前言
之前了解到了AI Agent 相关的一些基础概念,例如定义,LLM基础,Prompt Engineering,以及调 OpenAI API 等,接下来将介绍 LangChain 框架的基础知识和核心组件
LangChain 介绍
LangChain 是一个用于构建代理和大型语言模型应用的框架。
简单理解就是可以使用 LangChain 框架快速开发基于大模型的Agent和应用,可以连不同AI模型供应商提供的API,包括数据库、API、文件系统等
主要模块
langchain-core:核心抽象和基类langchain-community:社区贡献的集成和工具langchain-openai:OpenAI 模型集成langchain-text-splitters:文本分割工具langchain-vectorstores:向量存储集成
官网文档地址
docs.langchain.com/oss/python/...
安装
环境使用 Python 3.10+ 版本,据说 3.10 版本是最稳定的版本,建议使用 3.10 版本
安装 langchain 和 openai 包,如果是准备使用其他模型供应商的API,也需要安装对应的包
shell
pip install -U langchain
pip install -U langchain-openai构建一个简单的智能体
来看下官方的例子,引入 create_agent 函数,用于创建一个智能体,然后绑定一个工具函数 get_weather,用于获取天气信息,最后调用 invoke 方法来运行智能体
注意!,这个天气函数是一个简单的示例,实际中可能需要调用外部的天气 API 来获取真实的天气信息,或者手动写个静态的,让它返回固定的天气信息,能跑起来就行
python
from langchain.agents import create_agent
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[get_weather],
system_prompt="You are a helpful assistant",
)
# Run the agent
agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)官方的示例使用的 Claude 模型,需要改成 OpenAI 的模型,因为使用的是 OpenAI 的 Key,修改后的代码如下
python
from langchain.agents import create_agent
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# 加载环境变量
load_dotenv()
model = ChatOpenAI(
model_name="gpt-5-nano",
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0
)
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
agent = create_agent(
model=model,
tools=[get_weather],
system_prompt="You are a helpful assistant",
)
# Run the agent
response = agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)
# 打印完整响应
print("完整响应:", response)
# 如果响应包含结构化输出
if 'structured_output' in response:
print("结构化输出:", response['structured_output'])
# 或者如果响应包含消息
if 'messages' in response:
print("\n完整对话流程:")
print("-" * 50)
for msg in response['messages']:
# 根据消息对象类型确定角色
msg_type = type(msg).__name__
if msg_type == 'HumanMessage':
role = 'human'
content = msg.content
print(f"用户: {content}")
elif msg_type == 'AIMessage':
role = 'ai'
content = msg.content
print(f"助手:")
if content:
print(f" 回复: {content}")
# 检查是否有工具调用
if hasattr(msg, 'tool_calls') and msg.tool_calls:
for tool_call in msg.tool_calls:
# 尝试两种方式获取工具调用信息
try:
# 先尝试作为对象访问
tool_name = tool_call.name
tool_args = tool_call.args
except AttributeError:
# 如果失败,尝试作为字典访问
tool_name = tool_call.get('name', 'unknown_tool')
tool_args = tool_call.get('args', {})
print(f" 工具调用: {tool_name}")
print(f" 参数: {tool_args}")
elif msg_type == 'ToolMessage':
role = 'tool'
content = msg.content
# 检查是否有工具名称
tool_name = getattr(msg, 'name', '未知工具')
print(f"工具 {tool_name} 结果: {content}")
else:
# 处理其他类型的消息
content = msg.content if hasattr(msg, 'content') else str(msg)
print(f"{msg_type}: {content}")
print("-" * 50)运行后的效果如下
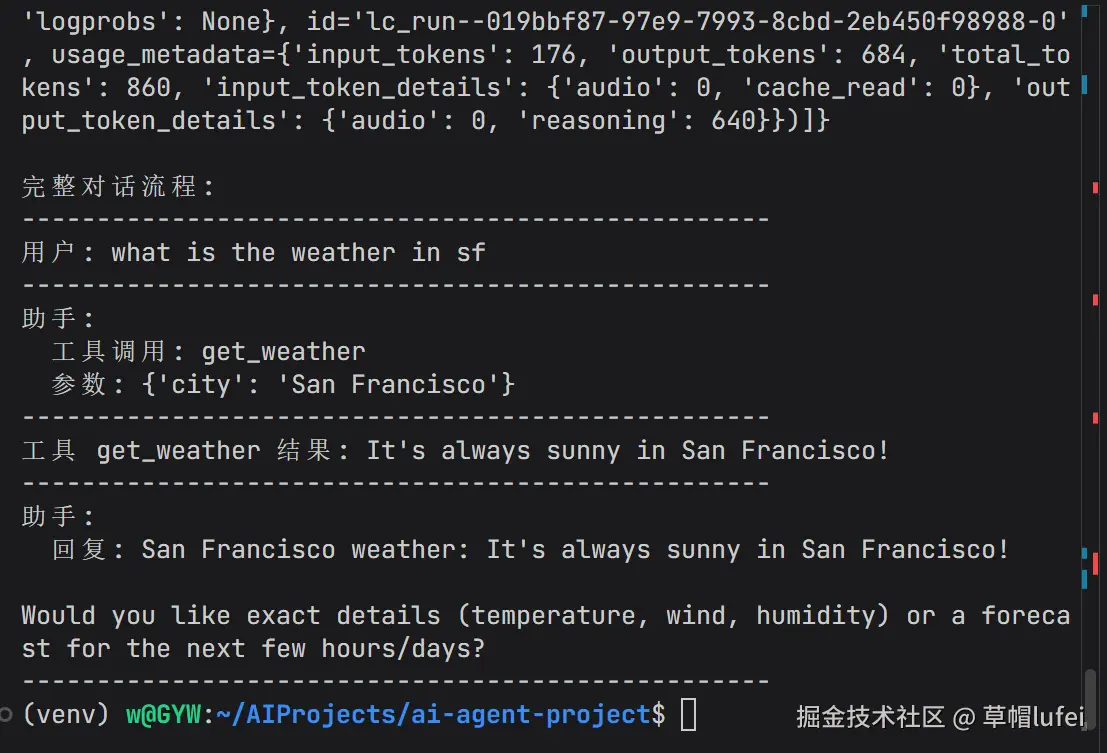
重点改动是输出,因为 agent.invoke 运行后,就完了,没有任何输出
python
response = agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)开始我还以为没运行成功,后来搜一下才知道,需要单独打印完整响应,格式化处理才能看到想要的输出,前端选手直接用Python运行代码学习的必爬之坑

为什么用Python,不直接用TS之类的去学习 LangChain 框架?
因为AI相关的Python生态是最完善的,其他语言也有,但是没有Python的生态完善,还有一个重要原因是,前端岗位已经要无了,直接用Python转后端或全栈,自己可能还能有一点点竞争力
换Key继续
因为 OpenAI 的免费账号申请的 Key 是有调用次数限制和频率限制,导致我在调试的时候,出现了报错的情况,搜了一下是 Key 调用次数多了,然后被限制了,这是问的 Google 具体描述如下

然后它提到了,Google AI Studio(Gemini API) 提供每天高达 1500 次的免费调用额度,哇哦,Google 可真是太豪了
还等什么,果断申请一个 Gemini API Key 继续学习

Gemini API Key 配置
在 .env 文件中添加 Gemini API Key
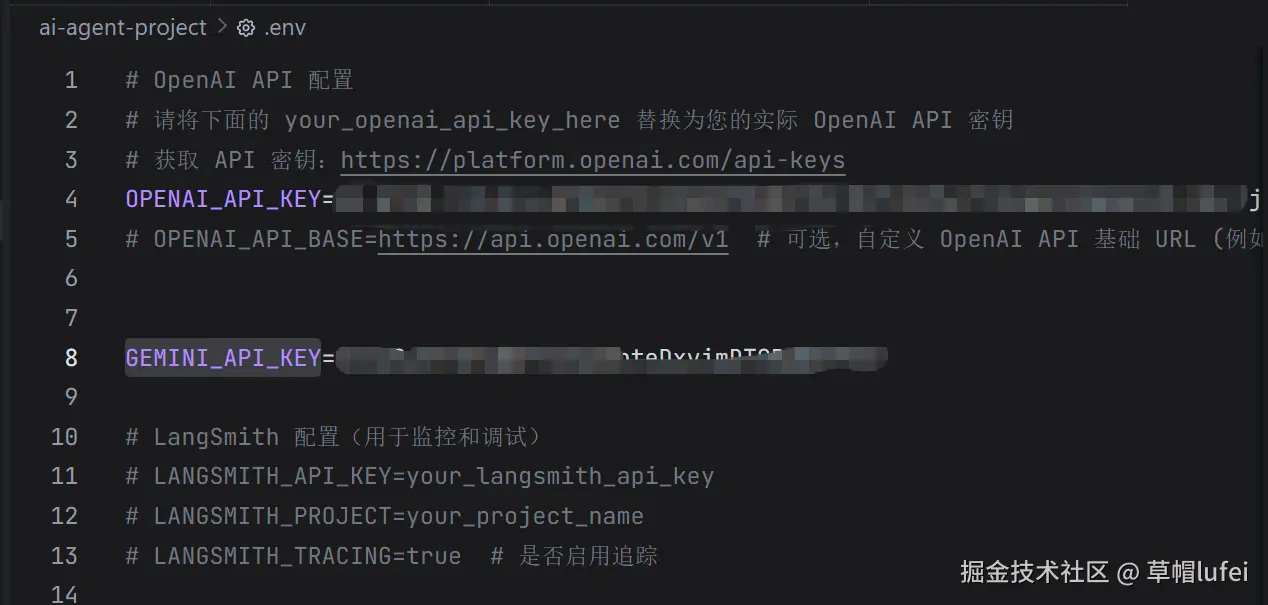
shell
GEMINI_API_KEY=your_gemini_api_key安装 Google GenAI SDK
shell
pip install -q -U google-genai重新创建一个文件,换上 Gemini API Key 测试一下请求,如果终端正确输出说明配置成功
python
from google import genai
import os
from dotenv import load_dotenv
load_dotenv()
client = genai.Client(api_key=os.getenv("GEMINI_API_KEY"))
response = client.models.generate_content(
model="gemini-3-flash-preview", contents="Explain how AI works in a few words"
)
print(response.text)很简单的替换,把原来 OpenAI 的部分换成 Gemini API 就行了
核心组件
接下来学习 LangChain 核心组件
Prompts(提示词)
这个不多说了,与 LLM 最基本的交互方式,内容包含提示词模板、少样本提示、输出解析器等
下面是一个简单的翻译例子,让AI把中文翻译成英文
python
# 创建提示词模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的翻译助手。请将用户的中文文本翻译成英文。"),
("user", "{input}")
])
# 初始化模型
model = ChatGoogleGenerativeAI(model="gemini-3-flash-preview")
# 组合链
chain = prompt | model
# 执行
result = chain.invoke({"input": "LangChain是一个强大的LLM应用开发框架。"})
# 只输出模型对话的结果
print(result.content[0]['text'])最后我添加了打印 result.content[0]['text'] ,只输出模型对话的结果,不然东西太多,影响调试,输出结果为如下内容
shell
(venv) w@GYW:~/AIProjects/ai-agent-project/Gemini$ python langchain.py
LangChain is a powerful LLM application development framework.Chains(链)
Chains 的作用是将多个组件组合在一起,形成一个完整的工作流程。包含以下类型:
- 简单链(Simple Chains)
- 顺序链(Sequential Chains)
- 分支链(Branch Chains)
- Runnable 接口
下面的例子中使用了 langchain_core 包中的 ChatPromptTemplate、StrOutputParser、RunnableParallel、 RunnableBranch、 RunnableLambda 等函数功能
简单链(Simple Chains)
上面的Prompts的代码中已经有了一个简单的翻译链
下面的简单链作用是将单个提示词和模型组合成一个简单的工作流
下面的这个函数添加了输出解析器,用于解析模型的输出,用 StrOutputParser 解析器能直接将将模型的输出转换为字符串
python
def simple_chain_example():
print("\n=== 1. 简单链(Simple Chains)示例 ===")
# 创建提示词模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的翻译助手。请将用户的中文文本翻译成英文。"),
("user", "{input}")
])
# 组合链:提示词 → 模型 → 输出解析器
chain = prompt | model | output_parser
# 执行
result = chain.invoke({"input": "LangChain是一个强大的LLM应用开发框架。"})
print(f"翻译结果: {result}")
return result顺序链(Sequential Chains)
顺序链的作用是将多个链按顺序连接,前一个链的输出作为后一个链的输入
重点看下面代码的 full_chain = translate_prompt | model | output_parser | uppercase_chain | count_chain
python
def sequential_chain_example():
print("\n=== 2. 顺序链(Sequential Chains)示例 ===")
# 优化提示词模板格式
# 第一个链:翻译中文到英文
translate_prompt = ChatPromptTemplate.from_template(
"请将以下中文文本翻译成英文:{chinese_text}"
)
translate_chain = translate_prompt | model | output_parser
# 第二个链:将英文文本转换为大写(使用Python内置函数替代模型调用)
def to_uppercase(text):
return text.upper()
uppercase_chain = RunnableLambda(to_uppercase)
# 第三个链:统计大写文本的单词数(使用Python内置函数替代模型调用)
def count_words(text):
return str(len(text.split()))
count_chain = RunnableLambda(count_words)
# 组合顺序链:翻译 → 大写转换 → 单词计数
full_chain = translate_prompt | model | output_parser | uppercase_chain | count_chain
# 执行顺序链
input_text = "LangChain是一个强大的LLM应用开发框架。"
word_count_result = full_chain.invoke({"chinese_text": input_text})
# 分步执行以显示中间结果
translated_text = translate_chain.invoke({"chinese_text": input_text})
uppercase_text = to_uppercase(translated_text)
print(f"1. 原始文本: {input_text}")
print(f"2. 翻译结果: {translated_text}")
print(f"3. 大写转换: {uppercase_text}")
print(f"4. 单词数量: {word_count_result}")
return {
"chinese_text": input_text,
"english_text": translated_text,
"uppercase_text": uppercase_text,
"word_count": word_count_result
}分支链(Branch Chains)
分支链的作用是根据输入条件选择不同的处理路径,就像普通代码的if-else语句一样,RunnableBranch 是实现分支逻辑的重点
python
def branch_chain_example():
print("\n=== 3. 分支链(Branch Chains)示例 ===")
# 定义不同任务的提示词
translation_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的翻译助手。请将用户的中文文本翻译成英文。"),
("user", "{content}")
])
summarization_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的总结助手。请将用户的文本总结为一句话。"),
("user", "{content}")
])
explanation_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的解释助手。请用简单易懂的语言解释用户提到的概念。"),
("user", "{content}")
])
# 创建不同任务的链
translation_chain = translation_prompt | model | output_parser
summarization_chain = summarization_prompt | model | output_parser
explanation_chain = explanation_prompt | model | output_parser
# 定义分支条件函数
def route_by_task(input_dict):
task = input_dict.get("task", "").lower()
if "翻译" in task:
return translation_chain
elif "总结" in task:
return summarization_chain
elif "解释" in task:
return explanation_chain
else:
# 默认返回翻译链
return translation_chain
# 创建分支链
branch_chain = RunnableBranch(
(
lambda x: "翻译" in x.get("task", "").lower(),
translation_chain
),
(
lambda x: "总结" in x.get("task", "").lower(),
summarization_chain
),
(
lambda x: "解释" in x.get("task", "").lower(),
explanation_chain
),
translation_chain # 默认链
)
# 测试不同分支
test_cases = [
{"task": "翻译", "content": "LangChain是一个强大的LLM应用开发框架。"},
{"task": "总结", "content": "LangChain是一个用于开发LLM应用的开源框架,它提供了丰富的组件和工具,可以帮助开发者快速构建复杂的AI应用。"},
{"task": "解释", "content": "大语言模型"}
]
results = []
for i, test_case in enumerate(test_cases, 1):
result = branch_chain.invoke(test_case)
print(f"测试 {i} (任务: {test_case['task']}): {result}")
results.append(result)
return resultsRunnable 接口
Runnable 接口是 LangChain 中所有可运行组件的基类,它定义了组件的基本行为,如 invoke、batch 等。通过实现 Runnable 接口,自定义组件可以与 LangChain 的其他组件无缝集成,实现复杂的工作流
简单理解是组合不同的链或者组件功能,实现更复杂的工作流或者功能
重点看下面的例子中最后的返回 return 是返回了一个字典,包含了不同链的处理结果
python
def runnable_interface_example():
print("\n=== 4. Runnable 接口示例 ===")
# 创建基础提示词
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的助手。请根据用户的要求处理文本。"),
("user", "{input}")
])
# 1. RunnableLambda:创建自定义处理函数
def process_text(text):
return f"处理后的文本:{text.upper()}"
lambda_chain = RunnableLambda(process_text)
# 2. RunnableParallel:并行执行多个链
parallel_chain = RunnableParallel(
original=prompt | model | output_parser,
uppercase=prompt | model | output_parser | RunnableLambda(lambda x: x.upper()),
lowercase=prompt | model | output_parser | RunnableLambda(lambda x: x.lower())
)
# 3. RunnableSequence:顺序执行链(与 | 操作符等价)
from langchain_core.runnables import RunnableSequence
# 定义自定义解析器
def custom_parser(output):
# 简单示例:只返回包含"框架"的部分
if isinstance(output, dict) and "content" in output:
return output.content[0]['text'] if output.content else ""
return output
sequence_chain = RunnableSequence(
first=prompt,
middle=[model],
last=RunnableLambda(custom_parser)
)
# 测试Runnable接口
input_text = "LangChain是一个强大的LLM应用开发框架。"
# 测试RunnableLambda
lambda_result = lambda_chain.invoke(input_text)
print(f"RunnableLambda结果: {lambda_result}")
# 测试RunnableParallel
parallel_result = parallel_chain.invoke({"input": input_text})
print(f"RunnableParallel结果:")
for key, value in parallel_result.items():
print(f" {key}: {value}")
# 测试RunnableSequence
sequence_result = sequence_chain.invoke({"input": input_text})
print(f"RunnableSequence结果: {sequence_result}")
return {
"lambda_result": lambda_result,
"parallel_result": parallel_result,
"sequence_result": sequence_result
}小结
面向AI的学习方式很快,读代码的话需要有一定的基础,比如Python,LLM等,对应的代码自己去运行一下,然后改改参数,看看效果,在实践中去理解组件/函数的功能和作用,下一篇学习LangChain的核心组件 Memory(记忆)和 Document Loaders(文档加载器)
欢迎留言交流,如果觉得有帮助,可以
点个赞支持一下公众号:草帽lufei