写在前面
本系列推文为《R for Data Science (2)》的中文翻译版本。所有内容都通过开源免费的方式上传至Github,欢迎大家参与贡献,详细信息见:
Books-zh-cn 项目介绍:
Books-zh-cn:开源免费的中文书籍社区
r4ds-zh-cn Github 地址:
https://github.com/Books-zh-cn/r4ds-zh-cn
r4ds-zh-cn 网站地址:
https://books-zh-cn.github.io/r4ds-zh-cn/
目录
-
17.3 日期-时间组件
-
17.4 时间跨度
-
17.5 时区
-
17.6 总结
17.3 日期-时间组件
现在你已经知道如何将 date-time 数据导入 R 的 date-time 数据结构,接下来让我们探索可以对它们进行哪些操作。 本节将重点介绍用于获取和设置单个组件的访问器函数。 下一节将探讨 date-times 的算术运算。
17.3.1 获取组件
你可以使用访问器函数 year(), month(), mday() (day of the month), yday() (day of the year), wday() (day of the week), hour(), minute(), 和 second() 来提取日期的各个组成部分。 这些函数实际上是 make_datetime() 的反向操作。
datetime <- ymd_hms("2026-07-08 12:34:56")
year(datetime)
#> [1] 2026
month(datetime)
#> [1] 7
mday(datetime)
#> [1] 8
yday(datetime)
#> [1] 189
wday(datetime)
#> [1] 4对于 month() 和 wday() 函数,你可以设置 label = TRUE 来返回月份或星期几的缩写名称。 设置 abbr = FALSE 可返回完整名称。
month(datetime, label = TRUE)
#> [1] Jul
#> 12 Levels: Jan < Feb < Mar < Apr < May < Jun < Jul < Aug < Sep < ... < Dec
wday(datetime, label = TRUE, abbr = FALSE)
#> [1] Wednesday
#> 7 Levels: Sunday < Monday < Tuesday < Wednesday < Thursday < ... < Saturday我们可以使用 wday() 来观察工作日出发的航班数量多于周末:
flights_dt |>
mutate(wday = wday(dep_time, label = TRUE)) |>
ggplot(aes(x = wday)) +
geom_bar()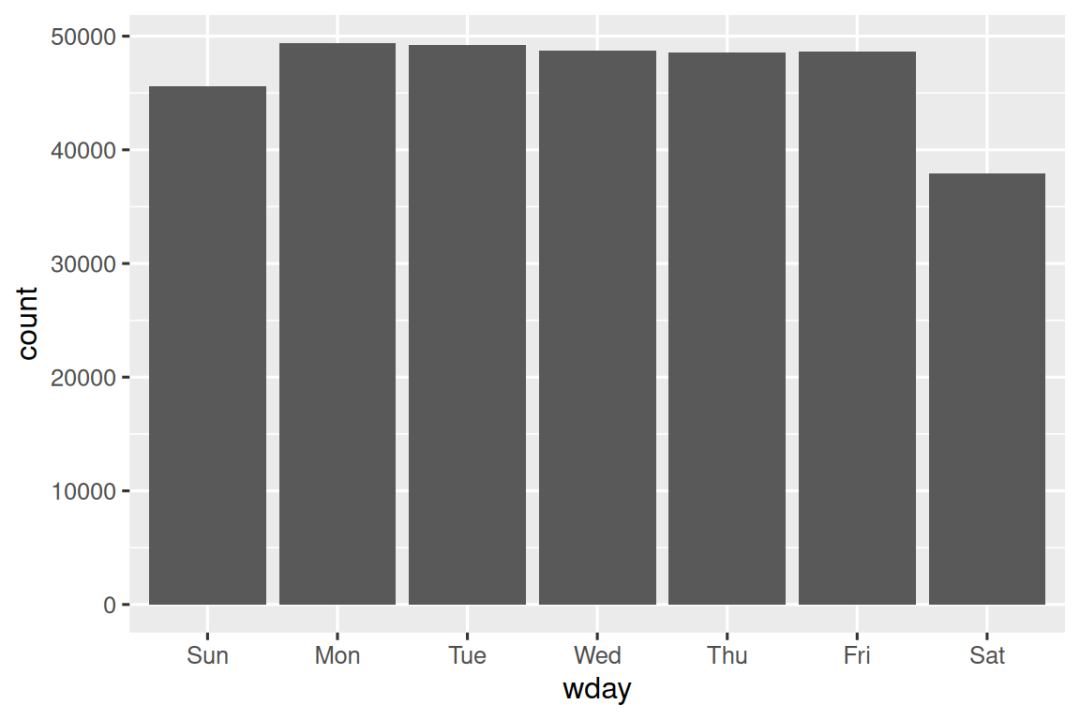
我们还可以观察每小时之内分钟粒度的平均起飞延误情况。 这里有一个有趣的规律:在 20-30 分钟和 50-60 分钟起飞的航班,其延误程度远低于该小时内其他时段的航班!
flights_dt |>
mutate(minute = minute(dep_time)) |>
group_by(minute) |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
n = n()
) |>
ggplot(aes(x = minute, y = avg_delay)) +
geom_line()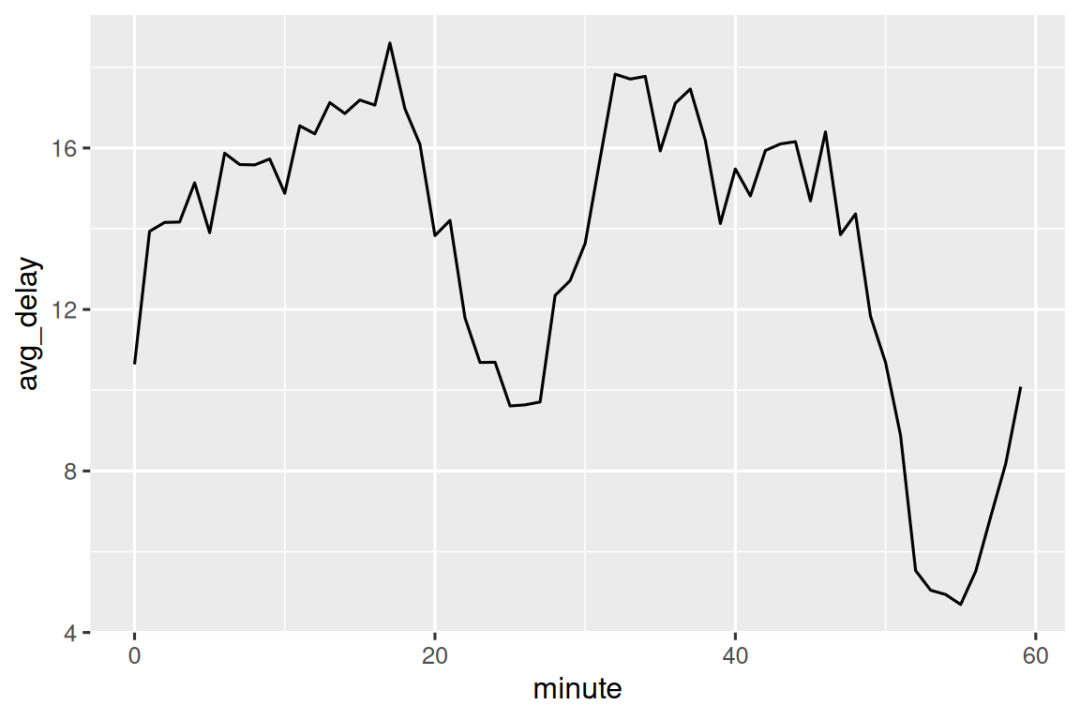
有趣的是,如果我们查看计划起飞时间,并没有观察到如此明显的规律:
sched_dep <- flights_dt |>
mutate(minute = minute(sched_dep_time)) |>
group_by(minute) |>
summarize(
avg_delay = mean(arr_delay, na.rm = TRUE),
n = n()
)
ggplot(sched_dep, aes(x = minute, y = avg_delay)) +
geom_line()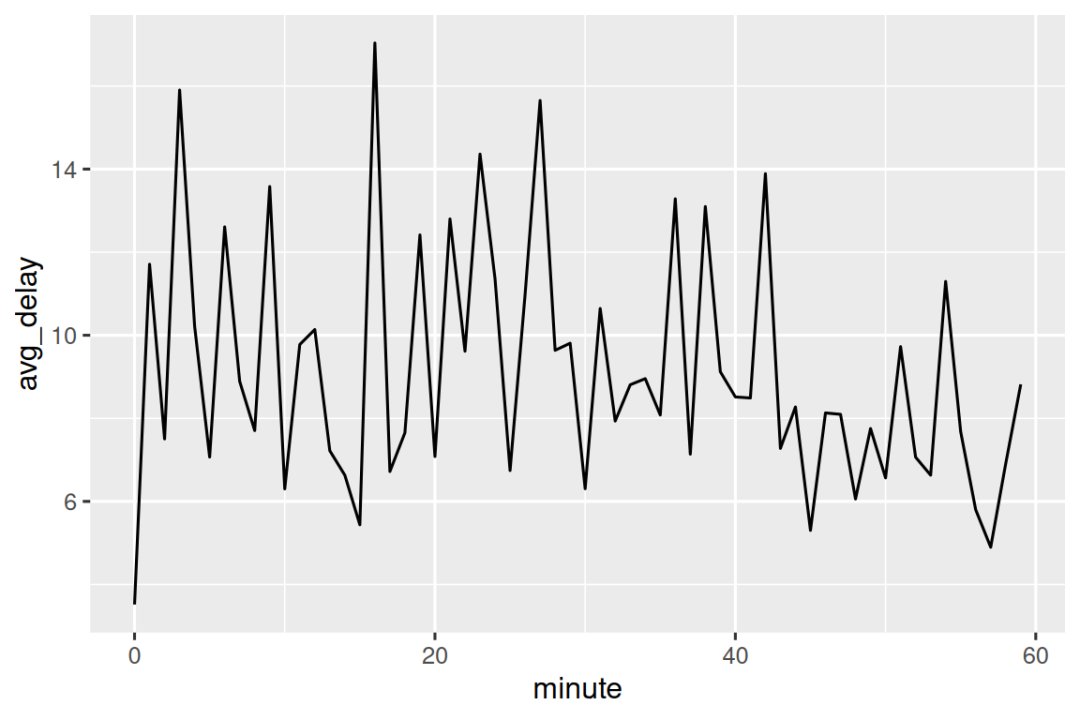
那么,为什么在实际起飞时间中会出现这种规律呢? 事实上,如同许多由人工收集的数据一样,航班倾向于在"整点"时间起飞,如 Figure 17.1 所示,这导致了明显的偏差。 在处理涉及人为判断的数据时,务必警惕这类规律的存在!
