哈希入门
基本概念
Hash通常翻译为散列或哈希,简单来说,它是通过特定算法把任意长度的输入数据 ,映射成固定长度输出的过程,这个输出结果就是哈希值。举一个不太严谨的例子,假设小明正在抄书带回去研读,一开始为了确保自己没有抄错,每次抄完一页都一个个字比对;后来有人告诉了他每页都有多少字数,那他就可以快速比对自己抄录的字数和参考字数有没有差别。
那么为什么用Hash这个词来表示这个过程呢?目的就是强调它的不可逆,hash的本意是剁碎的意思:

假设我们把土豆磨碎和上生粉,就可以去炸薯饼了,但是反过来拿着薯饼去还原土豆,基本是不可能的;因此这个算法得名Hash。
我们需要注意hash与加密的区别,加密通常是可逆的。比如我们下载了Linux的ISO文件,通常也会给我们一串字符用来校验版本正确和版本完整性,这串字符就是整个软件的hash值,但我们无法用这串字符去复原整个ISO文件;相反,我们可以对压缩文件上锁,只要把密钥告诉其他人,他们就能还原完整的文件出来。
特性概括
固定性:不管输入数据是几 KB 的文本还是几个 GB 的视频,经同一哈希算法处理后,哈希值长度固定。比如 SHA - 256 算法的哈希值永远是 256 位。
不可逆性:哈希算法是单向运算,只能由原始数据算出哈希值,没法从哈希值反推回原始数据,这也是它适合密码存储的关键原因。
高敏感性:原始数据哪怕只有微小改动,比如把文本里的一个小写字母改成大写,对应的哈希值都会发生巨大变化,能快速察觉数据是否被篡改。
确定性:同一原始数据用同一哈希算法计算,得到的哈希值必然相同,这保证了哈希值可用于数据一致性校验。
典型应用
密码存储:网站不会存储用户明文密码,而是存储密码的哈希值。用户登录时,输入密码经哈希运算后,与数据库中存储的哈希值比对,一致则登录成功,即便数据库泄露,黑客也难以获取明文密码。
文件校验:下载软件或大型文件时,官方会附带文件的哈希值。用户下载后计算本地文件的哈希值,和官方值对比,就能判断文件是否损坏或被篡改。
哈希表:这是基于哈希的重要数据结构。它通过哈希函数将数据的键映射到数组对应位置,能实现快速的查找、插入操作,像 Java 中的 HashMap 就是典型应用。
区块链:区块链的每个区块都会通过哈希算法生成唯一哈希值,且包含上一区块的哈希值。一旦某区块数据被篡改,其哈希值会改变,进而影响后续所有区块,以此保障区块链数据的完整性。
数组与哈希表
数组利用固定索引寻找元素,但如果元素种类较多,或者元素的特性较多,则会对CRUD造成很大的影响。因此哈希表不再使用索引寻找元素,而是利用**键值对(key-value)**机制。Python里面的字典底层机制就是hash表。

数组的索引是一个个整数,程序通过这个整数找到对应的内存地址;哈希表里面的键可以是字符串或者整数,但这个键不会直接对应相应的内存地址,需要进行运算之后才可以进行内存寻址。这个运算方式就是哈希函数。
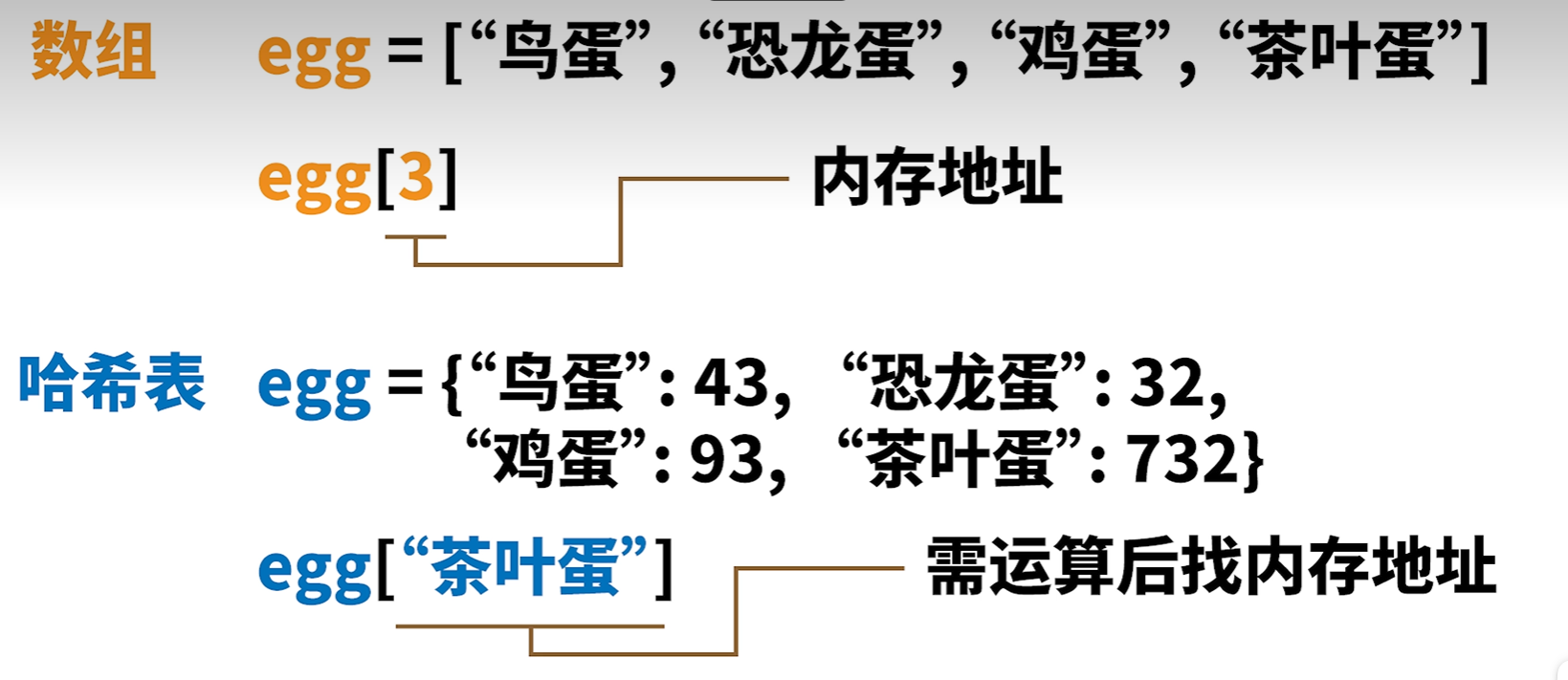
下面插播一个概念辨析,哈希表、哈希函数与哈希算法的关系。哈希算法的核心是哈希函数 (运算规则),和哈希表无关;哈希表是数据结构,只是 "使用" 哈希函数实现快速存取。哈希表的核心是存储业务数据(Key-Value),哈希值是计算存储位置的 "索引工具",而非哈希表的存储对象。
哈希函数
哈希函数一定要用到取余运算才能实现不可逆。
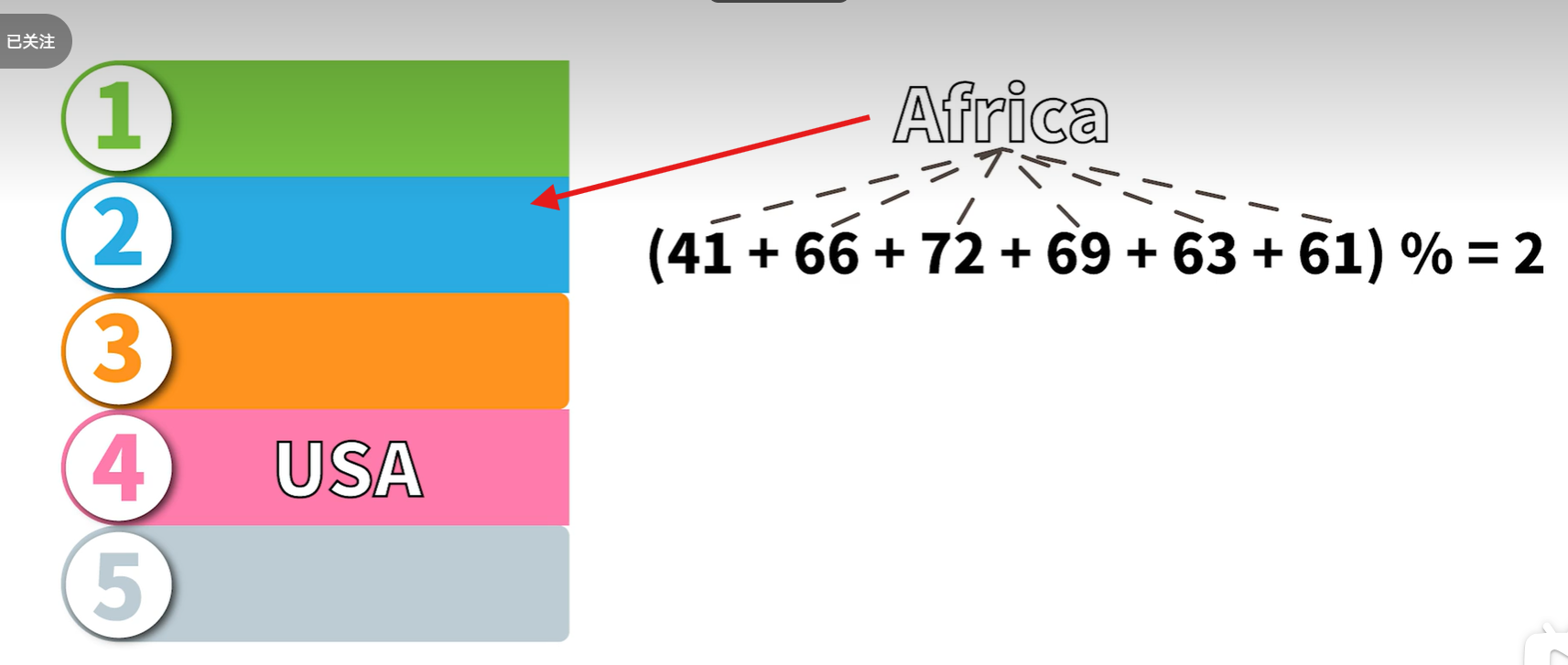
最简单的例子,假设存在一个长度为5的哈希表,现在想要存储"AFRICA"这三个字符,可以怎么操作呢?AFRICA分别对应ASCII码值41、66、72、69、63、61,最简单的办法是相加之后和长度求余:(41+66+71+69+63+61 )%5=2,那么就可以把"AFRICA"放入第三个哈希表项。
冲突/碰撞
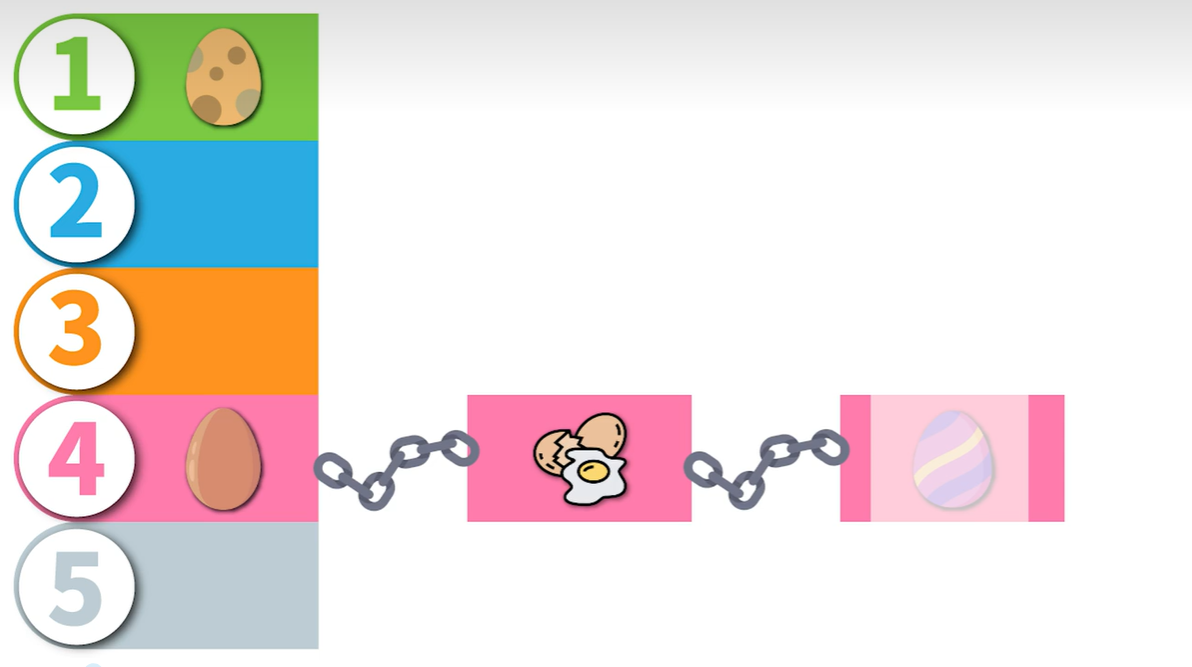
哈希函数输入不同的内容可能得到相同的输出,比如我们还想存储ASIA,那么经过上面提到的哈希函数计算出的key是2,这就叫做hash冲突。哈希函数在设计的时候就必须考虑到解决冲突的问题,通常我们会用两种方式,开放寻址法与封闭寻址法。
封闭寻址法中最常用的又是链表法,链表法就是将哈希表中的位置设置为链表,当某个节点发生冲突的时候,直接把插入数据放入当前节点的链表之中。这种方法容易受到集群现象的影响,可能会导致查找效率降低。
开放寻址法里面最常用的是线性探测法,这种方法实现方式是在发生冲突之后就往下面找空闲内存,但是这种方法可能会导致数据聚集在某一块,每次查表的时候我们可能都会花大量时间查找同一块内存,这种现象叫做一次聚集现象。
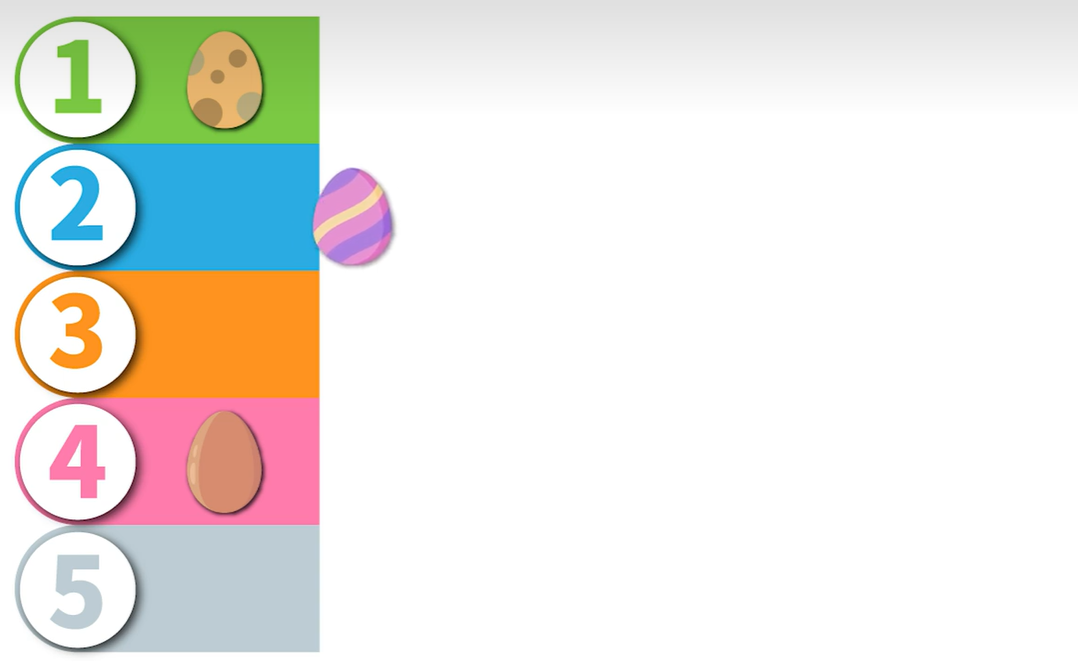
为了应对这个问题,出现了二次探测法,跨次方寻找空闲内存。
哈希算法
MD5和SHA是最常用的hash算法,它们可以把不定长数据转换为绝对固定长度数值,这个数值一般叫做摘要。
其他应用
