一句话先讲明白
这篇论文要解决一个现实痛点:LLM 能写 GPU kernel,但很难稳定、可评测、可部署。作者提出 FlashInfer-Bench (FIB) ,把 生成 → 评测 → 部署 变成一套闭环流程,并用真实线上 trace 来验证 AI 生成 kernel 的正确性和收益。
1. 背景:LLM 推理的瓶颈不在模型,而在 GPU Kernel
现代 LLM 推理系统(SGLang、vLLM 等)本质是 CPU 调度 + 大量 GPU kernel 调用 。真正决定延迟和吞吐的是 kernel 本身。
关键问题:
- Kernel 类型少但复杂 :GEMM、Attention、MoE、Sampling。
- 优化极度依赖硬件细节 :SM 数、tensor core 指令、内存层级、低精度格式。
- 现实 workload 很"脏" :ragged shape、稀疏、非确定性。
现有手段:
- 库与模板 (cuBLAS、FlashInfer)
- 自动调度搜索 (TVM/Ansor)
- LLM 生成 kernel (KernelBench、TritonBench)
问题是:LLM 生成的 kernel 没有统一规格、无法稳定评测、也很难无侵入部署到真实系统。
2. 核心方案:FlashInfer-Bench 的闭环架构
FIB 的核心是三件事:
- 标准化描述 :
FlashInfer Trace (FITRACE)把 kernel 定义、工作负载、实现、评测结果统一描述。 - 真实 workload 数据集 :从真实 LLM Serving trace 中抽取 workload。
- 动态替换机制 :
apply()允许把最优 kernel 在运行时注入推理引擎。
下面是完整架构:
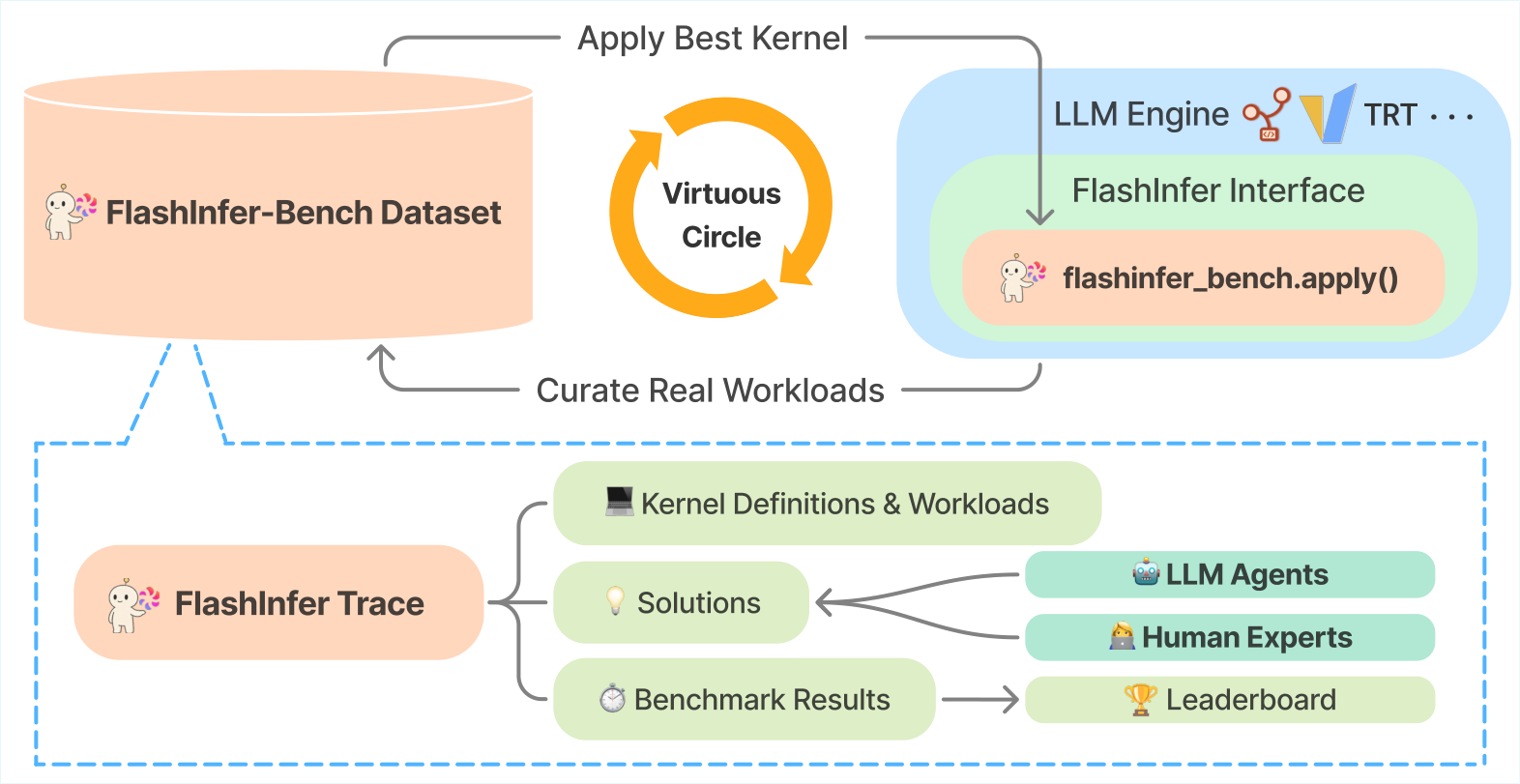
图解:这张图展示了 FIB 的闭环结构。左侧是 FITRACE 统一 schema,用于描述 kernel 任务、workload 和评测结果;中间是数据集与评测框架;右侧是
apply()将最优 kernel 动态替换进 SGLang、vLLM 等真实系统。
3. FITRACE:让 AI 与系统"说同一种话"
FITRACE 把所有内容拆成四块:
- Definition :输入输出张量、dtype、轴定义(const/var)、参考实现
run。 - Workload :具体输入实例,绑定 Definition。
- Solution :AI 生成实现 + 代码文件 + 运行元信息。
- Evaluation :一次评测的结果(正确性、性能、环境)。
这让 kernel 生成、评测与部署变成标准化可复现流程。
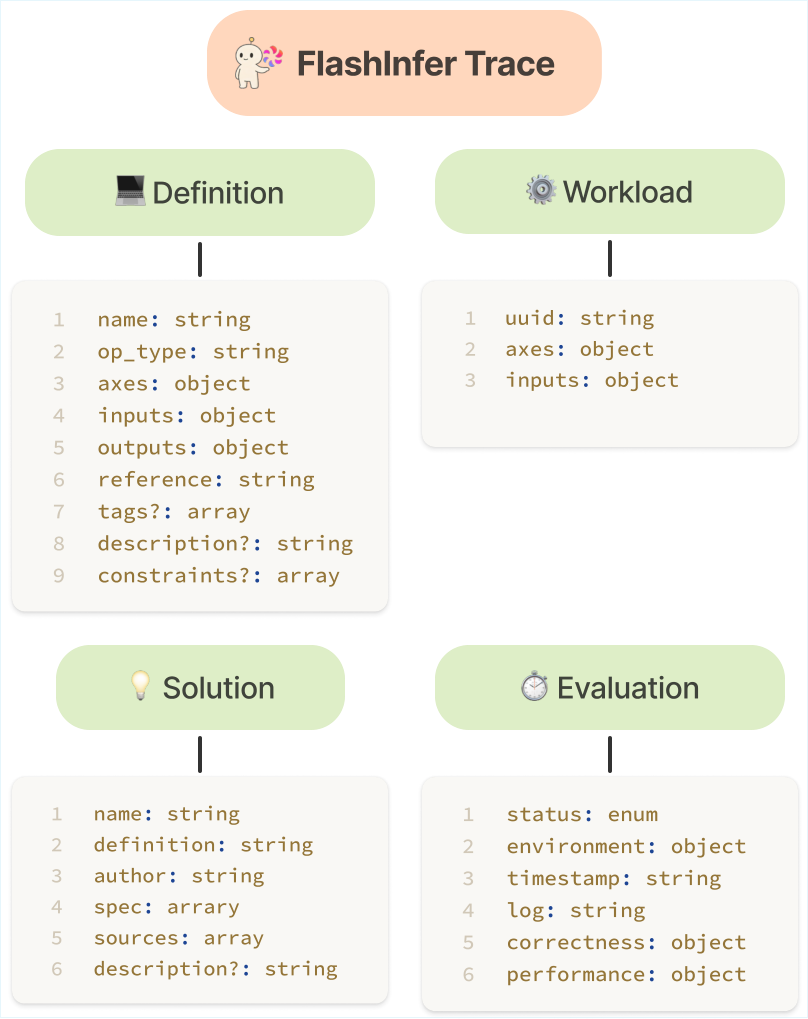
图解:FITRACE 的四层结构示意。Definition 和 Workload 定义任务语义,Solution 描述实现,Evaluation 固化性能结果,用于后续部署和对比。
4. 数据集:来自真实 LLM Serving Trace
数据集中覆盖 8 类 kernel :
- GEMM
- Ragged/Paged GQA
- Ragged/Paged MLA
- Fused MoE
- RMSNorm
- Sampling
构建细节:
- 41 个 kernel 定义
- 1600 个 workload
- 240 个 AI 生成方案
- 9600 个评测结果
核心原则:
- workload 不是随机采样,而是真实线上 trace。
- 数据去重以 shape + 性能敏感维度 为标准。
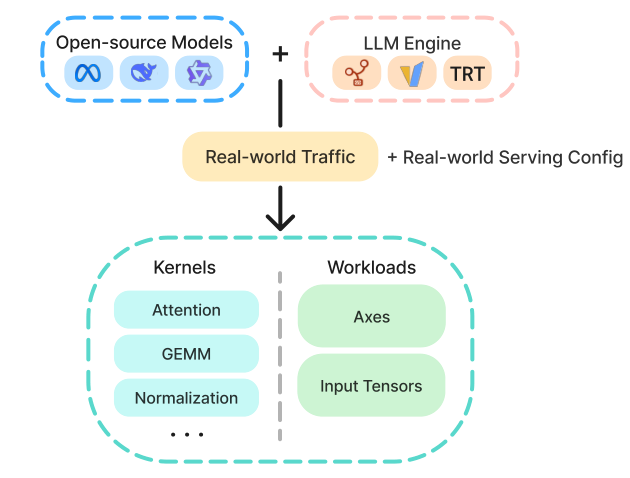
图解:这张图展示数据集构建流程,从真实 LLM serving trace 采集 kernel 调用,再做 shape 去重与过滤,最终形成可复现实验集。
5. Benchmark:正确性 + 性能的联合评测
论文提出 fast_p 指标:
fast p = 1 N ∑ i = 1 N 1 ( correct i ∧ { speedup i > p } ) \text{fast}p = \frac{1}{N} \sum{i=1}^{N} \mathbf{1}(\text{correct}_i \land \{\text{speedup}_i > p\}) fastp=N1i=1∑N1(correcti∧{speedupi>p})
关键点:
p=0代表 正确率fast_p曲线的 AUC 反映整体性能
此外评测机制覆盖:
- 确定性 kernel :逐元素误差阈值
- 低精度 kernel :允许 ρ \rho ρ 比例通过
- 随机 kernel :用 TVD 比较分布
6. Agent 评测结果:性能、正确性与失败模式
6.1 fast_p 曲线结果
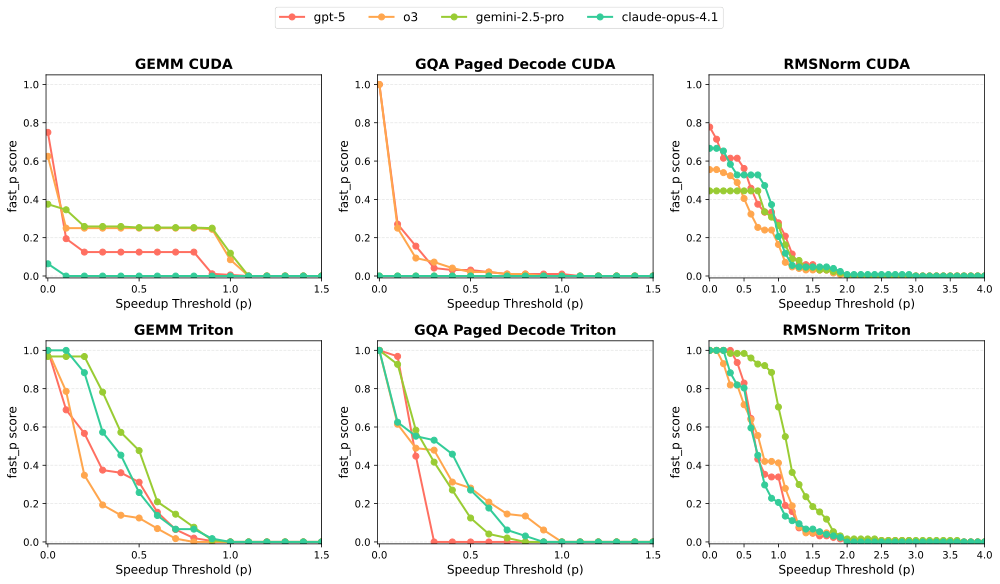
图解:图中横轴是速度提升阈值 p p p,纵轴是
fast_p。越往右越严格,曲线越高代表既正确又快的 workload 比例更高。
结论:
- GEMM / GQA :LLM 明显落后人类,超过半数 workload 低于 50% SOTA。
- RMSNorm :接近人类水平,因为它是 memory-bound。
6.2 错误类型统计
主要错误不是运行错误,而是 编译失败 :
- API 使用错误(Triton 常见)
- Host/Device 混淆
- dtype 或 shape 不匹配
6.3 语言对比:Triton vs CUDA
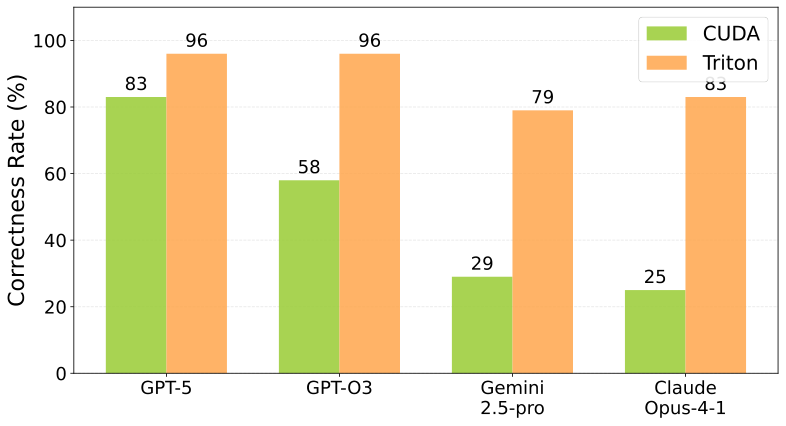
图解:这张图展示不同语言下的正确率。Triton 显著高于 CUDA,说明高层 DSL 更适合 LLM 生成。
核心结论:
- Triton :正确率高,开发负担低,但性能上限略低
- CUDA :更高潜力,但 AI 很难写对
7. Case Study:为什么 Triton 比 CUDA 更容易成功
7.1 GEMM:编译器自动"补完"
- Triton kernel 通过
autotune+tl.dot()自动利用tcgen05 - CUDA kernel 只能靠 WMMA,无法调用最新指令
结论: 高层 DSL 把硬件细节"藏"起来,让 LLM 更容易得到好结果。
7.2 GQA Paged Decode:CUDA 仍然太难
- CUDA kernel 无法实现复杂优化(tile、pipeline、async)
- 即使手动提示,LLM 也难以实现正确版本
结论: LLM 知道"怎么优化",但做不到"如何正确实现"。
8. 动态替换:apply() 是否真能提升系统端到端性能
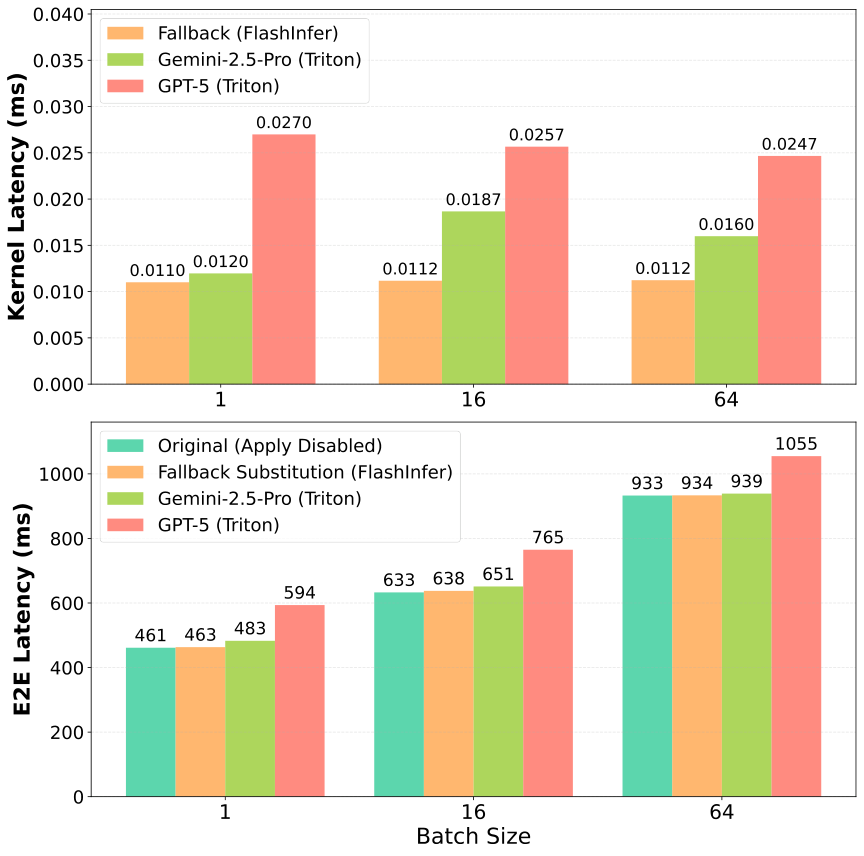
图解:上图比较 kernel 级延迟,下图对比端到端请求延迟。结果显示 kernel 级别收益可以稳定传递到系统级延迟。
实验发现:
apply()机制开销 仅 1-2 μs- 端到端延迟提升与 kernel 速度一致
- 速度更快的 kernel 直接带来系统吞吐提升
9. 结论与启示
核心贡献
- FITRACE :统一 kernel 描述、实现和评测
- FIB Dataset :真实 LLM workload 驱动
- Benchmark + Leaderboard :持续评测 AI kernel 能力
- apply() 部署机制 :让 kernel 生成进入生产流程
三个关键发现
- 编译失败是最大问题
- LLM 对硬件细节掌握不足
- Triton 正确率高,CUDA 潜力大但难度高
本文参考自 FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems