Docker+Kubernetes企业级容器化部署解决方案
一、项目概述
1.1 项目背景
本方案基于三台服务器构建生产级Docker+Kubernetes企业级容器化平台,实现从代码构建、镜像管理、应用部署到监控运维的完整CI/CD流水线,满足企业多团队协作、高可用部署、安全合规等核心需求。
1.1.1 架构说明 - 为什么选择 Kubernetes 1.23.x
本方案采用 Kubernetes 1.23.x 版本,该版本已完全移除 dockershim 组件,采用 containerd 作为容器运行时,同时保留 Docker 用于镜像构建和开发环境。
版本选择理由:
- 移除 dockershim: Kubernetes 1.23.x 已完全移除 dockershim,采用标准的 containerd 运行时
- 配置简单: containerd 作为 K8s 原生运行时,无需额外适配器,降低部署复杂度
- 生产稳定: 经过大量企业生产环境验证,稳定性和可靠性有保障
- 长期支持: Kubernetes 1.23.x 属于 LTS 版本,官方提供长期支持
- 生态成熟: containerd 是 CNCF 毕业项目,生态完善,社区支持丰富
架构优势:
- Docker: 用于镜像构建、本地开发和测试,保持开发体验
- containerd: 作为 Kubernetes 容器运行时,提供稳定的生产环境
- 分离职责: 构建时使用 Docker,运行时使用 containerd,符合云原生最佳实践
- 兼容性好: Docker 构建的镜像可以直接在 containerd 上运行
适用场景:
- 企业级生产环境,追求稳定性和可靠性
- 需要保留 Docker 生态用于开发和构建
- 快速部署和交付项目,时间紧迫
- 遵循云原生最佳实践,使用标准容器运行时
1.2 核心优势
- 高可用架构: 三节点K8s集群,控制平面冗余,etcd数据持久化
- 全生命周期管理: CI/CD自动化流水线,从代码到生产一键部署
- 多环境隔离: 命名空间、资源配额、网络策略实现多团队协作
- 企业级监控: Prometheus+Grafana三级监控,智能告警机制
- 安全合规: RBAC权限管理、镜像安全扫描、敏感信息加密
- 数据持久化: StorageClass动态存储,满足不同应用需求
- 灾备恢复: 关键数据备份、故障自动恢复、灾难恢复方案
1.3 技术栈
| 类别 | 技术选型 | 版本 | 用途 |
|---|---|---|---|
| 容器运行时 | Docker CE | 20.10.x | 镜像构建、开发测试 |
| 容器运行时 | containerd | 1.6.x | Kubernetes 运行时 |
| 编排平台 | Kubernetes | 1.23.x | 容器编排 |
| 私有仓库 | Harbor | 2.5.x | 镜像存储 |
| CI/CD | Jenkins | 2.401.x | 持续集成部署 |
| 监控系统 | Prometheus | 2.45.x | 指标采集存储 |
| 可视化 | Grafana | 9.5.x | 监控可视化 |
| 日志收集 | ELK Stack | 8.5.x | 日志分析 |
| 存储 | NFS | 4.1.x | 共享存储 |
| 负载均衡 | Nginx | 1.22.x | Ingress控制器 |
1.4 服务器规划
| 服务器IP | 角色 | 配置 | 部署组件 |
|---|---|---|---|
| 192.168.30.10 | Master-1 | 4C8G100G | K8s Master、etcd、Nginx Ingress、Prometheus |
| 192.168.30.11 | Master-2 | 4C8G100G | K8s Master、etcd、Grafana、Harbor |
| 192.168.30.12 | Master-3/Worker | 4C8G100G | K8s Master/Worker、etcd、Jenkins、NFS Server |
说明:
- 采用3节点高可用架构,每个节点同时运行Master和Worker角色
- etcd采用集群模式部署,数据三副本存储
- 组件分布确保单节点故障不影响集群整体可用性
二、高可用Kubernetes集群架构设计
2.1 集群架构图
┌─────────────────────────────────────┐
│ External Load Balancer (VIP) │
│ 192.168.30.100 │
└──────────────┬──────────────────────┘
│
┌──────────────┼──────────────────────┐
│ │ │
┌──────────▼──────┐ ┌────▼──────┐ ┌────────────▼──────────┐
│ 192.168.30.10 │ │192.168.30.11│ │ 192.168.30.12 │
│ Master-1 │ │ Master-2 │ │ Master-3/Worker │
├─────────────────┤ ├────────────┤ ├─────────────────────┤
│ API Server │ │ API Server │ │ API Server │
│ Scheduler │ │ Scheduler │ │ Scheduler │
│ Controller Mgr │ │ Controller │ │ Controller │
│ etcd-1 │ │ etcd-2 │ │ etcd-3 │
│ Kubelet │ │ Kubelet │ │ Kubelet │
│ Kube-proxy │ │ Kube-proxy │ │ Kube-proxy │
│ containerd │ │ containerd │ │ containerd │
│ Docker(构建) │ │ Docker(构建)│ │ Docker(构建) │
├─────────────────┤ ├────────────┤ ├─────────────────────┤
│ Nginx Ingress │ │ Harbor │ │ Jenkins │
│ Prometheus │ │ Grafana │ │ NFS Server │
│ Node Exporter │ │ Node Exp. │ │ Node Exporter │
└─────────────────┘ └────────────┘ └─────────────────────┘
│ │ │
└──────────────┼──────────────────────┘
│
┌──────────────▼──────────────────────┐
│ Kubernetes Cluster Network │
│ (Calico CNI - 10.244.0.0/16) │
└──────────────────────────────────────┘2.1.1 容器运行时架构说明
┌─────────────────────────────────────────────────────────────┐
│ Kubernetes 集群 │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ Kubelet │──────│ Kube-proxy │ │
│ └──────┬───────┘ └──────────────┘ │
│ │ │
│ │ CRI 接口 (Container Runtime Interface) │
│ │ │
│ ┌──────▼──────────────────────────────────────────────┐ │
│ │ containerd (容器运行时) │ │
│ │ - 容器生命周期管理 (创建、启动、停止、删除) │ │
│ │ - 镜像管理 (拉取、存储) │ │
│ │ - 存储驱动 (overlayfs) │ │
│ │ - 网络管理 (CNI 插件) │ │
│ └──────┬──────────────────────────────────────────────┘ │
│ │ │
│ │ │
│ ┌──────▼──────────────────────────────────────────────┐ │
│ │ Docker Engine (镜像构建) │ │
│ │ - 镜像构建 (Dockerfile、docker build) │ │
│ │ - 镜像推送 (docker push) │ │
│ │ - 本地开发 (docker run、docker ps) │ │
│ │ - CI/CD 集成 (Jenkins 构建) │ │
│ └──────┬──────────────────────────────────────────────┘ │
│ │ │
│ │ │
│ ┌──────▼──────────────────────────────────────────────┐ │
│ │ Linux 内核 (容器隔离) │ │
│ │ - Namespaces (UTS、PID、Network、Mount、User) │ │
│ │ - Cgroups (资源限制: CPU、内存、IO) │ │
│ │ - Capabilities (权限控制) │ │
│ └──────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘工作流程:
- 镜像构建: Docker Engine 根据 Dockerfile 构建镜像
- 镜像推送: Docker 将构建的镜像推送到 Harbor 私有仓库
- 镜像拉取: containerd 从 Harbor 拉取镜像到本地
- 容器运行: Kubelet 通过 CRI 接口调用 containerd 运行容器
- 资源隔离: containerd 利用 Linux 内核的 Namespaces 和 Cgroups 实现容器隔离和资源限制
为什么选择 Docker + containerd 架构:
- 职责分离: Docker 专注于镜像构建,containerd 专注于容器运行
- 最佳实践: 符合云原生标准,containerd 是 CNCF 毕业项目
- 性能优化: containerd 作为轻量级运行时,性能优于 Docker
- 开发体验: 保留 Docker 生态,开发体验不受影响
- 生产稳定: containerd 作为 K8s 原生运行时,稳定性更高
2.2 核心组件说明
2.2.1 控制平面组件
- API Server: 集群统一入口,RESTful API服务
- Scheduler: 资源调度,Pod分配到最优节点
- Controller Manager: 维护集群状态,副本控制、节点管理等
- etcd: 键值存储,集群配置和状态数据持久化
2.2.2 工作节点组件
- Kubelet: 与API Server通信,管理Pod生命周期
- Kube-proxy: 维护网络规则,实现Service负载均衡
- containerd: Kubernetes 容器运行时,负责容器生命周期管理
- Docker: 用于镜像构建、本地开发和测试,不作为 K8s 运行时
2.2.3 网络组件
- Calico CNI: 网络插件,实现Pod间网络通信
- Nginx Ingress: 七层负载均衡,外部流量入口
- CoreDNS: 集群内部DNS服务解析
2.3 高可用机制
2.3.1 控制平面高可用
- 多Master架构: 3个Master节点,任一节点故障不影响集群
- 负载均衡: Nginx+Keepalived实现VIP漂移,API Server高可用
- etcd集群: 3节点etcd集群,数据三副本,Raft协议保证一致性
2.3.2 应用高可用
- 多副本部署: 关键应用至少2个副本,跨节点分布
- Pod反亲和性: 确保Pod分布在不同节点
- 健康检查: Liveness/Readiness探针自动重启故障Pod
- 自动扩缩容: HPA根据CPU/内存使用率自动调整副本数
2.3.3 数据高可用
- etcd备份: 定期备份etcd数据,支持快速恢复
- 持久化存储: PVC绑定PV,Pod重建数据不丢失
- NFS共享存储: 多节点共享数据,避免单点故障
三、环境准备与基础配置
3.1 硬件要求
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| CPU | 4核 | 8核及以上 |
| 内存 | 8GB | 16GB及以上 |
| 磁盘 | 100GB | 200GB及以上(SSD) |
| 网络 | 千兆网卡 | 万兆网卡 |
| 操作系统 | CentOS 7.9 | CentOS 7.9(64位) |
3.2 系统初始化(所有节点执行)
3.2.1 配置主机名和hosts解析
bash
# 192.168.30.10节点
hostnamectl set-hostname k8s-master-1
# 192.168.30.11节点
hostnamectl set-hostname k8s-master-2
# 192.168.30.12节点
hostnamectl set-hostname k8s-master-3
# 所有节点执行
cat >> /etc/hosts << EOF
192.168.30.10 k8s-master-1
192.168.30.11 k8s-master-2
192.168.30.12 k8s-master-3
192.168.30.100 k8s-vip
EOF3.2.2 关闭防火墙和SELinux
bash
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭SELinux
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 验证
getenforce3.2.3 关闭Swap分区
bash
# 临时关闭
swapoff -a
# 永久关闭
sed -i '/swap/d' /etc/fstab
# 验证
free -h3.2.4 配置内核参数
bash
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.ipv4.conf.all.forwarding = 1
vm.swappiness = 0
vm.overcommit_memory = 1
vm.panic_on_oom = 0
fs.inotify.max_user_instances = 8192
fs.inotify.max_user_watches = 1048576
fs.file-max = 52706963
fs.nr_open = 52706963
net.ipv6.conf.all.disable_ipv6 = 1
net.netfilter.nf_conntrack_max = 2310720
EOF
# 加载内核模块
modprobe br_netfilter
modprobe ip_vs
modprobe ip_vs_rr
modprobe ip_vs_wrr
modprobe ip_vs_sh
modprobe nf_conntrack
# 使配置生效
sysctl -p /etc/sysctl.d/k8s.conf
# 配置开机加载
cat > /etc/modules-load.d/k8s.conf << EOF
br_netfilter
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
EOF3.2.5 配置时间同步
bash
# 安装chrony
yum install -y chrony
# 配置时间服务器
cat > /etc/chrony.conf << EOF
server ntp.aliyun.com iburst
server time1.cloud.tencent.com iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
allow 192.168.30.0/24
logdir /var/log/chrony
EOF
# 启动chrony服务
systemctl enable chronyd
systemctl start chronyd
# 验证时间同步
chronyc sources -v
date3.2.6 配置SSH免密登录(Master节点)
bash
# 在k8s-master-1节点生成密钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 复制公钥到其他节点
ssh-copy-id root@k8s-master-1
ssh-copy-id root@k8s-master-2
ssh-copy-id root@k8s-master-3
# 验证免密登录
ssh k8s-master-2 "hostname"
ssh k8s-master-3 "hostname"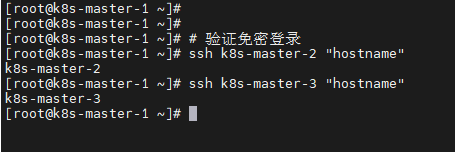
四、Docker环境部署
4.1 Docker安装(所有节点执行)
bash
# 1. 卸载旧版本
yum remove -y docker docker-client docker-client-latest docker-common \
docker-latest docker-latest-logrotate docker-logrotate docker-engine
# 2. 配置阿里云Docker YUM源
yum install -y yum-utils
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 3. 安装Docker CE
yum install -y docker-ce-20.10.24 docker-ce-cli-20.10.24 containerd.io
# 4. 启动Docker并设置开机自启
systemctl start docker
systemctl enable docker
# 5. 验证安装
docker version4.2 Docker配置优化
bash
# 1. 创建Docker配置目录
mkdir -p /etc/docker
# 2. 配置Docker daemon
cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": [
"https://xxxxx.xuanyuan.run"
],
"insecure-registries": ["192.168.30.11"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
EOF
# 3. 重启Docker
systemctl daemon-reload
systemctl restart docker
# 4. 验证配置
docker info | grep -E "Registry Mirrors|Cgroup Driver|Storage Driver"4.3 安装Docker Compose
bash
# 下载Docker Compose
curl -L "https://github.com/docker/compose/releases/download/v2.20.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# 添加执行权限
chmod +x /usr/local/bin/docker-compose
# 创建软链接
ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
# 验证安装
docker-compose --version4.4 配置containerd(所有节点执行)
bash
# 创建 containerd 和 CNI 配置目录
mkdir -p /etc/containerd/certs.d
mkdir -p /etc/cni/net.d
mkdir -p /opt/cni/bin
# 只在k8s-master-1执行,下载 CNI 插件包 (v1.2.0 兼容 Kubernetes v1.23.x)
wget https://github.com/containernetworking/plugins/releases/download/v1.2.0/cni-plugins-linux-amd64-v1.2.0.tgz
# 只在k8s-master-1执行,把 cni-plugins-linux-amd64-v1.2.0.tgz 发送到 192.168.30.11和12
scp cni-plugins-linux-amd64-v1.2.0.tgz root@192.168.30.11:/root/
scp cni-plugins-linux-amd64-v1.2.0.tgz root@192.168.30.12:/root/
# 2. 解压到 CNI 目录
tar zxvf cni-plugins-linux-amd64-v1.2.0.tgz -C /opt/cni/bin
rm -f cni-plugins-linux-amd64-v1.2.0.tgz
# 3. 验证安装
ls /opt/cni/bin
# 生成containerd 配置
cat > /etc/containerd/config.toml <<EOF
version = 2
root = "/var/lib/containerd"
state = "/run/containerd"
plugin_dir = ""
disabled_plugins = []
required_plugins = []
oom_score = 0
imports = ["/etc/containerd/config.toml"]
[grpc]
address = "/run/containerd/containerd.sock"
gid = 0
uid = 0
max_recv_message_size = 16777216
max_send_message_size = 16777216
[debug]
address = ""
uid = 0
gid = 0
level = ""
[metrics]
address = ""
grpc_histogram = false
[cgroup]
path = ""
[timeouts]
"io.containerd.timeout.shim.cleanup" = "5s"
"io.containerd.timeout.shim.load" = "5s"
"io.containerd.timeout.shim.shutdown" = "3s"
"io.containerd.timeout.task.state" = "2s"
[plugins]
[plugins."io.containerd.gc.v1.scheduler"]
deletion_threshold = 0
mutation_threshold = 100
pause_threshold = 0.02
schedule_delay = "0s"
startup_delay = "100ms"
[plugins."io.containerd.grpc.v1.cri"]
disable_tcp_service = true
stream_server_address = "127.0.0.1"
stream_server_port = "0"
stream_idle_timeout = "4h0m0s"
enable_selinux = false
selinux_category_range = 1024
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.7"
stats_collect_period = 10
enable_tls_streaming = false
max_container_log_line_size = 16384
disable_cgroup = false
disable_apparmor = false
restrict_oom_score_adj = false
max_concurrent_downloads = 3
disable_proc_mount = false
unset_seccomp_profile = ""
tolerate_missing_hugetlb_controller = true
ignore_image_defined_volumes = false
enable_cni = true
cni_load_timeout = "10s"
[plugins."io.containerd.grpc.v1.cri".containerd]
snapshotter = "overlayfs"
default_runtime_name = "runc"
no_pivot = false
disable_snapshot_annotations = true
discard_unpacked_layers = false
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
runtime_engine = ""
runtime_root = ""
pod_annotations = []
container_annotations = []
privileged_without_host_devices = false
base_runtime_spec = ""
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
BinaryName = ""
CriuImagePath = ""
CriuPath = ""
CriuWorkPath = ""
IoGid = 0
IoUid = 0
NoNewKeyring = false
NoPivotRoot = false
Root = ""
ShimCgroup = ""
[plugins."io.containerd.grpc.v1.cri".cni]
bin_dir = "/opt/cni/bin"
conf_dir = "/etc/cni/net.d"
max_conf_num = 1
conf_template = ""
ip_pref = "ipv4"
[plugins."io.containerd.grpc.v1.cri".registry]
config_path = ""
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://xxxx.xuanyuan.run"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."gcr.io"]
endpoint = ["https://xxxxx.xuanyuan.run"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."k8s.gcr.io"]
endpoint = ["https://xxxxxxxxx.xuanyuan.run"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."quay.io"]
endpoint = ["https://xxxxxxxx.xuanyuan.run"]
[plugins."io.containerd.grpc.v1.cri".image_decryption]
key_model = "node"
EOF
# 创建 loopback 网络配置(确保 containerd 能正常加载 CNI)
cat > /etc/cni/net.d/00-loopback.conf <<EOF
{
"cniVersion": "0.3.1",
"name": "lo",
"type": "loopback"
}
EOF
# 设置正确权限
chmod 644 /etc/cni/net.d/00-loopback.conf
# 1. 重新加载 systemd 配置
systemctl daemon-reload
# 2. 启动 containerd 服务
systemctl restart containerd
# 3. 设置开机自启
systemctl enable containerd
# 4. 验证服务状态
systemctl status containerd --no-pager
# 5. 验证 containerd 版本
ctr version
# 安装 crictl (必需工具)
# 1. 下载兼容版本 (crictl v1.24.0+ 支持 containerd 1.6+)
wget https://github.com/kubernetes-sigs/cri-tools/releases/download/v1.24.0/crictl-v1.24.0-linux-amd64.tar.gz
# 2. 解压到系统路径
tar zxvf crictl-v1.24.0-linux-amd64.tar.gz -C /usr/local/bin
rm -f crictl-v1.24.0-linux-amd64.tar.gz
# 3. 配置 crictl 连接 containerd
cat > /etc/crictl.yaml <<EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 30
debug: false
EOF
# 4. 设置环境变量(永久生效)
cat > /etc/profile.d/crictl.sh <<EOF
export CONTAINER_RUNTIME_ENDPOINT=unix:///run/containerd/containerd.sock
export IMAGE_SERVICE_ENDPOINT=unix:///run/containerd/containerd.sock
export CRI_CONFIG_FILE=/etc/crictl.yaml
EOF
# 5. 应用环境变量
source /etc/profile.d/crictl.sh
# 1. 验证 crictl 连接
crictl pods
# 2. 验证详细状态
crictl info | grep -E "cgroupDriver|sandboxImage|NetworkReady"
# 3. 验证 CNI 配置
crictl info | grep "lastCNILoadStatus"
# 4. 验证 CNI 插件
ls /opt/cni/bin | grep -E "bridge|loopback|host-local"
# 应显示已安装的 CNI 插件
# 5. 验证镜像源配置
grep -A 15 '\[plugins."io.containerd.grpc.v1.cri".registry.mirrors\]' /etc/containerd/config.toml五、Kubernetes集群部署
5.1 配置Kubernetes YUM源(所有节点执行)
bash
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
EOF5.2 安装Kubernetes组件(所有节点执行)
bash
# 安装kubelet、kubeadm、kubectl
yum install -y kubelet-1.23.17 kubeadm-1.23.17 kubectl-1.23.17
# 启动kubelet并设置开机自启
systemctl enable kubelet
# 验证安装
kubelet --version
kubeadm version
kubectl version --client5.3 初始化第一个Master节点(k8s-master-1执行)
bash
# 临时创建 192.168.30.100
# 将 192.168.30.100 添加到 ens33 接口的 IP 列表中
sudo ip addr add 192.168.30.100/24 dev ens33
# 查看输出,应该能看到 192.168.30.10 和 192.168.30.100 都在这个接口上
ip addr show dev ens33
# 创建kubeadm配置文件
cat > /root/kubeadm-config.yaml << EOF
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.30.10
bindPort: 6443
nodeRegistration:
criSocket: unix:///run/containerd/containerd.sock
name: k8s-master-1
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: v1.23.17
controlPlaneEndpoint: "192.168.30.100:6443"
networking:
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
dnsDomain: cluster.local
imageRepository: registry.aliyuncs.com/google_containers
apiServer:
certSANs:
- "192.168.30.100"
- "192.168.30.10"
- "192.168.30.11"
- "192.168.30.12"
- "k8s-vip"
- "k8s-master-1"
- "k8s-master-2"
- "k8s-master-3"
extraArgs:
authorization-mode: Node,RBAC
controllerManager:
extraArgs:
bind-address: 0.0.0.0
scheduler:
extraArgs:
bind-address: 0.0.0.0
---
apiVersion: kube-proxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
EOF
# 初始化集群
kubeadm init --config=/root/kubeadm-config.yaml --upload-certs
# 保存join命令和证书key(后续添加Master节点使用)
kubeadm token create --print-join-command
# join命令和证书key:
[root@k8s-master-1 ~]# 保存join命令和证书key(后续添加Master节点使用)
[root@k8s-master-1 ~]# kubeadm token create --print-join-command
kubeadm join 192.168.30.100:6443 --token gi5dxg.62rm1ewl9rf9wv4e --discovery-token-ca-cert-hash sha256:b5105e58fb6cc95f40c493263031c243f6669ce75f8f2ef8566e3fa467601c23
[root@k8s-master-1 ~]#5.4 配置kubectl(k8s-master-1执行)
bash
# 配置kubectl
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
# 验证集群状态
kubectl get nodes
kubectl get cs5.5 安装Calico网络插件(k8s-master-1执行)
5.5.1 部署前环境检查
bash
# 1. 检查节点状态
echo "=== 检查节点状态 ==="
kubectl get nodes -o wide
# 2. 检查系统Pod状态
echo "=== 检查系统Pod状态 ==="
kubectl get pods -n kube-system
# 3. 检查containerd配置
echo "=== 检查containerd配置 ==="
crictl info | grep -A 5 "cni"
# 4. 检查CNI插件
echo "=== 检查CNI插件 ==="
ls -la /opt/cni/bin/
# 5. 检查网络接口
echo "=== 检查网络接口 ==="
ip addr show | grep -E "^[0-9]+:|inet "
# 6. 检查内核模块
echo "=== 检查内核模块 ==="
lsmod | grep -E "br_netfilter|ip_vs|overlay"
# 7. 验证kubelet配置
echo "=== 验证kubelet配置 ==="
systemctl status kubelet --no-pager | head -20
# 8. 检查API Server连接
echo "=== 检查API Server连接 ==="
kubectl cluster-info5.5.2 下载并修改Calico配置
bash
# 1. 下载Calico YAML文件
echo "=== 下载Calico YAML文件 ==="
cd /root
wget https://docs.projectcalico.org/v3.24/manifests/calico.yaml -O calico.yaml
# 2. 备份原始文件
cp calico.yaml calico.yaml.bak
# 3. 修改Calico配置以适配当前环境
echo "=== 修改Calico配置 ==="
# 设置Pod网络CIDR(与kubeadm配置保持一致:10.244.0.0/16)
sed -i 's|# - name: CALICO_IPV4POOL_CIDR|# - name: CALICO_IPV4POOL_CIDR|g' calico.yaml
sed -i 's|# value: "192.168.0.0/16"| value: "10.244.0.0/16"|g' calico.yaml
# 设置IP自动检测方法(使用first-found)
sed -i 's|# - name: IP_AUTODETECTION_METHOD|# - name: IP_AUTODETECTION_METHOD|g' calico.yaml
sed -i 's|# value: "first-found"| value: "first-found"|g' calico.yaml
# 启用IPIP模式(确保跨节点网络通信)
sed -i 's|# - name: CALICO_IPV4POOL_IPIP|# - name: CALICO_IPV4POOL_IPIP|g' calico.yaml
sed -i 's|# value: "Always"| value: "Always"|g' calico.yaml
# 设置MTU值(根据网络环境调整,默认为1440)
sed -i 's|# - name: FELIX_IPINIPMTU|# - name: FELIX_IPINIPMTU|g' calico.yaml
sed -i 's|# value: "1440"| value: "1440"|g' calico.yaml
# 启用日志记录(便于故障排查)
sed -i 's|# - name: FELIX_LOGSEVERITYSCREEN|# - name: FELIX_LOGSEVERITYSCREEN|g' calico.yaml
sed -i 's|# value: "info"| value: "info"|g' calico.yaml
# 4. 验证配置修改
echo "=== 验证Calico配置 ==="
grep -A 2 "CALICO_IPV4POOL_CIDR" calico.yaml
grep -A 2 "CALICO_IPV4POOL_IPIP" calico.yaml
grep -A 2 "IP_AUTODETECTION_METHOD" calico.yaml5.5.3 分步部署Calico
bash
# 1. 创建Calico命名空间(如果不存在)
echo "=== 创建Calico命名空间 ==="
kubectl create namespace kube-system --dry-run=client -o yaml | kubectl apply -f -
# 2. 应用Calico配置
echo "=== 应用Calico配置 ==="
kubectl apply -f calico.yaml
# 3. 等待Calico Pod启动
echo "=== 等待Calico Pod启动 ==="
echo "这可能需要2-5分钟,请耐心等待..."
kubectl wait --for=condition=ready pod -l k8s-app=calico-node -n kube-system --timeout=300s
kubectl wait --for=condition=ready pod -l k8s-app=calico-kube-controllers -n kube-system --timeout=300s
# 4. 检查Calico Pod状态
echo "=== 检查Calico Pod状态 ==="
kubectl get pods -n kube-system -l k8s-app=calico
# 5. 查看Calico Pod详细信息
echo "=== 查看Calico Pod详细信息 ==="
kubectl describe pods -n kube-system -l k8s-app=calico-node | tail -205.5.4 验证Calico部署
bash
# 1. 检查Calico节点状态
echo "=== 检查Calico节点状态 ==="
kubectl get nodes -o wide
# 2. 检查Calico网络配置
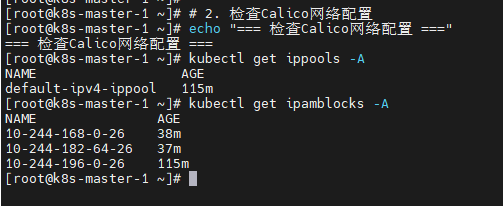
echo "=== 检查Calico网络配置 ==="
kubectl get ippools -A
kubectl get ipamblocks -A
# 3. 检查Calico组件日志(没出错可以不查看!)
echo "=== 检查Calico组件日志 ==="
kubectl logs -n kube-system -l k8s-app=calico-node --tail=50
kubectl logs -n kube-system -l k8s-app=calico-kube-controllers --tail=50
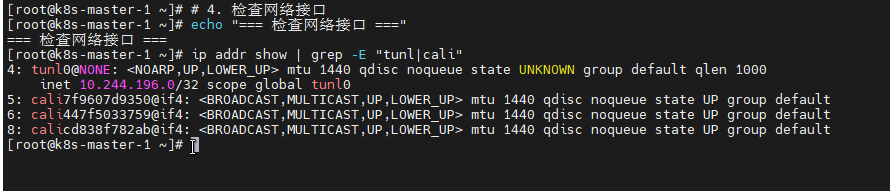
# 4. 检查网络接口
echo "=== 检查网络接口 ==="
ip addr show | grep -E "tunl|cali"
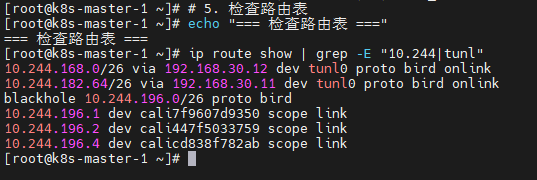
# 5. 检查路由表
echo "=== 检查路由表 ==="
ip route show | grep -E "10.244|tunl"
5.5.5 故障排查与修复
bash
# 1. 如果Calico Pod未就绪,检查错误
echo "=== 检查Calico Pod错误 ==="
kubectl get pods -n kube-system -l k8s-app=calico
kubectl describe pods -n kube-system -l k8s-app=calico-node | grep -A 10 "Events:"
# 2. 如果镜像拉取失败,手动拉取镜像
echo "=== 手动拉取Calico镜像 ==="
crictl pull calico/node:v3.24.5
crictl pull calico/cni:v3.24.5
crictl pull calico/kube-controllers:v3.24.5
crictl pull calico/pod2daemon-flexvol:v3.24.5
# 3. 如果CNI配置有问题,重新生成
echo "=== 重新生成CNI配置 ==="
rm -rf /etc/cni/net.d/*
kubectl apply -f calico.yaml
# 4. 如果网络接口异常,重启Calico Pod
echo "=== 重启Calico Pod ==="
kubectl delete pods -n kube-system -l k8s-app=calico-node
kubectl delete pods -n kube-system -l k8s-app=calico-kube-controllers
# 5. 等待Pod重新启动
echo "=== 等待Pod重新启动 ==="
kubectl wait --for=condition=ready pod -l k8s-app=calico-node -n kube-system --timeout=300s
kubectl wait --for=condition=ready pod -l k8s-app=calico-kube-controllers -n kube-system --timeout=300s5.5.6 移除Master污点(在Calico完全就绪后)
bash
# 1. 确认所有节点Ready
echo "=== 确认所有节点Ready ==="
kubectl get nodes
# 2. 确认Calico Pod全部Running
echo "=== 确认Calico Pod全部Running ==="
kubectl get pods -n kube-system -l k8s-app=calico
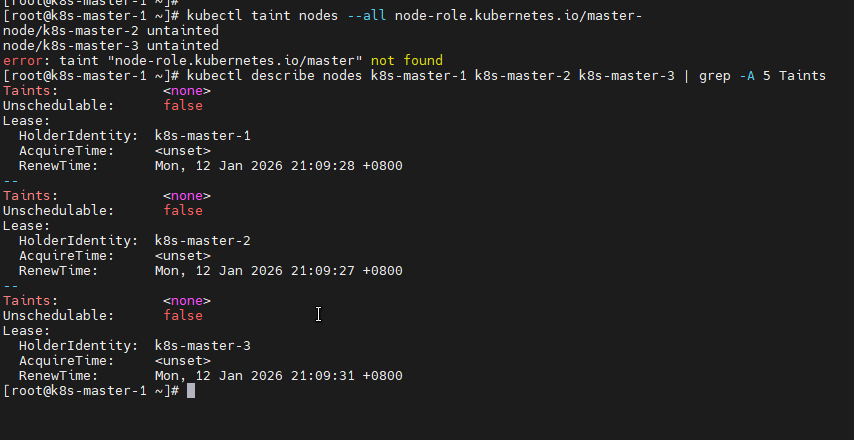
# 3. 移除Master污点(允许Pod调度到Master节点)
echo "=== 移除Master污点 ==="
kubectl taint nodes --all node-role.kubernetes.io/master-
# 4. 验证污点已移除
echo "=== 验证污点已移除 ==="
kubectl describe nodes k8s-master-1 k8s-master-2 k8s-master-3 | grep -A 5 Taints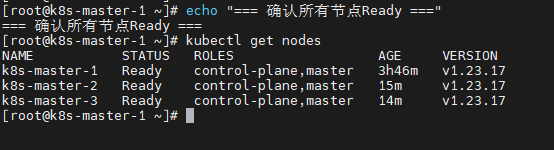 !
!

5.5.7 部署测试Pod验证网络
bash
# 1. 部署测试Pod
echo "=== 部署测试Pod ==="
kubectl run test-pod --image=busybox:1.28 --restart=Never -- sleep 3600
# 2. 等待Pod就绪
echo "=== 等待测试Pod就绪 ==="
kubectl wait --for=condition=ready pod/test-pod --timeout=120s
# 3. 查看Pod IP
echo "=== 查看测试Pod IP ==="
kubectl get pod test-pod -o wide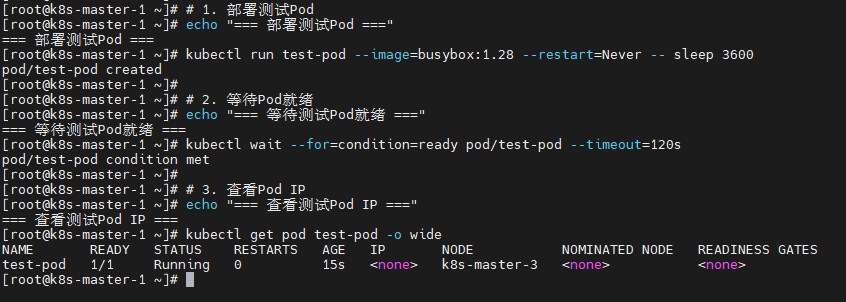
这个是我的私人镜像加速器的拉取记录,可以看到部署测试Pod时我拉取了:busybox:1.28
5.5.8 常见问题处理
问题1: Calico Pod一直处于Init状态
bash
# 检查Pod事件
kubectl describe pod -n kube-system -l k8s-app=calico-node
# 检查是否是镜像拉取问题
kubectl get pods -n kube-system -l k8s-app=calico-node -o jsonpath='{.items[*].spec.containers[*].image}'
# 手动拉取镜像
crictl pull calico/node:v3.24.5
crictl pull calico/cni:v3.24.5问题2: 节点NotReady,网络插件未就绪
bash
# 检查kubelet日志
journalctl -u kubelet -f
# 检查containerd日志
journalctl -u containerd -f
# 重启kubelet
systemctl restart kubelet
# 重启containerd
systemctl restart containerd问题3: Pod无法获取IP地址
bash
# 检查IP池状态
kubectl get ippools -A
# 检查IPAM块状态
kubectl get ipamblocks -A
# 查看Calico控制器日志
kubectl logs -n kube-system -l k8s-app=calico-kube-controllers问题4: Pod间无法通信
bash
# 检查网络策略
kubectl get networkpolicies -A
# 检查Calico Felix配置
kubectl get felixconfigurations.crd.projectcalico.org -A
# 查看Felix日志
kubectl logs -n kube-system -l k8s-app=calico-node5.6 添加其他Master节点(k8s-master-2和k8s-master-3执行)
bash
# 使用kubeadm init输出的join命令添加节点
# 示例(实际命令请使用k8s-master-1上输出的命令)
kubeadm join 192.168.30.100:6443 --token <token> \
--discovery-token-ca-cert-hash sha256:<hash> \
--control-plane --certificate-key <cert-key>
# 配置kubectl
mkdir -p $HOME/.kube
scp root@k8s-master-1:/etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
# 验证节点状态
kubectl get nodesk8s-master-2 添加Master节点
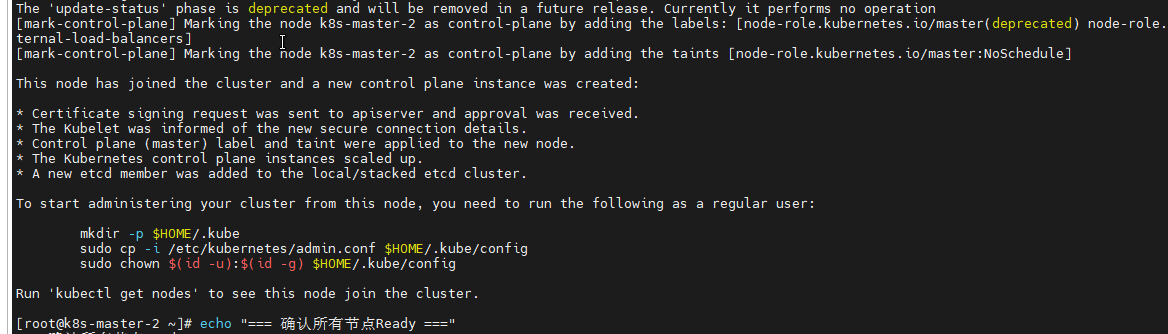
k8s-master-2 状态
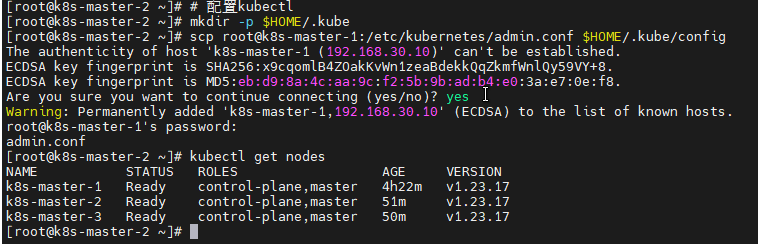
k8s-master-3 添加Master节点
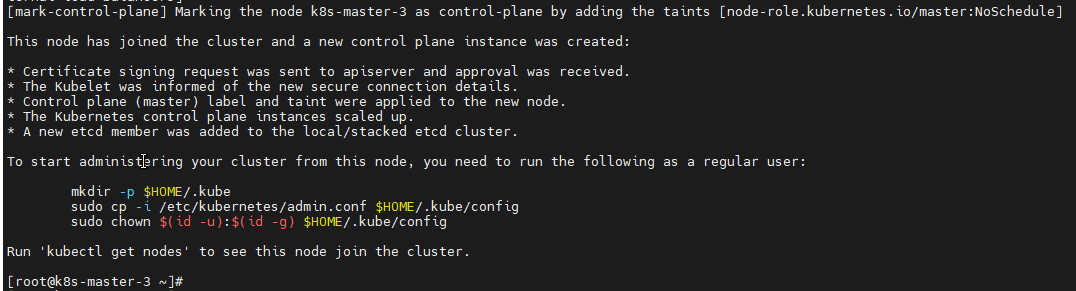
k8s-master-3 状态
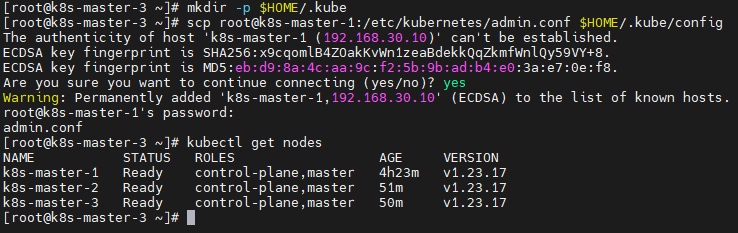
5.7 验证集群功能
5.7.1 节点状态验证
bash
# 1. 查看所有节点状态
echo "=== 查看所有节点状态 ==="
kubectl get nodes -o wide
# 2. 查看节点详细信息
echo "=== 查看节点详细信息 ==="
kubectl describe nodes
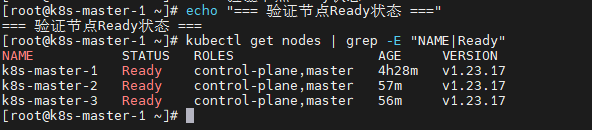
# 3. 验证节点Ready状态
echo "=== 验证节点Ready状态 ==="
kubectl get nodes | grep -E "NAME|Ready"
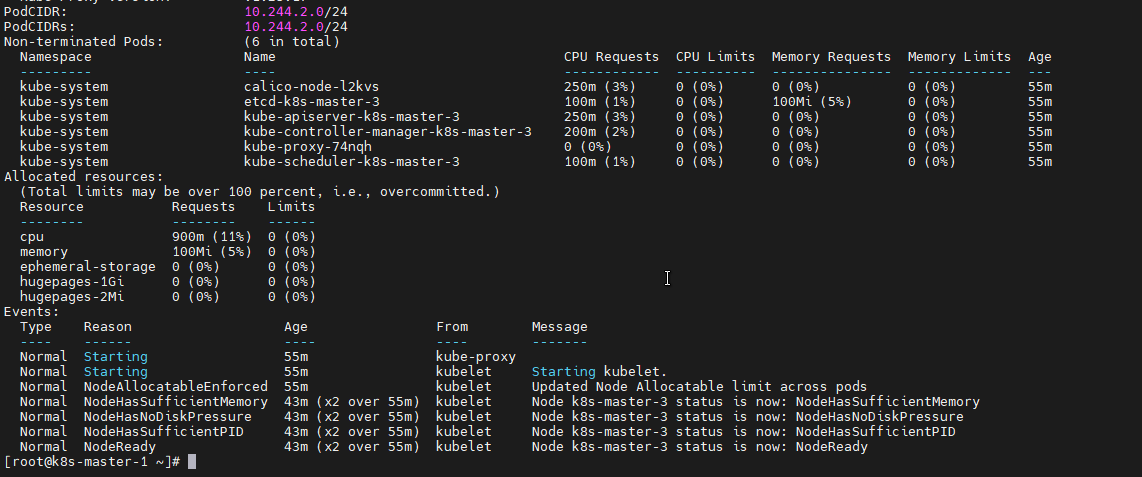
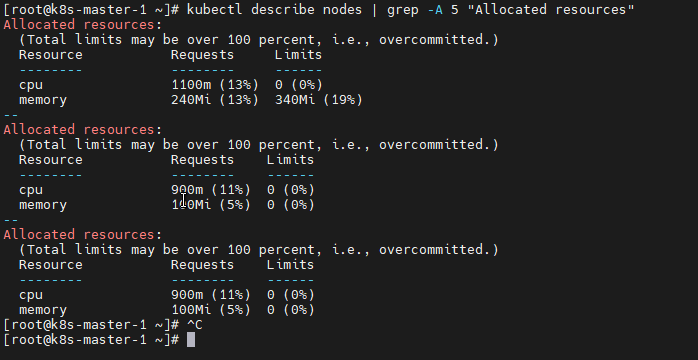
# 4. 检查节点资源
echo "=== 检查节点资源 ==="
kubectl describe nodes | grep -A 5 "Allocated resources"
5.7.2 系统Pod状态验证
bash
# 1. 查看系统Pod状态
echo "=== 查看系统Pod状态 ==="
kubectl get pods -n kube-system
# 2. 查看所有命名空间的Pod
echo "=== 查看所有命名空间的Pod ==="
kubectl get pods -A
# 3. 查看Pod详细信息
echo "=== 查看Pod详细信息 ==="
kubectl describe pods -n kube-system
# 4. 检查Pod健康状态
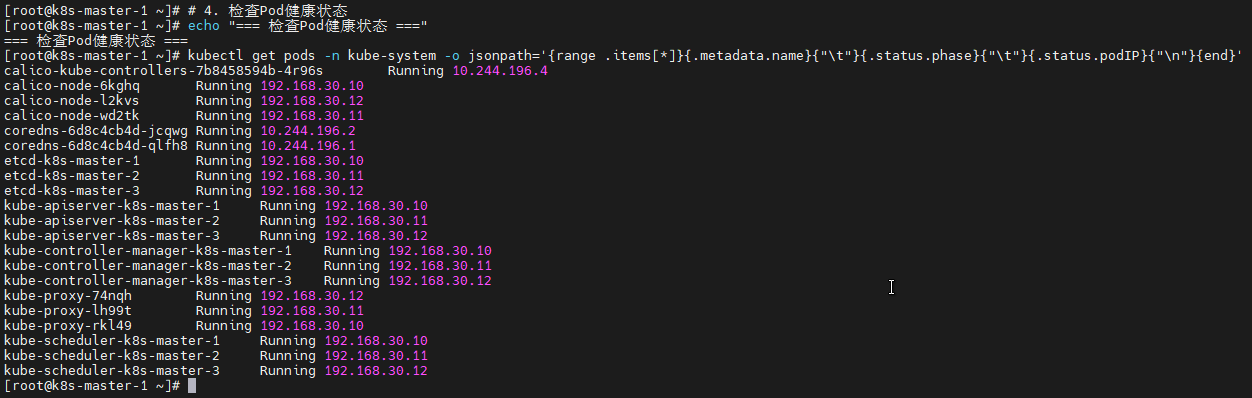
echo "=== 检查Pod健康状态 ==="
kubectl get pods -n kube-system -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.phase}{"\t"}{.status.podIP}{"\n"}{end}'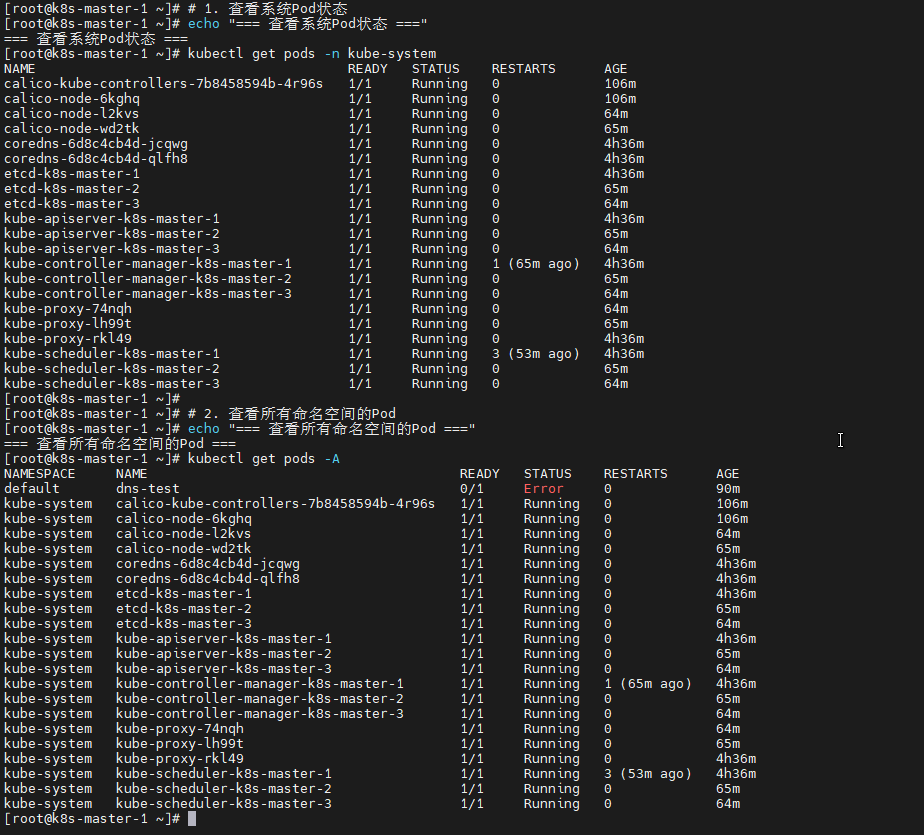
5.7.3 Pod网络通信测试
bash
# 1. 创建测试Deployment(跨节点部署)
echo "=== 创建测试Deployment ==="
cat > test-network.yaml << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: network-test
spec:
replicas: 3
selector:
matchLabels:
app: network-test
template:
metadata:
labels:
app: network-test
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- network-test
topologyKey: kubernetes.io/hostname
containers:
- name: network-test
image: busybox:1.28
command:
- sleep
- "3600"
EOF
kubectl apply -f test-network.yaml
# 2. 等待Pod就绪
echo "=== 等待测试Pod就绪 ==="
kubectl rollout status deployment/network-test --timeout=300s
# 3. 查看Pod分布
echo "=== 查看Pod分布 ==="
kubectl get pods -l app=network-test -o wide
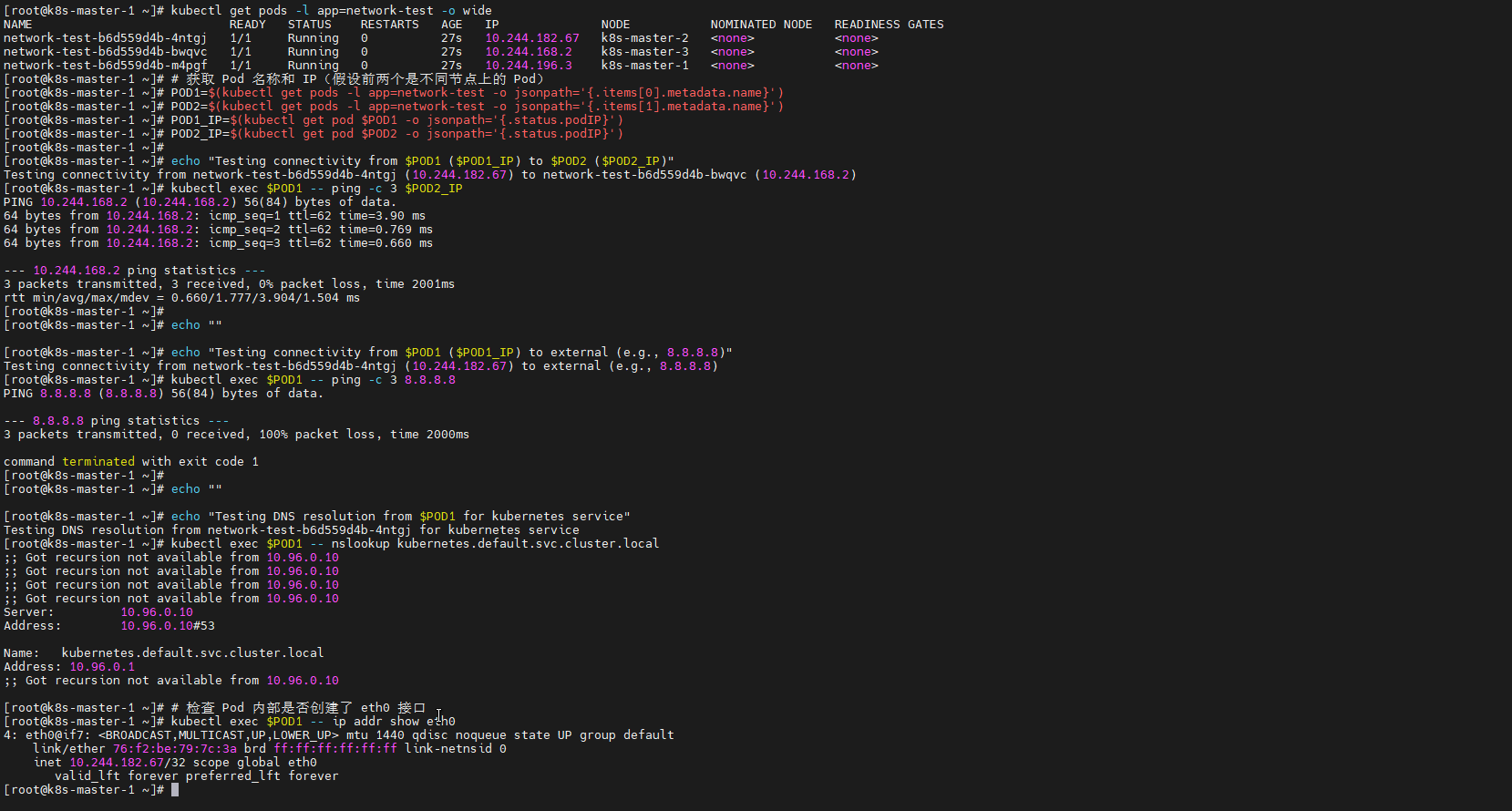
# 4. 测试Pod间网络通信
echo "=== 测试Pod间网络通信 ==="
POD1=$(kubectl get pods -l app=network-test -o jsonpath='{.items[0].metadata.name}')
POD2=$(kubectl get pods -l app=network-test -o jsonpath='{.items[1].metadata.name}')
POD1_IP=$(kubectl get pod $POD1 -o jsonpath='{.status.podIP}')
POD2_IP=$(kubectl get pod $POD2 -o jsonpath='{.status.podIP}')
echo "从 $POD1 ($POD1_IP) ping $POD2 ($POD2_IP)"
kubectl exec $POD1 -- ping -c 3 $POD2_IP
# 5. 测试跨节点通信
echo "=== 测试跨节点通信 ==="
kubectl exec $POD1 -- ping -c 3 8.8.8.8
# 6. 清理测试资源
echo "=== 清理测试资源 ==="
kubectl delete -f test-network.yaml
rm -f test-network.yaml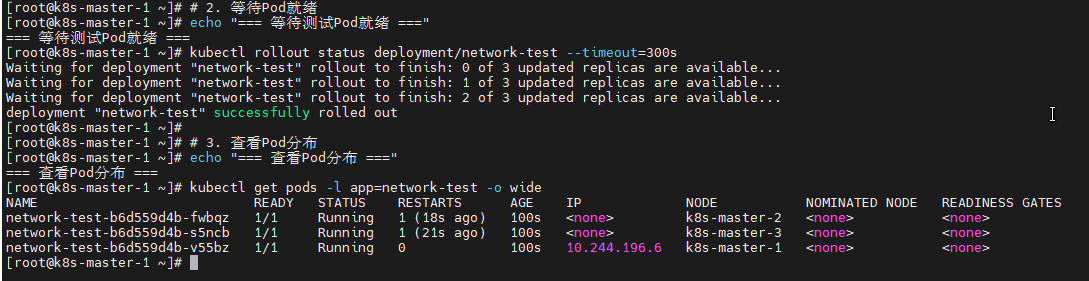
5.7.4 Service网络测试(持久的测试方法)
bash
# 1. 创建测试Service
echo "=== 创建测试Service ==="
cat > test-service.yaml << 'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-test
spec:
replicas: 2
selector:
matchLabels:
app: nginx-test
template:
metadata:
labels:
app: nginx-test
spec:
containers:
- name: nginx
image: nginx:1.14
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-test
spec:
selector:
app: nginx-test
ports:
- port: 80
targetPort: 80
type: ClusterIP
EOF
kubectl apply -f test-service.yaml
# 2. 等待Pod就绪
echo "=== 等待Pod就绪 ==="
kubectl rollout status deployment/nginx-test --timeout=120s
# 3. 查看Service信息
echo "=== 查看Service信息 ==="
kubectl get svc nginx-test
kubectl describe svc nginx-test
# 4. 创建持久测试Pod
echo "=== 创建持久测试Pod ==="
kubectl run test-service-connectivity --image=nicolaka/netshoot:latest --command -- sleep 3600
# 5. 等待持久测试Pod就绪
echo "=== 等待持久测试Pod就绪 ==="
kubectl wait --for=condition=ready pod/test-service-connectivity --timeout=120s
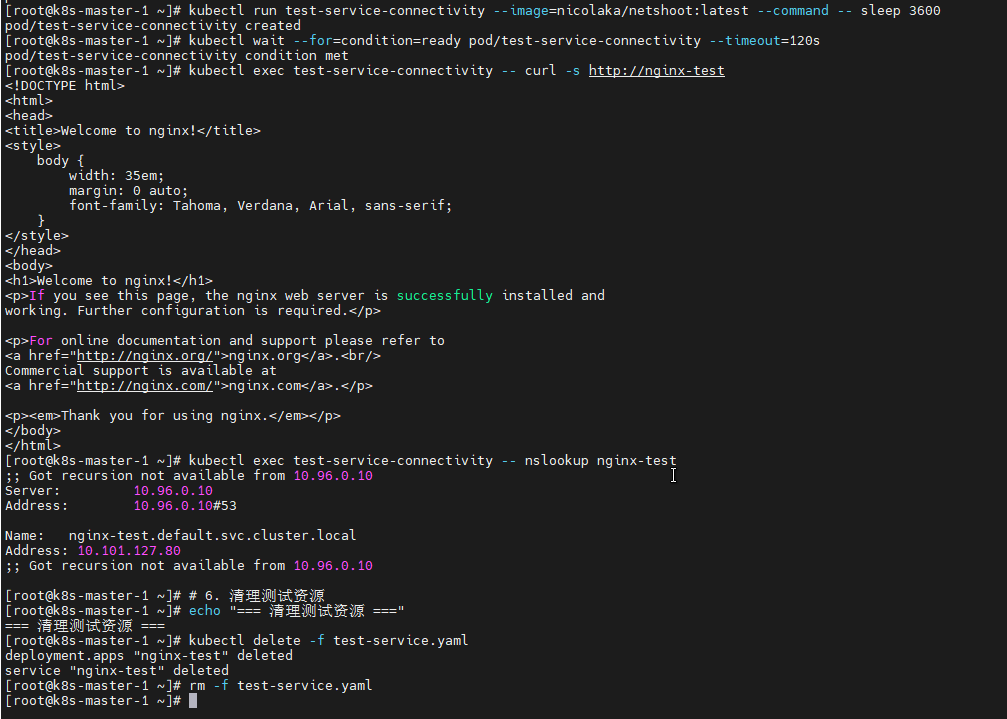
# 6. 测试Service访问 (从持久Pod内部)
echo "=== 测试Service访问 (从持久Pod内部) ==="
kubectl exec test-service-connectivity -- curl -s http://nginx-test
# 7. 测试Service DNS解析 (从持久Pod内部)
echo "=== 测试Service DNS解析 (从持久Pod内部) ==="
kubectl exec test-service-connectivity -- nslookup nginx-test
# 8. 清理测试资源
echo "=== 清理测试资源 ==="
kubectl delete -f test-service.yaml
kubectl delete pod test-service-connectivity
rm -f test-service.yaml验证照片:
5.7.5 集群健康检查
bash
# 1. 检查集群组件状态
echo "=== 检查集群组件状态 ==="
kubectl get cs
