2026年1月14日,智谱AI发布了GLM-Image,这标志着AI图像生成技术的重要里程碑。这个突破性的模型是首个开源的工业级离散自回归图像生成系统,结合了90亿参数的自回归模块和70亿参数的扩散解码器,在文本渲染和知识密集型场景中表现出色。

如果你一直在寻找一个擅长创建海报、演示文稿和科学图表的AI图像生成模型,特别是需要准确的文本渲染(尤其是中文),GLM-Image提供了令人信服的解决方案。本综合指南涵盖了关于GLM-Image的所有内容,从技术架构到实际应用。
GLM-Image的革命性创新
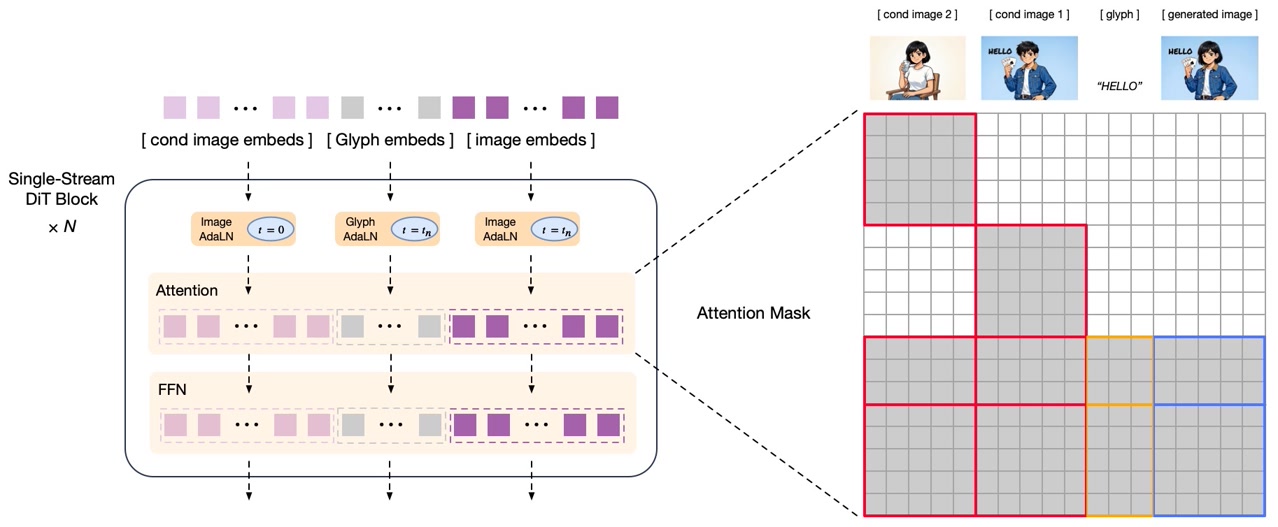
GLM-Image引入了一种混合架构,与传统的纯扩散模型有本质区别。通过结合自回归生成和扩散解码,它在理解复杂指令和渲染高保真细节方面实现了卓越性能。

混合架构设计
该模型采用两阶段生成过程:
第一阶段:自回归生成(90亿参数)
- 基于GLM-4-9B-0414基础模型
- 生成256-4096个紧凑的视觉token
- 处理文生图和图生图任务
- 使用MRoPE位置编码处理交错的图像文本序列
第二阶段:扩散解码器(70亿参数)
- 单流DiT(扩散Transformer)架构
- 集成轻量级Glyph-byT5模型用于文本渲染
- 输出高分辨率图像(1024px至2048px)
- 使用流匹配作为扩散调度策略
这种混合方法使GLM-Image在全局构图规划方面表现出色,同时保持精细的细节质量------这是纯扩散模型难以实现的组合。
卓越的文本渲染性能
文本渲染一直是AI图像生成中的持续挑战。GLM-Image以显著的准确性解决了这个问题:
CVTG-2k基准测试性能:
- GLM-Image:91.16%的词准确率
- Seedream 4.5:89.9%的词准确率
- 在英文文本渲染方面处于行业领先地位
LongText-Bench-ZH性能:
- 中文文本渲染准确率达97.88%
- 显著优于竞争模型
- 处理复杂的多行布局和段落级语义
这些结果使GLM-Image在创建营销材料、教育内容以及任何需要准确文本集成的应用中特别有价值。
技术规格与功能
了解GLM-Image的技术基础有助于你充分发挥其潜力。
模型架构详情
| 组件 | 规格 |
|---|---|
| 自回归模块 | 90亿参数(基于GLM-4-9B-0414) |
| 扩散解码器 | 70亿参数(单流DiT) |
| 输出分辨率 | 1024px - 2048px |
| 视觉token化 | 语义VQ token化 |
| 文本增强 | 集成Glyph-byT5 |
| 许可证 | MIT(开源) |
支持的生成任务
GLM-Image处理多种图像生成场景:
-
文生图生成
- 自然语言描述转图像
- 复杂的多主体构图
- 知识密集型内容创作
-
图生图转换
- 风格迁移和艺术渲染
- 图像编辑和修改
- 身份保留生成
-
多主体一致性
- 跨图像保持角色一致性
- 连贯的场景生成
- 品牌形象保持
GLM-Image与竞品模型性能对比
为了了解GLM-Image在当前AI图像生成领域的定位,让我们看看它与主要竞争对手的对比。
文本渲染对比
| 模型 | CVTG-2K | LongText-Bench EN | LongText-Bench ZH | 平均值 |
|---|---|---|---|---|
| GLM-Image | 0.9116 | 0.9557 | 0.7877 | 0.979 |
| Qwen-Image-2512 | 0.8604 | 0.9290 | 0.7819 | 0.965 |
| Z-Image | 0.8671 | 0.9367 | 0.7969 | 0.936 |
GLM-Image在英文文本渲染方面领先(CVTG-2K和LongText-Bench EN),使其成为西方市场和国际应用的首选。
通用图像生成性能
| 模型 | OneIG-Bench EN | OneIG-Bench ZH | TIIF-Bench Short | TIIF-Bench Long |
|---|---|---|---|---|
| GLM-Image | 0.528 | 0.511 | 81.01 | 81.02 |
| Nano Banana 2.0 | 0.578 | 0.567 | 91.00 | 88.26 |
| Qwen-Image | 0.539 | 0.548 | 86.14 | 86.83 |
虽然GLM-Image在整体图像生成得分上并不领先,但它在特定用例中表现出色:
GLM-Image的优势:
- 文本密集型构图(海报、信息图表)
- 知识密集型场景(教育材料、技术图表)
- 多步推理和推断任务
