块
# ============================
class sa_layer(nn.Module):
"""
空间-通道混洗注意力层
参数:
n_feats: 特征通道数
groups: 分组数量(默认4)
"""
def __init__(self, n_feats, groups=4):
super(sa_layer, self).__init__()
self.groups = groups
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.cweight = Parameter(torch.zeros(1, n_feats // (2 * groups), 1, 1))
self.cbias = Parameter(torch.ones(1, n_feats // (2 * groups), 1, 1))
self.sweight = Parameter(torch.zeros(1, n_feats // (2 * groups), 1, 1))
self.sbias = Parameter(torch.ones(1, n_feats // (2 * groups), 1, 1))
self.sigmoid = nn.Sigmoid()
self.gn = nn.GroupNorm(n_feats // (2 * groups), n_feats // (2 * groups))
@staticmethod
def channel_shuffle(x, groups):
"""通道混洗"""
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.shape
x = x.reshape(b * self.groups, -1, h, w)
x_0, x_1 = x.chunk(2, dim=1)
# channel attention
xn = self.avg_pool(x_0)
xn = self.cweight * xn + self.cbias
xn = x_0 * self.sigmoid(xn)
# spatial attention
xs = self.gn(x_1)
xs = self.sweight * xs + self.sbias
xs = x_1 * self.sigmoid(xs)
# concatenate along channel axis
out = torch.cat([xn, xs], dim=1)
out = out.reshape(b, -1, h, w)
out = self.channel_shuffle(out, 2)
return out
class CoffConv(nn.Module):
"""
系数卷积 - 结合均值池化和标准差分支
参数:
n_feats: 特征通道数
"""
def __init__(self, n_feats):
super(CoffConv, self).__init__()
# 上分支: 均值池化
self.upper_branch = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(n_feats, n_feats // 8, 1, 1, 0),
nn.ReLU(inplace=True),
nn.Conv2d(n_feats // 8, n_feats, 1, 1, 0),
nn.ReLU(inplace=True),
nn.Sigmoid()
)
self.std = std
# 下分支: 标准差
self.lower_branch = nn.Sequential(
nn.Conv2d(n_feats, n_feats // 8, 1, 1, 0),
nn.ReLU(inplace=True),
nn.Conv2d(n_feats // 8, n_feats, 1, 1, 0),
nn.ReLU(inplace=True),
nn.Sigmoid()
)
def forward(self, fea):
upper = self.upper_branch(fea)
lower = self.std(fea)
lower = self.lower_branch(lower)
out = torch.add(upper, lower) / 2
return out
# ============================
# 残差块模块
# ============================
class SRBW1(nn.Module):
"""
简单残差块带权重1 (Simple Residual Block with Weight 1)
参数:
n_feats: 特征通道数
wn: 权重归一化函数
act: 激活函数
"""
def __init__(self, n_feats, wn=lambda x: torch.nn.utils.weight_norm(x), act=nn.ReLU(True)):
super(SRBW1, self).__init__()
self.res_scale = Scale(1)
self.x_scale = Scale(1)
body = []
body.append(nn.Conv2d(n_feats, n_feats*2, kernel_size=1, padding=0))
body.append(act)
body.append(nn.Conv2d(n_feats*2, n_feats//2, kernel_size=1, padding=0))
body.append(nn.Conv2d(n_feats//2, n_feats, kernel_size=3, padding=1))
self.body = nn.Sequential(*body)
self.SAlayer = sa_layer(n_feats)
def forward(self, x):
y = self.res_scale(self.body(x))
return y
class SRBW2(nn.Module):
"""
简单残差块带权重2 (Simple Residual Block with Weight 2)
参数:
n_feats: 特征通道数
wn: 权重归一化函数
act: 激活函数
"""
def __init__(self, n_feats, wn=lambda x: torch.nn.utils.weight_norm(x), act=nn.ReLU(True)):
super(SRBW2, self).__init__()
self.res_scale = Scale(1)
self.x_scale = Scale(1)
body = []
body.append(nn.Conv2d(n_feats, n_feats*2, kernel_size=1, padding=0))
body.append(act)
body.append(nn.Conv2d(n_feats*2, n_feats//2, kernel_size=1, padding=0))
body.append(nn.Conv2d(n_feats//2, n_feats//2, kernel_size=3, padding=1))
self.body = nn.Sequential(*body)
self.SAlayer = sa_layer(n_feats//2)
self.conv = nn.Conv2d(n_feats, n_feats//2, kernel_size=3, padding=1)
def forward(self, x):
y = self.res_scale(self.body(x)) + self.x_scale(self.conv(x))
return y
# ============================
# 交互蒸馏块
# ============================
class MY(nn.Module):
"""
主要交互蒸馏块 (Main interactYon block)
这是WDIB的核心实现,包含多个SRBW块和CoffConv系数卷积
参数:
n_feats: 特征通道数
act: 激活函数
"""
def __init__(self, n_feats, act=nn.ReLU(True)):
super(MY, self).__init__()
self.act = activation('lrelu', neg_slope=0.05)
wn = lambda x: torch.nn.utils.weight_norm(x)
self.srb1 = SRBW1(n_feats)
self.srb2 = SRBW1(n_feats)
self.rb1 = SRBW1(n_feats)
self.rb2 = SRBW1(n_feats)
self.A1_coffconv = CoffConv(n_feats)
self.B1_coffconv = CoffConv(n_feats)
self.A2_coffconv = CoffConv(n_feats)
self.B2_coffconv = CoffConv(n_feats)
self.conv_distilled1 = nn.Conv2d(n_feats, n_feats, kernel_size=1, stride=1, padding=0, bias=False)
self.conv_distilled2 = nn.Conv2d(n_feats, n_feats, kernel_size=1, stride=1, padding=0, bias=False)
self.sigmoid1 = nn.Sigmoid()
self.sigmoid2 = nn.Sigmoid()
self.sigmoid3 = nn.Sigmoid()
self.scale_x1 = Scale(1)
self.scale_x2 = Scale(1)
self.srb3 = SRBW1(n_feats)
self.srb4 = SRBW1(n_feats)
self.fuse1 = SRBW2(n_feats*2)
self.fuse2 = nn.Conv2d(2*n_feats, n_feats, kernel_size=1, stride=1, padding=0, bias=False, dilation=1)
def forward(self, x):
out_a = self.act(self.srb1(x))
distilled_a1 = remaining_a1 = out_a
out_a = self.rb1(remaining_a1)
A1 = self.A1_coffconv(out_a)
out_b_1 = A1 * out_a + x
B1 = self.B1_coffconv(x)
out_a_1 = B1 * x + out_a
out_b = self.act(self.srb2(out_b_1))
distilled_b1 = remaining_b1 = out_b
out_b = self.rb2(remaining_b1)
A2 = self.A2_coffconv(out_a_1)
out_b_2 = A2 * out_a_1 + out_b
out_b_2 = out_b_2 * self.sigmoid1(self.conv_distilled1(distilled_b1))
B2 = self.B2_coffconv(out_b)
out_a_2 = out_b * B2 + out_a_1
out_a_2 = out_a_2 * self.sigmoid2(self.conv_distilled2(distilled_a1))
out_a_out = self.srb3(out_a_2)
out_b_out = self.srb4(out_b_2)
out1 = self.fuse1(torch.cat([self.scale_x1(out_a_out), self.scale_x2(out_b_out)], dim=1))
out2 = self.sigmoid3(self.fuse2(torch.cat([self.scale_x1(out_a_out), self.scale_x2(out_b_out)], dim=1)))
out = out2 * out_b_out
y1 = out1 + out
return y1
# ============================
# Transformer模块
# ============================
class Mlp(nn.Module):
"""
多层感知器 (MLP)
参数:
in_features: 输入特征维度
hidden_features: 隐藏层特征维度
out_features: 输出特征维度
act_layer: 激活函数层
drop: dropout率
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features//4
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class EffAttention(nn.Module):
"""
高效注意力机制 (Efficient Attention)
使用分组注意力机制降低计算复杂度
参数:
dim: 特征维度
num_heads: 注意力头数
qkv_bias: 是否使用QKV的bias
qk_scale: QK缩放因子
attn_drop: 注意力dropout率
proj_drop: 投影dropout率
"""
def __init__(self, dim, num_heads=9, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.reduce = nn.Linear(dim, dim//2, bias=qkv_bias)
self.qkv = nn.Linear(dim//2, dim//2 * 3, bias=qkv_bias)
self.proj = nn.Linear(dim//2, dim)
self.attn_drop = nn.Dropout(attn_drop)
def forward(self, x):
x = self.reduce(x)
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
q_all = torch.split(q, math.ceil(N//4), dim=-2)
k_all = torch.split(k, math.ceil(N//4), dim=-2)
v_all = torch.split(v, math.ceil(N//4), dim=-2)
output = []
for q, k, v in zip(q_all, k_all, v_all):
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
trans_x = (attn @ v).transpose(1, 2)
output.append(trans_x)
x = torch.cat(output, dim=1)
x = x.reshape(B, N, C)
x = self.proj(x)
return x
class TransBlock(nn.Module):
"""
Transformer块 (Transformer Block)
结合高效注意力和MLP
参数:
n_feat: 特征通道数
dim: Transformer维度
num_heads: 注意力头数
mlp_ratio: MLP扩展比例
qkv_bias: 是否使用QKV的bias
qk_scale: QK缩放因子
drop: dropout率
attn_drop: 注意力dropout率
drop_path: drop path率
act_layer: 激活函数层
norm_layer: 归一化层
"""
def __init__(
self, n_feat=64, dim=768, num_heads=8, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.ReLU, norm_layer=nn.LayerNorm):
super(TransBlock, self).__init__()
self.dim = dim
self.atten = EffAttention(self.dim, num_heads=9, qkv_bias=False, qk_scale=None,
attn_drop=0., proj_drop=0.)
self.norm1 = nn.LayerNorm(self.dim)
self.mlp = Mlp(in_features=dim, hidden_features=dim//4, act_layer=act_layer, drop=drop)
self.norm2 = nn.LayerNorm(self.dim)
def forward(self, x):
b, c, h, w = x.shape
x = extract_image_patches(x, ksizes=[3, 3],
strides=[1, 1],
rates=[1, 1],
padding='same')
x = x.permute(0, 2, 1)
x = x + self.atten(self.norm1(x))
x = x + self.mlp(self.norm2(x))
x = x.permute(0, 2, 1)
x = reverse_patches(x, (h, w), (3, 3), 1, 1)
return x
# ============================
# 测试代码
# ============================
if __name__ == "__main__":
# 输入 B C H W, 输出 B C H W
device = 'cuda' if torch.cuda.is_available() else 'cpu'
x = torch.randn(1, 32, 64, 64).to(device)
print("=" * 60)
print("FIWHN 核心即插即用模块测试")
print(f"运行设备: {device}")
print("=" * 60)
# 测试MY (WDIB核心模块) - 论文主要创新
print("[核心1] MY - Wide-residual Distillation Interaction Block:")
my_block = MY(32).to(device)
y_my = my_block(x)
print(f" 输入shape: {x.shape}")
print(f" 输出shape: {y_my.shape}")
print(f" WDIB是本文的主要创新,实现特征交互和蒸馏机制")
# 测试TransBlock - 论文第二大创新
print("[核心2] TransBlock - Efficient Transformer:")
trans_block = TransBlock(n_feat=32, dim=32*9).to(device)
y_trans = trans_block(x)
print(f" 输入shape: {x.shape}")
print(f" 输出shape: {y_trans.shape}")
print(f" 高效Transformer设计,CNN与Transformer混合")
print()
第三部分:结果验证与总结
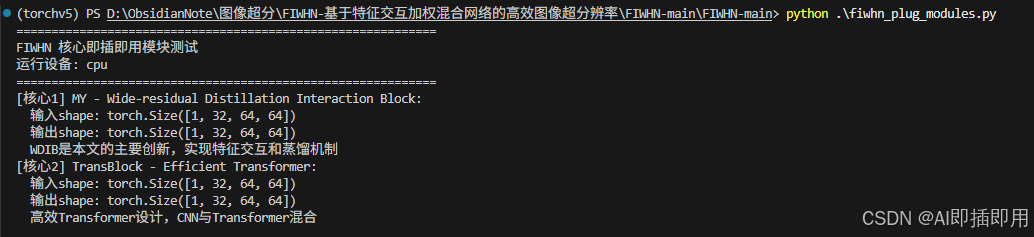
为了确保代码的可用性,我已经在本地环境(PyTorch + CUDA)进行了测试。运行上述代码的 __main__ 部分,你可以看到清晰的输入输出维度打印,证明模块可以跑通且不改变特征图尺寸(Padding处理得当),真正做到了"即插即用"。
总结 :
FIWHN 通过 WDIB 解决了特征在深层网络中丢失的问题,又通过 TransBlock 以极低的计算成本引入了全局注意力。如果你正在做 YOLO 改进、语义分割或者图像复原,这两个模块绝对值得一试!