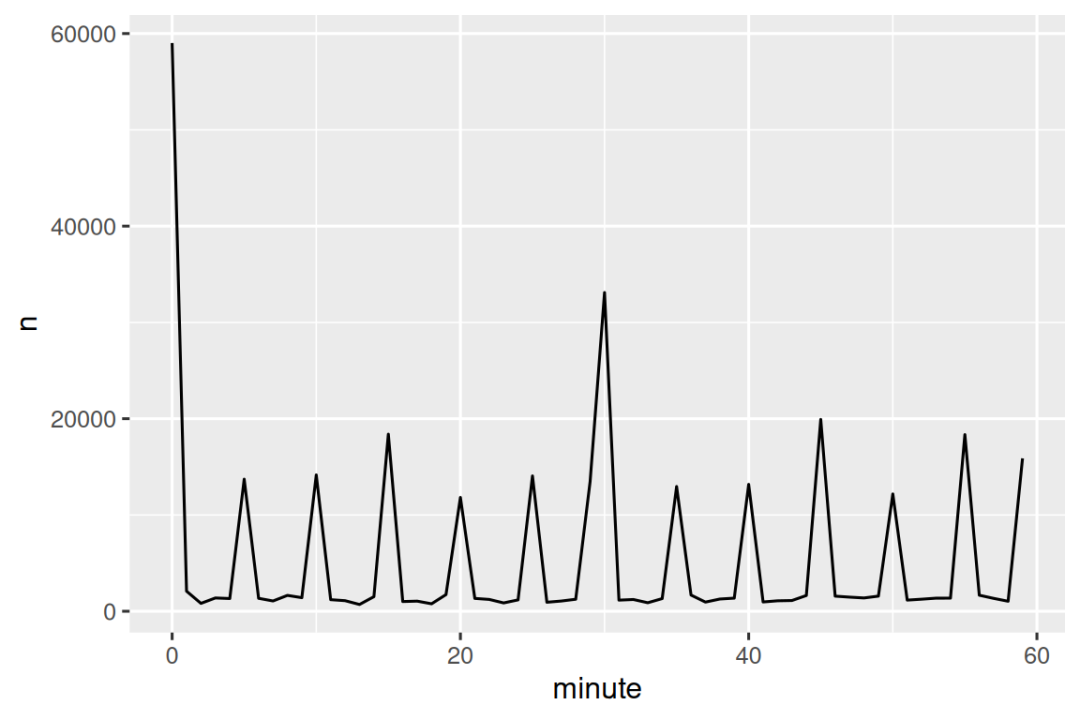
Figure 17.1: 显示每小时计划出发的航班数量的频数多边形。您可以看到人们对 0 和 30 之类的整数以及通常是 5 的倍数的数字有强烈的偏好。
Rounding
另一种绘制单个日期组成部分的方法是使用 floor_date()、round_date() 和 ceiling_date() 函数,将日期四舍五入到附近的时间单位。 每个函数都接受一个待调整的日期向量,以及要向下取整(floor)、向上取整(ceiling)或四舍五入(round)的时间单位名称。 例如,这使我们能够绘制每周的航班数量:
flights_dt |>
count(week = floor_date(dep_time, "week")) |>
ggplot(aes(x = week, y = n)) +
geom_line() +
geom_point()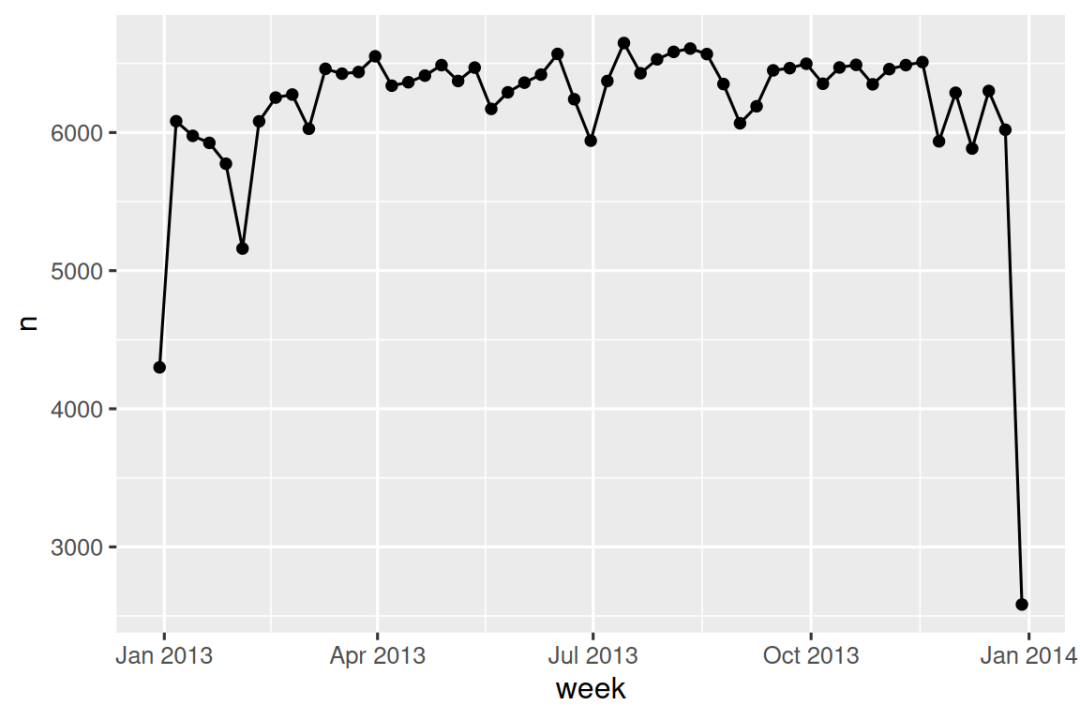
通过计算 dep_time 与当天最早时刻之间的差值,你可以使用四舍五入来展示航班在一天内的分布情况:
flights_dt |>
mutate(dep_hour = dep_time - floor_date(dep_time, "day")) |>
ggplot(aes(x = dep_hour)) +
geom_freqpoly(binwidth = 60 * 30)
#> Don't know how to automatically pick scale for object of type <difftime>.
#> Defaulting to continuous.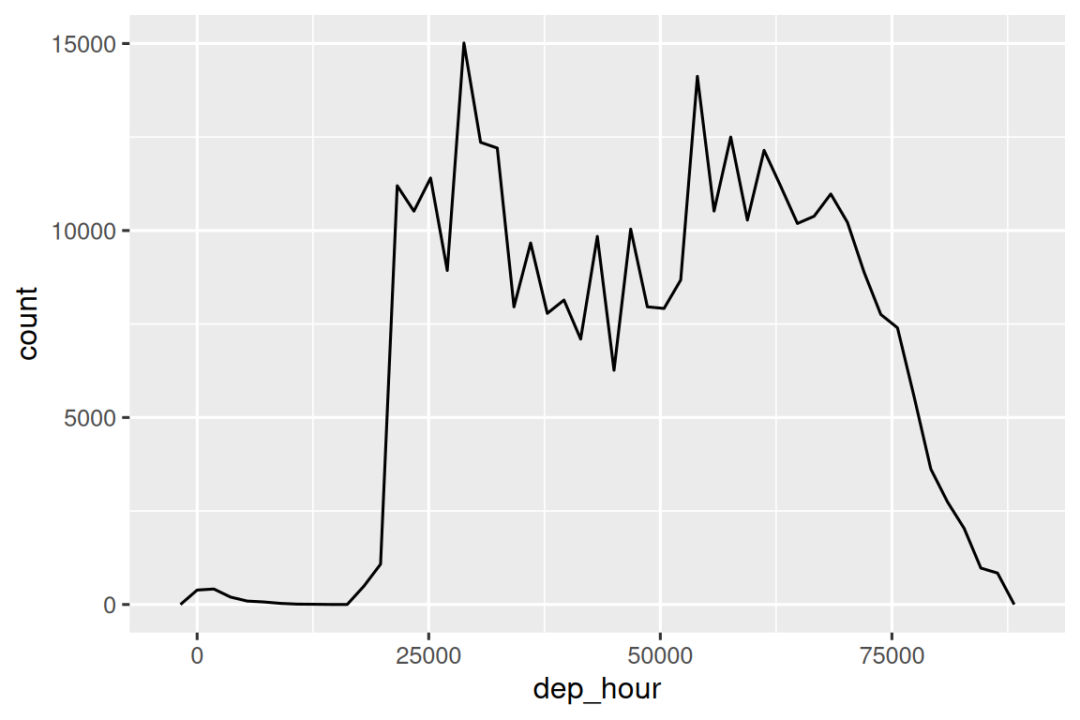
计算两个日期时间之间的差值会得到一个 difftime 对象(更多内容见 Section 17.4.3 节)。 我们可以将其转换为 hms 对象,以获得更有用的 x 轴:
flights_dt |>
mutate(dep_hour = hms::as_hms(dep_time - floor_date(dep_time, "day"))) |>
ggplot(aes(x = dep_hour)) +
geom_freqpoly(binwidth = 60 * 30)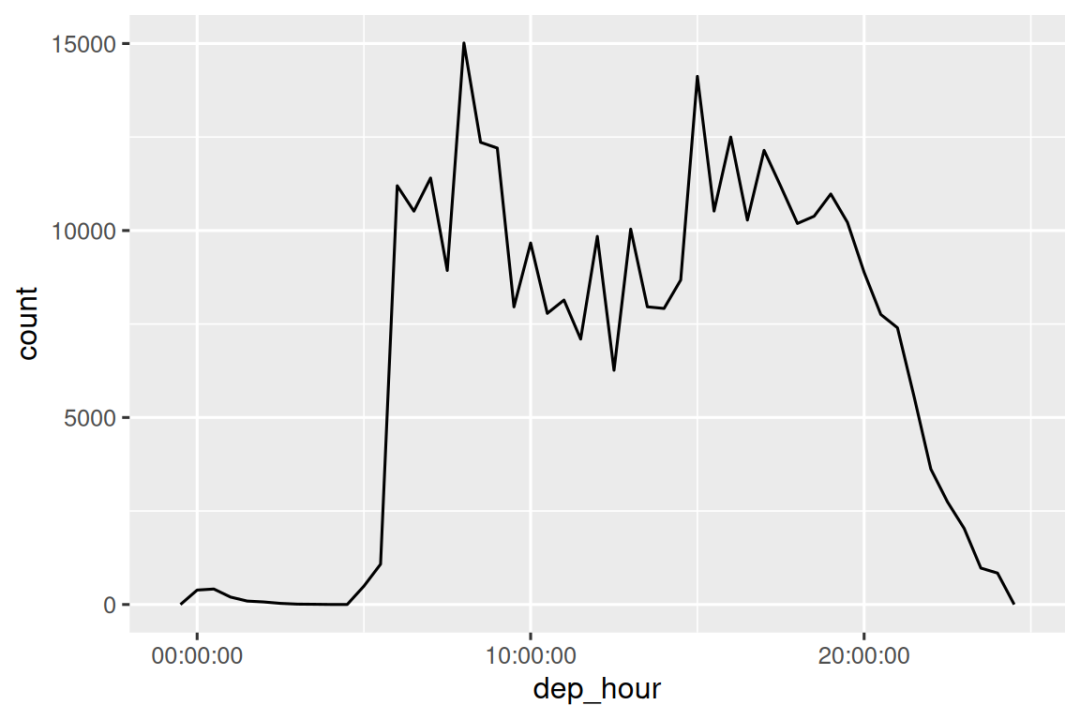
17.3.3 修改组件
你也可以使用每个访问器函数来修改 date/time 的组成部分。 这在数据分析中不常用,但在清理日期明显错误的数据时可能很有用。
(datetime <- ymd_hms("2026-07-08 12:34:56"))
year(datetime) <- 2030
datetime
#> [1] "2030-07-08 12:34:56 UTC"
month(datetime) <- 01
datetime
#> [1] "2030-01-08 12:34:56 UTC"
hour(datetime) <- hour(datetime) + 1
datetime
#> [1] "2030-01-08 13:34:56 UTC"或者,你无需修改现有变量,而是可以使用 update() 创建一个新的 date-time。 这还允许你一步设置多个值:
update(datetime, year = 2030, month = 2, mday = 2, hour = 2)
#> [1] "2030-02-02 02:34:56 UTC"如果设置的值过大,它们会自动向前进位:
update(ymd("2023-02-01"), mday = 30)
#> [1] "2023-03-02"
update(ymd("2023-02-01"), hour = 400)
#> [1] "2023-02-17 16:00:00 UTC"17.3.4 练习
-
一天内航班时间的分布如何随一年中的时间变化?
-
比较
dep_time,sched_dep_time和dep_delay。 它们是否一致? 请解释你的发现。 -
比较
air_time与起飞和到达之间的时间间隔。 解释你的发现。 (提示:考虑机场的位置。) -
一天中平均延误时间如何变化? 应该使用
dep_time还是sched_dep_time? 为什么? -
如果希望最小化延误的可能性,你应该在一周中的哪一天出发?
-
diamonds$carat和flights$sched_dep_time的分布有何相似之处? -
验证我们的假设:20-30 分钟和 50-60 分钟起飞的航班较早出发是由于计划航班提前起飞所致。 提示:创建一个二元变量来指示航班是否延误。
17.4 时间跨度
接下来,你将学习日期算术运算的原理,包括减法、加法和除法。 在此过程中,你会了解到三种表示时间跨度的重要类别:
-
Durations, 表示精确的秒数。
-
Periods, 表示人类可理解的单位,如周 (weeks) 和月 (months)。
-
Intervals, 表示一个起始点和结束点。
如何在 duration、periods 和 intervals 之间做出选择? 一如既往,选择能解决你问题的最简单数据结构。 如果你只关心物理时间,使用 duration;如果需要添加人类可理解的时间,使用 period;如果需要计算某个跨度在人类单位中的长度,使用 interval。
17.4.1 Durations
在 R 中,当你对两个日期进行相减时,会得到一个 difftime 对象:
# How old is Hadley?
h_age <- today() - ymd("1979-10-14")
h_age
#> Time difference of 16872 daysdifftime 类对象以秒、分钟、小时、天或周为单位记录时间跨度。 这种模糊性可能使得 difftimes 对象处理起来有些棘手,因此 lubridate 提供了另一种始终以秒为单位的时间跨度表示方式:duration。
as.duration(h_age)
#> [1] "1457740800s (~46.19 years)"Durations 附带了一系列便捷的构造函数:
dseconds(15)
#> [1] "15s"
dminutes(10)
#> [1] "600s (~10 minutes)"
dhours(c(12, 24))
#> [1] "43200s (~12 hours)" "86400s (~1 days)"
ddays(0:5)
#> [1] "0s" "86400s (~1 days)" "172800s (~2 days)"
#> [4] "259200s (~3 days)" "345600s (~4 days)" "432000s (~5 days)"
dweeks(3)
#> [1] "1814400s (~3 weeks)"
dyears(1)
#> [1] "31557600s (~1 years)"Durations 始终以秒为单位记录时间跨度。 更大的单位通过将分钟、小时、天、周和年转换为秒来创建:一分钟 60 秒,一小时 60 分钟,一天 24 小时,一周 7 天。 更大的时间单位则更具问题性。 一年使用"平均"年天数,即 365.25 天。 由于月份的变化太大,无法将其转换为 duration。
你可以对 durations 进行加减和乘法运算:
2 * dyears(1)
#> [1] "63115200s (~2 years)"
dyears(1) + dweeks(12) + dhours(15)
#> [1] "38869200s (~1.23 years)"你可以对日期进行 durations 的加减运算:
tomorrow <- today() + ddays(1)
last_year <- today() - dyears(1)然而,由于 durations 表示的是精确的秒数,有时你可能会得到意想不到的结果:
one_am <- ymd_hms("2026-03-08 01:00:00", tz = "America/New_York")
one_am
#> [1] "2026-03-08 01:00:00 EST"
one_am + ddays(1)
#> [1] "2026-03-09 02:00:00 EDT"为什么 3 月 8 日凌晨 1 点加上一天后是 3 月 9 日凌晨 2 点? 如果仔细观察日期,你可能还会注意到时区发生了变化。 3 月 8 日只有 23 小时,因为这是夏令时开始的时间,所以如果我们加上一整天的秒数,最终会得到一个不同的时间。
17.4.2 Periods
为了解决这个问题,lubridate 提供了 periods。 Periods 表示时间跨度,但其长度不以固定的秒数为单位,而是以"人类"时间(如 days 和 months)为单位。 这使得它们能以更直观的方式工作:
one_am
#> [1] "2026-03-08 01:00:00 EST"
one_am + days(1)
#> [1] "2026-03-09 01:00:00 EDT"与 durations 类似,periods 也可以通过一系列便捷的构造函数来创建。
hours(c(12, 24))
#> [1] "12H 0M 0S" "24H 0M 0S"
days(7)
#> [1] "7d 0H 0M 0S"
months(1:6)
#> [1] "1m 0d 0H 0M 0S" "2m 0d 0H 0M 0S" "3m 0d 0H 0M 0S" "4m 0d 0H 0M 0S"
#> [5] "5m 0d 0H 0M 0S" "6m 0d 0H 0M 0S"你可以对 periods 进行加法和乘法运算:
10 * (months(6) + days(1))
#> [1] "60m 10d 0H 0M 0S"
days(50) + hours(25) + minutes(2)
#> [1] "50d 25H 2M 0S"当然,也可以将它们与 dates 相加。 与 durations 相比,periods 更可能符合你的预期:
# A leap year
ymd("2024-01-01") + dyears(1)
#> [1] "2024-12-31 06:00:00 UTC"
ymd("2024-01-01") + years(1)
#> [1] "2025-01-01"
# Daylight saving time
one_am + ddays(1)
#> [1] "2026-03-09 02:00:00 EDT"
one_am + days(1)
#> [1] "2026-03-09 01:00:00 EDT"让我们使用 periods 来解决与航班日期相关的一个异常情况。 一些飞机似乎在其从纽约市起飞之前就已到达目的地。
flights_dt |>
filter(arr_time < dep_time)
#> # A tibble: 10,633 × 9
#> origin dest dep_delay arr_delay dep_time sched_dep_time
#> <chr> <chr> <dbl> <dbl> <dttm> <dttm>
#> 1 EWR BQN 9 -4 2013-01-01 19:29:00 2013-01-01 19:20:00
#> 2 JFK DFW 59 NA 2013-01-01 19:39:00 2013-01-01 18:40:00
#> 3 EWR TPA -2 9 2013-01-01 20:58:00 2013-01-01 21:00:00
#> 4 EWR SJU -6 -12 2013-01-01 21:02:00 2013-01-01 21:08:00
#> 5 EWR SFO 11 -14 2013-01-01 21:08:00 2013-01-01 20:57:00
#> 6 LGA FLL -10 -2 2013-01-01 21:20:00 2013-01-01 21:30:00
#> # ℹ 10,627 more rows
#> # ℹ 3 more variables: arr_time <dttm>, sched_arr_time <dttm>, ...这些是过夜航班。 我们在起飞和到达时间中使用了相同的日期信息,但这些航班实际上是在第二天抵达的。 我们可以通过为每个过夜航班的到达时间加上 days(1) 来修正这个问题。
flights_dt <- flights_dt |>
mutate(
overnight = arr_time < dep_time,
arr_time = arr_time + days(overnight),
sched_arr_time = sched_arr_time + days(overnight)
)现在,所有航班都符合物理定律了。
flights_dt |>
filter(arr_time < dep_time)
#> # A tibble: 0 × 10
#> # ℹ 10 variables: origin <chr>, dest <chr>, dep_delay <dbl>,
#> # arr_delay <dbl>, dep_time <dttm>, sched_dep_time <dttm>, ...17.4.3 Intervals
dyears(1) / ddays(365) 会返回什么结果? 它并不完全等于 1,因为 dyears() 被定义为每个平均年份的秒数,即 365.25 天。
那么 years(1) / days(1) 会返回什么? 如果年份是 2015,它应该返回 365;但如果是 2016,它应该返回 366! lubridate 没有足够的信息来给出一个唯一明确的答案。 它实际做的是给出一个估算值:
years(1) / days(1)
#> [1] 365.25如果你想要更精确的测量,就必须使用 interval。 interval 是一对起始和结束的日期时间,或者你可以将其视为带有起始点的时长。
你可以通过 start %--% end 的语法创建一个区间:
y2023 <- ymd("2023-01-01") %--% ymd("2024-01-01")
y2024 <- ymd("2024-01-01") %--% ymd("2025-01-01")
y2023
#> [1] 2023-01-01 UTC--2024-01-01 UTC
y2024
#> [1] 2024-01-01 UTC--2025-01-01 UTC然后你可以将其除以 days() 来找出该年份包含多少天:
y2023 / days(1)
#> [1] 365
y2024 / days(1)
#> [1] 36617.4.4 练习
-
向刚学习 R 的人解释
days(!overnight)和days(overnight)。 你需要了解的关键事实是什么? -
创建一个日期向量,表示 2015 年每个月的第一天。 再创建一个日期向量,表示当前年份每个月的第一天。
-
编写一个函数,根据你的生日(作为日期输入),返回你的年龄(以年为单位)。
-
为什么
(today() %--% (today() + years(1))) / months(1)无法运行?
17.5 时区
时区是一个极其复杂的主题,因为它们与地缘政治实体相互作用。 幸运的是,我们不需要深入探究所有细节,因为并非所有细节对数据分析都至关重要,但有一些挑战我们确实需要直面应对。
第一个挑战是日常使用的时区名称往往具有歧义性。 例如,如果你是美国人,可能很熟悉 EST(东部标准时间)。 然而,澳大利亚和加拿大也都有 EST! 为了避免混淆,R 采用国际标准的 IANA 时区。 这些时区使用一致的命名规则 {area}/{location},通常形式为 {continent}/{city} 或 {ocean}/{city}。 例如:"America/New_York"、"Europe/Paris" 和 "Pacific/Auckland"。
你可能会好奇,为什么时区使用城市名称,而通常我们认为时区与国家或国家内的区域相关联。 这是因为 IANA 数据库必须记录数十年的时区规则。 在几十年间,国家名称变更(或分裂)相当频繁,但城市名称往往保持不变。 另一个问题是,名称不仅需要反映当前行为,还需体现完整的历史。 例如,同时存在 "America/New_York" 和 "America/Detroit" 两个时区。 这两个城市目前都使用东部标准时间,但在 1969-1972 年间,密歇根州(底特律所在州)未遵循夏令时,因此需要一个不同的名称。 值得一读原始时区数据库(可在 https://www.iana.org/time-zones 获取),仅是为了了解其中的一些历史故事!
你可以通过 Sys.timezone() 查看 R 认为你当前的时区是什么:
Sys.timezone()
#> [1] "UTC"(如果 R 无法识别,则会返回 NA。)
可以通过 OlsonNames() 查看完整的时区名称列表:
length(OlsonNames())
#> [1] 598
head(OlsonNames())
#> [1] "Africa/Abidjan" "Africa/Accra" "Africa/Addis_Ababa"
#> [4] "Africa/Algiers" "Africa/Asmara" "Africa/Asmera"在 R 中,时区是 date-time 的一个属性,仅控制显示方式。 例如,以下三个对象表示同一时刻:
x1 <- ymd_hms("2024-06-01 12:00:00", tz = "America/New_York")
x1
#> [1] "2024-06-01 12:00:00 EDT"
x2 <- ymd_hms("2024-06-01 18:00:00", tz = "Europe/Copenhagen")
x2
#> [1] "2024-06-01 18:00:00 CEST"
x3 <- ymd_hms("2024-06-02 04:00:00", tz = "Pacific/Auckland")
x3
#> [1] "2024-06-02 04:00:00 NZST"你可以通过减法运算验证它们是同一时间:
x1 - x2
#> Time difference of 0 secs
x1 - x3
#> Time difference of 0 secs除非另有说明,lubridate 始终使用 UTC。 UTC(协调世界时)是科学界使用的标准时区,大致等同于 GMT(格林威治标准时间)。 它不采用夏令时,因此便于计算。 组合 date-times 的操作(如 c())通常会丢弃时区信息。 这种情况下,date-times 将按第一个元素的时区显示:
x4 <- c(x1, x2, x3)
x4
#> [1] "2024-06-01 12:00:00 EDT" "2024-06-01 12:00:00 EDT"
#> [3] "2024-06-01 12:00:00 EDT"你可以通过两种方式更改时区:
-
保持时间点不变,仅改变其显示方式。 当时间点正确但希望以更自然的方式显示时使用此方法。
x4a <- with_tz(x4, tzone = "Australia/Lord_Howe") x4a #> [1] "2024-06-02 02:30:00 +1030" "2024-06-02 02:30:00 +1030" #> [3] "2024-06-02 02:30:00 +1030" x4a - x4 #> Time differences in secs #> [1] 0 0 0(这也说明了时区的另一个挑战:它们并非都是整小时的偏移量!)
-
改变底层的时间点。 当时间点被标记了错误的时区且需要修正时使用此方法。
x4b <- force_tz(x4, tzone = "Australia/Lord_Howe") x4b #> [1] "2024-06-01 12:00:00 +1030" "2024-06-01 12:00:00 +1030" #> [3] "2024-06-01 12:00:00 +1030" x4b - x4 #> Time differences in hours #> [1] -14.5 -14.5 -14.5
17.6 总结
本章向你介绍了 lubridate 提供的工具,帮助你处理日期时间数据。 处理日期和时间看似比实际需要的更复杂,但希望本章能让你理解其原因------日期时间比乍看之下更为复杂,而处理各种可能的情况增加了其复杂性。 即使你的数据从未涉及夏令时变更或闰年,相关函数也必须能够应对这些情况。
下一章将系统总结缺失值的处理方法。 你已经在多个场景中遇到过缺失值,在自己的分析中也无疑会碰到它们。现 在,是时候提供一个实用技巧合集来应对这些情况了。
--------------- 本章结束 ---------------
本期翻译贡献:
@TigerZ生信宝库