- 中文文本渲染准确性
何时选择其他模型:
- Midjourney/Flux:艺术质量和照片级真实感
- DALL-E 3:对话式界面和提示词遵循
- Stable Diffusion:本地部署和最大定制化
- Qwen-Image:平衡性能的通用图像生成
硬件要求与系统配置
了解硬件要求有助于你有效规划GLM-Image的实施。
GPU显存要求
GLM-Image的计算需求因配置而异:
单GPU配置:
- 最低要求:80GB+显存(推荐)
- 示例:NVIDIA H100(80GB)或A100(80GB)
- 性能:完整模型能力和最佳速度
多GPU配置:
- 支持分布式推理
- 降低单GPU显存要求
- 增加整体系统复杂性
分辨率限制
所有生成的图像尺寸必须能被32整除:
有效分辨率:
- 1024×1024(标准正方形)
- 1024×768(4:3横向)
- 768×1024(3:4纵向)
- 1152×896(自定义宽屏)
无效分辨率:
- 1000×1000(不能被32整除)
- 1920×1080(1920可以,但1080不行)
性能基准
生成时间因硬件和分辨率而异:
H100 GPU(80GB):
- 1024×1024分辨率:每张图片约64秒
- 更高分辨率:成比例延长
优化考虑:
- vLLM-Omni集成:进行中
- SGLang支持:开发中
- 当前推理成本:相对较高
GLM-Image快速上手
使用GLM-Image有两种主要方法:通过transformers/diffusers管道或通过SGLang进行生产部署。
方法1:Transformers + Diffusers管道
这种方法适合开发和实验。
安装:
pip install git+https://github.com/huggingface/transformers.git pip install git+https://github.com/huggingface/diffusers.git
文生图生成:
import torch from diffusers.pipelines.glm_image import GlmImagePipeline # 加载模型 pipe = GlmImagePipeline.from_pretrained( "zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda" ) # 生成图像 prompt = "一张现代美食杂志风格的甜点食谱插图,配有优雅的排版" image = pipe( prompt=prompt, height=32 * 32, width=36 * 32, num_inference_steps=50, guidance_scale=1.5, generator=torch.Generator(device="cuda").manual_seed(42), ).images[0] image.save("output_t2i.png")
图生图生成:
import torch from diffusers.pipelines.glm_image import GlmImagePipeline from PIL import Image # 加载模型 pipe = GlmImagePipeline.from_pretrained( "zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda" ) # 加载参考图像 image_path = "reference.jpg" prompt = "将这个场景转换为赛博朋克风格,配上霓虹灯光" reference_image = Image.open(image_path).convert("RGB") # 生成转换后的图像 output = pipe( prompt=prompt, image=[reference_image], height=33 * 32, width=32 * 32, num_inference_steps=50, guidance_scale=1.5, generator=torch.Generator(device="cuda").manual_seed(42), ).images[0] output.save("output_i2i.png")
方法2:SGLang生产部署
SGLang为生产环境提供优化的推理。
安装:
pip install "sglang[diffusion] @ git+https://github.com/sgl-project/sglang.git#subdirectory=python" pip install git+https://github.com/huggingface/transformers.git pip install git+https://github.com/huggingface/diffusers.git