# 2. 检查集群信息
echo "=== 检查集群信息 ==="
kubectl cluster-info
# 3. 检查API Server健康状态
echo "=== 检查API Server健康状态 ==="
kubectl get --raw='/healthz'
# 4. 检查etcd健康状态
echo "=== 检查etcd健康状态 ==="
kubectl get --raw='/healthz/etcd'
# 5. 检查日志服务
echo "=== 检查日志服务 ==="
kubectl get --raw='/healthz/log'
# 6. 检查调度器
echo "=== 检查调度器 ==="
kubectl get --raw='/healthz/scheduler'
# 7. 检查控制器管理器
echo "=== 检查控制器管理器 ==="
kubectl get --raw='/healthz/controller-manager'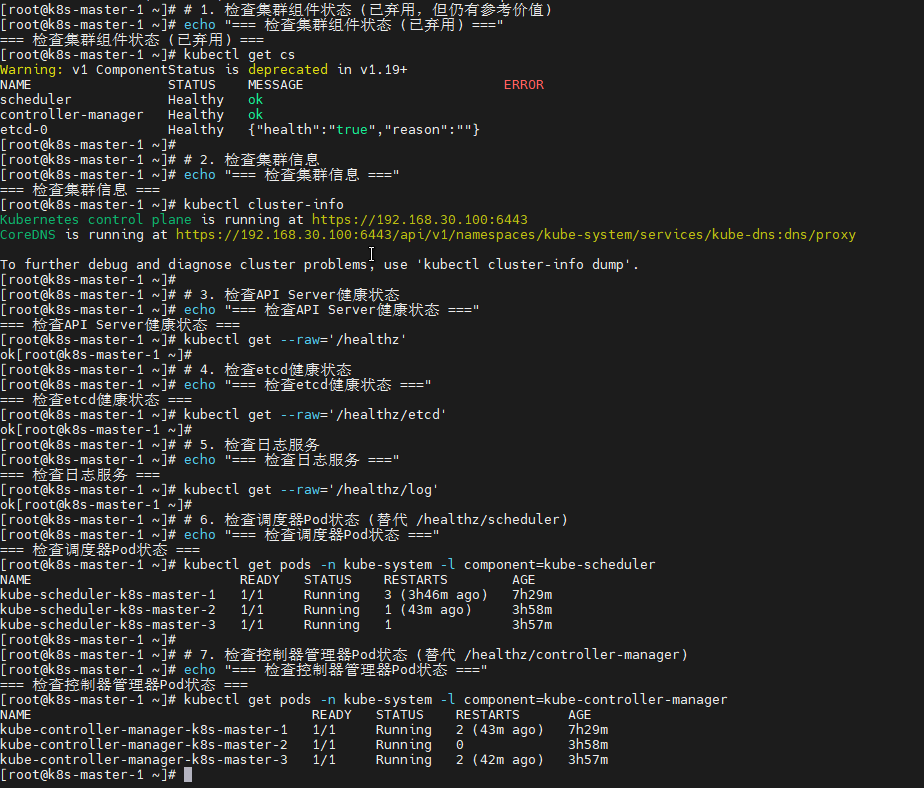
5.7.6 集群部署验证总结
bash
# 1. 生成集群状态报告
echo "=== 生成集群状态报告 ==="
echo "===== 集群节点状态 =====" > /tmp/cluster-status.txt
kubectl get nodes -o wide >> /tmp/cluster-status.txt
echo "" >> /tmp/cluster-status.txt
echo "===== 系统Pod状态 =====" >> /tmp/cluster-status.txt
kubectl get pods -n kube-system >> /tmp/cluster-status.txt
echo "" >> /tmp/cluster-status.txt
echo "===== 节点资源使用 =====" >> /tmp/cluster-status.txt
kubectl top nodes >> /tmp/cluster-status.txt
echo "" >> /tmp/cluster-status.txt
echo "===== 集群组件状态 =====" >> /tmp/cluster-status.txt
kubectl get cs >> /tmp/cluster-status.txt
echo "" >> /tmp/cluster-status.txt
echo "===== 集群信息 =====" >> /tmp/cluster-status.txt
kubectl cluster-info >> /tmp/cluster-status.txt
echo "" >> /tmp/cluster-status.txt
echo "===== 存储状态 =====" >> /tmp/cluster-status.txt
kubectl get pv,pvc -A >> /tmp/cluster-status.txt
echo "" >> /tmp/cluster-status.txt
echo "===== 网络状态 =====" >> /tmp/cluster-status.txt
kubectl get svc -A >> /tmp/cluster-status.txt
# 2. 显示报告
echo "=== 集群状态报告 ==="
cat /tmp/cluster-status.txt
# 3. 保存报告
echo "=== 集群状态报告已保存到 /tmp/cluster-status.txt ==="
# 4. 验证检查清单
echo "=== 集群部署验证检查清单 ==="
echo "✓ 所有节点状态为Ready"
echo "✓ 所有系统Pod状态为Running"
echo "✓ DNS解析正常"
echo "✓ Pod网络通信正常"
echo "✓ Service访问正常"
echo "✓ 存储功能正常"
echo "✓ 资源调度正常"
echo "✓ 健康检查正常"
echo ""
echo "如果以上所有项都正常,恭喜您!Kubernetes集群部署成功!"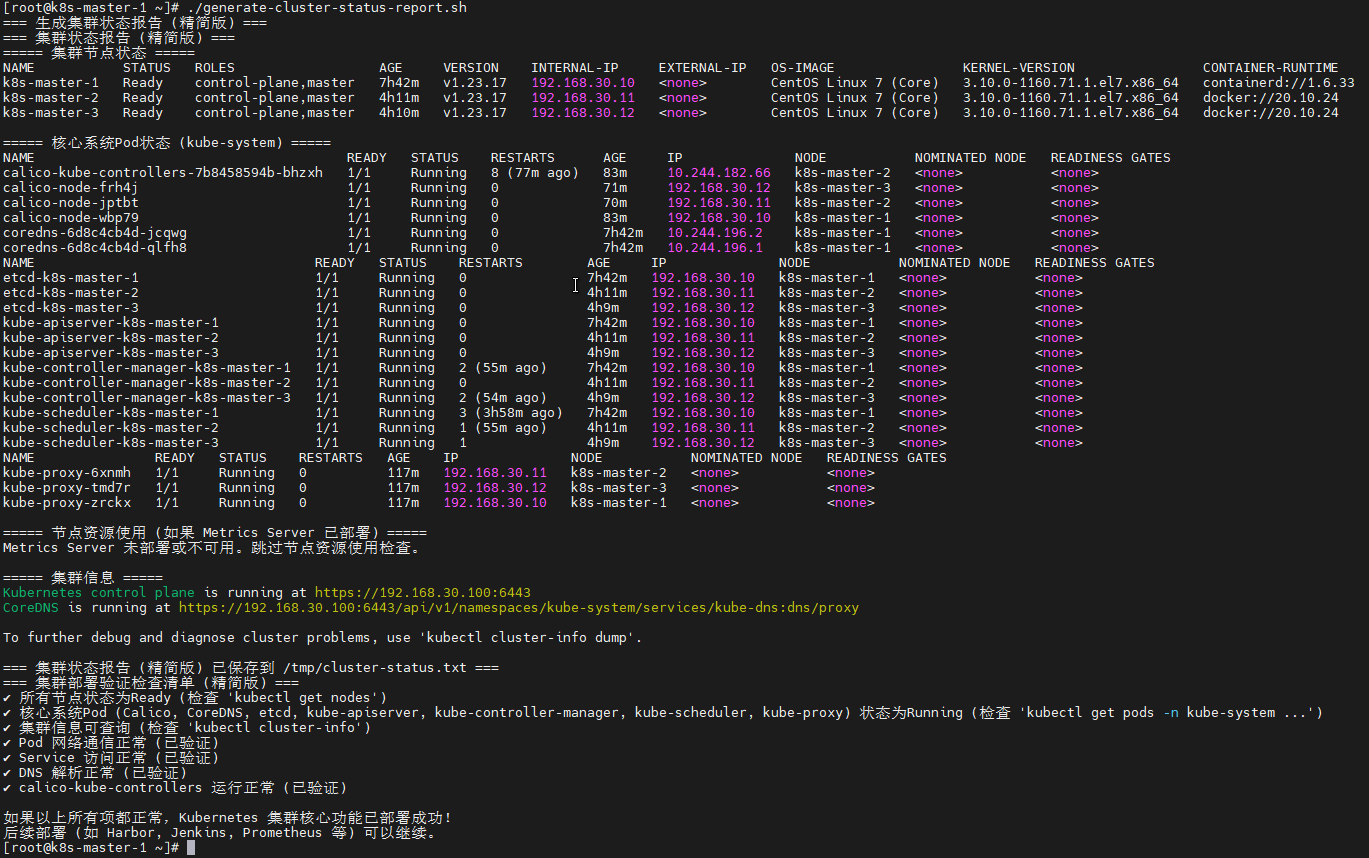
*注:本文档目前仅包含到第五章Kubernetes集群部署章节,后续章节将在后续逐步发布,敬请期待!