学 K8s 网络最容易卡在一种感觉上:名字都认识,放一起就乱。
kube-apiserver、kube-proxy、Calico(你写的 cailo 我按 Calico 理解)到底谁管什么?为什么都跟"网络"有关?更别说还牵扯网卡、网线、交换机这些"现实世界"的东西。你可能也问过:"是不是我 Service 访问不了,就是 apiserver 出问题?"
还真不一定。K8s 网络里最关键的一点是:控制面和数据面是分开的。你只要把这条线画出来,逻辑马上清晰。
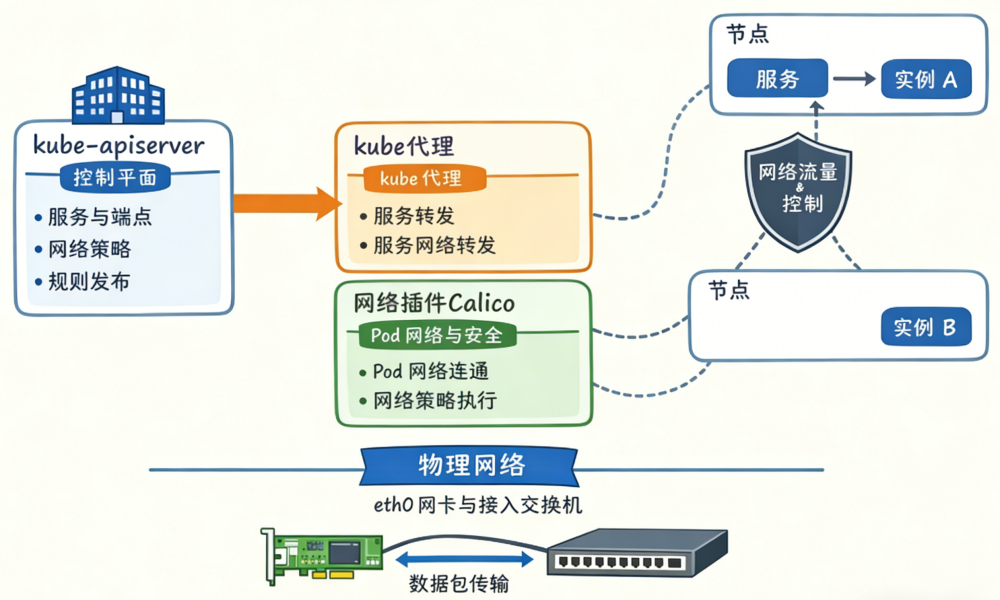
apiserver 管"规则",kube-proxy/Calico 管"落地",网卡网线负责"真搬运"
K8s 网络说复杂也复杂,说简单也简单:
kube-apiserver 是发布规则的地方,kube-proxy 和 Calico 是把规则变成转发/过滤动作的人,网卡网线才是数据包真正跑的路。
所以别再把所有网络问题都往 apiserver 身上扔------它很重要,但它并不转发你的业务流量。
kube-apiserver:网络对象的"登记处",不是转发器
kube-apiserver 的角色更像集群的"总台账":
-
Service、Endpoints/EndpointSlice、NetworkPolicy 这些对象都在这里存
-
各组件通过 watch 它来获取变化
-
权限控制(RBAC)、认证鉴权也在这里统一入口处理
但重点是:业务数据包不会经过 kube-apiserver。
你访问一个 Service,流量不会绕到控制平面去转一圈再回来。真那样的话,集群一忙就直接瘫了。
你可以把它想成:apiserver 是"交规发布中心",它负责告诉全世界"规则变了",但不负责在马路上指挥车辆。
kube-proxy:让 Service 这件事"真的能用起来"
Service 本质上是个"虚拟入口"。你访问的 ClusterIP 其实并不是某个真实 Pod,它只是一个抽象地址。那问题来了:这个虚拟入口怎么把流量导到后端 Pod?
kube-proxy 就是干这个的。
它会盯着两样东西:
-
Service(入口是什么)
-
Endpoints/EndpointSlice(后端 Pod 列表是谁)
然后在每个节点上写转发规则(常见 iptables 或 IPVS),最终效果就是:
-
你访问 Service 的 ClusterIP:Port
-
节点规则把流量转发到某个 PodIP:Port(顺带做负载均衡)
所以 kube-proxy 的定位很明确:
它解决的是"Service → Pod"的转发问题。
只要 Service 访问异常,这条链路就一定要排查:规则有没有下发?Endpoints 有没有更新?iptables/IPVS 是否正常?
Calico:把 Pod 网络"铺起来",再把 NetworkPolicy "执行起来"
如果 kube-proxy 解决的是 Service 的转发,那 Calico 更多解决的是另一层更基础的问题:
Pod 到底怎么联网?跨节点怎么互通?以及谁能访问谁?
Pod 网络连通:Calico 在"修路"
Pod 需要 IP,Pod 之间要互通,跨节点也要通。Calico 作为 CNI 插件,会负责:
-
给 Pod 分配 IP(IPAM)
-
把 Pod 接入节点网络(veth 等)
-
处理跨节点通信(不同模式下实现方式不同)
你可以简单理解成:Calico 把 Pod 网络这张"路网"铺好。
NetworkPolicy 落地:Calico 在"管控交通"
NetworkPolicy 在 K8s 里只是一个声明:写出来并不等于立刻生效,它需要具体网络插件去执行。Calico 就是常见的执行者:
-
监听 NetworkPolicy 的变化
-
在节点安装规则(iptables 或 eBPF 等)
-
决定某条流量"放行还是拦截"
所以 Calico 既修路,也管路。你想做"应用之间互相隔离",没有它(或者同类 CNI),光写 NetworkPolicy 是不够的。
把三者串起来:一次访问 Service 的流量到底经历了什么?
把场景拉到最常见的:访问一个 Service。
-
你创建 Service、Pod,相关对象写进 kube-apiserver(规则登记)
-
kube-proxy watch 到变化,在节点上生成转发规则(Service 能转到 Pod)
-
实际业务流量进入节点,按规则被转到目标 Pod
-
Pod 网络能不能通、跨节点能不能到,Calico 来保证
-
如果配置了 NetworkPolicy,Calico 决定这条流量是否允许通过
你看,分工是不是一下清楚了:
apiserver 负责"让大家看到规则",kube-proxy 和 Calico 负责"把规则变成动作",最后才轮到数据包真正跑起来。
网卡网线:K8s 再虚拟,最后还是要落在"物理世界"
说到底,K8s 网络再花哨,数据包最终还是要经过:
-
节点的物理网卡(比如 eth0)
-
交换机/路由器(也就是你说的网线那一层)
-
Linux 内核的路由、iptables、虚拟网卡(veth 等)
所以当你遇到"怎么都不通"的问题时,别只盯 K8s:
网卡有没有 up?IP 配得对吗?路由表对吗?MTU 对吗?交换机 ACL 有没有拦?
很多网络故障其实根本不是 kube-proxy、也不是 Calico 的锅,而是底层链路就没打通。
总而言之
-
kube-apiserver:发布和存储网络规则(Service、Endpoints、Policy),负责控制面
-
kube-proxy:把 Service 的访问引到正确 Pod,负责节点转发表(数据面转发)
-
Calico:提供 Pod 网络连通 + 执行 NetworkPolicy(数据面连通与隔离)
-
网卡网线:底层物理承载,所有虚拟网络最终都要落地到真实链路
换句话说:
apiserver 让规则"写得进去、看得见",kube-proxy/Calico 让规则"跑得起来",网卡网线让数据"真能走出去"。
这样理解,K8s 网络就没那么玄了。