启动服务器:
sglang serve --model-path zai-org/GLM-Image
API调用示例:
curl http://localhost:30000/v1/images/generations \ -H "Content-Type: application/json" \ -d '{ "model": "zai-org/GLM-Image", "prompt": "一张专业的商务演示幻灯片,配有清晰的排版", "n": 1, "response_format": "b64_json", "size": "1024x1024" }' | python3 -c "import sys, json, base64; open('output.png', 'wb').write(base64.b64decode(json.load(sys.stdin)['data'][0]['b64_json']))"
优化GLM-Image生成质量
要从GLM-Image获得最佳结果,需要了解其优势并相应优化工作流程。
使用GLM-4.7增强提示词
为获得最佳效果,在生成前使用GLM-4.7增强提示词:
基础提示词: "一张关于环保的海报"
GLM-4.7增强后的提示词: "一张现代环保海报,以充满活力的绿色地球为特色,周围环绕着可再生能源符号(太阳能板、风力涡轮机),配有翠绿色的粗体无衬线字体'保护我们的星球',白色背景的简约设计,专业平面设计风格"
增强后的提示词提供了关于构图、排版、颜色和风格的具体细节------这些都是GLM-Image擅长渲染的元素。
采样参数
GLM-Image使用特定的默认参数,适用于大多数场景:
默认配置:
do_sample=Truetemperature=0.9top_p=0.75num_inference_steps=50guidance_scale=1.5
何时调整:
- 降低温度(0.7):更一致、可预测的结果
- 提高温度(1.0):更有创意、多样化的输出
- 减少步数(25-30):更快生成,质量略低
- 增加步数(75-100):更高质量,生成时间更长
GLM-Image的最佳应用场景
GLM-Image在特定场景中表现出色:
1. 营销材料
- 带有突出文本元素的海报
- 带有数据可视化的信息图表
- 带有标题的社交媒体图形
- 带有品牌信息的广告设计
2. 教育内容
- 带有标签的科学图表
- 带有注释的技术插图
- 带有清晰排版的演示幻灯片
- 带有分步文本的教学材料
3. 知识密集型场景
- 准确细节的历史重现
- 技术文档插图
- 学术海报展示
- 复杂数据的研究可视化
常见问题与解决方案
了解潜在挑战有助于你有效排除故障。
内存管理
问题:生成过程中出现内存不足错误
解决方案:
- 将分辨率降低到1024×1024或更低
- 使用多GPU设置分散内存负载
- 关闭其他GPU密集型应用程序
- 在生成过程中监控显存使用情况
分辨率错误
问题:"分辨率必须能被32整除"错误
解决方案:
- 验证宽度和高度都是32的倍数
- 使用标准分辨率:1024×1024、1024×768、768×1024
- 计算自定义分辨率:(期望尺寸 // 32) × 32
文本渲染质量
问题:文本显得模糊或不正确
解决方案:
- 使用GLM-4.7增强提示词,添加具体的排版细节
- 将num_inference_steps增加到75-100
- 在提示词中指定字体样式、大小和颜色
- 避免在单次生成中使用过于复杂的文本布局
未来发展与路线图
GLM-Image持续发展,正在进行优化工作:
当前开发:
- vLLM-Omni集成以实现更快的推理
- SGLang优化用于生产部署
- 内存效率改进
- 扩展分辨率支持
社区资源:
总结
GLM-Image代表了AI图像生成领域的重大进步,特别是在需要准确文本渲染和知识密集型内容创作的应用中。其混合自回归-扩散架构在特定用例中提供了卓越的性能,使其成为营销专业人士、教育工作者和内容创作者的宝贵工具。
虽然本地部署的硬件要求很高,但该模型的开源性质和MIT许可证确保了研究和商业应用的可访问性。对于那些寻求即时访问而无需基础设施投资的人,ZImage.run提供了生产就绪的GLM-Image功能,具有专业特性和多模型支持。
随着AI图像生成领域的持续发展,GLM-Image对文本渲染准确性和知识密集型场景的关注使其成为一个专业工具,它补充而非竞争通用模型。无论你是创建教育材料、营销活动还是技术文档,GLM-Image都提供了解决AI生成图像中实际挑战的能力。
参考资料: