此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第五课第一周的课后习题和代码实践部分。
1.理论习题
【中英】【吴恩达课后测验】Course 5 - 序列模型 - 第一周测验
本周的理论习题中有一道较为巧妙,我们来看看:
这里有一些GRU的更新方程:
爱丽丝建议通过移除 \(Γ_u\) 来简化GRU,即设置 \(Γ_u=1\)。贝蒂提出通过移除 \(Γ_r\) 来简化GRU,即设置 \(Γ_r=1\)。哪种模型更容易在梯度不消失问题的情况下训练 ,即使在很长的输入序列上也可以进行训练?
答案: 贝蒂的模型(即移除\(Γ_r\)),因为对于一个时间步而言,如果\(Γ_u≈0\),梯度可以通过时间步反向传播而不会衰减。
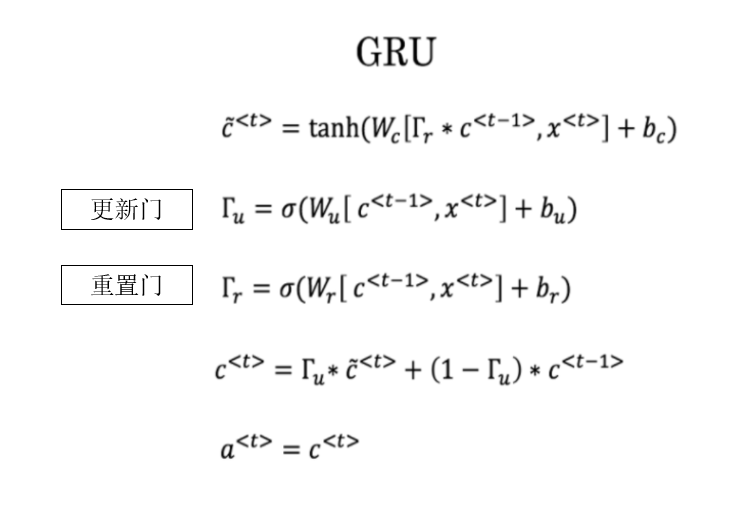
我们先回顾一下GRU中两道门的语义:
- 重置门:控制在计算当前候选隐藏状态时,上一时刻隐藏状态是否被抑制。
- 更新门:控制当前隐藏状态中,上一时刻隐藏状态与当前候选隐藏状态的融合比例。
现在再来看一下题中的两种简化逻辑:
- 移除 \(Γ_u\):令更新门恒为 1,此时当前隐藏状态完全由候选隐藏状态决定。
- 移除 \(Γ_r\):令重置门恒为 1,使候选隐藏状态在计算时不再抑制上一时刻的隐藏状态。
看到这里,我们可能看不出什么问题,因为只看语义,二者都是一种简化,无法直观看出对训练效果影响的程度。
这道题的关键在于题目中的:更容易在梯度不消失问题的情况下训练 。
也就是说,我们要看的应该是两种简化对梯度传递的影响 。
这就要回到公式了,我们来看看两种简化后的传播公式:

这里就可以很明显的发现:如果删去更新门,就是删去了时间步间的梯度直连通道 。而删去重置门则不会造成这一点。
显然,删除更新门会让梯度在时间步间的传播路径更长,梯度只能通过非线性变换反向传播,更容易衰减,自然就更容易造成梯度消失,由此得到答案。
2.代码实践
依旧还是先摆上这位博主的链接,这篇博客非常详细地展示了手动搭建 RNN、LSTM 等本周理论内容的过程。
我们依旧还是用成熟框架来演示本周所了解的内容,任务类型为命名实体识别,涉及模型列举如下:
- 单层单向 RNN
- 单层双向 RNN
- 单层双向 GRU
- 单层双向 LSTM
- 多层双向 LSTM
2.1 数据集:CoNLL-2003
在本节的代码实践中,我们选用 CoNLL-2003 命名实体识别数据集 作为数据集。
它是序列标注任务中最经典、也最常用的数据集之一,是一个词级别的序列标注数据集。
需要补充的是,关于命名实体识别任务,我们在之前的理论部分里仅使用 0/1 来进行人名的识别,但实际上的命名实体识别显然内容更丰富,并且对于各类实体的标签标注,也有一套主流的成熟标注体系,被称为 BIO 标注体系 。
并不复杂,BIO 的三个核心符号含义如下:
- B-类型 (Begin):表示这个词是一个实体的开头(第一个词)。
- I-类型 (Inside):表示这个词是实体的内部(非第一个词)。
- O (Outside):表示这个词不属于任何实体。
其中,B、I 后会接任务定义的实体命名。
来看一个实例:河北 2026 年 1 月 14 日 天气 很好
| 词 | 标签 | 解释 |
|---|---|---|
| 河北 | B-LOC | 地名的开头 |
| 2026 | B-TIME | 时间表达的开头 |
| 年 | I-TIME | 时间的内部 |
| 1 | I-TIME | 时间的内部 |
| 月 | I-TIME | 时间的内部 |
| 14 | I-TIME | 时间的内部 |
| 日 | I-TIME | 时间的内部 |
| 天气 | O | 非实体 |
| 很 | O | 非实体 |
| 好 | O | 非实体 |
CoNLL-2003 同样采用 BIO 标注体系,并定义了四类命名实体如下:
| 实体类型 | 含义 | BIO 标签示例 | 说明 |
|---|---|---|---|
| PER | 人名(Person) | B-PER, I-PER |
表示人物姓名及其组成部分 |
| ORG | 组织机构(Organization) | B-ORG, I-ORG |
公司、政府机构、学校等 |
| LOC | 地名(Location) | B-LOC, I-LOC |
国家、城市、地区等地理名称 |
| MISC | 其他专有名词(Miscellaneous) | B-MISC, I-MISC |
其他不属于上述类别的专名 |
| O | 非实体 | O |
不属于任何命名实体的普通词 |
了解了 CoNLL-2003 这类数据集的序列标注逻辑后,回到数据本身:
CoNLL-2003 数据集已经被官方划分为训练集、验证集和测试集三部分,其中:
- 训练集 :约 14,000 句。
- 验证集 :约 3,000 句。
- 测试集 :约 3,500 句。
总计包含 20,000+ 条标注句子,词级样本数量在 20 万级别。
CoNLL-2003 的下载接口同样在被封装在 python 的许多第三方库中,其中一个选择是 PyTorch 官方维护的一个 NLP 工具库:torchtext :
python
pip install torchtext安装后,便可以这样导入CoNLL-2003 的下载接口:
python
from torchtext.datasets import CoNLL2003但是,由于torchtext并非torch 的子模块,需要单独安装,且高度依赖和torch间的版本匹配,因此在实际安装中可能出现很多兼容性问题。
因此,我们选择另一个兼容性更好且实际上在这类使用上也更流行的库:HuggingFace 的 datasets:
python
pip install datasets安装后,便可以这样导入:
python
from datasets import load_dataset这样,我们就完成了数据集本身的准备,打印几条示例数据如下:

2.2 数据预处理
完成数据集准备后,自然下一步就要开始让数据输入模型,但序列数据不同于我们之前的图像,统一预处理后就可以输入网络,在 RNN 中,我们需要在数据预处理中花更多功夫,具体如下:
(1)导入相关库
开局当然还是先导库,在 NLP 相关任务中,这些相关库都很常见,尤其是python内置的collections库,我们常用它来统计语料库,构建词典。
python
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_sequence # 用于对不同长度的序列进行填充,使得批次张量对齐。
from datasets import load_dataset # 导入 CoNLL-2003 数据集。
from collections import Counter # 用于统计词频和标签频率,便于构建词表和标签表。
from torch.utils.data import DataLoader # 标配,提供批次化处理和打乱数据集功能。(2)加载数据集
这步很简单,就不多解释了:
python
