文章目录
1 什么是RAG
2 构建RAG实战
3 总结与思考
1 什么是RAG
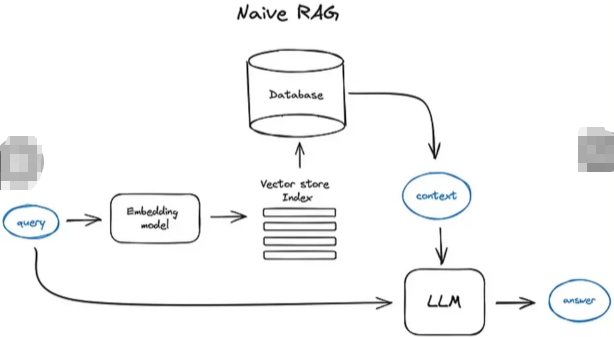
RAG(Retrieval-Augmented Generation)检索增强生成
Facebook AlResearch团队于2020年首次提出,通过在生成过程中引入外部知识库,RAG能够动态检索相关信息,从而增强生成内容的质量。
RAG通过更新外部知识库,可以提供给模型生成更实时的内容。这种技术适用于多种应用场景,如问答系统、文档生成和智能助手等。
提高文本生成质量
增强可解释性灵活性和可扩展性
减少幻觉问题
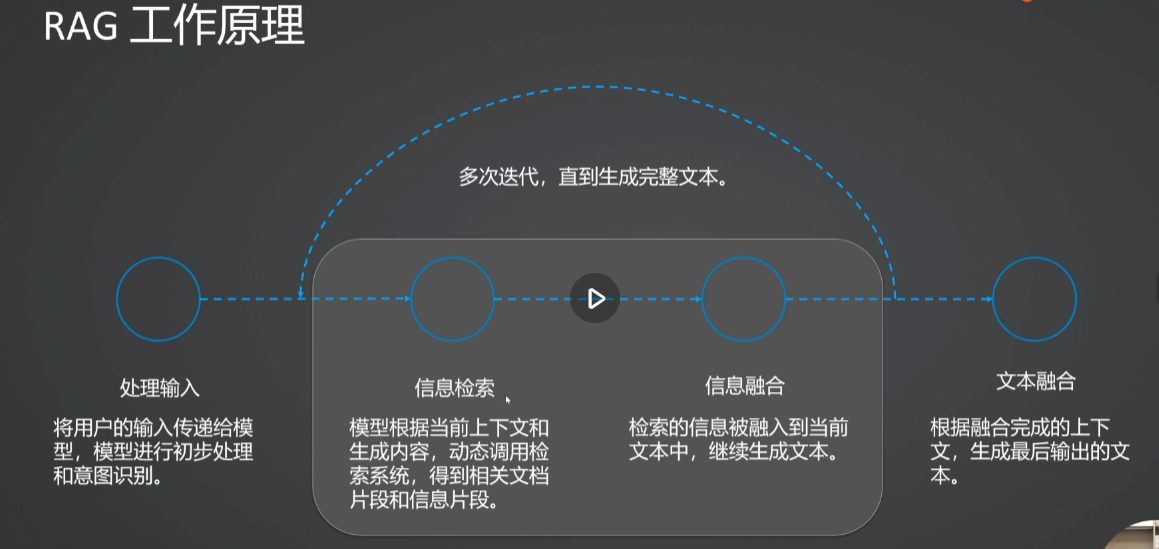
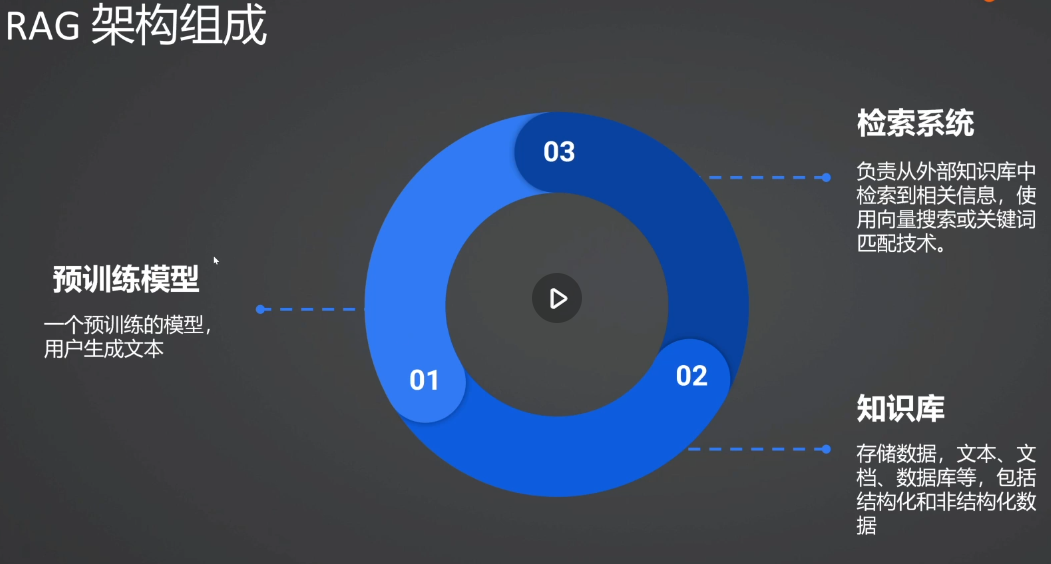
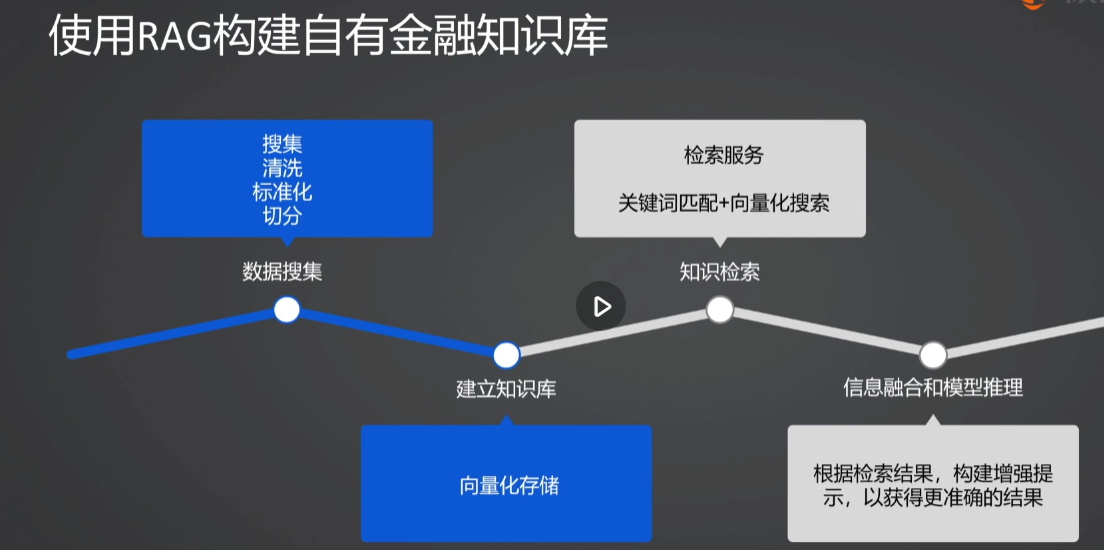
2.构建RAG实战
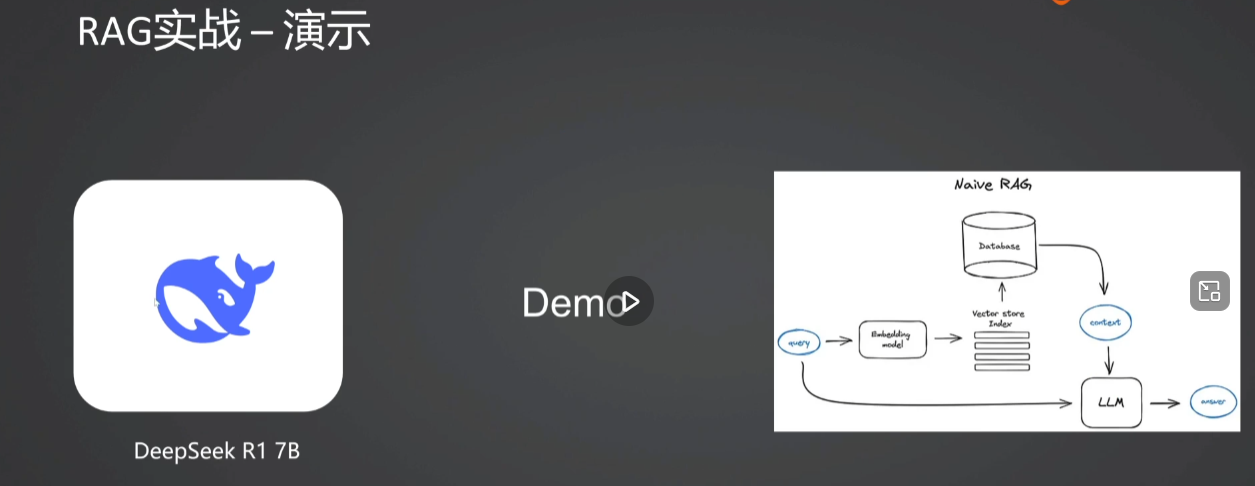
python
# 步骤1:导入所需要的库,确定是否有GPU
import torch
print(torch.__version_)
print(torch.cude.is_available())
# 步骤2:安裝第三方包,魔塔云已安装modelscope
# pip install langchain langchain-community sentence-transformers
# 步骤3:构造文件列表
data = [
{
"instruction": "股票交易有哪些常见风险?",
"input": "",
"output": "股票交易的风险包括市场风险、政策风险、公司经营风险等。投资者应合理分散投资,关注宏观经济环境和行业动态。"
},
{
"instruction": "如何理解货币基金的收益?",
"input": "",
"output": "货币基金的收益通常以七日年化收益率表示,但并非实际收益。投资者应关注基金的历史业绩和管理团队的专业水平。"
},
{
"instruction": "债券和股票哪个更适合稳健型投资者?",
"input": "",
"output": "债券通常比股票更适合稳健型投资者。债券风险相对较小,收益较为稳定,而股票则波动较大,适合追求高收益的投资者。"
},
{"instruction":"可转债风险大吗?和股票比风险大还是小?",
"input":"",
"output":"可转债和股票相比较,风险是比较小一些的,打新债需要先开账户,开户完之后的2,个交易日就可以打新债了。开户流程如下1.打开优选开户链接,点击开户;2.输入手机号和验证码;3.填写个人信息;4.视频认证;5.完成风险测评问题;6.3.6存管银行7.最后提交申请,等待审核。"
},
{
"instruction":"股票没有委托交收单可以吗?",
"input": "",
"output": "可以,当有相同价格的买单或者卖单就可以成交,股票按照价格优先、时间优先的原则进行成交。若委托单在交易时间未成交也未撤单的,那么股票清算后自动撤销该笔委托单,股票清算时间:交易日下午13: 00到晚上22: 00点。股票交易时间:周一至周五上午9: 30-11: 30,下午13: 00-15: 00。法定节假日不交易。"
},
{
"instruction":"除权的股票能长期持股吗?",
"input": "",
"output":"除权是股票分红的一个阶段,对股票涨跌没有影响,股票是长期持有不需要看是否除权,主要看股票是否具有投资价值。投资者可以根据基本面、技术面、消息面等情况分析股票是否具有投资价值。基本面主要分析财务指标、股东情况、公司状况等,财务指标看现金流量表(表示公司周转的资金,越多越好),资产负债表(表示公司负债情况,负债较少越好。主要看流动比率和速动比率)和利润表(表示公司收入,越多越好)。股东情况是公司基本概况包括:流通股东数,非流通股东,大股东权益,实际控制人,解禁时间等。公司概况是公司是行业是什么,公司比主要经营业务,投资者可以看分析主营业务是否具有发展情况。技术面主要风险指标,KDJ指标:当K线上穿D线时,形成金叉买入信号,RSI指标:当DIFF线上穿DEA线时,形成金叉是买进信号,均线指标:当短期均线向上穿过长期均线时,形成金叉是买入信号,K线组合:早晨之星、曙光初现、红三兵等是买入信号。消息面主要分析有没有利好上市公司业务发展的政策和消息等。这些政策和消息会利于股票上涨。"
}
]
# 步骤4:导入文本处理和导入模型相关的库
from langchain_core.embeddings import Embeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import SKLearnVectorStore
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download,AutoModelForCausalLM, AutoTokenizer
# 步骤5:下载模型文件
sentence_embedding_dir = snapshot_download('iic/nlp_gte_sentence-embedding_chinese-base')
qwen_model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B')
# 步骤6:文本分块
doc_list = [f"{doc['instruction']}\n{doc['output']}" for doc in data]
print(doc_list)
text_spliter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=250, chunk_overlap=200)
doc_splits = text_spliter.create_documents(doc_list)
# 步骤7:创建嵌入模型类
class SentenceTransformerEmbeddings(Embeddings):
def __init__(self, model_name):
self.model = SentenceTransformer(model_name)
def embed_documents(self, texts):
"""Embed a list of texts."""
return self.model.encode(texts, show_progress_bar=True)
def embed_query(self, text):
"""Embed a single query."""
return self.model.encode([text], show_progress_bar=False)[0]
# 步骤8:创建向量数据库
db = SKLearnVectorStore.from_documents(documents=doc_splits,
embedding=SentenceTransformerEmbeddings(model_name=sentence_embedding_dir))
# 步骤9:创建检索器
retriever = db.as_retriever(k=4)
# 步骤10:查询与文档检索
query = "可转债风险大吗?和股票比风险大还是小?"
documents = retriever.invoke(query)
doc_texts = "n".join([f"文档{index+1}\n{doc.page_content}" for index, doc in enumerate(documents)])
print(f'召回文档:\n{doc_texts}')
# 步骤11:构建对话模板并生成答案
messages = [
{"role": "system",
"content": "你是一个金融知识问答机器人,根据以下上下文回答问题,如果不知道请回答不知道。上下文:" + doc_texts},
{"role": "user",
"content": query}
]
# 步骤12:加载LM模型和Tokenizer
llm = AutoModelForCausalLM.from_pretrained(qwen_model_dir, torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(qwen_model_dir)
# 步骤13:模型生成答案
text = tokenizer.apply_chat_template(messages,tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(llm.device)
generated_ids = llm.generate(**model_inputs, max_new_tokens=512)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
# 步骤14:输出结果
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("Question: 可转债风险大吗?和股票比风险大还是小?")
print(f"Answer: {response}")3.总结与思考
1.RAG检索的过程主要分为几个步骤?
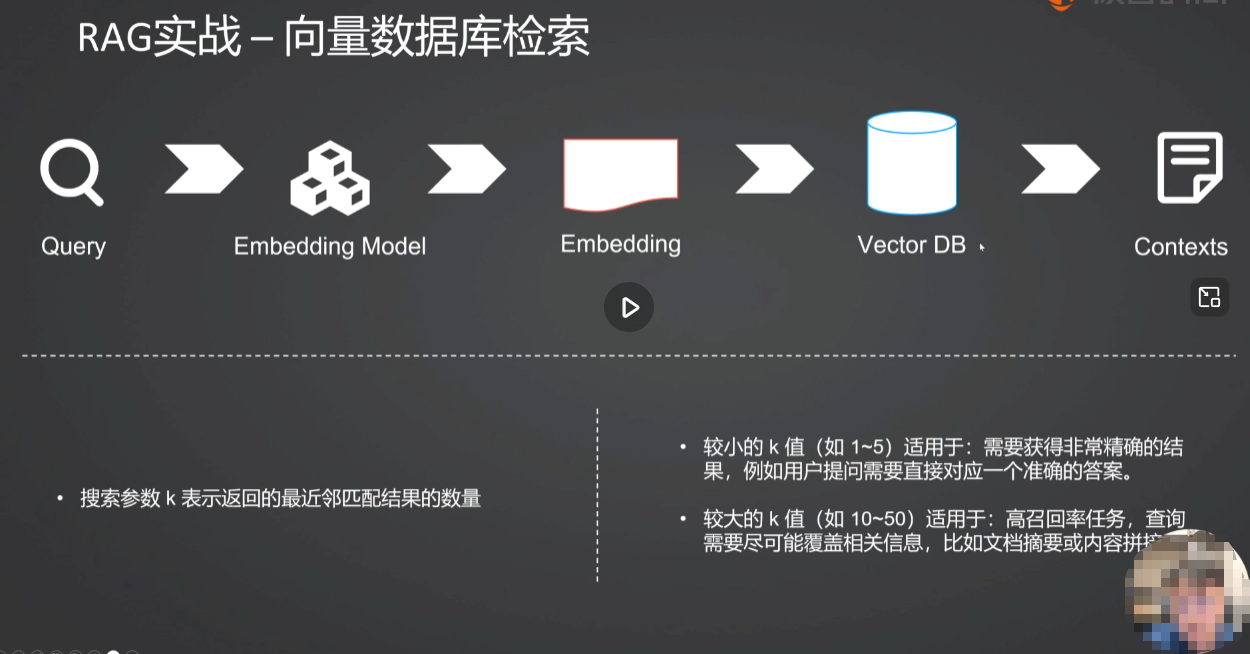
2.文档检索步骤可以被分为哪两个阶段?
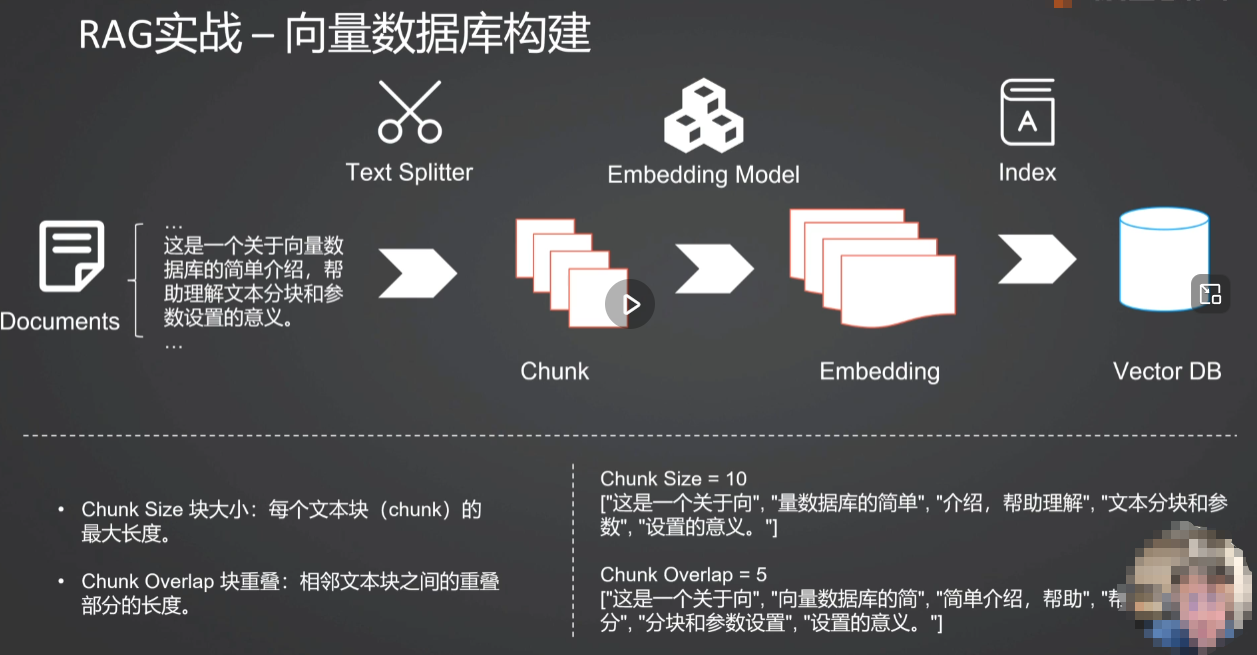
3.Chunk Size和Chunk Overlap的作用分别是什么?
4.RAG搜索时的检索参数K的大小对结果会有什么影响?