# 使用 HuggingFace datasets 加载数据
dataset = load_dataset("conll2003")
# 分别获取训练集、验证集、测试集
train_data = dataset['train']
valid_data = dataset['validation']
test_data = dataset['test'](3)构建词表和标签表
就像我们在理论部分介绍的,在做序列任务中,我们需要把文本和标签都转成索引形式,即计算机能理解的词典。
这里我们先用 Counter 统计词频和标签频率,然后构建词表和标签表。
在这里需要补充的内容是填充符<PAD> ,因为模型需要固定维度的输入,而序列往往长度不同,因此我们需要对不同长度的序列进行填充 来适配模型输入。
举个简单的例子:
| 填充前 | 填充后 |
|---|---|
| Hello my firend | Hello my firend |
| Hi | Hi <PAD>``<PAD> |
同样,当输入序列中出现<PAD>时,其对应的标签也是<PAD>。
在代码中,我们一般设置输入 序列中的<PAD>的 ID 为 0,但在标签 序列中则不同,我们一般设定为一个特殊值,比如下面的 -100,这个特殊值会被特殊记录,在计算损失时会忽略该位置的损失计算。
因为它本身的作用就是填充序列长度,模型不需要在这里浪费计算性能,也无法从这里学习信息。
编码如下:
python
# 统计词频和标签频率
# Counter():用来统计元素出现次数的字典
word_counter = Counter()
tag_counter = Counter()
for item in train_data:
words = item['tokens'] # 单词列表
tags = item['ner_tags'] # 标签索引
tag_counter.update(tags) # 统计标签
word_counter.update(words) # 统计词频
# 构建词表
word_vocab = {w: i + 2 for i, (w, _) in enumerate(word_counter.most_common())}
# word_counter.most_common() :返回按词频从高到低排列的 (单词, 出现次数) 列表。
# i + 2 我们给单词分配整数 ID,从 2 开始。
# {w: i + 2 for i, (w, _) in ...} :通过字典推导式,把每个单词 w 映射为对应的整数 ID。
# 最终 word_vocab = {'I':2, 'love':3, 'Python':4, ...}
word_vocab["<PAD>"] = 0 # 填充符
word_vocab["<UNK>"] = 1 # 未知词
# 构建标签表
tag_vocab = {t: t for t in tag_counter.keys()} # 标签索引直接映射自己
pad_tag_id = -100 # 定义 PAD 标签索引,在后续损失函数参数中使用。
num_classes = len(tag_vocab) # 预测类别,定义输出层
vocab_size = len(word_vocab) # 用于独热编码(4)定义编码函数
定义好好词表和标签表本身后,我们还需要定义第一个编码函数,它的作用就是把文本信息对照词典转换为计算机能理解的编码。 我们下一步就会通过这个函数来处理数据集。
同时,这一步还像是之前卷积网络中的 transform 方法,把在输入模型前,把数据转换成 PyTorch 要求的Tensor 张量。
不过和图像不同的是,这里处理的是文本序列。而 transform 针对的是图像数据,且处理逻辑也不同,因此并不能在这里直接使用。
python
# 将单条样本的单词和标签编码为 Tensor
def encode(item):
words = item['tokens']
tags = item['ner_tags']
x = torch.tensor([word_vocab.get(w, 1) for w in words], dtype=torch.long)
# 这段逻辑是,对于每个词:如果在词表里找到就返回其索引,如果没找到,就返回 1,即 <UNK> 的索引
y = torch.tensor(tags, dtype=torch.long)
# 标签索引
return x, y(4)数据填充和构建迭代器
到这一步,我们已经拥有了词典和相应的编码函数,自然,我们可以使用它们对数据进行预处理了,这一步的工作分为三部分:
- 定义填充函数。
- 使用编码函数对划分好的数据进行编码。
- 使用编码好的数据与填充函数,完成最终的批次迭代器定义。
python
# 自定义填充函数
def collate_fn(batch): # 参数为一批次数据
xs, ys = zip(*batch) # 把(样本,标签)拆成(样本,样本)和(标签,标签)
xs_pad = pad_sequence(xs, batch_first=True, padding_value=word_vocab["<PAD>"]) # pad_sequence 方法会自动找到最长序列并补充填充同一批次中其他序列到该长度。
# 不同批次的填充长度可以不同。
ys_pad = pad_sequence(ys, batch_first=True, padding_value=pad_tag_id)
return xs_pad.to(device), ys_pad.to(device)
# 对所有数据进行编码
train_dataset = [encode(item) for item in train_data]
valid_dataset = [encode(item) for item in valid_data]
test_dataset = [encode(item) for item in test_data]
# 使用编码好的数据划分批次,进行填充
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, collate_fn=collate_fn)
valid_loader = DataLoader(valid_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)至此,我们才完成了在数据集在输入模型前的预处理工作,下一步,自然就是要定义模型了。
2.3 定义 RNN 模型
同样,对于 RNN ,PyTorch 也有封装好的方法,我们定义要用的 RNN 模型如下:
python
class RNNTagger(nn.Module):
def __init__(self, vocab_size, hidden_dim, num_classes,
rnn_type='RNN', bidirectional=False, num_layers=1):
# 使用多个参数,方便我们调用不同模型,默认为单层单向 RNN
super().__init__()
self.vocab_size = vocab_size # 词表
self.bidirectional = bidirectional # 是否双向
self.rnn_type = rnn_type.upper() # 使用的循环单元
input_size = vocab_size # 使用独热编码,独热编码输入维度 = 词表大小
# 使用普通 RNN
if self.rnn_type == 'RNN':
self.rnn = nn.RNN(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
# 使用 LSTM
elif self.rnn_type == 'LSTM':
self.rnn = nn.LSTM(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers) # 使用 GRU
elif self.rnn_type == 'GRU':
self.rnn = nn.GRU(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
else:
raise ValueError("rnn_type must be 'RNN','LSTM','GRU'")
# 输出层
self.fc = nn.Linear(hidden_dim * (2 if bidirectional else 1), num_classes)
def forward(self, x):
# x: [batch, seq_len], 转独热
x_onehot = torch.nn.functional.one_hot(x, num_classes=self.vocab_size).float()
out, _ = self.rnn(x_onehot) #在这里就封装了按时间步传播的逻辑
out = self.fc(out)
return out在这里,你会发现,RNN、LSTM、GRU 都被封装成了单独的模型,我们只需要更改其参数,即可修改其深度和是否双向等。
最后,就是定义相应训练和验证逻辑了。
2.4 训练与验证
我们这次把整个训练与验证逻辑也定义为函数,方便之后使用不同的模型调用:
python
def train_validate(model, train_loader, valid_loader, epochs=5, lr=0.001):
model.to(device)
# 在损失函数种使用ignore_index参数来忽略对<PAD>的损失计算
criterion = nn.CrossEntropyLoss(ignore_index=pad_tag_id)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
train_loss_history = []
train_acc_history = []
val_acc_history = []
val_f1_history = []
epoch_times = []
total_start_time = time.time()
for epoch in range(epochs):
epoch_start_time = time.time()
# ========= 训练 =========
model.train()
total_loss = 0
total_correct = 0
total_tokens = 0
for x_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(x_batch)
outputs_reshape = outputs.view(-1, num_classes)
y_batch_reshape = y_batch.view(-1)
loss = criterion(outputs_reshape, y_batch_reshape)
loss.backward()
optimizer.step()
total_loss += loss.item()
preds = outputs.argmax(dim=-1)
for i in range(y_batch.size(0)):
mask = y_batch[i] != pad_tag_id
total_correct += (preds[i][mask] == y_batch[i][mask]).sum().item()
total_tokens += mask.sum().item()
avg_train_loss = total_loss / len(train_loader)
train_acc = total_correct / total_tokens
train_loss_history.append(avg_train_loss)
train_acc_history.append(train_acc)
# ========= 验证 =========
model.eval()
val_total_correct = 0
val_total_tokens = 0
all_preds = []
all_labels = []
with torch.no_grad():
for x_val, y_val in valid_loader:
outputs = model(x_val)
preds = outputs.argmax(dim=-1)
for i in range(y_val.size(0)):
mask = y_val[i] != pad_tag_id
val_total_correct += (preds[i][mask] == y_val[i][mask]).sum().item()
val_total_tokens += mask.sum().item()
all_preds.extend(preds[i][mask].cpu().tolist())
all_labels.extend(y_val[i][mask].cpu().tolist())
val_acc = val_total_correct / val_total_tokens
# ⭐ token-level F1(macro)
val_f1 = f1_score(all_labels, all_preds, average='macro')
val_acc_history.append(val_acc)
val_f1_history.append(val_f1)
epoch_time = time.time() - epoch_start_time
epoch_times.append(epoch_time)
print(
f"轮次 {epoch+1}: "
f"训练损失={avg_train_loss:.4f}, "
f"训练准确率={train_acc:.4f}, "
f"验证准确率={val_acc:.4f}, "
f"验证F1={val_f1:.4f}, "
f"本轮用时={epoch_time:.2f} 秒"
)
total_time = time.time() - total_start_time
avg_epoch_time = sum(epoch_times) / len(epoch_times)
print("\n======== 训练时间统计 ========")
print(f"总训练时间:{total_time:.2f} 秒")
print(f"平均每轮用时:{avg_epoch_time:.2f} 秒")
history = {
'train_loss': train_loss_history,
'train_acc': train_acc_history,
'val_acc': val_acc_history,
'val_f1': val_f1_history
}
return model, history自此,我们终于完成了主要的代码工作,下面就来运行看看吧。
2.5 运行结果
(1) 单层单向 RNN
首先,先试试最基础的单层单向 RNN,我们在主函数里这样调用它:
python
if __name__ == '__main__':
# 定义参数
cfg = {'rnn_type':'RNN','bidirectional':False,'num_layers':1}
# 传入模型
model = RNNTagger(vocab_size=len(word_vocab),
hidden_dim=128,
num_classes=num_classes,
rnn_type=cfg['rnn_type'],
bidirectional=cfg['bidirectional'],
num_layers=cfg['num_layers'])
# 进行训练
model, history = train_validate(model, train_loader, valid_loader, epochs=5) # 可视化
plot_training_curves(history) 需要强调的是:RNN 通常不需要设置过多的训练轮次 ,这是因为其训练采用时间反向传播,梯度需要沿时间维度逐步传递,时间步一长就容易出现梯度消失或爆炸的问题,使得后期训练收益迅速降低。
实践中,RNN 往往在前几轮就学到主要的序列模式,继续增加 epoch 不仅提升有限,还可能导致验证性能波动甚至过拟合,因此相比其他模型,RNN 的训练轮次通常设置得相对较少。
现在来看看运行结果:
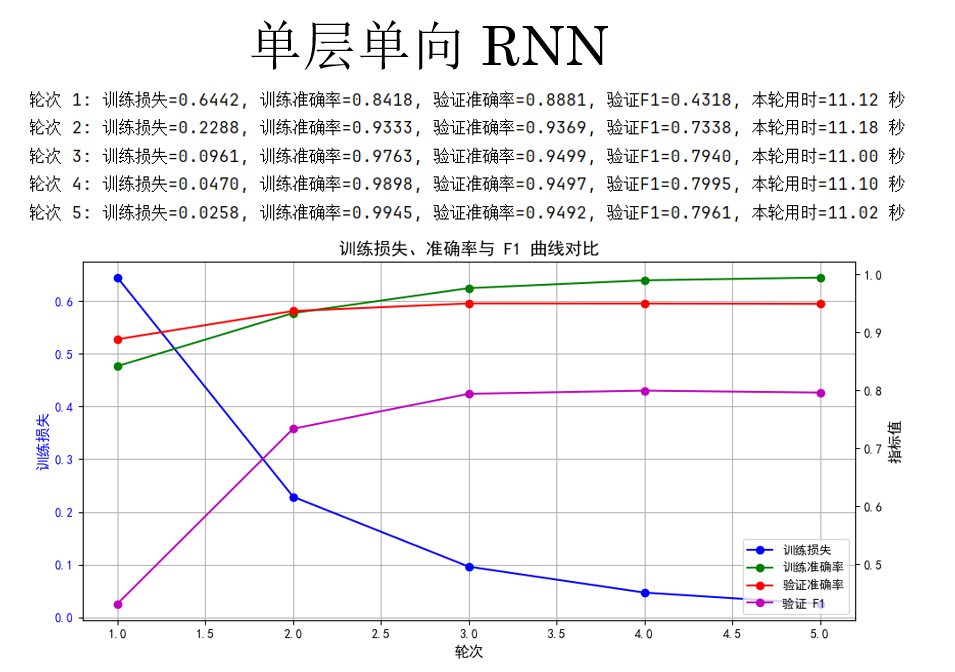
这里有一个问题,你会发现:F1 分数明显要比准确率低一截。
原因在于,序列标注任务中的类别分布通常是极度不均衡的 。以命名实体识别为例,大部分词实际上都属于非实体类别(如 O),模型即使只是"保守地"把绝大多数位置预测为 O,也能获得相当可观的准确率。这种情况下,准确率更多反映的是模型对"多数类"的拟合能力,而非对实体边界和类别的真实识别能力 。
相比之下,F1 分数同时考虑了精确率和召回率 ,只有当模型既能正确识别实体、又不过度漏掉实体时,F1 才会提高。因此,在命名实体识别这类关注"少数但关键结构"的任务中,F1 能更真实地刻画模型的实际效果。
也正因如此,在序列标注任务中,准确率往往具有较强的迷惑性,而 F1 才是更具判别力、也更被广泛采用的核心评价指标 。
我们继续,看看其他模型的表现。
(2)单层双向 RNN
第二个实验对象,单层双向 RNN,我们只需要更改一个参数:
python
if __name__ == '__main__':
# 定义参数: 'bidirectional':True
cfg = {'rnn_type':'RNN','bidirectional':True,'num_layers':1}
# 传入模型
model = RNNTagger(vocab_size=len(word_vocab),
hidden_dim=128,
num_classes=num_classes,
rnn_type=cfg['rnn_type'],
bidirectional=cfg['bidirectional'],
num_layers=cfg['num_layers'])
# 进行训练
model, history = train_validate(model, train_loader, valid_loader, epochs=5) # 可视化
plot_training_curves(history) 来看结果:
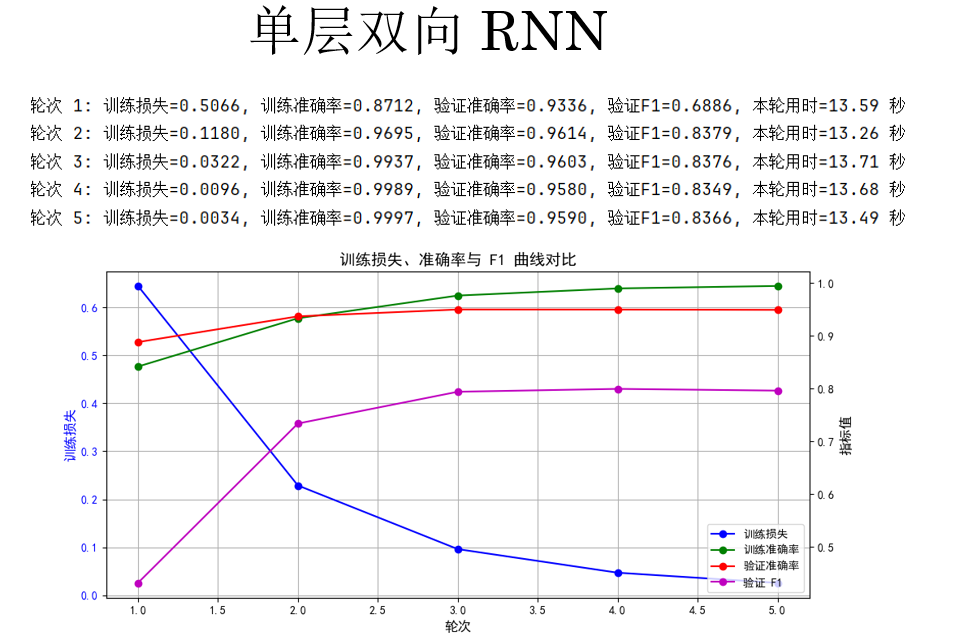
很明显,验证集上的 F1 分数有所提升从之前的 79% 左右到了 83% 左右,但随着计算量的增加,训练用时也相应的增加了约 20%。
我们继续。
(3)单层双向 GRU
第三个实验对象,单层双向 GRU,同样修改参数如下:
python
cfg = {'rnn_type': 'GRU', 'bidirectional': True, 'num_layers': 1} 来看结果:
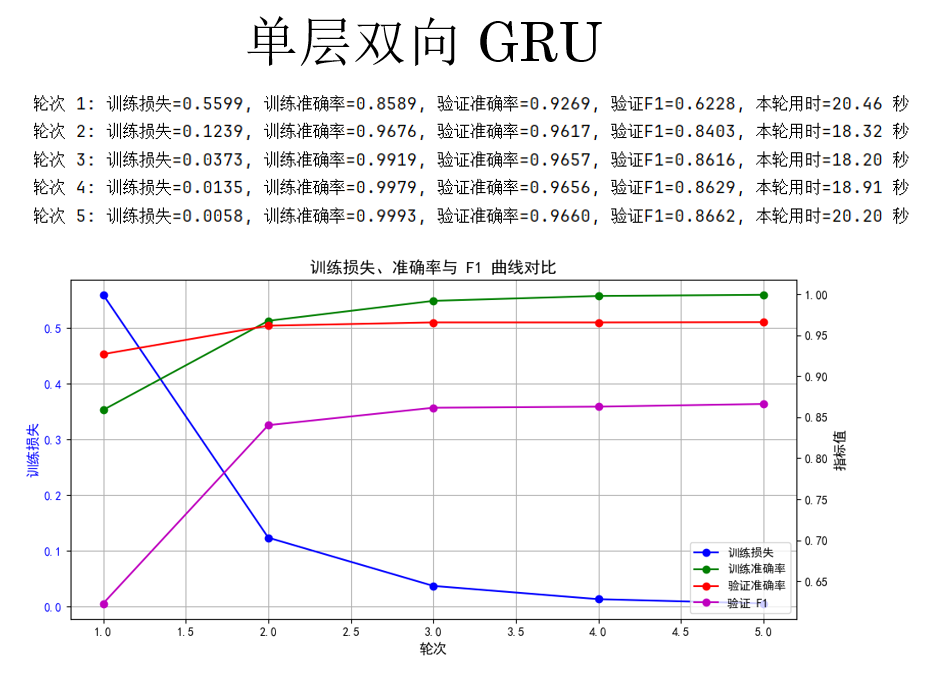
观察结果,你会发现,GRU 再次实现了 F1 分数的提升,但同时,更加复杂的循环单元也让其运行时间大幅提升。
(4)单层双向 LSTM
继续,来看看LSTM 的表现:
python
cfg = {'rnn_type': 'LSTM', 'bidirectional': True, 'num_layers': 1} 结果如下:
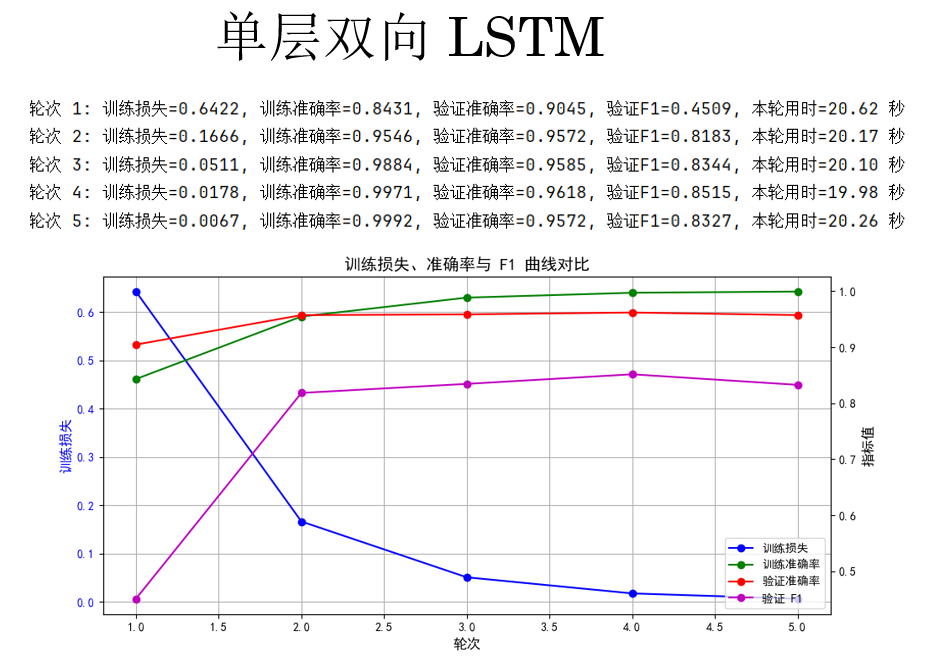
结果显示:在当前设置下, LSTM 并不如 GRU 。
其实原因也比较直观,LSTM 并不是一定比 GRU 好,它只是"上限更高、成本也更高",同时也更难训练,我们继续下一步来看看:
(5)多层双向 LSTM
最后一次,我们选择增加 LSTM 的深度,同时增加轮次为10。
python
cfg = {'rnn_type': 'LSTM', 'bidirectional': True, 'num_layers': 3} 结果如下:
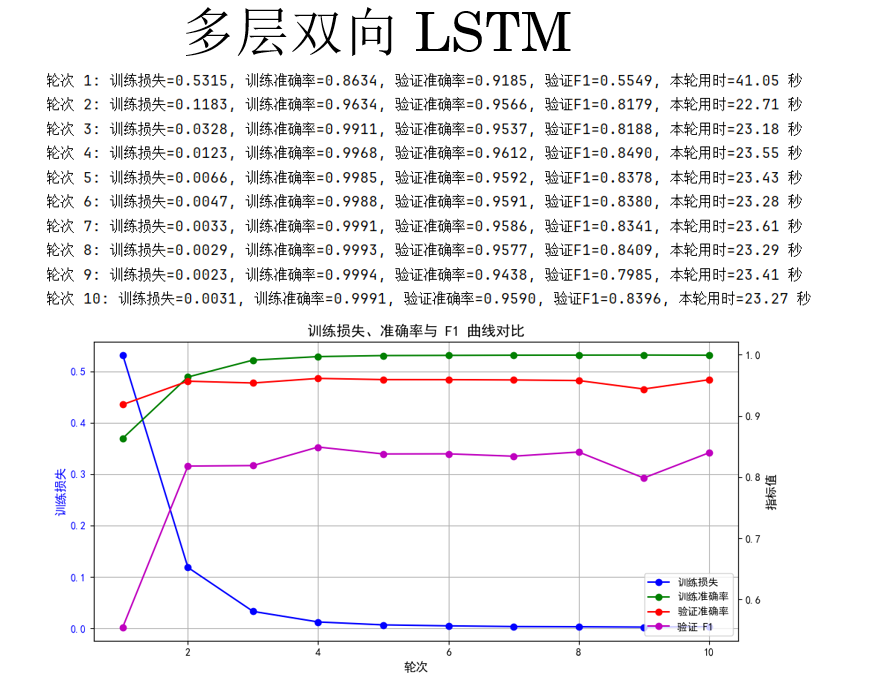
结果好像也并没有像我们所想一样有所提升,这也确实说明了,更复杂的模型,需要更多的训练技巧。
我们的演示部分就到这里。
你会发现,单层单向 RNN 训练快、准确率高但 F1 偏低,说明对少数类识别有限。
单层双向 RNN 利用前后文信息提升了 F1,但训练时间也有所提升。
单层双向 GRU 在保持训练稳定的同时进一步提升了 F1,性价比最好。
单层双向 LSTM 参数多、训练难度高,在当前设置下不如 GRU,多层双向 LSTM 即便增加轮次和深度,F1 仍未显著提升,说明复杂模型需要更精细的训练策略。
总体来看,对于中等规模的序列标注任务,浅层 GRU 是最稳健的选择。
当然,这只是针对我们现在所介绍的技术而言,下一周的内容关于词嵌入,是相比独热编码而言,更加合适的文本编码技术,到时我们再来看看各个模型的性能如何。
3. 附录
3.1 RNN 模型训练代码-PyTorch版
python
import time
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_sequence
from datasets import load_dataset
from collections import Counter
from torch.utils.data import DataLoader
from sklearn.metrics import f1_score
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = load_dataset("conll2003")
train_data = dataset['train']
valid_data = dataset['validation']
test_data = dataset['test']
word_counter = Counter()
tag_counter = Counter()
for item in train_data:
word_counter.update(item['tokens'])
tag_counter.update(item['ner_tags'])
# 词表
word_vocab = {w:i+2 for i,(w,_) in enumerate(word_counter.most_common())}
word_vocab["<PAD>"] = 0
word_vocab["<UNK>"] = 1
# 标签表
tag_vocab = {t:t for t in tag_counter.keys()}
pad_tag_id = -100
num_classes = len(tag_vocab)
vocab_size = len(word_vocab) # 用于独热编码
# 编码函数
def encode(item):
x = torch.tensor([word_vocab.get(w,1) for w in item['tokens']], dtype=torch.long)
y = torch.tensor(item['ner_tags'], dtype=torch.long)
return x, y
# DataLoader + 填充函数
def collate_fn(batch):
xs, ys = zip(*batch)
xs_pad = pad_sequence(xs, batch_first=True, padding_value=word_vocab["<PAD>"])
ys_pad = pad_sequence(ys, batch_first=True, padding_value=pad_tag_id)
return xs_pad.to(device), ys_pad.to(device)
train_dataset = [encode(item) for item in train_data]
valid_dataset = [encode(item) for item in valid_data]
test_dataset = [encode(item) for item in test_data]
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, collate_fn=collate_fn)
valid_loader = DataLoader(valid_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)
# RNN 模型
class RNNTagger(nn.Module):
def __init__(self, vocab_size, hidden_dim, num_classes,
rnn_type='RNN', bidirectional=False, num_layers=1):
super().__init__()
self.vocab_size = vocab_size
self.bidirectional = bidirectional
self.rnn_type = rnn_type.upper()
input_size = vocab_size # 独热编码输入维度 = 词表大小
if self.rnn_type == 'RNN':
self.rnn = nn.RNN(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
elif self.rnn_type == 'LSTM':
self.rnn = nn.LSTM(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
elif self.rnn_type == 'GRU':
self.rnn = nn.GRU(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
else:
raise ValueError("rnn_type must be 'RNN','LSTM','GRU'")
self.fc = nn.Linear(hidden_dim * (2 if bidirectional else 1), num_classes)
def forward(self, x):
# x: [batch, seq_len], 转独热
x_onehot = torch.nn.functional.one_hot(x, num_classes=self.vocab_size).float()
out, _ = self.rnn(x_onehot) # 过RNN
out = self.fc(out) #过输出层
return out
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode_minus'] = False
# 训练 + 验证函数
def train_validate(model, train_loader, valid_loader, epochs=5, lr=0.001):
model.to(device)
criterion = nn.CrossEntropyLoss(ignore_index=pad_tag_id)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
train_loss_history = []
train_acc_history = []
val_acc_history = []
val_f1_history = []
epoch_times = []
total_start_time = time.time()
for epoch in range(epochs):
epoch_start_time = time.time()
# ========= 训练 =========
model.train()
total_loss = 0
total_correct = 0
total_tokens = 0
for x_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(x_batch)
outputs_reshape = outputs.view(-1, num_classes)
y_batch_reshape = y_batch.view(-1)
loss = criterion(outputs_reshape, y_batch_reshape)
loss.backward()
optimizer.step()
total_loss += loss.item()
preds = outputs.argmax(dim=-1)
for i in range(y_batch.size(0)):
mask = y_batch[i] != pad_tag_id
total_correct += (preds[i][mask] == y_batch[i][mask]).sum().item()
total_tokens += mask.sum().item()
avg_train_loss = total_loss / len(train_loader)
train_acc = total_correct / total_tokens
train_loss_history.append(avg_train_loss)
train_acc_history.append(train_acc)
# ========= 验证 =========
model.eval()
val_total_correct = 0
val_total_tokens = 0
all_preds = []
all_labels = []
with torch.no_grad():
for x_val, y_val in valid_loader:
outputs = model(x_val)
preds = outputs.argmax(dim=-1)
for i in range(y_val.size(0)):
mask = y_val[i] != pad_tag_id
val_total_correct += (preds[i][mask] == y_val[i][mask]).sum().item()
val_total_tokens += mask.sum().item()
all_preds.extend(preds[i][mask].cpu().tolist())
all_labels.extend(y_val[i][mask].cpu().tolist())
val_acc = val_total_correct / val_total_tokens
val_f1 = f1_score(all_labels, all_preds, average='macro')
val_acc_history.append(val_acc)
val_f1_history.append(val_f1)
epoch_time = time.time() - epoch_start_time
epoch_times.append(epoch_time)
print(
f"轮次 {epoch+1}: "
f"训练损失={avg_train_loss:.4f}, "
f"训练准确率={train_acc:.4f}, "
f"验证准确率={val_acc:.4f}, "
f"验证F1={val_f1:.4f}, "
f"本轮用时={epoch_time:.2f} 秒"
)
total_time = time.time() - total_start_time
avg_epoch_time = sum(epoch_times) / len(epoch_times)
print("\n======== 训练时间统计 ========")
print(f"总训练时间:{total_time:.2f} 秒")
print(f"平均每轮用时:{avg_epoch_time:.2f} 秒")
history = {
'train_loss': train_loss_history,
'train_acc': train_acc_history,
'val_acc': val_acc_history,
'val_f1': val_f1_history
}
return model, history
def plot_training_curves(history):
epochs = range(1, len(history['train_loss']) + 1)
fig, ax1 = plt.subplots(figsize=(10, 5))
ax1.plot(epochs, history['train_loss'], 'b-o', label='训练损失')
ax1.set_xlabel("轮次", fontsize=12)
ax1.set_ylabel("训练损失", color='b', fontsize=12)
ax1.tick_params(axis='y', labelcolor='b')
ax1.grid(True)
ax2 = ax1.twinx()
ax2.plot(epochs, history['train_acc'], 'g-o', label='训练准确率')
ax2.plot(epochs, history['val_acc'], 'r-o', label='验证准确率')
ax2.plot(epochs, history['val_f1'], 'm-o', label='验证 F1')
ax2.set_ylabel("指标值", fontsize=12)
ax2.tick_params(axis='y')
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax2.legend(lines1 + lines2, labels1 + labels2, loc='lower right')
plt.title("训练损失、准确率与 F1 曲线对比", fontsize=14)
plt.tight_layout()
plt.show()
if __name__ == '__main__':
# cfg = {'rnn_type': 'RNN', 'bidirectional': False, 'num_layers': 1}
# cfg = {'rnn_type':'RNN','bidirectional':True,'num_layers':1} # cfg = {'rnn_type': 'GRU', 'bidirectional': True, 'num_layers': 1} # cfg = {'rnn_type': 'LSTM', 'bidirectional': True, 'num_layers': 1} cfg = {'rnn_type': 'LSTM', 'bidirectional': True, 'num_layers': 3}
model = RNNTagger(vocab_size=len(word_vocab),
hidden_dim=128,
num_classes=num_classes,
rnn_type=cfg['rnn_type'],
bidirectional=cfg['bidirectional'],
num_layers=cfg['num_layers'])
model, history = train_validate(model, train_loader, valid_loader, epochs=10)
plot_training_curves(history)3.2 RNN 模型训练代码-TF版
python
import time
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Layer, SimpleRNN, GRU, LSTM, Dense, Bidirectional, Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from datasets import load_dataset
from collections import Counter
from sklearn.metrics import f1_score
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode_minus'] = False
dataset = load_dataset("conll2003")
train_data = dataset['train']
valid_data = dataset['validation']
test_data = dataset['test']
word_counter = Counter()
tag_counter = Counter()
for item in train_data:
word_counter.update(item['tokens'])
tag_counter.update(item['ner_tags'])
# 词表
word_vocab = {w:i+2 for i,(w,_) in enumerate(word_counter.most_common())}
word_vocab["<PAD>"] = 0
word_vocab["<UNK>"] = 1
vocab_size = len(word_vocab)
# 标签表
tag_vocab = {t:t for t in tag_counter.keys()}
num_classes = len(tag_vocab)
pad_tag_id = -100 # 训练时忽略
# 编码函数
def encode(item):
x = [word_vocab.get(w, 1) for w in item['tokens']]
y = item['ner_tags']
return x, y
train_dataset = [encode(item) for item in train_data]
valid_dataset = [encode(item) for item in valid_data]
test_dataset = [encode(item) for item in test_data]
# 填充函数
def pad_sequences(seqs, pad_value=0):
max_len = max(len(s) for s in seqs)
padded = [s + [pad_value]*(max_len - len(s)) for s in seqs]
return np.array(padded)
def prepare_batch(dataset):
X = pad_sequences([x for x, y in dataset], pad_value=0)
y = pad_sequences([y for x, y in dataset], pad_value=pad_tag_id)
return X, y
X_train, y_train = prepare_batch(train_dataset)
X_valid, y_valid = prepare_batch(valid_dataset)
X_test, y_test = prepare_batch(test_dataset)
class OneHotLayer(Layer):
def __init__(self, depth, **kwargs):
super().__init__(**kwargs)
self.depth = depth
def call(self, inputs):
return tf.one_hot(inputs, depth=self.depth, dtype=tf.float32)
def build_rnn_model(vocab_size, num_classes, hidden_dim=128, rnn_type='RNN', bidirectional=False, num_layers=1):
inputs = Input(shape=(None,), dtype=tf.int32)
x = OneHotLayer(depth=vocab_size)(inputs)
for i in range(num_layers):
return_seq = True
rnn_layer = None
if rnn_type.upper() == 'RNN':
rnn_layer = SimpleRNN(hidden_dim, return_sequences=return_seq)
elif rnn_type.upper() == 'GRU':
rnn_layer = GRU(hidden_dim, return_sequences=return_seq)
elif rnn_type.upper() == 'LSTM':
rnn_layer = LSTM(hidden_dim, return_sequences=return_seq)
else:
raise ValueError("rnn_type must be 'RNN','LSTM','GRU'")
if bidirectional:
rnn_layer = Bidirectional(rnn_layer)
x = rnn_layer(x)
outputs = Dense(num_classes, activation='softmax')(x)
model = Model(inputs, outputs)
return model
def train_validate(model, X_train, y_train, X_valid, y_valid, batch_size=32, epochs=5, lr=0.001):
optimizer = Adam(learning_rate=lr)
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(ignore_class=pad_tag_id)
train_loss_history = []
train_acc_history = []
val_acc_history = []
val_f1_history = []
train_data = tf.data.Dataset.from_tensor_slices((X_train, y_train)).shuffle(1000).batch(batch_size)
valid_data = tf.data.Dataset.from_tensor_slices((X_valid, y_valid)).batch(batch_size)
for epoch in range(epochs):
start_time = time.time()
total_loss = 0
total_correct = 0
total_tokens = 0
# ========= 训练 =========
for step, (x_batch, y_batch) in enumerate(train_data):
with tf.GradientTape() as tape:
logits = model(x_batch, training=True)
loss = loss_fn(y_batch, logits)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
total_loss += loss.numpy()
preds = tf.argmax(logits, axis=-1,output_type=tf.int32)
mask = y_batch != pad_tag_id
total_correct += tf.reduce_sum(tf.cast(preds[mask] == y_batch[mask], tf.float32)).numpy()
total_tokens += tf.reduce_sum(tf.cast(mask, tf.float32)).numpy()
train_loss_history.append(total_loss / len(train_data))
train_acc_history.append(total_correct / total_tokens)
# ========= 验证 =========
all_preds = []
all_labels = []
total_correct_val = 0
total_tokens_val = 0
for x_batch, y_batch in valid_data:
logits = model(x_batch, training=False)
preds = tf.argmax(logits, axis=-1,output_type=tf.int32)
mask = y_batch != pad_tag_id
total_correct_val += tf.reduce_sum(tf.cast(preds[mask] == y_batch[mask], tf.float32)).numpy()
total_tokens_val += tf.reduce_sum(tf.cast(mask, tf.float32)).numpy()
all_preds.extend(preds[mask].numpy())
all_labels.extend(y_batch[mask].numpy())
val_acc = total_correct_val / total_tokens_val
val_f1 = f1_score(all_labels, all_preds, average='macro')
val_acc_history.append(val_acc)
val_f1_history.append(val_f1)
epoch_time = time.time() - start_time
print(f"轮次 {epoch+1}: 训练损失={train_loss_history[-1]:.4f}, "
f"训练准确率={train_acc_history[-1]:.4f}, "
f"验证准确率={val_acc:.4f}, 验证 F1={val_f1:.4f}, "
f"本轮用时={epoch_time:.2f} 秒")
history = {
'train_loss': train_loss_history,
'train_acc': train_acc_history,
'val_acc': val_acc_history,
'val_f1': val_f1_history
}
return history
def plot_training_curves(history):
epochs = range(1, len(history['train_loss']) + 1)
fig, ax1 = plt.subplots(figsize=(10, 5))
ax1.plot(epochs, history['train_loss'], 'b-o', label='训练损失')
ax1.set_xlabel("轮次", fontsize=12)
ax1.set_ylabel("训练损失", color='b', fontsize=12)
ax1.tick_params(axis='y', labelcolor='b')
ax1.grid(True)
ax2 = ax1.twinx()
ax2.plot(epochs, history['train_acc'], 'g-o', label='训练准确率')
ax2.plot(epochs, history['val_acc'], 'r-o', label='验证准确率')
ax2.plot(epochs, history['val_f1'], 'm-o', label='验证 F1')
ax2.set_ylabel("指标值", fontsize=12)
ax2.tick_params(axis='y')
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax2.legend(lines1 + lines2, labels1 + labels2, loc='lower right')
plt.title("训练损失、准确率与 F1 曲线对比", fontsize=14)
plt.tight_layout()
plt.show()
if __name__ == '__main__':
cfg = {'rnn_type':'RNN','bidirectional':True,'num_layers':1}
model = build_rnn_model(vocab_size=vocab_size,
num_classes=num_classes,
hidden_dim=128,
rnn_type=cfg['rnn_type'],
bidirectional=cfg['bidirectional'],
num_layers=cfg['num_layers'])
history = train_validate(model, X_train, y_train, X_valid, y_valid, batch_size=32, epochs=10, lr=0.001)
plot_training_curves(history)